Бипедальная локомоция с эвристическим планированием шагов для поддержания целевой скорости движения: переосмысление роли модельных априорных знаний

Автор: Сулиман В., Чайковская Е.М., Давыденко Е.В., Горбачев Р.А.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 4 (68) т.17, 2025 года.
Бесплатный доступ
В работе представлена расширенная схема обучения контроллера ходьбы антропоморфного робота, основанная на эвристическом подходе к планированию шагов, использующая отслеживание желаемой скорости движения торса робота. Такая схема позволяет обеспечивать более точное взаимодействие антропоморфного робота с окружающей средой — в частности, преодолевать такие препятствия, как ступени и разрывы, и точно подходить к целевым объектам. В отличие от методов, основанных на полной или упрощенной динамике, предложенное решение не требует использования сложных планировщиков шагов робота и не опирается на аналитические модели. Планирование шагов осуществляется с помощью простых эвристик Raibert-типа и реализуется через обратную связь между планировщиком и обучаемой политикой. Проведено сравнение с двумя распространенными модельно-ориентированными подходами к планированию шагов: методом на основе модели линейного обратного маятника (Linear Inverted Pendulum Model, LIPM) и контроллером на основе гибридной нулевой динамики (Hybrid Zero Dynamics, HZD). Эксперименты демонстрируют сопоставимую или превосходящую точность удержания заданной скорости (до 80%) и существенно более высокую устойчивость на пересеченной местности (более чем на 50%) при сохранении аналогичного уровня энергоэффективности. Эти результаты свидетельствуют о том, что включение сложных компонентов, основанных на аналитических моделях, в архитектуру обучения может быть избыточным для задач устойчивой двуногой ходьбы, в том числе и на пересеченной местности.
Обучение с подкреплением, двуногая ходьба, бипедальная локомоция, планирование шагов
Короткий адрес: https://sciup.org/142247121
IDR: 142247121 | УДК: 004.852
Learning-based velocity-controlled bipedal locomotion with heuristic footstep guidance: revisiting the role of model-based priors
A heuristic approach to step planning for bipedal locomotion learning is presented, extending the standard control scheme based on tracking the robot’s desired torso velocity. This enhancement enables precise interaction with the environment, particularly in overcoming obstacles such as steps and gaps, and in accurately approaching target locations. Unlike methods based on full or simplified dynamics, the proposed solution does not require complex footstep planners or rely on a priori models. Step planning is performed using simple Raibert-style heuristics and is implemented through feedback between the planner and the learned policy. The approach is compared with two common model-based step planning methods: one based on the Linear Inverted Pendulum Model (LIPM) and the other on fullbody dynamics via Hybrid Zero Dynamics (HZD). Experiments demonstrate comparable or superior speed-tracking accuracy (up to 80%) and significantly greater stability on rough terrain (up to 50% improvement), while maintaining similar energy efficiency. These results suggest that incorporating complex model-based components into the training architecture may be unnecessary for achieving robust bipedal locomotion.
Текст научной статьи Бипедальная локомоция с эвристическим планированием шагов для поддержания целевой скорости движения: переосмысление роли модельных априорных знаний
Шагающие антропоморфные роботы обладают существенными преимуществами при работе в среде, спроектированной для человека — особенно там, где применение колес- hbix платформ или iihbix платформ ограничено. Но в то же время уникальная двуногая конструкция антропоморфного робота представляет собой инженерный вызов: в отличие от статически устойчивых механизмов, такие роботы должны постоянно поддерживать динамическое равновесие и управлять множеством своих степеней свободы. Разработка устойчивой и энергоэффективной системы управления бипедальной локомоцией, способной адаптироваться к различным типам местности, остаётся одной из ключевых задач робототехники.
Во многих работах [1,2] в качестве верхнеуровневого управляющего сигнала, подаваемого на вход контроллера ходьбы, используется целевая скорость торса — аналогично управлению колесными платформами. Такой подход эффективен на ровной поверхности, но недостаточно точен в условиях сложного рельефа или ограниченного пространства. Альтернативой является управление через желаемые положения стоп, что обеспечивает более надёжное взаимодействие с окружающей средой, но требует интеграции планировщика шагов.
