A Novel Approach of Text Steganography using Nonlinear Character Positions (NCP)
")
Author: Sabyasachi Samanta, Saurabh Dutta, Goutam Sanyal
Journal: International Journal of Computer Network and Information Security(IJCNIS) @ijcnis
Article in issue: 1 vol.6, 2013.
Free access
Usually, the steganographic algorithms employ images, audio, video or text files as the medium to ensure hidden exchange of information between multiple contenders and to protect the data from the prying eyes. This paper presents a survey of text steganography method used for hiding secret information inside some cover text. Here the text steganography algorithms based on modification of font format, font style et cetera, has advantages of great capacity, good imperceptibility and wide application range. The nonlinear character positions of different pages are targeted through out the cover with insignificant modification. As compared to other methods, we believe that the approaches proposed convey superior randomness and thus support higher security.
Text steganography, Nonlinear character position (NCP), Security, Data hiding
Short address: https://sciup.org/15011267
IDR: 15011267
Text of the scientific article A Novel Approach of Text Steganography using Nonlinear Character Positions (NCP)
Published Online November 2013 in MECS DOI: 10.5815/ijcnis.2014.01.08
Steganography is the art and science of writing hidden messages in such a way that no one, apart from the sender and intended recipient, suspects the existence of the message. Steganography is derived from the Greek word steganos which literally means “Covered” and graphy means “Writing”, i.e. covered writing. Steganography refers to the science of “invisible” communication. Digital form of media as a cover-object being use in steganography are images, video clips, music or sounds.
Capacity, security, and robustness, are the three main aspects affecting steganography and its usefulness. Capacity refers to the amount of data bits that can be hidden in the cover medium. Security relates to the ability of an eavesdropper to figure the hidden information easily. Robustness is concerned about the resist possibility of modifying or destroying the hidden data [15] [16].
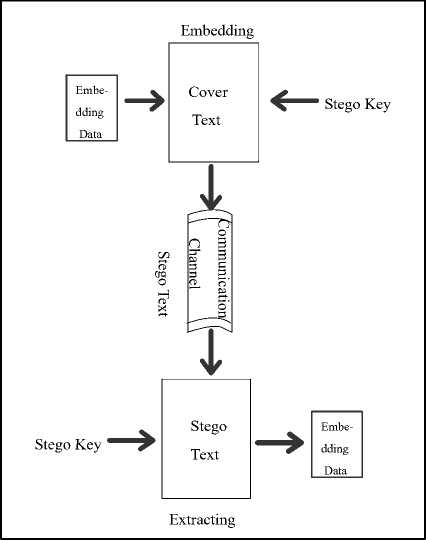
Figure 1.1: The Mechanism of Text Steganography
Steganography is different than cryptography and watermarking although they all have overlapping usages in the information hiding processes [17] [22]. Steganography security hides the knowledge that there is information in the cover medium, where cryptography revels this knowledge but encodes the data as cipher-text and disputes decoding it without permission; i.e., cryptography concentrate the challenge on the decoding process while steganography adds the search of detecting if there is hidden information or not [23][24][25].
Steganography can also be utilized for posting secret communications on the Web to avoid transmission or to hide data on the network in case of a violation. It can be useful for copyright protection, which is, in reality, digital watermarking [5]. Copyright protection is to protect the cover medium from claiming its credit be others, with no real emphasis on secrecy.
Text steganography also have been used since 2000 bc as a cover media. Text steganography is the most difficult kind of steganography, due largely to the relative lack of redundant information in a text file as compared to image or sound. Recently there have been several successful attempts to design text steganographic schemes for English, Japanese, Korean, Chinese, Thailand, Persian, and Arabic [10] [11].
Text steganography can be classified in three basic categories- format-based, random and statistical generation and linguistic method.
Text Steganography
Format based
Linguistic method
Figure 1.2: Basic categories of text steganography
-
A. Format-based
Format-based methods use and change the formatting of the cover-text to hide data. They do not change any word or sentence, so it does not harm the ’value’ of the cover-text. A format-based text steganography method is open space method. In this method extra white spaces are added into the text to hide information about the cover text [6] [18].
-
B. Random and statistical generation methods
Random and statistical generation methods are used to generate cover-text automatically according to the statistical properties of language. These methods use example grammars to produce cover-text in a certain natural language. The context-free grammar is a commonly used language model where each transformation rule of a context free grammar has a probability associated with it [6] [22].
