Анализ статистики продаж

Автор: Литовка М.К., Рожков М.С.
Журнал: Экономика и бизнес: теория и практика @economyandbusiness
Статья в выпуске: 8 (78), 2021 года.
Бесплатный доступ
В статье рассматриваются алгоритмы Data Mining для анализа продуктовой корзины магазина «Х». Авторами было проведено теоретическое исследование алгоритмов поиска ассоциативных правил и метода главных компонент; исследование возможностей применения алгоритмов Data mining для анализа продуктовой корзины; нахождение и исследование статистических данных в рыночной корзине потребителя, анализ рыночной корзины потребителя и выявление в ней ассоциативных правил с помощью алгоритма apriori, выявление стандартной годовой корзины покупателя с помощью метода главных компонент.
Продуктовая корзина, кластеризация, ассоциация, методы data mining
Короткий адрес: https://sciup.org/170183695
IDR: 170183695 | DOI: 10.24412/2411-0450-2021-8-111-122
Sales statistics analysis
The article deals with Data Mining algorithms for analyzing the shopping cart of store "X". The authors conducted a theoretical study of the algorithms for finding associative rules and the method of principal components; a study of the possibilities of applying Data mining algorithms to analyze the shopping cart; finding and researching statistical data in the market basket of consumers, analyzing the market basket of consumers and identifying associative rules in it using the apriori algorithm, identifying the standard annual shopping cart of a buyer using the method of principal components.
Текст научной статьи Анализ статистики продаж
В современном мире миллионы гигабайт информации находятся вокруг нас, ведь мы живем в такую эпоху цифрового развития, когда использовать эту информацию и оборачивать её в свою пользу просто необходимо. Экономические, медицинские, социальные сферы, в этих и не только областях используется технология Data mining, отвечающая на вопрос «Как обработать данную информацию с выгодой для себя и компании?». На данный вопрос дает ответ технология Data mining.
«Термин Data mining получил своё название из двух понятий: поиска ценной информации в больших базах данных Data и добыча горной руды Mining. Оба этих процесса или требуют огромного количества обработки или просеивания большого количества материала для разумного исследования и поиска искомых ценностей» [1].
Суть метода Data mining состоит в том, что с их помощью можно отыскивать ранее неизвестные знания, то есть знания должны быть новыми, а не подтверждение каких-либо ранее полученных сведений. Нетривиальных знаний – таких, которых нельзя просто так увидеть при построении визуального анализа или при вычислении простых статистических характеристик. Практически полезных - таких, которые представляют ценность для исследователя.
Доступы для интерпретации – те знания, которые можно представить в легко доступной для пользователя форме и легко объяснить в терминах предметной области. Эти требования во многом и определяют суть методов Data mining.
Преимущества Data mining:
-
- Малое количество ограничений на применение методов Data mining
-
- Поиск неочевидных закономерностей.
-
- Возможность работы с многомерными и данными огромного объема и сложной структуры.
-
- Применение методов Data mining – возможность извлечь пользу из накопленной информации.
Основные задачи, решаемые методом Data mining:
Классификация – определение класса объекта по его характеристикам.
Кластеризация – поиск независимых групп и характеристик во всем множестве данных.
Прогнозирование (регрессия) – подобно классификации, позволяет определить по известным характеристикам объекта значение некоторого его параметра, значением параметра является множество действительных чисел.
Ассоциация – нахождение частых взаимосвязей между объектами или события- ми, также могут быть использованы для предсказания появлений событий.
«Ассоциация – это функция интеллектуального анализа данных, которая обнаруживает вероятность одновременного появления элементов в коллекции. Отношения между сопутствующими элементами выражаются в виде ассоциативных правил» [2].
«Правила ассоциации часто используются для анализа сделок купли-продажи. Например, можно отметить, что клиенты, которые покупают хлопья в продуктовом магазине, часто покупают молоко одновременно. Фактически, ассоциативный анализ может обнаружить, что 85% кассовых сессий, включающих хлопья, также включают молоко» [3].
Это приложение ассоциативного моделирования называется анализ корзины. Это ценно для прямого маркетинга, продвижения продаж и выявления тенденций в бизнесе. Анализ корзины также можно эффективно использовать для макета магазина, дизайна каталога и перекрестных продаж.
Алгоритмы нахождения ассоциативных правил. Ассоциативные правила каждый день встречаются нам на различных сервисах, в магазинах, при онлайн покупках и других рекомендательных системах.
В общем виде ARL (правило ассоциации) звучит так – «Кто купил x, также купил y» [4].
«На данный момент существует несколько алгоритмов нахождения ассоциативных правил, в том числе: AIS и его продолжение SETM, Apriori, ECLAT и FP-growth» [5].
В данном исследовании был выбран Apriori алгоритм – самый популярный алгоритм ассоциативных правил майнинга. Он находит часто встречающиеся комбинации в базе данных и определяет правила ассоциации между элементами на основе 3 важных факторов:
Поддержка : вероятность того, что X и Y объединятся.
Уверенность : как часто Y происходит, когда X происходит первым.
Достоверность : соотношение поддержки и уверенности.
Для применения алгоритма необходимо изначально произвести обработку наших данных.
-
1 .Привести все данные к бинарному виду.
