Adaptive Weighted Clustering Algorithm for Mobile Ad-hoc Networks

Author: Adwan Yasin, Salah Jabareen
Journal: International Journal of Computer Network and Information Security(IJCNIS) @ijcnis
Article in issue: 4 vol.8, 2016.
Free access
In this paper we present a new algorithm for clustering MANET by considering several parameters. This is a new adaptive load balancing technique for clustering out Mobile Ad-hoc Networks (MANET). MANET is special kind of wireless networks where no central management exits and the nodes in the network cooperatively manage itself and maintains connectivity. The algorithm takes into account the local capabilities of each node, the remaining battery power, degree of connectivity and finally the power consumption based on the average distance between nodes and candidate cluster head. The proposed algorithm efficiently decreases the overhead in the network that enhances the overall MANET performance. Reducing the maintenance time of broken routes makes the network more stable, reliable. Saving the power of the nodes also guarantee consistent and reliable network.
MANET, Clustering, Connectivity, Power, Node Capabilities, Transmission range
Short address: https://sciup.org/15011516
IDR: 15011516
Text of the scientific article Adaptive Weighted Clustering Algorithm for Mobile Ad-hoc Networks
Published Online April 2016 in MECS
Wireless communication and the wide spread of personal mobile devices has led to increase the need for forming means of communication among these devices; those networks are called MANET [1] [2]. This kind of networks has special characteristics :( 1) no central administration unit – nodes need to manage themselves. (2) Mobility: the networks consists of mobile devices like laptops, smartphones, and PDAs etc. (3) battery-powered nodes and limited resources clients. Fig 1 shows a simple form of MANET networks. Any node could communicate directly with other (within transmission range) nodes in the network, or by using the assistance of other intermediate nodes to reach the desired destinations. Hence, the nodes in the network should act as routers capable of forwarding packets to the desired reachable destinations.
Designing and implementing efficient routing protocol is a big challenge, the desired protocol has to achieve a group of properties and satisfy MANET special needs. Dynamic topology change, mobility, power, resources and many other factors needs to be considered.
The main goal when designing efficient routing protocol is to consider the overhead of the network, we need primarily to reduce control messages to the minimum and reduce the delay.
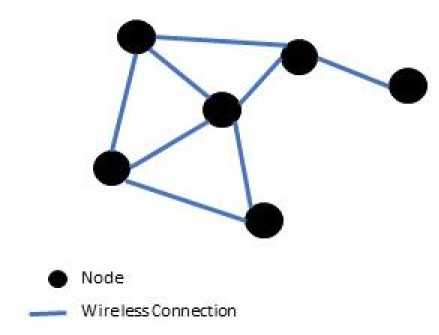
Fig.1. Simple form of MANET
When considering overhead an on-demand (reactive) routing mechanism is deployed, this mechanism does not require the nodes to periodically collect information about the network topology and store that information in its routing table for all the reachable destinations in the network. Instead, it works only based on routing requests from the nodes. Any source node in the network wants to communicate with other destination node; it first floods the network with a routing request message, the message propagates throughout the network until reaching its desired destination, the destination will reply with a route reply message using the same intermediate nodes to its originator. Finally, the originator selects a route among all routes reply messages received and use it to send data packets. An example of such routing protocols are AODV [3], DSR [4] and TORA [5].
On-demand routing significantly reduces the number of control messages needed to adapt topology change, but this mechanism may cause a significant initial delay as each node wants to send data to its destination has to wait some time before it can start sending data. To overcome this delay, the routing information should be kept in a routing table all the time. This requires that routing tables needs to be fresh and up to date all the time and aware of fast topological change. This mechanism of routing called (proactive routing) where all information required are collected in advance and used directly when needed. The nodes in the network periodically floods the network with control messages and updates their routing tables based on the data collected. This will guarantee freshness of the routes and no delay time to maintain a route to any destination. Sample proactive protocols include DSDV [6] and OLSR [7].Proactive routing could cause a lot of extra overhead because of the periodic control messages flooded over the network. Some of those protocols has shown better performance results than others [8]
Minimizing the number of control messages needed in the network is an important issue because the resources available in MANET like bandwidth, power and local resources of the nodes are limited. Due to nodes heterogeneity, the resources in the network may vary, this will lead to a hierarchy in the roles of nodes in the network. In addition, end-to-end and initial delay time are very important performance metrics and needs to be reduced to the minimum. In this paper, we propose a new algorithm for enhancing routing in MANET and reducing the overhead and delay time by using balanced weighted clustering technique. This technique make use of reactive and proactive routing mechanisms by considering nodes power, degree of connectivity and nodes local processing and memory capabilities.
