Анализ подходов к организации сборки проекта: компоновщик и пайплайн

Автор: А. В. Букреева, Д. А. Валиева, С. С. Голощапова, А. А. Ковтун
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 5 (3), 2025 года.
Бесплатный доступ
В статье проводится анализ архитектурных подходов к организации обработки и сборки данных в программных системах на основе паттернов Composite (компоновщик) и Pipeline (пайплайн), применяемых в контексте функционального программирования. Целью исследования является сопоставление этих паттернов с точки зрения их пригодности для решения прикладных задач в программной инженерии, а также выявление сильных и слабых сторон каждого подхода в условиях реального вычислительного окружения. Представлен обзор теоретических основ, описаны ключевые принципы построения систем с использованием указанных структурных решений, включая композицию, неизменяемость данных и модульность архитектуры. Работа включает в себя описание экспериментальной методики, охватывающей реализацию паттернов на языке программирования, построение тестовых сценариев с различными типами данных и структур, а также применение инструментов измерения производительности, памяти и масштабируемости. Особое внимание уделяется оценке расширяемости и читаемости кода, а также практическим аспектам реализации. Кроме того, рассматривается возможность комбинирования подходов для достижения баланса между гибкостью и эффективностью архитектурного решения. Результаты и наблюдения, полученные в ходе анализа, позволяют сформировать рекомендации по применению данных паттернов при проектировании и разработке современных программных систем с учетом их специфики и требований.
Архитектурные паттерны, компоновщик, пайплайн, производительность, масштабируемость, иерархичные структуры, Python
Короткий адрес: https://sciup.org/14135192
IDR: 14135192 | DOI: 10.47813/2782-2818-2025-5-3-1001-1008
Текст статьи Анализ подходов к организации сборки проекта: компоновщик и пайплайн
DOI:
Парадигма функционального стиля активно развивается, и всё большее внимание уделяется архитектурным подходам, которые используют композицию и потоковую обработку данных. Паттерны Composite (компоновщик) и Pipeline (пайплайн, конвейер) широко применяются на практике, но эффективность их применения в реальных вычислительных сценариях требует эмпирической оценки. Цель работы – сравнить указанные подходы по производительности, потреблению памяти и масштабируемости на основе экспериментальных данных и статистического анализа.
В контексте функционального подхода к проектированию систем важную роль играют принципы композиции, неизменяемости данных и предсказуемости выполнения. Два паттерна, которые будут рассмотрены в данной работе -Composite и Pipeline - предоставляют архитектурные решения для обработки сложных структур и потоков данных [1-2].
Composite применяется для организации объектов в иерархические структуры и обеспечения унифицированного интерфейса взаимодействия с отдельными элементами и их группами. Он активно используется, например, в файловых системах, DOM-деревьях (Document Object Model) – иерархическом представлении элементом веб-страницы, где каждый узел соответствует тегу, атрибуту или тексту, – и абстрактных синтаксических деревьях компиляторов [3-5].
Pipeline реализует последовательную обработку данных через цепочку преобразующих шагов. Это позволяет строить масштабируемые решения в задачах потоковой обработки, ETL-процессах (Extract, Transform, Load) – процесс извлечения, преобразования и загрузки данных, а также при работе с потоками данных в распределённых системах [5].
Для целей данной работы ключевым является не описание структуры паттернов, а оценка их поведения в реальных вычислительных сценариях, включая производительность, использование ресурсов и удобство расширения.
МАТЕРИАЛЫ И МЕТОДЫ
Цель эксперимента – получить прикладное сравнение паттернов Composite и Pipeline при решении типичных задач в программной инженерии. Оценка производилась по следующим ключевым метрикам: время выполнения алгоритмов, потребление оперативной памяти, масштабируемость при увеличении нагрузки, удобство расширения и читаемость кода.
Отдельно рассматривался гибридный сценарий, объединяющий оба паттерна, что помогло выявить возможные компромиссы между гибкостью и эффективностью.
Тестирование проводилось на двух независимых вычислительных платформах для исключения влияния аппаратного обеспечения или вычислительных ресурсов.
Таблица 1. Сравнение платформ. table 1. platform comparison.
|
Платформа |
Характеристики |
|
Локальная |
Intel Core i7-9700K (8 ядер/16 потоков), 16 GB RAM, Python 3.11 |
|
Облачная |
4 vCPU, 8 GB RAM, Ubuntu 22.04, Python 3.11 |
Оба программных окружения были приведены к идентичной конфигурации по библиотекам и версиям интерпретатора.
