Application of topic modeling methods to identify groups of internet resources in order to reduce the risk of cyber threats

Author: Dontsov D.Y., Isaev S.V.
Journal: Siberian Aerospace Journal @vestnik-sibsau-en
Section: Informatics, computer technology and management
Article in issue: 2 vol.23, 2022.
Free access
Internal network security is an important aspect of a successful enterprise. There are various means to prevent cyber threats and analyze visited Internet resources, but their speed and the possibility of applica-tion strongly depend on the volume of input data. This article discusses the existing methods for determin-ing network threats by analyzing proxy server logs, and proposes a method for clustering Internet re-sources aimed at reducing the volume of input data by excluding groups of secure Internet resources or selecting only suspicious Internet resources. The proposed method consists of 3 stages: data preprocessing, data analysis and interpretation of the results obtained. The initial data for the method are the proxy server log entries. At the first stage, data useful for analysis is selected from the source data, after which the con-tinuous data stream is divided into small sessions using the nuclear density estimation method. At the sec-ond stage, soft clustering of visited Internet resources is performed by applying the thematic modeling method. The result of the second stage are unmarked groups of Internet resources. At the third stage, with the help of an expert, the results are interpreted by analyzing the most popular Internet resources in each group. The method has many settings at each stage, which allows to configure it for any format and specif-ics of the input data. The scope of the method is not limited in any way. The resulting method can be used as an additional preprocessing step in order to reduce the amount of input data.
Topic-modeling, cyber security, data analysis
Short address: https://sciup.org/148329616
IDR: 148329616 | UDC: 004.738 | DOI: 10.31772/2712-8970-2022-23-2-148-155
Text of the scientific article Application of topic modeling methods to identify groups of internet resources in order to reduce the risk of cyber threats
Everyday the information technology is penetrating into people’s lives, due to this the cyber security issues are becoming more challenging.
There are three classes of cyber threat sources – human, technological and force majeure [1]. Humans cause the most cyber threats [2], and, therefore, the development of solutions to reduce the number of human-caused intrusions is a promising direction.
To prevent visiting malicious resources, large enterprises use Internet traffic filtering technology [3]. The solution significantly reduces the risk of cyber attacks, but it does not provide 100% security, so it is necessary to use additional means of protecting the internal network.
Internal network security includes capturing, storing, and analyzing network usage data. The analysis results detect changes in user behavior patterns, thereby providing the response and prevention of network threats in a timely manner [4–6]. The process of analyzing data generated by users of the internal network requires some time, and reducing the time spent on analyzing data directly affects the network security.
Network users daily generate hundreds of thousands of requests to various Internet resources, and therefore, reducing the volume of analyzed data is one of the most significant approaches to reduce analysis time.
Distributing visited resources into groups and identifying groups of safe and potentially malicious resources can reduce the amount of analyzed data and give a significant increase in the speed of detecting anomalies in user behavior patterns.
The article proposes an approach to divide visited Internet resources into groups with similar topics by analyzing proxy server access logs. The main goal of the proposed method is to divide resources into groups in order to reduce the amount of analyzed data by excluding "secure" resource groups.
Input data
The input data is the log files of the proxy server being an intermediary between a user and Internet resources. The log (log file) contains information on all user requests made during the 24 hours.
Each line of the log file has got the following information:
– the time of the request;
– the address of the visited Internet resource;
– unique identifier of the user who made the request;
– request type (get, post, put, delete, etc.);
– requested content type (image, html, css, js, …);
– amount of transferred data.
Further analysis requires only some of these fields are needed, such as:
-
– visiting time – the time a user sent the request;
-
– address of the visited resource;
-
– user-id – a unique user-id used to identify resources visited by a single user.
Proposed approach
The research applies the approach to identify and establish links among visited Internet resources through the analysis of their joint occurrence within some sessions (Fig. 1).
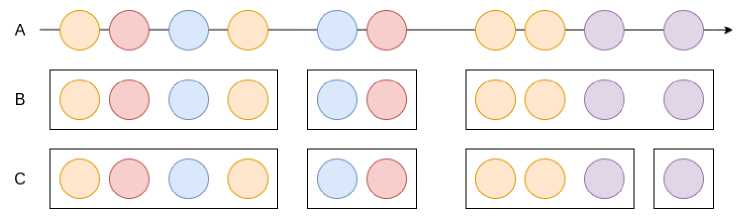
Рис. 1. Схема разбиения лог-файла на сессии:
A – исходный временной ряд; B – первый вариант разбиения; C – второй вариант разбиения
-
Fig. 1. The scheme of partitioning the log file into sessions:
A – is the original time series; B – is the first variant of the partition; C – is the second variant of the partition
A session means a set of Internet resources visited over a certain period of time. In the simplest case, a 24-hour period can be considered a session, however, to improve the quality of the method, it is necessary to consider other options to separate sessions.
