A New Enhanced Semi Supervised Image Segmentation Using Marker as Prior Information

Author: L.Sankari, C.Chandrasekar
Journal: International Journal of Image, Graphics and Signal Processing(IJIGSP) @ijigsp
Article in issue: 1 vol.4, 2012.
Free access
In Recent days Semi supervised image segmentation techniques play a noteworthy role in image processing. Semi supervised image segmentation needs both labeled data and unlabeled data. It means that a Small amount of human assistance or Prior information is given during clustering process. This paper discusses an enhanced semi supervised image segmentation method from labeled image. It uses both a background selection marker and fore ground object selection marker separately. The EM (Expectation Maximization) algorithm is used for clustering along with must link constraints. The proposed method is applied for natural images using MATLAB 7. Thus the proposed method extracts Object of Interest (OOI) from OONI (Object of Not Interest) efficiently and the experimental results are compared with Standard K Means and EM Algorithm also. The results show that the proposed system gives better results than the other two methods. It may also be suitable for object extraction from natural images and medical image analysis.
Semi supervised image segmentation, prior knowledge, constrained clustering
Short address: https://sciup.org/15012212
IDR: 15012212
Text of the scientific article A New Enhanced Semi Supervised Image Segmentation Using Marker as Prior Information
Image segmentation is the method of dividing an image into different regions such that each region is homogeneous. By partitioning an image into a set of disjoint segments, image segmentation leads to more compact image representation. As the central step in computer vision and image understanding, image segmentation has been extensively investigated in the past decades, with a large number of image segmentation algorithms. There are number of segmentation techniques exist in the literature. But no single method can be considered best for all kind of images. Most of the techniques are being pretty ad hoc in nature.
A) Need of semi supervised image segmentation:
Semi supervised method is the combination of both supervised (classification) and unsupervised (clustering) and classification concept. Before performing clustering some prior knowledge is given. If the algorithm is purely an unsupervised (clustering) algorithm it will not show good result for all kind of images since an iterative clustering algorithms commonly do not lead to optimal cluster solutions. Partitions that are generated by these algorithms are known to be sensitive to the initial partitions that are fed as an input parameter. A “good” selection of initial seed is an important clustering problem. Likewise the classification algorithm will not give best solution since the result depends on type of classifier. So this paper discuss about combination of these two methods called ‘semi supervised model’ for image segmentation.
The following section discuss about semi supervised model[13][14].
b.)Semi supervised clustering:
During clustering process a small amount of prior knowledge is given either as labels or constraints or any other prior information. The following figure explains about the semi supervised clustering model[15][16][17].
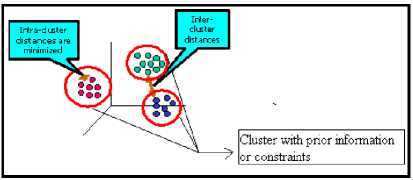
Figure 1. Semi supervised clustering model
In the above figure, the three clusters are formed using certain constraints or prior information. Besides the similarity information which is used as color knowledge, the other kind of knowledge is also available by either pair wise (must-link or cannot-link) constraints between data items or class labels for some items. Instead of simply using this knowledge for the external validation of the results of clustering, one can imagine letting it “guide” or “adjust” the clustering process, i.e. provide a limited form of supervision. There are two ways to provide information for semi supervised clustering.
