Автоматическое определение основ персидских глаголов: формальные vs. нейросетевые правила

Автор: Пиотровский Раймонд Генрихович, Луканин Артем Викторович
Журнал: Вестник Южно-Уральского государственного университета. Серия: Лингвистика @vestnik-susu-linguistics
Рубрика: Грамматика и прикладная лингвистика
Статья в выпуске: 2 (135), 2009 года.
Бесплатный доступ
В статье рассматриваются 2 подхода к автоматическому выводу основы настоящего времени из основы прошедшего времени персидских глаголов. Описываемая система генерации форм глаголов, основанная на фреймовом подходе, использует формальные правила и лексикон исключений. Предлагаемый нейросетевой подход, кроме того, позволяет выводить скрытые закономерности в формировании основ и не требует лексикона исключений.
Искусственная нейронная сеть, фрейм, вычислительная морфология
Короткий адрес: https://sciup.org/147153673
IDR: 147153673 | УДК: 81'322
Automatic determination of Persian verb stems: formal vs. neural network rules
The paper presents two approaches for automatic generation of present stems out of past stems of Persian verbs. Described Persian Verb Conjugator based on frame approach use formal rules and exceptions lexicon. Proposed neural network finds hidden regularities in stem generation and does not require a separate exceptions lexicon.
Текст научной статьи Автоматическое определение основ персидских глаголов: формальные vs. нейросетевые правила
Одним из популярных приемов организации выходного результата в системах ИИ, АПТ и обучающих лингвистических автоматов 60-х начала 90-х годов явилось использование заранее заготовленных шаблонов-ожиданий, или фреймов. Этот прием был подсказан машинной метафорой человеческого интеллекта, предложенной в период первой когнитивной революции. Вторая когнитивная революция середины 80-х годов поставила под сомнение предположение о жестко фреймовом характере самого человеческого мышления. Однако фреймовая методика успешно применяется для решения различных прикладных задач автоматической переработки текста (АПТ).
В связи с трудностью обучения спряжению персидских глаголов нами была разработана система автоматической генерации парадигм глаголов Persian Verb Conjugator (PVC), основанная на фреймовом подходе. Система PVC расположена по адресу:
В PVC каждой форме глагола соответствует строго определённый фрейм, слоты которого либо остаются пустыми, либо заполняются псевдо-аффиксами, вычисляемыми для каждого глагола на основе фонологических правил. Под псевдо-аффиксом понимается последовательность букв, неизоморфная суффиксу в традиционной грамматике. К примеру, инфинитив «suk-htan» (6^3“) делится на первичное причастие (the primordial participle) «sukh» и суффикс «tan» в Академической грамматике современного nep-
сидского языка1, в то время как в PVC инфинитив делится на основу прошедшего времени «sukht» и псевдо-аффикс «ап».
Для большинства глаголов в PVC выводится 112 словоформ. Тем не менее, функция генерации форм глагола, используемая как в системе PVC, так и в тестах по спряжению, может сгенерировать 240 словоформ (120 в активном залоге и 120 в пассивном залоге). В функции генерации содержится 120 фреймов для генерации форм глагола в активном залоге и 1 фрейм для генерации причастия прошедшего времени, который в соединении с фреймами активного залога формирует все формы пассивного залога.
Каждая словоформа персидского глагола образуется на базе одной из двух основ: основы настоящего времени (презентной основы) и основы прошедшего времени (претериальной основы). Основа прошедшего времени автоматически получается из инфинитива. Трудность представляет получение основы настоящего времени. Карин Мегердумиэн отмечает, что данные основы невыводимы одна из другой2, однако, Джон Эндрю Бойл предложил 10 групп глаголов, имеющих похожие соответствия между основой настоящего и основой прошедшего времён3. Взяв за основу эти 10 групп, нами было создано 10 правил вывода основы настоящего времени из основы прошедшего времени. Данные правила позволяют получить корректные основы настоящего времени для многих составных глаголов и глаголов, образованных с помощью префиксального словообразования, т.к. для выбора правила используется псевдо-окончание глагола. Исключения из правил записаны в лексиконе исключений. Составные глаголы, имеющие в составе глаголы- корректно, однако, т.к. в системе PVC нет особого правила для получения леммы глагола-исключения из глагола, образованного из него с помощью префиксального словообразования, то каждый глагол-исключение должен быть записан в лексиконе вместе со всеми его производными.
