Атрибуция медийных текстов на основе обученной модели естественного языка и лингвистическая оценка качества идентификации

Автор: Клячин В.А., Хижнякова Е.В.
Журнал: Вестник Волгоградского государственного университета. Серия 2: Языкознание @jvolsu-linguistics
Статья в выпуске: 5 т.23, 2024 года.
Бесплатный доступ
Разработка эффективных систем фильтрации медийных текстов обусловлена необходимостью развития систем искусственного интеллекта, представляющего собой большую модель языка, которая должна создаваться на основе «правильных» текстовых образцов, не содержащих признаков дезинформации, инфодемии и недостоверности. В статье изложены результаты автоматической идентификации качественных медийных текстов и текстовых экземпляров, содержащих инфодемические и недостоверные признаки. Она проведена с применением модели естественного языка, построенной методами машинного обучения на основе размеченного вручную корпуса. Цели работы заключались в создании модели языка медийных сообщений, оценке ее качества и выявлении ошибок идентификации, обусловленных лингвистическими характеристиками текстов. Создание модели языка медийных сообщений выступает условием повышения эффективности и качества систем искусственного интеллекта. Установлено, что тестовое использование обученной модели естественного языка позволяет с высокой точностью провести фильтрацию медийных текстов. Наибольшую эффективность в рамках модели продемонстрировал метод опорных векторов: доля ошибочно распознанных информативных текстов, отвечающих признакам достоверности и новизны, невысока и составляет 6,2 %, количество неправильно распознанных неинформативных текстов составляет примерно 10,2 %. Установленные ошибки в идентификации информативных текстов связаны с употреблением в заголовках имен собственных (антропонимов, топонимов) и числительных. К лингвистическим признакам неправильно распознанных текстов, содержащих признаки дезинформации, относятся текстовые образцы, содержащие высказывания с глаголами в форме будущего времени, а также глаголами речи, часто встречающимися в достоверных текстах.
Медийный текст, нейронная сеть, модель языка, метод машинного обучения, корпус, автоматическая идентификация
Короткий адрес: https://sciup.org/149147495
IDR: 149147495 | УДК: 81’322 | DOI: 10.15688/jvolsu2.2024.5.3
Attribution of media texts based on a trained natural language model and linguistic assessment of identification quality
The creation of effective systems for filtering media texts is due to the need to develop artificial intelligence systems, which is a large language model that should be trained using “correct” text samples that do not contain signs of disinformation, infodemic and unreliability. The article presents the results of automatic detection of high-quality media texts, as well as text samples with infodemic features carried out using a trained natural language model based on a manually labeled corpus. Manual marking of the corpus was carried out by experts based on the parameterization of the text content. The goal of our work is to build a model of the language of media messages, assess the quality and identify detection errors caused by the linguistic characteristics of texts. Creating a model of the language of media messages is a condition for increasing the efficiency and quality of artificial intelligence systems. It has been established that the test use of a trained natural language model allows filtering media texts with fairly high accuracy. The support vector machine method proved to be most effective. The share of incorrectly recognized informative texts that meet the criteria of reliability and novelty is low and amounts to 6.2 percent. The percentage of incorrectly recognized uninformative texts is approximately 3.9 percent, which indicates a fairly high efficiency of the developed model. The errors in the detection of informative texts are associated with the use of proper names (anthroponyms, toponyms) and numerals in the headings. Linguistic features of misclassified texts containing signs of fake and misinformation comprise text samples using statements with speech verbs that are often used in informative texts.
Текст научной статьи Атрибуция медийных текстов на основе обученной модели естественного языка и лингвистическая оценка качества идентификации
DOI:
Статья посвящена проблемам разработки модели языка медийных сообщений в целях фильтрации новостных текстов, находящихся в открытом доступе, в соответствии с критериями достоверности и информативности их содержания, а также лингвистической оценке эффективности разработанных алгоритмов. Актуальность проблематики обусловлена рядом обстоятельств:
– необходимостью разработки систем искусственного интеллекта (далее – ИИ), представляющего собой большую модель языка. Как отмечают ученые, основная цель исследований в области ИИ – «получение методов, моделей и программных средств, позволяющих искусственным устройствам реализовать целенаправленное поведение и разумные рассуждения» [Осипов, 2011, с. 9];
– понимание текстов машиной требует автоматического распознавания его интенциональной составляющей и определения объективных экстралингвистических и лингвистических маркеров, указывающих с высокой степенью вероятности на то, что мы имеем дело с ложной информацией [Николаева, 2019];
– широким распространением недостоверных текстов, основанных на мистифика- циях [Распопова, Богдан, 2018], погоне за сенсациями [Иссерс, 2014] либо образующими деструктивные речевые практики, манипулирующие общественным сознанием и порождающими девиантное социальное поведение, внушающими тревожность и даже панику, образующими «информационный шум», затрудняющими информационный поиск.
Задачи автоматической идентификации текстов медийного дискурса представляют особую сложность, поскольку коммуникативная практика массово-информационного общения, к основным функциям которого относятся информирование и воздействие, предполагает не просто освещение социально значимых событий, но и фокусность представления информации, когда автор текста отбирает и интерпретирует их признаки, направленные на адаптивное информирование аудитории, осуществляет выбор языковых средств, придающих тексту информационную ценность, привлекающих и удерживающих внимание адресата (см., например: [Ильино-ва, 2018; Bednarek, Caple, 2017]).
В последнее время в медийном пространстве увеличивается количество текстов, обладающих признаками недостоверного содержания, и служащих средством манипуляции общественным сознанием. В целях идентификации недостоверных текстов И.С. Карабу-латова использует понятие «деструктема», трактуемое как «ключевая смысловая единица текста, которая определяется на основе заложенной в нем интенции разрушения и соответствующей ей цели воздействия, находящих выражение в языковой ткани текста» [Кара-булатова, Копнина, 2023, с. 224]. Деструктивные тексты разнообразны, имеют различную природу, часто характеризуются пересекающимися признаками и с трудом поддаются классификации. К медийным текстам, образующим деструктивные медийные практики, исследователи относят инфодемические сообщения, фейковые тексты и тексты, использующие техники «кликбейтинга».
