An efficient object search in video using template matching

Author: Nitin S. Ujgare, Swati P. Baviskar
Journal: International Journal of Image, Graphics and Signal Processing @ijigsp
Article in issue: 3 vol.11, 2019.
Free access
This research paper presents a novel approach for object instance search in video. At the inception, video is selected for which the object instance within the desired video is to be searched and given as an input to system. In preprocessing step, video is divided into key frames. In next step, features are extracted from query image and using template matching algorithm it is compared with key frames. If the object is present in frame then it will display detected object. Similarly, all the frames in video which contains the object are displayed. Max Path Search algorithm is used to remove the noise against classifier and Spatio-Temporal trajectories are used to improve object search. We encountered the fundamental challenge to detect an object from a set of key frames of a video with a partial appearance of object due to lighting, positioning, occlusion etc. from a known class such as logo and any other. The goal of proposed method is to detect all instances of object from known class.
Object Detection, Spatio-Temporal Trajectories, Template Matching, Video
Short address: https://sciup.org/15016037
IDR: 15016037 | DOI: 10.5815/ijigsp.2019.03.02
Text of the scientific article An efficient object search in video using template matching
Published Online March 2019 in MECS
Detection of object in multiple images is widespread interest due to a large number of applications in the diverse discipline including video surveillance, medical diagnosis and high-level vision based intelligence applications. Object detection is a technology in computer vision for finding and identifying objects in an image or video key frames. Well searched domains of object detection are face detection, Pedestrian detection, etc. To search an object manually in huge videos is an exhausting task. Also in video surveillance [9] [10] partial object detection is a challenging task. Objects in the video may be of any dimension, color and may present at any angles, detecting these objects is difficult. So this motivates us to design a system that will search an object in a video, hence reducing the time to search. To alleviate this problem a novel approach is proposed that allows a partial detection of the object irrespective of shape, color and angles. However it is easy to locate large objects, but when it comes to smaller objects it becomes very critical. There are systems to detect a small object from a video but due to partial or full occlusion of image, it is very difficult to detect an object from the set of key frames. It is notably important that object search is mainly concerned with determining identity of object being observed in an image from a set of known tags. In this research paper, object search is done through the use of ordinary camera. The system is well extended in application like video surveillance system to detect the suspicious object. Robot localization and navigation, monitoring and surveillance, quality control and assembly in industrial plan, etc. are the other applications. Therefore the main objectives of system are:
-
• To ease the detection of object in a video
-
• To improve the efficiency of existing system.
-
• To reduce the time of manual video search
-
II. Related Work
Object search in a video allows the user to easily search for an object in a huge video. Normally to search an object from a video, user has to search within entire video. Video surveillance is an important application, but to search an object manually in large size videos is an exhausting task. Sometimes it is very difficult to detect every object in a video from eyes. Another problem is that through eyes we miss some partially visible images. Thus goal of proposed approach is to handles all the above problems and provide easy and fast object search irrespective of its position, partial visibility, shape and size. This section discusses different techniques for object detection in video. In background subtraction method [8] object detection is achieved by subtracting the current frame from the previous frame and obtains the threshold value which is difference between the frames [17][18]. If the threshold value is greater than given pixel, it is consider as foreground.
[)/ V'A J 1......if\D (X )|>T nx
B ( X ) { 0..... otherwise (1)
A drawback of this method is less efficiency and accuracy; it can’t deal with quick changes. This method is not appropriate because it gives false positives as a result and it fails if a shadow or any other obstacles are present. To resolve these issues in object searching, we have used template matching algorithm. It is widely used computer vision technique that identifies the part of an image that matches a pre-defined template. A template is a small image and the objective is to find occurrences of the template in a video. Meng, Yuan, Wang used Max Path search [2] to efficiently find the globally optimal Spatiotemporal trajectory of the object. Experimental results are shown on a collection of mobile-captured videos in real-world environments that demonstrate the effectiveness and accuracy of proposed approach. The authors have discovered three methods as follows.
