A collaborative approach to build a KBS for crop selection: combining experts knowledge and machine learning knowledge discovery

Author: Mulualem Bitew Anley, Tibebe Beshah Tesema
Journal: International Journal of Information Engineering and Electronic Business @ijieeb
Article in issue: 3 vol.11, 2019.
Free access
Selecting proper crops for farmland involves a sequence of activities. These activities and the entire process of farming require a help of expert knowledge. However, there is a shortage of skilled experts who provide advice for farmers at district level in developing countries. This study proposed designing knowledge based solution through the collaboration of experts’ knowledge with the machine learning knowledge base to recommending suitable agricultural crops for a farm land. To design the collaborative approach the knowledge was acquired from document analysis, domain experts’ interview and hidden knowledge were extracted from Ethiopia national meteorology agency weather dataset and from central statistics agency crop production dataset by using machine learning algorithms. The study follows the design science research methodology, with CommonKADS and HYBRID models; and WEKA, SWI-Prolog 7.32 and Java NetBeans tools for the whole process of extracting knowledge, develop the knowledge base and for developing graphical user interface respectively. Based on the objective measurement PART rule induction have the highest classifier algorithm which classified correctly 82.6087% among 9867 instances. The designed collaborative approach of experts’ knowledge with the knowledge discovery for agricultural crop selections based on the domain expert, farmers and agriculture extension evaluation 95.23%, 82.2 % and 88.5 % overall performance respectively.
Crop selection, Collaborative approch, Knowledge based system, Machine learning, Expertise knowledge, Knowledge acquisition
Short address: https://sciup.org/15016173
IDR: 15016173 | DOI: 10.5815/ijieeb.2019.03.02
Text of the scientific article A collaborative approach to build a KBS for crop selection: combining experts knowledge and machine learning knowledge discovery
Published Online May 2019 in MECS
Crop selection is a process of picking suitable crops for a farm unit based on the physical, economical, climatic and sociopolitical factors associated with the farm unit [1]. Those parameters are affecting the production yield of the crop. Farmers are facing a challenge during their cropping plan [1]. Taking a correct selection at suited time is directly affecting the product of the crop. Taking a selection is a very complex process as there are various factors affecting whole farming process. In order to enhance the decision, it needs to consider rainfall parameters, atmospheric condition, humidity, type of soil and many other factors [2].
Land evaluators and crop experts help farmers to choose the most productive crop that is best suited for a farm unit by assessing its land characters. But not all farmers get such advice and information, especially farmers living in developing country Ethiopia also no exception [3,4]. On the other hand, agriculture is the main source of economy and the means of employment for nearly 85 percent of the population, meals supply of the home market and methods for outside cash acquiring. The sector is sensitive distinctly affected with the aid of climate condition, poor agronomic practice, lack of market connection, scarcity of skilled professionals who provide advice for farmers at district stage [2]. Beside of these, agricultural specialist assistance is not always available when the farmer needs it. In order to alleviate this problem a collaborative approach for combining experts’ knowledge with results of knowledge discovery is a suitable solution that can overcome the scarcity of experts [3, 5]. Knowledge can be acquired from different sources such as making interview with the domain experts, document analysis, observation and automatic by using machine learning. Since tacit knowledge is personal and the knowledge expert may not tell all the knowledge she or he knows during the interview, there is hidden knowledge about the problem. Machine learning more general knowledge discovery techniques proposed for extracting hidden and previously unknown knowledge from datasets by different researchers [6].
-
II. Related Works
A study by Joshi [7] attempted to examine the fuzzy based intelligent system to predict most suitable crop. The fundamental goal of the work is to outline, improvement and organization of a fuzzy based agricultural decision support system which help farmers to make wise decisions regarding selection of a crop. They used a rule based system fuzzy DSS in light of MATLAB and they considered 15 parameters which are greatest among contemporary works and 22 different fuzzy rules.
Another study conducted by Thirumurugan [3] conducted on the design and development of a prototype knowledge based spatial decision support system. The investigation concentrates on assessing land assets and choosing suitable agricultural crops for a farm unit. The researcher considers the land evaluation process by including many experts from varied scientific domains. They at long last create a crop advisor expert system takes land information and recommend in consultation with the farmer a gathering of appropriate harvest decisions that are best as far as physical, monetary, social and political elements related with a farm unit.
