Адаптивный нечёткий алгоритм кэширования для прокси-серверов

Автор: Жуков Александр Игоревич
Журнал: Advanced Engineering Research (Rostov-on-Don) @vestnik-donstu
Рубрика: Технические науки
Статья в выпуске: 8 (69) т.12, 2012 года.
Бесплатный доступ
Рассматривается проблема увеличения эффективности кэш-систем за счёт использования методов искусственного интеллекта. Приведена формализованная постановка задачи повышения эффективности систем кэширования с использованием теоретико-множественного математического аппарата. Рассмотрена технология применения системы нечёткого вывода для определения объекта-жертвы, реализующая вычисление кэш-рейтинга объектов, сохранённых в кэш-памяти. В качестве одной из базовых характеристик web-ресурса, подаваемых на вход системы нечёткого вывода, впервые предложено использовать его пространственную локальность, определение которой основано на унифицированном идентификаторе web-ресурса URI. Определён способ выполнения адаптации нечёткой системы посредством синтеза лингвистической модели с использованием метода нечёткой кластеризации, а также приведены результаты экспериментального исследования разработанного алгоритма на имитационном стенде для трасс, полученных с использованием кэширующего прокси-сервера Squid.
Кэш-система, система нечёткого вывода, нечёткая кластеризация, адаптивная система кэширования
Короткий адрес: https://sciup.org/14249942
IDR: 14249942 | УДК: 004.65
Adaptive fuzzy caching algorithm for proxy servers
The problem of increasing the efficiency of cache systems using artificial intelligence techniques is considered. The formalized statement of raising the cache effectiveness on the basis of the set-theoretic mathematical tools is described. The fuzzy logic application technology for determining the victim which implements the calculation of cache values for object in cache memory is considered. It is first offered to use spatial locality of the web-resource as one of its basic characteristics applying to the input of the fuzzy logic system. The definition of this characteristic is based on the uniform resource identifier URI. The technique for the adaptation of fuzzy systems through the synthesis of the linguistic model using the method of fuzzy clustering is defined. Besides, the experimental study of the algorithm developed on the simulation stand for traces obtained through the proxy cache Squid is resulted.
Текст научной статьи Адаптивный нечёткий алгоритм кэширования для прокси-серверов
Введение. Растущая популярность web-технологий и Интернета позволили пользователям всего мира обмениваться большим числом данных, среди которых: страницы с электронным контентом, фото и видео материалы, документы различных форматов и размеров. Ещё в 1999 году размер файла в пятьдесят мегабайт назывался исследователями web-систем и прокси-серверов «экстремально большим» («extremely large object») [1], а сегодня ежедневно пользователи имеют возможность скачивать с различных серверов фильмы, размер каждого из которых составляет несколько гигабайт. Увеличение быстродействия web-систем, несомненно, связано с увеличением производительности аппаратного обеспечения, ростом числа серверов в глобальной паутине, появлением новых web-технологий и совершенствованием протоколов передачи данных. Однако человеческая природа постоянно требует всё более скоростных методов доступа к информации с меньшими временными задержками. В этом смысле использование кэширования в web-системах является одним из способов увеличения производительности, который, благодаря универсальности, может быть применён на различных уровнях функционирования web-систем [2, 3].
Одно из важнейших звеньев в реализации запроса конечного пользователя к оригинальному web-серверу с данными — это кэширующий прокси-сервер, предназначенный для выполнения косвенных запросов клиентов к другим серверам или сетевым службам. Применение кэширования на прокси-сервере позволяет [4]:
-
е увеличить производительность серверов, функционирующих в рамках сетевой информационной системы, так как кэш-система будет удовлетворять часть запросов и в результате сервер сможет обслуживать большее число запросов в единицу времени;
-
е уменьшить среднее значение времени ожидания пользователем запрошенных данных;
-
е уменьшить нагрузку на локальные и глобальные сети за счёт применения кэширования на локальных уровнях;
-
• перераспределить нагрузку между различными центрами обработки информации единой системы за счёт перенаправления кэш-запросов на системы с меньшей загрузкой.
Ключевым звеном системы кэширования является алгоритм кэширования, который на базе явно или неявно представленного кэш-рейтинга объектов системы определяет, какие объекты должны быть вытеснены из кэш-памяти при её переполнении. Вытесняемый из кэш-памяти объект, т. е. объект с минимальным рейтингом, называют жертвой. Определение жертвы — задача стратегии замещения.