Кроме того, мы используем 2 правила для инфинитивов, оканчивающихся на -estan (например, bayestan) и -stan (например, jastan), в то время как Бойл поместил такие глаголы в одну группу. Для получения основ настоящего време- ни этих глаголов первое правило удаляет псевдоокончание -estan, а второе правило удаляет псевдо-окончание -stan и добавляет -h, таким образом, мы получаем правильные основы ‘bay’ и ‘jah’.
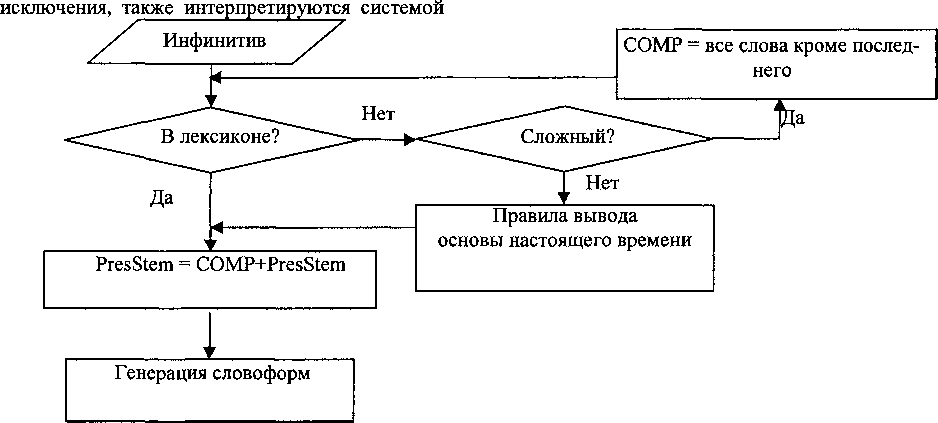
Рис. 1. Алгоритм системы PVC
Выбор правила зависит от 4-й буквы с конца. Правило состоит в том, чтобы удалить определённое количество букв с конца и добавить опреде- лённые буквы в конец полученной комбинации букв. Для выбора некоторых правил необходимо взглянуть на 5-ю букву с конца инфинитива.
Пиотровский Р.Г., Луканин А.В.
Автоматическое определение основ персидских глаголов: Формальные vs. нейросетевые правила
В связи с тем, что в персидском письме огласовки (краткие гласные) обычно не пишутся, правила для определения основы настоящего времени должны быть более сложными. Но так как во внимание принимается 4-я буква с конца, только одна краткая гласная может стоять в этой позиции в транслитерации - буква ‘а’ (например, глагол ‘zadan’). Таким образом, для глаголов, записанных на персидском алфавите, мы используем те же 10 правил, но правило для глаголов с псевдо-окончанием ‘-adan’ выполняется последним. В данном случае сравнивается не 4-я, а 3-я буква с конца, т.к. вторая буква с конца транслитерированного глагола, краткая гласная ‘а’, не пишется в персидском письме.
Трудности всё же существуют при выборе между правилами ‘-stan’ и ‘-estan’, т.к. краткая гласная ‘е’ не пишется. Т.к. Бойл приводит только 4 примера для глаголов, оканчивающихся на *-stan’, мы сделали правило на основе структуры этих глаголов: 2 из них состоят из 4-х букв, т.е. перед псевдо-аффиксом -stan стоит только 1 буква (например, ёя^), а 4-я с конца буква двух других глаголов - алеф (например, ёя^'^). Таким образом, если инфинитив не удовлетворяет этим условиям, то к нему применяется правило ‘-estan’.
В современном персидском языке широко используются так называемые сложные (составные) глаголы, которые образуются сочетанием имени с глаголом4 (около 90% всех персидских глаголов - составные). Наиболее частотные глаголы, используемые в глагольном словообразовании: kardan (ёРА), shodan (6-^), dadan (ёЯ^), zadan (O^J), budan (ё>^), dashtan (ёя^)> salditan (ёя^Ц), и т.д. Так как презентные основы большинства из них невыводимы с помощью наших правил (кроме глаголов dashtan и sakhtan), они записаны в лексиконе исключений. Генерация всех глагольных парадигм составных глаголов возможна, если корректно генерируются словоформы глаголов, входящих в их состав либо используя основу настоящего времени из лексикона исключений, либо получая её при помощи основообразующих правил (см. рис. 1). К примеру, если глагол 'kardan' находится в лексиконе исключений, мы получим корректную основу настоящего времени для глагола 'tabdil kardan' (й^ J^) - tabdil kon (6s Jj^). Основа же настоящего времени глагола 'baz dashtan' (ёя^^ Л); к примеру, будет корректно выведена (baz dar, Jb jb), используя правило "-shtan" (удалить -shtan и добавить -г) без обращения к лексикону исключений.