-
i) Discriminative mutual information score
A query is represented with Q and each frame Ii as collections of invariant local feature points p, dq ЄRN as the feature descriptor of points in Q and dp Є RN as the feature descriptor of points in Ii. Similarity between a feature point is measured in Q and Ii by the discriminative point-wise mutual information. Ω+ denotes the set of positive feature points as (i.e. feature points in Q) and Ω- denotes the set of negative features. Thus the point-wise score s(p) can be derived as:
s ( p ) = log
P ( Q+ ) +
P ( d p I ^ )
P ( d p | Q+ ) P ( Q- )
-
ii) Spatial localization using Hough voting
A problem with discriminative mutual information similarity measure is the Nave Bayes assumption, which assumes independence among the local feature points. In practice, this assumption is often violated. When two local feature points come from the same object, they must satisfy certain geometric constraints such as their relative distances to the object center and relative orientations. To resolve this problem, author proposes to transfer the geometric constraints on the query to its potential matches. However relative scale of the two object instances can be determined from the corresponding Gaussian scale levels. Specifically, for each feature point in Ω+, calculate its offset from the object center and dominant orientation. The mutual information score in equation (2) is then cast to the predicted center location instead of the feature location. Similarly, a negative vote is cast to the predicted object center for each nearest neighbor of points in Ω-. This results in a confidence map of frame Ii, where a high positive score at location ci implies a high likelihood that the target object center locates at ci, while a negative score indicates that the target center is unlikely to appear at ci.
-
iii) Spatio-temporal Localization via Max-Path Search
Once we obtain the confidence map of target object center for each frame Ii, we search for the optimal spatiotemporal center location in the entire video sequence using Max-Path search. As we locate the object center rather than the object, we do not need to test a number of window scales and aspect ratios as does. If we denote by s(ci) the discriminative confidence score of location ci, our goal is to find a smooth three dimensional spatiotemporal path ‘p’with the highest accumulative Confidence Score.
Meng, Yuan, Wang [3] had efficiently used Spatiotemporal trajectories to improve object instance search. The research discusses about how to determine the toptrajectories that locate and track the object instances in videos. These trajectories are ranked by the summations of its bounding box scores. Max-path uses dynamic programming to search for the optimal path over the 3D framework connecting bounding boxes that are scored prior to the Spatio Temporal search. All the problems are tackled by leveraging a randomized approach to quickly obtain pixel-wise confidence scores, which in combination with integral images permits the application of Max-Path search to large video datasets. They are the first to extend Max-Path search to the problem of finding object trajectories in large video volumes. The research paper [2] uses a combination of Hough Voting and MaxPath search to locate object centers in a video. But the disadvantage was that it can produce trajectories of the object center only rather than the object itself. Also, it is not efficient for large scale videos. To reduce search complexity to find object in huge videos it uses Max-Path search. Max-Path search uses dynamic programming to obtain the globally optimal trajectory.
An efficient approach [4] to search for and locate all occurrences of a specific object in large video volumes is presented. This is given by a single example. In 3-D videos, locations of object occurrences are returned as spatio-temporal trajectories. These methods locate the object independently in every image, so they do not preserve the spatio-temporal consistency in consecutive video frames. This results in suboptimal performance if it is directly applied to videos. Further objects are located jointly across video frames using spatio-temporal search. The input is taken as consumer video dataset consisting form YouTube or mobile captured consumer clips and then the efficiency and effectiveness of the proposed approach is demonstrated.
Ran Tao, Efstratios Gavves [5] determined Localities of object instances at all steps. Localized search in the image for an instance is advantageous but the signal to noise ratio within the bounding box is much higher than in the entire image. Continuing on the localization of the feature space by using very large vocabularies further improves the results considerably.