-
C. Linguistic method
The linguistic method considers the linguistic properties of the text to modify it. The method uses linguistic structure of the message as a place to hide information. Syntactic method is a linguistic steganography method where some punctuation signs like comma (,) and full-stop (.) are placed in proper places in the document to embed a data. This method needs proper identification of places where the signs can be inserted. In this method the synonym of words for some pre-selected are used. The words are replaced by their synonyms to hide information in it [6] [20].
Here we have proposed a new method to hide information in any letters instead of pointed ones only. We have pointed letters all through the text in a number of pages nonlinearly. First, we have taken a large text document with number pages. Let all the lines contains almost same number of characters or letters in every line what we done to align the text both the left and right margins except the last line of any paragraph. This creates a clean look along the left to right side of the page. After that the message is taken. Initially, the string length is calculated. Here we have taken the string less than 256 characters and also the number of pages less than or equal to nine. The corresponding 8-bit data for length is positioned into array. The characters are converted into its 8-bits data using ASCII-8. Here we have taken 4-bit at a time to hide information changing style, font etc on selected characters of cover text of selected page. So, calculate the number of character positions we have strike. The cover text is taken as normal text with Times New Roman font and size of 10. Here we have taken four different styles to hide the data with in text. We have used the styles like Arial (as theme font), Italic, Bold and Underline. For four data bits may occur at 16 different orders starting from 0000 to 1111 i.e. 16 different combination of style of cover text can represent 64-bit encryption. The presence of style is as 1 and the absence of it as 0. As earlier it also is vary 0000 to 1111with 16 occurrences. In the table below, the 1 is (√) and 0 is as (x) represented [13] [14].
Here no predetermined character or word is taken in our algorithm. The character or letter position is calculated using the key. From the key, the exponential values are calculated. From the exponential value the character position, line number and page number are calculated. Then taking 4-bit data from the encrypted array the corresponding approach is chosen using the Table 1.1.
Table 1.1: Encryption Table
|
Data Bits |
Style |
|||
|
Underline (0/1) |
Bold (0/1) |
Italic (0/1) |
Arial (0/1) |
|
|
0000 |
x |
x |
x |
x |
|
0001 |
x |
x |
x |
√ |
|
0010 |
x |
x |
√ |
x |
|
0011 |
x |
x |
√ |
√ |
|
0100 |
x |
√ |
x |
x |
|
0101 |
x |
√ |
x |
√ |
|
0110 |
x |
√ |
√ |
x |
|
0111 |
x |
√ |
√ |
√ |
|
1000 |
√ |
x |
x |
x |
|
1001 |
√ |
x |
x |
√ |
|
1010 |
√ |
x |
√ |
x |
|
1011 |
√ |
x |
√ |
√ |
|
1100 |
√ |
√ |
x |
x |
|
1101 |
√ |
√ |
x |
√ |
|
1110 |
√ |
√ |
√ |
x |
|
1111 |
√ |
√ |
√ |
√ |
If any exponential value hits the space between two words of the text document then the next character position is calculated and corresponding style is implemented. Or if it hits any line contains less number of characters than the specified number of characters then the next line is taken to change. If that character is already changed then the next character is taken and earlier method is applied [6] [7] [8] [12].
Section 2 represents the related work. Section 3 represents the scheme followed in the encryption technique. Section 4 represents an implementation of the technique. Section 5 gives you an idea about the experimental results. Section 6 draws a conclusion.
-
II. RELATED WORKS
There are so many techniques for hiding information with in text. As example, five methods are represented in this section.
-
A) Particular Characters in Word
Hiding information can be performed by selecting specific characters or letters in certain words. This method can range from simple to very complicated depending on the specifications. Another more sophisticated example can be by selecting the first letter of the first word, second letter of the second word, third from the third, and so on, to hide the information in cover text [1].
-
B) HTML Documents
Secret information can be hidden within HTML Tags as they are case insensitive. For example, the tag
can be also used as
and
and the tag
as
, as
and as
, are all equally applicable. Extraction of information can be easily done by comparing these tag words with the tag words in normal case [3].
-
C) Line and Word Shifting Strategy
Shifting text lines vertically and shifting words horizontally may help to hide some information with in cover text. Varying of distance between lines and words may puzzle the viewers. Shifting the lines up or down slightly with a fixed space (say 0.003 inch) and modifies the distances between the words, intended to hide the information. However, using this method, there is great possibility for the hidden information to be destroyed. Also, at the time of using character recognition programs, such as OCR, the data become lost or cannot be traced accurately [2].