The rest of the paper is organized as follows: in section II we introduce the concept of clustering and some common clustering algorithims. In section III we introduce the related work about clustering in more details. Section IV shows details about transmission range and power consumption. Our proposed AWCAMAN algorithm is presented in section V. section VI introduces the concept on gateways and how it operates in the clustering scheme. And finally we conclude in section VII.
-
II. Clustering
MANET consists of heterogeneous nodes that interacts with each other. The limited resources available and to reduce the overhead and the amount of control messages flooded throughout the network, we need to build clusters. Clustering depends on dividing the geographical area into smaller operational areas that has a central administrator node to operate the operations over its local cluster [15]. The idea of clustering is to group the nodes into operational logical clusters, routing occurs using paths between clusters instead of all nodes. This will reduce control messages exchange among network and increases lifetime of routes. Nodes in the network can register to any cluster and become a member within a group that administrated by a cluster head. The cluster head also can be any node that has the optimal requirements for operating a cluster like power, processing and mobility conditions.
The concept of clustering have been proposed in several algorithms, for example some algorithms works based on a local variable called the node identifier that assigned to every node and the cluster head is elected based on that identifier [8][16]. Another approaches depends on the connectivity of the nodes, where the distance between nodes is considered and the number of the neighbor nodes is calculated to elect the cluster head [12][17][18]. The mobility of nodes within the network is a major factor that affects the stability and reliability of the network as overall, this metric has been figured in clustering algorithms like in [19][20]. The power metric has been considered in [11] [21].
Clusters depends on selecting a specific node within a group of nodes called Cluster Head (CH), cluster head will be responsible for custom activities within its group (i.e. cluster). It will be responsible coordinating its cluster’s nodes. Cluster head will take responsibility of communicating with other cluster heads in the network during data transmission. Communication process between clusters occurs using intermediate ordinary nodes, those nodes has direct access to two or more cluster heads. Fig. 2 shows an example of MANET that uses clustering.
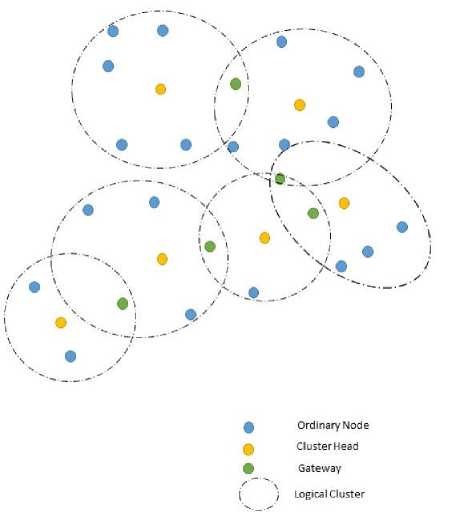
Fig.2. Clustering
When a node in a cluster wants to communicate with other node, it will communicate first with its cluster head. Cluster head in turn forwards data to its destination within the same cluster. If the destination is not within the same cluster, CH will forward the data to the gateway, which will in turn, passes the message to next cluster head. The message will propagate to the entire network using gateways and cluster heads only and hence reducing the overhead of the network and enhances the scalability and reliability of the network.