A study by Abdulkerim [8] has conducted research on integrating data mining with knowledge based system on the network intrusion detection area and general objectives of his study was to construct a prototype knowledge base system which can update its knowledge base using the hidden knowledge extracted from the intrusion dataset by using data mining techniques. The researcher used knowledge discovery the database (KDD) model for the data mining task, rule based knowledge representation approach to represent knowledge, prototyping approach to develop the knowledge based system, WEKA 3.8.1 to mine hidden knowledge and compare the performance of classifiers, Java NetBeans IDE 7.3 with JDK 6 to develop an integrator application, PROLOG to represent rules in knowledge base, Precision, Recall, F-measure and True Positive rate to evaluate accuracy of the models and test cases to evaluate the performance of the KBS. The system was aimed at utilizing hidden knowledge extracted by employing an induction algorithm of data mining, specifically JRip from sampled KDDcup‘99 intrusion dataset. They recommended integration of machine learning with a knowledge based system in other domain areas than intrusion detection specially the area that scarce of domain expert.
However, most of the research that has been conducted in the area of KBS their knowledge base was dependent on either domain expert knowledge only or on machine learning techniques which will limit the performance of the recommender. As pointed by [9, 10] each approach has its own limitation on the DSS. In the domain expert only knowledge acquisition experts do often provide a mixture of relevant, irrelevant and erroneous information. On the other side the machine learning approach has a limitation of the too dependent on the data that is provided from outside. According to [11] that have a problem of discovering knowledge might not be the needs of the real world and also has a problem of the rules surplus in depth and in quantity. Due to these problems the user of the rule is needed to decide many times during the use of the rule. Another problem the algorithm produces so many rules that are confused to choose the best rule to make a decision and the rules have too far from the facts so decision maker doesn’t believe that rule to make a decision in real world decision making process. A study conducted by [12] stated that collaborating experts with a machine learning approaches was higher benefit to increase the accuracy of the developed knowledge base.
-
III. Methodology of the Study
-
3.1 General Research Approach
-
-
3.2 Data Source
For this study, we used crop production and land information data sourced from the central statics agency agricultural dataset from year 2009 up to year 2015 G.C and climatic dataset obtained from Ethiopian national meteorology agency covering from years 1952 to 2016.
-
3.3 Knowledge Modeling and Representation
-
3.4 Implementation Procedures and Tools
-
3.5 Validation and Evaluation Approaches
This study followed the design science research approach as suggested by [13] to design the collaborative approach based KBS that combine experts’ knowledge with machine learning knowledge for agricultural extensions and farmers to crop selection decision support system with GUI. According to [13] the design science research process have six basic steps those are problem identification and motivation, definition of objectives for a solution, design and development, demonstration and evaluation lastly communication.
The researcher used by adopting the hybrid knowledge discovery process model to acquire knowledge from the central statistical agency (CSA) agricultural dataset and climate condition data from the National Meteorology agency for machine learning knowledge discovery. Machine learning methods build models based on previous observations which can then be used to predict new data. The model built as a result of a learning process that extracts useful information about the data generation process of the system using the previous observations. ML methods take a set of data corresponding to the process (in this case the weather at a sensor) and construct a model of that process in a variety of ways to predict that process. The resulting model can be applied to future data to attempt to predict the crop selection of the knowledge base. We used classification methods J48, PART and JRip decision trees and rule induction classification algorithms.
Expert knowledge base design approach for the development of the knowledge based system we used the CommonKADS knowledge based design model.
CommonKADS gives handy documentation for framework configuration transform furthermore energize more awesome modularity and reusability of the model. Arranged with help knowledge engineers in selection knowledge representations and programming techniques with a specific end goal to create a decent outline of a KBS framework. Expects to do this in a way which is both nonspecific platform independent for as long as possible thus opening up possibilities for reusability and economical it encourages preservation of the structures within the expertise model. Now a day CommonKADS are the primary methodology to support KBS engineering. It helps to perform a detailed analysis of knowledge tasks and processes [14].
In order to mine the hidden knowledge from the preprocessed dataset and compare the performance of classifiers the researcher would use WEKA data mining tool. In order to process the data that was collected from the CSA we have used SPSS and Microsoft Excel software. To represent rules in the knowledge base and construct the prototype of crop selection knowledge based system, the researcher used SWI-Prolog. We have used JPL jar file for incorporating the SWI-prolog knowledge base into GUI and java NetBeans for developing the prototype of GUI system.
The performance of the model developed using machine learning techniques are evaluated based on accuracy of classifiers, Precision, Recall, F-measure and True Positive rate. The prototype of KBS is evaluated using system performance testing by preparing test cases. Moreover it is also tested by domain experts and users to ensure user acceptance and check the extent to which the system meets user requirements.