Настоящая работа направлена на разработку системы управления двуногим шагающим роботом, которая использует гибридную постановку задачи: в качестве верхнеуровневых управляющих сигналов в контроллер ходьбы подаются как желаемые положения стоп, так и целевая скорость торса. Это позволяет сохранять гибкость управления ходьбой робота в открытых пространствах и обеспечивать точное перемещение в сложной среде — например, по ступеням или по поверхностям с разрывами. В следующем разделе представлен обзор существующих решений, обосновывающий выбор инструментария и архитектуры предлагаемого подхода.
1.1. Подходы к разработке систем управления гуманоидными роботами
В настоящее время существуют два основных метода управления двуногими шагающими роботами. Эти методы лежат в основе большинства подходов к управлению движением, между которыми располагаются многочисленные гибридные стратегии. Первый, более традиционный подход основан на классических методах управления. Он включает генерацию опорных траекторий для сочленений или звеньев робота — как в реальном времени, так и предварительно. Эти траектории могут быть получены с использованием моделей полной динамики тела, таких как метод гибридной нулевой динамики (Hybrid Zero Dynamics, HZD) [1,2], либо упрощённых моделей, таких как модель линейного обратного маятника (Linear Inverted Pendulum Model, LIPM) [3] и модель линейного обратного маятника с учётом момента импульса (Angular momentum Linear Inverted Pendulum, ALIP) [4]. После генерации опорных траекторий следующим шагом является обеспечение их точного отслеживания сочленениями или звеньями робота. Для этой цели применяются различные контроллеры, включая: ПД-контроллеры [2], контроллеры обратной динамики, такие как обратная динамика в пространстве задач (Task-Space Inverse Dynamics, TSID) [5] и ID-QP-контроллеры [6]. Генерацию траекторий можно рассматривать как управление высокого уровня, тогда как их отслеживание — как управление низкого уровня.
Основным преимуществом классических подходов является их предсказуемость — поведение робота можно заранее точно смоделировать. Однако серьёзным недостатком является жёсткая привязка к заранее заданным траекториям, что ограничивает адаптивность робота в условиях реального мира. Ещё одним недостатком является необходимость работы со сложными математическими моделями, которые даже после упрощения могут негативно сказаться на ключевых метриках производительности, таких как энергетическая эффективность.
Второй подход, тесно связанный с ростом вычислительной мощности современных компьютеров, основан на обучении без использования модели, в частности, обучении с подкреплением (Reinforcement Learning, RL). RL продемонстрировал высокий потенциал в задачах, требующих адаптивности и устойчивости, поскольку позволяет роботам осваивать эффективные стратегии управления методом проб и ошибок без необходимости точного моделирования системы. Такой подход упрощает процесс синтеза управляющих алгоритмов, однако может приводить к неинтуитивному или физически неестественному поведению из-за свободы агента в исследовании всего пространства действий. Несмотря на относительную новизну по сравнению с классическими методами, контроллеры на основе RL в последнее время достигли значительного прогресса, и ряд исследователей [7,9] успешно реализовали их на реальных двуногих роботах.
Одновременно развиваются гибридные методы, которые стремятся объединить преимущества обеих стратегий. Такие подходы ограничивают свободу действий методов RL путём включения знаний из классического управления. Например, структура HZD может использоваться для построения контроллера высокого уровня, тогда как обучение с подкреплением применяется для разработки контроллера низкого уровня, обеспечивающего отслеживание опорных траекторий [10,11].
1.2. Планирование шагов в задаче локомоции
Методы обучения с подкреплением демонстрируют высокий потенциал для реализации динамической локомоции у человекоподобных роботов. Тем не менее многие существующие контроллеры, основанные на RL, не учитывают явно ограничения на размещение стоп [7-9], позволяя системе управления свободно изменять положение стоп для поддержания равновесия. Хотя такой подход упрощает задачу обучения, он ограничивает применимость в условиях реального мира, требующих точное и аккуратное размещение стоп, например, при ходьбе по поверхности со щелями. Таким образом, явное включение ограничений на размещение ног в систему управления является ключевым условием для обеспечения устойчивой и надёжной локомоции в сложных и структурированных средах.
В данной работе представлена новая архитектура управления локомоцией, обеспечивающая отслеживание не только заданных команд по линейной и угловой скорости корпуса, но и желаемых положений стоп. В основе подхода лежит эвристический планировщик шагов, генерирующий целевые позиции для размещения ног. Эти цели подаются на вход политике, полученной с использованием методов обучения с подкреплением. Такая структура обеспечивает возможность адаптивной корректировки положения стоп в ответ на изменения среды — например, при необходимости обхода препятствий или преодоления разрывов в опорной поверхности.
