A Novel Web Page Change Detection Approach using Sql Server

Author: Abu Kausar, V. S. Dhaka, Sanjeev Kumar Singh
Journal: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Article in issue: 9 vol.7, 2015.
Free access
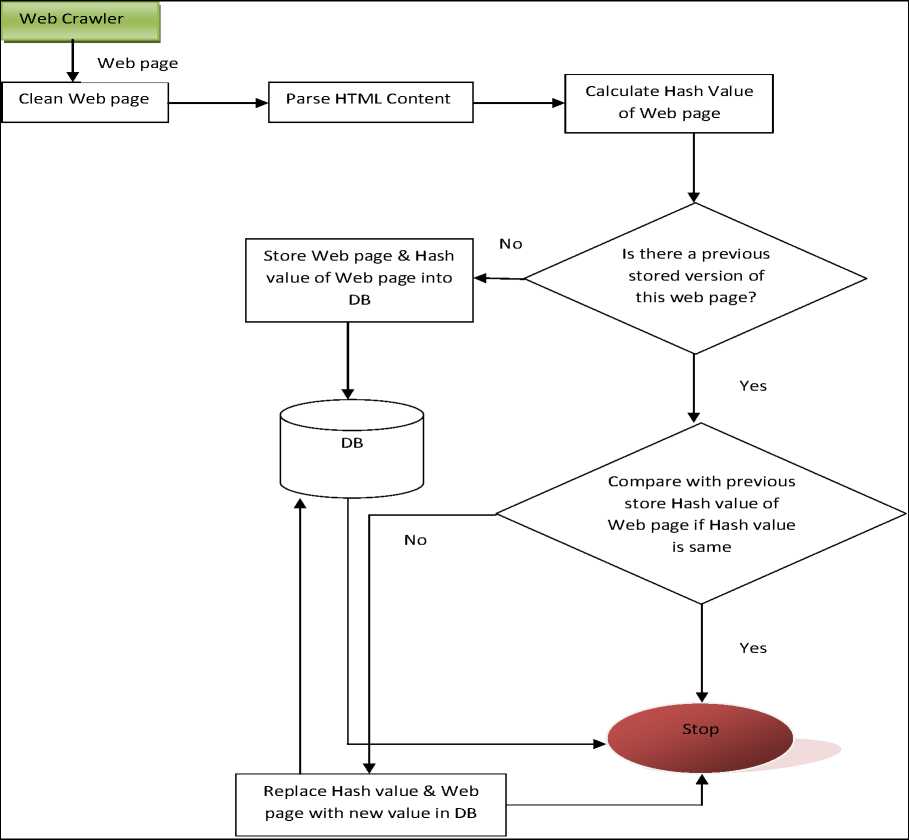
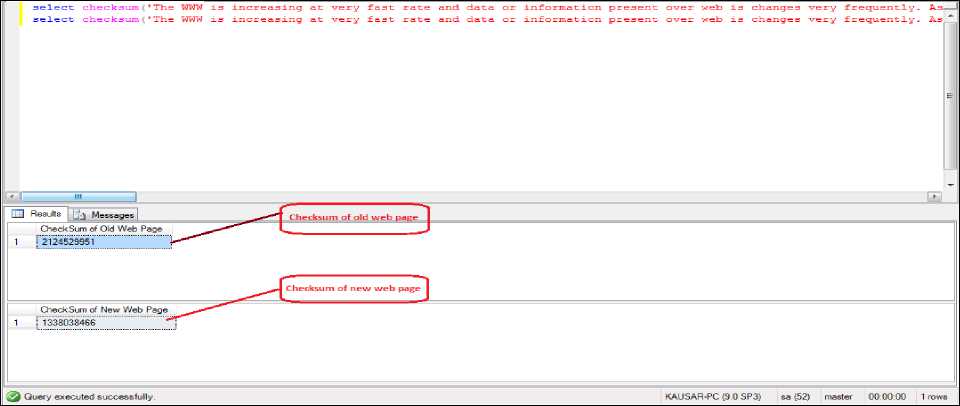
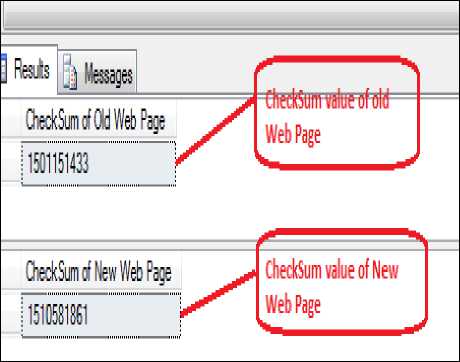
The WWW is very dynamic in nature and is basically used for the exchange of information or data, the content of web page is added, changed or deleted continuously, which makes Web crawlers very challenging to keep refresh the page with the current version. The web page is frequently changes its content hence it becomes essential to develop an effective system which could detect these types of changes efficiently in the lowest browsing time to achieve this changes. In this chapter we compare the old web page hash value with the new web page hash value if hash value is changed that means web page content changed. The changes in web page can be detected by calculating the hash value which is unique.