To further illustrate clustering and the communication process occurs in clusters scheme suppose the network in Fig. 3 which represents a group of mobile nodes {i0….i22} that forms a MANET, the nodes initially forms the clusters by electing cluster heads to operat the cluster, clusters here are formed based on any of the algorithims we mentioned before, the cluster heads in the example are (i1, i3, i8, i14 and i18), these cluster heads will be responsible for all the operations for all nodes belonging to its logical cluster. Any message from or to a node belongs to its cluster will pass throughout the cluster head. Suppose node i0 wants to communicate with node i15, first node i0 will initiate a route request to its cluster head i1, the cluster head will ask its adjacent cluster heads (in this example i3) for a route to the destination, the cluster i3 in turn asks for path from it’s adjacent cluster heads (i8 and i18 in our example) and also these CHs asks the adjacent CHs (i14). At this point CH i14 replies that the desired node (i15) belongs to its cluster. The response message passes through the same path to the origin node i0. The communication process starts using the path shown in Fig. 3. Note the the path is not nessesary the shortest path from source i0 to destination node i15. Actually this is the idea behind clustering, the heavy work is done by a central node instead of using all nodes participate in every path finding and transmitting process. Further more, CH knows the list of nodes belongs to its cluster and hence can handle the requests and communications apart from other nodes in the cluster.
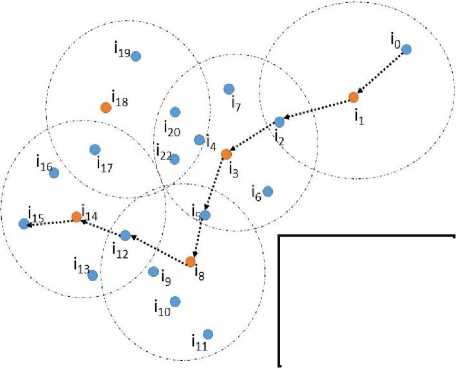
• Cluster Head
• Ordinary Node
( 'Cluster
••••*. Communication path
Fig.3. Example of Communication Process using Clusters
-
III. Related Works
The most important factor in clustering is the mechanism in which cluster head elected. Nodes are responsible for electing a cluster head within a group of nodes. Different algorithms proposed for electing the ideal cluster head:
Nodes assigned a unique ID each. This ID used to elect the cluster head. Cluster head is the node that has the minimum ID number like in (LIC) [8]. The algorithm selects the node with the lowest ID to be the cluster head among a group of directly accessed nodes. Initially each node broadcasts its ID, any node receives a message with a lower ID it will consider it as its cluster head. If no lower IDs received than its own it will broadcasts itself as the cluster head. The problem with that algorithm, it only elects cluster head based on its ID and only the node with the lower ID will be elected, no other properties participate in the election. Moreover, nodes with lower IDs are mostly the only candidates to be the cluster heads all the time and this will drain their power.
Another major factor that affects clustering is mobility of nodes. High Mobility of nodes may increase overhead and cause fast change of network topology. When selecting cluster heads it is important to take into consideration the stability of cluster heads movement. The mobility-based d-hop clustering algorithm [9] calculates the mobility of nodes and uses nodes stability as a metric for electing the cluster head. It uses signal strength to estimate the distances between neighbors. The stronger the signal the shorter the distance. It uses signal strength in several points to calculate the relative mobility. The relative mobility and estimated distance are used to calculate the local stability of a node and hence electing the node of higher stability to be the cluster head. The problem with this algorithm is that the estimated distance between nodes not precise because the nodes with lower battery may transmit signals at lower strength.
LBC [10] is an algorithm that balances the load of cluster heads based on nodes power. The algorithm specifies a unique virtual ID for each node. The one with the largest ID within a group of adjacent nodes will be elected as cluster head. The elected cluster head will remain in his role for a specific period of time (user-predefined time) then it resigns and sets its virtual ID to 0 and remains a non-cluster head node. The node with the higher ID then then takes the role within the same cluster. This way the algorithm will guarantee that power will be saved for all nodes. The problem with LBC that it only uses power saving time which is not enough indicator to select the cluster head. Another algorithm called Power-aware connected dominant set [11], the algorithm uses the power level of a node to guarantee the stability of network by making nodes serve as much time as possible. The algorithm builds a dominant set of nodes. The target is to minimize the power consumption of the dominant set nodes. This set is prone to lose power as they do extra jobs serving as cluster heads. Only the node with a higher level of power within a cluster will be elected as the cluster head and if any other dominant node exists within the same cluster it will be excluded from the dominant set and become an ordinary node. This algorithm ignores other nodes in the network and only thinks about the dominant set to save their power.
