An Object of Interest based Segmentation Approach for Selective Compression of Video Frames

Author: Marykutty Cyriac, Sankar. P.
Journal: International Journal of Image, Graphics and Signal Processing(IJIGSP) @ijigsp
Article in issue: 2 vol.8, 2016.
Free access
The automatic segmentation of objects of interest is a new research area with applications in various fields. In this paper, the object segmentation method is used for content based video management and compression of video frames for video conferencing. The face region, which is the object of interest in the video frames, is identified first using a skin color based algorithm. The face regions are then extracted and encoded without loss, while the non- face regions and the non-face frames are quantized before encoding. Results show that the decompressed video has an improved quality with the proposed approach at low bit rates.
Object of interest, segmentation, face detection, skin detection, video compression
Short address: https://sciup.org/15013950
IDR: 15013950
Text of the scientific article An Object of Interest based Segmentation Approach for Selective Compression of Video Frames
Published Online February 2016 in MECS
Video conferencing is a form of communication for transmitting the video frames over the network between two or more places. The computers at different places communicate over the network simultaneously. With the advent of high resolution cameras, the amount of data being sent over the network is large and growing. For example, an uncompressed high density video stream requires approximately one Giga bits per second. One approach to reduce the amount of data is to limit the resolution of the video to the smallest acceptable level, which effectively reduces the raw data itself. However, the visual quality of the video will be greatly deteriorated by this method. Hence, the next approach is to increase the efficiency of the compression algorithms.
The current approach for compressing video frames is H.264, where the motion compensation techniques are applied along with the DCT as the underlying algorithm. In order to increase the compression ratio, region-of-interest (ROI), object-of- interest (OOI) or frames-of-interest (FOI) techniques could be applied. ROI based techniques have been recently proposed for H.264 for tracking moving objects. The position of ROIs can be predicted from the previous frames by adding the compression and detection modules, thus reducing the computational cost for tracking for video surveillance applications [1]. The ROI detection is performed using an encoder-oriented fast algorithm that uses chrominance and texture contrast features, which saves the computational cost and reduces the throughput in non-ROI areas [2]. Wavelet based ROI and FOI based techniques are used for locating the ROI coefficients in an efficient way in [3].
-
II. Related Works
The OOI based segmentation is a promising research area with applications in content based image retrieval, watermarking, range segmentation for depth estimation, fusion of multiple images and object based image compression. Unlike other image segmentation methods, this method focuses on the automatic extraction of the specified OOI. Once the OOI is extracted, it can be used as the input for an object tracking algorithm [4] , which is an integral part of applications like computer vision, surveillance and other biometric based methods.
Various methods have been proposed in the literature for implementing the OOI technique. The OOI segmentation method based on human attention and semantic region clustering has been proposed in [5], where multiple OOIs are segmented according to a saliency map. Another method uses salient object segmentation method [6], where contrast and statistical information features are utilized for measuring the saliency. The resulting saliency map is then used in a CRF model to define an energy minimization based segmentation approach, which aims to recover salient objects. The quality of the segmentation is improved in [7] for H.264 videos by combining the motion vector with motion relativity in space and time. An automated unsupervised method to identify object-like regions in a video frame according to static and dynamic cues is proposed in [8]. Object features such as boundary, specific shape and intensity difference from the surroundings are used to define key segments. The key- segments point to object-like regions in a video frame. However, this method fails for some videos.
The drawback of all these approaches is that they are general in nature, and do not look for the presence of a human face in the frame. This is especially important for a video conferencing frame, where the frames contain human faces which are the object of interest. Hence, it is required to develop techniques to detect and identify faces from this kind of video frames. Many methods have been discussed in the literature for the detection of faces from images. The wavelet based compression scheme for face detection in video conferencing was proposed in [9][10].Using various features of the human face like lips, eyes and noses, several algorithms were designed and applied to detect human faces [11][12] [13]. A directional pattern has been used as a feature for recognizing the faces and its performance analysis has been carried out in [14][15]. One of the most popular face detection algorithms is Adaboost, which is used by several researchers for identifying and classifying the faces. Of late, usage of object detection techniques to identify faces in the field of sports and human tracking systems is widely increased. Face recognition techniques are used in these fields not only to identify the human face but also to record and update the athletic movements. Principal component Analysis (PCA) and Adaboost algorithm have been widely used for the detection of faces [16][17][18][19][20] Another popular face detection technique is the Eigen face generation, which recognizes a face by finding the Eigen vectors and projecting these vectors as significant features into a feature space to generate Eigen faces [21][22].