Visual object search [6] can be viewed as two combined tasks: object matching and object localization. For object bag-of-visual-words (BoVW) scheme, the Naive-Bayes Nearest Neighbor (NBNN) classifiers are adopted by assuming that each feature point is independent from the others. However, NBNN may fail when the Naive-Bayes assumption is violated. Another way to mitigate the quantization error is to consider spatial context instead of using individual point. By bundling co- occurring visual words within a constrained spatial instance into a visual phrase or feature group as the basic unit for object matching, the spatial context information is incorporated to enhance the discriminative power of visual words.
Relja Arandjelovic, Andrew Zisserman [7] proposed a new method which compares SIFT descriptors. This results into significant performance without extending processing or storage requirements. This proposed method for query expansion leads to richer model best suited for immediate object retrieval through efficient use of the inverted index. It is notably important that augmenting features those are spatially consistent with the augmented image are considered in feature extraction. Feature augmentation is a useful method of increasing recall but this requires a complicated processing for graph construction.
-
III. Proposed Method
Fig.1 shows the block diagram of the proposed method. Objects in the video may be of any dimension, color and may present at any angles, detecting these objects is difficult. This induces to propose a systematic approach that will effectively search an object in a video, hence reducing the time to search. In addition, it allows partial detection of object irrespective of shape, color and angles. The proposed system has five components. First is video acquisition, in which video is taken as an input. The acquired video is then divided into a number of frames. In next step, object to be searched is taken as a template and features of the object are extracted. This template containing the features is then matched with all the frames of the video. There is a frame-wise matching of the object. Since there is per frame matching, accuracy to detect the desired object become more. If the object is matched in the given frame then that frame containing the object is displayed. The object or the features in frames throughout the video close to the target object is displayed.
-
A. Video Acquisition
In this phase, a video is accepted from the user. User provides a video from which system detects an object if it is present. This video can be of any duration of time. For example, if a user needs to find a missing object from a shop or a mall then desired video which is recorded by CCTV cameras would be given as an input.
-
B. Frame Extraction
Any video is made up of many frames. In this phase, the accepted video is broken down into frames. These frames help in the easy matching of the object if it is present in the video. The number of frames present in a video is dependent on the time duration i.e. the length of the video. We have used C# and OOPL, which has its own in built libraries for frame extraction. As soon as the video is given as an input to the system, the libraries for frame extraction extract all the frames and save it in specified
-
C. Template Matching Algorithm
Image selected for the detection is used as a template. Its features are then extracted. The features of the template which was extracted previously are matched with each and every frame of the video. Template matching [12] [13] is a trial and error type also called as ’brute-force’ algorithm for object recognition. Its working is simple: Create a small template (sub-image) of the query object which is to be found, for example a football. Now pixel by pixel matching of template with the image to be scanned is accomplished by placing a center of the template at every possible pixel of the main image. We now use similarity metric, like normalized cross-correlation (NCC), to find the pixel and getting the maximum match. It gives place which has image most similar to the template (football).
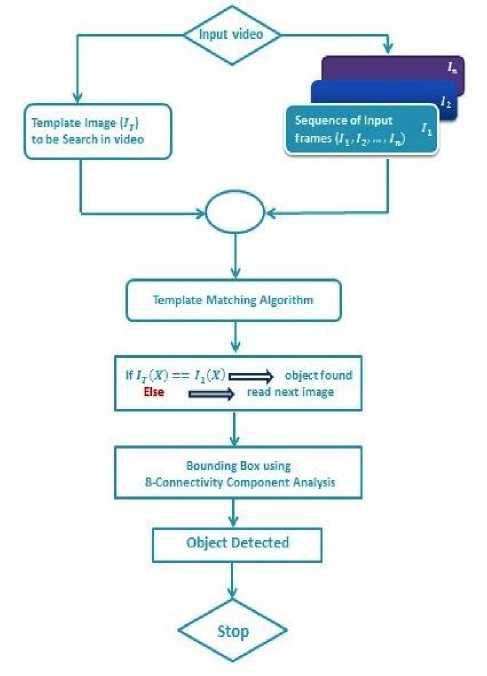
Fig.1. Block Diagram of Proposed Method
Using AForge ffmpeg wrapper we can extract frame from a video using VideoFileReader class and save it as a bitmap. In template matching each portion of the image is calculated and examined. Similarities between each frame and the templates are matched and considered. Template matching algorithm consists of sliding the template image[14] over each frame and calculating a distortion or correlation. It also measures estimating the dissimilarity or similarity between the template image and source image. Then, the maximum correlation or minimum distortion, a position is taken to represent the instance of the template into the image under examination.
