A New Research Resource for Optical Recognition of Embossed and Hand-Punched Hindi Devanagari Braille Characters: Bharati Braille Bank

Author: Shreekanth.T, V.Udayashankara
Journal: International Journal of Image, Graphics and Signal Processing(IJIGSP) @ijigsp
Article in issue: 6 vol.7, 2015.
Free access
To develop a Braille recognition system, it is required to have the stored images of Braille sheets. This paper describes a method and also the challenges of building the corpora for Hindi Devanagari Braille. A few Braille databases and commercial software's are obtainable for English and Arabic Braille languages, but none for Indian Braille which is popularly known as Bharathi Braille. However, the size and scope of the English and Arabic Braille language databases are limited. Researchers frequently develop and self-evaluate their algorithm based on the same private data set and report its behavior using ad-hoc measures of performance. There is no well-defined benchmark database for comparative performance evaluation of results obtained. The developed Braille database, Bharati Braille-Bank, is a large and well characterized information of Braille documents and its related data for use by the research community working in Optical Braille Recognition (OBR) for Bharati Braille. In the present form it includes databases of embossed double sided, embossed single sided, skewed, Hand punched and images with varying resolutions of Hindi Braille. The objective of this work is to stimulate current research and new investigations in the study of Hindi OBR. Without common databases such as those provided by Braille Bank it is impossible to resolve certain contradictory research results. To overcome this problem, Braille Bank provides facilities for the comparative analysis of the data and the evaluation of proposed algorithms with the standard database. In addition, it provides free access to the developed database in the form of Compact Disc-Read Only Memory (CD-ROM). This work is a step forward in the direction of development of standards for Hindi Devanagari Braille data collection for Indian languages. The mission of the resource is to accelerate the development of OBR for Bharati Braille.
Bharati Braille, Grade-I, Hand punched, Hindi Devanagari, Inter-point, OBR
Short address: https://sciup.org/15013878
IDR: 15013878
Text of the scientific article A New Research Resource for Optical Recognition of Embossed and Hand-Punched Hindi Devanagari Braille Characters: Bharati Braille Bank
Published Online May 2015 in MECS DOI: 10.5815/ijigsp.2015.06.03
-
I. Introduction
Braille is a language for the blind to read and write through the sense of touch. Braille is formatted to a standard size by Frenchman Louis Braille in 1825.Braille is a system of raised dots arranged in cells. Any combination of one to six dots may be raised within each cell and the number and position of the raised dots within a cell convey to the reader the letter, word, number, or symbol the cell exemplifies. There are 64 possible combinations of raised dots within a single cell. The locus of the dot patterns for Braille are named universally by numbering the dots by 1 through 3 from top to bottom on the left and 4 through 6 from top to bottom on the right as shown in Fig. 1[1].
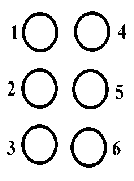
Fig. 1. Braille cell
-
A. Braille Dimension and Types of Braille
The library of congress have formulated the dot dimension, cell dimension, the distance between the dots within the cells, the distance between the cells in a word according to the tactile resolution of the fingertips of an individual. Dot height is approximately 0.02 inch (0.5 mm), the horizontal and vertical spacing between dot centers within a cell is approximately 0.1 inch (2.5 mm), the blank space between dots on adjacent cells is approximately 0.15 inch (3.75 mm) horizontally and 0.2 inch (5.0 mm) vertically as shown in Fig. 2(a). A standard Braille page is 11 by 11 inches and typically has a maximum of 40 to 42 Braille cells per line and 25 lines per page [14].
There are two types of Braille documents based on embossing. The embossing of Braille dots can be on single side or on both the sides of the Braille sheet. The contents in the single sided Braille document are less, since the information present is only on one side. Thereby the volume of the Braille document will escalate. In order to reduce the volume of the Braille document, the embossing is done on both sides of the sheet. To avoid the merging of protrusions and depressions a slight diagonal offset is maintained while embossing the dots on both sides of the Braille documents depicted in Fig. 2(b) [7]. The translation of the double sided Braille document to text is a complex task, because the recognition techniques employed are based on the visual perception but not on the tactile sensing used by the visually impaired.