В последнее время наблюдается рост популярности применения известных технологий и методов искусственного интеллекта в различных прикладных задачах [5]. В работах [6, 7] представлено семейство нечётких алгоритмов замещения (англ, fuzzy algorithm replacement), разработанных для применения в системах web-кэширования. Несмотря на нашедшую отражение в этих работах эффективность нечётких стратегий, представленные алгоритмы имеют существенные недостатки:
-
• необходимость предварительного анализа потока запросов к кэш-системе для формирования базы правил;
-
• невозможность адаптации кэш-системы к изменениям законов распределения вероятностей доступа к объектам, происходящим в трассе.
В данной работе определён метод разработки адаптивной системы кэширования на базе нечёткой стратегии замещения с использованием системы нечёткого вывода (СНВ), а также модуля адаптации на базе нечёткой кластеризации для синтеза лингвистической модели. Постановка задачи. Сформулируем математическую постановку решаемой научной задачи. Для этого введём в рассмотрение некоторые понятия.
Пусть R— множество алгоритмов кэширования (англ, replacement algorithm')-.
R -lA A A *
где А,— представляет Ай алгоритм из множества R, определённый в соответствии с математической моделью абстрактной одноуровневой кэш-системы [8]; г — мощность множества R, т. е. число алгоритмов принадлежащих множеству (г = |/?|).
Пусть та(М,1,Т^ — случайная функция, результатом которой является случайная трасса со, соответствующая модели потока запросов [8] и составленная из Т идентификаторов г, объектов системы (г, е /V), полученных начиная с момента времени t.
to = ^rvr7,...,rT^
В общем случае со является элементарным исходом случайного процесса и принадлежит пространству элементарных событий Пг (coeQ^), которое включено в Т-ую Декартову степень множества идентификаторов объектов системы:
Пг <^NT,
где /V— множество идентификаторов объектов системы.
Введём в рассмотрение отображение ф, определяющее случайное положительное рациональное число р, которое представляет значение рейтинга кэш-попаданий (англ, hit-ratio"), полученное для кэш-памяти объёма М, с использованием алгоритма кэширования Д и случайной трассы длинной Т, полученной для множества идентификаторов объектов системы /V, начиная с момента времени t.
ф(ДЛ,тп(/УД,Т)) = р, ф : R х N х £1Т -> R+,
где R— множество алгоритмов кэширования (1); Пг — множество случайных трасс длины Т; № — множество натуральных чисел; IR+ — множество положительных рациональных чисел.
В общем случае требуется реализовать такой алгоритм кэширования А, который в среднем обеспечивает наибольший рейтинг кэш-попаданий для заданного объёма кэш-памяти, множества объектов системы и их идентификаторов, на всех трассах длинны Т, т. е. решить задачу стохастического программирования с моделью ожидаемого среднего значения {expected value model — EVM) [9]:
maxEU(A,M,^(N,t,TA\\, (6)
где E (•) — операция нахождения среднего значения.
Адаптивный нечёткий алгоритм кэширования. Вычисление кэш-рейтингов объектов в системе кэширования на базе нечёткой логики основано на системе нечёткого вывода (СНВ), структура которой представлена ниже (рис. 1).
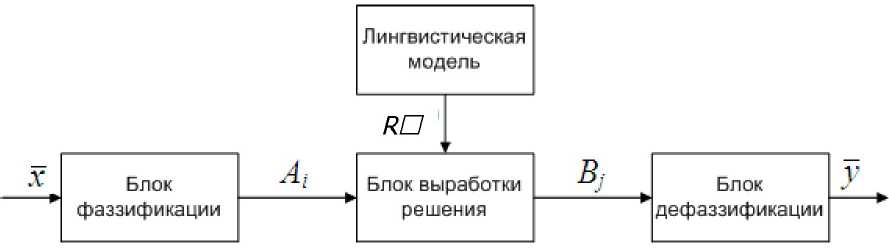
Рис. 1. Структурная схема системы нечёткого вывода
На схеме представлены следующие модули СНВ:
-
• блок фаззификации (англ, fuzzification), предназначенный для перевода параметров расчёта, представленных вектором чётких чисел х, в нечёткие множества Ддля последующего использования в блоке вывода;
-
• блок дефаззификации, применяемый для перевода полученных нечётких множеств В, в вектор чётких значений выходных данных у;
-
• лингвистическая модель или база правил, представляющая множество правил нечетких продукций, с посылкой (А) и следствием (В) [5]:
Rw ■. Ak ^ Bk, k = V,(7)
где г— число нечётких правил; к— номер правила; Ак и 5^— нечёткие множества такие, что:
Ак = Акх А^х ...х Ак АксХ;,(8)
Вк =Вк хВк х...хВк В^У,,(9)
где Хи Y— пространство входных и выходных переменных, при этом / = 1,л, j = l,m;
-
• блок выработки решения (блок вывода), который формирует с использованием заданной базы правил на своём выходе одно или несколько нечётких множеств В, применив полученные на вход нечёткие множества А, при этом используется следующая последовательность шагов:
-
1. Агрегирование условий, составляющих посылку правила;
-
2. Активизация заключений, составляющих следствие правила;
-
3. Аккумуляция следствия — получение нечёткого множества (или множеств) представляющего следствие.