-
IV. Experiment And Result Findings
-
4.1. Knowledge Modeling
-
-
4.2. Knowledge Discovery
-
4.2.1 Data Preprocessing
-
-
4.2.2 Missing Value Handling Method
The researchers used mean imputation method for the meteorology agency dataset. This method is an effective method to fill missing values in the case of time series where the missed value is strongly related to its previous and next values. For NMA data total 11 attributes of the original dataset collected from since 1952 from different district and zonal stations. Among that dataset we use the data that are collected 2009-2015 G.C because of integrating with the CSA agricultural data and the remaining year data have high missing values from station to station. For the remaining NMA data attributes the researchers’ uses to handles the missed attribute, the attribute mean to fill in the missing value. For this research CSA agricultural data have total 43 attributes of the original data set, 9 attributes were ignored because of their high missing values and 15 attributes that have no relation to the research goals have been removed. For the remaining attributes the researchers uses to handles the missed attribute values a global constant to fill in the missing value.
-
4.2.3 Data Integration
-
4.2.4 Data Transformation and Data Conversion
-
4.2.5 Attribute Selection
The researchers have used expert knowledge and knowledge from machine learning knowledge elicitation. The expert knowledge are modeled by CommonKADS knowledge modeling. However, there are many methods for modeling the knowledge such as topic maps, semantic networks, mind map, etc. In the knowledge modeling stage UML was proposed as a standard notation for CommonKADS methodology for this research.
This research used weather and crop production sample survey datasets. CSA dataset was available in the SPSS software format in the CSA of Ethiopia database. Then, the researchers export those datasets into MS-excel for deciding on the usefulness of the data used as input for the stated machine learning methodology accordingly.
The integration was done by being able to identify attributes which match in both data sets and integrating the data based on those variables. In this case the basis for my integrating was the district, season and year where these variables were the same. Other points to consider during data integration on the time unit chosen as a basis for recording time of the data.
Table 1. Converted Attributes Value
|
S. No |
Attributes |
Previous Values |
Values after conversion |
|
1 |
Field Type |
Numeric {1, 2, 3} |
1=Pure Stand, 2= Mixed Crops 3= Other Land Use |
|
2 |
Percent of Field In Use |
Numeric{0, 100} |
0=Land Use Only, 100= Single Crop |
|
3 |
Seed Type |
Numeric{1, 2} |
1=Improved Seed, 2=Non Improved Seed, |
|
4 |
Irrigation Used |
Numeric{1, 2} |
1=YES, 2=NO |
|
5 |
Irrigation Source |
Numeric {1, 2, 3, 4, 5} |
1=River, 2=Lake, 3=Pond,4= Harvested Water, 5=Others |
|
6 |
Fertilizer Used |
Numeric{1, 2} |
1=YES, 2=NO |
|
7 |
Fertilizer Type |
Numeric {1, 2, 3} |
1=Natural, 2=Chemical, 3=Both |
|
8 |
Chemical Fertilizer Type |
Numeric {1, 2, 3, 9} |
1=UREA, 2=DAP,3= BOTH, 9=NOT STATED |
|
9 |
Crop Damage |
Numeric{1, 2} |
1=YES, 2=NO |
|
10 |
Prevention Measure Taken |
Numeric{1,2 } |
1=YES,2= NO |
|
11 |
Damage Prevention Type |
Numeric {1, 2, 3} |
1=Chemical, 2=Non Chemical, 3=Both |
|
12 |
Extension Program |
Numeric{1, 2} |
1=YES,2= NO |
|
13 |
Crop Type |
Numeric {1, 2, 7} |
1=BARLEY,2=MAIZE, 7=TEFF |
The process of converting an attributes values from numeric to nominal and vice versa. Since, for the purpose of this research work, the researchers employed to attribute values convert depicted on table 1.
The attributes used for conducting this research were selected using domain experts investigation and information gain attribute evaluator and ranker search method which are relevant to the proposed study. Descriptions of the selected attributes that have been taken from the original dataset for experimentation are shown in Table 2.