В настоящее время лексикон исключений насчитывает 95 глаголов. Так как большинство из них используется для образования составных глаголов, считается, что система PVC способна сгенерировать правильные парадигмы около 90 -
95% всех персидских глаголов (включая возможные неологизмы).
В системе PVC используется подход, при котором буква в определённой позиции глагола влияет на выбор правила вывода презентной основы из претериальной. Как известно, ребёнок в первые годы своей жизни выявляет знания о языке самостоятельно без помощи каких-то определённых формальных грамматик подобных тем правилам, которым впоследствии его учат в школе. Аналогично этому взрослые люди не могут объяснить, почему одно сочетание букв/слов верно, а другое нет. Это интуитивное знание фактически является автоматически формируемой грамматикой мозга человека: чем больше человек приобретает однотипных знаний, тем грамматичней они становятся. Лингвистические грамматики, описанные лингвистами в учебниках, являются осмыслением, формализацией этого опыта, преобразованием его в словесные правила.
Моделирование процесса автоматического приобретения знаний является на сегодняшний момент попыткой преодолеть те трудности, которые возникли при решении лингвистических задач, таких как машинный перевод, попыткой решать эти задачи более интеллектуально. Наиболее адекватной, хотя и очень грубой с биологической точки зрения моделью мозга человека является искусственная нейронная сеть (ИНС). Это своего рода промежуточный уровень между лингвистическим формализмом, к примеру, лингвистическими сетями, и нервной системой, биологическими нейронами мозга человека.
Дэвид Румельхарт и Джеймс МакКлелланд успешно обучили однослойную нейросетевую модель для генерации форм прошедшего времени английских глаголов, используя алгоритм обучения персептрона5, причем их исследование согласуется с исследованиями, проводимыми психолингвистами: сеть проходит те же этапы обучения, какие проходят дети при овладении английскими глаголами. Их ассоциативная нейронная сеть сопоставляет форму настоящего времени глагола с формой прошедшего времени. Такой подход критиковался Стивеном Пинкером6 за невозможность повторения эксперимента с другими глаголами, в том числе придуманными. Мы придерживаемся мнения, что мозг человека как-то формализует знания и для облегчения обучения искусственной нейронной сети необходимо предъявлять частично формализованные знания.
Нами была предпринята попытка смоделировать процесс вывода презентной основы персидского глагола, записанной в персидском алфавите, из претериальной с помощью многослойного персептрона. Задача состояла в том, чтобы научить ИНС определять зависимость между буквенным составом претериальной основы и правилами модификации её для получения пре-зентной основы (назовём их аддитивными правилами).
На вход ИНС подавался вектор из 198 бинарных чисел, соответствующих 6 буквам прете-риальной основы, выровненных по окончанию. Каждая буква представляет собой подвектор, состоящий из 33 бинарных чисел, соответствующие 32 буквам персидского алфавита и пробелу
(обозначаемому «_»), где все числа равны 0 кроме кодируемого символа, который равен 1. Для обучения двум аддитивным правилам («•^1-<3^1» и «^jjil-jjjil») на выходе использовался вектор из 4 бинарных чисел, соответствующих 4м элементарным операциям: удалению 1, 2, 3 букв с конца и добавления буквы ‘J’ в конец. На внутреннем слое персептрона использовалось 3 нейрона (рис. 2).