В последние годы ряд исследований был посвящён интеграции планирования шагов в архитектуры обучения с подкреплением для управления бипедальной локомоцией. Например, в работе [12] RL-политика тесно связана с модулем планирования размещения стоп, что позволяет определять допустимые положения ног в сложных условиях окружающей среды. Несмотря на то, что такие архитектуры способны повысить адаптивность, они также существенно увеличивают сложность системы управления и вычислительные затраты. Кроме того, они, как правило, требуют точной оценки глобального положения стоп для надёжного отслеживания команд на размещение шагов в каждом цикле управления.
Предлагаемый нами подход сохраняет простоту классического управления с отслеживанием скорости — робот следует номинальной траектории движения, — дополняя его способностью при необходимости корректировать положения стоп. Такая декомпозированная структура способствует модульности и вычислительной эффективности, что повышает надёжность в различных сценариях локомоции.
Схожая стратегия была представлена в работе [13], где целевые положения стоп определяются с использованием линейной модели инвертированного маятника. Однако мы утверждаем, что применение классических модельных планировщиков, таких как ЫРМ, не является строго необходимым и, напротив, может привести к излишнему усложнению системы управления без существенного прироста качества. Для проверки этой гипотезы мы проводим сравнительный анализ трёх стратегий управления локомоцией, учитывающих планирование шагов: (i) эвристического метода, предложенного в данной работе (далее — метод линейного планирования шагов, или LS-подход); (ii) подхода, основанного на модели ЫРМ из [13]; и (iii) контроллера, использующего полную динамическую модель на основе гибридной нулевой динамики. Через это исследование мы стремимся ответить на ключевой вопрос в области бипедальной локомоции на основе RL: Насколько необходимы знания, полученные из математических моделей, для направления процесса обучения? Кроме того, как использование таких моделей влияет на поведение, эффективность и способность к обобщению у полученных стратегий управления?
В данной работе представлен вклад в двух основных направлениях: (1) Интеграция эвристического планирования шагов в архитектуру обучения. Предложена простая структура планирования шагов, не требующая использования сложных динамических моделей. В отличие от предыдущих подходов, в которых целевые положения стоп учитывались только в функции вознаграждения RL-политики или не задавались совсем [7,8], в нашем подходе используется механизм обратной связи, сравнивающий реальное и целевое размещение стоп в процессе работы политики (см. рис. 1). (2) Сравнительный анализ методов на основе математических моделей. Проведено систематическое сравнение предложенного подхода с двумя методами: на основе упрощённой модели динамики (ЫРМ) и на основе полной модели динамики (HZD). Это позволяет проанализировать влияние информации, полученной из математических моделей, на обучение, устойчивость локомоции, качество движения и способность политики к обобщению.
Предложенный подход был валидирован в симуляторах физики реального мира Pybullet и Isaac Gym на модели двуногого робота BRUCE (Bipedal Robot Unit with Compliance Enhanced) [15] и продемонстрировал эффективность в условиях сложной среды. BRUCE представляет собой гуманоидного робота, высотой 70 см и массой 4.8 кг, который был разработан в лаборатории RoMeLa в сотрудничестве с компанией Westwood Robotics. У робота десять приводов для ног — по пять на каждую ногу: сгибание-разгибание бедра, вращение бедра, поворот бедра, колено и сгибание-разгибание голеностопа.
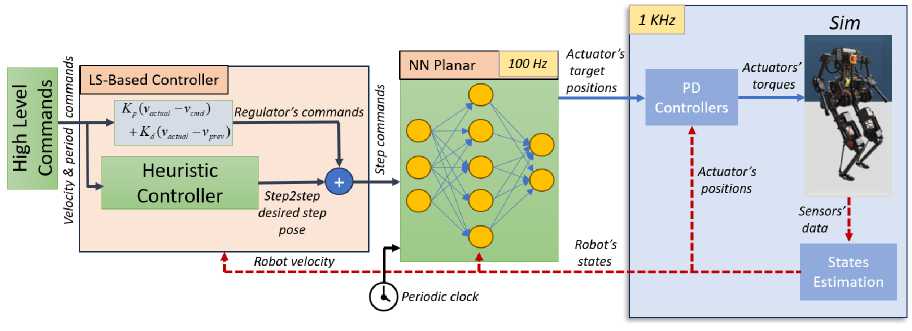
Рис. 1. Архитектура системы управления локомоцией бипедального робота. Метод использует эвристический планировщик шагов для определения позиций стоп, планировщик включает эвристику Райберта для точного отслеживания желаемой скорости
2. Предварительные сведения и постановка задачи
В этом разделе представлена реализация двух подходов к планированию шагов: простого эвристического планировщика, не использующего модель, и метода, основанного на гибридной нулевой динамике, в котором используется заранее сформированная библиотека походок для генерации опорных траекторий.
