Автоматизация формирования информационной базы мультилингвистической адаптивно-обучающей технологии

Автор: Карасева Маргарита Владимировна, Лесков Виталий Олегович
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 4 (17), 2007 года.
Бесплатный доступ
Рассмотрены системные аспекты формирования информационной базы мультилингвистической адаптивно-обучающей технологии, такие как сбор информации о скрытых лексических связях, и применение ее в формировании информационно-терминологического базиса. Предложена система первичной обработки текстов, приведен алгоритм ее работы, а также структура выходных данных.
Короткий адрес: https://sciup.org/148175600
IDR: 148175600 | УДК: 62-506.1
Automation of the informational basis formation of the multilingual adaptive technology
The system aspects of information basis generating multilingual adaptive-training technology are exact the information gathering about hidden lexical relations and use of this information in forming of information-technology basis are considered. The texts system preprocessing is connected with its algorithm of work and output data structure.
Текст научной статьи Автоматизация формирования информационной базы мультилингвистической адаптивно-обучающей технологии
Проблема эффективного обучения иностранным языкам всегда была актуальна для человечества. Создаются различные методики обучения, а вместе с ними множество учебников, словарей (в том числе электронных), предпринимались попытки создания унифицированных языков достаточно простой и логичной структуры. Результаты этих попыток весьма спорны, но одно можно сказать наверняка: все это было вызвано необходимостью понимания иностранной речи, умения высказаться в рамках специальной области. Кроме того возникла острая необходимость в квалифицированных переводчиках. Но какой бы квалификацией не обладал переводчик, он не в силах постичь все многообразие сфер человеческой деятельности, изобилующее своими специальными терминами, не говоря уже о том, что значения одних и тех же, казалось бы, терминов в разных сферах бывают очень различны. Как показывает практика, контактировать с представителями других языковых групп приходится если не во всех сферах человеческой деятельности, то в большинстве из них, и часто не прибегая к услугам переводчика.
Резюмируя все вышесказанное, можно утверждать, что на сегодняшний день предпочтительно, чтобы специалист самолично мог общаться на иностранных языках с зарубежными коллегами или партнерами, хотя бы в рамках своей рабочей области. В российской практике, к сожалению, данная тенденция развивается медленно. А значит, ярко выражена необходимость в создании эффективных методов обучения специальной лексике.
На сегодняшний день все более часто используют специальные компьютерные программы, обучающие иностранной лексике. Они относительно дешевы и просты при создании по сравнению с бумажными аналогами и не менее эффективны. Такие программы обычно обладают достаточно гибкой структурой, позволяющей обновлять (актуализировать) свои БД, а также заменять их для обучения лексике иных специальных областей.
Примечательно, что процесс обучения с помощью таких программ становиться индивидуальным, и обучаемый способен прервать или возобновить процесс обучения в любое удобное для него время. Не маловажно, что подобные обучающие программы, как правило, имеют ряд дополнительных функций при обучении, в том числе средства мультимедиа. Это также заметно повышает эффективность таких программ.
Единственный минус подобных средств обучения по сравнению с бумажными аналогами состоит в том, что некоторые люди принципиально не приемлют компьютерное обучение как таковое. Причины этого тривиальны: дело в том, что обучение посредством компьютера требует определенной усидчивости и терпения от обучаемого, что не каждый может себе позволить. Естественно, что помимо этого от пользователя требуется умение пользоваться компьютером хотя бы на начальном уровне.
Но, тем не менее, основная часть специалистов, на которых нацелены подобные обучающие программы, не должна испытать никаких затруднений в их освоении, поскольку к современным специалистам предъявляется более высокий уровень требований . А это означает, что подобные обучающие программы еще долго будут востребованы на рынке средств обучения иностранным языкам.
Последнее время очень часто перед современным специалистом ставится требование знать лексику нескольких иностранных языков.
Решение этой задачи посредством описанных выше программных продуктов имеет побочные эффекты. Нередко возникает несоответствие языковых аналогов. Одни аналоги забываются быстрее - другие нет. И это усугубляет процесс обучения.
Конечно, это происходит в первую очередь из-за того, что сам процесс обучения происходит поэтапно. Муль-тилингвистическая адаптивно-обучающая технология (МЛ-технология) [1] предлагает иной подход к изучению нескольких иностранных языков последовательно, а именно изучение иностранного языка с учетом и при помощи знания другого ранее изученного иностранного языка. МЛ-технология основана на механизмах восприятия и памяти человека и предусматривает адаптацию системы к конкретному пользователю.
В настоящее время в рамках МЛ-технологии проводится ряд исследований, и она как ядро обучающей системы обрастает новыми методами и системами их реализующими.