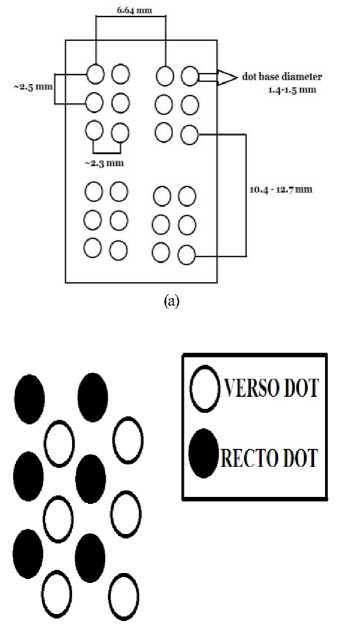
(b)
Fig. 2. (a) Braille cell dimension (b) Inter-point Braille
-
B. Grades of Braille
The Braille codes for Hindi and other languages use compressed codes to represent a word or a sentence instead of spelling all the letters occurring in a word. The meaning of each Braille character depends on the type of Braille encoding used. Due to the varying needs of Braille readers, there are three different grades of Braille.
In grade I Braille, each Braille cell corresponds to each character in the equivalent text. There is a one-to-one correspondence in the Braille representation and the printed text. Grade I Braille is bulkier and larger than the normal text. In grade II Braille, a cell can represent a group of characters and it is a standardized form of contracted Braille. It is most common form of tactile writing. Grade III Braille is a complicated form of Braille and it is not standardized because each writer uses their own dialect of codes as a form of personal shorthand, which other Braille readers may not be able to read [25].
-
C. OBR and Need for OBR
OBR system is a computer software that automates the process of acquiring and processing the images of Braille documents. It is essential to transliterate the Braille documents to the text document in the corresponding language in order to establish a feasible bi-directional communication amid the visually impaired and the sighted community. There are a substantial number of longstanding Braille documents that need to be reproduced so that they can be preserved and accessed by more people; hence this concept of OBR has proved to be beneficial in attaining this requisite. Every person who wishes to work with blind people does not need to know how to read Braille, and these people can successfully communicate with the blind by using the OBR. The key reason for developing a system that can read Braille is to preserve and multiply large volumes of manually crafted books. It is undeniably difficult for even a skilled copyist to retype and reproduce the documents or the books on mathematics and music into Braille due to the specific rules that apply in Braille. In view of all these there is a need for OBR system for all the native languages.
-
D. Overview of Hindi Language
Hindi is the official language of India, it is spoken as first language by 33 percent of the Indian population, and by many more as a lingua franca. Also it is interesting to note that Hindi is the fourth-most-widely spoken language in the world.
Hindi is mainly written in Devanagari script. In the Hindi language there are 33 consonants and 13 vowels. The Hindi language has one to one correspondence with the spoken language and the written form. The phonemes are divided into two types, vowels (swara) and consonants (vyanjan).
Vowels (Swara): Vowels are the independently existing letters which are called swara.
अ आ इ ई उ ऊ ॠ ए ऐ ओ औ
Consonants (Vyanjan): Consonants are those which depend on vowels to form their independent letter.
ч у ч ч т, ч ^ ч ^ ч, г 5 з ч щ, ч У ч у ч, ч ч ч ч ч, य र ल व श ष स ह
Therefore, we can say that the Hindi language is phonemic in nature. Amalgamation of vowels with consonants will from a syllable and it is also called as "Baraha Khadi" [27].
-
E. Bharati Braille
Bharati Braille is a largely unified Braille script for writing the languages of India which was developed in April 1951 and is the collective name given to all the languages of India [26].
The Bharati Braille, the Braille scheme adopted by India and some of the Asian Countries, use phonetic equivalents from the English Braille to represent the Hindi texts. Bharati Braille follows the syllabic writing system for all the Indian languages. The Braille notations for the Hindi Braille are shown in Fig. 3. Braille notations for special symbols of Bharati Braille are shown in Fig. 4 [26].
