Анализ двухуровневой информационной системы с репликацией данных

Автор: Мейкшан Л.И.
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Технологии компьютерных систем и сетей
Статья в выпуске: 2 т.7, 2009 года.
Бесплатный доступ
Рассматривается распределенная информационная система (ИС), состоящая из центральной базы данных (ЦБД) и совокупности локальных баз данных (ЛБД) для удаленных пользователей. С помощью асинхронной репликации в каждой ЛБД поддерживается копия некоторой части ЦБД. Для анализируемой ИС представлена математическая модель и с использованием этой модели показано, что при определенных условиях наличие локальных данных уменьшает среднее время обработки запроса, а также снижает затраты на передачу данных между отдельными элементами системы.
Короткий адрес: https://sciup.org/140191316
IDR: 140191316 | УДК: 621.395
Analysis of two-level information system with data replication
Distributed information system (IS) is considered with main (central) database (MDB) and collection of local databases (LDBs) at remote user workstations. With the help of asynchronous replication mechanisms a copy of certain part of MDB is maintained in each LDB. Mathematical model for analyzed system is presented and by means of this model it is demonstrated that under certain conditions the presence of local data decreases the mean duration of query processing and reduces as well expenses for data transmission between separate elements of IS.
Текст научной статьи Анализ двухуровневой информационной системы с репликацией данных
Появление технологии баз данных первоначально привело к централизованной поддержке и обработке больших объемов данных. Однако в дальнейшем под влиянием быстрого развития инфокоммуникационных технологий (мощные персональные компьютеры, цифровые сети связи, Internet) значительно усилились противоположные факторы децентрализации процессов хранения и обработки данных [1]. Одним из самых существенных достижений в этой области считается создание программных средств для управления распределенными базами данных.
Все дело в том, что децентрализованный подход в большей степени соответствует организационной структуре многих крупных корпораций, состоящих из отдельных функциональных подразделений и филиалов, которые географически распределены в пределах обширной территории. При этом каждая достаточно самостоятельная организационная единица всегда имеет дело с собственным набором данных, необходимых для управления соответствующими бизнес-процес-сами.
Не вызывает сомнений, что распределенные БД, способные обеспечивать требуемый уровень доступности данных, производительности и надежности, являются гораздо более сложными аппаратно-программными комплексами по сравнению с сосредоточенными системами. В частности, дополнительные предпосылки для усложнения создаются при использовании технологии тиражирования (репликации) данных [2-4]. Если соответствующие механизмы функционируют недостаточно эффективно, то преимущества рас- пределенной архитектуры превращаются в ее недостатки.
Описание исследуемой системы
В рассматриваемой информационной системе (ИС) центральный узел содержит основной (эталонный) экземпляр базы данных и получает все ее обновления (соответствующие запросы образуют пуассоновский поток со средней интенсивностью λ u ). Кроме того, на каждой рабочей станции имеется локальная БД, где хранится некоторая доля ( h е[0;1]) центральной БД. Следовательно, с вероятностью h поступающий запрос на обновление относится к тиражируемым данным, поэтому обработка такого запроса сопровождается рассылкой корректирующих сообщений в соответствующие ЛБД. Такая структура распределенной ИС может использоваться при наличии центрального офиса компании и нескольких территориально удаленных филиалов.
Применение псевдокопий, когда при заданных требованиях к когерентности данных допускаются определенные несоответствия между оригиналом объекта в ЦБД и его образом в ЛБД, позволяет снизить фактическое число отправляемых сообщений. Разные уровни когерентности для тиражируемых данных будем характеризовать коэффициентом q ^ [0;1], причем q = 1 означает полное совпадение между оригиналами объектов и их копиями в локальных БД. Тогда вероятность того, что обработка поступившего запроса на обновление потребует рассылки сообщений с новыми данными, равна hq .
Каждая из n рабочих станций принимает от своих пользователей поисковые запросы, посту-пающиесосреднейинтенсивностью λ q . Предполагается, что для отдельно взятой рабочей станции информационные потребности пользователей имеют четко выраженную направленность, учитываемую при формировании соответствующей ЛБД. Чтобы количественно выразить более высокую вероятность обращения к локальным данным, вводится дополнительный параметр f е [1;1/ h] . С учетом указанного параметра вероятность локальной обработки поискового запроса равна hf , а отправка этого запроса для обработки в ЦБД происходит с вероятностью 1- hf .