Построение компьютерной системы, обучающей иностранной лексике (в частности, на основе МЛ-технологии), можно представить в виде ряда последовательных этапов.
Формирование программной оболочки и механизма, обеспечивающего прохождение системы, включает различные механизмы адаптации и дополнительные функции.
Формирование терминологического базиса происходит в несколько этапов:
-
1) построение лексической базы, адекватно и достаточно полно отражающей специфику некоторой области какого-либо иностранного языка (нескольких иностранных языков, в контексте МЛ-технологии):
-
- поиск текстов, принадлежащих данной специальной области,
-
- обработка текстов и сбор мусора,
-
- построение лексической базы в виде частотного словаря;
-
2) формирование мультилингвистического информационного терминологического базиса посредством ряда методов, в том числе методов оптимизации структуры базиса.
Достаточно часто для описания технологических процессов и управления ими используется теория Марковских процессов.
Марковский процесс - это процесс, когда для каждого момента времени вероятность любого состояния объекта в будущем обусловлено только состоянием объекта в данный момент и не зависит от того, каким образом объект пришел в это состояние. Говорят еще, что такой процесс обладает Марковским свойством.
Цепочкой Маркова называется Марковский процесс с дискретным временем, заданный в измеримом пространстве.
Для описания Марковских процессов используются модели Маркова, которые включают в себя множество состояний, множество переходов между этими состояниями и вероятностные характеристики этих переходов (переходная вероятность или вероятность перехода). Для удобного использования переходных вероятностей, они часто записываются в матрицу (матрицу переходных вероятностей).
Пример Марковской цепочки - произношение слова «корова» в двух различных вариантах (рис. 1). Согласно этому рисунку слово «корова» с вероятностью 0,7 будет произнесено как [карова], с вероятностью 0,3 как [корова].
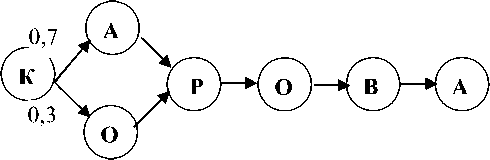
Рис. 1. Пример цепочки Маркова
Все приведенные состояния, кроме начального, являются функциями предыдущего состояния. Совокупность состояний, приведенную в данном примере, логично рассматривать как совокупность биграммам (последовательностей из двух слов), так как каждое состояние (кроме начального) является функцией только от одного предыдущего состояния.
Когда некоторое состояние зависит сразу от нескольких предыдущих, тогда совокупность этих состояний логично рассматривать как совокупность триграмм, тетраграмм и т. д. (последние не часто используются в решении технологических задач, так как построение системы, основанной на них, достаточно ресурсоемко). Здесь уместно говорить о расширении понятия Марковского процесса.
Если цепочка Маркова включает в себя хотя бы одно состояние, которое может быть достигнуто одиночными переходами из нескольких предыдущих (состояние 3, рис. 1), то такая цепочка называется скрытой Марковской цепочкой (обладает скрытым Марковским свойством).
Условимся называть связи (отражающие возможность перехода в скрытой Марковской цепи) скрытыми Марковскими зависимостями (связями), а в контексте данной статьи, с учетом ее тематики - скрытыми лексическими связями.
Теперь следует заметить, что представленная структура построения компьютерной системы обучения иностранной лексике не учитывает скрытые Марковские зависимости между лексемами (далее - скрытые лексические связи).
Однако очевидно, что такие зависимости (в первую очередь связи между понятиями, а не лексемами) могут служить достаточно сильным ассоциативным механизмом при запоминании некоторого набора лексем языка (языков). А значит, изучение этого механизма и возможностей манипулировать им полностью соответствует целям обучающей системы.
Предположим что, существует механизм использования данных о скрытых лексических связях в построении информационного терминологического базиса.
Тогда необходимо построить систему, которая бы позволяла находить и представлять данные о скрытых лексических связях таким образом, чтобы они могли быть использованы упомянутым ранее механизмом. К такой системе предъявляется два основных требования:
-
- органично вписываться в общую структуру компьютерной системы обучения (наименьшая ресурсоем-кость, синхронизация с отдельными подсистемами);
-
- универсальность и простота представления данных (механизмы использования могут быть различны, как и требования к представлению их входных данных).
Естественно было бы отнести интегрируемую систему ко второму этапу в построении системы обучения иностранной лексике (предварительная обработка текстов, построение лексической базы).
Также естественно было бы расположить ее в данной структуре либо до применения подсистемы генерации частотного словаря, либо после.
