Алгоритмы оптимизации данных в облачных системах

Автор: М. А. Войтенко, Н. А. Третьяк, А. А. Ковтун
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 5 (4), 2025 года.
Бесплатный доступ
Статья посвящена анализу алгоритмов оптимизации данных в облачных системах, которые работают в условиях роста объёмов информации и необходимости поддержания высокой производительности распределённых платформ. Рассматриваются особенности облачных вычислений, определяющие требования к алгоритмам хранения, передачи и обработки данных, включая масштабируемость, устойчивость к сбоям, минимизацию сетевых и вычислительных затрат, а также энергоэффективность. В работе подробно описаны существующие подходы, применяемые в современных облачных инфраструктурах: модель MapReduce для параллельной обработки больших данных, алгоритмы балансировки нагрузки Round Robin и Least Connections, механизмы репликации и коррекции ошибок, а также методы машинного обучения, используемые для прогнозирования нагрузки и интеллектуальной маршрутизации. Показаны преимущества и ограничения каждого подхода, связанные с сетевыми задержками, затратами на избыточность, сложностью миграции между провайдерами и недостаточной адаптивностью традиционных механизмов. В практической части предложен гибридный алгоритм балансировки нагрузки, сочетающий аналитические метрики и прогнозирование с использованием модели линейной регрессии. Представленный фрагмент реализации демонстрирует сбор данных, обучение модели и выбор оптимального узла для распределения запросов. Сформулированы перспективные направления развития: переход к обработке данных в реальном времени, интеграция ML-моделей в планировщики ресурсов, использование аппаратных ускорителей и стандартизация интерфейсов. Результаты работы подчёркивают необходимость дальнейшего совершенствования алгоритмов для повышения эффективности и устойчивости облачных систем.
Облачные системы, распределённая обработка данных, алгоритмы балансировки нагрузки, MapReduce, репликация и устойчивость данных, оптимизация ресурсов, машинное обучение в облачных системах
Короткий адрес: https://sciup.org/14135234
IDR: 14135234 | DOI: 10.47813/2782-2818-2025-5-4-2081-2092
Текст статьи Алгоритмы оптимизации данных в облачных системах
DOI:
Рост объёмов данных, поступающих от вебсервисов, корпоративных систем и потоковых приложений, приводит к повышению требований к инфраструктуре хранения и обработки информации. Актуальность исследования обусловлена тем, что традиционные централизованные архитектуры не обеспечивают необходимого уровня масштабируемости: при увеличении нагрузки возрастает время отклика, снижается пропускная способность и повышается риск отказов. На этом фоне облачные вычисления становятся ключевой технологией, позволяющей распределять ресурсы между узлами и автоматически адаптировать их под текущие запросы [1].
В научной и прикладной литературе значительное внимание уделяется методам распределённой обработки данных, алгоритмам репликации и механизмам балансировки нагрузки [2, 3]. Наиболее изученными решениями являются модель MapReduce, методы многократного копирования данных и предиктивные подходы, опирающиеся на анализ нагрузки. Однако существующие исследования отмечают ограничения таких методов: межузловые задержки на этапе передачи данных, рост затрат на поддержание копий и снижение эффективности стандартных алгоритмов распределения нагрузки при динамически изменяющихся профилях запросов [4, 5].
Проблема исследования заключается в том, что современные алгоритмы оптимизации данных в облачных системах недостаточно эффективно справляются с задержками межсерверного обмена, высокими затратами хранения и необходимостью адаптивного управления ресурсами при изменяющейся нагрузке.
Цель работы – проанализировать существующие алгоритмы обработки и хранения данных в облачных системах и определить направления их совершенствования для повышения производительности, устойчивости и экономичности распределённых платформ.
Для достижения цели решаются следующие задачи:
-
• определить особенности облачных
вычислений, влияющие на требования к алгоритмам оптимизации данных;
-
• провести анализ существующих алгоритмов распределённой обработки, балансировки нагрузки и обеспечения устойчивости хранения;
-
• выделить их ключевые преимущества и
- ограничения;
-
• предложить подходы к улучшению
эффективности работы облачных систем на основе адаптивных и предиктивных механизмов.