-
D) Approach based on curves in a character
In this approach, English letters are divided into two groups based on the shape i.e. whether a character has a curvature in its shape or not. Characters like ‘B’, ‘C’ have rounded shape where as the letters ‘A’, ‘E’ etc. does not have so. Letters with full or partial curvature hides 0 and without any sort of curvature hides 1 [9].
-
E) Shifting letter points and extensions
Both Arabic and English languages have points in their letters and the number of pointed letters differs too much. English language has points in only two letters, small "i" and small "j", while Arabic has in 15 letters out of its 28 alphabet letters. That letters are utilized for steganography and information security. By changing the point location within the pointed letters information hiding is achievable [4].
-
F) Semantic and Character Feature Methods
To protect hidden information among electronic retyping or OCR usage problems of the previous shifting approach, semantic and character feature steganography methods are suggested. Semantic method proposes using synonyms of words for certain words as for hiding information in the text. However, this method may alter the meaning of the text which will change the intended hidden information.
Text steganography change some of the features of the text characters. Text steganography can hold a large quantity of secret information without making ordinary readers aware of the existence of such information in the text [18] 19] [21].
-
III. THE SCHEME
-
3.1 Encryption of message bits about the cover text
-
3.1.1 Create an array from message data
-
-
3.1.2 Selection of NCP using key
Step I: Take input from keyboard or special characters and compute the length (chlen).
Step II: Convert the length (chlen) into its 8-bit binary equivalent. Store that data bits to earr[bit] as LSB (Least Significant Bit) to earr[1] and MSB (Most Significant Bit) to earr[8] respectively.
Step III: Convert each character to 8-bit (using ASCII-8) binary equivalent and store to earr [ ] as LSB to earr[1+(i*8)] and MSB to earr[8+i*8].
Step IV: Repeat Step III for i=0 to (N-1).
Step V: Stop.
Step I: Calculate number of characters (p) to attack as 4-bit is taken at a time. So p= (bit /4).
Step II : Take the key (K) and calculate the exponential value using
E = Kp [i.e. pow (k, p)].
Step III : Store the exponential long double values into file one by one.
Step IV : Repeat Step II to Step III for i= (1 to p) and go to next step.
Step V : Read the values as character up to “e” of the every line of the file and store it to another file with out taking the point [.].
Step VI : Modify the value as numeric and store it to an array arrxyz[p].
Step VII : Take most three significant digit to arrx[p], next three digits to array arry[p] and least significant digit to arrz[p].
Step VIII : Repeat Step V to Step VII up to end of the file.
Step IX: Stop.
-
3.1.3 Replacement of array elements about the cover text
-
3.2 Decryption of the data bits from the image
-
3.2.1 Regain of replaced message from the stego-text Step I: To get the character position, line and page number from the stego-text go through Step I to Step IV of Algorithm 3.1.2 and Step I to Step III of Algorithm 3.1.3.
-
Step I: S elect the character position (cp) =mod[ arrx mod nocl ], line number (ln) =[ arry mod linp ] and page number (pn) =[arrz mod plmt ].
Step II: Taking 4-bit at a time from the array (earr[]) select the approach from the Table-1.1 . Apply the corresponding style on the selected character.
Step III: Repeat Step II to Step VI for i=1 to p . Step IV: Stop.
Step II: By comparing it with the normal case, collect the data bits from the corresponding characters and store it to darr[]respectively.
Step III: Calculate length taking darrlen [1] as LSB and darrlen [8] as MSB (chlen) of message.
Step IV: Taking data values from the decrypted array darr[ ], LSB as darr[8*i+1] and MSB as darr[8*(i+1))] respectively, convert to its equivalent ASCII-8 character. And store the character to an array msg[len]. Step V: Repeat Step IV for i=3 to p.
Step VI: Finally place the characters one by one from the array msg[len] and assemble the original message. Step VII: Stop.
-
IV. AN IMPLEMENTATION
Let the message to be encrypt is “India is great”. =12(Decimal equivalent) =00001100(8 Bit Binary equivalent).
The array size will be= (8+ (12x8)).
Number of characters required = (100/4) =25.
Let the size of text matrix is 56 x 102.
