Автоматический анализ фреймов для оценки воздействия текста

Автор: Котов А.А.
Журнал: Вестник Волгоградского государственного университета. Серия 2: Языкознание @jvolsu-linguistics
Рубрика: Теория и практика речевой коммуникации
Статья в выпуске: 3 т.23, 2024 года.
Бесплатный доступ
В статье рассматривается механизм работы семантического парсера при автоматическом анализе текстов и приводятся некоторые результаты анализа новостных сообщений общим объемом 2,2 млн клауз. Этот механизм моделирует процессы понимания текста и в данной работе применяется для оценки воздействия текста на читателя. Парсер конструирует семантическое представление текста и сопоставляет смысл каждой клаузы определенному фрейму из 300 эмоциональных и 4500 рациональных фреймов. В результате сравнения фреймов федеральных и оппозиционных (заблокированных в России) источников установлено, что в текстах федеральных СМИ чаще встречаются фреймы, характерные для интерактивного диалога между СМИ и спикером (отметить, добавить, вспоминать), а в текстах заблокированных СМИ - фреймы, вводящие высказывание спикера, которое стало известно данному источнику (сообщать, написать, говориться), что отражает удаленность редакций заблокированных СМИ от российских спикеров. Федеральные СМИ чаще рассказывают о забавных или неожиданных покупках, а также о том, как сотрудники федеральных служб спасают людей, что должно производить положительное впечатление. В заблокированных СМИ чаще упоминаются ситуации судебного приговора и гибели людей, что должно воздействовать негативно. Показано, что естественно-языковой вывод, получаемый с помощью комбинаций фреймов, позволяет распознавать эмоциональные ситуации в производных смыслах, прямо не выраженных в тексте, и автоматически анализировать более сложные механизмы манипуляции.
Автоматическое понимание текста, естественно-языковой вывод, автоматический анализ текста, речевое манипулирование, семантическое представление текста
Короткий адрес: https://sciup.org/149146324
IDR: 149146324 | УДК: 81’322.2 | DOI: 10.15688/jvolsu2.2024.3.4
Automatic frame analysis for the evaluation of text influence
The research paper focuses on the mechanism of semantic parser for automatic text analysis and represents some results of analyzing news with a total volume of 2.2 million clauses. This mechanism models the processes of text comprehension and in this paper it is applied to the evaluation of the text influence on the reader. The parser constructs a semantic representation of the text and maps the meaning of each clause to a particular frame belonging either to the set of 300 emotional or to the set of 4500 rational frames. Comparing the frames of pro-state (federal) and blocked sources in Russia, the authors show that the most frequent frames in federal news represent an interactive dialog between the media and the speaker (note, add, recall, etc.), while the most frequent frames in blocked news introduce the speaker’s utterance that has become known to the news agencies (report, write, say, etc.). This reflects the remoteness of the editors of blocked news from Russian speakers. The federal media more often report about funny or unexpected purchases, as well as about how federal employees rescue people, and this agenda should make a positive impression. The blocked media, on the other hand, are more likely to mention court sentencing and death, which should have a negative impact. The natural-language inference constructed via frame combinations is shown to enable the recognition of emotional situations in derived meanings that are not explicitly expressed in the text and, thus, it allows to analyze automatically more compound mechanisms of manipulation.
Текст научной статьи Автоматический анализ фреймов для оценки воздействия текста
DOI:
В классической литературе по лингвистике и искусственному интеллекту термин фрейм вводится для обозначения знакомой человеку стереотипной ситуации. Как писал М. Минский, все мы помним миллионы фреймов, каждый из которых представляет собой стереотипную ситуацию, например встретить человека определенного типа, находиться в комнате определенного типа или посетить мероприятие определенного типа [Minsky, 1988, p. 244]. Хотя в некоторых рассуждениях М. Минский говорит о фреймах для отдельных физических объектов (фрейм стола или фрейм человека), мы далее будем отталкиваться от понимания фрейма как представления о ситуации. Известным примером лингвистического анализа фреймов является проект FrameNet [Baker, Fillmore, Lowe, 1998]. В рамках этого проекта описано 1224 фрейма, большинство из которых соответствует глаголам или отглагольным существительным. Однако в инвентаре также представлены фреймы отдельных объектов типа ‘животное’ (animal) или ‘оружие’ (armor), которые соответствуют существительным, а также нелексические фреймы, которые имеют описательные названия, например ‘сце-нарий_путешественника’ (Visitor_scenario), где агент оставляет привычное место и приез- жает в новое место, преследуя некоторую цель, а затем возвращается в свое привычное место. Такое расширенное определение фрейма соответствует понятию сценария в литературе по искусственному интеллекту. Как отмечает Р. Шенк, сценарий включает последовательность ситуаций и позволяет отслеживать по тексту последовательность событий и действий героя [Шенк, 1980]. Аналогичный этому подход ранее использовался в российской лингвистике для описания сюжетной структуры волшебной сказки [Пропп, 1928], формального представления мотивов ее героев [Дорофеев, Мартемьянов, 1969].
Задача нашей работы состоит в том, чтобы продемонстрировать возможности приложения инвентаря фреймов и сценариев к задаче автоматического понимания текста. В статье показано, как данный инвентарь может использоваться для описания воздействия информационных источников на читателя. При этом мы будем использовать термин фрейм строго как описание регулярной (стереотипной) ситуации, соответствующей отдельной синтаксической клаузе, например простому предложению. Семантическое представление клаузы может быть достаточно богатым (включать множество признаков), но фрейм содержит только те признаки, которые характерны для стереотипной ситуации. Отнесение высказывания к фрейму позво- ляет человеку классифицировать высказывание, понять коммуникативное намерение автора, установить эмоциональную значимость высказывания, восстановить возможные причины и следствия описанной ситуации. Мы также будем использовать термин сценарий для обозначения стандартного отношения между фреймами.
