Автоматическое распознавание автомобильных номерных знаков

Автор: Полтавский А. В., Юрушкина Т. Г., Юрушкин М. В.
Журнал: Advanced Engineering Research (Rostov-on-Don) @vestnik-donstu
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 1 т.20, 2020 года.
Бесплатный доступ
Введение. Статья посвящена задаче автоматического обнаружения и распознавания автомобильных номеров, решение которой имеет множество потенциальных применений, начиная от обеспечения безопасности и заканчивая управлением трафиком на дорогах. Целью данной работы являлась разработка интеллектуальной системы нахождения и распознавания автомобильных номеров, основанной на применении алгоритмов глубокого обучения и сверточных нейронных сетей, учитывающей различные региональные стандарты автомобильных номеров, и устойчивой к различным расположениям камеры, качеству видео, освещению, погодным условиям и деформациям номерных знаков.Материалы и методы. Предложен комплексный подход к решению задачи, основанный на применении сверточных нейронных сетей. Проведен экспериментальный анализ нейросетевых моделей, обученных под требования задачи универсального распознавания номерного знака. На его основании были выбраны модели, показывающие лучшее соотношение качества и быстродействия. Качество системы обеспечивается оптимизацией различных моделей с различными модификациями...
Обнаружение и распознавание объектов, сверточные нейронные сети, генерация и аугментация данных, распознавание номерных знаков
Короткий адрес: https://sciup.org/142223726
IDR: 142223726 | УДК: 621.893 | DOI: 10.23947/1992-5980-2020-20-1-93-99
Automatic license-plate recognition
Introduction. The problem of automatic license plate recognition is considered. Its solution has many potential applications from safety to traffic control. The work objective was to develop an intelligent recognition system based on the application of deep learning algorithms, such as convolution neural networks that consider automotive standards for license plates in various countries and continents, and are tolerant to camera locations and quality of input images, as well as to changing lighting, weather conditions, and license plate deformations.Materials and Methods. An integrated approach for the problem solution based on the application of convolution neural network composition is proposed. An experimental analysis of neural network models trained to meet the requirements of the universal license plate recognition task was conducted. Based on it, models that showed the best ratio of quality and speed were selected. Quality of the system is provided through the optimization of various models with different modifications...
Текст научной статьи Автоматическое распознавание автомобильных номерных знаков
УДК 621.893
Введение. Системы автоматического распознавания номеров (ALPR) используются для автоматического контроля скорости движения, идентификации угнанных транспортных средств, контроля доступа транспортных средств в частных помещениях и взимания платы за проезд1 [1, 2, 3]. Однако большинство существующих алгоритмов2, 3 работают только для конкретного шаблона номерного знака или со сложными системами захвата изображений, требовательны к условиям освещения и типам транспортных средств [4, 5, 6].
Благодаря быстрому развитию глубинного обучения и его приложений в области компьютерного зрения [7] стало возможным создание системы ALPR, способной распознавать многочисленные шаблоны номерных знаков в произвольной среде 4,5,6 [8]. Основными трудностями при распознавании номерных знаков являются особенности условий съемки — наличие дождя, снега или плохое освещение. Задача распознавания становится более сложной, если номерной знак имеет нетривиальные площадь и соотношение сторон, цвет фона, форму, количество линий, размер шрифта, расстояние между символами и т. д.
Целью данной работы являлась разработка системы распознавания автомобильных номеров, поддерживающей различные региональные стандарты номерных знаков, и не зависящей от условий видеосъемки автомобилей, таких как грязь на номерах, погодные условия и т.д.
Материалы и методы. Автоматическая система детекции и распознавания автомобильных номеров. В рамках данного раздела дается описание программной реализации системы обнаружения транспортного средства на фотографии, нахождения в нем номерного знака и его распознавания.