Other algorithms of clustering depends on the degree of connectivity. The degree of connectivity represents the number of nodes that are directly connected to a node; the higher the number of nodes is the higher the degree of connectivity [8]. The cluster heads remains longer time but it shows lower throughput as the number of nodes in the cluster increases. Another approach is to set a threshold limit for the number of nodes a cluster head can manage like in [12] to reduce the delay may result from the big number a cluster head may manage and causes bottleneck. In t his way the load will be balanced among nodes rather than only some few clusters.
-
IV. Transmission Range and Power Consumption
The power needed to transmit some amount of data depends on the distance between nodes and the propagation environment, the relation between distance and consumed power is given in the following formula [13]:
= ( ; ) (1)
Where Pr is receiving power, Pt is the transmitted power; d is the distance between sender and receiver node and n is the transmission factor whose value depends on the propagation environment.
To measure the distance between node i and node j we incorporate the effect of path loss exponent and shadowing parameters [14]:
RSSI-A dtj =10 ∗ (2)
Where:
dij : distance from node i to node j.
RSSI : receiving signal strength indicator.
A : is received power from reference distance which is 1 meter
n : is the transmission factor whose value depends on the propagation environment.
Eq. (2) shows the estimated distance between every two nodes in the system, the distance used to decide which node can act as cluster head based on its location among its neighbors. The node that is closer to its neighbors does not consume a lot of power to transmit.
-
V. Proposed AWCAMAN
We believe that power constrain of nodes in MANET is a master key and a very important factor in that type of networks because it directly affect the consistency and stability of network topology. Moreover, the capabilities of nodes itself is another important factor in selecting the cluster-head, because the cluster-head will be responsible for the monitoring other nodes in the cluster, do the required calculations and hence fire a suitable response. Another important issue is degree of connectivity that proposed by Gerla and Tsai [8], where the node with higher degree of connectivity will be chosen as the cluster head. Here we will build an algorithm that balances those three major constraints: power, capabilities, and nodes connectivity.
In our proposed work, the election process depends on the following basis:
-
• Each node has the chance to be a cluster head based on the calculation of the constraints of power, connectivity, and node capabilities.
-
• Any elected cluster-head could remain a clusterhead until a better candidate cluster-head elected, i.e. the election process is not limited to a period.
-
• The remaining power is a major factor in calculating the chance of being a cluster head where the node with a higher remaining battery power has a higher chance to be selected.
-
• Node capabilities is a master constrain in selecting cluster head as it represents the ability and performance of node to cope all the calculations of its citizens like message passing and topological changes.
Based on those features we can present an algorithm that combines all those factors to get an efficient mechanism for clustering the network and hence dividing the network into balanced loaded sections over custom nodes with higher capabilities. The calculation has is done in three situations: start-up of the system, a change in the factors in each node, and when nodes in some clusters are lost or new nodes added to the system. The algorithm for electing a cluster-head will go as follow:
-
• For every node i in the system find the neighbors (neighbors means the nodes within its transmission range).
∀ і ∈ М→{N j |i ∈ Ν j ,N j ⊆ М} (3)
Where:
Ni is the degree of node i (i.e. Number of neighbors) M is the set of all nodes in the system.
i is any node in the system.
-
• For every node i in the system find the number of nodes it can handle Nmax (i) .
-
• Find the connectivity degree Ci for every node i,
Nj N(max
-
• For every node find the remaining battery power RBP=Battery power/maximum battery power.
=
PB
Max PB
-
• For every node in the system calculate the distance to its neighbors using Eq. (2), then calculate the average distance for all the neighbors (D):
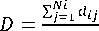
Nl
-
• Retrieve the node capabilities Ri for every node i where Ri = processor speed + RAM capacity and speed.