Исследователи, ссылаясь на работы Р. Шенка и М. Минского, обычно рассматривают сценарии и фреймы как «классику искусственного интеллекта». Предполагается, что при решении многих задач они в последние десятилетия были с успехом заменены искусственными нейронными сетями. Тем не менее механизм фреймов и сценариев перспективен по нескольким причинам: а) он обладает объяснительной силой (мы можем проследить, почему агент выбрал некоторое решение или некоторую интерпретацию текста); б) он может использоваться для перебора решений в проблемном пространстве, то есть действовать аналогично универсальному решателю задач [Newell, Simon, 1972; Laird, Newell, Rosenbloom, 1987]; в) он может использоваться для явного конструирования альтернативных выводов или пониманий текста; г) он может использоваться роботами в задачах, где требуется комбинация речи и действия (например, если робот должен построить варианты действий и обсудить с человеком предпочтительный вариант).
Методы
Для решения поставленной задачи нами разработан парсер, который для каждого предложения строит его синтаксическое дерево и семантическое представление либо множество омонимичных деревьев и семантических представлений [Kotov et al., 2021]. Парсер представляет собой универсальную систему и может применяться в качестве самостоятельного программного продукта для анализа текстов, а кроме того – управлять роботом-компаньоном Ф-2 в коммуникации с человеком. В составе парсера присутствует множество д-сценариев (доминантных сценариев) [Котов, 2021] для оценки семантического представления как позитивного или негативного (см. рисунок). Например, робот рад, если на него обращают внимание (позитивный д-сценарий ВНИМАНИЕ) или если его хва- лят (позитивный д-сценарий «превосходство-одобрение» – ПРЕВОСХ-ОДОБР), но расстраивается, если против него что-то замышляют (негативный д-сценарий ПЛАНИР) или если он никому не нужен (негативный д-сце-нарий НЕНУЖН). Обработка начинается с того, что робот (парсер) получает на вход некоторый стимул S1 – это может быть смысл высказывания или репрезентация некоторой ситуации, распознанной роботом. В ответ на входящий стимул S1 могут быть активизированы несколько д-сценариев: d-scr1, d-scr2 (см. рисунок). Если стимул S1 совпал с фреймом Mi этого сценария – мы будем использовать термин начальное семантическое представление (или начальное представление) сценария. Сценарии активизируются пропорционально близости стимула S1 и их начальных представлений Mi. Наиболее релевантным будет считаться наиболее активизированный сценарий (d-scr1), он может подавить альтернативные сценарии. При работе парсера на роботе активизация каждого д-сценария порождает некоторый пакет поведения: робот отвечает на высказывание с помощью эмоциональной реакции – речи и жестов. Если же парсер работает на сервере, то для каждого высказывания будет рассчитана его близость к сценариям и эти данные будут сохранены в базу для дальнейшего анализа. Для теоретического инвентаря из 34 д-сценариев, описанных в нашей книге [Котов, 2021], в базе семантического парсера используется около 300 семантических представлений, поскольку клаузы, различающиеся структурой (синтаксические конверсивы и синонимичные варианты), записываются в базу как варианты одного сценария – как различные фреймы Mi. Например, высказывания (а) люди заботятся о тебе и (б) люди делают тебе добро относятся к одному д-сцена-рию ЗАБОТА, хотя их синтаксические и семантические структуры различны. Таким образом, каждый д-сценарий содержит некоторый фрейм Mi – репрезентацию эмоциогенной ситуации, обнаружение которой во входящих текстах вызывает активизацию сценария: возможную реакцию робота или сохранение результатов анализа в базу данных.
Уровень рациональной обработки смысла состоит из р-сценариев (рациональных сценариев). На рисунке р-сценарии представлены как
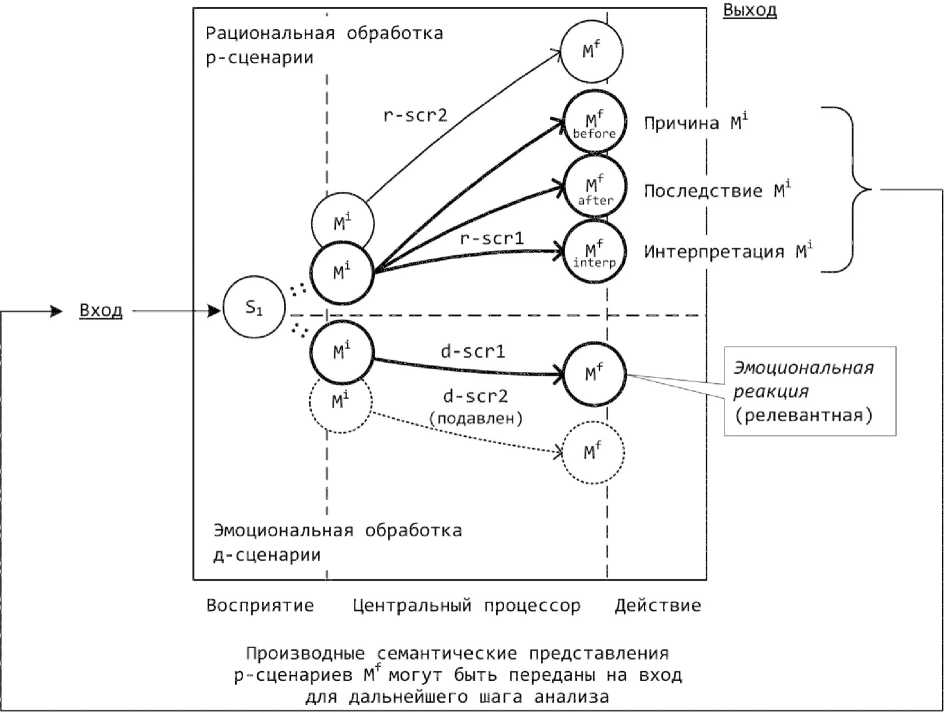
Общая схема сценариев
General scheme of scenarios
более высокий уровень модели, что соответствует архитектуре CogAff [Sloman, Chrisley, 2003]. Следуя этой же модели, мы считаем, что д- и р-сценарии конкурируют при анализе текста: механизм обработки смысла для робота состоит в том, что робот может предпочесть рациональный или эмоциональный способ интерпретации каждого высказывания, каждого входящего смысла S1. Р-сценарии должны правильно классифицировать семантику входящего сообщения и разрешать омонимию. Это достигается за счет того, что р-сценарии распознают в смысле текста свои начальные представления Mi: среди омонимичных разборов предложения выбирается тот, который ближе к некоторому известному положению дел, зафиксированному фреймом Mi. Кроме того, р-сценарии должны реконструировать возможные следствия и причины стимула S1. Таким образом, р-сценарии поддерживают механизм естественно-языкового вывода. Для этого каждый р-сценарий снабжается дополнительными фреймами – конечными представления- ми Mf. Такие конечные представления могут описывать причину исходного фрейма Mi (Mf типа before), следствие Mi (Mf типа after) или интерпретацию Mi (Mf типа interp) 2. Если некоторый р-сценарий был сопоставлен стимулу S1, то за счет своих конечных представлений Mf р-сцена-рий построит ситуации, связанные с S1.
