Безопасные способы обмена информацией в системах радиочастотной идентификации

Автор: Михайлов Дмитрий Михайлович, Холявин Виталий Борисович, Егоров Алексей Дмитриевич, Проничкин Алексей Сергеевич
Журнал: Спецтехника и связь @st-s
Статья в выпуске: 6, 2013 года.
Бесплатный доступ
В данной статье рассматриваются два способа обмена информацией в RFID-системах: метод обмена информацией в RFID-системе, базирующийся на простейшей идентификации, и протокол для RFID-меток со встроенным генератором псевдослучайных чисел.
Rfid-метка, хэш-код, генератор псевдослучайных чисел, идентификация
Короткий адрес: https://sciup.org/14967185
IDR: 14967185
Текст научной статьи Безопасные способы обмена информацией в системах радиочастотной идентификации
Серийный номер – это случайное число, которое назначается системой, как идентификатор метки. Серийный номер каждой метки уникален в системе и используется как открытый ключ. Каждая метка обладает закрытым ключом, связанным с ее открытым ключом. Зашифрованный хэш-код генерируется с использованием закрытого ключа метки и хэш-функции. Так как серийный номер каждой метки отличен от других, то хэш-код каждой метки в системе уникален. Третье поле – информация производителя, которая содержит различные виды данных в зависимости от требований.
Использование идентификатора как открытого ключа называется криптографией, базирующейся на идентификации. Криптографическая схема, базирующаяся на идентификации, была впервые предложена Shamir в 1984 г. [1]. Но только к 2001 г. благодаря Дену Боне (Dan Boneh) и Мэтью Франклину (Matthew Franklin) [2], а также Клиффорду Коксу (Clifford Cocks) [3] была
Таблица 1. Структура данных RFID-метки
|
Серийный номер |
Зашифрованный хэш-код |
Информация производителя |
разработана эффективная схема шифрования, базирующаяся на идентификации.
Криптографическая схема, базирующаяся на идентификации, – это один из методов криптографии, базирующихся на открытом ключе, который может использоваться двумя участниками для обмена сообщениями и эффективной проверки подписей. В отличие от традиционных систем с открытым ключом, которые используют случайную строку как открытый ключ, в криптографии, базирующейся на идентификации, идентификатор пользователя, который однозначно идентифицирует каждого пользователя в системе, используется как открытый ключ для шифрования и проверки подписи.
Генерация PU pkg и PR pkg
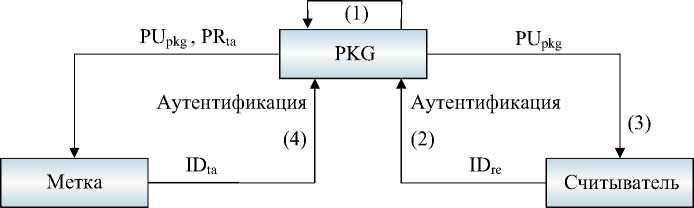
Рис.1. Создание и распределение ключей
При использовании криптографии, базирующейся на идентификации, сложность системы может значительно снизиться, так как двум пользователям не требуется обмениваться своими открытыми и закрытыми ключами и не требуется большой справочник с ключами.
Другим преимуществом шифрования, базирующегося на идентификации, является то, что если все пользователи в системе были изданы с ключами центра генерации доверительных ключей, то центр генерации ключей может быть удален. Для шифрования, базирующегося на идентификации, и схемы подписи вместо генерации пары из открытого и закрытого ключей самим пользователем каждый пользователь будет использовать свой идентификатор как открытый ключ, и только третья сторона, пользующаяся доверием, называемая PKG (генератор открытых ключей), а не пользователь, будет создавать связанный закрытый ключ.
Процесс создания закрытого ключа и распределения ключей показан на рис. 1 .
-
1 PKG создает «основной» открытый ключ PUpkg и связанный «основной» закрытый ключ PRpkg и сохраняет их в своей памяти;
-
2 RFID-считыватель аутентифицирует себя в PKG со своим идентификатором IDre;
-
3 Если считыватель может пройти аутентификацию, PKG отправит ему PUpkg;
-
4 Каждая метка аутентифицирует себя в PKG со своим идентификатором IDta;
-
5 Если метка может пройти аутентификацию, PKG создает уникальный закрытый ключ PRta для метки
и отправляет PRta вместе с PUpkg метке.