МАТЕРИАЛЫ И МЕТОДЫ
Облачные вычисления и их особенности
Облачные вычисления представляют собой модель распределённой обработки данных, при которой вычислительные ресурсы, хранилища и сетевые сервисы предоставляются пользователям удалённо через интернет. Вычисления выполняются в центрах обработки данных провайдера провайдера, а пользователи получают доступ к виртуализованным ресурсам, которые можно быстро масштабировать в зависимости от нагрузки.
Основой развития облачных систем стали виртуализация и высокоскоростные сети, позволившие запускать множество изолированных виртуальных машин на одном сервере и обеспечивать приемлемые задержки при удалённой работе.
Облака отличаются по способу развертывания: публичные предоставляют масштабируемые ресурсы внешним пользователям, частные дают больший контроль над данными, гибридные комбинируют оба подхода. По уровню услуг выделяются модели IaaS, PaaS и SaaS, различающиеся объёмом предоставляемой инфраструктуры [1].
Согласно NIST, облачные платформы характеризуются самообслуживанием, широким сетевым доступом, объединением ресурсов, быстрым масштабированием и измеримостью. Эти свойства позволяют гибко распределять вычислительную мощность и контролировать использование ресурсов [6].
Основные ограничения облачных систем связаны с сетевыми задержками при передаче данных, риском перегрузки узлов, необходимостью надёжного восстановления после отказов, а также сложностями безопасности и миграции между разными провайдерами.
Требования к алгоритмам оптимизации
ДАННЫХ В ОБЛАЧНЫХ СРЕДАХ
Алгоритмы оптимизации данных в облачных системах должны учитывать распределённый характер инфраструктуры, где узлы могут добавляться, выходить из строя и работать под разной нагрузкой. В таких условиях алгоритм обязан сохранять корректность работы и стабильное время отклика при изменении числа серверов, объёма данных и интенсивности запросов.
К ключевым требованиям относится масштабируемость: увеличение объёма данных или узлов не должно приводить к росту задержек и появлению узких мест, поскольку это снижает производительность систем распределения нагрузки, хранения и обработки [7].
Не менее важна устойчивость к сбоям. Алгоритм должен обеспечивать сохранность данных и доступность сервисов при отказах узлов или сетевых компонентов, используя репликацию, журналы операций, коды коррекции ошибок и автоматическое восстановление без заметного увеличения задержек и нарушения согласованности [8, 9].
В условиях переменной нагрузки алгоритмы обязаны динамически перераспределять ресурсы, а именно вычислительную мощность, память и пропускную способность сети. Это предотвращает перегрузку узлов и стабилизирует время отклика приложений.
Минимизация сетевых и вычислительных затрат также критична: межузловая передача данных является одной из самых дорогих операций, поэтому алгоритмы должны сокращать трафик, выполнять больше вычислений локально и избегать лишних взаимодействий между серверами.
Кроме того, алгоритмы должны учитывать энергоэффективность, снижая количество активно работающих узлов и поддерживая оптимальную загрузку серверов, что уменьшает эксплуатационные расходы дата-центров.
Таким образом, алгоритмы оптимизации данных должны обеспечивать масштабируемость, устойчивость к сбоям, низкие сетевые и вычислительные затраты и рациональное использование ресурсов, что необходимо для стабильной работы распределённых систем при росте объёмов данных и изменяющейся нагрузке.
Описание и анализ существующих
АЛГОРИТМОВ В ОБЛАЧНЫХ СИСТЕМАХ
Современные облачные системы опираются на специализированные алгоритмы, которые обеспечивают масштабируемую обработку данных, устойчивость хранилищ и равномерное распределение нагрузки между узлами. Одним из ключевых направлений остаётся распределённая обработка, наиболее известной моделью которой является MapReduce. Она позволяет автоматически распараллеливать выполнение задач, что особенно важно при работе с крупными наборами данных [10].