2.1. Реализация линейного планировщика шагов
Мы предлагаем простой планировщик высокого уровня, который вычисляет длину шага используя линейные зависимости, следующим образом:
Pd — [^step У step ^st ер] ,
где
{ V x • T d , lmax , lmax,
^max
vx • Td > ^max vx • Td — knax
И
{ ^ I v y > 0 и фаза переноса левой ноги
9 ’ 1 vy — 0 и фаза переноса правой ноги
2.2. Планировщик шагов на основе гибридной нулевой динамики
—sign(vy) • Wmin, в противном случае гДе vx,y ~ текущая скорость торса робота, Td — желаемая продолжительность шага, 0step — угол поворота стопы по курсу, lmax — максимальная длина шага, а Тщш — минимальная ширина шага. В данной работе ориентация стоп робота соответствует ориентации его торса. Однако данный подход может быть легко расширен в будущем за счёт включения команды ориентации стопы.
Для обеспечения точного отслеживания целевой скорости ходьбы используется регулятор типа Raibert, который добавляет смещение к позиции постановки стопы [19]:
^(х, У) — К р « - v d ) + K d (v a - <-1) ,
где v^ 11 v^ — фактическая и жстасмая скорости па. шаге k: Kp ii Kd — константы.
Динамика ходьбы человекоподобных роботов имеет гибридный характер: она включает как непрерывную фазу (движение между ударами ног), так и дискретные события (моменты контакта стопы с поверхностью). Существует множество методов управления такими гибридными системами, среди которых особо выделяется подход гибридной нулевой динамики [14]. В HZD используются управляющие воздействия и* (ж) для реализации виртуальных ограничений [20], которые навязывают движение по желаемой поверхности в пространстве состояний. Это достигается через экспоненциальное стремление ошибки отслеживания к нулю в непрерывных фазах:
у а : В Ы Rm : y a (q) — y a (q) — y d (r(q),a). (3)
Здесь q G В C Rn представляет собой обобщённые координаты робота, описывающие его текущую конфигурацию. Подмножество В определяет допустимую область конфигурационного пространства, в которой возможно применение управления. Фактический выход ya(q) (actual output) — это наблюдаемые переменные системы, такие как положение бедра, угол наклона туловища и другие параметры, подлежащие контролю. Желаемый выход yd(T(q^a) (desired output) 'задаётся как функция фазовой переменной т(q) ii параметров безье-полиномов a G Rmx(b+1)) где Ь — порядок полинома. Фазовая переменная т(q) служит нормализованным индикатором прогресса вдоль походки и позволяет синхронизировать движение по одной параметрической шкале, например, через горизонтальное смещение бедра. Таким образом, ошибка ya(q) отражает отклонение текущего поведения системы от желаемой траектории. HZD-инвариантные поверхности, полученные таким образом, называются нулевыми динамическими поверхностями, и метод требует, чтобы они сохранялись как в непрерывной, так и в дискретной фазе, что обеспечивает гарантированную устойчивость периодической походки.
Используя методы оптимизации, HZD позволяет генерировать набор траекторий, называемый библиотекой походок [2]. Следуя траекториям из этой библиотеки, робот может двигаться с различными скоростями или выполнять различные движения. Положение постановки ноги рассчитывается в ходе оптимизации, что делает данный метод схожим с методом линейного планирования шагов, но с учетом динамики всего тела. Для генерации библиотеки походок используется инструмент FROST, основанный на методе прямой коллокации [16].
В данной работе предполагается, что руки Bruce зафиксированы, чтобы сосредоточиться на методах планирования шагов. Аналогично подходу в работе Cassie [1], контакт с землей рассматривается как линейный вдоль оси х из-за малой ширины стопы. При этом Bruce, имеющий 10 приводов, является недоактуированным роботом.