После создания и распределения ключей каждая метка в системе будет обладать своим собственным закрытым ключом. Этот закрытый ключ будет использоваться для создания шифрованного хэш-кода метки. Для создания шифрованного хэш-кода система применяет алгоритм SHA-1 (Secure Hash Algorithm 1 – алгоритм криптографического хеширования) [4] к информации производителя метки и создает хэш-код метки. Потом система зашифрует этот хэш-код, используя закрытый ключ метки, и сохранит серийный номер, информацию производителя и зашифрованный хэш-код в памяти метки. RFID-считыватель после сканирования RFID-метки получит всю информацию, хранящуюся в ее памяти.
Чтобы проверить целостность информации производителя, RFID-считыватель считывает серийный номер метки и использует этот серийный номер и PUpkg для создания открытого ключа этой метки, а также использует этот открытый ключ для дешифрования шифрованного хэш-кода. Потом считывателю требуется применить алгоритм SHA-1 к информации производителя метки и создать хэш-код. Сравнивая этот хэш-код с дешифрованным хэш-кодом, RFID-считыватель может проверить целостность информации производителя. Так как шифрованный хэш-код, хранящийся в метке, создается с использованием закрытого ключа метки, этот шифрованный хэш-код может использоваться как цифровая подпись этой метки. RFID-метка может использовать эту цифровую подпись для аутентификации себя в RFID-считывателе. RFID-метки с такой структурой данных могут обеспечить аутентификацию и цифровую подпись для меток.
Одной из проблем RFID-меток, которые используют память с возможностью перезаписи, является то, что злоумышленники могут легко изменить информацию, хранящуюся в метках. В рассматриваемой структуре данных злоумышленники могут изменять информацию RFID-меток. Но, не зная правильного закрытого ключа метки, злоумышленник не может создать правильный шифрованный хэш-код и, следовательно, не может пройти аутентификацию на считывателе.
В данной схеме каждая RFID-метка обладает своим собственным закрытым ключом, и эти ключи отличаются друг от друга. Если закрытый ключ метки будет известен злоумышленнику, это не окажет большого влияния на систему целиком, так как мошенник не сможет узнать закрытые ключи других меток по этому ключу.
В приведенной схеме шифрованный хэш-код может рассматриваться как цифровая подпись метки. Эта цифровая подпись создается с использованием закрытого ключа метки и, следовательно, каждая подпись отличается от других. RFID-считыватель может легко проверить эту цифровую подпись, используя открытый ключ метки. Так как серийный номер RFID-меток может использоваться для создания их открытых ключей в рассматриваемых RFID-системах, PKG не нужно хранить директорию ключей, таким образом можно уменьшить требования к ресурсам системы. Другим преимуществом является то, что считывателю не нужно знать открытые ключи RFID-меток заранее. Если считыватель хочет проверить подлинность цифровой подписи RFID-метки, он может считать серийный номер метки и использовать открытый ключ, созданный из этого серийного номера, для проверки цифровой подписи.
Для решения проблемы аннулирования криптографии, базирующейся на идентификации, в RFID-системе идентификатор метки используется для создания открытого ключа. Если закрытый ключ метки взломан, то система может легко назначить новый идентификатор и создать новый закрытый ключ для метки.
Протокол для RFID-меток со встроенным генератором псевдослучайных чисел
Качественный генератор псевдослучайных чисел (ГПСЧ), ориентированный на использование в задачах защиты информации, должен удовлетворять следующим требованиям:
-
♦ непредсказуемость (по сути, криптографическая стойкость);
-
♦ хорошие статистические свойства (последовательность псевдослучайных чисел по своим статистическим свойствам не должна отличаться от истинно случайной последовательности);
-
♦ большой период формируемой последовательности, учитывая, что при преобразовании больших массивов данных каждому элементу входной последовательности необходимо ставить в соответствие свой элемент псевдослучайной последовательности;
-
♦ эффективная программная и аппаратная реализация.