To analyze the joint occurrence of resources within one session, probabilistic thematic modeling is used [7]. Thematic modeling performs soft clustering of "documents" based on the co-occurrence of "terms" in these documents. In this case, the resources visited within the same session are used as documents, and the resources themselves are used as terms. The result of thematic modeling is Internet resources grouped into a certain number of unnamed groups (Fig. 2).
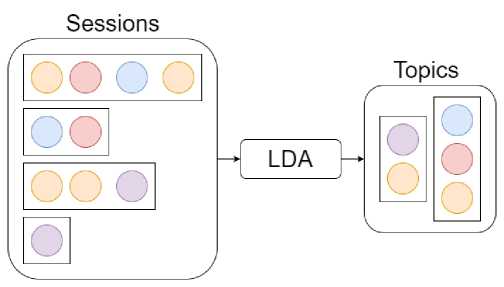
Рис. 2. Схема работы предложенного метода
-
Fig. 2. The scheme of the proposed method
Manual analysis of the most popular Internet resources falling into each group will allow to determine the name of each group and identify groups of secure and malicious Internet resources.
Preprocessing log files
Internet users generate thousands of entries into the log files every day (Fig. 3), and most of the entries in these files do not contain useful information. When visiting a web page, the browser makes an average of 10–20 requests, each of these requests recorded in the proxy server log. The main purpose of preprocessing is to reduce the number of processed data, which will speed up the analysis process and improve the quality of the results [8].
For further analysis, excluding records is reasonable to meet one of the requirements:
– the requested resource is of css/js/image type;
– the request was made by an anonymous user.
On average, such filtering reduces the amount of data by approximately 5 times. Optionally, to further reduce the number of processed data, only get requests can be considered.
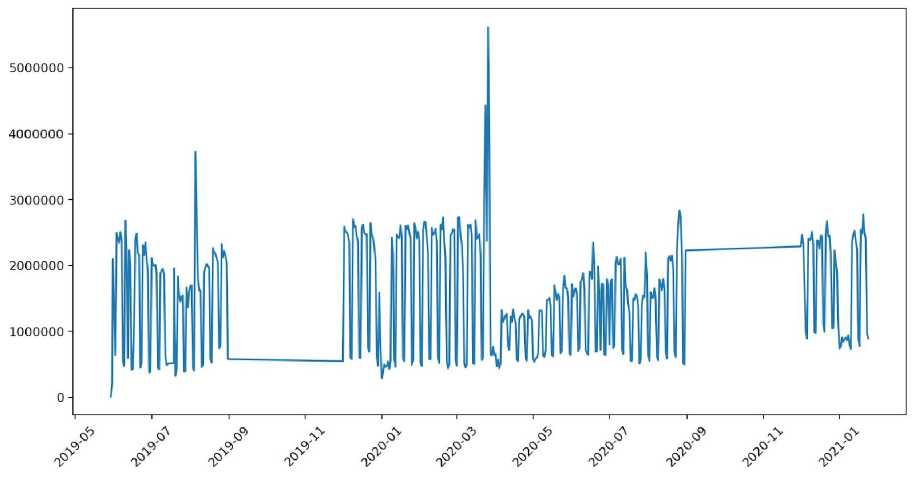
Рис. 3. Ежедневное число запросов, генерируемых 700 пользователями внутренней сети
Fig. 3. Daily number of requests generated by 700 users of the internal network
The second stage of preprocessing is to allocate domains (or IP addresses) of the visited resources in order to consider visiting two pages of the same site as visiting the same resource twice.
Partitioning log files into sessions
This stage requires to partition each user's proxy log entries into short sessions. There could be various options to separate sessions. Further there are some of them.
They are fixed length sessions. To get sessions of a fixed length, it is required to set a certain time interval, for example, 24-hour period, and partition the entire set of records through the selected interval. This approach is imperfect because it combines short-length sessions. For example, a user could use the Internet twice - in the morning and in the evening, however, for this approach, this will be considered the same session.
Using a period of user inactivity results in generating sessions of different lengths, separated by a certain period of time where there was no activity (for example, 1 hour). This method has got a significant drawback: it will not detect sessions if the user has background processes constantly generating requests (for instance, once every 10 minutes).