Механизм естественно-языкового вывода комбинируется с механизмом эмоциональной оценки. При речевой манипуляции эмоциональным может оказаться не само содержание текста, а вывод из него. При моделировании этого процесса р-сценарий должен построить производные смыслы Mf, один из которых активизирует д-сценарий, то есть построенные смыслы Mf должны заново подаваться на вход модели для продолжения вывода 3. Например, высказывание террористы устроили взрыв сопоставляется рациональному сценарию, который конструирует следствие ‘погибли люди’4, и уже это следствие оценивается как негативное д-сценарием ОПАСН.
Для создания р-сценариев парсером были разработаны тексты общим объемом 80 млн словоформ и построили семантические представления отдельных клауз – факты ; всего около 10 млн. После этого мы кластеризовали эти факты так, чтобы в каждом кластере получить одно семантическое представление некоторой стандартной ситуации, встречающейся во всех клаузах этого кластера, или, иначе говоря, один фрейм, например: ‘крыса бегала по кругу’, ‘из комнаты раздался крик’ и т. д.; всего около 4500 фреймов. Каждый такой фрейм включает глагол и самое частотное существительное для каждой синтаксической валентности глагола. Эти фреймы примерно соответствуют глагольным фреймам в проекте FrameNet [Baker, Fillmore, Lowe, 1998]. Для каждого фрейма был создан р-сценарий, при этом фрейм занял позицию начального представления соответствующего сценария. Напомним, что начальное представление – это тот фрейм, обнаружение которого в тексте приводит к выбору данного р-сценария. Механизм сопоставления предложений сценариям при автоматическом анализе текста работает следующим образом: для каждой клаузы парсер строит ее семантическое представление и сравнивает его с начальными представлениями всех д- и р-сценариев, после чего информация о наиболее близких сценариях сохраняется в базе данных. Таким образом, для каждого сценария можно увидеть все предложения, в которых этот сценарий был выделен парсером, найти слова, замещающие каждую из валентностей фрейма данного сценария. Хотя в проекте FrameNet для каждого фрейма также можно просмотреть предложения-примеры, но эти соответствия – результат работы разметчиков. Ключевое отличие нашего подхода от других, нацеленных на решение схожих задач, состоит в том, что фреймы (и, как следствие, сценарии) обнаруживаются в тексте при автоматическом анализе. Это позволяет изучать тексты на основании встречаемости в них тех или иных фреймов.
Как было сказано выше, р-сценарий должен обеспечивать естественно-языковой вывод – строить производные семантические представления Mf. Для реализации этого механизма мы попросили 8 человек описать для каждого р-сценария (точнее, для его начального представления) возможные предшествующие и последующие ситуации, а также возможные интерпретации этой ситуации. Например, если ‘крыса бегала по кругу’, то, возможно, ранее ‘крыса потерялась’, ‘крыса искала выход’, а потом – ‘крыса выбралась на свободу’. Если ‘из комнаты раздался крик’, то, возможно, ‘преступник напал на человека в комнате’, ‘люди услышали крик из комнаты’ и т. д. Каждое такое связанное высказывание было разобрано парсером, и его семантика была включена в р-сценарий как конечное представление Mf. При этом в структуре сценариев была сохранена информация о кореферентности семантических структур сценария: то есть по кругу бегала именно та крыса, которая потерялась.
При поступлении высказывания парсер строит его семантическое представление, которое далее сопоставляет со всеми имеющимися сценариями. Наиболее близкий сценарий считается наиболее релевантной интерпретацией данного высказывания. В базе может не оказаться релевантного сценария для исходной ситуации, в этом случае ситуация будет обработана неверно: для ситуации будет выбран неверный р-сценарий, построены неверные производные смыслы. Например, если высказывание футболист бегал по полю будет сопоставлено сценарию ‘крыса бегала по кругу’, то это приведет к неверным выводам: ‘футболист потерялся’, ‘футболист искал выход’, ‘футболист выбрался [с поля] на свободу’. При верном сопоставлении высказывания сценарию парсер должен построить корректные (вероятные) производные смыслы. Так, этот механизм по высказыванию террористы устроили взрыв реконструирует смысл ‘погибли люди’, который сопоставляется д-сценарию ОПАСН при определении эмоциональной оценки высказывания.
Далее мы продемонстрируем методы анализа текстов по встречаемости р-сценариев, а затем перспективы оценки текста с учетом естественно-языкового вывода.
Результаты и обсуждение
Оценка текстов по используемым р-сценариям
В рамках проекта, посвященного анализу текстов СМИ, парсер ежедневно запускается для разбора текущих новостей из нескольких источников, наиболее влиятельных по данным сайта «Медиалогия». Сайты некоторых из этих СМИ заблокированы на территории России из-за нарушения законодательства или проведения оппозиционной политики – такие СМИ мы будем условно называть заблокированными.
Те СМИ, сайты которых доступны для граждан России, мы будем условно считать поддерживающими федеральную политику и для краткости называть федеральными . Материал федеральных и заблокированных СМИ ежедневно выгружается парсером из те-леграм-каналов, которые не заблокированы и в полном объеме доступны в России.