-
D. Object Detection
Wherever the features are matched in a frame considering the threshold value, the object is detected. This object is marked with a border showing its location and highlighting it. A problem that arises in this phase is the detection of partial image and images which are resent on a different angle than in the given template. Objects occlusion is also a major problem as they are not visible in the frame, ultimately results in no features that are matched.
-
E. 8-Connectivity
The goal of the connected component analysis is to detect the large-sized connected foreground region of object. The result analysis of research paper [4] has shown that accuracy of 8-connectivity is better than 4-connectivity labeling because computationally 8 connectivity is efficient. During the implementation of connected component analysis, we have used two pass labeling algorithm to extract maximally connected blob. The author [4] has mentioned the entire process of first pass and second pass labeling algorithm.
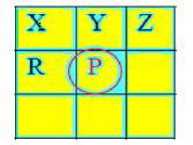
Fig.2. 8-Connectivity Check
Step 1
-
a) Iterate through each pixel of rectangular image array by column, then by row (Raster Scanning)
-
b) If the element is not the background
-
i) Get the neighboring pixel of the current pixel
-
ii) If there are no neighbors, uniquely label the current pixel and continue
-
iii) Otherwise, find the neighbor with the smallest label and assign it to the current pixel
-
iv) Store the equivalence between neighboring labels
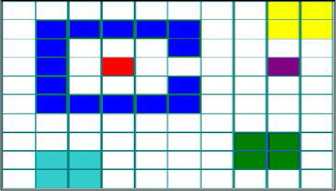
Fig.3. Sample Output of the First Pass
Step 2
-
a) Iterate through each pixel of the rectangular array by column, then by row
-
b) If the pixel is not the background
-
i. Relabel the element with the lowest equivalent label
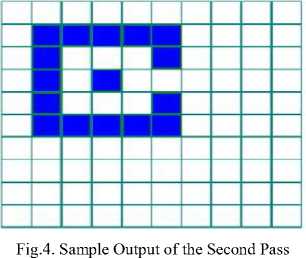
-
F. Display Object
The highlighted objects are then displayed to the user as output. A user can navigate through all the frames in which the object is detected. It also displays partial objects. Objects that are very small and difficult to search with human eyes are also displayed by this system.
-
G. Implemented Algorithm
The following exhibit template matching algorithm for object searching. The steps for the simplified object searching algorithm are presented below:
-
1) Read the input video in which the image is to be searched.
-
2) Read template image I which is to be searched in input video from step 1.
-
3) The input video is broken down into frames
-
4) Check each frame with the template image using template matching algorithm as below.
-
i. Read input search image S(x, y), where (x, y) represent the coordinates of each pixel in the search image.
-
ii. Read template image T( xy ), where ( xy ) represent the coordinates of each pixel in the template.
-
iii. Move center (or the origin) of the template T( xy ) over each ( x , y ) point in the search image and calculate sum of products between the coefficients in S( x , y ) and T( xy ) over the whole area spanned by the template.
-
iv. Identify position with the highest score and mark it as best position.
-
v. Display the detected object and match imaged 5) If the template matching is successful then highlight
the image using a bounding box Else goto STEP 4(i) and read next frame.
-
6) Save detected image in output folder for display.