Для получения объективных данных использовались следующие инструменты:
-
• timeit – измерение времени микрофрагментов кода;
-
• pytest-benchmark – повторяемые замеры с
агрегацией статистики;
-
• memory_profiler – отслеживание пикового
потребления оперативной памяти;
-
• cProfile + pstats – анализ распределения времени по функциям;
-
• multiprocessing и concurrent.futures – реализация многопоточности и замеры ускорения при параллельной обработке [6].
Результаты работы программы записывались в файл формата CSV для последующей визуализации и анализа.
Для воспроизводимых и объективных замеров были смоделированы следующие ситуации:
-
• Pipeline: обработка списков данных от 10 тысяч до 1 миллиона элементов (целые числа, строки, вложенные коллекции), сборка цепочек из 2–10 шагов трансформации, сравнение eager- и lazy-реализаций: eager – жадная загрузка, вычисления сразу при
объявлении, lazy – ленивая загрузка, вычисления откладываются до момента реального использования;
-
• Composite: генерация сбалансированных,
несбалансированных и случайных деревьев глубиной от 10 до 50 уровней и шириной до 200 ветвей;
-
• Гибрид: агрегирование данных через
Composite и их последующая обработка через Pipeline.
Все сценарии предусматривали динамическое создание данных и вариативность структуры. Каждый эксперимент запускался от 20 до 30 раз для минимизации случайных отклонений. Для количественных показателей рассчитывались такие данные, как среднее значение, стандартное отклонение и 95% доверительный интервал. Кроме того, вычислялись p-значения по двухвыборочному t-тесту (при α=0.05) для оценки значимости различий между реализациями.
Дополнительно оценивались субъективные характеристики кода, такие как читаемость и расширяемость. Эти оценки основывались на разборе и сравнении объёма кода, его структуры и количества изменений, необходимых при добавлении новых элементов или шагов обработки. Выводы носили качественный характер и подкреплялись примерами из реализации.
Для проведения экспериментального анализа были реализованы упрощённые версии паттернов Composite и Pipeline на языке Python. Это позволило стандартизировать нагрузочные тесты и объективно измерить ключевые метрики. Ниже представлен базовый код, демонстрирующий суть реализации.
Листинг 1. Упрощённые версии паттернов C OMPOSITE и Pipeline.
Listing 1. Simplified versions of the Composite and Pipeline patterns.
class Component:
def operation(self): pass class Leaf(Component):
def operation(self): results = []
for child in self.children:
Рассмотрим из чего состоит этот код. Composite представляет структуру с узлами (Component) и листьями (Leaf), реализующими метод operation(), который рекурсивно обрабатывает все дочерние элементы. Pipeline строит цепочку функций, которые последовательно применяются к входным данным через метод execute() [7].
Этот код лёгок для понимания и модификации, что позволяет исследовать влияние различных параметров (размер данных, глубина дерева, количество шагов конвейера) на производительность и потребление памяти.
Также рассмотрим базовый код гибридного режима.
Листинг 2. Базовый код гибридного режима. Listing 2. Basic code of the hybrid mode.
def hybrid_example():
-
# Сборка иерархии через
Composite root = Composite()
for i in range(5):
j))
def operation(self):
Composite (вложенные списки)
class Composite(Component): data = root.operation()
def __init__(self):
-
# Уплощение данных (flatten) def flatten(lst):
flat = []
for item in lst:
if isinstance(item, list):
else:
-
# Обработка через Pipeline
pipeline = Pipeline()
pipeline.add_step(lambda x:[v for v in x if v % 2 ==0])
pipeline.add_step(lambda x:[v
+ 1 for v in x])
pipeline.add_step(sum)
result= pipeline.execute(flat_data)
print("Результат гибридной обработки:", result)
Гибридный метод сначала использует паттерн Composite для построения иерархии объектов и получения вложенное структуры. Затем данная структура упрощается до линейного списка, после чего данные обрабатываются через цепочку шагов Pipeline.
Такой подход помогает объединить агрегирование данных и их последовательную трансформацию, сохраняя читаемость и модульность кода.
Данная реализация была основой для всех измерений, результаты которых представлены в последующих разделах.
РЕЗУЛЬТАТЫ
Эксперимент 1. Линейные данные
Цель: сравнить поведение паттернов на простой последовательной задаче.
Сценарий: обрабатывать список из 1 000 000 целых чисел с выполнением последовательных операций (умножение на 2, фильтрация по условию х%3 == 0, суммирование).
Таблица 2. Результаты эксперимента 1.