Но если рассмотреть ближе структуру обоих упомянутых систем, то становится очевидным, что они основаны на одном и том же алгоритме обработки текстов - алгоритме «Поиска образа в строке». И поскольку ресурсо-емкость задач с применением такого алгоритма прямо пропорционально зависит от объема обрабатываемого текста, встает вопрос о слиянии этих двух систем.
Удачное решение этого вопроса намного сократит ресурсоемкость этапа формирования лексической базы по сравнению с последовательным применением этих двух систем.
Для того чтобы понять как эффективнее и проще организовать представление выходных данных системы, необходимо знать, что эти данные из себя представляют.
Все скрытые лексические связи в тексте могут быть представлены в виде ориентированного взвешенного графа, вершины которого соответствуют отдельным лексемам, ориентированные дуги - самой скрытой лексической связи, а веса - вероятностям перехода между лексемами (рис. 2).
Трактовать такой граф, применительно к приведенному примеру, следует таким образом (табл. 1):
Вершина 1:
Лексема: Computer.
За лексемой «Computer» следуют лексемы:
-
- «System» с вероятностью 0,7,
-
- «Design» с вероятностью 0,3.
Аналогично относительно вершин 2, 3,4,5.
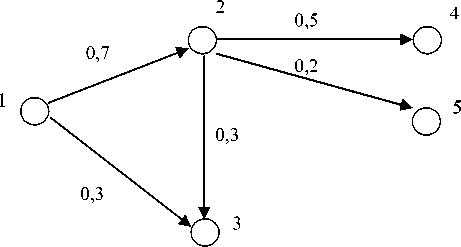
Рис. 2. Пример части орграфа, отражающего скрытые лексические зависимости текста некоторой предметной области
Таблица 1
Частотные характеристики лексем
|
Вершина |
Лексемы |
Данные ЧС |
|
1 |
Computer |
0,007 |
|
2 |
System |
0,002 |
|
3 |
Design |
0,000 6 |
|
4 |
Architecture |
0,000 1 |
|
5 |
Method |
0,003 |
Чаще всего орграфы, да и любые другие графы, имеют машинное представление в виде совокупности матрицы смежности и инцидентности. Такие матрицы для орграфа, приведенного на рис. 1, будут иметь следующий вид (табл. 2 и 3).
Таблица 2
Матрица смежности
|
№ |
1 |
2 |
3 |
4 |
5 |
|
1 |
0 |
1 |
1 |
0 |
0 |
|
2 |
1 |
0 |
1 |
1 |
1 |
|
3 |
1 |
1 |
0 |
0 |
0 |
|
4 |
0 |
1 |
0 |
0 |
0 |
|
5 |
0 |
1 |
0 |
0 |
0 |
Таблица 3
Матрица инцидентности с весами ребер
|
№ |
12 |
13 |
23 |
24 |
25 |
|
1 |
-0,7 |
-0,3 |
0 |
0 |
0 |
|
2 |
0,7 |
0 |
-0,3 |
-0,5 |
-0,2 |
|
3 |
0 |
0,3 |
0,3 |
0 |
0 |
|
4 |
0 |
0 |
0 |
0,5 |
0 |
|
5 |
0 |
0 |
0 |
0 |
0,2 |
Для удобства хранения и наименьшей ресурсоемкос-ти данных о скрытых лексических связях предлагается сле- дующая модификация матриц смежности и инцидентности, которая представляет собой только одну таблицу и эквивалентна матрице переходных вероятностей, обычно используемой в контексте Марковских цепей (табл. 4).
тодов. Автором статьи на основании результатов собственного небольшого исследования области решения подобных задач рекомендуется метод «Быстрого поиска», имеющий минимальную ресурсоемкость.
Таблица 4
Матрица переходных вероятностей
|
№ |
1 |
2 |
3 |
4 |
5 |
|
1 |
0 |
0,7 |
0,3 |
0 |
0 |
|
2 |
0 |
0 |
0,3 |
0,5 |
0,2 |
|
3 |
0 |
0 |
0 |
0 |
0 |
|
4 |
0 |
0 |
0 |
0 |
0 |
|
5 |
0 |
0 |
0 |
0 |
0 |
Таблица 6
Скрытые лексические связи
|
ID |
1 |
2 |
3 |
4 |
5 |
|
1 |
0 |
0,007 |
0,023 |
0 |
0 |
|
2 |
0 |
0 |
0,03 |
0,07 |
0,08 |
|
3 |
0 |
0 |
0 |
0 |
0 |
|
4 |
0 |
0 |
0 |
0 |
0 |
|
5 |
0 |
0 |
0 |
0 |
0 |
Такую матрицу следует читать относительно строк, где, например, запись в ячейке М [1, 2] - «0,7» означает, что связь весом 0,7 входит в точку 2 из точки 1, иными словами «0,7» - значение вероятности перехода от лексемы 1 к лексеме 2.
