Анализ PDF-файлов на наличие вредоносного кода с применением методов машинного обучения

Автор: Д. В. Климов, В. А. Корякова
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 5 (4), 2025 года.
Бесплатный доступ
В статье рассматривается задача обнаружения вредоносного кода в PDF-файлах с применением методов машинного обучения. Актуальность исследования обусловлена широким распространением формата PDF и его активным использованием злоумышленниками для внедрения вредоносных скриптов, эксплуатации уязвимостей и удалённого выполнения кода. Традиционные подходы к анализу PDF-файлов, основанные на сигнатурном и эвристическом анализе, демонстрируют ограниченную эффективность при выявлении новых и обфусцированных угроз, что требует разработки более адаптивных методов защиты. В работе выполнен анализ структуры формата PDF и основных векторов атак, включая внедрение JavaScript-кода, манипуляции с таблицей кросс-ссылок и использование зашифрованных потоков данных. На основе открытого набора данных CIC-PDFMal2022 был сформирован датасет, содержащий вредоносные и безопасные PDF-файлы. Проведены этапы предварительной обработки данных и извлечения признаков, отражающих структурные и функциональные характеристики документов. Для классификации файлов была разработана модель машинного обучения на основе алгоритма Random Forest Classifier с оптимизацией гиперпараметров. Оценка качества модели проводилась с использованием метрик Accuracy, Precision, Recall, F1-score и ROC AUC. Экспериментальные результаты показали высокую точность классификации (около 99 %) и устойчивость модели к переобучению. Анализ важности признаков позволил выявить ключевые характеристики, влияющие на обнаружение вредоносного кода. Полученные результаты подтверждают эффективность применения машинного обучения для анализа безопасности PDF-файлов.
Машинное обучение, анализ PDF-файлов, вредоносный код, классификация, информационная безопасность.
Короткий адрес: https://sciup.org/14135233
IDR: 14135233 | DOI: 10.47813/2782-2818-2025-5-4-2072-2080
Текст статьи Анализ PDF-файлов на наличие вредоносного кода с применением методов машинного обучения
DOI:
В условиях стремительного развития интернет-технологий и постоянного совершенствования компьютерных приложений, а также системного программного обеспечения, наблюдается значительная трансформация в области киберугроз. В частности, резко возросло количество разнообразных видов вредоносного программного обеспечения [1]. Современные вредоносные программы характеризуются высокой степенью сложности, изменчивости и опасности для информационной безопасности [2]. Они представляют собой одну из ключевых угроз цифровой среды, поскольку способны незаметно и оперативно распространяться с использованием передовых методов, таких как инъекции кода, обход механизмов виртуализации, антиотладочные техники, использование упаковщиков, шифрование, а также реализация механизмов настойчивости [3,4].
Одним из набирающих популярность способов распространения вредоносного программного обеспечения является распространение вредоносного кода внутри PDF-файлов. Формат PDF, созданный компанией Adobe Systems в 1993 году, предназначен для хранения различных типов электронной информации. Его преимуществом является возможность чтения и печати PDF-файлов независимо от используемого программного обеспечения, оборудования или операционной системы. Однако злоумышленники часто встраивают вредоносный код в PDF-файлы и распространяют его для удаленного выполнения кода (RCE). Пользователи, не осознавая рисков, могут открыть эти файлы, что может привести к компрометации системной безопасности и утечке конфиденциальной информации. В связи с этим, возникает потребность в разработке эффективных методов анализа PDF-файлов на предмет обнаружения вредоносного кода.
Целью данного исследования является разработка методики обнаружения вредоносного кода в PDF-файлах путем обучения модели машинного обучения.
АНАЛИЗ ПОТЕНЦИАЛЬНЫХ УЯЗВИМОСТЕЙ В СТРУКТУРЕ PDF
Несмотря на многочисленные достоинства, такие как платформенная независимость, сохранение структуры документа и богатые функциональные возможности, сложная внутренняя организация PDF - файлов делает их потенциальной мишенью для кибератак.
Разнообразие форматов данных, поддержка сценариев, встроенные объекты и использование внешних библиотек открывают злоумышленникам широкие возможности для реализации 10 различных типов атак.