|
Alphabet: Hindi |
|||||
|
M |
a (1) " |
я |
gh (126) •; |
я |
b (12) - |
|
ЗТГ |
a (345) J |
h (346) .. |
IT |
bh (45) ;f |
|
|
? |
I (24} •: |
я |
С (14) |
Я |
m (134) “ |
|
% |
I (35} it |
ch (16) |
a |
у (13456) i: |
|
|
3 |
u (136) .. |
j (245) •? |
T |
r (1235) :• |
|
|
7 |
a (1256) :: |
ST |
jh (356) .: |
Я |
I (123) ; |
|
ft |
e (26} •. |
я |
n (25) ff |
I (456) E |
|
|
ё (15) Л |
г |
1 (23456) :: |
у |
v (1236) :i |
|
|
ft |
al (34} i: |
3 |
th (2456) •: |
IT |
5 (146) " |
|
3ft |
о (1346) ;; |
У |
d (1246) " |
y |
s (12346) t; |
|
3ft |
6 (135) if |
dh (123456) :: |
я |
s (234) :* |
|
|
3ft |
au (246) •; |
тт |
n (3456) ,E |
F |
h (125) v |
|
^ |
f (5,1235) > :• |
я |
t (2345) :■ |
8T |
ks (12345) :r |
|
ж |
Г (6.1235) :i:r |
я |
th (1456) 4 |
Я |
Jfl (156) *i |
|
I (5. 123) * E |
d (145) f |
у |
r/r (12456) 4 |
||
|
^ |
r (6.123) . E |
u |
dh (2346) !; |
S |
rh (5, 12456) :• 4 |
|
V |
к (13) Г |
я |
n (1345) :• |
ЯГ |
f (124) |
|
ST |
kh (46} :; |
я |
p (1234) " |
5" |
z (1356) I: |
|
л |
g (1245) ” |
яг |
ph (235) :• |
||
|
Diacritics |
|||||
|
о |
Virama (4) :: |
О: |
Visarga (6) :• |
s |
Avagraha (2) f: |
|
о |
Anusvara (56) : |
-Y |
Candrabindu (3) i: |
||
Numbers
|
T 1 (3456. 1) .: * |
Я 6 (3456.124) .:" |
|
4 2 (3456. 12) .t! |
Is 7 (3456,1245) .E “ |
|
3 3 (3456, 14) .: ” |
4 8 (3456,125) .E *• |
|
V 4 (3456. 145) .: “ |
4 9 (3456,24) .: •' |
|
4 5 (3456. 15) .: *• |
о 0 (3456,245) .: *: |
Fig. 3. Hindi Braille Notations
Punctuation: Indian Languages
|
, comma |
(2) |
|
|
: semicolon |
(23) |
|
|
: colon |
{25) |
•r |
|
I danda, . period, full stop |
<256) |
|
|
II double danda |
(256, 256) |
■: ■: |
|
? question mark |
(236) |
|
|
I exclamation |
<235) |
|
|
' apostrophe |
(2) |
?: |
|
quote |
(236...356) |
... |
|
[...] brackets |
(2356..2356) |
::...:: |
|
- hyphen |
(36) |
|
|
— dash |
(36, 36) |
.♦ •; |
|
* asterisk |
(35, 35) |
|
|
capital * |
(6) |
: - |
|
number sign |
(3456) |
.: |
|
/taf/cs |
(46) |
|
|
* Capital used only when transcribing English |
||
Fig. 4. Special symbols of Bharati Braille
F. Review on Related Works and Need For Bharati Braille Bank
The Braille code system has been widely used by the visually impaired since it is comfortable for them to use it for reading and writing. Different countries have adopted their own Braille notations to suit their native languages. To develop Braille recognition system, it is required to have the stored images of Braille sheets. Previously, such a database was developed for English and Arabic Braille. A Braille database for both single sided and double sided Braille documents has been established for developing an OBR for English language by Nestor Falcon et.al. [20]. Zainab et.al. , have developed the database of single sided Braille document of Green and Yellow color [21]. However, the size and scope of these two databases are limited.
Many research developments are lagging behind due to want of sufficient, high-quality and accurately standardized resources for various applications. Developing the optical Braille recognition system needs high-quality Braille images; this indeed requires a Braille corpus. Various authors have attempted to develop the Braille corpora but they limited their work to generate the images of Braille sheets of a few pages and access to the developed database is not provided. Hence, developing a robust system for Braille recognition is hindered by lack of various resources. Also, the processes of the evaluation of new algorithms and comparison of the research results are complicated due to lack of standardized test data and testing methods. The set of problems and challenges is reminiscent of the research in OBR. This motivated us to develop the rich Braille corpora and provide free access to the researchers working in the area of Hindi OBR.
The primary reason for selecting the Hindi Devanagari Braille is, as English Braille has been globalized, the OBR software for the same has been commercialized, but in case of other languages it is less focused. Various authors have developed the OBR systems for English and Arabic [1] - [19]. Very less effort has been put in for the development of OBR for Hindi Braille. Hindi being the national language of India, the commercial software is unavailable for Hindi Braille. A significant effort is required to develop software for Hindi Devanagari Braille.