In this paper, a novel OOI based segmentation approach for face detection and selective compression of frames with particular attention to video conferencing application is presented. In the proposed approach, the first step is the segregation of video frames based on their content; i.e whether they contain a face or not. This frame identification operation is performed by applying skin detection and face detection algorithms to all frames. If a frame does not contain a face, then it is quantized fully. For frames with faces, selective compression is performed by quantizing the non-face area alone. This technique ensures that the quality of the face region is maintained, while the background which is less important is quantized.
This paper is organised as follows: Related works are discussed in Section 2 . Section 3 details the concept of OOI and the proposed architecture. Section 4 explains the face detection methodology and the algorithms proposed in this paper. Simulation results are given in Section 5. Finally, Section 6 concludes the paper.
-
III. Object of Interest based Segmentation
Consider an image of size U * V. Let Q denote a group of pixels, Q ={(u,v) ;1≤u≤U, 1≤v≤V}. The objective of OOI based segmentation is to separate the image into object-of-interest (OOI) and the background.
Let P = {Qi, i=1:N} denote a partition of Q. The OOI of an image is defined as follows:
N OOI
OOI = N OO Qi (1)
i = 1
where Q i is called the ith connected region and NOOI represents the number of regions that belong to OOI. Especially, the OOI represents the objects of interest, composed of NOOI regions of P. Equation (1) permits for the definition of numerous OOIs. In other words, OOI can be a collection of separated sub-OOIs.
A. Architecture
For a video conferencing application, the speed of the face detection algorithm is very important. Even though the Adaboost algorithm is very efficient in identifying a face, it uses a classifier which is slow due to the training requirement. Hence it is appropriate to choose a skin color based face detection algorithm for this kind of application. The block diagram of the OOI based compression system is shown in Fig. 1.
Face frame processing
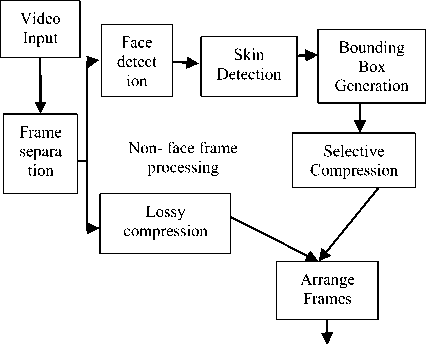
Compressed
Video
Fig.1. Block diagram of the OOI based selective compression system
-
IV. Face Detection Methodolgy
The face detection approaches available in the literature can be categorized into four classes; template matching, appearance based, knowledge based and feature based. Template matching methods are more suitable for frontal faces and compute the correlation between an Eigen face/template face and the input face. Appearance based methods view the detection problem as a classification problem and uses classifiers. The Adaboost algorithm falls into this category. Knowledge based methods use the human knowledge about a face; position of nose, mouth, eyes etc. Feature based techniques extract position invariant features and creates a face model to detect faces.
In video conferencing, the frontal face appears in most frames. However, one should expect frames with tilted faces also. Hence, feature based techniques are more suitable for these types of frames than the rest of the methods. The feature based approaches further subdivides into methods that use facial features, texture or color. Since the facial features are not clearly visible in non-frontal faces, the facial feature method becomes ineffective. Texture is an important feature of discrimination for a human observer. Gabor wavelet based approaches are generally used to extract the texture features. However, they use complex sinusoids, thus making it unsuitable for our application. Since skin color based technique is robust towards face orientation and changes in the levels of illumination, this method is used in this work. Skin color based segmentation has been previously implemented by several researchers with good performance [23,] [24]
-
A. Skin Colour Detection
The skin color clustering region is different in different color spaces. Therefore, choosing the correct color space is important to achieve proper face detection results. In general, RGB color space is more susceptible to variations in illumination, while HSV and YCbCr color spaces exhibit less sensitivity, since they separate the luminance and the chrominance components.