Предлагаемая система состоит из композиции нескольких нейросетевых моделей. Идея композиции заключается в том, что на вход следующей модели подается результат выполнения предыдущей, а весь процесс анализа разбивается на этапы. Схематически принцип работы системы представлен на рис. 1:
Обнаружение транспортного Средства / Vehicle detection

Обнаружение номерного знака / Распознавание символов номерного
Licensee plane detection знака / License plate recognition

Рис. 1. Трехэтапный подход в задаче обнаружения и распознавания номерных знаков
Первый этап работы алгоритма заключается в обнаружении транспортного средства. Для решения этой задачи использовалась модель SSD Resnet 1 , обученная на наборе данных COCO (Common Objects in Context) 2 . Результатом работы данной модели являются фрагменты входного изображения, которые включают в себя транспортные средства. На втором этапе полученные фрагменты подаются на вход разработанной модели детекции автомобильных номеров, которая возвращает фрагменты изображения, включающие только автомобильные номера. На заключительном этапе производится распознавание символов, образующих автомобильный номер, и их склейка. Подробное описание разработанных моделей, используемых во втором и третьем этапе работы алгоритма, приведено в соответствующих разделах статьи.
Выбранный подход обладает следующими преимуществами:
Отсекаются объекты, которые могут восприниматься как номерной знак: вывески на витринах магазинов, окнах или ограждениях;
Становится возможным установить взаимосвязь между номером и соответствующим транспортным средством, предусматривая расширение системы в сторону распознавания других характеристик, таких как вид, марка и модель транспортного средства, цвет и направление движения, отслеживание в видеопотоке;
Сохраняется модульность системы, состоящей из независимых моделей, специализирующихся в решении конкретной задачи на высоком уровне.
Модель детекции номеров. Начальный набор данных для тренировки модели представлял из себя 1700 изображений индийских автомобилей, снятых под определенным углом. Обученная на данном наборе модель не являлась вариативной к разным условиям, поэтому был применен метод псевдолейблинга 3 для неразмеченных наборов данных (изображений с транспортными средствами). Таким образом, изначальный набор данных для тренировки был увеличен до 400 тысяч изображений. Размер набора данных для валидации равен 5% от набора для тренировки. Изображения выбирались случайно и проверялись на правильность разметки координат номерного знака.
Для оценки качества модели использовались метрики IoU (Intersection over Untion), mAP (mean Average Precision) и AR (Average Recall)4:
'DetectionBoxes_Precision/mAP': точность классов, усредненная по пороговым значениям IоU в диапазоне от 0,5 до 0,95 с шагом 0,05;
Информатика, вычислительная техника и управление
'DetectionBoxes_Precision/mAP@.50IOU': средняя точность классов по значению IоU равному 0,5;
'DetectionBoxes_Precision/mAP (small)': средняя точность классов для маленьких объектов (площадь < 32^2 пикселя);
'DetectionBoxes_Precision/mAP (medium)': средняя точность классов для объектов (32^2 пикселя < площадь < 96^2 пикселя);
'DetectionBoxes_Precision/mAP (large)': средняя точность классов для больших объектов (96^2 пикселя < площадь < 10000^2 пикселя).
Таблица 1
Результат mAP на валидационных данных
|
Задача / task |
Модель / model |
mAP |
mAP@.50IOU |
mAP@.75IOU |
mAP (small) |
mAP (medium) |
mAP (large) |
|
Обнаружение номерных знаков / License plate detection |
SSD MobileNet v1 FPN |
0,8292 |
0,9843 |
0,9739 |
0,7199 |
0,8197 |
0,8544 |
Полученная модель устойчива к размеру входного изображения (таблица 1), обнаруживает номерные знаки под наклоном, а также с нетривиальным соотношением сторон.
Модель распознавания номеров. Задача распознавания номерного знака сводится к задаче детекции объектов 36 классов: 26 букв латинского алфавита верхнего регистра и 10 цифр.
Начальный набор данных для обучения модели представлял из себя 1700 изображений индийских автомобилей. Валидация происходила на 10% от начального набора, состоящих преимущественно из трудночитаемых изображений, размеченных вручную.