Математическая модель
Отдельные элементы рассматриваемой ИС (центральный узел и периферийные рабочие станции) моделируются с помощью однолинейных СМО типа M / G /1/ FCFS . При этом процессы обслуживания заявок разного вида характеризуются следующими величинами:
-
- среднее время обработки поискового запроса τ q (в центральной БД) и τ q ′ (в локальной БД);
-
- среднее время обработки запроса на обновление τ u ′ (в центральной БД) и τ u ′ (в локальной БД);
-
- среднее время, требуемое серверу центральной БД на отправку одного сообщения для обновления локальной БД τ b .
Время доставки сообщения, передаваемого между центральной БД и рабочей станцией, рассматривается как постоянная величина ( т r ). Задержки в предоставлении доступа к каналу связи не учитываются. При этом предположении «узким местом» для исследуемой распределенной системы могут быть серверы баз данных, но не телекоммуникационное оборудование.
Среднее время, в течение которого пользователь ожидает ответа системы на свой запрос, будем определять с помощью соотношения
R = hf [ W w + т q ] + (1 - hf )[2 т r + W c + T q ], (1) где W c и W w - средние значения времени пребывания запроса в очереди на обработку для центрального узла и рабочей станции, соответственно. Первое слагаемое в этом выражении соответствует случаю, когда с вероятностью hf запрос полностью обслуживается в локальной БД, а второе слагаемое относится к обработке запроса в центральной БД (вероятность такой ситуации равна 1 - hf ).
На рабочей станции имеется два вида заявок:
-
- поисковые запросы от пользователей – поступают с интенсивностью 1 { = hf 1 q и каждый из них требует для своего обслуживания среднего времени Θ 1 ′=τ q ′ ;
-
- запросы на обновление данных в локальной БД - возникают с интенсивностью ^ = hq ^ u и отдельная транзакция выполняется за среднее время Θ′ 2 =τ u ′ .
Для математического ожидания и второго момента случайного времени обслуживания ( X ) заявки можно записать:
e[ x ] = (А' / ^ )®i + № / ^ )®2;
E[X2 ] = 2[(Л1 / 2)(©‘ )2 + (22 / 2)(©2 )2 ], где 2 = 21' + 2 22. Тогда с помощью формулы
Поллячека-Хинчина получаем:
W
w
2E[X2 ] _ A{©1 + A2^2
2(1 - 2 E[X]) = 1 - ( A ’+ A 2 ) ,
где Ai = 2i®' = hf2qTq ; A = 22®2 = hq^TU .
Центральный узел характеризуется наличием трех категорий заявок: запросы на обновление данных – интенсивность поступления λ 1 = λ u и среднее время выполнения запроса ® 1 = т u ; требования на отправку корректирующих сообщений для обновления копий в локальных БД – возникают с интенсивностью λ 2 = hqλ u и в каждом случае процедура рассылки осуществляется за среднее время ® 2 = пт ь ; поисковые запросы от рабочих станций – поступают с интенсивностью 2 3 = n (1 - hf ) 2 q и процесс обработки отдельного запроса имеет среднюю длительность @ 3 = т q . При этих условиях применение формулы Поллячека-Хинчина дает следующий результат:
W = Ai®i + A2®2 + Аз®з c 1 - (A + A2 + A3 )
где A i = 2 1 © 1 = 2 u т u ; A 2 = 2 2 © 2 = nhqX u T ь ; A 3 = 2 3 © 3 = n (1 - hf ) 2 q T q .
Введемследующиедополнительныеобозначе-ния: A u = λ u τ u – загрузка сервера центральной БД обработкой запросов на обновление; A q = λ q τ q – загрузка сервера центральной БД поисковыми запросами от одной рабочей станции (если бы все из них полностью обрабатывались этим сервером); коэффициент в = т qq / т q = т'и / т u - характеризует соотношение между быстродействием локальной БД и центральной БД; коэффициент Y = т u / т q = т U / т q - определяет соотношение между затратами времени на обработку поискового запроса и запроса на обновление; ω= τ b /τ q ; g = τ r /τ q . С учетом этих обозначений получим: A 1 = hfв A q ; A 2 = hq в A u ; A 1 = A u ; A 2 = nhq rn A u / y ; A 3 = n (1 - hf ) A q .