Рассмотрим реализацию СНВ для использования в качестве модуля расчёта кэш-рейтингов объектов в алгоритме кэширования, применяемом для web-прокси серверов. На вход СНВ подаются значения характеристик объекта системы, на выходе получаем кэш-рейтинг объекта. Используются известные характеристики объекта в трассе: дистанция последнего доступа, популярность за последнее время (частота доступов), размер объекта. Кроме того, в качестве входного параметра впервые предлагается использовать характеристику пространственной локальности web-pecypca.
В традиционном смысле пространственная локальность применяется при кэшировании программных инструкций в оперативной памяти, когда близкими являются инструкции расположенные в одном блоке. Если общее информационное пространство web-среды рассматривать как единое множество адресов, то близкими с точки зрения пространственной локальности можно называть ресурсы, расположенные на одном web-сервере (либо в одной локальной сети, либо на одном прокси-сервере и т. д., в зависимости от решаемой задачи). При этом мера близости двух web-ресурсов в самом простом случае может быть установлена с использованием унифицированных идентификаторов этих ресурсов (англ. Uniform Resource Identifier, URI)\ например, все ресурсы, расположенные на одном доменном имени являются близкими. При этом далёкими по отношению к ним называются остальные ресурсы. Таким образом, мера близости двух web-ресурсов представляется функцией:
м(^,х2)
О, и далек от их
1, и близок к и
(Ю)
где xi и х2 — численные идентификаторы web-ресурсов, как объектов системы; и и иХг — URI web-ресурсов с идентификаторами xi и хг.
Суть описываемой ситуации заключается в том, что обращение пользователя к некоторому информационному контенту web-сайта, как правило, влечёт за собой несколько параллельных асинхронных запросов к web-серверу на предоставление такой информации, как изображения, js-скрипты, таблицы стилей css и т. д. Таким образом, запрос данных с сервера подразумевает выполнение множественных запросов на получение объектов из множества близких ресурсов, а значит, кэш-рейтинги этих ресурсов должны быть повышены.
Для применения данного свойства в реальной системе кэширования требуется его характеризовать численным образом. Для этого введём в рассмотрение кортеж с LRU-организацией Duri, составленный из адресов доменов, к которым принадлежат ресурсы, запрашиваемые в трассе:
D . = (d1,d,...d ),
(И)
un \vVM2 мn ) *
где d— доменное имя; i— позиция имени в кортеже.
Позиция имени в кортеже характеризует новизну обращений к ресурсам данного домена: на первой позиции расположено имя, к ресурсу которого было последнее обращение, т. е. позиция в кортеже Duri представляет дистанцию последнего обращения к ресурсам соответствующего доменного имени.
Таким образом, на вход блока фаззификации поступают следующие значения:
е дистанция последнего обращения к объекту в трассе (OD — object distance), характеризующая свойство новизны — число позиций в трассе (либо число секунд) до предыдущего обращения к объекту, а если обращение к объекту первое в трассе, то OD = -1;
-
• популярность объекта {OP— object popularity) — число обращений к объекту;
-
• размер объекта (OS — object size) — размер объекта в заданных единицах информации (например, в байтах);
е характеристику пространственной локальности объекта (SL — spatial locality), которая представлена позицией домена web-pecypca в кортеже Duri, а если домен в кортеже ещё не представлен, то SL = -1.
Для каждого представленного значения выполняется операция фаззификации типа «синглтон» [5]. Полученные нечёткие множества подаются в блок вывода, на выходе которого регистрируется одно нечёткое множество, характеризующее значимость объекта для кэш-системы.
После дефаззификации данного нечёткого множества по методу центра тяжести, на выходе СНВ получаем кэш-рейтинг объекта.