Возникновению термина инфодемия , образованного путем словосложения существительных информация и эпидемия , способствовала пандемия коронавируса. По наблюдению Ф.В. Борхсениуса, инфодемия «представляет собой стремительное и неконтролируемое распространение в новых медиа необоснованной и ложной информации о кризисных событиях, усиливающее общественное беспокойство» [Борхсениус, 2021]. В современном мире отмечается усиление инфодемии, которая оказывает влияние на все сферы жизнедеятельности человека и интерпретируется как новый вызов для общества [Кондратьева, Игнатова, 2023]. Как отмечают ученые, в процессе умышленного или, наоборот, непреднамеренного создания и распространения инфо-демических нарративов ведущая роль отводится СМИ и соцмедиа [Землянский, 2021].
Рассматривая инфодемию как ключевой медиаконцепт современности О.Н. Кондратьева и Ю.С. Игнатова выделяют в его структуре исходный понятийный признак – «распространение недостоверной информации», который в массмедийном дискурсе получает максимальную конкретизацию, что выражается в появлении дополнительных, зачастую аксиологически нагруженных признаков» [Кондратьева, Игнатова, 2023]. Исследователи отмечают, что в инфодемичес-ких текстах информация квалифицируется как недостоверная, разнородная (смешение недостоверной и достоверной), избыточная и вредоносная; ее распространение характеризуется как преднамеренное, быстрое и массовое; основные перлокутивные эффекты сводятся к вытеснению информации на другие темы, введению в заблуждение, недоверию официальным источникам, психологическому давлению на общество, панике.
Представленные в настоящее время в литературе определения инфодемического нарратива относят к числу его основных признаков дезинформацию как отправную точку и основную составляющую инфодемии [Землянский, 2021, с. 113]. Отмечается, что жанры инфодемических текстов различаются: это могут быть статьи или короткие рассказы от первого лица. Исходя из изученных материалов и опираясь на данные платформы по выявлению фейковых новостей First Draft, А.В. Землянский выделяет четыре группы ин-фодемических текстов: псевдомедицинские материалы, тексты-предупреждения, панические и конспирологические тексты, отмечая, что отдельные образцы могут сочетать признаки различных групп [Землянский, 2021].
Фейковые новости как лингвистический медиапродукт часто используют прием жанровой мистификации [Иссерс, 2014], что обычно осознается адресатом сообщения или соответствуют функциональным и структурно-семантическим особенностям «жесткой» новости, что затрудняет возможность их идентификации. К экстралингвистическим факторам возникновения ложной информации исследователи относят в том числе такие неинтенциональные факторы, как небрежность журналиста или его добросовестное заблуждение в отношении некоторых фактов [Суходолов, Бычкова, 2017]. Наиболее полная классификация текстовых маркеров фейковых текстов предложена учеными Воронежского университета, которые собрали и систематизировали разнообразные способы представления недостоверного содержания [Стернин, Шестернина, 2020]. Авторы выделяют виды фейков по степени искажения информации, по степени достоверности пространственно-временных характеристик, по степени достоверности и надежности источника информации, по цели создания и типу репрезентации [Стернин, Шестернина, 2020, с. 4–6]. Установленные лингвопрагматические маркеры фейковой новости дают возможность исследователю и рядовому читателю проводить дискурсивный и лингвостилистический анализ новостных сообщений и интерпретировать потен- циально мистифицированные новости по шкале «ложь – правда» [Кошкарова, Бойко, 2020].
Разновидностью недостоверных медийных сообщений являются тексты, созданные с целью привлечения внимания читателя и увеличения количества переходов на сайт. Эти тексты строятся по модели информационного сообщения, но их содержание не соответствует содержащемуся в заголовке тезису (то есть используется технология кликбейтинга). Кликбей-ты также рассматриваются как средство фальсификации информации [Вольская, 2018; Чаны-шева, 2016; Al Asaad, Erascu, 2018; Shu et al., 2018]. Механизмы кликбейтинга неоднократно становились предметом лингвистического изучения. Например, Ж.Р. Сладкевич в качестве популярных механизмов подачи «кликабельного» контента называет такие, как подмена персонажей и ложная смерть, представление слухов под видом фактов, приемы семантической провокации, эвристические приемы, цитация и квазицитация, модификация контекста, преподнесение возможного как действительного [Слад-кевич, 2019]. Перечень приведенных механизмов может быть расширен, поскольку они постоянно меняются.
Таким образом, текстовые сообщения не соответствующие основной цели медийного дискурса – информированию, достаточно разнородны, не имеют четко выраженных критериев выделения, имитируют достоверные сообщения, используя определенную структуру и языковые средства. Кроме того, приемы создания таких текстов постоянно модифицируются, отражая новые практики создания деструктивного контента. Соответственно, важной задачей исследователей, как отмечает И.С. Ка-рабулатова, становится разработка параметрических моделей деструктивных текстов, что позволит в дальнейшем решить задачу поиска и идентификации деструктивной информации в разножанровых текстах автоматизированным путем [Карабулатова, Копнина, 2022].