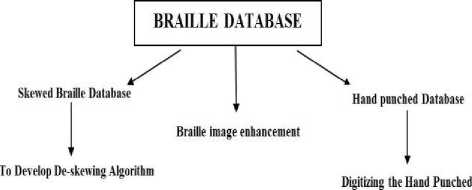
Optical Braille recognition is not a straight forward task for Indian languages as compared to English, as the basic character set of all the Indian languages is more than 64 and hence to represent a character, two Braille cells are required. OBR for Bharati Braille is still an area that requires the contribution of many enhanced research works. For all this, it is essential to develop the Braille corpora to enable the researchers to study the properties of different Braille documents and to develop models for OBR. So far, no efforts have been made for development of corpora for Hindi Devanagari Braille. Thus, we have provided Braille corpora built out of variety of documents that help in developing new algorithms for Hindi OBR, de-skewing algorithms and adaptive algorithms for Braille documents with varied resolutions. Large database is required to achieve a robust recognition.
Hence we have the standard Hindi Braille corpus with 155 pages of Hindi Devanagari Braille document, with approximately 2603 lines, 36570 cells and 102230 dots. These documents are manually validated and edited to ensure the correctness.
This paper describes the development of Braille corpora/ database for Hindi Devanagari language. The various application specific databases have also been introduced. Section II describes the outline of the Braille corpus design. Section III depicts the structure of the developed database. Section IV gives the statistical analysis of the developed database. Section V presents the few works being carried out at the various institutions, Universities and Research laboratories. Section IV presents the conclusion and discussion regarding the future work.
-
II. Braillecorpus Design
Braille-Bank is an archive of well characterized Bharati Braille documents pertaining to Hindi Devanagari language for use by the research community. The collection of the data is done in such a way that it includes all the possible components required for the development of robust OBR system for Hindi language.
-
A. Braille Corpus Collection
Traditional sources of Braille data are the machine printed (embossed), and the hand punched Braille documents. A long way has been crossed to come up with a Braille corpus to give a platform for researchers to develop the optical Braille recognition system and to check for accuracy and better performance. To start with an extensive survey of the related Braille documents of the selected language - Hindi (which is the area for which OBR is less focused) was done. The primary data collection was done in the form of 6 th standard Hindi Braille text Book of Government of Karnataka (GOK). Criterion for selecting this database was that it consists of Braille cells corresponding to simple characters to complex words, numerals and special symbols. Single sided and double sided embossed Braille documents were generated with the help of Government Braille printing press situated in Mysore, Karnataka. Braille documents that were taken from Braille press were made to undergo repeated verification. Hand punched documents were prepared with the help of three blind students for the same set of data as that of embossed documents and each document was verified with a trained Braille reader.
-
B. Braille Document Acquisition
Firstly, Braille documents were acquired through the commercially available scanner HP scan jet 3400C and Braille images were stored in JPEG format. This scanner was selected depending on the illumination requirement where it can provide clear dot location. Initially the acquisition of double sided Hindi Devanagari Braille in grade-I with the resolution of 1700x1502 was carried out for huge number of Braille document consisting of 95 pages. Later all the files were cropped to 1501x2121
using MATLAB programming to remove the unwanted region in the image. Like double sided Braille documents, all other documents were also cropped to the dimensions such that it excludes the unwanted regions. Each scanned Braille image consists of three types of pixels with different intensity values for background, a light area and a dark area for each recto and verso dot.
-
C. Braille Document Annotation and Equivalent Text Generation
The visual contents of the Braille documents i.e. the dots can be annotated in various possible ways to favour the researchers. The annotation of Braille document in our case was done using three experienced blind Braille readers. The information regarding the number of dots, number of lines, number of characters and number of words for each document is provided. To understand the contents in the Braille corpora and to ease the analysis of the work, it is required to provide the corresponding text of the Braille language. The Braille documents were read with the help of 3 blind students who are trained to read Hindi Braille language and equivalent text was generated using the " Baraha software".
