Адаптивное выделение символов рукописного текста

Автор: Горошкин Антон Николаевич
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 1 (18), 2008 года.
Бесплатный доступ
Рассмотрен метод сегментации изображений рукописного текста на отдельные текстовые зоны. Описан метод сегментации текстовых зон на отдельные символы при помощи адаптивной процедуры подстройки выделяющей ячейки. Также рассмотрен метод определения угла поворота изображения.
Короткий адрес: https://sciup.org/148175633
IDR: 148175633 | УДК: 681.3
Adaptive allocation of symbols of the hand-written text
The method of hand-written text images segmentation on separate text zones is considered. The method of text zones segmentation on separate symbols with using adaptive procedure of allocating cell tuning is resulted. And also the method of image rotation angle definition is considered.
Текст научной статьи Адаптивное выделение символов рукописного текста
При распознавании рукописных символов на изображениях в статическом режиме (offline) важную роль занимает обнаружение зон, содержащих рукописные знаки, а также сегментация изображений зон на отдельные символы. Цля обнаружения зон очень часто используют метод гистограмм. Цля этого изображение последовательно сканируется построчно, при этом количество пикселей в строке суммируется и строится гистограмма. Затем производится анализ гистограммы на максимумы и минимумы. Максимальное значение показывает вероятное расположение строки, содержащей символы. Цан-ный подход эффективен в случае, если строки расположены горизонтально. Если же строки расположены не горизонтально, то необходимо многократное сканирование в различных направлениях и выбор такого направления, которое обеспечивало бы максимально выраженные максимумы и минимумы на полученной гистограмме. Это накладывает существенные вычислительные ограничения и требует больших ресурсов машинного времени и памяти. Автором предложен метод, основанный на обнаружении текстовых зон при помощи морфологической обработки с последующим обнаружением связанных областей. Кроме того, данный метод позволяет определить ориентацию входного изображения, что существенно упрощает процедуру распознавания, тем самым увеличивая эффективность системы распознавания, а также обеспечивает сегментацию изображений текстовых зон на отдельные изображения символов.
Метод обнаружения и сегментации текстовых зон условно можно разделить на следующие этапы (рис. 1):
-
- предварительную обработку (устранение шумов, бинаризация);
-
- морфологическую обработку (операции расширения и сжатия);
-
- обнаружение связанных областей и построение текстовых зон;
-
- определение угла поворота текстовых зон относительно горизонтального направления и поворот изображения;
-
- сегментацию полученных текстовых зон на отдельные символы при помощи адаптивной процедуры подстройки выделяющей ячейки.
Изображение входного документа подвергается предварительной обработке, где осуществляется наложение сглаживающих фильтров и последующая бинаризация изображения, после чего бинарное изображение подвергается морфологической обработке, при которой происходят последовательные операции расширения и сжатия. Цалее выполняется обнаружение связанных областей и построение текстовых зон. Затем осуществляется нормализация изображения, т. е. вычисляется угол поворота текстовых зон относительно горизонтального направления, а также средний угол поворота всего изображения входного документа, и происходит поворот изображения входного документа. Заключительным этапом является сегментация текстовых зон на отдельные символы при помощи адаптивной процедуры подстройки выделяющей ячейки. Рассмотрим каждый из этапов более подробно.
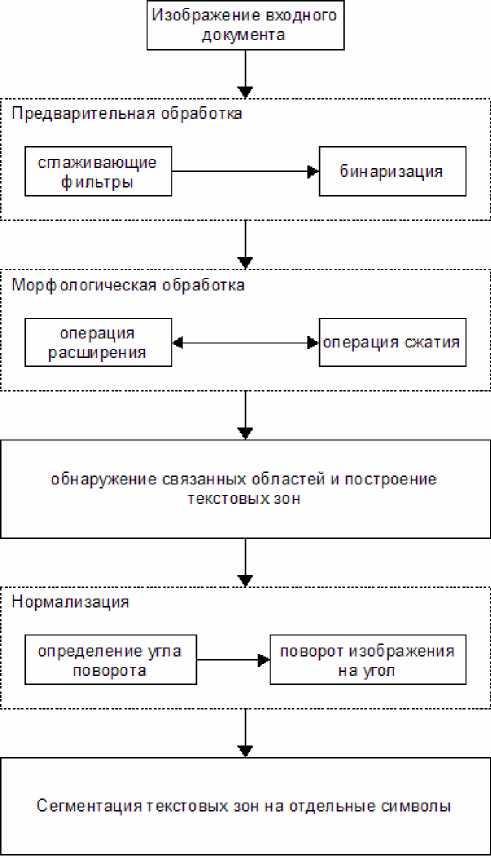
Рис. 1. Метод обнаружения и сегментации текстовых зон
На этапе предварительной обработки для устранения помех на изображении применяются различные методы фильтрации. Наиболее простыми являются сглаживающие фильтры: линейный и медианный. Линейный сглаживающий фильтр работает следующим образом: находится среднее арифметическое значение всех элементов рабочего окна изображения, после чего это среднее значение становится значением среднего элемента. Медианный фильтр основывается на нахождении медианы, т. е. среднего элемента последовательности в результате ее упорядочения по возрастанию (убыванию) и присваиванию найденного значения только среднему элементу Поскольку изображение с рукописными символами чаще всего представляет собой двухцветное изображение, то целесообразно преобразовать его к бинарному виду, чтобы в последующем можно было применить более простые методы морфологической обработки. Для приведения изображения к бинарному виду можно использовать ряд методов, к которым относятся метод преобразования на основе анализа гистограммы распределения яркости элементов изображения, метод бинаризации по площади и метод пороговой бинаризации. Авторам используется метод пороговой бинаризации, обладающий высоким быстродействием и в случае высококонтрастных изображений ничем не уступающий другим методам. При пороговой бинаризации присвоение значения выходному элементу выполняется по формуле
0, есЛи A ( i , j ) < P ,
1, если A(i, j) > P, где A(i,j) - значение яркости элемента исходного изображения; g(i, j) - значение бинарного изображения; Р - значение порога.