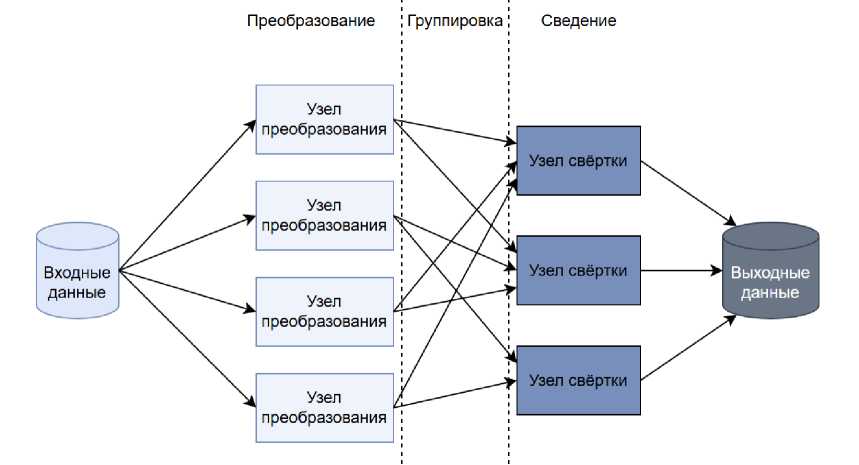
Рисунок 1. Схема алгоритма M AP R EDUCE .
Figure 1. MapReduce algorithm schematic.
Принцип работы MapReduce (рис. 1) основан на последовательности этапов map, shuffle и reduce. Входной набор данных предварительно разбивается на логические блоки распределённой файловой системы, и каждая map-задача назначается на тот узел, где физически хранится соответствующий блок. Это уменьшает количество межсерверных передач. На этапе map узел считывает блок, преобразует записи в пары «ключ–значение» и сохраняет отсортированные промежуточные данные. После завершения всех операций map начинается стадия shuffle, в ходе которой узлы определяют, какой reduce-сервер должен обработать конкретный ключ, и передают ему соответствующие группы данных. Reduce-узлы загружают полученные фрагменты, повторно их сортируют и выполняют операцию свёртки значений одного ключа, формируя итоговый результат, сохраняемый обратно в распределённую файловую систему. При сбоях механизм автоматически перезапускает задачи на других узлах.
Основным преимуществом MapReduce является масштабируемость: увеличение числа узлов действительно сокращает время выполнения за счёт независимости операций map. Однако эффективность ограничивается стадией shuffle, на которой возникает значительный сетевой трафик и рост задержек [10]. Таким образом, модель хорошо работает при больших объёмах данных, но остаётся чувствительной к межузловым задержкам.
Балансировка нагрузки обеспечивает равномерное распределение запросов между серверами. Простейший метод – Round Robin (рис. 2), работающий по принципу циклического обхода списка серверов: каждый новый запрос направляется следующему узлу [11].
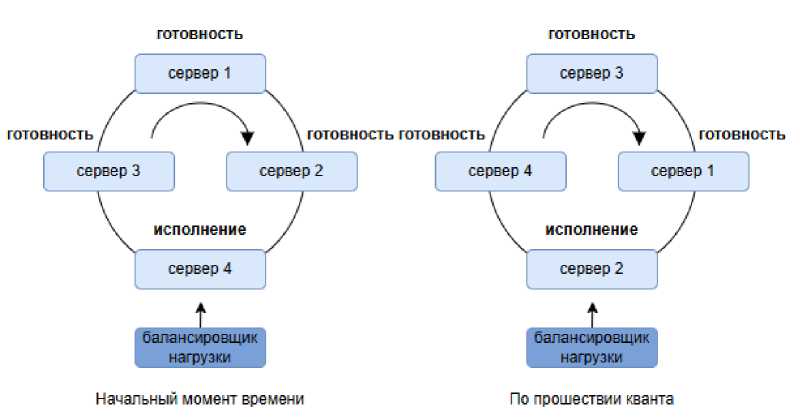
Рисунок 2. Схема алгоритма R OUND R OBIN .
Figure 2. Round Robin algorithm schematic.