It signify that, at least 102 characters in every line (horizontal direction) and 56 lines in every page (vertical direction) using Text size=10, Font=Times New Roman and Microsoft Office 2007. Page lay out as Normal, Top: 1", Bottom 1", Left 1"and Right 1". Let the key = 6359.
Using the key we get the nonlinear character position as in Table 4.1.
Table 4.1: Nonlinear character position using key
|
Key, i |
Exponent ial Value |
Charact er Position |
Page No. |
Array Data to Replace |
|
6359, 1 |
6.359000 e+3 |
(35,04) |
1 |
earr[1] earr[4] |
|
6359, 25 |
1.215403 e+128 |
(35:,04) |
4 |
earr[97] earr[100] |



Figure 4.3: Stego-text
-
V. ANALYSIS
In this paper, the major importance is given on the secrecy and the privacy of information. To achieve privacy we have used the concept of cryptography and on the other hand to implement secrecy, we have used steganography. This method satisfies both the security aspects and the hiding capacity necessities. We have simulated the proposed system and the results are shown in the figures 5.1, 5.2 and 5.3 respectively. It generates the stego-text with least degradation of cover text and which is not very informative to people about the existence of any hidden data. This method is capable to hide 4-bits at a time through each and every character in the cover text, which reflects the high embedding capacity of the system. Also this method uses unlike character positions of unlike pages which reflects the high robustness of the system. Anybody may take more bits at a time including more number of pages and more styles. Also dissimilar styles may use for dissimilar communications. This method is also capable of checking the authenticity of the secret message send by the sender to the receiver.
-
VI. CONCLUSION
In this paper, we have proposed a new text steganography technique using Indian language. To do so first we have located nonlinear character position in dissimilar page order, which are calculated through a private key. After that we have encoded the data bits from message by changing the style of selected characters throughout the cover text. For extracting the message we have applied the reverse method using the key. This method featured all the needed aspects of steganography that makes it useful in hidden exchange of information through text documents. This steganography technique is also useful to any other languages like Japanese, Korean, Arabic etc.
ACKNOWLEDGEMENT
The authors would like to thank all the anonymous reviewers who helped refine the state of this paper. The author would also like to acknowledge the Department of Information Technology, Haldia Institute of Technology, Haldia, West Bengal, INDIA for supporting their laboratory.
References A Novel Approach of Text Steganography using Nonlinear Character Positions (NCP)
- M. Grace Vennice, Prof. Tv. Rao, M. Swapna, Prof. J. Sasi kiran "Hiding the Text Information using Stegnography ", International Journal of Engineering Research and Applications (IJERA), ISSN: 2248-9622, Vol. 2, Issue 1, Jan-Feb 2012, pp.126-131.
- Herman Kabetta, B. Yudi Dwiandiyanta, Suyoto, "Information Hiding in CSS: A Secure Scheme Text-Steganography using Public Key Cryptosystem", International Journal on Cryptography and Information Security (IJCIS), Vol.1, No.1, December 2011, pp 13-22.
- Debnath Bhattacharyya, Poulami Das, Samir Kumar Bandyopadhyay and Tai-hoon Kim "Text Steganography: A Novel Approach", International Journal of Advanced Science and Technology Vol. 3, February, 2009, pp. 79 – 86.
- Adnan Abdul-Aziz Gutub, Manal Mohammad Fattani, "A Novel Arabic Text Steganography Method Using Letter Points and Extensions", World Academy of Science, Engineering and Technology 27 2007, pp. 28-32.
- Md. Khairullah, "A Novel Text Steganography System in Cricket Match Scorecard", International Journal of Computer Applications (0975 – 8887) Volume 21– No.9, May 2011, pp. 43-47.
- Souvik Bhattacharyya , Indradip Banerjee, Gautam Sanyal , "A Novel Approach of Secure Text Based Steganography Model using Word Mapping Method(WMM)" International Journal of Computer and Information Engineering 4:2 2010, pp. 96-103.
- Sabyasachi Samanta, Saurabh Dutta, Goutam Sanyal, "An Enhancement of Security on Image Applying Asymmetric Key Algorithm", International Journal of Computer Applications (0975 – 8887), Volume 25– No.5, July 2011, pp. 19-23.
- Atif Bin Mansoor, Zohaib Khan, Shoab Ahmed Khan, " CRYPTO-STEG: A Hybrid Cryptology – Steganography Approach for Improved Data Security", Mehran University Research Journal of Engineering & Technology, Volume 31, No. 2, April, 2012 [ISSN 0254-7821], pp. 219-226.