Всего с 24.10.2022 проанализировано 2,2 млн предложений, получено 5 млн фактов из следующих СМИ (в скобках приведены сокращенные наименования для удобства дальнейшего анализа): 360tv, LIFE (LIF), NEWS.ru (NEW), Москва 24 (М24), Московский комсомолец (МК), Радио Свобода * (РСв), Meduza (Мед), The Insider (Ins), Царьград ТВ (Ц), Голос Америки (ГАм), BBC News (BBC), ВЗГЛЯД.РУ (ВЗГ), РБК, Russia Today (RT), Газета.Ru (Газ), Лента дня (Лен), Комсомольская правда (КП). Их можно условно разделить на «развлекательные» и «серьезные» новостные источники [Переверзева и др., 2023]. Доля каждого источника составляет:
– федеральные «серьезные» СМИ: 360tv ≈ 0.078; LIF ≈ 0.012; NEW ≈ 0.042; RT ≈ 0.092; ВЗГ ≈ 0.069; Газ ≈ 0.051; КП ≈ 0.068; МК ≈ 0.05; РБК ≈ 0.056; Ц ≈ 0.098;
– федеральные «развлекательные» СМИ: М24 ≈ 0.024; Лен ≈ 0.042;
– заблокированные СМИ: BBC ≈ 0.086; Ins ≈ 0.018; ГАм ≈ 0.03; Мед ≈ 0.082; РСв ≈ 0.1.
Наблюдения над корпусом СМИ показывают, что одни р-сценарии чаще встречаются в текстах федеральных СМИ (см. табл. 1), другие – в текстах заблокированных СМИ (см. табл. 2).
В таблице 1 приведены р-сценарии, характерные для текстов федеральных СМИ, то есть те сценарии, относительная доля которых в новостях федеральных СМИ наиболее отличается от относительной доли этого сценария в оппозиционных источниках. Для сценария приведен ранг (по федеральным источникам), а также разница между рангом этого сценария в новостях федеральных и заблокированных СМИ.
Как видно, верх таблицы занимают общие бытийные суждения, имеющие сходный ранг в разных группах источников. Основным содержанием таблицы являются высказывания пропозициональной установки – суждения, вводящие цитату новостного источника (выделены курсивом). Вместе с тем в таблице имеются и сценарии, тематически отражающие специфику данной группы источников. Это прежде всего @купить_2235_VERB_2 и @спасти_5056_VERB_3 (выделены полужирным); эти два сценария будут рассмотрены далее.
В заблокированных новостных каналах также имеются тематически отличающиеся сценарии (см. табл. 2), прежде всего @приговорить_16667_VERB_2 и 1, а также @погибнуть_3647_VERB_2 (выделены полужирным).
Как и в таблице 1, основное содержание таблицы 2 представляют суждения, вводящие цитату (выделены курсивом). Однако список этих сценариев в новостных источниках разных групп обладает значимыми различиями. В новостях федеральных СМИ используются сценарии, иллюстрирующие живой интерактивный диалог с информационным источником: отметить , добавить , ожидать , вспоминать , признаться 5. Вместе с тем оппозиционные источники «издалека» цитируют спикеров, находящихся в российском информационном поле, поэтому используются более формальные сценарии: говориться , сообщать , сообщаться , утверждать , подтвердить . Таким образом, основное противопоставление сценариев отражает ситуацию, при которой редакции заблокированных СМИ находятся за рубежом и обычно цитируют ньюсмейкеров, а федеральные корреспонденты могут интервьюировать ньюсмейкеров лично и пишут об этом в более интерактивной манере.
Таблица 1. Р-сценарии текстов федеральных СМИ
Table 1. R-scenarios of texts of the federal media
|
Ранг |
Р-сценарий |
Кол-во |
Доля сценария |
Разница в ранге |
Разница в доле |
|
1 |
@иметься_1794_VERB_1 |
104885 |
0.0637 |
0 |
0.0158 |
|
2 |
@иметься_1794_VERB_4 |
55189 |
0.0335 |
0 |
0.0042 |
|
5 |
@предупредить_4054_VERB_3 |
19427 |
0.0118 |
1 |
0.0025 |
|
4 |
@существовать_5254_VERB_1 |
27583 |
0.0168 |
0 |
0.0022 |
|
16 |
@сообщить_5010_VERB_6 |
7528 |
0.0046 |
18 |
0.0017 |
|
9 |
@иметься_1794_VERB_13 |
11546 |
0.0070 |
6 |
0.0015 |
|
20 |
@увидеть_5549_VERB_1 |
5579 |
0.0034 |
58 |
0.0015 |
|
57 |
@отметить_3328_VERB_3 |
3220 |
0.0020 |
166 |
0.0011 |
|
46 |
@решить_4536_VERB_7 |
3615 |
0.0022 |
85 |
0.0009 |
|
45 |
@понять_3874_VERB_1 |
3641 |
0.0022 |
68 |
0.0008 |
|
50 |
@найти_2729_VERB_2 |
3463 |
0.0021 |
72 |
0.0008 |
|
69 |
@купить_2235_VERB_2 |
2991 |
0.0018 |
85 |
0.0007 |
|
24 |
@добавить_1172_VERB_1 |
5344 |
0.0032 |
18 |
0.0007 |
|
38 |
@хотеть_5875_VERB_4 |
4184 |
0.0025 |
41 |
0.0007 |
|
31 |
@хотеть_5875_VERB_3 |
4751 |
0.0029 |
25 |
0.0007 |
|
82 |
@случиться_4892_VERB_8 |
2648 |
0.0016 |
106 |
0.0007 |
|
163 |
@существовать_5254_VERB_32 |
1656 |
0.0010 |
430 |
0.0007 |
|
62 |
@ожидать_3155_VERB_1 |
3107 |
0.0019 |
75 |
0.0006 |
|
138 |
@вспоминать_699_VERB_1 |
1862 |
0.0011 |
277 |
0.0006 |
|
90 |
@летать_2305_VERB_3 |
2409 |
0.0015 |
141 |
0.0006 |
|
183 |
@спасти_5056_VERB_3 |
1548 |
0.0009 |
475 |
0.0006 |
|
185 |
@признаться_16721_VERB_1 |