Для построения библиотеки походок необходимо определить набор виртуальных ограничений. Поскольку акцент сделан на методе планирования шагов, выбран следующий набор виртуальных ограничений:
Положение основания относительно опорной стопы
y a (q) =
Положение маховой стопы относительно опорной Ориентация таза
Ориентация стопы
стопы
РЬа (e(q- Р (?)
Р^(Q) - Р g (?)
’
( ,0^
где Pbase; Р ар> и Р ip — эт0 положения торса, опорной и маховой ноги соответственно в мировой системе координат.
В процессе оптимизации накладываются ограничения на максимальную высоту маховой ноги и ориентацию таза, чтобы обеспечить устойчивость робота в реальных условиях. Походки генерировались при средней скорости в сагиттальной плоскости от -0.5м/с до 0.8 м с с шагом 0.1м с. и (-родной скорости в латеральной плоскости от -0.3м с до 0.3м/с. Кроме того, чтобы поощрить исследование пространств состояний робота во время обучения, длительность шага варьировалась в диапазоне [0.2, 0.4] с шагом 0.05 секунды. В результате общее количество сгенерированных походок составило 490.
3. Постановка задачи обучения с подкреплением
В рамках данной работы исследуется влияние различных высокоуровневых стратегий планирования на эффективность обучения с подкреплением в задаче бипедальной локомоции. Для этого реализованы две структуры обучения, а также воспроизведён метод из работы [13].
Первая структура (см. рис. 1) основана на эвристическом планировщике шагов, описанном в разделе 2.1. В ней опорные положения ног вычисляются с использованием простой обратной связи по скорости.
Вторая структура использует контроллер на основе библиотеки походок, сгенерированной при помощи метода гибридной нулевой динамики. Вместо планирования шага на лету, политика отслеживает заранее оптимизированные положения стоп из библиотеки. Эти эталонные траектории выбираются в соответствии с фактической скоростью робота как в процессе обучения, так и при исполнении.
В дополнение к этим двум структурам был реализован метод из работы [13], в котором планировщик шагов основан на упрощенной модели.
Во всех трёх случаях политика управления представлена в виде полносвязной нейронной сети с тремя скрытыми слоями по 256 нейронов. На вход в политику подаются со- стояние робота, команды скорости от пользователя, команды длительности шага, а также команды шага, полученные от соответствующих контроллеров высокого уровня.
Мы обучаем нашу политику в среде симуляции Isaac Gym на ровной поверхности, используя алгоритм РРО [17]. Пространства состояний и действий, а также функция вознаграждения для задачи RL подготовлены аналогично работе [13], при этом веса адаптированы под нашу модель, как представлено в табл. 1. Исключением является высота торса в методе на основе HZD, поскольку в этом случае используется опорное значение высоты из библиотеки походок. Для эвристического метода (LS) значения коэффициентов регулятора типа Райберта заданы как: К ^ = [0.3,0.3] и Кг / = [0.1,0.1].
Таблица!
Веса функций вознаграждения
|
Компонент вознаграждения |
Вес |
Компонент вознаграждения |
Вес |
|
Крутящий момент |
1 х 10-4 |
Плавность управления 2 |
0.005 |
|
Ограничение момента |
0.01 |
Регуляризация тазобедренных суставов |
1 |
|
Скорость сочленений |
1 х 10-3 |
Скорость наклона основания |
0.01 |
|
Ограничения сочленений |
10 |
Высота основания |
3 |
|
Плавность управления 1 |
0.1 |
Наклон основания |
1 |
|
Ориентация основания |
3 |
Отслеживание скорости |
4 |
|
График контактов |
9 |
4. Результаты экспериментов
Мы представляем результаты моделирования с использованием робота BRUCE, а также выполняем перенос политики управления из одной симуляции в другую (sim-to-sim) — в среду PyBullet, чтобы оценить эффективность предложенных подходов. На рис. 2 показана последовательность движений робота в среде PyBullet при поступательной скорости 0.6 м/с, полученная с использованием метода на основе LS. Сначала представлены результаты моделирования, за которыми следует подробное обсуждение.