-
2 . Также необходимо изменить саму структуры данных.
Есть два этапа работы этого алгоритма, на первом подчитываются часто встречающиеся наборы, предварительно необходимо задать нужные значения поддержки и достоверности, а на втором извлечь из полученных данных уже сами правила.
Алгоритм apriori. Данный алгоритм напрямую связан с анализом корзины покупателя. Постановка задачи: имеется база данных одной из точек магазина Х, она состоит из чеков клиентов, где содержатся различные наборы покупок. Иными сло- вами, каждая покупка – это транзакция, определяющая купленный набор товаров одним покупателем. Необходимо при помощи алгоритма apriori выявить ассоциа- тивные правила.
«Определение: Пусть I = {i1,i2,i3,... in,} - множество товаров (элементы). Пусть D - множество транзакций, где каждая тран закция Т - это набор элементов из I, Т с I» [6]. Каждая транзакция представляет собой бинарный вектор, где t[k] = 1, если ik элемент присутствует в транзакции, иначе t[k] = 0. Транзакция Т содержит, некоторый набор элементов из I, если X с Т [6]»
«Ассоциативное правило определяется как импликация X ^ Y, где X с I, Y с I и X с Y =0 [6]. Поддержкой правила X ^ Y называется величина support s, если s% транзакций из D, содержат X U Y, »
supp(X ^ Y) = supp(X U Y).
«Достоверность правила определяет то, какова вероятность того, что из X следует Y. Достоверностью правила X ^ Y называ ется величина confidence c, если c% тран закций из D, содержащих X, также содер жат Y, [6]»
supp(XuY) supp(X) .
conf(X ^ Y)
«Алгоритмы нахождения ассоциативных правил разработаны в первую очередь для определения всех возможных комби- наций (правил) X ^ X с поддержкой и до- стоверностью больше, чем заранее опре- деленных пользователем порогов
(thresholds), которые обозначают как ми- нимальная поддержка и достоверность – minsupp и minconf» [7].
Далее рассмотрим еще один показатель: lift conf(X^Y) SUPP(Y) .
Hft(X ^Y) =
Также показатель lift обладает свой- ством:
Hft(X ^ Y) = Hft(Y ^ X).
Иными словами, он показывает во сколько раз увеличивается вероятность покупки одного набора, при покупке другого.
Кроме анализа рыночной корзины покупателя этот алгоритм применим ко множеству других сфер. Например: медицина и различные исследования в ней, анализ различных данных в бизнесе для увеличения показателей.
Метод главных компонент (Principal component analysis). «Метод главных ком- понент – это технология многомерного статистического анализа, используемая для сокращения размерности пространства признаков с минимальной потерей полезной информации. Предложен K. Пирсоном в 1901 г., а затем детально разработан американским экономистом и статистиком Г. Хоттелингом» [8].
«С точки зрения математики этот метод представляет из себя ортогональное ли нейное преобразование, отображающее данные из исходного пространства в новое пространство меньшей размерности с сохранением основных(значимых) данных» [9, с. 78-81].
При это построение новой базы строится таким образом, чтобы дисперсия в новой компоненте была максимальна. Вторая компонента строится перпендикулярно первой, чтобы дисперсия данных была максимальной их оставшихся возможных и так далее.
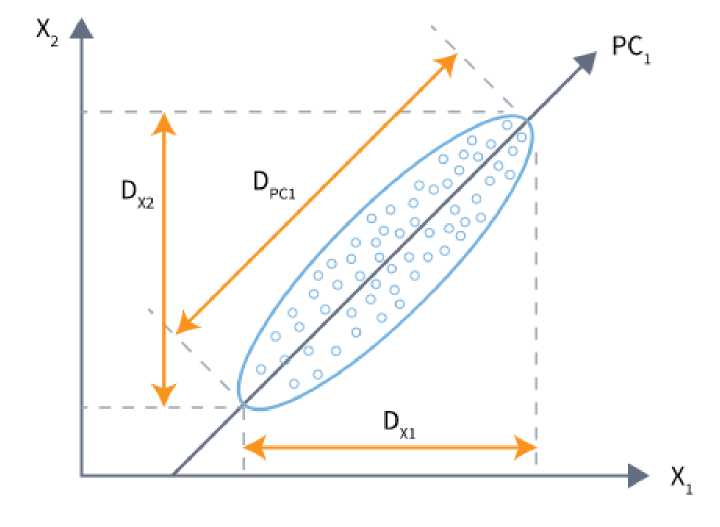
Рис. 1. Снижение размерности исходного 2-мерного пространства с помощью метода главных компонент до 1-мерного
«PC1 (главная компонента) ориентированная вдоль направления наибольшей вытянутости эллипсоида рассеяния точек объектов исходного набора данных в про- странстве признаков, иными словами с ней связана наибольшая дисперсия» (рис. 1)» [9, с. 85].
«На рисунке можно увидеть, что проекция дисперсии данных на ось первой главной компоненты, больше, чем её проекции на исходные оси DX1 и DX2, но меньше их суммы. Иными словами, первой главной компонентой отразить всю дисперсию данных не получилось. В таком случае строят вторую, третью и т.д. главные компоненты, пока они суммарно не отразят большую часть дисперсии» [8].