Основные угрозы безопасности, связанные с использованием PDF, включают следующие векторы атак:
-
• уязвимости в обработке объектов: злоумышленники могут создавать PDF-документы, содержащие специально
модифицированные объекты, которые при открытии вызывают переполнение буфера, позволяют выполнить произвольный код или приводят к сбоям в работе приложения. Такие атаки могут быть направлены на компрометацию системы пользователя или нарушение её нормального функционирования;
-
• javascript – внедрение: поскольку формат поддерживает встраивание скриптов,
злоумышленники могут использовать этот механизм для выполнения вредоносных действий, таких как сбор конфиденциальных данных, изменение параметров системы или инициирование загрузки и запуска вредоносного ПО на устройстве жертвы;
-
• использование уязвимостей в сторонних библиотеках: PDF-ридеры часто используют сторонние библиотеки для обработки графических элементов, шрифтов и других ресурсов документа. Уязвимости в этих библиотеках могут быть эксплуатированы с целью получения несанкционированного доступа к системе. Атакующий может спроектировать файл таким образом, чтобы при его обработке происходило обращение к уязвимому коду, что может привести к выполнению вредоносного кода на уровне приложения или ядра операционной системы;
-
• уязвимости в таблице кросс-ссылок: изменяя её структуру или содержимое,
злоумышленник может повлиять на процесс разбора файла, перехватить управление потоком исполнения и организовать выполнение своей payload-части;
-
• уязвимости в алгоритмах сжатия: поскольку в PDF-файлах активно используются потоки, сжатые с помощью алгоритмов вроде LZW, Deflate или FlateDecode, наличие ошибок в реализации процедур декомпрессии может позволить злоумышленнику внедрить
вредоносный код в сжатую область и активировать его при открытии документа.
Эффективность различных подходов к обнаружению вредоносного кода в PDF-файлах варьируется в зависимости от типа угрозы, сложности обфускации и используемых методов и описана в таблице 1.
Таблица 1. Эффективность различных подходов к обнаружению вредоносного кода в PDF- ФАЙЛАХ .
Table 1. Effectiveness of different approaches to detecting malicious code in pdf files.
|
Метод |
Преимущества |
Недостатки |
Эффективность |
|
Сигнатурный анализ |
Быстро и эффективно для известных угроз |
Неэффективен против новых и полиморфных угроз |
Низкая-средняя |
|
Эвристический анализ |
Обнаруживает неизвестные угрозы на основе правил |
Может выдавать ложные срабатывания |
Средняя |
|
Динамический анализ |
Обнаруживает вредоносное поведение в реальном времени |
Требует изолированной среды, может быть замедленным |
Средняя |
|
Анализ JavaScript |
Обнаруживает вредоносный код в JavaScript-скриптах |
Требует знаний JavaScript, может быть обфусцированным |
Средняя-высокая |
|
Машинное обучение |
Адаптируется к новым угрозам, снижает ложные срабатывания |
Требует большого объема данных для обучения |
Средняя-высокая |
|
Ручной анализ |
Позволяет обнаружить любые изменения в PDF-файл |
Требует определённого уровня квалификации Очень затратен по времени Не работает если использована обфускация |
Высокая |
В настоящее время наиболее эффективными являются решения, комбинирующие несколько подходов, таких как сигнатурный анализ, эвристика или динамический анализ. Кроме того, важно постоянно обновлять базы данных сигнатур и алгоритмы обнаружения, чтобы обеспечить защиту от новых и развивающихся угроз. Специализированные инструменты анализа PDF, такие как peepdf и Origami
Framework, являются ценными ресурсами для экспертов по безопасности, позволяя им глубоко анализировать структуру PDF - файлов и выявлять сложные вредоносные программы.
Сравнительный анализ инструментов для анализа безопасности PDF-файлов представлен в таблице 2.
Таблица 2 . Сравнительный анализ инструментов для анализа безопасности PDF- ФАЙЛОВ .
Table 2. Comparative analysis of tools for pdf file security analysis.
|
Инструмент |
Особенности и функции |
Доступность |
|
Adobe Acrobat |
Создание, редактирование и просмотр PDF-документов Поддержка комментирования, подписывания и защиты документов Работа с интерактивными элементами, вложенными файлами и мультимедиа Частые обновления для повышения безопасности и устранения уязвимостей |
Платный |
|
PDF Analyzer |
Просмотр структуры документа и извлечение информации Поиск и фильтрация данных Экспорт результатов анализа в различные форматы |
Бесплатный |
|
Инструмент |
Особенности и функции |
Доступность |
|
Peepdf |
Изучение внутренней структуры PDF-файла Обнаружение потенциально вредоносного кода |
Бесплатный, с открытым исходным кодом |
|
Didier Stevens Suite |
Анализ и манипуляция PDF-файлами с целью выявления уязвимостей и вредоносного кода Извлечение метаданных, декодирование строк и выполнение сценариев |
Бесплатный, с открытым исходным кодом |
|
Foxit PhantomPDF |
Создание, редактирование, аннотирование и просмотр PDF-документов Защита данных, подписывание электронных документов и совместное использование файлов |
Платный |
Исходя из данных в таблице, выбор инструмента для анализа PDF - файлов должен основываться на специфических потребностях и задачах пользователя. Adobe Acrobat и Foxit PhantomPDF предлагают обширный функционал за определенную плату, в то время как PDF Analyzer, Peepdf и Didier Stevens Suite предоставляют бесплатные инструменты с различным уровнем функциональности и гибкостью. Каждый инструмент имеет свои преимущества и ограничения, и выбор определенного инструмента будет зависеть от конкретных требований и предпочтений пользователя, однако ни один из вышеперечисленных инструментов не обладает достаточным уровнем защиты от вредоносного кода.