Рис. 2. Последовательность кадров движения при симулированной ходьбе с использованием LS-метода в среде PyBullet при v x = 0,6 м/с и длительности шага 0,25 с. Пустые прямоугольные зоны соответствуют команде на правую ногу, закрашенные прямоугольные зоны — команде на левую ногу
-
4.1. Результаты моделирования
Точность отслеживания скорости
Было произведено сравнение производительности исследуемых методов при следовании за заданным профилем поступательной скорости во время ходьбы по ровной поверхности, как показано на рис. 3. В таблице 2 приведены средняя абсолютная ошибка (МАЕ) и стандартное отклонение поступательной скорости центра масс при заданной скорости 0.5 м/с, измеренные за 100 шагов с длительностью одного шага 0.25 с. LS-подход достигает МАЕ, равной 0.0136 м/с, что примерно на 80% меньше, чем у других методов, что свидетельствует о значительно более высокой точности. Также наблюдается наименьшее стандартное отклонение (0.0141 м/с), что указывает на стабильную работу контроллера.
Т а б л и ц а 2
Точность отслеживания линейной скорости
|
HZD-подход |
ЫРМ-подход |
LS-подход |
|
|
Средняя абсолютная ошибка [м/с] |
0.0868 |
0.0767 |
0.0136 |
|
Среднеквадратичное отклонение [м/с] |
0.0208 |
0.0540 |
0.0141 |
Отслеживание желаемого положения стопы
В таблице 3 приведено сравнение RL-контроллеров по точности следования за желаемыми положениями стоп. Ошибка измеряется как средняя абсолютная ошибка между запланированным и фактическим положением стопы при движении робота со средней скоростью 0,6 м/с в течение 20 шагов.
Т а б л и ц а 3
Ошибка отслеживания желаемого положения стопы
|
HZD-подход |
ЫРМ-подход |
LS-подход |
|
|
Средняя абсолютная ошибка [м] |
0.010 |
0.003 |
0.002 |
Производительность при разной длительности шага (частоте шагания)
Мы обучили все контроллеры работать в условиях, предполагающих вариацию длительности шага (или, эквивалентно, частоты шагания) в диапазоне от 0.2 до 0.4 секунд. В целом роботы успешно адаптировались к этим изменениям, демонстрируя устойчивое поведение во всём диапазоне.
Энергоэффективность
Энергоэффективность оценивалась на основе стоимости транспортировки (СоТ), рассчитанной как по механическим затратам, так и по электропотреблению [18]. Показатель полной энергетической стоимости Cet отражает суммарные энергетические затраты, включая потери в электронике и преобразователях, тогда как механическая стоимость Cmt учитывает только механическую работу, совершаемую приводами. Робот двигался по ровной поверхности со средней скоростью 0,6 м/с в течение 100 шагов. Результаты приведены в табл. 4 . Метод на основе LS превосходит метод на основе ЫРМ и достигает сопоставимых результатов с методом на основе HZD, несмотря на то, что метод HZD использует полную модель динамики робота для определения оптимальных положений.
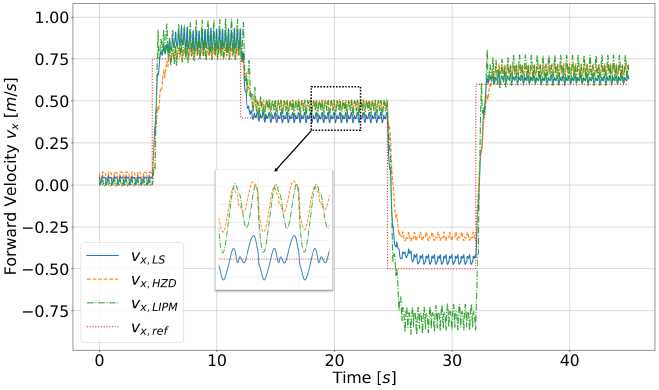
Рис. 3. Точность отслеживания скорости на ровной поверхности для трёх методов при длительности шага 0,25 с. Метод на основе LS превосходит подходы, основанные на HZD и LIPM
Т а б л и ц а 4
Энергетическая эффективность (стоимость транспортировки)
|
HZD-подход |
LIPM-подход |
LS-подход |
|
|
Cet [Дж/кГ • м] |
0.34 |
0.41 |
0.35 |
|
Cmt [Дж/кг • м] |
0.18 |
0.20 |
0.19 |
LIPM-Based Method
-6 -4 -2 0 2 4 6
Longitudinal Impulse [N.s]
HZD-Based Method
Tn 4 г
UI 2
I 0
2 -2
SI 4 -4
-6
-6 -4 -2 0 2 4 6
Longitudinal Impulse [Л/.s]
• Recover # Fall
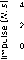
ru -2
-4