Таким образом, смысл метода главных компонент в том, что каждая главная компонента связана с определенной долей общей дисперсии исходной базы данных.
В данном случае, при нахождении среднегодовой корзины потребителя дисперсия, может отражать уровень информативности данных.
«Основной целью является отбор максимально изменчивых компонентов, поэтому первая главная компонента имеет максимальную выборочную дисперсию» [10]. Алгоритм таким образом подбирает веса чтобы разброс первой главной компоненты был максимально возможным при условии, что сумма будет 1. После формирования первой главной компоненты можно сформировать вторую ее веса алгоритм подбирает так, чтобы она была некоррелированная с первой главной компонентой, и чтобы сама компонента была с максимальной дисперсией для себя. Таким же образом побираются веса последующих главных компонент.
Анализ и обработка данных. Проанализируем данные о составе покупок в среднем за год покупателей одной из торговых точек магазина «Х». База данных представляет собой транзакции покупателей магазина за один год, состоящие из 43 товаров и 60467 операций (транзакций), где каждая строчка представляет собой один чек покупателя. База данных состоит из 43 товаров, кодов к ним, также имеется вторая база с расшифровкой этих товаров, общего количества потраченных денег на товары. Для начала работы с данными проведем первичный анализ данных и подсчитаем статистики по каждому из товаров. Результаты расчетов приведены в таблице 1.
Таблица 1. Статистические показатели классов товаров
|
Класс товаров |
Максимум |
Среднее значение |
Дисперсия |
Стандартное отклонение |
|
|
201 |
Бакалея |
22565.1 |
139.5305 |
289539.2 |
538.0885 |
|
202 |
Детское питание |
10733.6 |
23.9079 |
45544.91 |
213.4125 |
|
203 |
Здоровое питание |
7257 |
15.47595 |
16845.68 |
129.7909 |
|
204 |
Не мучные кондитерские изделия |
109679.9 |
467.7868 |
2953418 |
1718.551 |
|
205 |
Консервация |
44135.6 |
121.9103 |
292792.1 |
541.1026 |
|
206 |
Масло растительное |
8236.6 |
23.7314 |
17173.4 |
131.0473 |
|
207 |
Снеки, орехи, сухофрукты |
44007.6 |
71.76888 |
164839 |
406.0037 |
|
209 |
Чай, кофе |
26595.1 |
130.0431 |
252234.4 |
502.2294 |
|
210 |
Алкогольные напитки |
152993.3 |
210.8441 |
2324303 |
1524.567 |
|
211 |
Безалкогольные напитки |
33966.2 |
106.1894 |
285393.6 |
534.2224 |
|
213 |
Пиво |
55716 |
48.9884 |
267265 |
516.9768 |
|
214 |
Овощи, фрукты, грибы свежие |
107474.8 |
922.1909 |
10804447 |
3287.012 |
|
215 |
Хлеб и хлебобулочные изделия |
23660.8 |
192.0647 |
455097 |
674.6088 |
|
216 |
Молочные продукты |
50934.3 |
486.6373 |
3231544 |
1797.65 |
|
217 |
Сыры |
132476.3 |
543.4093 |
5094193 |
2257.032 |
|
218 |
Масложировая продукция |
20197.4 |
123.431 |
260198.7 |
510.0968 |
|
221 |
Замороженные продукты |
31648.7 |
256.751 |
889491.9 |
943.1288 |
|
222 |
Рыбный гастроном |
35414.7 |
119.3019 |
401788.5 |
633.8679 |
|
223 |
Колбасы |
169589.5 |
816.5619 |
11086149 |
3329.587 |
|
224 |
Готовая Продукция |
190201.2 |
434.9755 |
7063231 |
2657.674 |
|
225 |
Мучные кондитерские изделия |
138795.2 |
294.0508 |
1455889 |
1206.602 |
|
226 |
П/ф высокой степени готовности |
33169 |
64.61243 |
213533.9 |
462.0972 |
|
227 |
Мясная продукция охлажденная |
41724 |
208.7144 |
1043510 |
1021.524 |
|
228 |
Рыбные товары охлажденные |
1119.8 |
0.1675377 |
82.23485 |
9.068343 |
|
230 |
Яйцо |
16491.1 |
50.24908 |
61446.45 |
247.8839 |
|
401 |
Табачные изделия |
26166 |
39.20327 |
140989.2 |
375.4852 |
|
Класс товаров |
Максимум |
Среднее значение |
Дисперсия |
Стандартное отклонение |
|
|
404 |
Цветоводство, садоводство |
2885.5 |
9.61341 |
3882.89 |
62.31284 |
|
405 |
Одежда |
4670.3 |
19.07044 |
14091.94 |
118.7095 |
|
408 |
Текстиль д/домашнего обихода |
2180 |
1.632872 |
1495.782 |
38.67534 |
|
409 |
Сумки, пакеты Семья |
2965.4 |
9.845587 |
2342.95 |
48.40403 |
|
411 |
Товары для праздника |
2132.9 |
3.748371 |
1021.547 |
31.96165 |
|
413 |
Электробытовые товары |
1820.1 |
2.737349 |
909.9458 |
30.16531 |
|
414 |
Авто товары |
813.7 |
0.4437941 |
132.6267 |
11.51637 |
|
415 |
Школьно-письм. и канцелярские товары |
1022.4 |
1.171547 |
271.7985 |
16.48631 |
|
416 |
Хозяйственные товары |
5322.1 |
9.294033 |
4950.309 |
70.35843 |
|
417 |
Посуда для приготовления и сервировки |
8042.9 |
10.213 |
10928.66 |
104.5402 |
|
419 |
Печатная продукция |
17548 |
22.06552 |
35207.36 |
187.6362 |
|
425 |
Бытовая химия |
13300.8 |
27.77398 |
32672.35 |
180.755 |
|
427 |
Парфюмерно-косметическая продукция |
11000.5 |
39.14421 |
48248.26 |
219.6549 |
|
428 |
Товары для животных |
34781.4 |
49.72224 |
198258.3 |
445.262 |
|
430 |
Гигиена |
12573 |
39.80149 |
50983.4 |
225.795 |
|
431 |
Дети |
2490.4 |
2.692711 |
1820.441 |
42.66662 |
|
432 |
Хобби, отдых |
3964 |
2.658237 |
1521.192 |
39.00246 |
Исходя из таблицы 1 и Рис. 2. Макси мальные затраты на классы товаровв идно, что максимальное количество денег (выделено цветом) было потрачено на:
-
1. Готовая продукция – 190201.2 рубля.