При использовании непредсказуемого ГПСЧ три следующие задачи вычислительно не разрешимы для злоумышленников, не знающих ключевой информации:
-
♦ определение предыдущего ( i -1)-го элемента γi –1 последовательности на основе известного фрагмента последовательности γi γi +1 γi +2 ... γi+b –1 конечной длины b ( непредсказуемость влев о);
-
♦ определение последующего ( i+b )-го элемента γi+b последовательности на основе известного фрагмента гаммы γi γi +1 γi +2 ... γi + b –1 конечной длины b ( непредсказуемость вправо );
-
♦ определение ключевой информации по известному фрагменту последовательности конечной длины.
Непредсказуемый влево ГПСЧ является криптостойким.
Злоумышленник, знающий принцип работы такого генератора, имеющий возможность анализировать фрагмент выходной последовательности конечной длины, но не знающий используемой ключевой информации, для определения предыдущего выработанного элемента последовательности не может предложить лучшего способа, чем угадывание.
Непредсказуемость ГПСЧ чрезвычай- но сложно оценить количественно. Чаще всего обоснования стойкости нелинейной функции Fk ГПСЧ сводятся к недоказуемым предположениям о том, что у злоумышленника не хватит ресурсов (вычислительных, временных или стоимостных) для того, чтобы при неизвестном k обратить (инвертировать) эту функцию.
В рамках другого подхода к построению качественного ГПСЧ предлагается свести задачу построения криптографически сильного генератора к задаче построения статистически безопасного генератора. Статистически безопасный ГПСЧ должен удовлетворять следующим требованиям:
-
♦ ни один статистический тест не обнаруживает в псевдослучайной последовательности каких-либо закономерностей, иными словами не отличает эту последовательность от истинно случайной;
-
♦ нелинейное преобразование F k , зависящее от секретной информации (ключа k ), используемое для построения генератора, обладает свойством «размножения» искажений – все выходные (преобразованные) вектора e ' возможны и равновероятны, независимо от исходного вектора e ;
-
♦ при инициализации случайными значениями генератор порождает статистически независимые псевдослучайные последовательности.
При описании протокола использованы следующие обозначения:
h(х) – хеш-функция, отображающая последовательность битов длиной l в последовательность битов длиной l ;
S = Eк(m) – код аутентификации сообщения;
Eк – функция вычисления МАС;
N – общее количество меток;
l – длина идентификатора метки;
Ti – метка c номером i (1 < i < N );
Di – информация, записываемая в метке Ti ;
ui – строка из l битов, ассоциированная с меткой;
ti = h(ui) – строка-идентификатор метки Ti ;
r – строка длиной l битов.
Производитель меток должен присвоить каждой метке Ti строку ui длиной l битов, вычислить ti = h(ui) и записать ti в метку, причем длина l должна быть достаточной для того, чтобы злоумыш- ленник не мог подобрать пару значений ti и ui .
Значения ( ui, ti ) new , ( ui , ti ) old , Di хранятся отдельно для каждой метки. Первая пара – это новые значения ui и ti , вторая пара ui и ti – это прежде записанные значения, Di – информация, записываемая в метку (произвольные данные). Если в метке еще никакие данные не записывались, то паре ( ui , ti ) new присваиваются новые сгенерированные значения, а пара ( ui , ti ) old устанавливается в нули.
Далее приводится процесс аутентификации по шагам.
-
1 Считыватель генерирует псевдослучайную строку r1 ∈ R {0, 1} l и отправляет ее метке Ti .
-
2 Метка Ti генерирует случайную строку r2 ∈ R {0, 1} l и вычисляет M 1 = t i XOR r 2 и M 2 = E ti ( r 1 XOR r 2 ). После этого метка Ti отправляет M1 и M2 считывателю.
-
3 Считыватель отправляет M1 , M2 и r1 серверу.
-
4 Сервер получает переданные ему от считывателя данные и выполняет следующую последовательность действий.