-
7) Stop
-
IV. Result Analysis
To measure the performance of the proposed algorithm, we have selected threshold value, the processing time for each frame in seconds, number frames correctly matched and a number of frames incorrectly matched as performance parameters. Figure 5 and 6 show some typical results of objects search in image and video. In fact, effort is made to overcome the drawbacks of previous object searching systems such as partial detection of objects which are cluttered in the background with many images. The goal is to reduce search complexity.
-
A. Object Search in an Image
In this section we will discuss the results of object detection in specified target image.
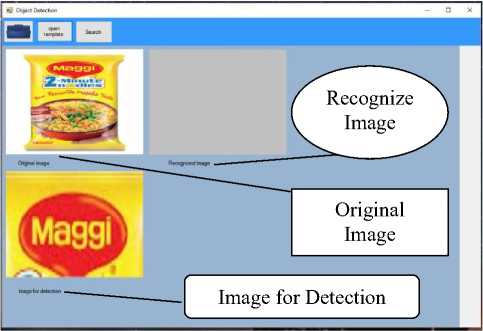
Fig.5.1. Selection of age for object search
The target image is selected as an input from which the object is to be searched. The first rectangular box in above image indicates the original image. The Second grey box shows the recognized image and third in the bottom shows object instance for detection.
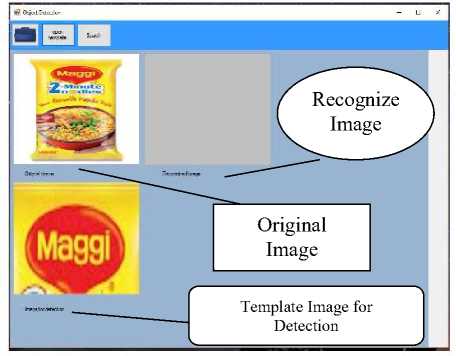
Fig.5.2. Template Image given by User
The next step (Fig. 5.2) is selection of template to be searched within the image. This image is taken as an input from the user.
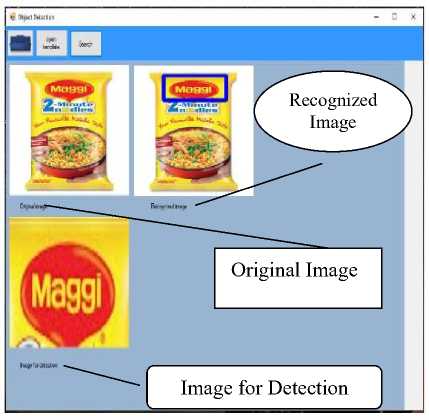
Fig.5.3. Template Image detected in video
The last processing step is detection of object instance in an image given as template. In above Fig. 5.3, the object instance is detected in the target image and object is highlighted with blue color bounding box.
-
B. Object Search in Video
In this section we will discuss the result of object instance search in video. On the top bar, user have different menu option like start camera, source image, template image, open video, matching and Save.
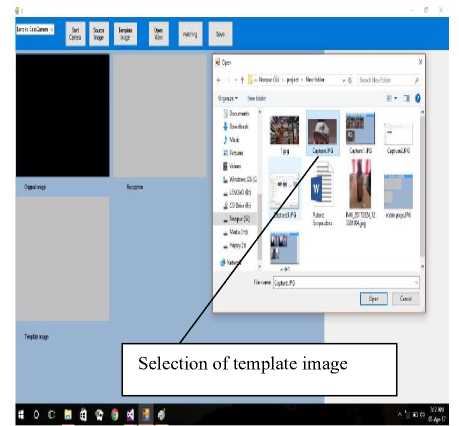
Fig.6.1. Selection of Template Image for Object Search in Video
The above image indicates the selection of template by the user.

Fig.6.2. Template Image Selected
The Fig. 6.2 shows the template image selected by the user for object search in video.