В дальнейшем при оценке времени реакции исследуемой распределенной системы выберем в качестве условной единицы времени (у.е.в.) величину τ q . Тогда формула (1) преобразуется к следующему виду:
R* =— = hf[wW + в] + (1 - hf)[2g + Wc* +1], (2) τq где Ww
Ww = в (A{ + Y A2 ) Tq 1 - ( A{ + A2 ) ,
* W c _ Y A 1 + n Ю A 2 + A 3
■
T q 1 - ( A 1 + A 2 + A 3 )
Среднее количество сообщений, передаваемых за единицу времени между центральным узлом и периферийными станциями, равно
M = 2 n (1 - fh )2 q + nhq 2 u .
Здесь первое слагаемое относится к поисковым запросам, для которых необходимые данные отсутствуют на рабочих станциях, а второе слагаемое обусловлено сообщениями, с помощью которых происходит обновление данных в локальных БД.
Если перейти к введенной ранее условной единице времени ( т q ), то получим
M * = M т q = 2 n (1 - fh) A q + nhqA u / Y ■ (3)
Численные результаты
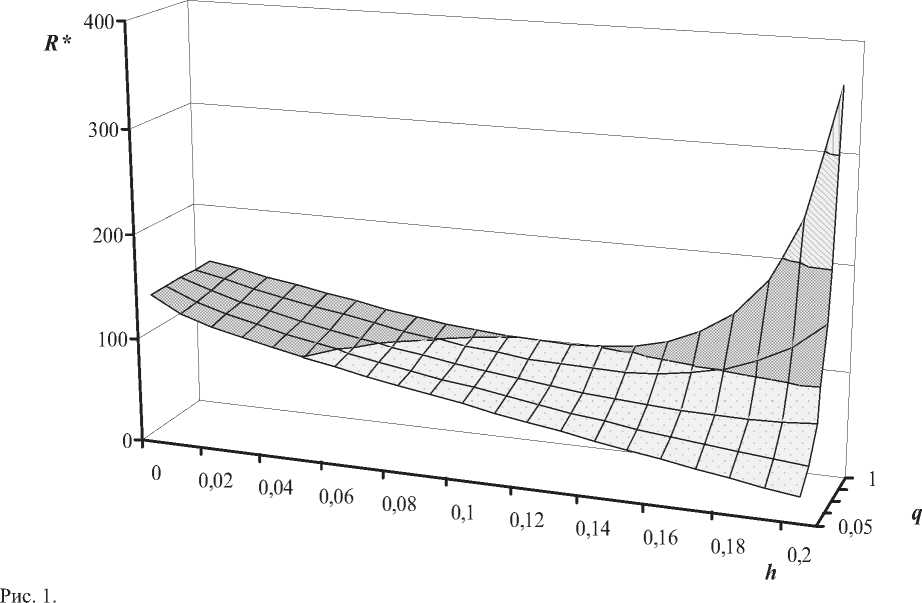
В графическом виде зависимость R * = f (h, q) , полученная с помощью расчетов по формуле (2), представлена на рис. 1. Эти расчеты, которые позволяют выявить общий характер изменения времени реакции рассматриваемой ИС в ( h , g )-пространстве, производились при следующих значениях остальных параметров, характеризующих структуру системы и происходящие в ней процессы: n = 150; A u = 0,2; A q = 0,005; f = 5; β = 20; γ = 2; ω = 0,15; g = 60.
Чтобы более детально исследовать, каким образом среднее время обработки запроса зависит от величины h , определяющей размер локальной БД (тоестьстепеньрепликацииданных),рассмот-рим семейство кривых на рис. 2 для нескольких фиксированных значений индекса когерентности данных ( q ). Перед анализом этих результатов напомним, что h = 0 означает полное отсутствие локальных БД, то есть все поисковые запросы от пользователей рабочих станций проходят обработку в центральном узле. Если h = 0,2; то каждая рабочая станция содержит 20% данных из состава центральной БД, и при заданном значении f = 5 все поисковые запросы будут обслуживаться локально.