Table 2. Experiment 1 Results.
|
Паттерн |
Время выполнения (с) |
Пиковое потребление памяти (MB) |
Расширяемость |
|
Composite |
1.62 ± 0.04 |
165 ± 6 |
низкая |
|
Pipeline (eager) |
0.89 ± 0.03 |
142 ± 5 |
высокая |
|
Pipeline (lazy) |
0.76 ± 0.02 |
118 ± 4 |
высокая |
Вывод: Composite-паттерн показывает избыточную сложность и слабую масштабируемость при линейной обработке. Pipeline демонстрирует лучшую производительность и минимальное накладные расходы, особенно в ленивой реализации.
Эксперимент 2. Иерархические структуры
Цель: определить преимущества и издержки использования паттернов при работе с древовидными структурами.
Сценарий: создается дерево глубиной 25 с 10 дочерними узлами на каждом уровне (≈100 000 узлов). Задача – суммировать все значения узлов.
Таблица 3. Результаты эксперимента 2.
Table 3. Experiment 2 Results.
|
Паттерн |
Время выполнения (с) |
Пиковое потребление памяти (MB) |
Особенности реализации |
|
Composite |
1.20 ± 0.03 |
152 ± 5 |
естественная работа с иерархией, возможна паралеллизация (+18%) |
|
Pipeline |
2.35 ± 0.07 |
198 ± 6 |
требуется преобразование структуры, теряется вложенность |
Вывод: Composite работает оптимально, Pipeline требует дополнительных преобразований и показывает худшую производительность. Использование Pipeline для иерархий нецелесообразно.
Эксперимент 3. Вложенные коллекции
Цель: выявить универсальность подходов при работе с JSON-подобными структурами
(JavaScript Object Notation) – текстовый формат обмена данных, основанные на синтаксисе объектов JavaScript.
Сценарий: список из 1000 вложенных списков, каждый из которых содержит 1000 чисел. Операции: Flatten – процесс преобразования вложенной структуры данных в одноуровневую, приращение и суммирование.
Таблица 4. Результаты эксперимента 3.
Table 4. Experiment 3 Results.
|
Паттерн |
Время выполнения (с) |
Пиковое потребление памяти (MB) |
Особенности реализации |
|
Composite |
1.85 ± 0.06 |
175 ± 7 |
заметная нагрузка при глубоком обходе |
|
Pipeline (eager) |
1.48 ± 0.05 |
160 ± 6 |
чуть выше расходы, но проще отладка |
|
Pipeline (lazy) |
1.22 ± 0.04 |
139 ± 5 |
лучшее соотношение скорость/память |
Вывод: Pipeline подходит для задач, где требуется работа с вложенностью – при условии предварительного уплощения. Composite менее гибок и требует ручной обработки иерархии.
Эксперимент 4. Гибридный подход: Composite + Pipeline
Цель: исследовать возможность комбинирования паттернов: сначала собрать иерархическую структуру, затем последовательно её обработать.
Сценарий: данные группировались через Composite, затем обрабатывались Pipeline-цепочкой из 5–10 шагов. Варьировалась глубина дерева (до 50) и длина конвейера (до 10 шагов).
Таблица 5. Результаты эксперимента 4.
Table 5. Experiment 4 Results.
|
Паттерн |
Время выполнения (с) |
Пиковое потребление памяти (MB) |
Усложнение архитектуры |
|
Гибридный |
1.80 ± 0.06 |
190 ± 7 |
заметный рост времени при высокой вложенности + длинной цепочке |
Вывод: гибридный подход полезен в задачах, где требуется сначала агрегировать данные по структуре, а затем применить обработку. Однако требует тонкой настройки: при глубине >30 и >5 шагов Pipeline наблюдается рост накладных расходов.
Сводные результаты экспериментов
Для наглядного сравнения паттернов представлена Таблица 6 с ключевыми метриками, отражающими производительность, потребление памяти и масштабируемость. Эти данные дают чёткое понимание, в каких сценариях каждый из паттернов демонстрирует свои сильные стороны [1].
Таблица 6. Сравнение паттернов.