-
2. Колбасы – 169589.5 рубля.
-
3. Алкогольные напитки – 152993.3
-
4. Мучные кондитерские изделия – 138795.2 рубля.
-
5. Сыры – 132476.3 рубля.
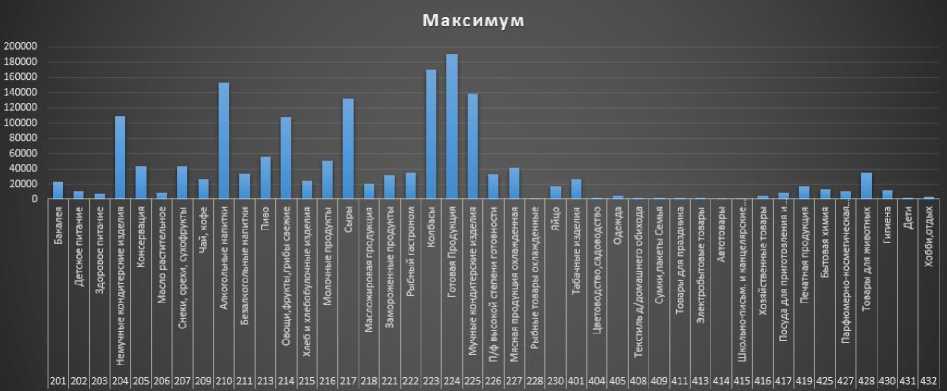
Рис. 2. Максимальные затраты на классы товаров
рубля.
Также исходя из таблицы 1 и Рис. 2. Максимальные затраты на классы това- ровм ожно сделать вывод и выявить топ товаров, на которые люди тратят в среднем большее количество денег:
-
1. Овощи, фрукты, грибы свежие – 922.1909 рубля.
-
2. Колбасы – 816.5619 рубля.
-
3. Сыры – 543.4093 рубля.
-
4. Молочные продукты – 486.6373 рубля.
-
5. Не мучные кондитерские изделия – 467.7868 рубля.
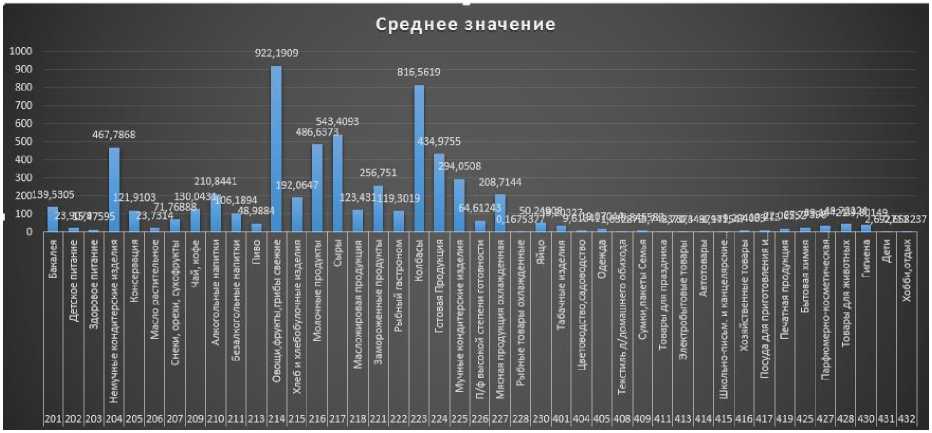
Рис. 3. Средние затраты на товары различных классов
Далее построим диаграмму для товаров, пользующихся наибольшим спросом (рис. 4).