- Shraddha Dulera, Devesh Jinwala, Aroop Dasgupta, "Experimenting with the Novel Approaches in Text Steganography", International Journal of Network Security & Its Applications (IJNSA), Vol.3, No.6, November 2011 pp. 213-225.
- V. Lokeswara Reddy, Dr. A. Subramanyam, Dr. P. Chenna Reddy, "Implementation of LSB Steganography and its Evaluation for Various File Formats", International Journal Advanced Networking and Applications Volume: 02, Issue: 05, Pages: 868-872.
- Dr. Ekta Walia, Payal Jain, An Analysis of LSB & DCT based Steganography", Global Journal of Computer Science and Technology, Vol. 10, Issue 1 (Ver 1.0), April 2010, pp. 4-8.
- Tu-Thach Quach, "Optimal Cover Estimation Methods and Steganographic Payload Location", IEEE Transactions On Information Forensics And Security, Vol. 6, No. 4, December 2011, pp. 1214-1222.
- Rongyue Zhang, Vasiliy Sachnev, Magnus Bakke Botnan, Hyoung Joong Kim, Jun Heo, "An Efficient Embedder for BCH Coding for Steganography", IEEE Transactions on Information Theory, Vol. 58, No. 12, December 2012, pp.7272-7279.
- Chunfang Yang, Fenlin Liu, Xiangyang Luo, And Ying Zeng, "Pixel Group Trace Model-Based Quantitative Steganalysis for Multiple Least-Significant Bits Steganography" IEEE Transactions on Information Forensics and Security, Vol. 8, No. 1, January 2013, pp. 216-228.
- Yedla Dinesh, Addanki Purna Ramesh, "Efficient Capacity Image Steganography by Using Wavelets", International Journal of Engineering Research and Applications (IJERA) ISSN: 2248-9622, Vol. 2, Issue 1, Jan-Feb 2012, pp.251-259.
- Atallah M. Al-Shatnawi, "A New Method in Image Steganography with Improved Image Quality", Applied Mathematical Sciences, Vol. 6, 2012, pp. 3907 – 3915.
- ak, #mum cryptolabs, "On the 2ROT13 Encryption Algorithm", April 1, 2005, pp. 1-4.
- Himanshu Gupta, Vinod Kumar Sharma, "Role of Multiple Encryption in Secure Electronic Transaction", International Journal of Network Security & Its Applications (IJNSA), Vol.3, No.6, November 2011, pp. 89-96.
- Pranam Paul, Saurabh Dutta, A K Bhattacharjee, "An Approach to ensure Security through Bit-level Encryption with Possible Lossless Compression", IJCSNS International Journal of Computer Science and Network Security, VOL.8 No.2, February 2008, pp. 291-299.
- Monika Agrawal, Pradeep Mishra , "A Comparative Survey on Symmetric Key Encryption Techniques" , International Journal on Computer Science and Engineering (IJCSE), Vol. 4 No. 05 May 2012, pp. 877-882.
- Akanksha Mathur, "A Research paper: An ASCII value based data encryption algorithm and its comparison with other symmetric data encryption algorithms", International Journal on Computer Science and Engineering (IJCSE), Vol. 4 No. 09 Sep 2012 pp. 1650-1657.
- Zaidoon Kh. AL-Ani, A. A. Zaidan, B. B. Zaidan, Hamdan O. Alanazi, "Overview: Main Fundamentals for Steganography ", Journal of Computing, Volume 2, Issue 3, March 2010, ISSN 2151-9617, pp. 158-165.
- Monika Agrawal, Pradeep Mishra , "A Comparative Survey on Symmetric Key Encryption Techniques" , International Journal on Computer Science and Engineering (IJCSE), Vol. 4 No. 05 May 2012, pp. 877-882.
- Akanksha Mathur, "A Research paper: An ASCII value based data encryption algorithm and its comparison with other symmetric data encryption algorithms", International Journal on Computer Science and Engineering (IJCSE), Vol. 4 No. 09 Sep 2012 pp. 1650-1657.
- Mrs. Kavitha, Kavita Kadam, Ashwini Koshti, Priya Dunghav, "Steganography Using Least Significant Bit Algorithm", "International Journal of Engineering Research and Applications (IJERA)" ISSN: 2248-9622, Vol. 2, Issue 3, May-Jun 2012, pp. 338-341.