Between HSV and YC b C r color spaces, the skin colour cluster is more compact in the YC b C r color space [25]. It is also shown that the C b C r values provide better coverage of the skin colors of different tones. In a YC b C r color space, the symbol Y indicates the intensity, while Cb and Cr provide the color difference information. Previous studies have also shown that the skin pixels have similar Cb and Cr values and works well across different skin tones. The YC b C r values can be calculated using (1) to (3).
Y = 0.299R - 0.587G - 0.11 B(2)
Cb = B — Y(3)
Cr = B - Y(4)
Various threshold values are applied to the colour components to find the correct region where the skin pixels are clustered. The skin pixels are correctly isolated for a threshold level of 140 <= Cr <= 165 and 140 <= Cb <= 195. These threshold levels are used to generate a binary image, where all skin pixels are assigned a ‘1’ value and the non-skin pixels are made zeros. The resultant image is called as a skin detected image.
-
B. r emoval of n on -f ace r egions
The skin detected image normally contains both face and non-face regions. In order to remove the non-face regions from the skin detected image, all regions present in the image should be labeled first. The connected component theory is a useful tool for labeling regions present in an image.
In order to identify the connected components, the image is scanned from left to right. Two pixels are said to be connected if they have similar gray level values and satisfy a predefined criteria for grouping.
After the connected regions are identified, they have to be labeled. The standard approach in labeling different regions is a two- step raster scanning process. Let F be the set of foreground regions in the image. Let p be the current pixel to be labeled and S be the set of already labeled neighbors of p . Define another set Sf which consists of the set of already visited neighboring pixels. If S f is empty, a new label is assigned to p , which means that p is the first pixel of a new connected region. If S f is nonempty and all the members of S f are labeled k , then p is also labeled k . This means that p is considered to be in the same region as other pixels in the set. If more than one pixel in S f have different label, then any one label is assigned to p . The labels of pixels in Sf are now said to be in an equivalent class. At the end of the first scan, a unique identifier is assigned to each class. During the second scan, each temporary label is replaced by the class identifier to complete the labeling process.
Once the different regions are labeled, next step is the elimination of non-face regions. These are non-face regions formed from pixels having similar in color to skin pixels. A general approach to detect a non-face region is to perform a shape analysis. Since the faces are normally oval in shape, by finding the ratio of the perimeter to area can detect such regions. However, in the skin detected image, most of the regions are found to be having random shapes, and shape based extraction of the face region is difficult. Hence, a novel approach is considered to eliminate the non-face regions.
Two feature parameters, namely, the area and the aspect ratio of the bounding box of a region are chosen to distinguish between face and non-face regions. The area of a region can be calculated in terms of the number of pixels enclosed by that region. Threshold values T 1 and T 2 are used to eliminate very large and very small nonface regions from the image. A value of T1 equal to 1000 and T2 equal to 5000 are found to be sufficient for eliminating most of the non-face regions.
The image still contains non-face regions having areas similar to a face region. Such regions can be eliminated by using the bounding box aspect ratio. The bounding box is generated by finding the centroid and the top-left corner pixel of a region. The aspect ratio of the bounding box is then calculated by finding the height and width of the bounding box. The aspect ratio for a face region is found to be within the threshold values, 0.5 (T3) and two (T4). Using these threshold values, the non-face regions having area similar to a face region are removed.
The pseudo code for eliminating the non-face regions from the skin detected image using the selected parameters is given below:- for every region if T1>area> T2
remove the region continue aspect ratio= height/width if T3 > aspect ratio > T4 remove the region continue end
Since the general scenario for a frame in a video conferencing video is a single face, the threshold values are finalized through trial and error using these kinds of frames. A sample face image processed using the proposed skin detection algorithm is shown in Fig. 2. The final binary image contains the face region alone.