1527 |
0.0009 |
489 |
0.0006 |
Таблица 2. Р-сценарии текстов заблокированных СМИ
Table 2. R-scenarios of texts of the blocked media
|
Ранг |
Р-сценарий |
Кол-во |
Доля сценария |
Разница в ранге |
Разница в доле |
|
8 |
@говориться_908_VERB_1 |
5593 |
0.0081 |
27 |
0.0054 |
|
9 |
@написать_2757_VERB_2 |
5551 |
0.0080 |
6 |
0.0033 |
|
18 |
@сообщать_19280_VERB_3 |
3205 |
0.0046 |
23 |
0.0022 |
|
5 |
@заявить_10117_VERB_1 |
8493 |
0.0122 |
1 |
0.0020 |
|
28 |
@сообщаться_19281_VERB_5 |
2263 |
0.0033 |
78 |
0.0019 |
|
48 |
@побеждать_15310_1844 |
1668 |
0.0024 |
287 |
0.0018 |
|
13 |
@рассказывать_4453_VERB_2 |
4546 |
0.0065 |
1 |
0.0018 |
|
43 |
@утверждать_20867_VERB_5 |
1772 |
0.0026 |
157 |
0.0017 |
|
27 |
@подтвердить_3711_VERB_2 |
2280 |
0.0033 |
47 |
0.0015 |
|
36 |
@сообщать_19280_VERB_1 |
1974 |
0.0028 |
66 |
0.0015 |
|
53 |
@утверждать_20868_1397 |
1567 |
0.0023 |
157 |
0.0014 |
|
80 |
@приговорить_16667_VERB_2 |
1280 |
0.0018 |
317 |
0.0013 |
|
20 |
@рисовать_4541_VERB_1 |
2862 |
0.0041 |
12 |
0.0013 |
|
7 |
@рассказать_4452_VERB_2 |
6426 |
0.0093 |
0 |
0.0013 |
|
30 |
@погибнуть_3647_VERB_2 |
2201 |
0.0032 |
33 |
0.0013 |
|
26 |
@сообщить_5010_VERB_1 |
2460 |
0.0035 |
18 |
0.0013 |
|
11 |
@находиться_2824_VERB_9 |
5161 |
0.0074 |
0 |
0.0012 |
|
32 |
@измениться_1772_VERB_10 |
2078 |
0.0030 |
36 |
0.0012 |
|
19 |
@сказать_4809_VERB_2 |
3070 |
0.0044 |
2 |
0.0011 |
|
95 |
@приговорить_16667_VERB_1 |
1104 |
0.0016 |
310 |
0.0011 |
Р-сценарии, характерные для федеральных источников: сценарии купить и спасти
Сценарий купить (@купить_2235_ VERB_2) описывает ситуации достаточно широкого класса, а именно смену владельца некоторого объекта. Так, этот сценарий активизируется семантическими репрезентациями клауз не только с глаголом купить , но и с другими семантически близкими глаголами: взять , унаследовать , стрельнуть ( сигарету ) и др., например:
-
(1) Именно его ружье взяла девочка, а потом пришла в учебное заведение и убила одноклассницу и себя ( https://t.me/tv360/133773 );
-
(2) По слухам, после смерти модельера в 2019 году его кошка унаследовала 300 млн (https:// t.me/gazetaru/20056);
-
(3) В Израиле женщина подошла на заправке к мужчине в надежде « стрельнуть» сигарету ( https://t.me/truekpru/121416 ).
Примечательно, что если из списка федеральных источников исключить источники развлекательного характера – «Москву 24» и «Ленту дня», то разница в доле федеральных и заблокированных СМИ существенно уменьшится и составит 0.0005. В таком случае сценарий купить не вошел бы в перечень частотных р-сценариев текстов федеральных СМИ (см. табл. 1). Очевидно, именно эти два источника обеспечивают статистическое преимущество федеральных источников над заблокированными.
Основная доля примеров данного сценария сформирована клаузами с глаголами закупать , закупить , заполучить , купить (включая формы купивший , куплен и купив ), покупать , приобрести и скупать , то есть с глаголами, обозначающими ситуацию купли-продажи. Ниже мы рассмотрим эти примеры и укажем на ряд различий в их содержании.
В новостях некоторых заблокированных источников 6 в роли покупателя часто выступает государство, компания или большая группа лиц, при этом сообщается обычно о самом факте покупки или о намерении что-либо купить:
-
(4) Ранее премьер-министр Польши Матеуш Моравецкий сообщал, что Украина купила у Польши
100 восьмиколесных боевых бронированных машин Rosomak... ( https://t.me/bbcrussian/44435 );
-
(5) Французский производитель спиртных напитков Pernod Ricard купил бренд водки Absolut у правительства Швеции в 2008 году ( https://t.me/ bbcrussian/44873);
-
(6) Российские импортеры покупают зарубежную продукцию, оплачивая акциз в России ( https://t.me/bbcrussian/54304 );
-
(7) По данным «Агентства», госкомпании и учреждения намерены купить 114 автомобилей из Китая, 37 машин – из Кореи, Японии и Чехии ( https://t.me/radiosvoboda/46999 );
-
(8) После этого учебные заведения , как показало расследование «Важных историй», стали их [беспилотники] закупать для образовательных целей ( https://t.me/radiosvoboda/44532 ).
В «развлекательных» источниках в роли покупателя часто выступают отдельные лица:
-
(9) Военный незаконно купил восемь гранат ( https://t.me/lentadnya/95812 );
-
(10) Шаурму купил владелец местного донера из-за салата в составе ( https://t.me/lentadnya/88721 );
-
(11) В Москве женщина купила ребенка за миллион рублей ( https://t.me/infomoscow24/53255 );
-
(12) Любовь купила ягоду в продуктовом магазине на улице Ватутина ( https://t.me/infomoscow24/42526 ).