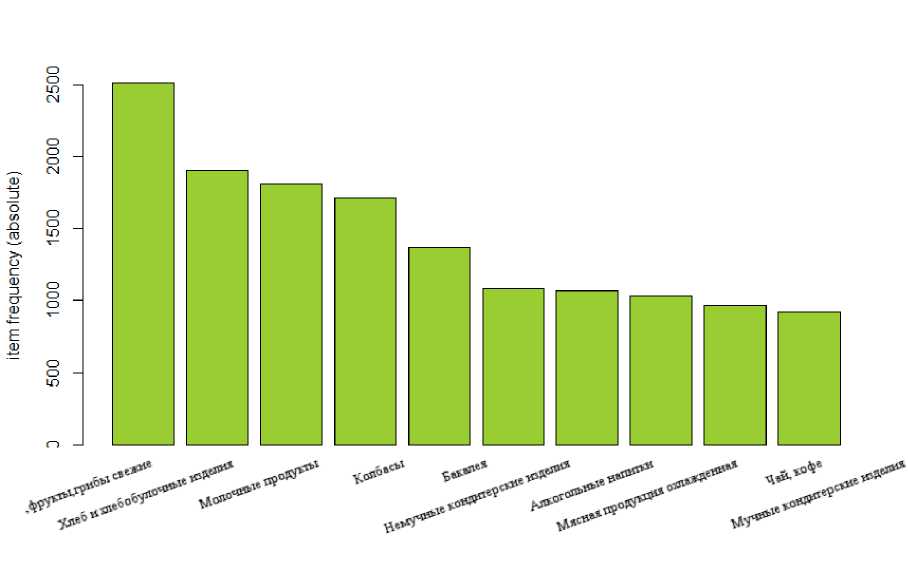
Рис. 4. Товары, пользующиеся наибольшим спросом
Из рисунка 4 видно первые 10 товаров, пользующихся наибольшим спросом:
-
1. Овощи, фрукты, грибы свежие.
-
2. Хлеб и хлебобулочные изделия.
-
3. Молочные продукты.
-
4. Колбасы.
-
5. Бакалея.
-
6. Не мучные кондитерские изделия.
-
7. Алкогольные напитки.
-
8. Мясная продукция охлажденная.
-
9. Чай, кофе.
-
10. Мучные кондитерские изделия.
Выведем данные 200 случайным образом выбранных чеков в разряженную матрицу, чтобы показать частоту товаров в чеках (рис. 5).
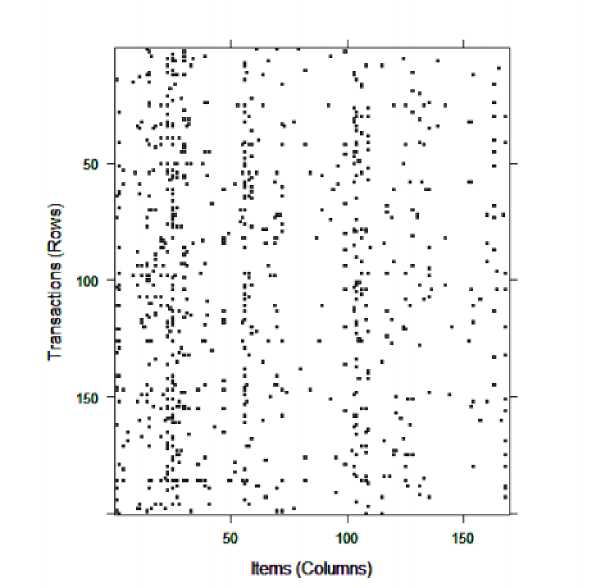
Рис. 5. Разряженная матрица 200 случайно выбранных чеков
Поиск ассоциативных правил с помощью Априорного алгоритма.
Для поиска ассоциативных правил необходимо найти все множество правил из всей базы данных, используя априор- ный алгоритм. Всего было найдено 6723 правила. Результаты поиска показали, что с высокой вероятностью (90%) покупка алкоголя, снеков, орехов и сухофруктов влечёт приобретение пива (рис. 6).
-
> iinspect(myrules [1: 5])
Ihs rhs support confidence coverage lift
-
[1] {Алкогольные напитки, => {Пиво} 0.001331876 0.9047619 0.002135231 11.235269
Снеки, орехи, сухофрукты}
-
[2] {мучные кондитерские изделия, => {чай, кофе}- 0.001016777 0.9090909 0.001118454 3.215669
Бакалея}
-
[3] {Хлеб и хлебобулочные изделия, => {Молочные продукты} 0.001118454 0.9166667 0.001220132 3.587512
Сыры}
-
[4] {Хлеб и хлебобулочные изделия, => {Молочные продукты} 0.001220132 0.9230769 0.001321810 3.612599
Мучные кондитерские изделия}
-
[5] {Готовая Продукция , пиво} => {Молочные продукты} 0.001016777 0.9090909 0.001118454 3.557863
Рис. 6. Первые 5 найденных ассоциативных правил
С вероятностью в 91% покупка мучных кондитерских изделий и бакалеи несет за собой покупку молочных продуктов. С вероятностью в 92% покупка хлеба, хлебобулочных изделий несет за собой покупку молока и так далее.
Оценка качества ассоциативных правил, полученных с помощью Априорного алгоритма представлена на рисунке 7.
-
> summa-ytrnyrul es) set of 129 rules
rule length distribution (Ihs + rhs):sizes 3 4 5 6
10 5 7 55 5
data ntransactions support confidence kn 60467 0.001 0.3
Рис. 7. Сводная информация о наборе полученных ассоциативных правил
Итак, исходя из условий, заданных алгоритму, поддержка равна 0.001, а достоверность – 0.9, было получено лишь 129 ассоциативных правил. Размер правил 3-6, помимо этих параметров, видно, что есть такой показатель как лифт. Он показывает, во сколько раз приобретение набора X увеличивает вероятность приобретения набора Y).