Существуют различные подходы к автоматическому определению текстов, содержащих признаки дезинформации. Как отмечают Г.А. Некрасов и И.И. Романова, «статистическая обработка множества поддельных статей позволяет выделить наборы ключевых слов, которые с определенной долей вероятности сигнализируют о возможности, что статья является под- дельной» [Некрасов, Романова, 2017, с. 129]. Основными методами решения задачи фильтрации некачественных текстов в недалеком прошлом выступали статистические, базирующиеся на вычислении различных частотных характеристик текста методы [Попов, Штельмах, 2019]. В последнее время для идентификации различных типов текстов и жанров используется метод машинного обучения. Автоматическое определение кликбейтинга на материале английского языка проведено в работах [Anand, Chakraborty, Park, 2017; Biyani, Tsioutsiouliklis, Blackmer, 2016; Kumar et al., 2018; и др.]; предложена гибридная техника категоризации кликбейтных и некликбейтных статей путем интеграции различных функций, структуры предложений и кластеризации, после чего к набору данных применяются модели машинного обучения для оценки алгоритмов машинного обучения [Pujahari, Sisodia, 2021]; создано расширение для браузера ClickBaitSecurity, основанное на алгоритме поиска легитимных и нелегитимных списков (LILS) и алгоритме проверки рейтинга домена (DRC) для более быстрого и эффективного обнаружения вредоносного контента [Razaque et al., 2022]; представлено определение фейковых сообщений на основе размеченного корпуса на английском языке в [Pérez-Rosas et al., 2018]; предложен метод выявления кликбейтных заголовков с использованием семантического анализа и методов машинного обучения: обосновано применение шести различных алгоритмов классификации машинного обучения (дерево решений, логистическая регрессия, наивный байесовский классификатор, машина опорных векторов, метод k-ближайшего соседа и дерево решений с градиентным усилением) как по отдельности, так и в совокупности [Bronakowski, Al-khassaweneh, Al Bataineh, 2023].
В русскоязычном научном поле сегодня представлены публикации, посвященные отдельным вопросам автоматизированного определения фейковых новостей с элементами искусственного интеллекта и машинного обучения [Жук Д. А., Жук Д. В., Третьяков, 2018, с. 23]. А.О. Третьяковым разрабатывается концепция метода автоматизированного определения фейковых новостей для русскоязычных текстов с элементами искусственного интеллекта и машинного обучения предложена в [Третьяков, 2018]. Автор делает вывод о большом потенциале, который можно извлечь из применения искусственного интеллекта в связке с инструментарием по обработке веб-данных, вместе с тем разработанный метод идентификации фейковых сообщений направлен на решение задач автоматизации исполнения процессов в программном обеспечении и не в полной мере учитывает лингвистические характеристики текстов.
Цель нашего исследования – построение обученной модели естественного языка медийных сообщений и лингвистическая оценка эффективности автоматического распознавания информативных и недостоверных медийных сообщений на ее основе.
Материал исследования
Для обучения искусственной нейронной сети и экспериментального исследования предлагаемого метода использовался размеченный корпус, содержащий 1750 текстовых фрагментов, в которых воплощаются исследуемые типы медийных текстов. Корпус медийных сообщений включает тексты, размещенные на порталах lenta.ru, news. ru, tass.ru, aif.ru, kp.ru, kommersant.ru, vedomosti.ru и др. Общий объем корпуса составил 1 млн слов.
В общей сложности получилось две текстовых выборки по 875 текстов каждая. Первая выборка состоит из оригинальных новостных текстов, сообщающих о различных событиях и имеющих информативный характер. Большой массив содержащих достоверную информацию текстов, используемый для обучения системы их характеристикам, позволяет обеспечить высокую точность фильтрации. Ко второй группе мы относим все тексты, которые не содержат строго фактической информации, не соответствуют стандартам журналистской этики, а также те, что включают признаки недостоверных текстов, представленных ниже.
Лингвистическое обеспечение программ автоматического распознавания информативных и деструктивных медийных сообщений заключается в установлении в текстах языковых маркеров, по которым эксперты идентифицируют качество их содержательной составляющей. Для разработки модели языка медийных сообщений требуется размеченный вручную корпус, при создания которого необходимо прежде всего провести параметризацию текстового содер- жания и описать показатели речевой системности в атрибуции его качества, которые в последствии будут предъявляться экспертам. Как отмечают исследователи, речевая (текстовая) системность выступает лингвистической базой компьютерного когнитивного моделирования [Салимовский и др., 2019]. В научной литературе описаны методы, используемые в системах автоматического распознавания интенций, основанных на идентификации эксплицитных языковых маркеров. Лингвистическое обеспечение программ автоматического распознавания коммуникативных действий заключается в систематизации маркирующих те или иные интенции разноуровневых языковых маркеров, по которым эксперты идентифицируют эти действия. Совокупность таких маркеров образует лингвистическую составляющую шаблонов, подлежащую дальнейшей программной формализации [Сали-мовский и др., 2021]. Вместе с тем интенция не всегда выражается на поверхностном уровне текста в эксплицитном виде и зачастую не соотносится с конкретными языковыми средствами ее воплощения, а скорее выражается комбинацией различных средств. В этом случае лингвистические признаки принадлежности текста к той или иной группе с трудом поддаются формализации и требуют выработки иных подходов к их автоматическому определению [Хижнякова, 2023].
Параметры недостоверных и содержащих признаки дезинформации текстов были выделены на основе систематизации имеющихся классификаций, а также анализе собственной коллекции текстов. Охарактеризуем установленные параметры.
Употребление собирательных существительных в сочетании с глаголами в форме будущего времени:
-
(1) Почти по 7 000 рублей: россияне получат специальную выплату перед самым Новым годом.
В дальнейшем содержании текста значение существительного конкретизируется за счет уточняющих признаков: пенсионеры, которые пострадали в результате техногенных или радиационных катастроф , отменяя таким образом пропозицию, вынесенную в заголовок .
Прием негативизации события, реализующийся в конструкции с использованием со- бирательного существительного и отрицательной частицы не с личной формой глагола в будущем времени:
-
(2) Про деньги можно забыть: пенсионеры не получат пенсию в январе.
Основной текст сообщает о том, что пенсионные выплаты будут произведены раньше, в декабре.
Вырванные из контекста цитаты [Слад-кевич, 2019], помещенные в другой контекст:
-
(3) «Не беспокоит»: Набиуллина заявила, что ЦБ не вернет деньги россиян с некоторых вкладов.