На этапе морфологической обработки осуществляется последовательное применение операции расширения и сжатия (рис. 2). В морфологических алгоритмах участвуют цифровые изображения, заданные функциями Кх,у) и Ъ(х,у), гдеф(х,у) - исходное изображение (рис. 2, а); Ъ(х,у) - изображение примитива. Тогда операция расши-рения/по Ъ определяется как
(f ® b)(s, t) = max{/(s-x, t-у) + +Ъ(x,у)|(s-x, t-у) е D , (х,у) е D Ъ }, где D f и D Ъ - области определений изображений/и Ъ соответственно; s и t - сдвиги координат по осям А и У. Аналогичным образом определяется операция сжатия/ по Ъ:
(f и Ъ)(s, t) - min{/(s+x,t+у)-
-Ъ(х,у) | (s+х, t+у)G D / ;(x,у)е D Ъ }, где D f и D Ъ - области определений изображений / и Ъ соответственно; s и t - сдвиги координат по осямАи У.
В качестве изображений примитива в операции расширения предлагается использовать маски аппертурой 3 х 5, 3 х 7 и выше, представляющие собой матрицы, состоящие из единиц, в результате чего контуры символов, стоящие близко друг к другу, будут связаны в общий контур и тем самым получится зона, содержащая текст. Далее применяется операция сжатия, обеспечивающая сглаживание внешних краев связанных областей (рис. 2, б). В качестве примитива берется маска апертурой 3 х 3. Эти операции могут осуществляться последовательно несколько раз для более эффективного слияния в общие области, выбираемого эмпирическим путем для соответствующих примитивов операций. Так, например, тестирование показывает, что для маски аппертурой 3 х 5 необходимо выполнить в среднем 3 операции расширения и сжатия, а для маски аппертурой 3 х 7 достаточно 1-2 операций, после чего осуществляется сканирование изображения и маркировка областей принадлежащих связанным областям с учетом окружающих маркеров (рис. 2, в). В качестве окружающих маркеров рассматривается маркер вышестоящего пикселя и пикселя слева. Если выше стоящий пиксель имеет маркер, то текущий пиксель при сканировании изображения маркируется аналогичным маркером. В противном случае текущий пиксель маркируется маркером, который имеет левый от текущего пиксель. Если же левый пиксель не имеет маркера, то текущий пиксель маркируется следующим номером маркера. На основании полученных маркеров строится таблица связности маркированных областей. В нашем случае при сканировании изображения и установке маркеров определяется связность областей с одинаковыми маркерами и осуществляется связывание маркированных областей в общую текстовую зону с пометкой данной зоны индексом (рис. 2, г).
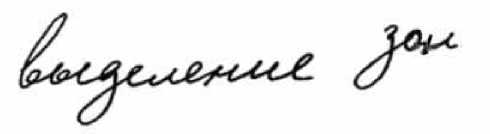
а

б


Рис. 2. Построение общих текстовых зон: а - исходное изображение; б - выделение изображений зон; в - маркировка областей; г - связывание областей
в текстовые зоны
Предположим, что строки текстовых символов расположены параллельно друг другу (максимальный угол отклонения - около Зе). В данном случае можно определить средний угол наклона текстовых зон относительно горизонтальной линии и таким образом вычислить угол поворота всего изображения, что обеспечит более качественную сегментацию текстовых зон на отдельные символы. Для этого вычисляются центры масс изображений текстовых зон и дальних отстоящих точек и вычисляются углы поворота изображений текстовых зон:
Alfa. = atan((y.m yU.p - xf)f где Alfa. - угол поворота i-й текстовой зоны; х т, у. - координаты дальней отстоящей точки i-й текстовой зоны; х.с, у.с - координаты точки центра масс i-й текстовой зоны. Соответственно угол поворота всего изображения находится по среднеарифметическому углов текстовых зон:
Alfa = "SAlfa. I n, где Alfa - угол поворота изображения^^. - угол поворота .-й текстовой зоны; n - общее число текстовых зон.