Fig.6.3. Selection of Input Video

Fig.6.4. Object Detection using Bounding Box
After processing, object instance is detected in video as shown with a blue colored box in Fig. 6.4.
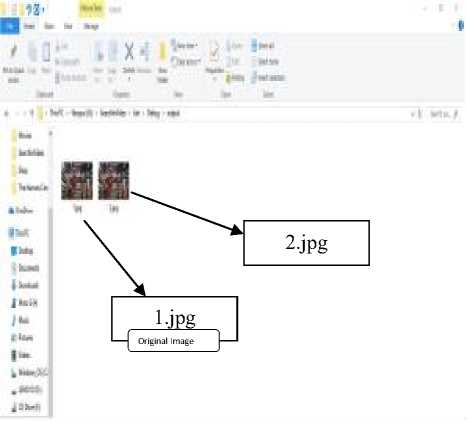
Fig.6.5. Detected Frames in Video
The above image shows the frame no. 1.jpg and 2.jpg of video in which the template image is detected. All the frames in which object is detected are saved in output folder for display using an external camera. We can easily identify from above result that the proposed system is robust as it recognize and searched the objects that are very small and difficult to search with human eyes.
-
C. Object Search in Real Time Video
This section shows the searching of object in a real time video. A real time video is a video which is captured live using an external camera device
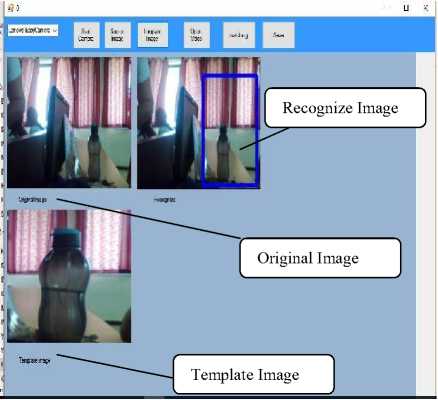
Fig.7. Object Detection in Real Time Video
The above result shows that the given highlighted objects using blue bounding box is detected in the real time video. The proposed method detect and search the
Object instance in video of any dimension, color and may present at any angle with presence of shadow without fail. This indicates that precision rate of object searching using template matching is high as compared to the other object detection and recognition method.
Table 1. Performance Analysis of Object Search
|
Threshold Value |
Length of original video |
Processing time for each frame |
Frames detected |
Misdetection of frames |
|
0.5 |
1 m 49 s |
2.5 sec |
7 |
5 |
|
0.6 |
1 m 49 s |
2.1 sec |
4 |
1 |
|
0.7 |
1 m 49 s |
1.8 sec |
2 |
0 |
From Table 1, we can conclude that, if we increase the threshold value then processing time for each frame decreases significantly with decrease in frame misdetection rate.
-
V. Conclusions
This work presents a computationally efficient method designed for searching and detecting an object with varied complexities. The system locates all occurrences of template image in a video where the image is present. Accuracy to detect an object in a video can be achieved by adjusting the threshold value, which includes the detection of partial images. Our system is better at handling miss detection of an object. We have tried to tackle high resolution-imagery change difficulties such as partial occlusion, projective distortion and detail profusion or the presence of shadow which do not corresponds to real changes in the scene and therefore make the interpretation more difficult. This system is best but not a silver bullet for all problems because it process .avi format videos only. The system can be extended to support all the video formats and can be modified by implementing an alarm system thereby helps to notify a user and hence reduce the manual work of watching the entire video.
Acknowledgment
We would like to thanks our daughters and parent for their constant support and patience during this research work. This research work is fully supported by the Government College of Engineering, Aurangabad and Nashik District Maratha Vidya Prasak Samaj’s Karmaveer Adv. Baburao Ganpatrao Thakare College of Engineering, Nashik, Maharashtra, India.