X * H^K (Recover: 215 (43%) 1 «Л* >6ХЧ2Л":285|57%,1
s< ft $ £ «V*
-6 -4 -2 0 2 4 6
Longitudinal Impulse [/V.s]
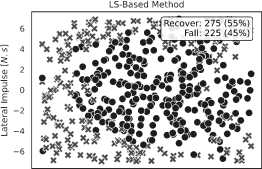
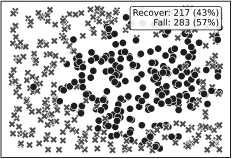
Рис. 4. Реакция робота на внешние возмущения при нулевой заданной скорости для трёх методов. Метод на основе LS смог выдержать большее количество импульсных воздействий с заданной силой по сравнению с другими, демонстрируя лучшую устойчивость. Общее число испытаний — 500. На каждом графике указано количество случаев восстановления равновесия и падений
Устойчивость к внешним возмущениям
Для оценки устойчивости каждого контроллера к торсу робота прикладывались внешние импульсы силы, а его реакция — падение или восстановление равновесия — отслеживалась. Каждый тест состоял из 500 повторений с максимальными значениями импульса силы 7 Н с и 5 Нс. В ходе испытаний роботу было задано поддерживать нулевую скорость.
Вероятность восстановления равновесия в табл. 5. На рис. 4 показано распределение положений, в которых робот либо падал, либо успешно восстанавливался при Lmaх = 7 Н с. Результаты показывают, что метод на основе LS превосходит другие подходы.
Ходьба по неровной поверхности
Для оценки адаптивности нашей политики к ранее неизвестным и неровным поверхностям мы провели эксперименты на сложном рельефе (рис. 5). В качестве метрики исполь-
Т а б л и ц а 5
Вероятность восстановления равновесия после внешнего воздействия
^^ LS-Based LWVi HZD-Based DOOM LIPM-Based
Рис. 5. Ходьба вслепую по пересечённой местности с использованием LS-метода в среде PyBullet (слева) и сравнение вероятностей успешного прохождения теста под управлением трех методов (справа). Метод на основе LS показал отличную устойчивость, демонстрируя приблизительно на 50% лучшую стабильность по сравнению с другими методами
Ходьба по поверхности с разрывами
Для демонстрации эффективности предлагаемого метода была проведена оценка поведения робота на поверхности с разрывами при использовании той же политики, обученной на ровной поверхности в среде симуляции IsaacGym. Восприятие рельефа осуществляется на основе карты высот, что соответствует условиям обучения при передвижении по лестнице. При обнаружении разрыва в области следующего запланированного шага робот смещает стопу к ближайшей допустимой плоской поверхности. Аналогичный подход был использован в [13] для обеспечения преодоления разрывов шагающими роботами. На рисунке 6 показано, как робот успешно передвигается по поверхности с разрывами, следуя сгенерированным командам шагов на скорости ходьбы 0.6 м/с. Это демонстрирует эффективность предлагаемого метода в поддержании устойчивости и динамическом изменении положений стоп при движении по прерывистой поверхности.
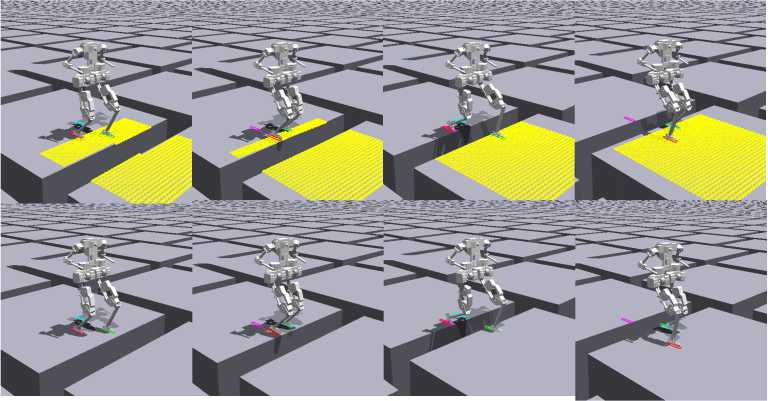
Рис. 6. Оценка предлагаемого подхода при ходьбе по поверхности с разрывами. Робот успешно пересекает разрывы, ширина которых не превышает максимально допустимую длину шага (40см). Цвета приведены в цветной версии статьи: красный — правая стопа, синий — левая стопа, жёлтые точки обозначают карту высот местности
4.2. Обсуждение
Предлагаемый метод, интегрирующий простое эвристическое планирование шагов в архитектуру обучения, показал высокую адаптивность. Несмотря на то, что политика обучалась на ровной поверхности, она успешно справляется с нарушениями структуры местности, включая прерывистые участки. Такая способность к обобщению подтверждает эффективность подхода при ходьбе по разнообразным типам рельефа.