Нередко такие источники рассказывают читателям о возможности / невозможности покупки чего-либо:
-
(13) Чипсы Pringles теперь можно купить вместе с настоящей икрой ( https://t.me/lentadnya/91780 );
-
(14) Купить билеты на поезд онлайн пока не получится , но в компании заявили, что уже все чинят ( https://t.me/lentadnya/84733 );
-
(15) Здесь мож [ но ] будет примерить и купить одежду ( https://t.me/infomoscow24/58043 );
-
(16) Купить любимый парфюм и не нарваться на подделку теперь стало настоящим квестом ( https://t.me/infomoscow24/43468 ).
«Развлекательные» источники могут обращаться к читателям с прямым вопросом Купили (ли) бы (вы себе) ...?:
-
(17) Представляем вашему вниманию шапочки для носа в мороз. <...> Купили бы? ( https://t.me/ lentadnya/100462);
-
(18) «АвтоВАЗ» представил новый отечественный автомобиль – Lada Vesta Aura. Цены вопроса – 2 миллиона рублей. <...> Купили бы? (https:// t.me/lentadnya/82131);
-
(19) Любмени появились в российских супермаркетах. Это пельмени в виде сердечек. <...> Купили бы? ( https://t.me/lentadnya/103018 );
-
(20) А вы бы купили машину на маркетплей-се? ( https://t.me/infomoscow24/60796 );
-
(21) Скафандр, в котором актриса Юлия Пе-ресильд летала в космос, выставили на аукцион. <...> Купили бы себе? ( https://t.me/infomoscow24/47344 ).
Сообщения о том, что у читателей появилась (или, наоборот, пропала) возможность что-либо приобрести, а также о том, что кто-либо (часто – известный человек) совершил какую-либо покупку (часто – необычную или очень дорогую), встречаются и новостях оппозиционных каналов:
-
(22) В Кызыле купить спиртное можно будет только в заведениях общепита ( https://t.me/meduzalive/76097 );
-
(23) Американка купила в комиссионке дешевую вазу и продала ее за $107 тыс ( https://t.me/ GolosAmeriki/28014);
-
(24) Глава «Газпром нефти» избежал санкций и купил особняк в Каннах ( https://t.me/theinsider/25062 ).
Очевидно, тексты о покупке интересны читателю. При этом наблюдается важное различие между количеством примеров данного сценария в источниках разных типов. Как было отмечено выше, наибольшее количество таких примеров содержится в новостях федеральных СМИ, причем, как правило, именно в «развлекательных» источниках. Федеральные СМИ пишут про «покупки» или как про некоторые курьезы и интересные случаи, или как про возможность человека приобрести товар. Заблокированные СМИ содержат очень мало таких контекстов; обычно эти источники описывают ситуации корпоративных или государственных закупок, например государственные закупки вооружения. Наш вывод состоит в том, что в заблокированных источниках в очень малой степени присутствуют тексты о повседневной жизни человека – о покупках и стиле жизни.
Сценарий спасти (@спасти_5056_ VERB_3) также чаще появляется в новостях федеральных СМИ. В роли агенса этого сценария часто выступают врач , сотрудник , пожарный и полицейский (всего 107 примеров):
-
(25) После смерти Моисеева Людмила попала в больницу: ее чудом спасли врачи ( https://t.me/ mk_ru/17656);
-
(26) Сотрудница полиции покормила грудью ребенка, более двух суток голодавшего после урагана ( https://t.me/lentadnya/95443 ).
Таким образом, новости федеральных СМИ часто представляют ситуацию, где врачи, полицейские и спасатели помогают гражданам. Для заблокированных источников данная особенность не характерна, в них имеется только 5 примеров с данным агенсом. В целом в заблокированных источниках агенс указывается при глаголе сравнительно редко. Говоря о ситуациях спасения, заблокированные СМИ широко используют пассивные конструкции и неопределенно-личные предложения, например:
-
(27) Спасены три человека, сообщает ведомство ( https://t.me/meduzalive/86864 );
-
(28) Там девушку спасли : из ее тела вытащили пулю, сейчас она восстанавливается ( https://t.me/ bbcrussian/62849).
Таким образом, в описаниях событий новости заблокированных СМИ снижают аген-тивность субъектов – врачей и сотрудников федеральных служб (аналогичный метод воздействия рассмотрен в: [Блакар, 1987]). Кроме того, новости заблокированных СМИ обычно сообщают не столько о совершившемся факте спасения, сколько о его возможности, используя при этом инфинитивные конструкции, где также снижается агентивность потенциального субъекта:
-
(29) Бродач призывает израильских военных сделать все возможное, чтобы спасти заложников ( https://t.me/radiosvoboda/50604 );
-
(30) Митинг солидарности с Израилем в центре Вашингтона и акция латиноамериканских активистов в Лос-Анджелесе с призывами спасти палестинских жителей ( https://t.me/GolosAmeriki/25624 );
-
(31) Волонтеры ныряли, пытаясь спасти животных, но ничего сделать не удалось, рассказали они The Insider ( https://t.me/theinsider/19334 ).
В федеральных источниках, напротив, предложения с агенсом, соответствующие сценарию спасти , встречаются часто. Интересный пример представляет «Лента дня». Наш корпус содержит 11 фраз из этого источника, в которых агенс обозначен словом россияне , даже в тех случаях, когда в тексте новости не упоминаются жители других стран:
-
(32) Россияне спасли женщину с кошкой из горящей квартиры. Жители Подмосковья увидели пожар в жилом доме ( https://t.me/lentadnya/108723 );
-
(33) Россияне спасли повисшего на балконе девятого этажа ребенка. Жители дома в Кисловодске услышали крики и вышли во двор ( https://t.me/ lentadnya/95214);
-
(34) «Биперы на поиск!»: россияне спасли людей, на которых сошла лавина. Пласт снега внезапно накрыл экстремалов в Хакасии ( https://t.me/ lentadnya/105373).
Во всех этих примерах номинация россияне не привносит в текст дополнительных знаний: очевидно, что и жители Подмосковья, и жители Кисловодска, и (по всей вероятности) лыжники и сноубордисты в Хакасии являются россиянами, и эта номинация избыточна (например, возможно перефразировать первое предложение как Женщина с кошкой была спасена из горящей квартиры без какой-либо потери смысла). Думается, что причины его появления в текстах «Ленты дня» идеологические: авторы новостей поддерживают у своей аудитории чувство национальной гордости, напоминая читателям об их принадлежности к нации, представители которой помогают тем, кто попал в беду.