Table 2. Attributes Description
|
S. N o |
Attribute Name |
Represent ation Type |
Value |
Description |
|
1 |
Elevatio n |
Nominal |
high, medium and low |
Altitude of the district |
|
2 |
Tempera ture |
Nominal |
Low, medium, high |
Average temperature |
|
3 |
Fertilizer Type |
Nominal |
Natural, Chemical, Both |
Type of fertilizer farmers used |
|
4 |
Rain fall |
Nominal |
High, medium, low |
Annual rainfall in different stations |
|
5 |
FieldType |
Nominal |
Pure stand, Mixed crop |
A plot of land which is used to produce same or mixed crops |
|
6 |
Seed Type |
Nominal |
Improved, Non Improved |
Varieties of seeds |
|
7 |
Ownersh ip |
Nominal |
Private, leased |
Describes the owner of the farm land |
|
8 |
Fertilizer Used |
Nominal |
YES, NO |
Fertilizer used for harvesting |
|
9 |
Main Season |
Nominal |
Belg, meher |
Seasons for crop cultivation |
|
10 |
Crop yield |
Numeric |
Low, medium, high |
The total amount of crops produce |
|
11 |
Irrigatio n used |
Nominal |
YES, NO |
irrigation for cropping or not |
|
12 |
Percent of Field in Use |
Numeric |
Single crop, Land use only |
The field in which used to weather cropping |
|
13 |
Crop type |
Nominal |
Barley, Maize, Teff, |
Describes most common cereal crops on north Gondar. |
4.3 Experimental Settings
After data preparation task completed and suitable for WEKA data miner software, we continue the experiment for building a classification model that can support a decision for farmers to choice crops based on their farmland. In order to do these the researchers conduct twelve different experimentations in four models from each three classification algorithms on integrated field information dataset and meteorology datasets to select the best model. In all experiment we have using 9867
instances were taken for training and model building. These experiments were done by using J48 decision tree classifier, PART rule based classifier and JRip rule based classifier algorithms. In the experimentation test set, cross-validation (10 folds) and percentage split (66%) training options employed and WEKA 3.8.0 data mining tool was used. The experiments conducted using confidence factor it ranges from 0.5-0.4 and minnumobj from 1-35 for every classifier algorithm since it permits accomplishing better precision compared with changing the default parameter values.
-
4.3.1 Experiment one using J48 Decision Tree
The J48 algorithm is used for building the decision tree model. This experiment were conducted with two scenarios, J48 with pruned and J48 with unpruned tree. In addition the researchers used a test set, cross-validation and percentage split testing options. As a result pruned tree has been simple to interpret and understand the rules generated from the datasets and it makes the decision making easier. The pruned tree J48 model has 286 tree size and 172 numbers of leaves. The algorithm has correctly classified 8139 instances in other word 82.4871 % among 9867 instances and 1728 instances in other word 17.5129 % classified incorrectly and time taken to build model 0.74 seconds.
-
4.3.2 Experiment two using PART Rule Based Classifier
This experiment is done by using PART rule based classifier. This experiment was done by using testing set, cross- validation and percentage split test option belongs to the WEKA data mining software. Cross validation was better classified correctly for training the classification model. The model generates 108 rules. The algorithm has correctly classified 8151(82.6087 %) among 9867 instances and 1716 (17.3913 %) classified incorrectly and time taken to build model 0.32 seconds.
-
4.3.3 Experiment three using JRip