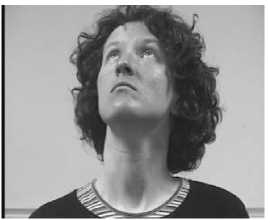
(a)

(b) (c)
Fig.2. (a) Original image (b) Binary image showing skin regions (c) image after removing non-face skin regions
-
C. Face Region Extraction
Once the face regions are identified, it is required to extract these regions from the image. Since the face regions are random in shape, contour identification is a proper approach. However, the identification and transmission of contour information is costly from the compression point of view. A simpler method is to find the smallest rectangular bounding box that encompasses the face region. The bounding box information can be easily stored as the co-ordinates of the top left corner of the box and the height and width information using few bytes. The bounding box generated for the sample image is shown in Fig.3.

Fig.3. Bounding box generation
-
D. Selective Compression
In this step, all non-face frames are quantized first to the required quality. For frames containing the face regions, the face region is extracted first and stored into a buffer. The frame is quantized similar to a non-face frame. After quantization, the face region is restored to its original position. This process ensures that the face region is of the original quality, while the background region has perceptual quality as decided by the quality factor used in the quantization process.
-
V. Simulation Results
The proposed method is tested using the face image database maintained by FGnet [26], which publishes land mark images on human activity. All face images in their database are taken with a person sitting in chair and staring at the camera without moving his/her eyes. Markers placed in the room are used to obtain different poses. Both frontal faces and tilted faces are used to check the efficiency of the face detection algorithm. The algorithm is robust enough to identify faces of different orientations. Fig. 4 shows the faces detected from images of multiple poses with the bounding box embedded in the images.

(a)
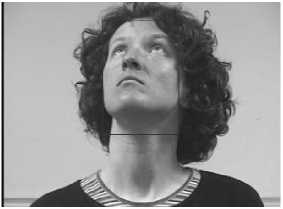
(b)

(c)
Fig.4. Face detection at varied angles (a) Frontal face (b)Face tilted up (c) face tilted to side
In order to demonstrate the effect of selective compression on the visual quality of the images, a sample image is compressed with and without selective compression. Fig.5 shows the decompressed images, where the left side image is compressed fully, while the right side image is with selective compression. The improvement in the visual quality is clearly visible.

(a) Normal decompression

(b) Decompressed after the selective compression (Q=90)
Fig.5. Effect of selective compression on the visual quality of decompressed images
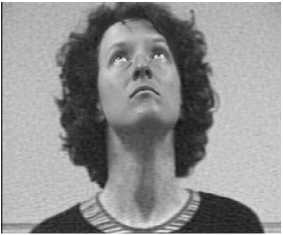
(b) Q=40
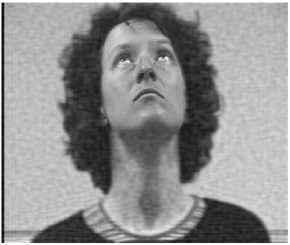
(c) Q=60

(d) Q=80
Fig.6. Visual Quality of the image after various levels of background quantisation
An objective analysis of the image quality is performed by computing the PSNR values for different quantization levels for the sample image . Fig.7 shows the PSNR values at different quantization levels for the sample image. The improvement in the PSNR values with the proposed method at high levels of quantization is clearly seen in the graph.
In order to display the effect of quantization on the selective compression, the quantization level (Q) is varied from 20 to 80. Fig. 6 shows the change in the quality of the decompressed images at the theses four different levels of quantization.
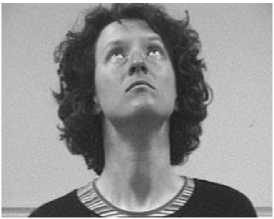
(a) Q=20
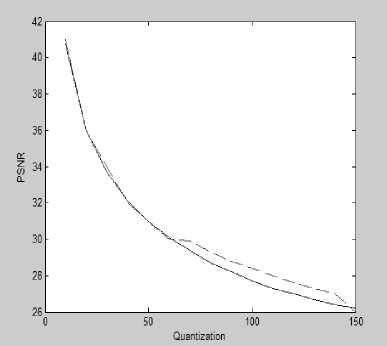
Fig.7. PSNR at different quantisation levels
Another database used for the analysis is the XM2VTSDB multi-modal face database maintained by the Department of Electronic Engineering, University of Surrey, U.K. [27]. The database contains frontal faces and rotated faces. In order to demonstrate the effectiveness of the algorithm for rotation invariance, a right rotated male face is considered. The DCT coefficients of the face image are quantized at various levels of quantization in all three color planes to implement selective compression. The resultant images obtained for Q values ranging from 30 to 150 are shown in Fig.8. It is seen that the proposed algorithm is able to detect the rotated face correctly. The visual quality of the face remains unaltered in all the three quantized images. The difference in the visual quality of the background is also clearly seen.