Возможность объединить матрицу смежности и инцидентности появилась благодаря тому, что две вершины орграфа скрытых лексических связей соединяет одно и только одно ребро, что позволяет не индексировать ребра; а о наличии-отсутствии ребра однозначно говорит ненулевое значение соответствующей ячейки матрицы переходных вероятностей.
Выход системы образования частотного словаря может быть представлен, например, в виде небольшой БД (табл. 5):
Это удобно в первую очередь благодаря гибкости и надежности структуры хранения данных, где гибкость заключается в том, что в зависимости от выбранных методов формирования терминологического базиса и методик обучения, можно модифицировать БД, добавив, например, атрибут «транскрипция для каждого языкового аналога». Надежность же обеспечивается самой структурой БД.
Матрица переходных вероятностей и частотные характеристики лексем должны быть синхронизированы, для этого предлагается представить матрицу переходных вероятностей в виде БД и объединить с БД частотного словаря по ID (уникальный номер) (табл. 6).
Таким образом, представление выходных данных системы поиска скрытых лексических связей в виде матрицы переходных вероятностей будет синхронизировано с выходом частотного словаря и наименее ресурсоемко.
Алгоритм представлен на определенном уровне абстракции, поэтому не включает детального описания некоторых пунктов. Поиск образа в строке здесь может быть произведен любым из существующих специальных ме-
Вход: текст, прошедший предварительную обработку (сбор мусора и т. д.):
-
1. Выделяется лексема, начиная с первой позиции текста. Назовем ее основной, так как она представляет собой состояние процесса в настоящий момент времени и именно по ней ведется учет частоты для ЧС. Лексема записывается в БД: в ЧС и в матрицу переходных вероятностей в качестве элемента и в качестве нового атрибута (если еще не встречалась как атрибут) с названием идентичным собственному ID основной лексемы, значение атрибута временно приравнивается нулю.
-
2. Изменяем текущее значение частоты для основной лексемы. Производится соответствующая запись в БД: ЧС.
-
3. Выделяется лексема, следующая за основной. Назовем ее связанной лексемой. Она являет собой состояние процесса в будущий момент времени и отражает скрытую лексическую связь. Если связанная лексема еще не встречалась в текущей паре, то она записывается в БД: в ЧС как новый элемент со своим ID и матрицу переходных вероятностей как новый атрибут.
-
4. Изменяем значение частоты для текущей пары лексем. Производится соответствующая запись в БД (матрице переходных вероятностей).
-
5. Производится поиск (любым из методов поиска образа в строке) лексемы в тексте, идентичной основной лексеме.
-
6. Если поиск увенчался успехом и искомая лексема найдена, алгоритм переходит в пункт 2 и продолжает работу.
-
7. Если просмотр текста закончен, и искомая лексема не найдена, то алгоритм переходит в пункт 1, присвоив лексеме, следующей за первым вхождением в текст основной лексемы статус основной. Алгоритм начинает работу уже относительно нее. И работает до тех пор, пока весь текст не будет пройден таким образом до конца.
Выход: БД.
Использование подсистемы обработки текстов, полученной в результате объединения подсистемы генерации
Таблица 5
Частотный словарь
|
ID |
Частота |
Английский |
Немецкий |
Русский |
|
1 |
0,007 |
Computer |
Computer |
Компьютер |
|
2 |
0,002 |
System |
System |
Система |
|
3 |
0,000 6 |
Design |
Design |
Дизайн |
|
4 |
0,000 1 |
Architecture |
Architektur |
Архитектура |
|
5 |
0,003 |
Method |
Methode |
Метод |
частотного словаря и подсистемы поиска скрытых лексических связей является очень удачным решением в построении информационно-терминологического базиса. С одной стороны, появляется возможность задействовать у обучаемого сильные, ранее не доступные, ассоциативные механизмы восприятия памяти, а с другой - ре-сурсоемкость построения базиса будет значительно ниже, чем при предварительном использовании двух ранее упомянутых подсистем.
Таким образом, за счет использования скрытых лексических связей повышается эффективность системы обучения иностранной лексике в целом. При этом разработаны такие структура и алгоритм работы подсистемы предварительной обработки текстов, при которых использование данной подсистемы при формировании инфор мационно-терминологического базиса будет наименее ресурсоемко.
Разработанная структура выходных данных подсистемы предварительной обработки текстов обеспечивает гибкость и целостность информации.
А в эффективном использовании данных о скрытых лексических связях непосредственно в процессе обучения отрывает возможность для новых исследований в данной области.