This experiment was done by testing set, crossvalidation and percentage split test option belongs to the WEKA data mining software. The algorithm generates a model with 32 rules and correctly classified instances are 7666(77.6933 %) and incorrectly classified instances are 2201(22.3067 %) from total number of instances of 9867. The algorithm takes 0.16 seconds to develop the model.
In algorithms evaluation, from above experiment, it is clearly observed that PART algorithm with the crossvalidation test option accuracy and TP rate is better than other algorithms. As a result, it is reasonable to conclude that PART algorithm is better than J48 and JRip method for this study. Therefore, the model which is developed with the PART rule with cross-validation test option classification techniques is considered as the selected working model for the next use in the development of machine learning knowledge base of the KBS and some of the rules generated from the selected model are presented here below:
Rules
Rule 1: If temperature = Low AND elevation = high AND rainfall = Medium AND Irrigation_used = No AND Crop_Yield = High: then crop type = BARLEY (1008.0/21.0)
Rule 2: If temperature = Low AND Crop_Yield = Low AND Main_Season = Belg AND Field_Type = Pure: then crop type= BARLEY (837.0/96.0)
Rule 3: if Fertilizer_Used = Yes AND
Fertilizer_Type = Both AND temperature = Medium
AND Irrigation_used = No AND Crop_Yield = High AND Field_Type = Pure: then crop type= TEFF
(11.0)
Rule 4: if Fertilizer_Used = Yes AND
Fertilizer_Type = Both AND rainfall = high AND Crop_Yield = Low: then crop type= MAIZE
(12.0/3.0)
Understanding of agricultural crop selection process
Understanding of crop production and metrology data
Inference engine
Machine Learning Knowledge Base
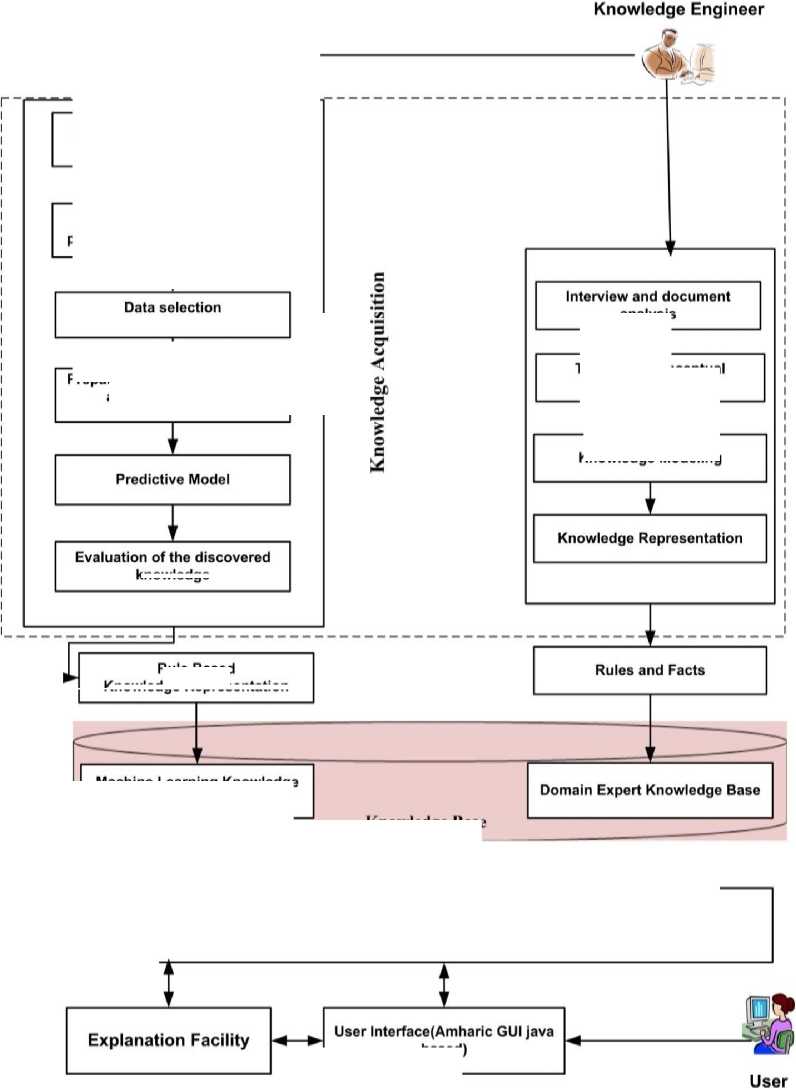
knowledge
Rule Based Knowledge Representation based)
Fig.1. Proposed Collaborative Approach Architecture
analysis
Preparation of crop production and metrology data
Transcript conceptual modeling
Knowledge Modeling
Knowledge Base
-
4.4 The Proposed Solution Architecture
-
4.4.1 Inference Engine
As depicted below on Figure 1 the design of knowledge based system through the collaboration of expert’s with the knowledge discovery to crop selection was begun from document analysis, interview the domain expert understanding the domain area and problem as a whole acquiring knowledge from the experts’ and from dataset using machine learning approaches. This research proposed to use dual knowledge base the first knowledge base contained in the machine learning rules which was extracted from the dataset by using a PART rule induction algorithm. The other knowledge base was contained the experts knowledge in the rule representation format. The inference engine inferred from those dual knowledge base for the user input parameters.
The contribution of this study is design an approach that collaborate the experts knowledge with the knowledge extracted by machine learning. The knowledge based system of this research, domain experts, knowledge collaboratively works with machine learning rule. Other contribution of this study, we have developed a java based GUI in Amharic language. Here below is the discussion of the above architecture through the collaboration of expert’s with the knowledge discovery for agricultural crop selection using GUI general collaborative approach.
After accessing the user interface the user feed the major land properties and climatic conditions parameter then the inference engine matches these with the existing rules in the knowledge bases and suggest most suited crop to that precise farming unit. It acts as an interpreter between the knowledge bases and the user interface here below the inference algorithms are discussed using flowchart depicted in figure 2.