Взятая в кавычки фраза «не беспокоит» представляет собой частью ответа на вопрос главы Центробанка Эльвиры Набиуллиной, которая ответила, что ее «не беспокоит отток наличной валюты за границу в виде вкладов».
Сенсационные заявления с использованием слов, обладающих отрицательной оценочной семантикой:
-
(4) Грядет обнуление: для россиян, пользующихся картами Сбербанка, принято неожиданное решение;
-
(5) Хворь будет забирать жизни людей: что ждет человечество в 2023 году.
Использование глаголов речи раскрывать , заговорить , заявить , назвать , пообещать , предрекать , раскрыть , признаться , заявить , ответить , глагола предсказать или производного от него существительного предсказание , в сочетании с оценочными фразами:
-
(6) Каким будет мир в 2023 году: раскрыты жуткие записки Нострадамуса;
-
(7) Виктор Бут назвал самое тяжелое в американской тюрьме;
-
(8) Лечению не поддается: вот в какой зависимости признался Якубович.
Заголовок (6) содержит элементы мистификации: имя известного предсказателя в сочетании с отрицательно оценочной фразой, прогнозируя развитие событий по катастрофическому, деструктивному сценарию. В заголовке (7) использовано относительное прилагательное американский, которое заставляет читателя предположить, что в основном тексте речь пойдет об особенностях содержания в американской тюрьме, вместе с тем текст сообщает об отсутствии возможности общения с близкими людьми. Заголовок (8) содержит отрицательно оценочное существительное зависимость в сочетании с глаголом признаваться, что сигнализирует об отсылке к «новой искренности».
Употребление сниженной и жаргонной лексики:
-
(9) Онемеете: на замок Пугачевой нашелся покупатель.
Использование лексики, описывающей эмоциональную реакцию адресата сообщения на событие :
-
(10) «Сбежала из больницы»: правда о поступке Степаненко вызовет слезы;
-
(11) «Трупные пятна»: Долина в жутком виде вызвала оторопь;
-
(12) Мать детей Киркорова вышла в свет! Все ахнули, узнав, что это всем известная...
Использование оценочной лексики:
-
(13) Ефремова больше нет: адвокат актера напугал страшным известием;
-
(14) Яна Чурикова: судьба Лены Терлеевой стала огромной трагедией для «Фабрики звезд-2».
Для распределения новостей по категориям применялся ручной отбор текстов и последующая сортировка на основании вышеописанных лингвистических признаков. Мы попросили экспертов выбрать ярлык «Недостоверный» или «Информационный», полагаясь на их собственное восприятие после прочтения новости. Два эксперта помечали новости в каждом наборе данных. В обоих случаях новостные статьи были представлены в случайном порядке, чтобы избежать предвзятости в их оценке. Эксперты разметили 875 и 875 новостей для наборов данных «Недостоверные новости» и «Информационные тексты», соответственно. Кроме того, мы оценивали эффективность автоматических классификаторов недостоверных новостей в сравнении со способностью человека их обнаруживать. Таким образом, мы сравниваем точность автоматической системы с точностью людей-экспертов.
Процессы решения задачи автоматизации идентификации информативных и неинформативных текстов на основе методов машинного обучения проводилось в два этапа.
Результатом первого этапа моделирования языка медийных сообщений стало векторное представление слов, которое является необходимым в задачах обработки естественных языков. Более того, использование численных методов сопряжено с использованием не просто числовым представлением слов, а с так называемым непрерывным представлением (подробно об этом см.: [Mikolov et al., 2013]). Современные методы искусственного интеллекта и машинного обучения выполняют обработку слов на основе их векторных представлений. Векторное представление слова – это сопоставление каждому слову некоторого набора чисел:
автомобиль ^ (1.2 , 3.4 , 1.22,0.17 , ..., 6.75)
Количество чисел в векторе задает его размерность. Если сопоставить каждому слову словаря подобный вектор, получается вложение слов в векторное пространство. Такое вложение образует модель языка. Таких моделей можно составить неограниченное количество, поэтому к вложению слов накладывают некоторые условия, одним из которых выступает минимизация расстояний вложений семантически близких слов. Это, в частности, означает, что ближе всего к данному слову располагаются слова, сходные в смысловом отношении. Приведем один из способов векторизации слов на основе подсчета статистики употребления слов в тексте. Рассмотрим несколько текстов как документов D1 , D2 , ..., DN . Для заданного слова w вычислим следующие величины:
TF(w,Di) = частота слова w в документе Di , IDF(w) = log( N / число документов, содержащих w ).
Характеристика TF-IDF(w,Di) вычисляется так:
TF-IDF(wD) = TF(w,D) х IDF(w).
Таким образом, получаем вложения слов из коллекции документов в векторное пространство размерности N. Такое представление подходит для решения различных задач обработки естественного языка, в частности задачи кластеризации текстов или их классификации различными методами, например такими, как k ближайших соседей, метод Байеса, метод опорных векторов и т. п. Однако характеристика TF-IDF не подходит для решения других задач, где требуется выявление более точных семантических связей. Например, для построения генеративных моделей характеристика TF-IDF не используется. Кратко охарактеризуем алгоритм построения вложения слов, который был предложен в [Mikolov et al., 2013] и модифицирован в [Klyachin, Khizhnyakova, 2023]. Задача решается средствами машинного обучения. Это означает, что строится некоторое отображение y = F(θ,x), в котором вектор x представляет собой вектор данных слов, а y представляет собой вектор предсказанных слов. При этом параметры и модели подбираются исходя из минимума ошибки предсказания:
E = |F( θ ,x1) – y1| 2 + ... + |F( θ ,xM) – yM| 2,
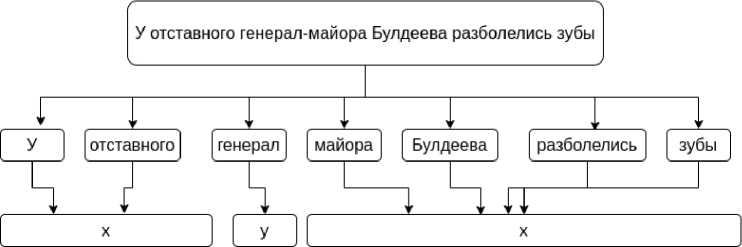
Рис. 1. Построение векторов из предложения
Fig. 1. A sentence converted to a vector
где M – число данных. Алгоритм обучения вложению не использует какой-либо специальной разметки текста, а слова, которые преобразуются в векторы x и y берутся непосредственно из текста. Это показано на рисунке 1.