Web Page change detection, Hash Value, Checksum, HTML
Short address: https://sciup.org/15014793
IDR: 15014793
Text of the scientific article A Novel Web Page Change Detection Approach using Sql Server
Published Online September 2015 in MECS
Nowadays people use internet for exchange of information across the world which results in uploading of new information on web sites very frequently. Web sites bring new and latest information in front of the user as a web page. The web is updated very frequently with new web pages that contain more relevant information to the user. Web page changes will be categorized as Structural Change i.e., addition or removal of tags, content changes. i.e. change of main content of web page, cosmetic changes e.g., changes in the font, color etc., Behavioral Change i.e., changes of script, applet etc. A client may visit a particular web site frequently and is concerned to see how every web page has changed from its previous version. For instance, a cricket lover will be concerned to know how the score is changing continually at every minute. Likewise, to locate any specific things in the web pages which change much of the time for instance one could be keen on knowing the positioning of the hit films. Here changes in the positioning relate to changes in the web page layout. Therefore this method supports to decrease the searching time of the client and permits the client to discover the things in web documents which changes regularly. Client may be involved in knowing the positioning of the hit movies. Here changes in the positioning of the movies match with changes in the design of the web page. Hence this framework assistance to decrease the searching time of the client and lets the client to locate the matters in web documents which changes regularly. Web pages content changes at very fast rate. Thus it becomes very difficult to examine the changes which are made in web pages and retrieve the original web pages at fast rate. About 60% of the contents on the Web is dynamic [1] and approx 14% of the links in search engines are broken [2]. Search engines depend on web crawlers to collect web pages and store the web pages in their local repository, and the copies of web pages are later saved to reply the related questions of user. The search engines may match these retrieved copies with their available user queries, due to limitations of resources it is not possible for web crawlers to continually observe and retrieve all web pages.
The rest of this paper is organized as follows: The existing work related to our problem is presented in Section 2. Section 3 describes the classification of web page change Section 4 describes the architecture of proposed system and Section 5 concludes this paper.
-
II. R elated W ork
To predict the probability of web page change detection is not a new problem and there are so many research papers [3], [4], [5], [6], [7], [8], [9]. For example,
Cho and Garcia-Molina [3] crawled approx 720,000 web documents in a day for a period of 4 months and examine how the web page changes. Ntoulas, Cho, and Olston [8] collect snapshots of approx 150 websites weekly for one year and examine web page change. The author found that most web documents did not change as per packs of words measure of comparability. Even for web documents which are changed, the change amount is minor. Recurrence of web page change was not a major indicator of the measure of web page change; however the measure of web page change was a decent indicator of the prospect measure of web page change.