-
III. Structure Of The Database
Initially the database has been validated in order to check the corpus before acquisition and to make sure that it would correspond to the specifications and include the versatility of the Braille text data. A huge database has been created in order to develop a robust OBR system for Hindi Braille with as many variants as we could. To gather the versatility of Hindi OBR six categories were identified, namely:
-
• Double sided embossed Braille document
-
• Single sided embossed Braille document
-
• Hand punched Double sided Braille document
-
• Hand punched single sided Braille document
-
• Skewed Braille documents
-
• Braille documents acquired with different resolution
All the above six categories of Hindi Braille database are confined to 6thstandard Hindi Braille text book of GOK. A double sided database has been developed for the entire text book whereas rest of the databases are developed on a selective basis of the Braille sheets. The database consists of healthy documents that sans inter-dot cracks that exist during the embossing process and unhealthy documents with inter-dot cracks due to the surface tension of the paper. The unhealthy documents require efficient image pre-processing techniques to eliminate the inter-dot noise components. The embossed single sided documents are free of inter-dot noise components. This is also true for the case of hand punched documents as they have been developed using the inter-dot Braille slate. We could not get much of the hand punched documents, because even if a single dot is punched wrongly, the entire documents are to be rejected and re-punched from scratch, which is a laborious and time consuming process. The skewed database as well as the database with varying resolution have been created in view of development of robust OBR systems. For documents to be free from tilt, it has to be aligned exactly with the edge of the scanner which is not always the case and this results in skewness in the document thus posing a major limitation to the system. The researcher has to take care of this skew angle correction while developing the robust OBR model. In this direction the skewed database has been created with tilt in both clockwise and in anti-clockwise direction. Documents with varied pixel resolution have been developed. Recognizing the dot components of these databases requires an efficient thresholding technique.
The developed database can be made use of by those researchers who are working on various areas as specified in Fig. 5. For double sided Braille the database consists of images of both sides of the Braille sheet. A sample database is as shown in Fig. 6, and its equivalent text is provided in Fig. 7, so that the researcher can verify the trueness of the system that he has d.eveloped. To clearly define the accuracy of the dot recognition this database provides the complete details of each Braille document. As an example, Table 1, depicts the detailed information of page number 9 and page number 10 of the double sided Braille document. All the documents are of size 28.5cm (horizontal) x21cm (vertical) and every document has been scanned with 200dpi and bit-depth of 24 bit.
The information on each and every document regarding the dot counts, cell counts, line counts, character counts, and information regarding the document type, size of the document, resolution of the acquired image database, pixel resolution and image format are summarized and depicted in Table 2 to Table 7, for each category of the developed databases.
Braille transliteration

Database
Fig. 5. The datasets provided is intended to enable a wide range of applications

(a)

(b)
Fig. 6. Acquired inter-point Braille image. (a) Front side and (b) Back side document
|
5 |
5 5 |
9 5 5 5 |
C 7 |
10 3 3 3 3 |
||
|
^г ^г |
таг |
5 5 |
ОТ 3 3 |
3 3 3 3 |
||
|
и ЩТ И (5 t5 $ t? t5 U \Я trifid ^T $КИ1 ^T ^t ^f ^r ^r ^r ^r 5[ 5Г ^ CiHECt (a) Text database of front side |
5 5Ж 5 5 5 5 5 5 5 5 й<^ФН Uf Uf U[ U[ U[ U| Uf H cT^W H H H H H H H ST sw ЗГ ar ar ar ar ar ar (b) Text database of Back side |
|||||
Fig. 7. Equivalent text database for Braille document
the algorithms with realistic data and to perform these tests repeatedly and reproducibly as and when the algorithm refinements are proposed. By making these data accessible to the researchers, these databases will make it possible to formulate and answer the problem without the need to develop a new set of reference data at greater costs in every single case. In this regard, Bharati Braille Bank can serve as a standard and permanent repository for studies related to Braille and, in particular, for Hindi Devanagari Braille.
Table 2. Embossed Double Sided Braille Database Developed
Number of Braille document
Total number of characters
Average number of characters per sheet
Total number of lines
Total number of dots
Average number of dots per sheet
Document size
Digital format
Resolution
Pixel resolution
Image format
Image Size
95pages 25827
(28.5cmx21cm) 24bit color image 200dpi 1501x2121
.jpg
328KB
Table 3. Embossed Single Sided Braille Database Developed
The tabulated information is provided in a similar fashion for all the documents for facilitating those users who are unaware of Hindi language and still working on developing the OBR system for their native languages. The users who are intended to work on developing the OBR system for Hindi Devanagari Braille can make use of the developed database to the full extent and for those users who are working on development of OBR systems for other languages can use this tabulated information to assess the performance of the system that they are intending to develop as the Braille has a standard pattern and dimensions, only the mapping differs from language to language. As the phrase says, " One picture is worth more than ten thousand words ", this database can be used worldwide for developing the OBR systems as there is a lot of room for fruitful research in the area of OBR.