Ключевым звеном описанной нечёткой системы, определяющим её функционирование, является лингвистическая модель, представленная множеством нечётких правил, которые в описанных ранее кэш-системах на базе СНВ определялись аналитически на базе известных участков трасс [6, 7]. Разработанный алгоритм реализует метод синтеза нечётких правил по результатам выполнения нечёткой кластеризации за счёт изменения функций принадлежности нечётких множеств, входящих в посылку правила [10]. Таким образом, представленный алгоритм кэширования на базе нечёткой логики адаптируется к изменяющимся характеристикам трассы.
Для получения входных данных процедуры кластеризации подаваемая на вход трасса объектов разбивается на участки. На каждом участке производится вычисление следующих характеристик объектов:
-
• оценка математического ожидания дистанции объекта (OD) на участке трассы;
-
• число обращений к объекту (О/3) на участке;
-
• размер объекта (05);
е оценка математического ожидания дистанции обращения к ресурсам домена (52.) на участке.
При этом учитываются только те объекты, число обращений к которым на участке больше некоторого заданного порогового значения Tfuzzy (JfUZZy > 1). Полученные данные объединяются в векторы, подаваемые в качестве входных в процедуру кластеризации:
— (х х х х х \ где xi — оценка математического ожидания дистанции объекта на участке t, хг — число обращений к объекту на участке t, х3 — размер объекта; Х\ — оценка математического ожидания дистанции обращения к ресурсам домена на участке t, х3 — число обращений на участке t+ 1.
Для получения кластеров из множества полученных векторов используется алгоритм нечётких с-средних (англ. Fuzzy C-Means) [5]. При этом число кластеров устанавливается соответствующим числу желаемых правил нечётких продукций, синтез которых осуществляется по следующим правилам:
-
• х^, хг, х3, Х\ — представляют посылку правила, х5 — следствие правила;
-
• в качестве заключения правила выбирается центр соответствующего кластера;
-
• функции принадлежности нечётких множеств, входящих в посылку и следствие нечёткого правила, продуцируются путём проецирования степеней принадлежности соответствующего кластера на входные переменные [10].
Полученные таким образом нечёткие правила применяются в качестве базы СНВ. Число участков трассы, после которых выполняется адаптация, и размер участка являются параметрами представленного нечёткого алгоритма.
Результаты имитационного моделирования. Исследования проводились с применением имитационного моделирования на разработанном программном стенде [И]. Для проведения исследований был выбран метод событийно-регулируемого управления моделированием (англ, trace-driven simulation), а в качестве входных данных подавались трассы с прокси-сервера Донского государственного технического университета, использующего в качестве программного обеспечения популярный кэширующий сервер Squid. Трассы получены на основе журналов работы Squid в период: март-май, июль-август 2012 года. При этом для проведения экспериментов все трассы были приведены к одинаковому размеру и в них оставлены только те обращения к web-ресурсам, которые могут кэшироваться прокси-сервером. Усреднённые статистические характеристики используемых реальных трасс представлены в таблице 1.
Таблица 1
Усреднённые параметры реальных трасс, используемых в исследованиях
|
Параметр |
Значение |
|
длина трассы |
1.000.000 |
|
% числа объектов, запрошенных единожды |
73,03 % ± 3 % |
|
% трафика объектов, запрошенных единожды |
65,70 % ± 3 % |
|
средний размер объекта |
18 Кб |
|
максимальный размер объекта |
68679 Кб |
|
минимальный размер объекта |
1 Кб |
|
общий размер трафика |
10,72 Гб |
При проведении экспериментов размер кэш-памяти варьировался в пределах от 10 Мб до 300 Мб. Результаты проведённых экспериментов приведены ниже (рис. 2, табл. 2).