-
• Calculate the combined factors value:
= + + +1⁄ (7)
-
• Select MAX Vi to be the cluster-head. All the neighbors for that cluster-head will be no more able to participate in other cluster-head calculations for other clusters and will belong to that node with higher Vi .
-
• Repeat the process for all nodes who are not in clusters yet.
This algorithm works when the system starts over and all nodes are up. Every node will broadcast its unique id to all nodes. Nodes within its transmission range will receive the message and will count all messages received with unique ids and get “Ni” value. Moreover, the nodes will also broadcast the value of Vi after calculating Ci and Ri and RBP for its own. At this point each node will receive the Vi value for all neighboring nodes and its Vi, the node will select the larger Vi value as its cluster-head and will not participate in any other calculation until an update occurs. The node that is selected as a cluster-head will broadcast a message to the neighbors informing them that it is the cluster-head , if a node does not receive that message consider itself as not belonging to any cluster and hence it will recalculate the Vi value and finds another cluster-head. If no one of its neighbors is a cluster-head then it will consider itself as a cluster-head with no citizens. The full detailed algorithm goes as follows:
//COUNT_NEIGHBORS: a counter for counting the number of neighbor nodes in range
//ID: is the associated node id
//TIMER1, TIMER2: are constant variable timers.
// NEIGHBORS_RESPONSE (ID): the response message for neighbors request message
//V_RESPONSE (V, ID): response message containing the combined value V and node ID
//V_MAX: is the maximum combined value V
//CH: is cluster head.
//CH_ACK(ID): is the message informs the nodes that the node (ID) is a cluster head
*/
COUNT_NEIGHBORS=0;
Initialize TIMER1;
Broadcast NEIGHBORS_REQUEST_MESSAGE (ID);
while
(TIMER1!
NEIGHBORS_RESPONSE(ID)!=NULL)
COUNT_NEIGHBORS + = 1;
Calculate distance to node SUM_D+=10^((RSSI-A)/-10*n));
D=SUM_D / COUNT_NEIGHBORS;
if (COUNT_NEIGHBORS==0)
{
Consider node as isolated node;
Re-initialize algorithm after specific time;
END;
}
Calculate connectivity degree C =
COUNT_NEIGHBORS / MAX_CONNECTIVITY Calculate combined value V = C + RBP + R;
broadcast V_RESPONSE(V,ID);
Listen for V values from neighbors;
V_MAX=V;
Initialize TIMER2;
{ store V value in ARRAY[ ID ];
If(ARRAY[ID]>V_MAX)
Set V_MAX = Array[ID];
}
If(V>V_MAX)
{
Consider node as CH;
broadcast CH_ACK(ID);
wait for JOIN_REQ (ID) messages store nodes who send JOIN_REQ () to be its citizens;
} else
{ consider node as member for V_MAX node source;
wait for CH_ACK from source node;
if (CH_ACK received after specific time)
send JOIN_REQ(ID);
else search ARRAY [ ] for the next higher V in the array and consider as cluster-head;
}
END
The main goal of clustering using this algorithm is to minimize the operation of finding cluster-heads. In addition, to take into consideration the capabilities variation and heterogeneity of nodes, because the operations and calculations needed for data forwarding and paths finding needs extra operations to execute and it will consume a lot of power, hence we give the remaining power of the node and the average distance to other nodes an extra attention.
The parameters used in our algorithm depends on the nature of the MANET network, each type of MANET networks may differ from other networks and each parameter may have higher priority than other. For example, in a high mobile network the distance between nodes play a critical role in selecting cluster head as it affects the power of the nodes. Another example in a limited resources nodes where nodes capabilities are limited and the cluster head is the one with higher resources.
The variations of networks requirements and needs can be figured by assigning a weighting factor for each parameter, those factors can be assigned be user to fit his needs during the setup process.
We update Eq. (7) as follows:
= 1 ∗ + 2 ∗ + 3 ∗ + 4⁄ (8)
Where w1...w4 are user defined factors; the average distance D represents the average distances of nodes within the transmission range of node i,; the lower D parameter the higher the chance to select as cluster head as it saves more power when transmitting.