Proposed Algorithm for Collaborative Inference
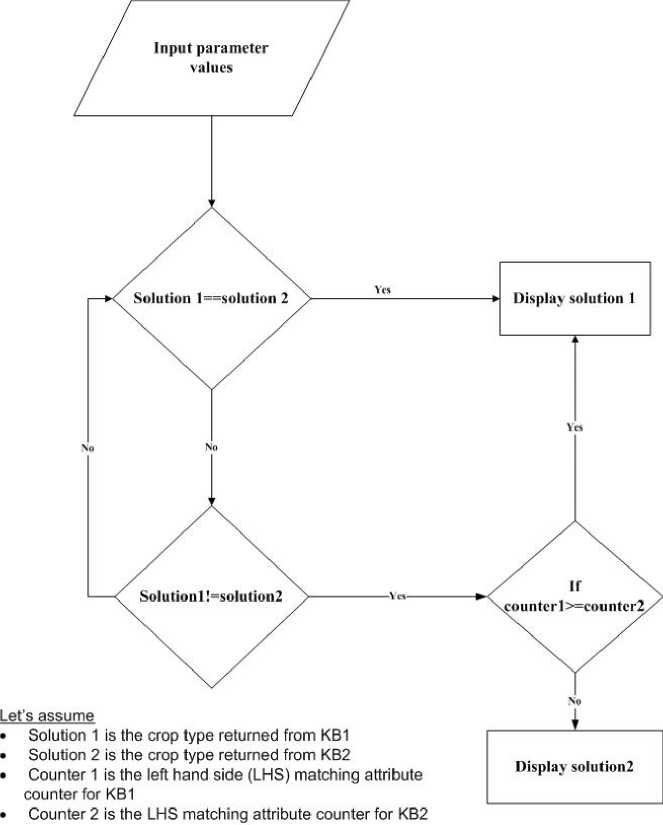
xounterl>=countcr2
Solution 1!=sol ution 2
Solution l=solution 2
Input parameter values
Let's assume
• Solution 1 is the crop type returned from KB1
• Solution 2 is the crop type returned from KB2
• Counter 1 is the left hand side (LHS) matching attribute counter for KB1
• Counter 2 is the LHS matching attribute counter for KB2
Display solution2
Display solution 1
Fig.2. Collaborative Approach Inference Engine Flow Chart
-
4.4.2 User Interface
According to [15] most farmers in Ethiopia are illiterate in somehow not more than reading and writing so it’s good to make the system that can be accessed on their own language. Alongside these studies is contributing to solve the gap that are rising on language barriers by designing and developing Amharic language GUI interface. Here below depicts on figure 3 the interface that the crop selection process pages.
As depicted in Figure 3 shows the user means agricultural extension and farmers properly select the options, then based on the given input the system return barley ( ገ ብስ ) as a recommended crop for the given input parameters.
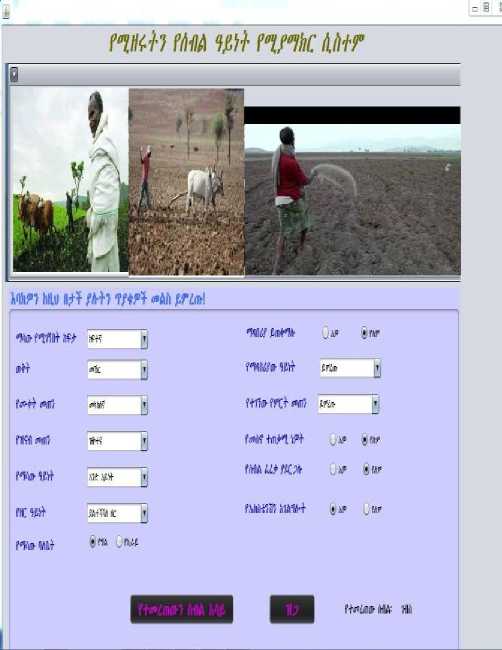
Fig.3. Crop Selection Recommendation Interface.
-
V. Evaluation And Validation
-
5.1 System Performance Testing
-
-
5.2 User Acceptance Testing
To evaluate the designed collaborative approach and prototype knowledge based system we have prepared test cases for evaluating the performance of the proposed system. Purposively the researchers prepared a total of 21 test cases and distributed to 4 domain experts. For each of the three crops type’s seven test cases are prepared. The domain expert expected to recommend crops based on the farm land area suitability and the estimated weather condition of the area for each test case. For comparing the performance of the experts and the KBS system confusion matrix is used. Based on the collected results from the domain experts evaluation of the total of 21 test cases the system classified 20 instances correctly to their corresponding classes and 1 instance classified incorrectly to other classes to the expected three crops. This means the proposed system’s agricultural crop selection recommendation has 95.23% accuracy according to the evaluation performed by the agriculture domain experts.