Анализ полученных результатов показывает, что все три подхода обеспечивают хорошую производительность, несмотря на их структурные различия. Это свидетельствует о том, что метод планирования шагов является перспективной стратегией в области управления ходьбой двуногого шагающего робота, так как не ограничивает способность робота использовать полную динамику своего тела.
При следовании заданной скоростной траектории все три метода продемонстрировали хорошие результаты. Однако LS-подход достигает средней абсолютной ошибки, равной 0.0136 м/с, что примерно на 80% меньше по сравнению с другими методами, что свидетельствует о значительно более высокой точности отслеживания скорости.
Робот смог осуществлять ходьбу с различными частотами шагов во всех трёх методах. Мы полагаем, что обучение робота с использованием различных частот ходьбы позволило ему более эффективно использовать свою динамику. Это подтверждается тем, что ходьба с увеличенной длительностью шага напоминала бег трусцой, а не обычную ходьбу. Кроме того, при внешних возмущениях реакции робота были аналогичны тем, что наблюдались при большей длительности шагов.
Как можно было ожидать, метод на основе HZD показал наилучшую энергоэффективность. Однако неожиданным оказалось то, что метод LS продемонстрировал практически идентичные результаты. Это можно объяснить тем, что более простой контроллер предоставляет политике обучения с подкреплением большую свободу при исследовании траекторий по сравнению с методом, основанным на LIPM, что приводит к повышению энергоэффективности.
Метод LS продемонстрировал способность справляться с возмущениями приблизительно на 20% больше по сравнению с другими методами при импульсе силы 5 Н с. Кроме того, он продемонстрировал отличные результаты при «слепой» ходьбе по пересечённой местности, обеспечивая приблизительно на 50% более высокую стабильность в испытаниях по сравнению с другими методами.
Одним из наиболее важных результатов нашего исследования является то, что достижение высокой производительности и устойчивости возможно даже без опоры на точную модель динамики робота. Предложенный эвристический метод показал, что простое планирование шагов может быть достаточным для формирования эффективной и обобщающей стратегии управления. Это подтверждает, что модельно-ориентированные методы не обязательно необходимы для получения информации, направляющей обучение.
5. Заключение
В данной работе был представлен подход для обучения политики, которая точно отслеживала заданные координаты постановки ног. Наш метод использует простой линейный контроллер планирования шагов, при этом политика обучения с подкреплением (RL) обеспечивает хорошую устойчивость. Его производительность была сопоставлена с двумя альтернативными подходами: одним на основе упрощенной модели и другим — с использованием полной динамики тела. Результаты показывают, что даже простой контроллер достаточен для достижения целей обучения и демонстрирует хорошие результаты по нескольким ключевым показателям, таким как отслеживание скорости, энергоэффективность и устойчивость. Это сравнение также затрагивает важный вопрос о необходимости использования модельных методов для направления обучения RL-политики и рассматривает, как выбор метода влияет на производительность.
Будущие исследования сосредоточены на дальнейшем развитии контроллера RL, основанного на LS. Авторы ставят перед собой две цели: 1) Оценить производительность предложенного метода на реальном аппаратном обеспечении робота BRUCE. 2) Обучение контроллера RL, основанного на LS, для адаптации к изменениям уровня поверхности за счёт регулирования высоты шага. Следующим шагом будет обучение контроллера RL, основанного на LS, для адаптации к изменениям уровня поверхности за счёт регулирования высоты шага. Это расширение станет основой для разработки контроллера перспективного типа на основе RL, который заменит высокоуровневый LS-контроллер и будет работать в связке с низкоуровневой политикой для управления движением по пересечённой местности с разрывами и переменной высотой шагов.