Number of Braille document
Total number of characters
Average number of characters per sheet
Total number of lines
Average number of lines per sheet
Total number of dots
Average number of dots per sheet
Document size
Digital format
Resolution
Pixel resolution
Image format
Image Size
20pages
(28.5cmx21cm)
24bit color image
200dpi 1501x2121
.jpg
296KB
Table 4. Hand punched Double-Sided Braille Database Developed
Table 1. Inter-point Braille document information (a) Front side Braille sheet (b) Back side Braille sheet
|
Page No. |
Line Number |
No. of dots |
No. of cells |
Page No. |
Line Number |
No. of dots |
No. of cells |
|
9 |
1 |
6 |
2 |
10 |
1 |
8 |
3 |
|
2 |
18 |
6 |
2 |
35 |
7 |
||
|
3 |
12 |
5 |
3 |
12 |
3 |
||
|
4 |
14 |
7 |
4 |
28 |
7 |
||
|
5 |
8 |
4 |
5 |
19 |
5 |
||
|
6 |
14 |
7 |
6 |
28 |
7 |
||
|
7 |
16 |
5 |
7 |
21 |
6 |
||
|
8 |
28 |
7 |
8 |
42 |
7 |
||
|
9 |
17 |
5 |
9 |
28 |
7 |
||
|
10 |
21 |
7 |
10 |
16 |
5 |
||
|
11 |
8 |
2 |
11 |
28 |
7 |
||
|
12 |
14 |
7 |
12 |
12 |
3 |
||
|
13 |
25 |
6 |
13 |
28 |
7 |
||
|
Total |
13 |
201 |
70 |
Total |
13 |
305 |
74 |
Number of Braille document
Total number of characters
Average number of characters per sheet
Total number of lines
Average number of lines per sheet
Total number of dots
Average number of dots per sheet
Document size
Digital format
Resolution
Pixel resolution
Image format
Image Size
6pages
(28.5cmx21cm) 24bit color image 200dpi 1700x2341
.jpg 348KB
Table 5. Hand punched Single-Sided Braille Database Developed
References A New Research Resource for Optical Recognition of Embossed and Hand-Punched Hindi Devanagari Braille Characters: Bharati Braille Bank
- J. Mennens, L. Van Tichelen, G. Francosis and J. Engelen. "Optical recognition of Braille writing", Proceedings of second international conference on Document analysis and Recognition, IEEE Oct-1993, pp. 428-431.
- J. Mennens, L. Van Tichelen, G. Francosis and J. Engelen. "Optical Recognition of Braille Writing Using Standard Equipment", IEEE transactions of rehabilitation engineering, Vol. 2, No. 4, Dec 1994.
- T. W .Hentzschel, and P. Blenkhorn. "An Optical Reading Systems for Embossed Braille Characters using a Twin Shadows Approach", Journal of Microcomputer Applications, 1995, pp. 341-345.
- R .T. Ritchings, A. Antonacopoulos and D .Drakopoulos. "Analysis of Scanned Braille Documents", In: Dengel, A., Spitz, A.L. (eds.): Document Analysis Systems, World Scientific Publishing Company 1995, pp. 413–421.
- Y. Oyama, T. Tajima, and H. Koga. "Character Recognition of Mixed Convex- Concave Braille Points and Legibility of Deteriorated Braille Points", System and Computer in Japan, Vol. 28, No. 2, 1997.
- C.M. Ng, V.Ng and Y.Lau. "Regular feature extraction for recognition of Braille", Third International conference on computational Intelligence and Multimedia Applications, 1999, pp. 302—306.
- A. Antonacopoulos and D. Bridson. "A Robust Braille Recognition System", Document Analysis Systems VI, A. Dengel and S. Marinai (Eds.), Springer Lecture Notes in Computer Science, LNCS 3163, 2004, pp. 533-545.
- L. Wong, W. Abdulla and S. Hussmann. "A Software Algorithm Prototype for Optical Recognition of Embossed Braille", 17th Conference of the International Conference in Pattern Recognition, Cambridge, UK, IEEE-2004, pp. 23–26.