За отсутствием в достаточном количестве размеченных наборов данных, удовлетворяющим требованиям обучения модели распознавания номеров, было принято решение сгенерировать синтетический набор данных. В качестве аугментаций использовались такие преобразования как поворот, размытие и затемнение, а также различные размеры и цветовые раскраски номерного знака, начертания шрифтов, расстояния между символами (рис. 2).

Рис. 2. Примеры генерируемых изображений
Модель обучалась на синтетическом наборе данных, включающем 300 тысяч изображений. Для повышения точности и количества реальных данных для обучения модели была применена техника псевдолейблинга, увеличившая набор реальных данных до 250 тысяч. Точность распознавания на валидационном наборе данных выросла на 15%, достигнув отметки в 63% (рис. 4). Этот рост обусловлен присутствием в реальных изображениях артефактов, недоступных при генерации.
Таблица 2
|
Задача / task |
Модель / model |
mAP |
mAP@,50IOU |
mAP@,75IOU |
mAP (small) |
mAP (medium) |
mAP (large) |
|
Распознавание номерных знаков / License plate recognition |
Faster R-CNN Resnet-101 |
0,4783 |
0,9372 |
0,3578 |
0,4689 |
0,5251 |
0,5543 |
|
0,6332 |
0,9503 |
0,7228 |
0,6009 |
0,6397 |
0,7051 |
||
|
Faster R-CNN Inception v2 |
0,5567 |
0,9534 |
0,6113 |
0,5569 |
0,6094 |
0,6493 |
|
|
0,5784 |
0,9652 |
0,6184 |
0,5583 |
0,6157 |
0,6676 |
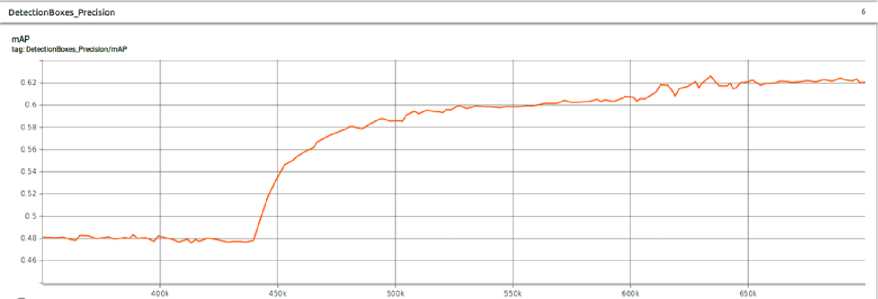
Рис. 3. Результаты mAP модели до и после добавления реальных наборов данных
Сравнение mAP моделей на валидационных данных
Результаты исследования. В полученной комбинации нейросетевых моделей каждый из классификаторов независимо обучался с использованием изображений из нескольких наборов данных, включающих в себя номерные знаки стран всех континентов и методов увеличения этих наборов для достижения устойчивости в различных условиях 1, 2 .
Для оценки результатов обнаружения номерных знаков использовалась метрика IoU. Для задачи распознавания символов номерного знака правильно размеченным считалось то изображением, в котором все символы в номерном знаке были распознаны корректно. Лишний, отсутствующий или некорректно распознанный символ считались ошибкой на всем номере.
Сравнение результатов проводилось с последней облачной версией коммерческого пакета OpenALPR 3 и с упомянутым выше исследованием 2016 года 4 . Тестирование проводилось на наборе данных 2017-IWT4S-HDR_LP-dataset (таблица 3), предоставленном в исследовании 5 и Application-Oriented License Plate (AOLP) (таблица 4), предоставленном в исследовании 6 , включающим в себя 2049 изображений с тайваньскими номерными знаками. Они подразделялись на три подмножества с различным уровнем сложности и условиями фотографирования: Access Control (AC), Law Enforcement (LE) и Road Patrol (RP).
-
1 Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning.
-
2 Nowruzi FE, et al. How much real data do we actually need: Analyzing object detection performance using synthetic and real data. 2019. arXiv preprint arXiv:1907.07061.