Applying the KDE (Kernel Density Estimation) method [9–11] can eliminate the disadvantages of the considered approaches. This method can estimate the distribution density of a one-dimensional data set and determine local extremum points. Using such points to divide a continuous data set into segments will allow generating sessions of various lengths being close to the real user behavior (Fig. 4). The KDE method possesses two configurable parameters - a kernel and channel width. These pa- rameters significantly affect the result, and they need to be selected by manually analyzing the lengths of the sessions received.
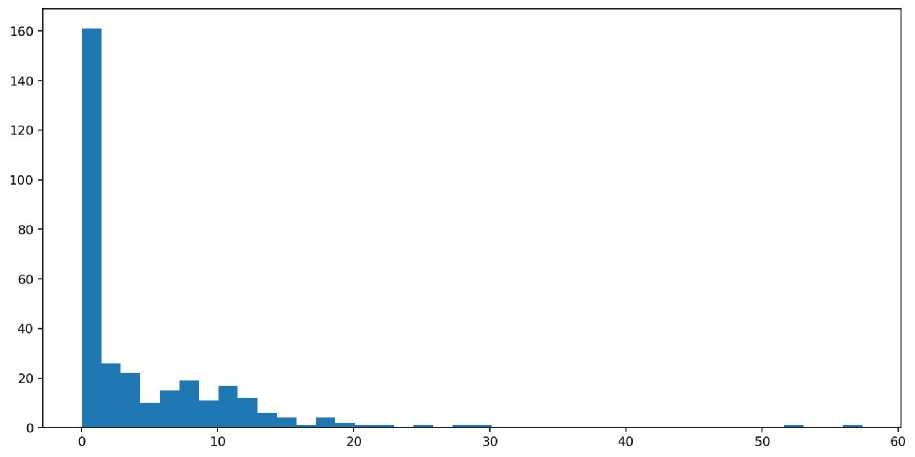
Рис. 4. Гистограмма распределения длин сессий за 1 день. По горизонтальной оси указано время в минутах, а по вертикальной – количество сессий. Средняя длина сессии – 4,5 мин
Fig. 4. Histogram of the distribution of session lengths per 1 day. The horizontal axis shows the time in minutes, and the vertical axis shows the number of sessions. The average session length is 4.5 minutes
Thematic modelling
The thematic modeling is used for hard or soft clustering of documents consisting of terms. There are many different thematic modeling methods [12–13], however, this article describes the LDA method [14–15].
To use topic modeling, documents and terms need to be defined.A term means a domain of an Internet resource visited by a user, a document being a set of domains (terms) visited by one user within one session.
Applying any ready-made implementation of the LDA method for the received documents results in gently grouping all domains of Internet resources into a fixed number of groups. A user establishes a number of groups and determine this empirically. The table presents modelling results of 5 groups. The higher the resource is located in the group, the more it belongs to this group.
Analysis of the most popular Internet resources in each group leads to determining the theme of each group and deciding whether the group is "secure". If the themes of the groups cannot be determined, changing the number of themes searched should be tried.
The results of data modelling for February 2020 for 5 groups
|
1 |
2 |
3 |
4 |
5 |
|
newslab.ru |
nowa.cc |
update.eset.com |
apps.webofknowledge.com |
fitohobby.ru |
|
4pda.ru |
ugadalki.ru |
law-college-sfu.ru |
packages.linuxmint.com |
ib.adnxs.com |
|
sfkras.ru |
scask.ru |
kinoaction.ru |
http.debian.net |
allrefs.net |
|
edu.sfu-kras.ru |
forum.rcmir.com |
kiwt.ru |
urod.ru |
ckp-rf.ru |
|
worldcrisis.ru |
2baksa.net |
dostavka-krasnoyarsk.ru |
fips.ru |
teammodels.no |
|
libgen.is |
autoopt.ru |
kinoaction.ru |
mc.corel.com |
profinance.ru |
For more accurate results, more groups should be selected. Fig. 5 presents a projection of 30 themes into two main components.