The biggest examine of web page change detection was carry out by Fetterly et al. [4]. The author crawled approx. 150 million web documents in a week for eleven weeks, and analyzed the changes of web documents. Ntoulas et al. [8], they discovered a moderately little measure of page change, by approx 65% of web document sets remain closely the similar. The study also establish that previous web page change was a decent predictor of prospect change, that web document measurement was connected with age change, and the top level area of a web document was associated with change.
Olston and Panday [10] crawled approx 10,000 random Web pages and approx 10,000 web pages tested from the Open Directory for a number of months in every two days. Their examinations measured both change recurrence and data life span, and found only a reasonable association between the two.
-
[11] and [12] discussed how the retrieved outcomes change over time. The main aim of these studies about the understanding of the changing aspects of searching tools and the concerns modify for explore who need to revisit to formerly observed web documents.
In [13], E. Leonardi and Bhowmick studied that web page change detection using ordered and unordered tree model method is not appropriate for the reason that many memories needed for keeping two different types of XML records in the memory. In this research work author use relational database for identifying content variations of ordered large XML document. Firstly it saves XML data in relational database and then identifies the variations of web pages by the use of SQL queries. This method provides the improved scalability and enhanced execution.
XMLTreeDiff [14] figures variance among XML Documents taking into account heuristic closeness. It processes the checksum values for the hubs of both the records utilizing DOM checksum [15] and after that decreases the measure of the two trees by evacuating indistinguishable sub trees.
In [16] [17] [18], different diff algorithms are clarified for identifying modifications in XML data. The algorithm in [18] is taking into account discovering and afterward taking out the similar hubs from the two XML documents that are being analyzed. The change operations are next detected from the non-matching nodes. Coordinating of hubs is taking into account looking at elements of hub substance and children (signatures) and request of event in common manner request subsequences of hubs. In [16] [17] utilize alter scripting to analyze between two web pages and convert the web documents to trees as per the XML configuration. The power of these algorithm lies in their low time-complexity, which is in the order of O(nlogn). Though, this great execution can’t be attained when looking at HTML pages as it depend on certain XML structures. Alter scripting only is not enough for attaining O(nlogn), particularly if move operations are to be considered.
In [19] convert a HTML page into a tree structure and classify node data into attributes, content and configuration. Three likeness methods are utilized to identify variations of these three types, intersect i.e., rate of words which are similar, attdist i.e., amount of the relative weight of similar attributes, and typedist i.e. measure of the location of the elements in the tree. The system hypothetically uses the Hungarian algorithm [20] for searching the most similar subtree between two web pages, but no such type of details on its uses are given. The experimental results do not discuss speed performance they only display the effects of the importance actions on finding correctness. In [21], a novel web page change detection method for static web pages was proposed which is taking into account into three heuristic-derived enhancements to the Hungarian algorithm. For the Hungarian algorithm the comparability coefficients among all hubs of each subtree in the mention page and those of each subtree in the upgraded page are calculated and set in a cost matrix. The primary advancement limits the utilization of the calculation to the subtrees having the conceivable of being the most related subtrees, the second manages the halting criteria of the calculation if the span of the upgraded subtrees page gets to be not as much as that of the subtree of the notice page by a particular issue, lastly, the third improvement stops the calculation after the similarity coefficients drop beneath a certain edge.
-
III. W eb P age C hange C lassification
The changes of web pages can be classified into following four main categories [22]:
-
A. Structural Change
-
B. Content Change
-
C. Cosmetic Change
-
D. Behavioral Change
-
A. Structural Change
The structure of web page is change by addition or deletion of some tags. The addition or deletions of link in a web page also change the whole structure of the web page.
Fig.1. Initial Version of Web Page.
Fig.2. Changed Version of Web Page.
-
B. Content Change
When the main content of the web page is change then this type of change comes under content change. For example, web page created for online news site change very frequently to keep latest information from time to time. Another example can take of web page created for any match which is continuously updated as the tournament progress. When the match ends, the web page displays the information about award ceremony instead of match scores. The web page which contains the records of the players get modified according to reflect the latest records.