На наш взгляд, количественный перевес сценария спасти в текстах федеральных СМИ может быть объяснен тем, что в новостях данного типа существенно выделяется тема помощи, которую оказывают пострадавшим россияне или сотрудники государственных служб. Сообщения о спасении людей помогают федеральным СМИ создавать позитивную новостную повестку.
Р-сценарии, характерные для оппозиционных источников: сценарии приговорить и погибнуть
Сценарий приговорить (точнее, два сценария приговорить_16667_VERB_1 и приговорить_16667_VERB_2; далее для краткости мы позволим себе объединить их под одним названием) и сценарий погибнуть (@погибнуть_3647_VERB_2) описывают ситуацию преступления или трагедии, то есть относятся к сценариям, способным вызвать не- гативную эмоциональную реакцию аудитории. Ряд исследователей (см., например: [Маркелов, Громова, Нафиева, 2019], а также обзор западных работ в: [Lichter, 2017]) обращают внимание на большое количество новостей негативного содержания в разных типах СМИ в целом. Некоторые объясняют это повышенным интересом аудитории к плохим новостям, получившим в англоязычной литературе название «negativity bias» («негативный уклон»), который, в свою очередь, имеет психологические причины [Колезев, 2018; Keene et al., 2017]. В нашем случае, однако, значимым фактором оказывается политическая ориентация источника. Сценарии приговорить и погибнуть встречаются преимущественно в заблокированных СМИ, федеральные же СМИ стараются их избегать. Такая редакционная политика федеральных источников может быть объяснена их нежеланием подчеркивать значимость соответствующих событий, поскольку, как было показано в работах, описывающих механизмы формирования новостной повестки, количество упоминаний некоторого факта в новостях прямо связано с потенциальной эмоциональной оценкой этого факта аудиторией [Черепанова, 2016; McCombs, Shaw, 1972].
В качестве примера рассмотрим сценарий приговорить . В большинстве своем соответствующие ему фразы содержат предикаты приговорить и осудить :
-
(35) Бизнесмена Василия Бойко-Великого осудили на 6,5 года за хищение 89 млн рублей (https:// t.me/tv360/127257);
-
(36) Суд заочно приговорил к 8 годам колонии Дмитрия Глуховского ** – автора постапокалиптических романов «Метро» ( https://t.me/lentadnya/87852 );
-
(37) В Волгограде пятерых военных осудили за попытку откупиться от повторной отправки на фронт ( https://t.me/meduzalive/96995 );
-
(38) Сопредседателя «Мемориала» Олега Орлова приговорили к штрафу в размере 150 тысяч рублей ( https://t.me/radiosvoboda/49013 ).
Тематически близкие новости с этим сценарием несколько различаются в федеральных и оппозиционных источниках. В новостях федеральных СМИ сравнительно малочислен- ные примеры этого сценария описывают ситуации вынесения приговора людям, совершившим тяжкие преступления (пример (35)), либо иностранным оппозиционным деятелям (36). Заблокированные источники, напротив, подробно описывают приговоры, вынесенные противникам военных действий (37) или оппозиционным деятелям, находящимся в России (38). Именно за счет таких примеров сценарий приговорить чаще представлен в новостях заблокированных СМИ.
Отдельного внимания заслуживают сюжеты, посвященные мигрантам. В федеральных источниках мигранты нередко выступают в роли агента противоправных действий, а в заблокированных – в роли жертвы (тем самым при дальнейшей обработке таких высказываний д-сценариями упоминающимся в них персонажам в одном случае может быть приписана глубинно-семантическая роль AGGR, в другом – VICT, см.: [Котов, 2021]):
-
(39) (Фед.) «Насиловал детей, душил мать»: Суд в Тюмени приговорил мигранта к 14 годам ( https://t.me/tsargradtv/62838 );
-
(40) (Заблок.) В июле прошлого года российский суд приговорил Максима Аристархова к 16 годам лишения свободы по делу об убийстве двух мигрантов в 2007 году на почве межнациональной ненависти ( https://t.me/radiosvoboda/50521 ).
Неодинаковое отношение новостных источников к мигрантам демонстрирует и сценарий погибнуть . Во фразах, соответствующих данному сценарию, мигранты упоминаются 8 раз. 7 примеров принадлежат заблокированным источникам, которые рассказывают о гибели мигрантов:
-
(41) ООН: в 2023 году погибло наибольшее количество мигрантов за 10 лет ( https://t.me/ GolosAmeriki/31008);
-
(42) Неизвестно, были ли все погибшие мигрантами, однако сообщается, что большинство жертв – граждане Венесуэлы ( https://t.me/radiosvoboda/40489 ).
В единственном примере из федерального источника сообщается о гибели военного по вине мигранта:
-
(43) ...Обладатель множества наград погиб в глубоком тылу от рук пьяного мигранта (https:// t.me/tsargradtv/57978).
Механизм естественно-языкового вывода для автоматического анализа
Механизм сценариев должен не только классифицировать семантику высказывания, относя ее к конкретному фрейму, но и строить производные семантические представления – элементы естественно-языкового вывода. Моделирование этого процесса позволит: а) лучше описать механизм понимания текста человеком; б) создавать роботов, обладающих большими интеллектуальными способностями; в) распознавать в тексте фрагменты, воздействующие на читателя за счет имплицитных смыслов.
Рассмотрим пример обработки парсером производных смыслов. Высказывание Террористы устроили взрыв содержит семантически бедный предикат устроить (результат лексической функции Caus( взрыв )), который затрудняет распознавание в высказывании прототипических эмоциональных ситуаций. Для оценки воздействия этого высказывания оно должно быть преобразовано в форму, более прозрачную для д-сценариев. При работе парсера данное высказывание относится к сценарию @устроить_5702_VERB_3 – ‘смертник устроил взрыв’. Среди конечных представлений этого сценария – ‘люди погибли’ и ‘смертник взорвал людей’. Каждое из этих следствий – вероятностное, в исходном высказывании они не подтверждаются. Вместе с тем производный смысл ‘смертник взорвал людей’ уже соответствует д-сценарию ОПАСН (близость 0.1920).