МЕТОДИКА ВЫЯВЛЕНИЯ
ВРЕДОНОСНОГО КОДА В PDF- ФАЙЛАХ
Методика выявления вредоносного кода в PDF-файлах при помощи использования алгоритмов искусственного интеллекта предполагает анализ уникальных характеристик, включая объем файла, число листов, присутствие скриптов JavaScript и многих других. Эти характеристики анализируются и направляются в подготовленную модель, такую как классификатор случайного леса
(RandomForestClassifier) из библиотеки scikit-learn, которая применяет информацию из публичной базы данных KAGGLE для определения безопасности файлов. Система предсказывает присутствие вредоносных программ, а её результативность анализируется через показатели точности и полноты, демонстрируя умение корректно категоризировать новые файлы.
Методика начинается с формирования набора данных, в который включаются как заведомо безопасные PDF-файлы, так и образцы, содержащие вредоносный код. Эти файлы проходят предварительное исследование, в ходе которого уточняется их происхождение, метаданные и общие характеристики, чтобы обеспечить корректность разметки и равномерность распределения типов документов в обучающей выборке.
Затем происходит этап извлечения признаков. Из каждого PDF-файла выделяются структурные, содержательные и поведенческие характеристики, которые могут отражать потенциально опасные элементы. Анализируется внутренняя структура документа, количество и типы объектов, наличие встроенных скриптов, особенности использования потоков данных, статистика по шрифтам, изображениям и нестандартным конструкциям. Все эти параметры переводятся в числовые или категориальные признаки, пригодные для работы алгоритмов машинного обучения. Особое внимание уделяется тем элементам, которые исторически чаще встречаются в вредоносных файлах: например, аномальному количеству зашифрованных объектов или нетипичным параметрам JavaScript-блоков.
После извлечения признаков инициируется процесс обучения модели. Для этого выбирается подходящий алгоритм, который способен выявлять скрытые зависимости в данных. Это может быть модель классификации, построенная на деревьях решений, методах ансамблирования или нейронных сетях, обученных распознавать сложные закономерности. Модель постепенно подстраивается под набор признаков таким образом, чтобы различать безопасные и вредоносные документы, минимизируя ошибки классификации. Одновременно отслеживается переобучение, а также корректируется набор признаков, чтобы модель учитывала только информативные и устойчивые характеристики.
Следующим этапом является проверка PDF-файлов в контролируемой среде, но теперь поведенческие данные также служат входом для модели. Файл открывается в песочнице, анализируется его реакция и реакция системы. Генерируются дополнительные признаки, отражающие возможные попытки обращения к сети, запуск скрытых процессов, изменения системных файлов или взаимодействие с уязвимыми компонентами ПО. Эти динамические признаки обрабатываются моделью так же, как статические, расширяя её способность выявлять скрытые угрозы.
После завершения обучения проводится оценка точности и устойчивости модели. Используются тестовые наборы данных, не участвующие в обучении, чтобы определить её способность распознавать новые, ранее невиданные образцы. На основе анализа ошибок определяется, какие признаки требуется доработать, какие данные необходимо добавить, и насколько модель устойчива к неизвестным техникам обхода защиты.
В завершение методики обученная модель интегрируется в процесс анализа PDF-файлов. Новый документ сначала проходит автоматическое извлечение признаков, затем модель вычисляет вероятность того, что файл содержит вредоносный код. При выявлении риска специалист получает детализированную интерпретацию модели, показывающую, какие признаки повлияли на решение. Это позволяет понять, какой тип аномалии был обнаружен, насколько он критичен и какие дополнительные проверки могут понадобиться. В результате совмещение статических, динамических и машинных методов обеспечивает более глубокое и надёжное выявление вредоносных PDF-файлов, чем при использовании традиционных подходов.