Таким образом, модель y = F( θ ,x) обучается предсказывать пропущенные слова в тексте – наиболее подходящие по смыслу.
Опишем теперь структуру y = F( θ ,x) как нейросетевую модель. Она состоит из трех слоев (рис. 2).
Первый слой вложения – это именно тот слой, который вычисляет матрицу вложения. На схеме (рис. 2) n – это число слов в векторе x , который представлен так называемым унитарным кодированием слова из словаря, собранного из всех обрабатываемых текстов. Унитарное кодирование – это сопоставление слову из словаря вектора, в котором все значения равны 0, за исключением одной компоненты, равной единице, номер которой совпадает с номером слова в словаре. Далее, dim – размерность вложения. Этот параметр выбирается разработчиками. Второй слой – рекуррентный слой GRU, который анализирует последовательность слов, вырабатывая один вектор. В отличие от структуры нейронной сети, представленной в наших предыдущих работах (см.: [Klyachin, Khizhnyakova, 2023]), мы используем слой типа GRU, так как он добавляет нелинейность в обработке данных и, соответственно, улучшает аппроксимативные свойства модели. Третий слой – это плотный слой. Он предсказывает пропущенное слово, то есть имеет размерность, равную размеру словаря, вычисляя вероятности каждого слова. Далее используется принцип максимальной вероятности, и мы вырабатываем соответствующий вектор y .
Отметим, что похожие алгоритмы используются для обучения вложению на основе различных корпусов текстов на естественных языках. Например, имеется ресурс
RusVectōrēs , на котором на странице models/ в общий доступ выложены результаты обучения в виде моделей русского языка. В целом ресурс RusVectōrēs представляет собой инструмент, который позволяет исследовать отношения между словами в непрерывных моделях. Авторы сервиса называют собственный ресурс «семантическим калькулятором». Из тщательно подготовленных моделей, обученных на разных корпусах, пользователь может выбрать одну или несколько. Используя выбранную модель, можно выполнять в режиме онлайн следующие операции:
– вычислять семантическое сходство между парами слов;
-
– находить список слов, ближайших к заданному с дополнительной возможностью фильтрации по части речи и частотности;
-
– решать аналогии вида «найти слово X , которое так относится к слову Y , как слово A относится к слову B »;
-
– выполнять над векторами слов алгебраические операции – сложение, вычитание, поиск геометрического центра лексического кластера и вычислять расстояния до этого центра;
-
– рисовать семантические карты отношений между словами для визуального анализа семантических кластеров.
Приведем неполный список семантических связей, которые сохраняются моделями, представленными на этом ресурсе:
-
– cвязь глагол → существительное (например: летать → самолет ⇒ плыть → корабль );
-
– обобщение (например: красный → цвет ⇒ собака → животное );
-
– часть → целое (например: колесо → машина ⇒ палец → рука );
-
– степени прилагательных (например: сильный → сильнейший ⇒ близкий → ближайший ).
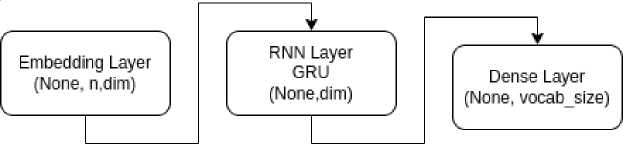
Рис. 2. Структура нейросетевой модели для обучения вложению
Fig. 2. The structure of the neuromodel for embedment learning
При этом связи типа a ^ b ^ c ^ d могут быть вычислены по формуле d = c + (b – a), предполагая, что ищутся слова, ближайшие к вектору d.
У описываемого сервиса есть API (Application Programming Interface), с помощью которого можно для любого слова получить список семантически близких к нему слов, указав модель языка. Результат можно получить в двух форматах: json и csv. Для этого необходимо выполнить GET-запрос по адресу следующего вида: https://rusvectores. org/MODEL/WORD/ api/FORMAT/, где MODEL – идентификатор для выбранной модели (берутся из таблицы на странице , WORD – слово запроса, FORMAT – «csv» или «json» устанавливается по выбору. В результате запроса сервис возвращает файл в соответствующем формате, в котором перечислены ближайшие десять соседей слова. Кроме того, использовав формат запроса https:// rusvectores. org/MODEL/WORD1__WORD2/ api/similarity/, можно получать значения семантической близости для пар слов в любой из моделей.
Для решения задачи выявления неинформативных текстов мы использовали специально настроенную модель русского языка. Опишем процедуру создания такой модели. Подготовленные файлы, содержащие тексты (как информативные, так и нет) размещаются в отдельном каталоге. Алгоритм последовательно выполняет следующие этапы:
-
1) с использованием библиотеки NLTK проводится токенизация каждого текста и удаляются стоп слова. При этом сохраняются разделители предложений. На основе слов, содержащихся в текстах, строится словарь;
-
2) выбирается необходимое количество предложений текста и для каждого слова строится его унитарное представление y , а остальные слова размещаются в векторе x – в соответствии со схемой на с рисунке 1. Таким образом получаются матрицы X и Y размером, соответственно
M x vocab_size • window_size
и
M x vocab_size, где window_size – число слов в векторе x;
-
3) процесс обучения нейронной сети, структура которой изображена на рисунке 2, проводился на двух датасетах. Необходимо отметить, что компьютерное моделирование нейронной сети осуществляется на основе библиотек Keras и Tensorflow на языке программирования Python 3.5. При этом параметры Датасета 1 вычислялись по корпусу vocab_size = 7 560 (количество уникальных слов); а также выбирались разработчиками следующим образом: window_size = 6; dim = 144; M = 19 033 (количество слов корпуса 39 082). Количество эпох обучения = 16 000. Обучение заняло 53 часа 20 минут. Параметры компьютера: Intel® Core™ i7-3770K CPU @ 3.50GHz x 8, операционная система ROSA Linux Server Edition, ядро Linux 3.10.0-514.44.1.el7.x86_64 x86_64, ОЗУ 16 Гб.