Table 6. Comparison of patterns.
|
Паттерн |
Время (с) |
Память (MB) |
Масштабируемость |
Расширяемость |
Наиболее подходящие задачи |
|
Composite |
1.18 – 1.85 |
148 – 175 |
хорошая по ширине, ухудшается по глубине |
средняя |
иерархии, древовидные данные |
|
Паттерн |
Время (с) |
Память (MB) |
Масштабируемость |
Расширяемость |
Наиболее подходящие задачи |
|
Pipeline (eager) |
0.89 – 1.48 |
142 – 160 |
линейная, зависит от размера входных данных |
высокая |
потоковые задачи, где важна читаемость и отладка |
|
Pipeline (lazy) |
0.76 – 1.22 |
118 – 139 |
линейная, высокая при генераторах |
очень высокая |
большие объемы, эффективное использование памяти |
|
Composite + Pipeline |
1.80 ± 0.06 |
190 ± 7 |
смешанная: зависит от структуры и шагов |
умеренная |
иерархия и обработка |
На рисунке ниже визуально показано сравнение паттернов по времени выполнения (левый столбец) и пиковому потреблению памяти (правый столбец). Графики позволяют оценить компромиссы между производительностью и использованием ресурсов в разных архитектурных решениях.
Сравнение паттернов по времени выполнения и потреблению памяти
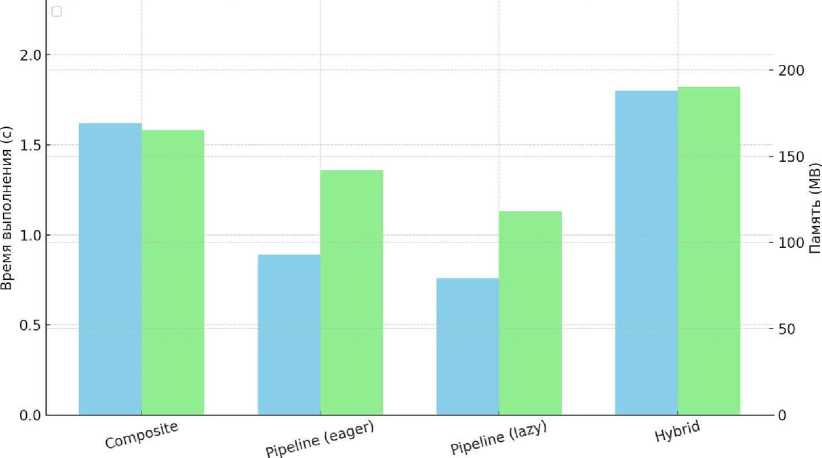
Рисунок 1. Сравнение паттернов по времени выполнения и потреблению памяти.
Figure 1. Comparison of patterns in terms of execution time and memory consumption
ОБСУЖДЕНИЕ
Проведённые эксперименты позволили выявить ключевые особенности и ограничения паттернов Composite и Pipeline, а также их гибридной комбинации.
Composite продемонстрировал свою эффективность в задачах с иерархическими структурами, обеспечивая единообразную обработку вложенных элементов. Однако его производительность заметно снижается при увеличении глубины дерева из-за рекурсивного обхода и накладных расходов на управление стеком вызовов. Параллельная обработка может улучшить производительность, но требует значительных изменений в архитектуре.
Pipeline, напротив, показал устойчивую линейную масштабируемость и эффективное использование памяти, особенно при реализации с ленивыми вычислениями (генераторами). Этот паттерн особенно хорошо подходит для потоковой обработки данных, например, в ETL-системах, где критичны скорость и простота расширения.
Гибридный подход, сочетающий Composite и Pipeline, может быть полезен в задачах, требующих как иерархической агрегации, так и последовательной обработки. Однако при увеличении глубины вложенности и длины цепочки обработки резко возрастают требования к памяти и времени выполнения, что требует тщательного проектирования.
Сравнение результатов подтверждает, что Composite лучше подходит для задач с динамическими структурами, а Pipeline — для потоковой обработки. Однако гибридный подход изучен меньше, и его применение требует дополнительных исследований.
ЗАКЛЮЧЕНИЕ
На основании проведённого исследования можно сделать следующие выводы:
-
• Composite следует применять в задачах с иерархическими структурами, где важна единообразная обработка вложенных
элементов.
-
• Pipeline оптимален для линейной, потоковой обработки данных, особенно при работе с большими объёмами информации.
-
• Гибридный подход эффективен в случаях, когда требуется совместить иерархическую агрегацию и последовательную обработку, но требует осторожности при проектировании из-за возможного снижения
производительности.
Выбор паттерна должен основываться на специфике задачи и её требованиях к производительности, масштабируемости и простоте поддержки. Полученные результаты могут служить практическим руководством при проектировании программных систем в парадигме функционального программирования.
Перспективы дальнейших исследований включают:
-
• Оптимизацию гибридного подхода для
снижения накладных расходов.
-
• Изучение влияния других паттернов на
производительность комбинированных решений.
-
• Разработку методик выбора оптимального паттерна на основе метрик сложности задачи.