To accomplish the objectives of evaluation the researchers select evaluators by convenience sampling method 10 farmers and 10 agricultural extension workers in the study area. After the discussion of the system, in order to assess the user acceptance of the proposed system, questionnaires were distributed. For this study the format of the questionnaire was adapted from [4] study conducted on cereal crop disease diagnosis prototype KBS. Accordingly, to the farmers’ evaluation the system would have the 82.2% performance on the accuracy. The same evaluation questions were forwarded to the agricultural extension workers. According to the agricultural extension evaluation the system would have 88.5 % performance for accuracy.
-
VI. Conclusion And Recommendation
This study designed a collaborative approach to combine the domain experts’ knowledge with the knowledge discovery result and implemented a prototype knowledge based system for the agricultural crop selection. The approach we used in the knowledge based system development was different from the previous research on the agricultural crop selection. In addition, this research includes the climatic factor parameters for recommending the optimal crop to the farm land. Information gain attributes ranking method and domain experts’ evaluation were used and this study finds out that elevation, temperature, fertilizer type, rainfall, field type, seed type and soil type are the main factors to select crops to the farm land. We have done twelve experiments by using J48 decision tree classification algorithm as well as PART and JRip rule induction algorithms using test set, 10-fold cross validation and percentage split test options then after the experiment shows that the PART classification algorithm is the best classification algorithm to recommend the optimum crops for the farm land which classified 82.6087% correctly which means 8151 are classified correctly among 9867 instances. According to the selected farmers’ evaluation the developed prototype succeeds 82.2% performance by the domain experts’ evaluations have 95.23% accuracy and by the agricultural extensions evaluation the proposed solution succeed 88.5% performance.
We conclude that the collaborative approach based KBS we designed and developed prototype have the potential to increase the accuracy of knowledge based system and a way to collaboration of expertise with machine learning for decision support, at last for increasing the production of crops.
The machine learning knowledge base for this study was done by the knowledge engineer after the PART algorithm generated, further a researcher can also done to be automatically the machine learning rule read with the knowledge based system. In addition, automatic machine translation for extracting rules in different local language also recommended for further study.
Acknowledgment
We would like thank to all Gondar agricultural research center cereal crop research teams for their expert knowledge and guidance in developing the domain expert knowledge base, farmers and agricultural extensions for willing to evaluate the designed collaborative approach and developed prototype. We thank to the central statics agency and Ethiopian national meteorology agency staffs for providing the necessary data and their support regarding to the nature of the data to select relevant features used for conducting this research.
Refernces
-
[1] D. G. Rossiter, “ALES: A framework for land evaluation using a microcomputer,” Soil use Manag. , vol. 6, no. 1, pp. 7–20, 1990.
-
[2] D. Beed, “Software Engineering Decision Support System for Agriculture Domain,” vol. 431602, pp. 1–5.
-
[3] T. Ponnusamy, “KNOWLEDGE-BASED EXPERT SYSTEM FOR AGRICULTURAL LAND USE PLANNING,” no. February, 2007.
-
[4] T. EJIGU, “Developing knowledge based system for cereal crop diagnosis and treatment: the case of kulumsa agriculture research center,” 2012.
-
[5] G. Prasad and A. V. Babu, “A Study on Expert Systems in Agriculture,” Ext. Technol. From Labs to Farms , p. 297, 2008.
-
[6] J. M. Heines, “Basic concepts in knowledge-based systems,” Mach. Learn. , vol. 1, no. 1, pp. 65–95, 1983.
-
[7] R. Joshi, H. Fadewar, and P. Bhalchandra, “Fuzzy Based Intelligent System to Predict Most Suitable Crop,” 2017.
-
[8] A. Mohammed, “Towards Integrating Data Mining with Knowledge Based System: The Case of Network Intrusion detection,” M. Sc. Thesis, Addis Ababa University , 2013.
-
[9] B. R. Gaines and M. L. G. Shaw, “Integrated knowledge acquisition architectures,” J. Intell. Inf. Syst., vol. 1, no. 1, pp. 9–34, 1992.
-
[10] G. I. Webb and J. Wells, “Recent progress in machineexpert collaboration for knowledge acquisition,” in AI-CONFERENCE-, 1995, pp. 291–298.
-
[11] A. Huang, L. Zhang, Z. Zhu, and Y. Shi, “Data mining integrated with domain knowledge,” Cutting-Edge Res. Top. Mult. Criteria Decis. Mak., pp. 184–187, 2009.