-
VI. Gateways
A gateway node is a node that is situated in the transmission range of two neighbor cluster heads. It is used by those cluster heads to bypass messages among them. In Fig. 4 below, green nodes are gateways in there ideal locations. Gateway is a member of only one cluster and also able to communicate directly with at least one another neighbor cluster head (i.e. one cluster head or more). Cluster head uses gateway to bypass data and control messages to other clusters, and when there is no gateway member in its cluster, this cluster will be isolated from the entire network. Fig. 4 shows an example of such a situation.
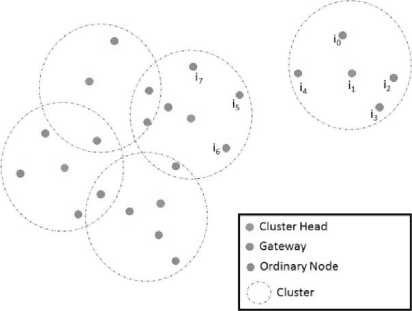
Fig.4. Isolated Cluster Situation
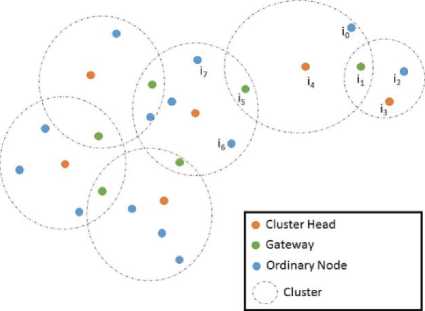
Fig.5. Isolated Cluster Solution
In the example above, the node i1 elected as the cluster head during the initialization process. Cluster members are {i0, i2, i3, i4). This cluster has no gateway (i.e. there is no nodes that directly connected to other cluster heads).
To solve this problem we need to reform the cluster such that there is at least one gateway connected to its cluster head. The following formula should be implemented:
∃ i ∈ СНi|i ∈ СНi∩i ∈ СНk (9)
Where:
CHi, CHk the group of nodes that are within the transmission range of cluster heads CHi and CHk .
To implement the formula in (9), the cluster head i1 will check the nodes within its cluster, if there is no node can reach another cluster head it will acknowledge its members that it is no more a cluster head. The process of startup will be repeated excluding that cluster head candidate. Nodes will find new cluster head and the new cluster head will check for a gateway. The process still repeated until the ideal situation is reached. Fig. 5 shows the final clusters after the isolated cluster problem solved.
Gateways are a major component in each cluster and it’s the medium that passes messages between clusters.
-
VII. Conclusion
Heterogeneity and limited resources of mobile ad-hoc networks are the major limitations when designing protocols, they directly affect the connectivity and reliability of those networks. The best way to handle those limitations is to balance the load and assign the heavyduty roles to the fittest nodes with higher battery power and higher degree of connectivity and bigger local resources. The algorithm we presented above can adaptively handle big networks, high rate of topological changes, heterogeneous networks; and significantly increases the network connectivity and reliability. Links establishment and maintenance are faster. The user also has the chance to alter the factors of the parameters to fit his needs and to take into consideration the variation among different MANETs.
References Adaptive Weighted Clustering Algorithm for Mobile Ad-hoc Networks
- Charles E.Perkins, "Ad hoc Networking", Addison Wesley, 2001.J.
- Subir Kumar Sarkar, T.G. Basavaraju, C. Puttamadappa "Ad Hoc Mobile Wireless Networks: Principles, Protocols and Applications", Auerbach Publications – Taylor & Francis Group, 2008.
- C. E. Perkins, E. M. Belding-Royer, and S. Das. Ad hoc OnDemand Distance Vector (AODV) Routing. RFC 3561, July 2003.
- Johnson, David B., David A. Maltz, and Josh Broch. "DSR: The dynamic source routing protocol for multi-hop wireless ad hoc networks." Ad hoc networking 5 (2001): 139-172.