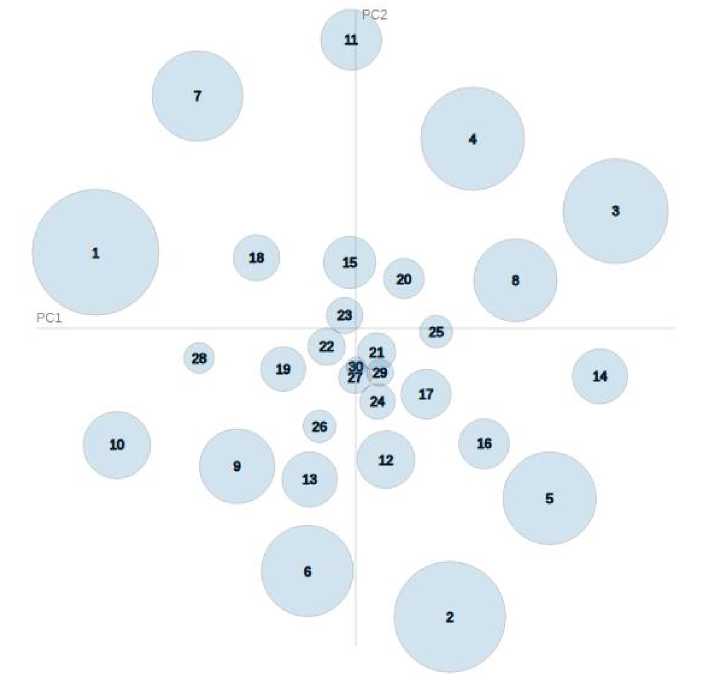
Рис. 5. Проекция 30 групп, полученных путем моделирования данных за февраль 2020 г., на две главные компоненты
Fig. 5. Projection of 30 groups obtained by modeling data for February 2020 into two main components
Conclusion
The method proposed in the article obtains many configurable parameters allowing to fine-tune it for different data sources, whether it is a small internal network or a highly loaded node of a large-scale network.
Grouping Internet resources on a similar theme can be used in various ways for different tasks such as:
– determination of the user's interests;
-
– identification of secure and malicious sites to reduce the number of analyzed data;
-
– determination of the theme of the Internet resource.
Further research considers the use of various metadata, such as the type of content requested and the time of the session. Identifying and screening the advertising services can also be a direction for further development.
References Application of topic modeling methods to identify groups of internet resources in order to reduce the risk of cyber threats
- Mouna J., Latifa B., Latifa B. R., Anis A. Classification of security threats in information sys-tems. // Procedia Computer Science. 2014. Vol. 32. P. 489–496.
- Derendyaev D. A., Gatchin Yu. A., Bezrukov V. A. [Determining the influence of the human factor on the main characteristics of security threats]. Cybernetics and programming. 2019, No. 3, P. 38–42 (In Russ.).
- Gyorodi R., Cornelia G., Pecherle G., Radu L. Network Security Using Firewalls. Journal of Computer Science and Control Systems. 2008, Vol. 1.
- Kao D. Y., Wang S. J., Huang F. Dataset Analysis of Proxy Logs Detecting to Curb Propaga-tions in Network Attacks. Intelligence and Security Informatics. 2008, P. 245–250.
- Marshall B., Chen, H. Using Importance Flooding to Identify Interesting Networks of Criminal Activity. Lecture Notes in Computer Science. 2006, Vol. 3975, P. 14–25.
- Mukkamala S., Sung A. Identifying significant features fornetwork forensic analysis using artifi-cial techniques. InternationalJournal of Digital Evidence. 2003, Vol. 1, No 4.
- Blei D. M. Probabilistiс topiс models. Communiсations of the ACM. 2012, Vol. 55, No. 4, P. 77–84.
- Fei B., Eloff J., Oliver M., Venter H. Analysis of Web Proxy Logs. IFIP International Confer-ence on Digital Forensics. Orlando, 2006, Vol. 222, P. 247–258.
- Scott D. W. Multivariate Density Estimation. Theory. Practice and Visualization: Second edi-tion. New York, 2015.
- King T. L., Bentley R. J., Thornton L. E. et al. Using kernel density estimation to understand the influence of neighbourhood destinations on BMI. BMJ Open. 2016, Vol. 6.
- Kalinic M., Krisp J. Kernel Density Estimation (KDE) vs. Hot-Spot Analysis – Detecting Crim-inal Hot Spots in the City of San Francisco. Lund, Sweden, 2018.
- Vorontsov K. V. Obzor veroyatnostnykh tematicheskikh modelei [Overview of probabilistic thematic models]. Moscow, 2021. 112 p.
- Albalawi R., Yeap T., Benyoucef M. Using Topic Modeling Methods for Short-Text Data: A Comparative Analysis. Frontiers in Artificial Intelligence. 2020, Vol. 3.
- Jelodar H., Wang Y., Yuan, Ch., Xia, F. Latent Dirichlet Allocation (LDA) and Topic model-ing: models, applications, a survey. 2017.
- Tharwat A., Gaber T., Ibrahim A., Hassanien A. E. Linear discriminant analysis: A detailed tu-torial. Ai Communications. 2017, Vol. 30, P. 169–190.