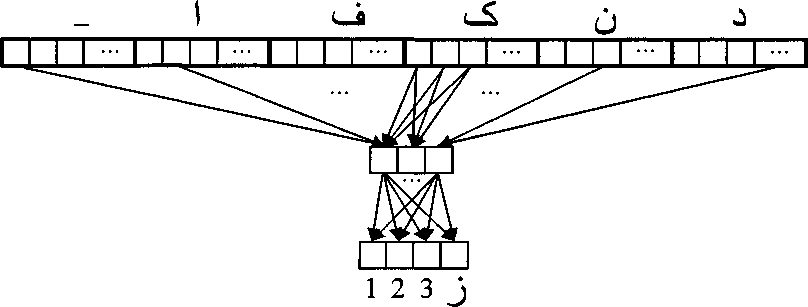
Рис. 2. Модель искусственной нейронной сети для генерации основы настоящего времени персидских глаголов. ИНС является полносвязной, для удобства изображены не все связи и не все ячейки входного вектора
Для выведения 1-го «интуитивного» правила, фактически являющимся совокупностью весовых коэффициентов ИНС, оказалось достаточным обучить ИНС на одном глаголе, т.к. сравнивать претери-альную основу было не с чем. Для автоматического отнесения 36 глаголов к 2 аддитивным правилам потребовалось обучить ИНС на 3-х случайно выбранных глаголах каждого аддитивного правила. Следует отметить, что здесь используется отличный от PVC метод генерации основы настоящего времени. При описании формальных правил PVC мы сравнивали 3ю букву с конца инфинитива, и в зависимости от неё определяли действия (удаление и добавление букв). В данном случае ИНС предъявляются только аддитивные правила, а основания для применения этих правил выявляет сама ИНС. Так, к ряду глаголов-исключений применяются те же ад дитивные правила, определённые в PVC, но для ИНС они не являются исключениями. Следовательно, ИНС выявила скрытые закономерности отнесения глаголов к аддитивным правилам, которые трудно формализовать, используя обычные лингвистические сети.
Как мы видим, автоматический вывод основы настоящего времени из основы прошедшего времени персидских глаголов возможен как при использовании формальных правил, так и при использовании искусственной нейронной сети, но в последнем случае не требуется лексикон исключений. Т.е. ИНС выявляет те закономерности, которые лежат в основе зависимости двух, казалось бы, ничем не связанных основах персидских глаголов.
-
2 Karine Megerdomian. Finite-state morphological analysis of Persian. In Proceedings of the Workshop on Computational Approaches to Arabic Script-based Languages. Coling 2004, University of Geneva. August 28, 2004.
-
3 Boyle, John Andrew. Grammar of modern Persian. Wiesbaden, Harrassowitz, 1966.
-
4 Мошкало B.B. Персидский язык. Языки мира РАН. Ин-т языкознания; Редкол.: В.Н. Ярцева (пред.) и др. М.: Индрик, 1997. Иранские языки. Ч. 1: Юго-западные иранские языки / Редкол.: В.С. Расторгуева (отв. ред.) и др. С. 71-102.
-
5 Rumelhart, D. Е. and McClelland, J. L. (1986) On Learning the Past Tenses of English Verbs. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, vol. 2, pp. 216-271. Cambridge, MA: MIT Press.
-
6 Пинкер, С. Язык как инстинкт: Пер. с англ. / Стивен Пинкер. М.: Едиториал УРСС, 2004. С. 456.
Список литературы Автоматическое определение основ персидских глаголов: формальные vs. нейросетевые правила
- Navid Fazel. 2006. Academic Grammar of New Persian. http://www.fazel.de/dastxir/EN/mdex.htrnl
- Karine Megerdomian. Finite-state morphological analysis of Persian. In Proceedings of the Workshop on Computational Approaches to Arabic Script-based Languages. Coling 2004, University of Geneva. August 28, 2004.
- Boyle, John Andrew. Grammar of modern Persian. Wiesbaden, Harrassowitz, 1966.
- Мошкало В.В. Персидский язык. Языки мира РАН. Ин-т языкознания; Редкол.: В.Н. Ярцева (пред.) и др. М.: Индрик, 1997. Иранские языки. Ч. 1: Юго-западные иранские языки/Редкол.: B.C. Расторгуева (отв. ред.) и др. С. 71-102.
- Rumelhart, D. E. and McClelland, J. L. (1986) On Learning the Past Tenses of English Verbs. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, vol. 2, pp. 216-271. Cambridge, MA: MIT Press.
- Линкер, С. Язык как инстинкт: Пер. с англ./Стивен Линкер. М.: Едиториал УРСС, 2004. С. 456.