Такой алгоритм не создаёт вычислительной нагрузки и работает предсказуемо, однако не учитывает реальную занятость серверов и сложность выполняемых операций. При неоднородной нагрузке возникает ситуация, когда один из узлов получает значительно больше тяжёлых запросов и оказывается перегруженным, в то время как другие остаются частично свободны.
Более адаптивным считается алгоритм Least Connections (рис. 3). Он направляет запрос на тот сервер, у которого в данный момент меньше всего активных соединений. Балансировщик регулярно получает информацию о состоянии узлов через heartbeat-сообщения и быстрее реагирует на ситуации, когда сервер удерживает множество долгих соединений. Однако и этот метод имеет ограничения, поскольку число соединений не всегда отражает фактическую длительность операций: сервер с малым числом соединений может выполнять тяжёлые операции дольше остальных, что алгоритм предсказать не способен [5].
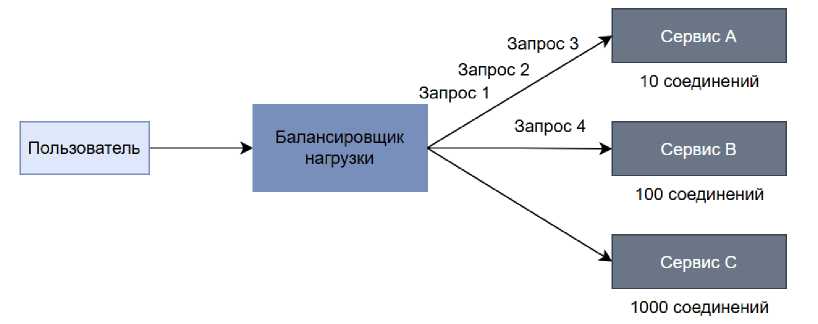
Рисунок 3. Схема алгоритма L EAST C ONNECTIONS .
Figure 3. Least Connections algorithm schematic.
Для обеспечения устойчивости данных в облачных хранилищах широко используется репликация. Данные дублируются на нескольких узлах, что позволяет сохранить доступность даже при отказе части оборудования. Синхронная репликация обеспечивает высокую согласованность, но увеличивает задержку записи, поскольку операция считается завершённой только после подтверждения всех реплик. Асинхронная репликация снижает задержки, но повышает риск потери последних изменений при отказе ведущего узла. В распределённых СУБД применяются протоколы согласования, такие как Paxos и Raft, которые выбирают новый ведущий узел и согласовывают состояние журнала операций при сбоях, поддерживая целостность данных [8].
Для экономии хранилища используются коды коррекции ошибок, например коды Рида– Соломона. В этом случае данные разбиваются на фрагменты, к которым добавляются проверочные блоки, вычисленные с помощью линейных преобразований. При потере части блоков система способна восстановить недостающие данные путём решения системы уравнений. Преимущество такого подхода состоит в уменьшении объёмов хранимой избыточности, однако вычислительная нагрузка на кодирование и реконструкцию существенно выше, что создаёт узкие места при интенсивных потоках записи [9, 12].
Алгоритмы, основанные на методах машинного обучения, становятся важной частью современной оптимизации распределённых систем. Модели анализируют историю нагрузок, задержки между узлами, частоту ошибок и изменения профиля запросов. Это позволяет прогнозировать пики активности и заранее перераспределять вычислительные ресурсы. В сетевых подсистемах такие подходы применяются для интеллектуальной маршрутизации трафика: узлы учитывают текущие задержки и выбирают пути с наименьшим временем передачи либо обходят перегружённые сегменты сети. Эти методы повышают предсказуемость работы платформы, однако их эффективность напрямую зависит от полноты и качества данных. В условиях резких изменений поведения пользователей модели могут выдавать некорректные прогнозы [3].
Несмотря на развитость технологий, остаются проблемы совместимости между решениями разных облачных провайдеров. Отличия в API, форматах данных и протоколах приводят к сложности миграции, создавая эффект привязки к платформе. Это снижает гибкость инфраструктуры и усложняет построение межоблачных систем.