Так, согласно данным, приведённым на рисунке 7, при покупке алкоголя, снеков орехов и сухофруктов в 11 раз увеличивается вероятность того, что будет приобретено пиво. Для наглядности эти правила представлены в таблица. 2, 3, 4.
Таблица 2. Первые 5 найденных ассоциативных правил
|
LHS |
RHS |
Support |
Confidence |
Coverage |
Lift |
|
Алкогольные напитки, снеки, орехи, сухофрукты |
Пиво |
0.0011931876 |
0.9047619 |
0.002135231 |
11.235269 |
|
Мучные кондитерские изделия, бакалея |
Чай, кофе |
0.001016777 |
0.9090909 |
0.001118454 |
3.215669 |
|
Хлеб и хлебобулочные изделия, сыры |
Молочные продукты |
0.001118454 |
0.9166667 |
0.001220132 |
3.587512 |
|
Хлеб и хлебобулочные изделия, мучные кондитерские |
Молочные продукты |
0.001220132 |
0.9230769 |
0.001321810 |
3.612599 |
|
Готовая продукция, пиво |
Молочные продукты |
0.001016777 |
0.9090909 |
0.001118454 |
3.557863 |
Таблица 3. Найденные ассоциативные правила в порядке убывания показателя Lift
|
LHS |
RHS |
Support |
Confid |
Covera |
Lift |
|
Алкогольные напитки, снеки, орехи, сухофрукты |
Пиво |
0.00119 31876 |
0.9047 619 |
0.00213 5231 |
11.23 5269 |
|
Бакалея, Безалкогольные напитки, масло растительное |
Овощи, фрукты, грибы свежие |
0.00101 6777 |
0.9090 909 |
0.00111 8454 |
8.340 400 |
|
Парфюмерные-косметическая продукция, хозяйственные товары |
Бытовая химия |
0.00101 6777 |
0.9090 909 |
0.00111 8454 |
7.562 356 |
|
Масложировая продукция, сыры, колбасы |
Хлеб и хлебобу лочные изделия |
0.00101 6777 |
0.9090 909 |
0.00111 8454 |
6.516 698 |
|
Замороженные продукты, рыбный гастроном, снеки, орехи, сухофрукты |
Безалкогольные напитки |
0.00101 6777 |
0.9090 909 |
0.00111 8454 |
6.216 724 |
Таблица 4. Найденные ассоциативные правила, содержащие молочные продукты
|
LHS |
RHS |
Support |
Confidence |
Coverage |
Lift |
|
Масло растительное, мо лочные продукты, бакалея |
Овощи, фрукты, грибы све- |
0.001016777 |
0.9047619 |
0.002135231 |
8.340400 |
|
Бакалея, Безалкогольные напитки, масло раститель- |
Снеки, орехи, сухофрукты |
0.001016777 |
0.9090909 |
0.001118454 |
2.785641 |
|
Замор о жен ные продукты, молочные продукты, яйцо |
Овощи, фрукты, грибы све- |
0.001016777 |
0.9090909 |
0.001118454 |
5.168156 |
|
Молочные продукты, рыб ный гастроном, готовая |
Овощи, фрукты, грибы све- |
0.001118454 |
0.9090909 |
0.001118454 |
1.782141 |
|
Молочные продукты, масложировая продукция, консервация, мясная продукция охлажденная |
Овощи, фрукты, грибы свежие |
0.001016777 |
0.9090909 |
0.001118454 |
3.215122 |
Далее для наглядности представим полученные правила в виде графов (рис. 7-8). Фиолетовым цветом показаны товары левого плеча, синим – правого. Число рядом со стрелкой показывает значение показателя лифт – во сколько раз покупка товарного набора влечен за собой покупку другого.