- V. Park and S. Corson, Temporally Ordered Routing Algorithm (TORA) Version 1, Functional specification IETF Internet draft (1998).
- Perkins, Charles E., and Pravin Bhagwat. "Highly dynamic destination-sequenced distance-vector routing (DSDV) for mobile computers." ACM SIGCOMM Computer Communication Review. Vol. 24. No. 4. ACM, 1994.
- Jacquet, Philippe, et al. "Optimized link state routing protocol for ad hoc networks." Multi Topic Conference, 2001. IEEE INMIC 2001. Technology for the 21st Century. Proceedings. IEEE International. IEEE, 2001.
- Jha, Rakesh Kumar, and Pooja Kharga. "A Comparative Performance Analysis of Routing Protocols in MANET using NS3 Simulator." (2015). I. J. Computer Network and Information Security, 2015, 4, 62-68.
- M. Gerla and J. T. Tsai, "Multiuser, Mobile, Multimedia Radio Network," Wireless Networks, vol. 1, pp. 255–65, Oct. 1995.
- I. Er and W. Seah. "Mobility-based d-hop clustering algorithm for mobile ad hoc networks". IEEE Wireless Communications and Networking Conference Vol. 4. pp. 2359-2364, 2004.
- A. D. Amis and R. Prakash, "Load-Balancing Clusters in Wireless Ad Hoc Networks," in proceedings of 3rd IEEE ASSET'00, pp. 25–32 Mar. 2000.
- J. Wu et al., "On Calculating Power-Aware Connected Dominating Sets for Efficient Routing in Ad Hoc Wireless Networks," J. Commun. And Networks, vol. 4, no. 1, pp. 59–70 Mar. 2002.
- F. Li, S. Zhang, X. Wang, X. Xue, H. Shen, "Vote- Based Clustering Algorithm in Mobile Ad Hoc Networks", In proceedings of International Conference on Networking Technologies, 2004.
- Zhang Jianwu, Zhang Lu "Research on Distance Measurement Based on RSSI of ZigBee" CCCM IEEE 2009.
- Neeraj Choudhary, Ajay K Sharma "Performance Evaluation of LR-WPAN for different Path-Loss M odels" International Journal of Computer Applications (0975 – 8887) Volume 7– No.10, October 2010.
- M. Joa-Ng and I.-T. Lu, "A Peer-to-Peer Zone-based 'ko-level Link State Routing for Mobile Ad Hoc Networks", IEEE Journal on Selected Areas in Communications, Aug. 1999, pp. 1415-1425.
- A.D. Amis, R. Prakash, T.H.P Vuong, D.T. Huynh. "Max-Min DCluster Formation in Wireless Ad Hoc Networks". In proceedings of IEEE Conference on Computer Communications (INFOCOM) Vol. 1.pp. 32-41, 2000.
- G. Chen, F. Nocetti, J. Gonzalez, and I. Stojmenovic, "Connectivity based k-hop clustering in wireless networks". Proceedings of the 35th Annual Hawaii International Conference on System Sciences. Vol. 7, pp. 188.3, 2002.
- T. Ohta, S. Inoue, and Y. Kakuda, "An Adaptive Multihop Clustering Scheme for Highly Mobile Ad Hoc Networks," in proceedings of 6th ISADS'03, Apr. 2003.
- P. Basu, N. Khan, and T. D. C. Little, "A Mobility Based Metric for Clustering in Mobile Ad Hoc Networks," in proceedings of IEEE ICDCSW' 01, pp. 413–18, Apr. 2001.
- A. B. MaDonald and T. F. Znati, "A Mobility-based Frame Work for Adaptive Clustering in Wireless Ad Hoc Networks," IEEE JSAC, vol. 17, pp. 1466–87, Aug. 1999.
- J.-H. Ryu, S. Song, and D.-H. Cho, "New Clustering Schemes for Energy Conservation in Two-Tiered Mobile Ad-Hoc Networks," in proceedings of IEEE ICC'01, vo1. 3, pp. 862–66, June 2001.