- N. Falcon, C. M. Travieso, J. B. Alonso and M. A. Ferrer. "Image Processing Techniques for Braille writing Recognitor", EUROCAST 2005, LNCS 3643.
- A. Malik Al-Salman, Y. ALOHAI, M. Alkanhal and A. Airajith. "An Arabic Optical Braille Recognition System", ICTA Apr 2007, pp.12-14.
- A. Malik S. Al-Salman, A. El-Zaart, Y. Al-Suhaibani, K. Al-Hokail and A. O. Al-Qabbany. "An Efficient Braille Cells Recognition", IEEE-2010.
- J. Yin, L. Wang and J. Li. "The Research on Paper-mediated Braille Automatic Recognition Method", Fifth International Conference on Frontier of Computer Science and Technology, IEEE-2010, pp. 619-624.
- J. Li and X. Yan. "Optical Braille Character Recognition with Support-Vector Machine Classifier", International Conference on Computer Application and System Modelling, 2010.
- S. D. Al-Shamma and S. Fathi. "Arabic Braille Recognition and Transcription into Text and Voice", 5th Cairo International Biomedical Engineering Conference Cairo, Egypt, Dec 2010.
- Z. Tai, S. Cheng, P. K. Verma and Y. Zhai. "Braille document recognition using Belief Propagation", Journal of Visual Communication and Image Representation 21(7): 722-730 (2010).
- A. Al-Saleh, A. El-Zaart and A. Malik Al-Salman. "Dot Detection of Braille Images Using A Mixture of Beta Distributions", 2011 Journal of Computer Science ISSN 1549-3636, pp. 1749-1759.
- J. Bhattacharya, S.Majumder and G.Sanyal. "Automatic Inspection of Braille character: A Vision based approach", International Journal of computer and Organization trends – volume1, Issue3, 2011, ISSN: 2249-2593, pp. 19-26 .
- M. Wajid, M. Waris Abdullah and O. Farooq. "Imprinted Braille-Character Pattern Recognition using Image Processing Techniques", International Conference on Image Information Processing, 2011.
- R. Ismail Zaghloul and T. Jameel Bani-Ata. "Braille Recognition System – With a Case Study Arabic Braille Documents", European Journal of Scientific Research, ISSN 1450-216X, Vol.62, No.1, 2011, pp. 116-122.
- N. Falcon, C. M. Travieso, J. B. Alonso and M. A Ferrer, "Image Processing Techniques for Braille writing Recognitor", EUROCAST 2005, LNCS 3643.
- Z. Authman and Z. F. Jebr, "Algorithm Prototype for Regular Feature Extraction of Arabic Braille Scripts" International Journal of Scientific Knowledge Computing and Information Technology ISSN 2305-1493, February 2013. Vol. 2, No.1, pp. 20-27 .
- S. Halder, A. Hasnat, A. Khatun, D. Bhattacharjee and M. Nasipuri, "Development of a Bangla Character Recognition (BCR) System for Generation of Bengali Text from Braille Notation", International Journal of Innovative Technology and Exploring Engineering , ISSN: 2278-3075, Volume-3, Issue-1, June 2013.
- S. Padmavathi, K.S.S Manojana, S. Sphoorthy Reddy and D. Meenakshy, "Conversion of Braille to Text in English, Hindi and Tamil Languages", International Journal of Computer science, Engineering and Applications, Vol.3, No.3, June 2013.
- S. Srinath and C. N. Ravi Kumar, "Recognition of Hand Punched Kannada Braille Characters Using Knowledge Based Multi Decision Concept: Basic Symbols", Proceedings of International Conference on Advances in Computing Advances in Intelligent Systems and Computing, Vol. 174, 2012, pp 847-857.
- "World Braille Usage". Third Edition. Perkins. International Council on English Braille. National Library Service for the Blind and Physically Handicapped.
- World Braille Usage. UNESCO. National Library Service for the Blind and Physically Handicapped. Library of Congress. Washington, D.C., USA. 1990.
- C. Arun Kumar, T. Shreekanth and V. Udayashankara, "Development of Speech Database for Hindi Text to Speech system Considering Syllable as a Basic Unit", International Journal of Advanced Research in Computer Science and Software Engineering, Vol. 4, 2014, pp. 531-549.