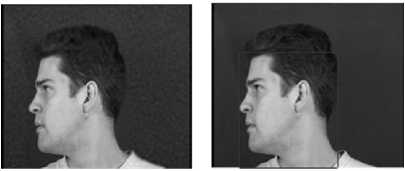
(a) Unquantised (b) Q= 30
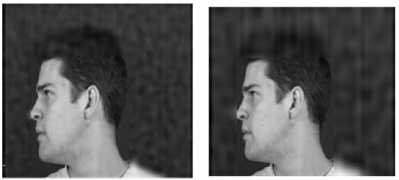
(c)Q=70 (d)Q=150
Fig.8. Quantisation for a rotated face
Let n 1 and n 2 represent the number of symbols in the image before and after the quantization operation. A value C indicates the reduction in the number of different symbols obtained through the method. Table 1 shows the reduction in the size achieved for various images.
Table 1. Reduction in the size of various images
|
Image Name |
Quantisation Level |
||
|
Q=30 |
Q=70 |
Q=150 |
|
|
C=n1/n2 |
C=n1/n2 |
C=n1/n2 |
|
|
Charles_c1 |
24.9 |
83.72 |
273.67 |
|
charles_U1 |
23.05 |
74.3 |
268.9 |
|
Charles_r1 |
25.5 |
84.6 |
243.5 |
|
Face_straight |
19.5 |
73.3 |
228.1 |
|
Face_up |
14.6 |
56.9 |
166.5 |
|
family |
23.2 |
80.5 |
259.7 |
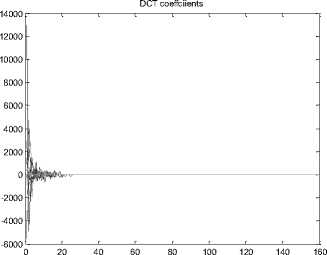
The distribution of DCT coefficients in the Red plane before and after the selective compression for the Charles_r1 image is shown in Fig.9. The number of nonzero DCT coefficients has been drastically reduced in the Red plane after the quantization operation.
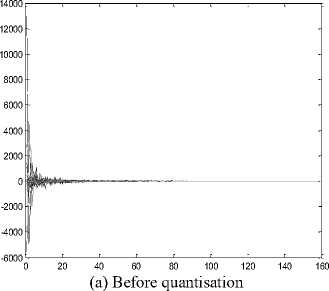
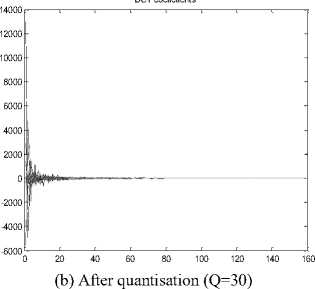
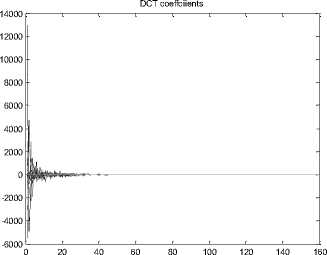
(c)After quantisation (Q=70)
(b) After quantisation (Q=150)
Fig.9. Distribution of the DCT coefficients for the Red plane of the Charles-r1 image
Since the proposed method is about the video quality, it is necessary to conduct a subjective analysis for a video. A frequently used metric for subjective analysis is the Mean Opinion Score (MOS). MOS is generally expressed as a single digit number with values ranging from 1 to 5, where 1 indicates the worst quality and 5 the best. The MOS indices and their corresponding impairment values are shown in Table 2.