-
4.1. Сервер осуществляет поиск в базе данных на основе значений M1 , M2 и r1 :
-
а) сначала сервер выбирает ti из значений ti new или ti old , которые хранятся в базе данных;
-
б) на основании выбранного значения сервер вычисляет M'2 = Eti(r1 XOR r2) , где r2 = M1 XOR ti ;
-
в) если M'2 = M2 , то тег Ti успешно идентифицирован и выполняется шаг (4.3). Если же совпадение не выявлено, то осуществляется переход к шагу (а).
-
4.2. Если совпадений не найдено, то сервер посылает считывателю сообщение о неудачном завершении процесса аутентификации.
-
4.3. Сервер вычисляет M3 = ui XOR r2 и посылает это значение с Di считы-
- вателю.
-
4.4. Сервер обновляет значение ( ui , ti ) old для тега Ti , заменяя их значением ( ui , ti ) new , и устанавливает новые значения ui new = ui XOR ti XOR r1 XOR r2 и t i new = h ( u i new ).
-
5 Считыватель направляет M3 метке T i .
-
6 Метка вычисляет ui = M3 XOR r2 и проверяет, что h ( ui ) = ti . Если про-

Сервер
Считыватель
Тег
^Ui, ^newi t^b ti\dd, Dj
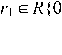
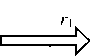
пеЦ», 1}'
Mx = t,XOR r2
M2 = Eti (r, XOR rO
Mi, Mill и

Выбор tj из значений tj new или tj м
M'. = Eti (n NOR r2), где r2 = Mx XOR tf, M3 = и j XOR r.
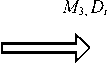
ti old h iii „„,. = Ui XOR tj XOR rA XOR r2 ^i new f^Ui ntir)
Ui - M3XOR r2 h(U;) ?= tj ti = h(u^ XOR tiXOR r, XOR r2.
Рис. 2. Схема протокола для меток со встроенным ГПСЧ верка прошла успешно, это означает, что метка аутентифицировала сервер. После этого метка устанавливает ti = h(ui) XOR ti XOR r1 XOR r2. Если проверка не прошла, то метка не изменяет текущее значение ti.
Схема протокола приведена на рис. 2 .
Данный протокол позволяет решить целый ряд следующих проблем современных RFID-систем.
♦ Информация с метки не может быть похищена, а также не может быть подменена, так как она хранится на сервере, который, согласно допущениям, является безопасным.
♦ Сервер и считыватель обмениваются данными по закрытому каналу. Только сервер, авторизованный на считывание информации, может извлечь идентификатор ti из информации, переданной меткой. Сервер же немедленно предоставит считывателю данные Di в случае успешной идентификации.
♦ С внедрением данного протокола аутентификации становится невозможным несанкционированное отслеживание перемещения тега. Ведь все, что считыватель может получить при запросе к тегу – это псевдослучайные числа. Эти псевдослучайные числа неавторизован- ный считыватель не может ассоциировать ни с одним тегом, так как это всего лишь произвольный и каждый раз отличный от предыдущего набор битов.
♦ Алгоритм является стойким к перехвату и повторной отправке значений M1 , M2 и M3 , так как эти значения каждый раз генерируются псевдослучайным образом.
♦ Еще одна возможная уязвимость RFID-систем, связанная с DоS-ата-кой, решена с помощью хранения на сервере как новых, так и старых значений ui и ti . Таким образом, если злоумышленник захочет помешать с помощью DоS-атаки передаче параметров, вызвав тем самым рассинхронизацию, на сервере все же останется пара старых значений.
Список литературы Безопасные способы обмена информацией в системах радиочастотной идентификации
- Shamir, Identity-based Cryptosystems and Signature Schemes. Advances in Cryptology: Proceeding of CRYPTO 84, LNCS, 1984. -PP. 47 -53.
- D. Boneh, M.Franklin: Identity-based Encryption from the Weil Pairing. In: Kilian, J. (ed.) CRYPTO 2001. LNCS, Springer, Heidelberg, 2001. -V. 2139. -PP. 433 -439.
- Cocks: An Identity-based Encryption Scheme Based on Quadratic Residues. In: Proceeding of 8th IMA International Conference on Cryptography and Coding, 2001.
- Eastlake, P. Jones. US Secure Hash Algorithm 1 (SHA1), 2001. URL: http://tools.ietf.org/html/rfc3174.