В совокупности описанные алгоритмы формируют основу современных облачных инфраструктур. Каждый из них решает отдельную задачу – от параллельной обработки данных до обеспечения надёжности хранения и управления нагрузкой. Однако их возможности ограничены фундаментальными особенностями распределённых систем: ростом задержек при увеличении межузловых взаимодействий, вычислительными затратами на обеспечение устойчивости данных и сложностью адаптации к непредсказуемым изменениям нагрузки.
Разработка и методология гибридного
АЛГОРИТМА ОПТИМИЗАЦИИ НАГРУЗКИ
Несмотря на развитость облачных систем, их работа ограничивается межузловыми задержками, недостаточной точностью распределения нагрузки и высокой стоимостью хранения данных. Повысить эффективность можно за счёт алгоритмов, которые делают управление ресурсами более адаптивным и предсказуемым.
Одним из направлений является внедрение гибридных алгоритмов балансировки нагрузки, совмещающих аналитические модели и методы машинного обучения. В отличие от традиционных подходов [4, 5], такие алгоритмы учитывают не только текущее число соединений на узлах, но и фактическую нагрузку: длительность выполнения запросов, профиль поступающих задач и историю пиков. Модель прогнозирует, какой узел вскоре станет наиболее подходящим с точки зрения задержек и пропускной способности, а балансировщик распределяет запросы с учётом ожидаемой нагрузки. Это уменьшает риск перегрузки при резких изменениях потока запросов.
Для наглядности ниже приведён фрагмент реализации гибридного алгоритма балансировки нагрузки. Код демонстрирует ключевую логику: сбор метрик, обучение прогнозной модели (в отличие от традиционных алгоритмов балансировки) и выбор оптимального узла на основе предсказаний.
Листинг 1. Пример гибридного балансировщика с обучением на метриках узлов. Listing 1. Example of a Hybrid Load Balancer with Node Metric Learning import numpy as np from sklearn.linear_model import LinearRegression import time from typing import List, Dict, Tuple class HybridLoadBalancer:
def __init__(self, nodes: List[str]): self.nodes = nodes # Список идентификаторов узлов self.metrics = {node: [] for node in nodes} # История метрик по узлам self.model = LinearRegression() self.is_trained = False def collect_metrics(self, node: str, cpu_load: float, mem_load: float, conn_count: int):
"""Собирает текущие метрики узла"""
for i in range(1, len(self.metrics[node])): prev = self.metrics[node][i-1]
curr = self.metrics[node][i]
-
# Признаки: загрузка CPU, памяти, число соединений в момент t X.append([prev[0], prev[1], prev[2]])
-
# Цель: время обработки запроса (разница временных меток) y.append(curr[3] - prev[3])
def select_node(self, request_size: int) -> str: """
Выбирает узел с минимальным прогнозируемым временем отклика request_size – условный размер запроса (влияет на нагрузку)
best_node = None best_time = float('inf')
-
# Получаем текущие метрики узла (пример)
if self.metrics[node]:
cpu_load, mem_load, conn_count, _ = self.metrics[node][-1]
else:
cpu_load, mem_load, conn_count = 0.5, 0.5, 10 # значения по умолчанию
-
# Учитываем размер запроса
adjusted_cpu = cpu_load + request_size * 0.01
adjusted_mem = mem_load + request_size * 0.02
pred_time = self.predict_response_time(adjusted_cpu, adjusted_mem, conn_count)
if pred_time < best_time:
best_time = pred_time best_node = node return best_node if __name__ == "__main__":
-
# Инициализация балансировщика с 3 узлами
lb = HybridLoadBalancer(["node1", "node2", "node3"])
-
# Сбор метрик (в реальной системе – из мониторинга) lb.collect_metrics("node1", 0.4, 0.5,8)
lb.collect_metrics("node1", 0.45, 0.55,9)
lb.collect_metrics("node2", 0.7, 0.8,15)
lb.collect_metrics("node2", 0.75, 0.85,16)
lb.collect_metrics("node3", 0.3, 0.4,5)
lb.collect_metrics("node3", 0.35, 0.45,6)
-
# Обучение модели lb.train_model()
# Выбор узла для запроса размером 100 единиц selected_node = lb.select_node(100) print(f"Выбран узел: {selected_node}")
Представленный алгоритм служит экспериментальным методом, позволяющим оценить влияние предиктивного распределения нагрузки на уменьшение задержек и стабилизацию работы распределённых систем. Для проверки его корректности была выполнена серия тестов на смоделированных метриках нагрузки узлов, что позволило оценить реакцию алгоритма на изменения CPU-нагрузки, потребления памяти и количества соединений. Тестирование проводилось в программной среде на основе Python 3 с использованием библиотеки scikit-learn (модель линейной регрессии) и виртуализированной модели узлов, для которых генерировались последовательности метрик.