-
< li> Afghanistan set 255-run target for B'desh
-
< li> Suicide at metro station in Kolkata, services affected
-
< li> Asia Cup: India need to make amends against Pak
-
< li> Asia Cup: Sri Lanka beat India by two wickets.
Fig.3. Initial Version of Content Change of Web Page.
- Asia Cup 2014: Stanikzai, Shenwari lead
Afghanistan to 254/6 against Bangladesh
< li> Suicide at metro station in Kolkata, services affected
< li> President rule in Andhra Pradesh, assent to Telangana bill.
< li> Asia Cup: Sri Lanka beat India by two wickets.
-
Fig.4. Changed Version of Content Change of Web Page.
-
C. Cosmetic Change
When the HTML tag of the web page is changed without changing the content of the web page then this type of change comes under cosmetic change. The content of web page is remained.
Afghanistan set 255-run target for B'desh
-
< p> Suicide at metro station in Kolkata, services affected
-
< p style=”background-color: yellow”> Asia Cup: India need to make amends against Pak
-
< p style=”background-color: green”> Asia Cup: Sri Lanka beat India by two wickets.
-
Fig.5. Initial Version of Cosmetic Change of Web Page.
-
D. Behavioral Change
When scripts, applets etc. in web page gets modified then this type of modifications comes under behavioral change. This type of codes (Script, applets etc.) is especially hidden in other files. However, it is difficult to grasp such modifications.
-
< p> Afghanistan set 255-run target for B'desh
-
< p> Suicide at metro station in Kolkata, services affected
-
< p> Asia Cup: India need to make amends against Pak
-
< p> Asia Cup: Sri Lanka beat India by two wickets.
Fig.6. Changed Version of Cosmetic Change of Web Page modify the web pages in some specific portions like latest news and events. Figure 7 is an example of web page using design of templates. The blocks surrounded by the blue boxes are generally used to display fresh information on this web page.
To accommodate modification on web pages, we use document tree to denote different types of web pages in takeout web changes. Our algorithm is carried out in two different stages:
-
• Construction of document tree
-
• Calculate Hash value of web pages
-
A. Document tree construction
We use Document Object Model (DOM) [23] to construct HTML document tree. The components in HTML pages are not all the time viewed in a nested way. While constructing the HTML document tree following two difficulties are faced.
-
IV. E xtraction of W eb P age C hanges B etween D ifferent V ersions
HTML pages are made by markup languages which can be used to construct a document tree. For instance, the Document Object Model [23] builds a document tree for a HTML pages. The document tree of web pages brings more data than a content document and extracts more information efficiently than a text file.
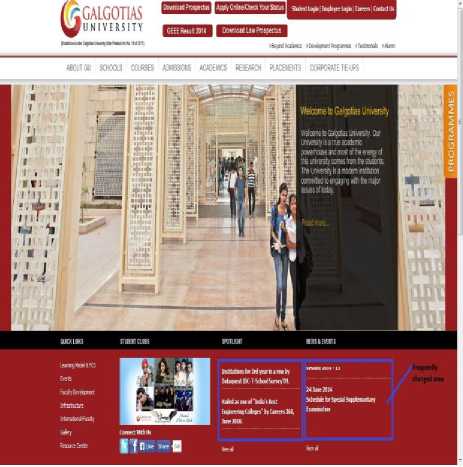
Fig.7. An Example of Modification Areas on Web Pages.
On average the quantity of change on current web document is considerably lesser than the content of the web page. At the point when users add or change the content of page, it is possible that only content is included or changed whereas the web page tree structure and design of content in web pages remain comparatively fixed. Nowadays more web developers have a tendency to keep up the structure of site pages as layouts, they
-
• According to HTML 4.01 Description [24], the presence of end tag can be compulsory or noncompulsory or not allowed. For instance, ,
References A Novel Web Page Change Detection Approach using Sql Server
- Cho, Junghoo, Angeles, Los, and Garcia-Molina, Hector, "Effective Page Refresh Policies for Web Crawlers", ACM Transactions on Database Systems, Volume 28, Issue 4, pp. 390 – 426, December 2003.