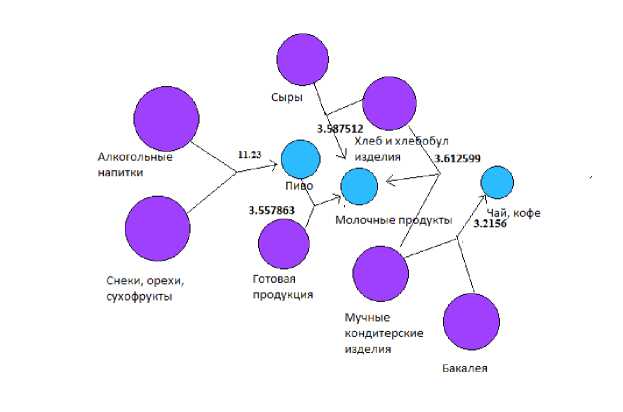
Рис. 7. Граф первых 5 найденных ассоциативных правил
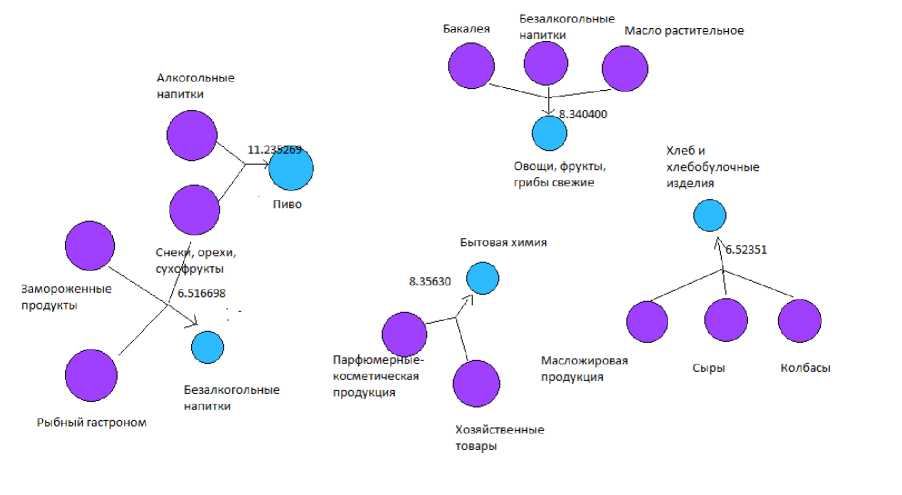
Рис. 8. Граф правил, в порядке убывания показателя лифт
Нахождение стандартной годовой корзины.
Для нахождения стандартной годовой корзины потребителя воспользуемся методом главных компонент. Результаты показаны на рисункке 9.
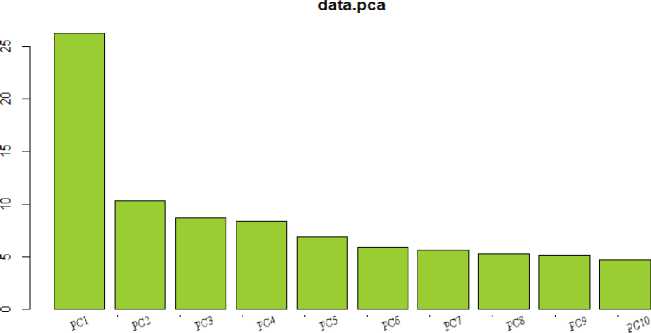
Рис. 9. Диаграмма значений каждой компоненты
На рисунке 9 можно видеть, что первая главная компонента достаточно хорошо описывает вариацию исходных данных. На рисунке 10 представлены сами главные компоненты.
> sunmary(pca)
importance of components:
PCI PC2 РСЗ PC4 PCS PCб PC7 PC8 PC9 PC10 PC11PC12
Standard deviation 2.9042 1.12839 1.11235 1.06501 1.02390 1.01425 1.01206 1.00817 1.00565 1.00380 1.00045 0.99846
Proportion of Variance 0.1961 0.02961 0.02878 0.02638 0.02438 0.02392 0.02382 0.02364 0.02352 0.02343 0.02328 0.02318
Cumulative Proportion 0.1961 0.22576 0.25454 0.28091 0.30529 0.32922 0.35304 0.37668 0.40019 0.42363 0.44690 0.47009
PC13 PC14 PC15 PC16 PC17 PC18 PC19 PC20 PC21 PC22 PC23PC24
Standard deviation 0.99573 0.99252 0.9879 0.98655 0.98385 0.98157 0.97499 0.97389 0.9682 0.96282 0.95828 0.9502
Proportion of variance 0.02306 0.02291 0.0227 0.02263 0.02251 0.02241 0.02211 0.02206 0.0218 0.02156 0.02136 0.0210
Cumulative Proportion 0.49315 0.51606 0.5387 0.56139 0.58390 0.60630 0.62841 0.65047 0.6723 0.69382 0.71518 0.7362
PC25 PC26 PC27 PC28 PC29 PC30 PC31 PC32 РСЗЗ PC34 PC35PC36
Standard deviation 0.93977 0.9296 0.91123 0.8870 0.86821 0.84839 0.82785 0.80832 0.79526 0.78361 0.75815 0.71956
Proportion of Variance 0.02054 0.0201 0.01931 0.0183 0.01753 0.01674 0.01594 0.01519 0.01471 0.01428 0.01337 0.01204
Cumulative Proportion 0.75672 0.7768 0.79612 0.8144 0.83195 0.84869 0.86463 0.87982 0.89453 0.90881 0.92218 0.93422
PC37 PC 38 PC39 PC40 PC41 PC42PC43
Standard deviation 0.70748 0.68210 0.66585 0.63832 0.62094 0.56902 0.55023
Proportion of Variance 0.01164 0.01082 0.01031 0.00948 0.00897 0.00753 0.00704
cumulative Proportion 0.94586 0.95668 0.96699 0.97646 0.98543 0.99296 1.00000
Рис. 10. Главные компоненты
На рисунке 11. Рис. 10. п редставлены стандартные отклонения каждой из компонент.