Такая программная реализация позволила воспроизвести условия работы распределённой системы и зафиксировать динамику выбора узлов балансировщиком. Полученные результаты представлены в следующем разделе.
РЕЗУЛЬТАТЫ И ОБСУЖДЕНИЕ
Результаты экспериментального
ИССЛЕДОВАНИЯ
Для оценки эффективности предложенного алгоритма было проведено сравнение трёх методов: Round Robin, Least Connections и гибридного алгоритма. Моделирование выполнялось на пяти виртуальных узлах с обработкой потока из 1000 запросов различной вычислительной сложности. Для каждого узла генерировались метрики загрузки CPU, памяти и числа активных соединений; время отклика рассчитывалось по модели, учитывающей реальную текущую нагрузку.
Для сравнения были выбраны именно алгоритмы Round Robin и Least Connections, поскольку оба относятся к классу методов балансировки нагрузки и непосредственно решают задачу распределения входящих запросов между узлами. Round Robin является базовым алгоритмом, широко используемым в промышленности как эталон минимальной оптимизации, а Least Connections представляет собой адаптивный механизм, учитывающий текущее состояние серверов. Оба метода применяются в реальных облачных инфраструктурах и подходят для корректного количественного сравнения.
-
• Round Robin распределял запросы равномерно, без анализа состояния узлов.
-
• Least Connections направлял запросы на сервер с минимальным числом активных соединений.
-
• Гибридный алгоритм использовал линейную регрессию для прогнозирования времени отклика на основе метрик узлов.
Все три алгоритма выполняли обработку одной и той же последовательности запросов в идентичных условиях
Сводные результаты представлены в таблице 1.
Таблица 1. Сравнение алгоритмов распределения нагрузки.
Table 1. Comparison of load balancing algorithms.
|
Алгоритм |
Среднее время отклика (мс) |
95-й перцентиль (мс) |
Максимальная задержка (мс) |
|
Round Robin |
120 |
190 |
260 |
|
Least Connections |
95 |
150 |
210 |
|
Гибридный (ML) |
82 |
130 |
175 |
На основе этих данных можно сделать следующие выводы:
-
• Среднее время отклика гибридного алгоритма ниже на 31,6% по сравнению с Round Robin и на 13,7% по сравнению с Least Connections, что указывает на более рациональное распределение нагрузки.
-
• 95-й перцентиль задержек уменьшился на
31,5% относительно Round Robin и на 13,3% относительно Least Connections, что подтверждает рост стабильности при высокой нагрузке.
-
• Максимальная задержка снизилась с 260 мс (Round Robin) до 175 мс в гибридном алгоритме, что соответствует снижению пика задержек на 32,7%.
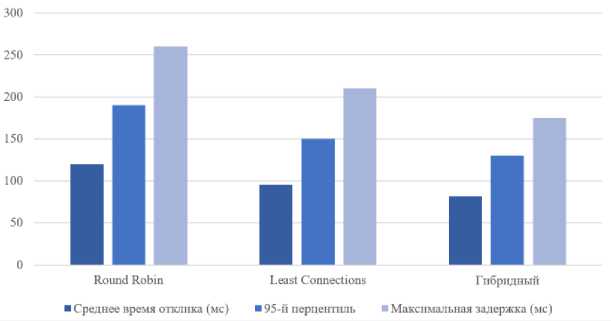
Рисунок 4. Сравнение алгоритмов распределения нагрузки.