Если q = 1, то для каждого объекта БД его локальная копия не должна отличаться от своего оригинала. В этом случае (при выбранных параметрах системы) репликация данных не всегда целесообразна, что обусловлено несколькими противодействующими факторами. В частности, по мере увеличения h нагрузка, создаваемая обработкой поисковых запросов, постепенно переносится с центрального узла на рабочие станции. Однако при этом на центральном узле увеличивается объем работы по рассылке сообщений для обновления данных, хранящихся в локальных БД. Кроме того, при h ^ 0,2 начинает возникать эффект перегруженности рабочих станций, которые помимо обслуживания поисковых запросов от своих пользователей должны еще производить
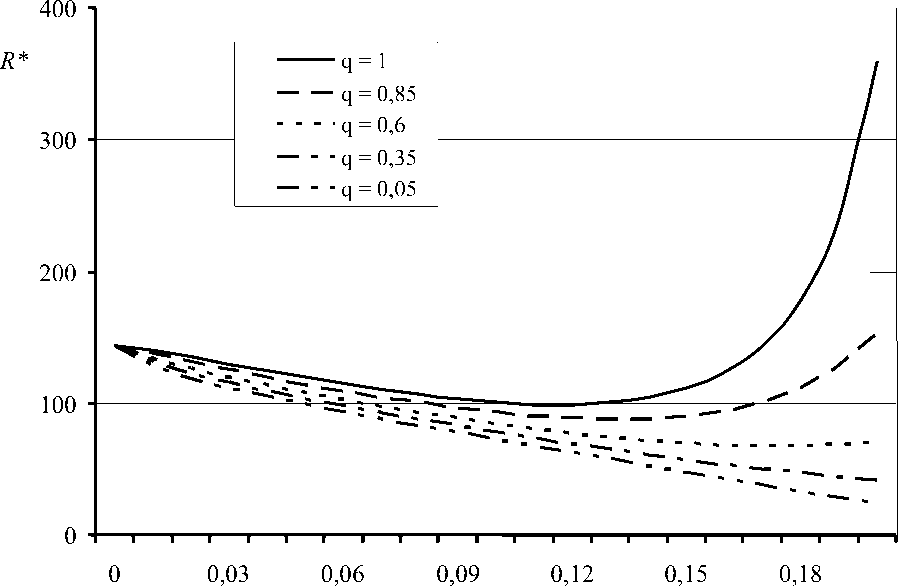
Рис. 2.
h
обновление локальных данных. Наилучшим вариантом является h = 0,117, когда за счет репли- *
кации данных время реакции системы ( R = 98,7 у.е.в.) почти в 1,5 раза снижается по сравнению с R * = 144 у.е.в. при h = 0.
При уменьшении q ситуация существенно меняется: любая копия, которая хранится в ЛБД, может отличаться от своего оригинала в ЦБД, поэтому уже не требуется при каждом обновлении оригинала рассылать корректирующие сообщения. Следовательно, из-за снижения затрат на поддержку согласованности тиражируемых данных ускоряется обработка поисковых запросов: когда q = 0,85; время реакции системы достигает минимального значения R* = 87.9 у.е.в. при h = 0,132. Дальнейшее снижение требований к когерентности тиражируемых данных (q ≤ ) при водит к тому, что локальная обработка всех запросов от пользователей рабочих станций ( h = 0.2) становится наилучшим вариантом. В результате обеспечивается существенное повышение скорости обработки запросов: к примеру, для q = 0,35 величина R* = 41,3 у.е.в. в 3,5 раза меньше, чем при h = 0.
Чтобы проследить, каким образом степень репликации данных (h) влияет на загруженность каналов связи (сетевой трафик), рассмотрим соотношение (3) как функциональную зависимость
*
M = ф (h). Эта зависимость относится к типу ф (h) = ah + b, где a = n(qAu / Y - 2 fAq ) , (4) и b= 2 nAq . Следовательно, при а < 0 увеличение размера ЛБД будет приводить к снижению сетевого трафика по сравнению с исходным вариантом, который характеризуется отсутствием репликации данных ( h = 0).
С учетом (4) неравенство a < 0 преобразуется к следующему условию: q < 2 fA q y I A u . Для индекса когерентности тиражируемых данных это условие ограничивает область тех значений, при которых обеспечивается выигрыш с точки зрения интенсивностипотоковсообщений,передаваемых между центральной БД и рабочими станциями.