Table 2. MOS Index
|
MOS |
Quality |
Impairment |
|
5 |
Excellent |
Imperceptible |
|
4 |
Good |
Perceptible but not annoying |
|
3 |
Fair |
Slightly annoying |
|
2 |
Poor |
Annoying |
|
1 |
Bad |
Very annoying |
In order to calculate the MOS values, a sample video of 11 sec duration is chosen. The video frames are extracted and given as input to the proposed algorithm. The face frames are selectively compressed while full compression is performed for the non-face frames. All frames are assembled back to get the selectively compressed video. The Matlab software is used to implement the algorithm and for video reading and writing operations.
The video was shown to a group of observers. The number of observers is about 50 under the age group of 18 to 23 with unimpaired vision. The observers were divided into five groups. Initially the original video was played to them. Subsequently, the selectively compressed video was played and they were asked to comment on the quality of the selectively compressed video. The observations made by each group are recorded separately and the average is calculated for each group. The Arithmetic mean value for all the average observations is given in Table 3.
Table 3. Mean Opinion Score (MOS)
|
Group |
Quantization Level |
||||
|
10 |
30 |
50 |
80 |
100 |
|
|
Group 1 |
5 |
4.8 |
4 |
3.6 |
2 |
|
Group 2 |
5 |
4.9 |
3.8 |
3.7 |
2.4 |
|
Group 3 |
5 |
4.86 |
3.9 |
3.4 |
2.5 |
|
Group 4 |
5 |
4.9 |
4.1 |
3.5 |
2.6 |
|
Group 5 |
5 |
5 |
4.3 |
3.6 |
2.4 |
|
Arithmetic Mean |
5 |
4.915 |
4.025 |
3.56 |
2.38 |
As per the MOS values, the visual quality degradation is imperceptible for all the groups when the quantization value is 10 or below. The quantization level of upto 30 gives excellent performance. Considerable distortion is observed only when the quantization value is beyond 80. However, the distortion is limited to the non-face region alone due to the application of selective compression method. Although the improvement in the bitrates for large quantization levels is marginal, the visual quality of the OOI is substantial with the proposed method.
-
VI. Conclusion
In this paper, a novel framework for OOI based segmentation is proposed for the selective compression of facial frames. Frames containing the face region are identified first by using a skin defection algorithm. The non-face objects in the images are removed by using area and aspect ratio information. The face region is compressed at full quality, while the background is compressed after quantization. The PSNR values of the images decompressed after the selective compression is superior to that of images reconstructed without the selective compression at low bit rates. Further, subjective quality analysis is performed using MOS. The face quality is maintained even for higher quantization levels. Our future work is to improve the visual quality at low bit rates, which could be achieved by replacing the DCT with the wavelet transform.
References An Object of Interest based Segmentation Approach for Selective Compression of Video Frames
- Fernandez, IA, Rondao AP, Tong G, Lauwereins. R, De Vleeschouwer C, "Integrated H.264 region-of-interest detection, tracking and compression for surveillance scenes", Packet Video Workshop (PV), 2010, 18th Inter-national , vol.17,no. 24, pp.13-14,2010.
- Minghui W, Tianruo Z, Chen Liu, Goto S, "Region-of-interest based H.264 encoding parameter allocation for low power video communication, Signal Processing & Its Applications", 5th International Colloquium on, pp. 233-237,2009.
- Chaoqiang L, Tao X, Hui L ."ROI and FOI Algorithms for Wavelet-Based Video Compression", Advances in Multimedia Information Processing, PCM 2004, Lecture Notes in Computer Science 3333, pp.241-248, 2004.
- Jatoth R.J, Gopisetty.S, Hussain.M, "Performance Analysis of Alpha Beta Filter, Kalman Filter and Meanshift for Object Tracking in Video Sequences", International Journal of Image, Graphics and Signal Processing, vol.7, no.3, pp.24-30, 2015.
- Byoung C.K and Jae-Yeal N , "Object-of-interest image segmentation based on human attention and semantic region clustering", J. Opt. Soc. Am. vol. A / 23(10), pp. 2462-2470, 2006.
- Esa R, Juho Ka, Mikko S, and Janne H, "Segmenting salient objects from images and videos", In Proceedings of the 11th European conference on Computer vision (ECCV'10), Springer-Verlag, Berlin, Heidelberg, pp.366-379,2010.