-
1. Search based.
-
2. Similarity based.
-
1.Search based :
2.Similarity based:
The clustering algorithm itself is modified so that user-provided constraints or labels can be used to bias the search for an appropriate clustering. This can be done in several ways, such as by performing a transitive closure of the constraints and using them to initialize clusters [4], by including the cost function a penalty for lack of compliance with the specified constraints [10][11], or by requiring constraints to be satisfied during cluster assignment in the clustering process [12].
There are several similarity measures existing in the domain. Any one similarity measure is adapted[7][8][9] so that the given constraints can be easily satisfied.
In this paper semi supervised image segmentation with minimum user label is discussed. Instead of selecting some sample pixels with mouse clicks [1], a group of pixels are selected as a region using mouse. A pixel which has the same color and intensity as in the selected marker region (by mouse selection) will come under one cluster and others pixels will not be. This concept is given in detail in the following sections.
-
I. Previous Related Works
Recently there are many papers focusing the importance of semi supervised image segmentation. Among them a few papers are analyzed. According to paper [3], the semi-supervised C-Means algorithm is introduced in this paper to solve three problems in the domains like choosing and validating the correct number of clusters, Insuring that algorithmic labels correspond to meaningful physical labels tendency to recommend solutions that equalize cluster populations. The algorithm used MRI brain image for segmentation.
In this [4] paper, how the popular k-means Clustering algorithm can be modified to make use of the available information with some artificial constraints. This method was implemented for six datasets and it has showed good improvement in clustering accuracy. This method was also applied to the real world problem of automatically detecting road lanes from GPS data and observed dramatic increases in performance.
In paper [5] a novel semi-supervised Fuzzy C-means algorithm is proposed. A set called as seed set which contains a small amount of labeled data is used. First, an initial partition in the seed set is done, then use the center of each partition as the cluster center and optimize the objective function of FCM using EM algorithm. Experiments results show that the defect of fuzzy c-means is avoided that is sensitive to the initial centers partly and give much better partition accuracy.
In Paper [6], Semi-supervised clustering uses a small amount of labeled data to aid and bias the clustering of unlabeled data. Here labeled data is used to generate initial seed clusters along with the constraints generated from labeled data to guide the clustering process. It introduces two semi-supervised variants of KMeans clustering that can be viewed as instances of the EM algorithm, where labeled data provides prior information about the conditional distributions of hidden category labels. Experimental results demonstrate the advantages of these methods over standard random seeding and COP-KMeans, a previously developed semi-supervised clustering algorithm.