- Lawrence, S., and Giles, C. L., "Accessibility of information on the web", Nature, 400:107-109, 1999.
- Cho, J. and H. Garcia-Molina. The evolution of the Web and implications for an incremental crawler. VLDB conference 2000, 200-209, 2000.
- Fetterly, D., M. Manasse, M. Najork, and J. Wiener. A large-scale study of the evolution of Web pages. WWW '03, 669-678, 2003.
- Kim, J. K., and S. H. Lee. An empirical study of the change of Web pages. APWeb '05, 632-642, 2005.
- Koehler, W. Web page change and persistence: A four-year longitudinal study. JASIST, 53(2), 162-171, 2002.
- Kwon, S. H., S. H. Lee, and S. J. Kim. Effective criteria for Web page changes. In Proceedings of APWeb '06, 837-842, 2006.
- Ntoulas, A., Cho, J., and Olston, C. What's new on the Web? The evolution of the Web from a search engine perspective. WWW '04, 1-12, 2004.
- Pitkow, J. and Pirolli, P. Life, death, and lawfulness on the electronic frontier. CHI '97, 383-390, 1997.
- Olston, C. and Pandey, S. Recrawl scheduling based on information longevity. WWW '08, 437-446, 2008.
- Selberg, E. and Etzioni, O. On the instability of Web search engines. In Proceedings of RIAO '00, 2000.
- Teevan, J., E. Adar, R. Jones, and M. A. Potts. Information reretrieval: repeat queries in Yahoo's logs. SIGIR '07, 151-158, 2007.
- Erwin Leonardi, Sourav S. Bhownick, "Detecting Content Changes on Ordered XML Documents Using Relational Databases".
- F.P.Cubera, D.A. Epstein. "Fast Difference and Update of XML documents", Xtech, san Jose, March 1999.
- H. Mayurama, K. Tamora, "Digest value for DOM (DOM hash) proposal", IBM Tokyo Research Laboratory, http://www.tri.ibm.co.jp/projects/xml/domhash.htm, 1998.
- G. Cobena, S. Abiteboul, A. Marian, Detecting changes in XML documents, in: 18th International Conference on Data Engineering, San Jose, CA, 2002, pp. 41–52.
- Y. Wang, D. DeWitt, J. Cai, X-Diff: an effective change detection algorithm for XML documents, in: International Conference on Data Engineering, Bangalore, India, 2003, pp. 519–530.
- J. Jacob, A. Sache, S. Chakravarthy, CX-DIFF: a change detection algorithm for XML content and change visualization for WebVigiL, Data and Knowledge Engineering, Volume 52, Issue 2, pp. 209–230, 2005.
- S. Flesca, E. Masciari, Efficient and effective web change detection, Data and Knowledge Engineering, Volume 46, Issue 2, pp. 203–224, 2003.
- H. Kuhn, The Hungarian method for the assignment problem, Naval Research Logistics, Volume 2, Issue 1, pp. 7–21, 2005.
- I. Khoury, R. El-Mawas, O. El-Rawas, E. Mounayar, H. Artail, An efficient web page change detection system based on an optimized Hungarian algorithm, IEEE Transactions on Knowledge and Data Engineering, Volume 19, Issue 5, pp. 599–613, 2007.
- Francisco-Revilla, L., Shipman, F., Furuta, R., Karadkar, U. and Arora, A., "Managing Change on the Web", In Proceedings of the 1st ACM/IEEE-CS joint conference on Digital libraries, pp. 67 – 76, 2001.
- P. L. Hegaret, R. Whitmer, and L. Wood, "W3C Document Object Model (DOM)", June 2005. URL http://www.w3.org/DOM/.
- HTML 4.01 Specifications. http://www.w3.org/TR/html4/.