- Niu C, Liu Y, " Moving Object Segmentation in the H.264 Compressed Domain", ACCV 2009, Lecture Notes in Computer Science, vol. 5995, 2009,pp. 645-654.
- Lee Y.J, Kim J, Grauman K, "Key-segments for video object segmentation", IEEE International Conference on Computer Vision , pp. 6-13, 2011
- Jiebo L, Chang W.C, and Kevin J.P, "Face Location in Wavelet-Based Video Compression for High Perceptual Quality Video-conferencing", IEEE Transactions on Circuits and Systems for Video Technology, vol. 6, no.4, pp.411-415, 1996.
- Ali M.S, Ahmeed S.F, Loay E.G, "Fast Intra-frame compression for Video Conferencing using Adaptive Shift Coding", International Journal of Computer Applications ,vol. 81, no. 8, pp. 29-33,2013.
- Zeynep O, Abdulkadir B, Erdem K, "A Study On Face, Eye Detection And Gaze Estimation", International Journal of Computer Science & Engineering Survey, vol 2, no.3, pp.29-46, 2011.
- Tao G, "High-precision Immune Computation for Secure Face Recognition", International Journal of Security and Its Applications, vol. 6, no. 2, pp.293-298,2012.
- Sasikumar G and Tripathy B.K, "Design and Implementation of Face Recognition System in Matlab Using the Features of Lips, International Journal of Intelligent Systems and Applications, vol 8,pp.30-36 .2011.
- Taskeed J, Kabir M.H, Oksam C,"Robust Facial Expression Recognition Based on Local Directional Pattern", ETRI Journal, vol. 32, no.5, pp.784-794, 2010.
- Dong-Ju K, Lee S and Sohn M.K, "Face Recognition via Local Directional Pattern", International Journal of Security and its Applications, vol.7, no.2, pp.191-200,2013.
- Yasaman H, Abolfazl T.H, "An Efficient Face Detection Method Using Adaboost and Facial Parts", IJSSST, vol 12. no.4, pp.473-804,2011.
- Lee Y, Han D.K, Ko H (2013), Reinforced AdaBoost Learning for Object Detection with Local Pattern Representations, The Scientific World Journal, Article ID 153465, doi.org/10.1155/2013/153465.
- Ghimire D and Lee H, "Geometric Feature-Based Facial Expression Recognition in Image Sequences Using Multi-Class AdaBoost and Support Vector Machines", Sensors, vol.13, pp.7714-7734, 2013, doi:10.3390/s130607714.
- Baskoro H, Kim J.S, Kim C.S, "Mean-Shift Object Tracking with Discrete and Real AdaBoost Techniques", ETRI Journal, vol. 31, no.3, pp. 282-292, 2013.
- Kim K, Kang S, Chi S and Jaehong Kim, "Object Recognition on Horse Riding Simulator System", World Academy of Science, Engineering and Technology,vol.77, pp. 05-23,2009.
- Turk M and Pentland A, "Eigenfaces for recognition" , Journal of Cognitive Neuroscience archive, vol.3, no.11, pp.71-86,1991.
- Slavković M and Jevtić D, "Face Recognition Using Eigenface Approach", Serbian Journal of Electrical Engineering , vol. 9, no.1, pp.121-130,2012.
- Alireza Tofighi, Khairdoost. N., S. Amirhassan Monadjemi and Kamal Jamshidi, "A Robust Face Recognition System in Image and Video", International Journal of Image, Graphics and Signal Processing, vol.6, no. 8, pp.1-11, 2014.
- Prashanth K.G, Shashidhara M, "Real Time Detection and Tracking of Human Face using Skin Color Segmentation and Region Properties", International Journal of Image, Graphics and Signal Processing, vol. 6, no. 8, pp..40-46, 2014.
- R.L Hsu, M.A .Mottaleb,A.K.Jain, Face detection in color Images, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.24, 696-706, 2002.
- Face image database http://www.prima.inrialpes.fr/FGnet/html/benchmarks.html
- http://www.ee.surrey.ac.uk/