This paper [12] focuses on semi-supervised clustering, where the goal is to cluster a set of data-points given a set of similar/dissimilar examples. Along with instance-level equivalence (similar pairs belong to the same cluster) and in-equivalence constraints (dissimilar pairs belong to different clusters) feature space level constraints (how similar are two regions in feature space) are also used for getting final clustering. This task is accomplished by learning distance metrics (i.e., how similar are two regions in the feature space?) over the feature space which that are guided by the instance-level. A bag of words models, which are nothing but code words (or visual-words) are used as building blocks. Our proposed technique learns non-parametric distance metrics over codewords from these equivalence (and optionally, inequivalence) constraints, which are then able to propagate back to compute a dissimilarity measure between any two points in the feature space. Thus this work is more advanced than previous works. First, unlike past efforts on global distance metric learning which try to transform the entire feature space so that similar pairs are close. This transformation is non-parametric and thus allows arbitrary non-linear deformations of the feature space. Second, while most Mahalanobis metrics are learnt using Semi-Definite Programming (SDP), this paper discuss about a Linear Program (LP) and in practice, is extremely fast. Finally, Corel image datasets (MSRC, Corel) where ground-truth segmentation is available. Over all, this idea gives improved clustering accuracy.
-
II. METHODOLOGY
In this paper, ground truth image is taken with proper class labels. The Octree color quantization algorithm is applied to get the reduced colors. This color table is integrated with must link constraints for the given image using EM algorithm.
A group of pixels as a region must be selected separately for object of interest (OOI) and object of not interest (OONI) for back ground and foreground from an input image. Here OOI and OONI refer foreground and back ground objects respectively. Find the smallest distance for each and every pixel in the marker to its neighboring pixels using Mahalanobi’s formula.
tiLti; ; = к; - Г J * CW1 kt - Г;)
---- (1)
Where
x row vector which contains the pixels inside a marker and the other area.
COV represents sample covariance matrix.
belongs to same region, group them into one region otherwise need not group.
Repeats steps 4 and 5 for each point in object of interest(OOI) and object of not interest(OONI)
Let X be a selection with N points
For each point in X n
-
a. Let Y = x i (x e X)
-
b. Consider its neighboring coordinates within a rectangle, R of size 3 x 3.
-
c. Calculate distance vector using
Mahalanobis distance d(R i , Y)
-
d. Find minimum distance d(R i , Y).
-
e. If d < threshold then find Color index of Y and R i
i. If belong to same label, group into same region
ii. If belong to different labels but have same color then delete Ri
2. Repeats step s 4 and 5 for each point in В and О3. Let X b e a s el ecti on with N p о i nts4. Fo r each p ci nt in XL a. Let Y = x-(x e X)
Labeled I nput Image
Uctr ее c ol our Quantizati cm
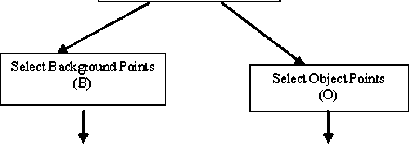
Pi op os ed S egm ent a ti on Pi' ocediu e
1. Cluster quantized colour table using EM Algorithm integrated with must-link constraints
b. Consider its neighbouring coordinates within a rectangle, R of size 3 x
3. " " "
c. Calculate distance vector using Mahalanobis distance d(Ri, Y)
d. Find minimum distance d(Rj, Y).
e. If d < threshold then find Color index of Y and R^
i. If belong to same label, group into same region ii. If belong to different labels but. have same colour then delete Ri "
Fig 1. Work Flow Diagram of the proposed work The algorithm based on proposed idea is given below:
-
1. Labeled image is taken as input image.
-
2. Octree color quantization to reduce the colors and store with class label.
-
3. Mark object of interest (OOI) and object of not interest (OONI) using mouse.
-
4. Cluster quantized color table using EM Algorithm interated with must-link constraints. Must link constraints means that if any point
-
III. RESULTS AND DISCUSSIONS
Figure 2:
Here three different labeled images are taken as input . These three images are partially separated images.
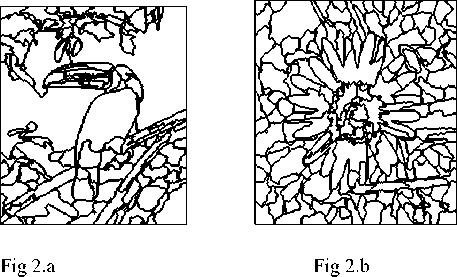