Исходные данные для обучения модели были получены из открытого источника KAGGLE [5]. Данные включают 10025 записей, из которых 5557 являются вредоносными, а 4468 – не вреденосными. Перед обучением была проведена предварительная обработка данных. Были выполнены следующие шаги: преобразование категориальных признаков в числовые с помощью one-hot encoding, заполнение пропущенных значений, масштабирование числовых признаков с помощью StandardScaler, и создание алгоритма обнаружения ошибок. Из датасета были удалены неинформативные признаки, такие как имя файла, заголовок и номер страницы. Обработанные и используемые признаки включают размер файла, размер метаданных, количество страниц, длину таблицы кросс-ссылок, количество символов в заголовке, флаг шифрования, количество встроенных файлов, количество изображений, количество текстовых элементов, количество объектов, количество концов объектов, количество потоков, количество концов потоков, количество кросс-ссылок, количество трейлеров, начало кросс-ссылки, флаг первой страницы, флаг наличия JavaScript, количество JavaScript-кодов, флаг автоматических действий, флаг открытия действия, флаг наличия AcroForm, флаг наличия JBIG2Decode, флаг наличия RichMedia, флаг запуска, флаг наличия XFA, количество цветов и класс файла.
Процесс обучения модели включал разделение данных на тренировочную и тестовую выборки в соотношении 70/30, инициализацию RandomForestClassifier и оптимизацию гиперпараметров с помощью GridSearchCV. Оптимизация включала настройку количества деревьев, максимальной глубины, минимального количества объектов в листовом узле и количества признаков для разбиения. Обученная модель была оценена на тестовой выборке [6,7].
Для оценки качества модели на тестовых данных использовались метрики: Accuracy, True Positive (TP), True Negative (TN), False Positive (FP), и False Negative (FN). Обученная модель RandomForestClassifier показала точность Accuracy – 99 %. Анализ этих метрик подтверждает высокую точность классификации и способность модели к обобщению. На Рисунке 1 показана матрица распределения результатов по TN, FP, FN, TP.
Матрица ошибок
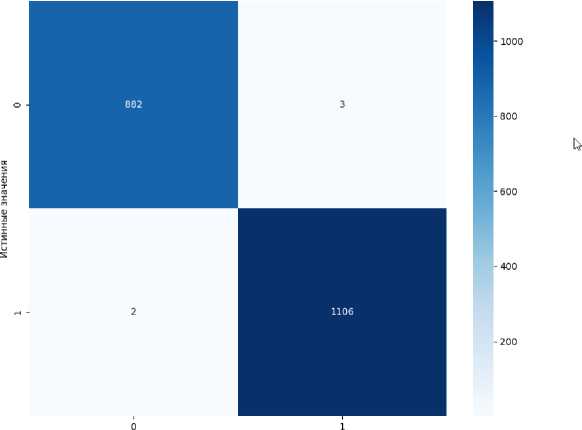
Предсказанные значения
Рисунок 1. Матрица ошибок.
Figure 1. Error matrix.
Матрица ошибок позволяет рассчитать другие точность, отзыв и F1-показатель, представленные показатели производительности, такие как в таблице 3.
Таблица 3. Показатели производительности моделей.
Table 3. Model performance indicators.
|
Алгоритм |
Accuracy |
Precision |
Recall |
F1-Score |
ROC AUC |
|
LogisticRegression |
0,952158 |
0,949936 |
0,954118 |
0,951589 |
0,976990 |
|
RandomForestClassifier |
0,991971 |
0,991920 |
0,991746 |
0,99183 |
0,999646 |
|
SupportVectorClassifier |
0,976246 |
0,975104 |
0,991746 |
0,975885 |
0,995620 |
|
DecisionTreeClassifier |
0,987956 |
0,988010 |
0,987486 |
0,987744 |
0,987486 |
|
GradientBoostingClassifier |
0,990967 |
0,991031 |
0,990593 |
0,99080 |
0,998603 |
|
MLPClassifier |
0,988960 |
0,988900 |
0,988639 |
0,988768 |
0,996047 |
Учитывая результаты, несколько алгоритмов показывают исключительную производительность с AUC 1,00. Однако помимо AUC, важно учитывать другие факторы, такие как баланс между точностью и отзывом, интерпретируемость и вычислительная эффективность. Алгоритм случайного леса демонстрирует лучшие результаты по всем показателям. У него самое низкое количество ложно-положительных результатов (13) и ложно - отрицательных результатов (11), что приводит к высокой точности (0,99), точности (0,99), отзыву (0,99) и F1-показателю (0,99). Более того, Random Forest – это алгоритм, который хорошо известен своей надежностью и способностью обрабатывать сложные наборы данных без значительной перенастройки. Он менее склонен к переобучению по сравнению с отдельными деревьями решений, что делает его более надежным для невидимых данных.