В результате обучения нейронной сети на материале Датасета 1 был получен файл, состоящий из 7 560 строк, каждая из которых содержит в начале слово из словаря и вычисленные нейронной сетью 144 координаты вложения этого слова.
Для Датасета 2 эксперимент был проведен со следующими данными: vocab_size = 14 468 (количество уникальных слов, увеличено по сравнению с первым датасетом в два раза); выбранные параметры были следующие: window_size = 6; dim = 144; M = 19 033 (количество слов корпуса 54 100). Количество эпох обучения = 16 000. Обучение заняло 222 часа 10 минут. Параметры компьютера: Intel® Core™ i7-3770K CPU @ 3.50GHz x 8, операционная система ROSA Linux Server Edition, ядро Linux 3.10.0-514.44.1.el7.x86_64 x86_64, ОЗУ 16 Гб.
В результате обучения нейронной сети на материале Датасета 2 был получен файл, состоящий из 15 560 120 строк, каждая из которых содержит в начале слово из словаря и вычисленные нейронной сетью 144 координаты вложения этого слова.
Полученная модель языка позволяет определить, является ли текст информативным или в нем содержатся признаки дезинформации, недостоверных сведений или инфодеми-ческие признаки.
Далее решались задачи автоматической идентификации недостоверных текстов. На этом этапе применялись стандартные методы машинного обучения, такие как байесовский классификатор и метод ближайших соседей для идентификации неинформативного текста. Для применения этих методов использовалась модель, обученная на Датасетах 1 и 2. Все тексты преобразовывались в векторы на основе соответствующих вычисленных коэффициентов матрицы линейного преобразования.
Результаты проведенных экспериментов приведены в таблице 1.
Как следует из таблицы 1, наилучшего качества классификации удалось с помощью линейного метода опорных векторов (SVM). При этом точность распознавания повышается с увеличением объема словаря, о чем свидетельствуют данные эксперимента, полученные для Датасета 2.
Результаты и обсуждение
Рассмотрим ошибки автоматического распознавания достоверных / недостоверных текстов, которые были выявлены в результате фильтрации, проведенной с использованием обученной модели естественного языка. В таблице 2 приводятся примеры текстов, которые были ошибочно идентифицированы как содержащие признаки дезинформации с указанием типа ошибки и ее доли в общем количестве неправильно распознанных текстов.
Как показывают результаты анализа, наибольшее количество ошибок в группе информативных текстов связано с использованием класса имен собственных, в частности антропонимов, называющих государственных деятелей, известных спортсменов, артистов эстрады и кино, журналистов и телеведущих и т. д., например: Долина , Назарбаев , Ми-лохин , Ланская и др.; топонимов, называющих страны, города и другие географических объекты, например: Москва , Рязань , Свердловск , Турция , Россия и др. К отличительным признакам ошибочно классифицированных информативных текстов относится использование числительных (не только в основном тексте, но и в заголовках), например: Правительство выделит более 9 млрд
Таблица 1. Результаты автоматической идентификации медийных текстов с применением методов машинного обучения, %
Table 1. The results of media texts automatic detection by machine learning methods, %
|
Классификатор |
Точность предсказания |
|
|
Датасет 1 |
Датасет 2 |
|
|
Наивный байесовский классификатор |
74,63 |
77,93 |
|
Метод ближайших соседей |
74,87 |
77,35 |
|
Дерево решений |
73,82 |
74,59 |
|
Случайный лес |
80,37 |
80,30 |
|
Метод опорных векторов |
81,22 |
83,50 |
Таблица 2. Оценка качества выявления исследуемых информативных текстов на основе обученной модели языка
Table 2. Quality assessment of informative texts detection based on the learned language model
|
Языковые маркеры |
Примеры заголовков |
% |
|
Имена собственные (антропонимы) в сочетании с глаголами прошедшего времени |
Экс-первая ракетка мира Навратилова победила рак груди и горла. Оксану Самойлову экстренно госпитализировали со странными симптомами. Блогер Александр Черкасов разобрал 1,8-литровый мотор ВАЗ-21179 от LADA Vesta и XRay |
62,5 |
|
Имена собственные (антропонимы и топонимы) |
Бедствующий в Дубае Даня Милохин в три раза снизил гонорар за концерт – теперь ему достаточно миллиона. Андрей Бурковский из США: переехал на ПМЖ или просто гостит уже 2 месяца? |
18,75 |
|
Числительные |
Почти 70 % россиян не хватает 5 тысяч рублей до зарплаты |
18,75 |
рублей на строительство спортплощадок в регионах России .
В таблице 3 приведены примеры неинформативных текстов, ошибочно отмеченных машиной как информативные, доля которых составляет 16,5 %. Результат проверки качества автоматической оценки показал, что экспертная оценка текстов была проведена ошибочно в 6,3 % случаев, что свидетельствует о высокой точности модели. Доля нераспознанных деструктивных текстов составляет 10,2 %. Примеры текстов, которые были ошибочно идентифицированы как содержащие признаки информативности с указанием типа ошибки и ее доли в общем количестве неправильно распознанных текстов, представлены в таблице 3.