Figure 4. Comparison of load balancing algorithms.
На Рисунке 4 представлено визуальное сравнение работы алгоритмов распределения нагрузки. Графическое представление позволяет наглядно оценить различия в стабильности работы, чувствительности к пиковым нагрузкам и общей эффективности каждого алгоритма в условиях распределённой среды.
Полученные результаты показывают, что предложенный гибридный алгоритм обеспечивает как снижение средних задержек, так и уменьшение разброса времени отклика. Это подтверждает эффективность использования предиктивных моделей для распределения нагрузки в облачных системах и демонстрирует преимущество рассматриваемого метода по сравнению с традиционными подходами.
Перспективы и направления будущих
ИССЛЕДОВАНИЙ В ОБЛАЧНОЙ ОПТИМИЗАЦИИ
Развитие облачных вычислений связано с необходимостью уменьшения задержек обработки данных, повышения точности распределения нагрузки и эффективного использования ресурсов. Существующие решения частично закрывают эти задачи, однако потоковые системы, распределённый мониторинг и высоконагруженные сервисы требуют дальнейших архитектурных улучшений.
Одним из перспективных направлений является адаптация принципов MapReduce для обработки данных в реальном времени [10]. Основное ограничение классической модели – стадия shuffle, поэтому в real-time-подходах данные обрабатываются сразу по мере поступления, без накопления больших объёмов и полной сортировки. Использование долгоживущих процессов делает такую схему применимой для событий IoT, телеметрии и логов.
Методы искусственного интеллекта в планировщиках ресурсов позволяют прогнозировать будущие пики нагрузки, снижать вероятность перегрузок и сокращать время отклика [3]. Их преимущество заключается в адаптивности к изменениям профиля запросов и динамичным рабочим условиям.
Аппаратные ускорители также открывают возможности для оптимизации. GPU обеспечивают высокую скорость параллельных вычислений, а FPGA позволяют аппаратно реализовывать специализированные алгоритмы и снижать энергопотребление. Комбинирование CPU с GPU и FPGA повышает эффективность масштабируемых сервисов.
Стандартизация интерфейсов и протоколов остаётся важной задачей: различия между облачными провайдерами усложняют перенос приложений и интеграцию распределённых систем [7]. Унификация API и форматов данных позволит упростить взаимодействие сервисов и ускорить внедрение интеллектуальных механизмов управления ресурсами.
Таким образом, ключевыми направлениями развития являются переход к обработке данных в реальном времени, применение ML-моделей в планировщиках, использование аппаратных ускорителей и стандартизация межоблачного взаимодействия. Эти подходы позволят снизить задержки, повысить эффективность распределения ресурсов и обеспечить устойчивость систем при увеличении объёмов данных.
ЗАКЛЮЧЕНИЕ
Облачные платформы обеспечивают масштабируемую обработку данных и высокую доступность сервисов, однако их производительность и надёжность напрямую зависят от применяемых алгоритмов распределения, хранения и маршрутизации информации. Параллельная обработка, балансировка нагрузки и механизмы избыточного хранения остаются эффективными в базовых условиях, но сталкиваются с ограничениями при увеличении объёмов данных и росте межузлового трафика.
Результаты экспериментального сравнения показывают, что использование предиктивных методов позволяет снижать задержки и повышать стабильность распределённых систем по сравнению с классическими моделями. Эффективность облачных платформ определяется тем, насколько применяемые алгоритмы способны уменьшать сетевую нагрузку, стабилизировать время отклика и обеспечивать корректное восстановление после сбоев при сохранении согласованности данных. Поэтому совершенствование методов обработки и хранения остаётся ключевым направлением развития облачных технологий.
Перспективными направлениями являются переход к обработке данных в реальном времени, применение ML-моделей в планировщиках ресурсов, использование аппаратных ускорителей и стандартизация интерфейсов [3, 7, 10]. Эти подходы дополняют классические алгоритмы [4, 5, 8, 11] и позволяют облачным системам эффективнее масштабироваться и обеспечивать стабильную работу приложений, критичных к времени отклика и надёжности.