Хотя алгоритмы градиентного бустинга и MLP-классификатора также показывают отличные результаты, Random Forest часто предпочитают из-за его интерпретируемости и вычислительной эффективности. Градиентный бустинг может быть чувствителен к 42 переподгонке и требует тщательной настройки, а MLP - классификаторы, будучи мощными, являются «черными ящиками», которые трудно интерпретировать. SVM также обеспечивает высокую производительность, но могут быть менее масштабируемыми для больших наборов данных по сравнению со случайным лесом.
Логистическая регрессия, хотя и является интерпретируемой и вычислительно эффективной, демонстрирует немного более низкую производительность по сравнению с другими алгоритмами, как указано в ее более низком значении AUC (0,98) и более высокой частоте ложно - отрицательных результатов. Таким образом, он может быть менее подходящим для решения задач, требующих высокой точности и полноты.
Для всесторонней оценки разработанной модели машинного обучения был проведен комплекс дополнительных исследований, направленных на изучение ее ключевых характеристик и поведенческих особенностей. Центральное место в этом анализе заняло исследование важност и признаков, позволившее выявить наиболее значимые факторы, 47 влияющие на принятие решений моделью. Этот анализ осуществлялся с применением современных методов интерпретируемости моделей, включая расчет значений SHAP (Shapley Additive Explanations) и анализ permutation importance.
Особое внимание было уделено визуализации внутренних механизмов работы модели. С помощью методов снижения размерности, таких как t - SNE (t - distributed Stochastic Neighbor Embedding) и UMAP (Uniform Manifold Approximation and Projection), удалось получить на глядное представление о пространстве признаков и характере распределения анализируемых образцов. Визуализация градиентов активации в сверточных слоях нейронной сети позволила проанализировать, на какие именно структурные элементы PDF-документов модель обращает особое внимание при классификации.
Дополнительно был проведен анализ ошибок классификации, выявивший систематические закономерности в случаях неправильного распознавания. Этот этап исследования показал, что наибольшие трудности модель испытывает при работе с особо сложными случаями обфускации, где вредоносные интенции искусно маскируются под легитимные операции. Для решения этой проблемы были разработаны специальные методы постобработки результатов, учитывающие контекстные особенности анализируемых документов.
Для интерпретации работы модели был проведен анализ важности признаков. С помощью функции feature_importances алгоритма Random Forest Classifier было определено, что наиболее значимыми признаками являются: размер метаданных (важность 14,28%), смещение от начала файла в таблицу перекрестных ссылок (важность 13,24%), и наличие кода javascript (важность 8,7%). На рисунке 2 показана диаграмма распределения важности признаков.
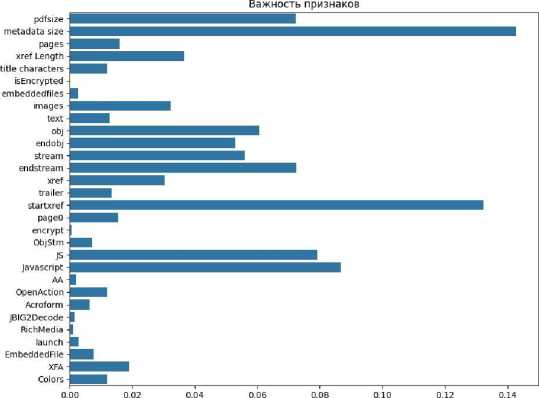
Важность
Рисунок 2. Диаграмма распределения важности признаков.
Figure 2. Feature importance distribution diagram.
Сохранение обученной модели для дальнейшего использования осуществлялось с помощью библиотеки joblib. Joblib оптимизирована для работы с большими массивами данных и моделями scikit-learn, обеспечивая быструю сериализацию и десериализацию. Блоки кода для сохранения, загрузки, извлечения признаков и применения модели к новым данным были реализованы и протестированы. Применение загруженной модели к новым PDF-файлам включает извлечение признаков, формирование DataFrame и выполнение функции прогнозирования.
ЗАКЛЮЧЕНИЕ
Была разработана и проанализирована модель машинного обучения для решения задачи анализа PDF-файлов на наличие вредоносного кода. Основные этапы включали сбор и предварительную обработку данных, выбор и реализацию алгоритма Random Forest Classifier,