В исходном варианте Террористы устроили взрыв высказывание ближе к р-сценариям (близость 0.2986 к @устроить_5702_VERB_3), чем к д-сценариям (близость 0.1406 к позитивному д-сценарию ТВОРЕНИЕ – ‘человек создает шедевр’ и 0.1403 к негативному д-сце-нарию ПЛАНИР – ‘люди замышляют что-то против меня’). Однако высказывание Террористы взорвали людей уже ближе к д-сце-нариям: близость 0.1920 к д-сценарию ОПАСН и 0.1809 к наилучшему р-сценарию @убить_5534_VERB_1. Хотя производные смыслы и имеют вероятностную природу, сама возможность построения таких эмоциональных смыслов должна добавлять парсеру мотивации: если робот «боится», что такое эмоциональное следствие возможно, он должен переспрашивать это в диалоге или искать подтверждение в контексте.
Заключение
Как мы показали в работе, подход, основанный на классических концепциях фреймов и сценариев, может оказаться перспективным для автоматического анализа семантики текста. Этот подход применим при анализе упоминания ситуаций и определении имплицитных смыслов текста. Статистический анализ фреймов, автоматически обнаруженных в тексте, позволил выявить различия между федеральными и заблокированными СМИ, что в свою очередь позволило сделать выводы о коммуникативной дистанции между новостными источниками и ньюсмейкерами, а также описать частотные фреймы в СМИ, навязывающие читателю определенные темы и концептуализацию событий. Статистические данные, полученные в ходе автоматического анализа фреймов, предоставляют исследователям возможности для оценки потенциального воздействия текстов различных источников на аудиторию.
Сценарии, активизированные конкретными фреймами, позволяют реконструировать имплицитные смыслы, которые могут содержаться в тексте. Таким образом, для формального лингвистического анализа становится доступно еще одно сложное семантическое явление, традиционно связываемое с речевым воздействием, но ранее не поддававшееся автоматическому анализу. В целом с использованием аппарата фреймов и сценариев при автоматическом анализе текста можно обнаружить и зафиксировать для дальнейшего лингвистического анализа, проводимого человеком, различные смысловые элементы, участвующие в неявной передаче смыслов и оценок посредством естественно-языковых единиц.
Список литературы Автоматический анализ фреймов для оценки воздействия текста
- Блакар Р. М., 1987. Язык как инструмент социальной власти // Язык и моделирование социального взаимодействия. М.: Прогресс. С. 88–125.
- Дорофеев Г. В., Мартемьянов Ю. С., 1969. Логический вывод и выявление связей между предложениями в тексте // Машинный перевод и прикладная лингвистика. Т. 12. С. 36–59.
- Колезев Д. Е., 2018. Негативный уклон: почему интернет-СМИ так много пишут о плохом // Приоритеты массмедиа и ценности профессии журналиста. Екатеринбург: Урал. федер. ун-т им. первого Президента России Б.Н. Ельцина. С. 33–36.
- Котов А. А., 2021. Механизмы речевого воздействия. М.: РГГУ. 431 с.
- Маркелов К. В., Громова Е. Б., Нафиева Н. Р., 2019. Негативная новость на центральных телеканалах России и Украины: общее и специфическое // Вестник Российского университета дружбы народов. Серия: Литературоведение. Журналистика. Т. 24, № 3. С. 521–532. DOI: 10.22363/2312-9220-2019-24-3-521-532
- Переверзева С. И., Котов А. А., Жеребцова Я. А., Зинина А. А., 2023. Вводные слова и выражения со значением (не)уверенности в Telegram-каналах СМИ // Вестник РГГУ. Серия «Литературоведение. Языкознание. Культурология». № 5. С. 153–185. DOI: 10.28995/2686-7249-2023-5-153-185
- Пропп В., 1928. Морфология сказки. Л.: Academia. 152 с.
- Черепанова Д. А., 2016. Информационная повестка как механизм формирования политического имиджа государства // Вестник Поволжского института управления. № 5 (56). С. 136–141.
- Шенк Р., 1980. Обработка концептуальной информации. М.: Энергия. 360 с.
- Allen S. R., 2001. Concern Processing in Autonomous Agents: Ph.D. thesis. The University of Birmingham. 225 p.
- Baker C. F., Fillmore C. J., Lowe J. B., 1998. The Berkeley FrameNet Project // 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics. Vol. 1. Montreal: Association for Computational Linguistics. P. 86–90. DOI: 10.3115/980845.980860
- Keene J. R., Shoenberger H., Berntike C. K., Bolls P. D., 2017. The Biological Roots of Political Extremism: Negativity Bias, Political Ideology, and Preferences for Political News // Politics and the Life Sciences. № 36 (2). P. 37–48.
- Kotov A., Zaidelman L., Zinina A., Arinkin N., Filatov A., Kivva K., 2021. Conceptual Processing System for a Companion Robot // Cognitive Systems Research. Vol. 67. P. 28–32. DOI: 10.1016/j.cogsys.2020.12.007
- Laird J. E., Newell A., Rosenbloom P. S., 1987. SOAR: An Architecture for General Intelligence // Artificial Intelligence. Vol. 33, № 1. P. 1–64. DOI: 10.1016/0004-3702(87)90050-6
- Lichter S. R., 2017. Theories of Media Bias // The Oxford Handbook of Political Communication. Oxford: Oxford University Press. P. 403–416.
- McCombs M. E., Shaw D. L., 1972. The Agenda-Setting Function of Mass Media // The Public Opinion Quarterly. Vol. 36, № 2 (Summer, 1972). P. 176–187.
- Minsky M. L., 1988. The Society of Mind. N. Y.: Simon & Schuster. 339 p.
- Newell A., Simon H., 1972. Human Problem Solving. Englewood Cliffs: Prentice-Hall. 920 p.
- Sloman A., Chrisley R., 2003. Virtual Machines and Consciousness // Journal of Consciousness Studies. № 10 (4–5). P. 133–172.