References An efficient object search in video using template matching
- Yuning Jiang, Jingjing Meng, Junsong Yuan-“Grid-Based local feature bundling for efficient object search and localization”,18th IEEE International Conference on. Image Processing (ICIP 2011), 113-116. Date. 2011
- Jingjing Meng, Junsong Yuan, Gang Wang, Yap-Peng Tan and Jianbo Xu - "Object instance search in videos” Dec 2013, 9th International Conference (ICICS)
- JingjingMeng, Jiong Yang, Gang Wang, “Object Instance Search in Videos via Spatio-Temporal Trajectory Discovery”, IEEE TRANSACTIONS on Multimedia, Vol. 18, No. 1, January 2016
- Jingjing Meng, Junsong Yuan, Yap-Peng Tan, Gang Wang - "Fast object Instance Search in Videos from One Example.” 27-30 Sept 2015, IEEE International Conference on Image Processing (ICIP), ISBN: 978-1-4799-8339-1
- Ran Tao, Efstratios Gavves, Cees G.M. Snoek, Arnold W.M. Smeulders - "Locality in Generic Instance Search from One Example." 23-28 June 2014,Computer Vision and Pattern Recognition (CVPR),2014 IEEE Conference, ISBN: 978-1-4799-5118-5
- Yuning Jiang Jingjing Meng Junsong Yuan "Randomized Visual Phrases for Object Search" Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference, 16-21 June 2012, 10.1109/CVPR.2012.6248042
- Relja Arandjelovic, Andrew Zisserman - "Three things everyone should know to improve object retrieval.” CVPR '12 Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 16-21 June 2012, Pages 2911-2918
- Priyank Shah, Hardik Modi,"Comprehensive Study and Comparative Analysis of Different Types of Background Sub-traction Algorithms", IJIGSP, vol.6, no.8, pp.47-52, 2014.DOI: 10.5815/ijigsp.2014.08.07
- Pawan Kumar Mishra, G.P Saroha, "A Study on Classification for Static and Moving Object in Video Surveillance System", International Journal of Image, Graphics and Signal Processing(IJIGSP), Vol.8, No.5, pp.76-82, 2016.DOI: 10.5815/ijigsp.2016.05.07
- G.Mallikarjuna Rao, Ch.Satyanarayana,"Object Tracking System Using Approximate Median Filter, Kalman Filter and Dynamic Template Matching", JISA, vol.6, no.5, pp.83-89, 2014. DOI: 10.5815/ijisa.2014.05.09
- Prasad Halgaonkar, “Connected Component analysis and Change Detection for Images” IJCTT June Issue 2011, Volume 1(2):224-227 ISSN: 2231-2803.
- Wisarut Chantara, Ji-Hun Mun, Dong-Won Shin, and Yo-Sung Ho “Object Tracking using Adaptive Template Matching” IEIE Transactions on Smart Processing and Computing, vol. 4, no. 1, February 2015.
- Nazil Perveen, Darshan Kumar and Ishan Bhardwaj “An Overview on Template Matching Methodologies and its Applications” International Journal of Research in Computer and Communication Technology, Vol 2, Issue 10, October- 2013, ISSN (Online) 2278- 5841.
- Paridhi Swaroop, Neelam Sharma, “An Overview of Various Template Matching Methodologies in Image Processing”, International Journal of Computer Applications (0975 – 8887) Volume 153 – No 10, November 2016
- J. Sivic and A. Zisserman, “Video Google: A text retrieval approach to object matching in videos,” in Proc. IEEE Int. Conf. Comput. Vis., Oct. 2003, vol. 2, pp. 1470–1477.
- J. Meng et al., “Interactive visual object search through mutual information maximization,” in Proc. ACM Multimedia, 2010, pp.1147–1150.
- Richard J. Radake, Srinivas Andra, “Image Change Detection Algorithms: A Systematic Survey,” IEEE Trans. On Pattern Analysis and Machine Intelligence, vol. 22, no. 3, August 2000
- Allen Bovik, “The Essential Guide to Video Processing,” Academic Press- 2nd Edition 2009.