-
3 OpenALPR Cloud API. Available at: https://api.openalpr.com/v2/ (accessed: 02.11.2019).
-
4 Li H., Shen C. Op. cit.
-
5 Hsu G., Chen J., Chung Y. Op. cit.
-
6 Li H., Shen C. Op. cit.
Информатика, вычислительная техника и управление
Таблица 3
|
Метрики / metrics |
ours |
OpenALPR |
|
Количество корректно распознанных номерных знаков / Number of correct license plate recognitions |
619 / 653 |
377 / 653 |
|
Процент корректно распознанных номерных знаков / Percent of correct license plate recognitions |
94,79 |
57,73 |
Таблица 4
|
Метрики / metrics |
Применяемые решения / Applied solutions |
Подмножество AC / Subset AC (%) |
Подмножество LE / Subset LE (%) |
Подмножество RP / Subset RP (%) |
|
IoU обнаружения номерного знака / plate detection |
ours |
95,58 |
93,97 |
94,29 |
|
OpenALPR |
91,80 |
86,89 |
90,84 |
|
|
[12] 1st approach(with CNN I) |
93,53 |
89,83 |
86,58 |
|
|
[12] 1st approach(with CNN II) |
93,25 |
90,62 |
86,74 |
|
|
[12] 1st approach(with CNN I & II) |
93,97 |
92,87 |
87,73 |
|
|
[12] 2st approach(with global features only) |
90,50 |
91,15 |
83,98 |
|
|
[12] 2st approach(with both local and global features) |
94,85 |
94,19 |
88,38 |
|
|
Количество корректно распознанных номерных знаков / number of correct letter recognitions: |
ours |
88,75 |
83,94 |
85,40 |
|
OpenALPR |
86,04 |
77,98 |
85,71 |
Численный эксперимент на публичном наборе данных 2017-IWT4S-HDR_LP-dataset
Численный эксперимент на публичном наборе данных
Обсуждение и заключения. Были построены модели для обнаружения и распознавания номерных знаков транспортных средств. Согласно численным экспериментам, модель для обнаружения номеров оказалась точнее решений, полученных в 2016 и 2019 годах 1,2 на наборе данных, опубликованных в 2013 году 3 . Модель распознавания автомобильных номеров оказалась точнее решения 2019 года 4 на наборе данных, полученных в 2017 году [8]. Для увеличения точности моделей были использованы методы генерации синтетических данных и
-
1 Li H., Shen C. Op. cit.
-
2 OpenALPR Cloud API.
-
3 Hsu G., Chen J., Chung Y. Op. cit.
-
4 OpenALPR Cloud API.
псевдолейблинга. Полученная система оказалась устойчивой к размеру входного изображения и особенностям среды.
Список литературы Автоматическое распознавание автомобильных номерных знаков
- Bernstein, D. Automatic vehicle identification: technologies and functionalities / D. Bernstein, A. Y. Kanaan // Journal of Intelligent Transportation System. - 1993. - 1 (2). - P. 191-204.
- Development of vehicle-license number recognition system using real-time image processing and its application to travel-time measurement / K. Kanayama// IEEE Vehicular Technology Conference. - May, 1991. - P. 798-804.
- Kessentini, Y. A two-stage deep neural network for multi-norm license plate detection and recognition / Y. Kessentini, M.D. Besbes, S. Ammar, A. Chabbouh // ExpertSystems with Applications. - 2019. - Vol. 136. - P. 159- 170.
- Tian, J. A two-stage character segmentation method for Chinese license plate / J. Tian, R. Wang, G. Wang, J. Liu, Y. Xia // Computers & Electrical Engineering. - 2015. - Vol.46. - P. 539-553.
- A CNN-based approach for automatic license plate recognition in the wild / M. Dong// British Machine Vision Conference (BMVC). - 2017. - P. 1-12.
- LeCun, Y. Deep learning / Y. LeCun, Y. Bengio, G. Hinton // Nature. - 2015. - Vol. 521, no. 7553. - P. 436-444.
- Holistic recognition of low quality license plates by CNN using track annotated data / J. Španhel// 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). - 2017. - P. 1-6.