Для иллюстрации выявленных закономерностей, которые относятся к процессам обмена данными между отдельными элементами рассматриваемой ИС, на рис. 3 представлены графические зависимости M * = ф (h) при нескольких значениях q . Остальные параметры, входящие в соотношение (2), сохраняли указанные ранее значения.
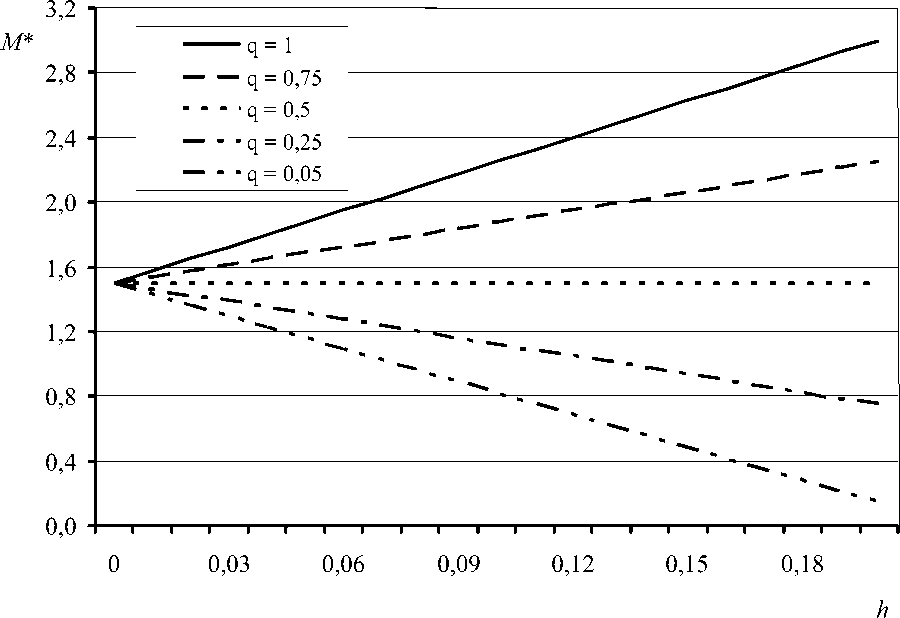
Рис. 3.
Заключение
В крупных ИС с распределенной архитектурой репликация данных обеспечивает целый ряд важных преимуществ: увеличение доступности данных и надежности системы (поскольку при потере соединения с одним из серверов работа может продолжаться с идентичными данными на другом сервере); более равномерное распределение нагрузки по разным серверам; ускорение доступа к локальным данным и др. Вместе с тем, синхронная репликация предъявляет дополнительные требования к сетевым ресурсам и негативно влияет на производительность системы, поэтому все более популярным становится режим асинхронной репликации. Асинхронная репликация менее чувствительна к низкой пропускной способности каналов связи,до-пускает использование более дешевых технологий передачи данных и может происходить по расписанию (например, раз в сутки в ночное время) при отсутствии постоянного соединения с главной БД, но все это приводит к несоответствиям (расхождениям) между копиями данных и их оригиналами.
Таким образом, ввиду того, что разные технологии репликации данных обладают опреде- ленными достоинствами и недостатками, вопрос выбора наиболее рационального варианта организации внутрисистемных средств тиражирования данных в составе распределенной ИС требует тщательного изучения с использованием соответствующих математических моделей. В статье представлена одна из таких моделей для двухуровневой системы, построенной по архитектуре «клиент-сервер».
Список литературы Анализ двухуровневой информационной системы с репликацией данных
- Таненбаум Э., Ван Стеен М. Распределенные системы. Принципы и парадигмы. СПб.: Питер, 2003. -877 с.
- Барон Г., Ладыженский Г. Технология тиражирования данных в распределенных системах//Открытые системы. № 2, 1994. -С. 17-22.
- Коржов В. Базы данных идут в тираж//Системы управления базами данных. № 3, 1998. -С. 60-64.
- Калиниченко Б. Асинхронное тиражирование данных в гетерогенных средах//Системы управления базами данных. № 3, 1996. -С. 50-54.