Как показывают результаты анализа, большая часть неправильно распознанных текстов, обладающих признаками недостоверности, содержат глаголы в будущем времени и отрицательно оценочную лексику. В меньшей степени представлены глаголы речи, такие как раскрывать , заговорить , заявить , назвать , пообещать , предрекать , раскрыть , заявить , ответить , что объясняется их широким использованием в информативных текстах; языковые средства, обозначающие ретроспекцию, то есть отсылку к произошедшему событию (глагол случаться в форме прошедшего времени). Выделенные языковые средства используются в следующих категориях недостоверных текстов:
– текстах, прогнозирующих развития событий по катастрофическому, деструктивному сценарию;
– текстах, содержащих конспирологическую аргументацию (ссылка на некий заговор, тайный глобальный план).
Выводы
Изучение текстов медийных сообщений как носителей объективного, достоверного знания или содержащего признаки инфодемии, ложной информации, отражающие деструктивные практики медийного дискурса, определяет значимость данного объекта для формального описания этих процессов средствами ИИ. Одним из прикладных аспектов этой проблематики является автоматическое распознавание информационной ценности текста посредством идентификации сообщений, содержащих признаки недостоверности и дезинформации, означающее, по сути, «понимание» машиной смысла высказывания. Опираясь на положение о системности медийной речи, детерминированной культурно и социально обусловленными целеустановками в структуре процессов информирования и воздействия, мы ставили цель – построить модель языка медийных сообщений и оценить эффективность алгоритма фильтрации текстов, содержащих ин-фодемические признаки.
Автоматический анализ текстов на основе обученной модели естественного языка продемонстрировал хорошее качество идентификации информативных и неинформативных текстов. Высокого качества классификации удалось добиться с помощью линейного метода опорных векторов (SVM).
Лингвистический анализ оценки эффективности идентификации текста, содержаще-
Таблица 3. Оценка качества выявления исследуемых недостоверных текстов на основе обученной модели языка
Table 3. Quality assessment of non-informative texts detection based on the learned language model
|
Языковые маркеры |
Примеры заголовков |
% |
|
Глаголы, обозначающие коммуникативные действия |
«Затронет весь мир»: экстрасенс заявила о грядущих авиакатастрофах |
15,7 |
|
Глаголы в будущем времени |
Каким будет мир в 2023 году: раскрыты жуткие записки Нострадамуса. Россия кончит плохо в апреле 2023. Страшное предсказание Глобы |
31,4 |
|
Лексика отрицательной оценочной семантики |
Час назад пришла трагическая весть об Мишустине: слезы по всей РФ. Крест на карьере: как Соловьев отмоется от такого позора |
47,1 |
|
Другие |
«ДАВНО УМЕР И ПОХОРОНИЛИ»: ЧТО СЛУЧИЛОСЬ С ПОПАВШИМ В БОЛЬНИЦУ НАЗАРБАЕВЫМ |
5,8 |
го признаки недостоверности и дезинформации, показал, что в области автоматического распознавания интенции имеются определенные успехи, но необходимо совершенствование имеющихся алгоритмов. Перспективы дальнейшего исследования видятся нам в разработке датасета языка медийных сообщений на русском языке и повышении эффективности алгоритмов автоматической фильтрации медийных сообщений.
Список литературы Атрибуция медийных текстов на основе обученной модели естественного языка и лингвистическая оценка качества идентификации
- Борхсениус А. В., 2021. Инфодемия: понятие, социальные и политические последствия, методы борьбы // Вестник Российского университета дружбы народов. Серия: Государственное и муниципальное управление. Т. 8, № 1. С. 52–58. DOI: 10.22363/2312-8313-2021-8-1-52-58
- Вольская Н. Н., 2018. Кликбейт как средство создания ложной информации в интернет коммуникации // Медиаскоп. № 2. DOI: 10.30547/mediascope.2.2018.12
- Жук Д. А., Жук Д. В., Третьяков А. О., 2018. Методы определения поддельных новостей в социальных сетях с использованием машинного обучения // Информационные ресурсы России. № 3. С. 29–32.
- Землянский А. В., 2021. Инфодемия: генезис и морфология явления // Вестник ВГУ. Серия: Филология и журналистика. № 4. С. 111–114.
- Ильинова Е. Ю., 2018. Полимодусность дискурсивной репрезентации медийного события // Когнитивные исследования языка. № 35. С. 280–287.
- Иссерс О. С., 2014. Медиафейки: между правдой и мистификацией // Коммуникативные исследования. № 2. С. 112–123.
- Карабулатова И. С., Копнина Г. А., 2023. Специфика лингвистической параметризации деструктивного массмедийного текста с обесцениванием исторической памяти // Медиалингвистика. Т. 10, № 3. С. 319–335. DOI: 10.21638/spbu22.2023.303
- Карабулатова И. С., Копнина Г. А., 2022. Лингвистическая параметризация деструктивного массмедийного текста: к постановке проблемы // Медиалингвистика. Вып. 9. Язык в координатах массмедиа: материалы VI Междунар. науч. конф. (СПб., 30 июня – 2 июля 2022 г.) / под ред. Л. Р. Дускаева. СПб.: Медиапапир. С. 364–367.
- Кондратьева О. Н., Игнатова Ю. С., 2023. Инфодемия: становление нового медиаконцепта // Медиалингвистика, Т. 10, № 4. С. 497–521. DOI: 10.21638/spbu22.2023.404
- Кошкарова Н. Н., Бойко Е. С., 2020. «Фейк, я тебя знаю»: лингвистические механизмы распознавания ложной информации // Политическая лингвистика. № 2 (80). С. 77–82. DOI: 10.26170/pl20-02-08
- Некрасов Г. А., Романова И. И., 2017. Разработка поискового робота для обнаружения веб-контента с фейковыми новостями // Инновационные, информационные и коммуникационные технологии. № 1. С. 128–130.
- Николаева А. В., 2019. Языковые особенности фейковых публикаций // Верхневолжский филологический вестник. № 3 (18). С. 55–59.