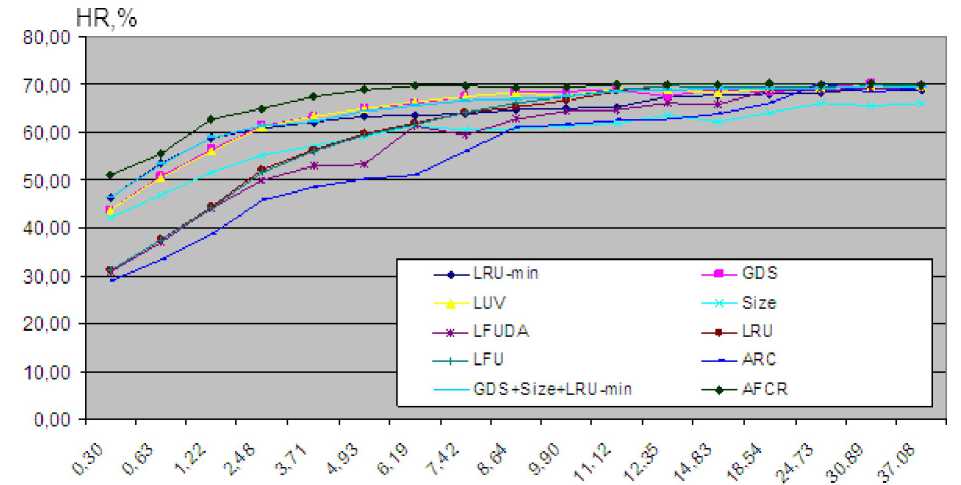
относительный объём кэш-памяти, %
Рис. 2. Динамика изменения эффективности стратегий замещения на реальных трассах для объектов, запрошенных более одного раза
Таблица 2
Сравнение стратегий замещения на реальных трассах для объектов запрошенных более одного раза
|
LFU |
LRU |
Size |
LFU DA |
LRU-min |
CDS |
LUV |
ARC |
AFCR |
|
|
HR |
60,350 |
60,347 |
59,201 |
58,209 |
62,288 |
63,492 |
63,355 |
58,236 |
68,031 |
|
BHR |
25,139 |
26,363 |
26,845 |
22,358 |
25,213 |
24,101 |
25,213 |
24,842 |
27,809 |
Выводы. Разработанная специально для прокси-серверов адаптивная нечёткая стратегия замещения AFCR на имитационном стенде показала превышение значений рейтинга кэш-попаданий, как основного критерия эффективности алгоритмов кэширования, известных стратегий замещения в среднем на 8 % и с вероятностью 0,95 не менее, чем на 5 %.
Список литературы Адаптивный нечёткий алгоритм кэширования для прокси-серверов
- Arlitt, M. F. Performance Evaluation of Web Proxy Cache Replacement Policies/Martin Arlitt, Rich Friedrich, Tai Jin//Internet Systems and Applications Laboratory. -October, 1999.
- Danzig, P. B. A Case for Caching File Objects Inside Internetworks/Peter B. Danzig, Richard S. Hall, Michael F. Schwartz//ACM SIGCOMM Computer Communication Review. -Volume 23. -Issue 4. -1993.
- Yang, Q. Web-Log Mining for Predictive Web Caching./Q. Yang, and H. H. Zhang//IEEE Transactions on Knowledge and Data Engineering. -2003. -Volume 15. -Number 4.
- Жуков, А. И. Использование информационных систем и технологий в целях удовлетворения информационных потребностей/А. И. Жуков, А. Г. Сорокин. -Красноярск: Научно-инновационный центр, 2012. -68 с.
- Рутковский, Л. Методы и технологии искусственного интеллекта/Л. Рутковский; [перевод с польского И. Д. Рудинского]. -Москва: Горячая линия -Телеком, 2010. -520 с.
- Calzarossa, M. C. A Fuzzy Algorithm for Web Caching [Электронный ресурс]/Maria Carla Calzarossa, Giacomo Valli. -Режим доступа: http://peg.unipv.it/publications/PDF/Proxy.pdf (дата обращения: 12.11.2012).
- Sabeghi, M. Using Fuzzy Logic to Improve Cache Replacement Decisions/Mojtaba Sabeghi, and Mohammad Hossein Yaghmaee//IJCSNS International Journal of Computer Science and Network Security. -2006. -Volume 6. -No. 3.
- Жуков, А. И. Модель адаптивного векторного управления стохастическим гибридным алгоритмом кэширования/А. И. Жуков//Вестник Донского гос. техн. ун-та. -2012. -№ 5. -С. 19-29.
- Лю, Б. Теория и практика неопределённого программирования/Б. Лю. -Москва: БИНОМ. Лаборатория знаний, 2005. -416 с.
- Штовба, С. Д. Введение в теорию нечётких множеств и нечёткую логику/С. Д. Штовба. -Винница: Континент-Прим, 2003. -198 c.
- Жуков, А. И. Программный стенд для исследования эффективности алгоритмов кэширования/А. И. Жуков//Системный анализ, управление и обработка информации: Труды 1-го Международного семинара студентов, аспирантов и учёных. -Ростов-на-Дону: ИЦ ДГТУ, 2010. -С. 249-253.