Таким образом определяются зоны, содержащие текст и угол поворота изображения. Затем изображение поворачивается на вычисленный угол и найденные зоны выделяются прямоугольной областью. Происходит наложение этих областей на первоначальное изображение и осуществляется сегментация выделенных текстовых зон, для чего изображение подвергается повторной морфологической обработке с целью выделения возможного ядра каждого символа в группе символов. Для этого зона, содержащая большую часть изображения текстовых символов, делится на две части средней горизонтальной линией (рис. З). Изображения верхней и нижней части зоны подвергаются морфологической процедуре расширения с примитивами размерности З X З (рис. 4).

Рис. З. Операция расширения для групп символов: а - исходное изображение; б - после операции расширения
|
0 |
1 |
0 |
|
0 |
0 |
0 |
|
0 |
0 |
0 |
|
0 |
0 |
0 |
|
0 |
0 |
0 |
|
0 |
1 |
0 |
a б
Рис. 4. Примитивы морфологической операции расширения: а - для верхней части зоны; б - для нижней части зоны
В результате такой процедуры получается расширенное изображение группы символов, в которых внутренние области символов наиболее насыщены (ядра), при этом межсимвольные расстояния остаются практически неизменными (рис. 5). Затем среди информативных зон ищутся самые наименьшие зоны (предположительно одиночные символы союзов и предлогов) и вычисляется среднее значение размера ячейки для нескольких типов символов (строчные, прописные и строчные с хвостиком: «в», «б», «д», «у» и т. д.). Далее на оставшиеся группы символов накладывается полученная выделяющая ячейка. По умолчанию накладывается ячейка для строчного типа символов, так как данные символы, как правило, составляют большую часть документа.
Предположим, что написание текста идет слева направо. В этом случае для определения границы символа на правой границе выделяющей ячейки ищется локальный минимум плотности точек изображения текстовых символов (на рис. 5 большим прямоугольником показана выделяющая ячейка, меньшим прямоугольником выделена область, внутри которой ищется локальный минимум плотности точек изображения).
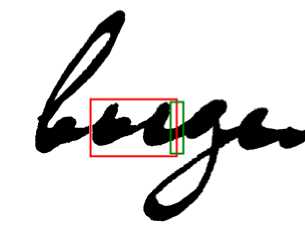
Рис. 5. Сегментация текстовых зон
Пусть IM(i, у") - изображение группы символов, где i = 1,2, ...,HG;j = 1,2, ..., WG, здесь HG - высота группы символов, WG - ширина группы символов. Вычислим массив средних значений яркости пиксельных столбцов в изображении группы символов:
SG_COL(j/) -sum(IM(i,/)) I HG, где i = 1,2, ...,HG.
Далее в этом массиве найдем номера столбцов, которые входят в текущую область на правой границе выделяющей ячейки и для которых значения элементов мас сива минимальны. Сделаем предположение о том, что эти столбцы представляют собой местоположение связующего символы элемента и происходит коррекция выделяющей ячейки до этого местоположения, а также закраска цветом фона границы выделяющей ячейки. В результате получаются новые параметры выделяющей ячейки, которые заносятся в таблицу для дальнейших операций, и происходит сегментация изображения текстовых зон на отдельные зоны содержащие символы. Последующие параметры выделяющей ячейки (длина, ширина) выбираются как средние между всеми параметрами ячеек, занесенных в таблицу Таким образом происходит сегментация изображений групп символов на отдельные символы и получается набор сегментированных изображений, которые в дальнейшем могут быть использованы в системе распознавания.
Предложенный выше метод адаптивного выделения символов рукописного текста может эффективно применяться в различного рода системах распознавания и анализа документов, содержащих изображения рукописных символов и текста. Кроме того, этот метод позволяет осуществлять определение угла поворота изображения документа и тем самым обеспечивать дополнительную коррекцию изображения. В настоящее время ведется апробация метода в составе автоматизированного комплекса распознавания документов, содержащих рукописные символы и текст.
ADAPTIVE ALLOCATION OF SYMBOLS OF THE HAND-WRITTEN TEXT
The method of hand-written text images segmentation on separate text zones is considered. The method of text zones segmentation on separate symbols with using adaptive procedure of allocating cell tuning is resulted. And also the method of image rotation angle definition is considered.