Fig 2.c
Figure 3:
Marking of OOI (Object of interest) and OONI (Object of not interest) for all the above three figures using blue and green color.
Object of intereste (Green Color mark)
Object of Not interest (Blue color mark )
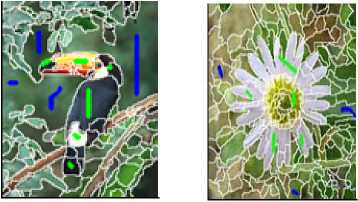
Fig 3.a Fig 3.
Figure 6:
Results using proposed idea for the above figure 5 using different marker selection.

Fig 6.a
Fig 6.b
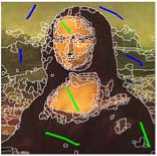
Fig 3.c
(From these two pictues the object is segmented properly)
Figure 4:
Resullt of proposed method for the above three figures.


Fig 4.b

Fig.6.c
The object of interest is not segmented properly
Fig 4.a

Figure 7:
Results of input images using K Means method.
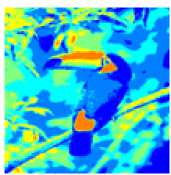

Fig 7.b
Fig 4.c

Fig 7.a

Fig 7.c
Figure 8:
Result of input images using Standard EM method.

Fig 5.c

Fig 8.a

Fig.8.b

Fig 8.c
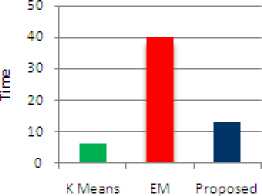
The time taken for getting the result of the input image1 (Bird) using proposed method is noted down in the table.
Table 1. Performance Table for image1
|
S No |
Methods |
Time in sec. |
|
1 |
K Means |
6.3214 |
|
2 |
EM |
40.22405 |
|
3 |
Proposed |
13.05598 |
It shows that the proposed method has taken more time than K means and less time than EM method. The performance is shown in the chart given below.
Performance chart
■ К Means
■ EM
■ Proposed
Types of segmentation algorithms
Figure 9. Performance chart
-
IV. CONCLUSION
The above result shows that the proposed semi supervised segmentation extracts the object of interest precisely. But the result of segmentation depends on the marker selection on left and right side of the image. If the marker selection is not given properly, the result of segmentation will not be good. This may be eliminated in future by adding certain other constraints for texture, color etc.
References A New Enhanced Semi Supervised Image Segmentation Using Marker as Prior Information
- Yuntao Qian, Wenwu Si, IEEE, ” Semi-supervised Color Image Segmentation Method”-2005
- Yanhua Chen, Manjeet Rege, Ming Dong, JingHua Farshad Fotouhi Department of Computer Science Wayne State UniversityDetroit, MI48202 “Incorporating User Provided Constraints into Document Clustering”,2009
- Amine M. Bensaid, Lawrence O. Hall Department of Computer Science and Engineering Universit of South Florida Tampa, Partially Supervised Clustering for Image Segmentation -1994
- Kiri Wagstaff, Claire Cardie ,Seth Rogers &Stefan Schroedl ,”Constrained K-means Clustering with Background Knowledge-2001”
- Kunlun Li; Zheng Cao; Liping Cao; Rui Zhao; Coll. Of Electron. & Inf. Eng., Hebei Univ., Baoding, China ,“A novel semi-supervised fuzzy c-means clustering method”2009,IEEE Explorer
- Sugato Basu , Arindam Banerjee , R. Mooney , In proceedings of 19th international conference on Machine Learning(ICML-2002),Semi-supervised Clustering by Seeding (2002)
- David Cohn, Rich Caruana, and Andrew McCallum. Semi-supervised clustering with user feedback, 2000.
- Dan Klein, Sepandar D. Kamvar, and Christopher D. Manning. From instance-level constraints to space-level constraints: Making the most of prior knowledge in data clustering. In Proceedings of the 19th International Conference on Machine Learning, pages 307–314. Morgan Kaufmann Publishers Inc., 2002.
- Eric P. Xing, Andrew Y. Ng, Michael I. Jordan, and Stuart Russell. Distance metric learning with application to clustering with sideinformation. In S. Thrun S. Becker and K. Obermayer, editors, Advances in Neural Information Processing Systems 15, pages 505–512, Cambridge, MA, 2003. MIT Press.
- A. Demiriz, K. Bennett, and M. Embrechts. Semi-supervised clustering using genetic algorithms. In C. H. Dagli et al., editor, Intelligent Engineering Systems Through Artificial Neural Networks 9, pages 809–814. ASME Press, 1999.
- K.Wagstaff and C. Cardie. Clustering with instance-level constraints. In Proceedings of the 17th International Conference on Machine Learning, pages 1103–1110, 2000.
- Dhruv Batra, Rahul Sukthankar and Tsuhan Chen,“Semi-Supervised Clustering via Learnt Codeword Distances”,2008.
- Richard Nock, Frank Nielsen,Semi supervised statistical region refinement for color image segmentation,2005
- Jan Kohout,Czech Technical University in Prague Faculty of Electrical Engineering,Supervisor: Ing . Jan Urban,Semi supervised image segmentation of biological samples-PPT,July 29, 2010
- Ant´onio R. C. Paiva1 and Tolga Tasdizen,Fast Semi Supervised image segmentation by novelty selection,2009
- Kwangcheol Shin and Ajith Abraham, Two Phase Semi-supervised ClusteringUsing Background Knowledge,2006.
- M´ario A. T. Figueiredo, Dong Seon Cheng, Vittorio Murino, Clustering Under Prior Knowledge with Application to Image Segmentation,2005.