- Осипов Г. С., 2011. Методы искусственного интеллекта. М.: ФИЗМАТЛИТ. 296 с.
- Попов В. В., Штельмах Т. В., 2019. Естественный текст: математические методы атрибуции // Вестник Волгоградского государственного университета. Серия 2: Языкознание. Т. 18, № 2. С. 147–158. DOI: https://doi.org/10.15688/jvolsu2.2019.2.13
- Распопова С. С., Богдан Е. Н., 2018. Фейковые новости: Информационная мистификация: учеб. пособие. М.: Аспект Пресс. 112 с.
- Салимовский В. А., Девяткин Д. А., Каджая Л. А., Мишланов В. А., 2019. Автоматическое распознавание ментальных действий, реализуемых в научных эмпирических текстах // Научно-технические ведомости СПбГПУ. Гуманитарные и общественные науки. Т. 10, № 3. C. 74–88. DOI: 10.18721/JHSS.10307
- Салимовский В. А., Девяткин Д. А., Каджая Л. А., Мишланов В. А., Чудова Н. В., 2021. Исследование речевых жанров в задачах по искусственному интеллекту (идентификация познавательно-речевых действий, образующих жанровую форму) // Жанры речи. № 3 (31). С. 170–180. DOI: 10.18500/2311-0740-2021-3-31-170-180
- Сладкевич Ж. Р., 2019. Заголовки-анонсы в сетевых медиасервисах: между информированием и кликбейтингом // Медиалингвистика. Т. 6, № 3. С. 353–368. DOI: 10.21638/spbu22.2019.306
- Стернин И. А., Шестернина А. М., 2020. Маркеры фейка в медиатекстах. Воронеж: РИТМ. 34 с.
- Суходолов А. П., Бычкова А. М., 2017. «Фейковые новости» как феномен современного медиапространства: понятия, виды, назначения, меры противодействия // Вопросы теории и практики журналистики. Т. 6, № 2. C. 155–156.
- Третьяков О. А., 2018. Метод определения русскоязычных фейковых новостей с использованием элементов искусственного интеллекта // International Journal of Open Information Technologies. Vol. 6, № 12. P. 99–105.
- Хижнякова Е. В., 2023. Автоматическое распознавание инфодемического текста: к построению модели языка медийного дискурса // Медиалингвистика. Вып. 10. Язык в координатах массмедиа: материалы VII Междунар. науч. конф. (СПб., 28 июня – 1 июля 2023 г.) / науч. ред. Л. Р. Дускаева, отв. ред. А. А. Малышев. C. 201–206.
- Чанышева З. З., 2016. Информационные технологии смысловых искажений в кликбейт-заголовках // Вестник Пермского национального исследовательского политехнического университета. Проблемы языкознания и педагогики. № 4. С. 54–62. DOI: 10.15593/2224- 9389/2016.4.5
- Al Asaad B., Erascu M., 2018. A Tool for Fake News Detection // 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC) (Romania, 20–23 September). Timisoara. P. 379–386. DOI: 10.1109/SYNASC.2018.00064
- Anand A., Chakraborty T., Park N., 2017. We Used Neural Networks to Detect Clickbaits: You Won’t Believe What Happened Next! // 39th European Conference on Information Retrieval (ECIR). Lecture Notes in Computer Science (LNCS) (Aberdeen, United Kingdom, 8–13 April 2017). Vol. 10193. P. 541–547. DOI: 10.1007/978-3-319-56608-5_46
- Bednarek M., Caple H., 2017. The Discourse of News Values: How News Organizations Create Newsworthiness. N. Y.: Oxford University Press. 302 p.
- Bronakowski M., Al-khassaweneh M., Al Bataineh A., 2023. Automatic Detection of Clickbait Headlines Using Semantic Analysis and Machine Learning Techniques // Applied Sciences. Vol. 13, iss. 4. P. 2456. DOI: 10.3390/app13042456
- Biyani P., Tsioutsiouliklis K., Blackmer J., 2016. 8 Amazing Secrets for Getting More Clicks: Detecting Clickbaits in News Streams Using Article Informality // Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. URL: https://ojs.aaai.org/index.php/AAAI/article/view/9966
- Klyachin V. A., Khizhnyakova E. V., 2023. Machine Learning Methods and Words Embeddings in the Problem of Identification of Informative Content of a Media Text // CSOC2023, Artificial Intelligence Application in Networks and Systems. Proceedings of 12th Computer Science On-line Conference 2023, vol. 3. P. 463–471.
- Kumar V., Khattar D., Gairola S., Kumar Lal Y., Varma V., 2018. Identifying Clickbait: A Multi-Strategy Approach Using Neural Networks // Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval (Ann Arbor, MI, USA, 8–12 July 2018). P. 1225–1228.
- Mikolov T., Chen, K., Corrado, G. Dean J., 2013. Efficient Estimation of Word Representations in Vector Space. DOI: 10.48550/arXiv.1301.3781
- Pérez-Rosas V., Kleinberg B. Lefevre A., Mihalcea R., 2018. Automatic Detection of Fake News // Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe, New Mexico, USA. Association for Computational Linguistics. P. 3391–3401.
- Pujahari A., Sisodia D. S., 2021. Clickbait Detection Using Multiple Categorisation Techniques // Journal of Information Science. Vol. 47, iss. 1. P. 118–128. DOI: 10.1177/0165551519871822
- Razaque A., Alotaibi B., Alotaibi M., Hussain S., Alotaibi A., Jotsov V., 2022. Clickbait Detection Using Deep Recurrent Neural Network. Applied Sciences. Vol. 12, iss. 1. P. 504.
- Shu K., Wang S., Le T., Lee D., Liu H., 2018. Deep Headline Generation for Clickbait Detection // 18th IEEE International Conference on Data Mining (ICDM) (Singapore, 17–20 November). P. 467–476. DOI: 10.1109/ICDM.2018.00062