> pcal<-pca$x[,1]
> vl<-pca$rotation[,l]
> vl
sc201 sc202
0.07304293
SC213 0.12071462
SC225 0.21947263
SC411 0.02842436
SC430 0.02186295
0.02984 303
SC214 0.28566142
SC226 0.15923370 sc413 0.02833863
SC431 0.05721992
SC203 0.03235116
SC215
0.12299681
SC227 0.25751182
SC414 0.03795333
SC432 0.05663781
SC204 0.16312005
SC216 0.23574594
SC228 0.03027576 sc415 0.03803172
SC2O5 0.24624678
SC217 0.24110398
SC23O 0.25566486 sc416 0.17432673
sc206
0.20783150
SC218
0.19629244
SC401
0.07943891
SC417 0.01149274
sc2O7 0.08063912
SC221 0.26247618
SC404 0.01162269
SC419 0.14949787
sc209 0.04954887
SC222 0.19778028
SC405 0.15341859 sc425 0.21561831
sc210sc211
0.15606581 0.06522273
SC223SC224
0.26315489 0.16234972
SC408SC409
0.03583719 -0.02925346
SC427SC428
0.07003428 0.05995685
Рис. 11. Веса первой главной компоненты
Веса компоненты на рисунке 11 указывают на степень корреляции между исходными переменными и новыми основными компонентами. Таким образом они показывают, насколько каждая из исходных переменных вносит вклад в новые пере- менные. В данном примере ясно, что основной компонент 1 состоит из довольно однородных вкладов всех исходных переменных.
Заключение.
В результате проделанной работы было проведено исследование продуктовой корзины с помощью алгоритмов Data Mining. Были решены все поставленные задачи в соответствии с целью исследования. Были исследованы возможности применения алгоритмов Data mining для анализа продуктовой корзины. Также была рассмотрена история Data mining рассмотрены задачи, решаемые с помощью Data mining и рассмотрены алгоритмы нахождения ассоциативных правил. Проведено теоретическое исследование алгоритмов поиска ассоциативных правил и метода главных компонент. Были найдены ассоциативные правила в базе данных чеков магазина за год и определены товары, пользующиеся наибольшим спросом. Также с помощью метода главных компонент была найдена главная компонента, отражающая среднегодовую корзину покупателя.
Проанализированы данные о составе покупок в среднем за год покупателей одной из торговых точек и найдены 129 надежных ассоциативных правил. Ассоциативные правила получились такие:
-
1. Алкогольные напитки, снеки, орехи, сухофрукты -> Пиво.
-
2. Бакалея, безалкогольные напитки, масло растительное -> Овощи, фрукты, грибы свежие.
-
3. Парфюмерно-косметическая продукция, хозяйственные товары, гигиена -> Бытовая химия.
-
4. Масложировая продукция, сыры,
-
5. Замороженные продукты, рыбный гастроном, снеки, орехи, сухофрукты-> Безалкогольные напитки.
колбасы -> Хлеб и хлебобулочные изделия.
Также были найдены 10 товаров, пользующихся наибольшим спросом в магазине:
-
1. Овощи, фрукты, грибы свежие.
-
2. Хлеб и хлебобулочные изделия.
-
3. Молочные продукты.
-
4. Колбасы.
-
5. Бакалея.
-
6. Не мучные кондитерские изделия.
-
7. Алкогольные напитки.
-
8. Алкогольные напитки.
-
9. Чай, кофе.
-
10. Мучные кондитерские изделия.
Максимальное количество денег было потрачено на:
-
1. Готовая продукция – 190201.2 рубля.
-
2. Колбасы – 169589.5 рубля.
-
3. Алкогольные напитки – 152993.3
-
4. Мучные кондитерские изделия – 138795.2 рубля.
-
5. Сыры – 132476.3 рубля.
рубля.
Топ товаров, на которые люди тратят в среднем большее количество денег.
-
1. Овощи, фрукты, грибы свежие – 922.1909 рубля.
-
2. Колбасы – 816.5619 рубля.
-
3. Сыры – 543.4093 рубля.
-
4. Молочные продукты – 486.6373 рубля.
Список литературы Анализ статистики продаж
- Барсегян А.А., Куприянов M.С., Степаненко В.В., Холод И.И. Методы и модели анализа данных: OLAP и Data Mining - 2004. - С. 5-69.
- Раменская А. В., "Ассоциативыне правила в социально -экономических и экологических исследованиях. - 2015. - 86 с.
- Сегаран Т. Программируем коллективный разум. - Пер. с англ. - СПб: Символ-Плюс, 2008. - 20 с.
- Чубукова И. А. DataMining: учебное пособие. - М.: Интернет-университет информационных технологий: БИНОМ: Лаборатория знаний - 2006. - С. 21-35.
- Шистаков М. С., Мастицкий В.К. "Классификация, регрессия и другие алгоритмы Data Mining с использованием R". - 2007. - 71 с.
- О'Нил К., Шатт Р. Data Science. Инсайдерская информация для новичков. Включая язык R. - 2013. - С. 25-32.
- Agrawal, Rakesh and Srikant, Ramakrishnan: Fast algorithms for mining association rules in large databases. - Чили, 1994. - С. 5-11.
- Рофалович В. Р. Data Mining, или Интеллектуальный анализ данных для занятых. Практический курс. - 2014. - С. 121-128.
- Паклин Н.Б., Орешков В.И. Бизнес-аналитика: от данных к знаниям. - СПб.: Изд-во Питер, 2009. - 85 с.
- dygraphs. - [Электронный ресурс]. - URL: https://rstudio.github.io/dygraphs