-
[12] G. I. Webb, J. Wells, and Z. Zheng, “An experimental evaluation of integrating machine learning with knowledge acquisition,” Mach. Learn., vol. 35, no. 1, pp. 5–23, 1999.
-
[13] K. Peffers, T. Tuunanen, M. A. Rothenberger, and S. Chatterjee, “A design science research methodology for information systems research,” J. Manag. Inf. Syst. , vol. 24, no. 3, pp. 45–77, 2007.
-
[14] G. Schreiber, B. Wielinga, R. de Hoog, H. Akkermans, and W. de Velde, “CommonKADS: A comprehensive methodology for KBS development,” IEEE Expert , vol. 9, no. 6, pp. 28–37, 1994.
-
[15] M. YALEW, “the impact of education on farm and off-farm income in rural households of ethiopia.”
Authors’ Profiles

Mulualem B. Anley (MSc) lecturer at university of Gondar and also serving the University as educational quality assurance and audit head of informatics faculty. Mr. Mulualem received his MSc. in Information Technology from University of Gondar, Gondar, Ethiopia in 2018 and he received his BSC in
information Technology from Adama Science and Technology University Adama, Ethiopia in 2013, His main research fields are data mining (Integration of heterogeneous data bases on public services, business Intelligences), neural network, machine learning, data mining and knowledge based system, big data management and security cloud computing and artificial intelligence.

Tibebe B. Tesema (PhD) is an Asst. Professor in Information Systems at Addis Ababa University, Ethiopia. Currently he is Head of School of IS at Addis Ababa University. He is also Coordinating the IS track of IT Doctoral Program. His main research fields are: Data/Web/Sentiment Mining, Information
Architecture, Knowledge representation, Appropriating Information Systems in organizations. He is an author/co-author of more than 25 scientific articles and conducted a number of research projects in Information systems.
References A collaborative approach to build a KBS for crop selection: combining experts knowledge and machine learning knowledge discovery
- D. G. Rossiter, “ALES: A framework for land evaluation using a microcomputer,” Soil use Manag., vol. 6, no. 1, pp. 7–20, 1990.
- D. Beed, “Software Engineering Decision Support System for Agriculture Domain,” vol. 431602, pp. 1–5.
- T. Ponnusamy, “KNOWLEDGE-BASED EXPERT SYSTEM FOR AGRICULTURAL LAND USE PLANNING,” no. February, 2007.
- T. EJIGU, “Developing knowledge based system for cereal crop diagnosis and treatment: the case of kulumsa agriculture research center,” 2012.
- G. Prasad and A. V. Babu, “A Study on Expert Systems in Agriculture,” Ext. Technol. From Labs to Farms, p. 297, 2008.
- J. M. Heines, “Basic concepts in knowledge-based systems,” Mach. Learn., vol. 1, no. 1, pp. 65–95, 1983.
- R. Joshi, H. Fadewar, and P. Bhalchandra, “Fuzzy Based Intelligent System to Predict Most Suitable Crop,” 2017.
- A. Mohammed, “Towards Integrating Data Mining with Knowledge Based System: The Case of Network Intrusion detection,” M. Sc. Thesis, Addis Ababa University, 2013.
- B. R. Gaines and M. L. G. Shaw, “Integrated knowledge acquisition architectures,” J. Intell. Inf. Syst., vol. 1, no. 1, pp. 9–34, 1992.
- G. I. Webb and J. Wells, “Recent progress in machine-expert collaboration for knowledge acquisition,” in AI-CONFERENCE-, 1995, pp. 291–298.
- A. Huang, L. Zhang, Z. Zhu, and Y. Shi, “Data mining integrated with domain knowledge,” Cutting-Edge Res. Top. Mult. Criteria Decis. Mak., pp. 184–187, 2009.
- G. I. Webb, J. Wells, and Z. Zheng, “An experimental evaluation of integrating machine learning with knowledge acquisition,” Mach. Learn., vol. 35, no. 1, pp. 5–23, 1999.
- K. Peffers, T. Tuunanen, M. A. Rothenberger, and S. Chatterjee, “A design science research methodology for information systems research,” J. Manag. Inf. Syst., vol. 24, no. 3, pp. 45–77, 2007.
- G. Schreiber, B. Wielinga, R. de Hoog, H. Akkermans, and W. de Velde, “CommonKADS: A comprehensive methodology for KBS development,” IEEE Expert, vol. 9, no. 6, pp. 28–37, 1994.
- M. YALEW, “the impact of education on farm and off-farm income in rural households of ethiopia.”
