Building a Natural Disaster Management System based on Blogging Platforms

Author: M.V.Sangameswar, M.Nagabhushana Rao, M.Shiva Kumar
Journal: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Article in issue: 8, 2017.
Free access
Over the decades, numerous kinds of knowledge discovering and sharing of the data techniques are playing a major role to reach the information quickly. Among these since last few years, social networks or media and own blogging are playing a major in sharing the personal information, updating the status, tagging the location and many more features. These data are considered to examine and the acceptance for emergency services to respond with the information gathered from the social network. Taking this into the consideration, proposed an algorithm to find out the location of the person based upon the information shared. This is implemented on a most popular social media twitter to identify the tweets.
Emergency services, Twitter, Google map API, named entity recognizer, gazetteer database, user search methods
Short address: https://sciup.org/15014993
IDR: 15014993
Text of the scientific article Building a Natural Disaster Management System based on Blogging Platforms
Published Online August 2017 in MECS DOI: 10.5815/ijmecs.2017.08.05
-
A. Importance of Social Media
Social media is the combination of online interactions channels keen to community-based input, communication, content-sharing, and relationship. It is an essential part of life online as social websites and applications. Social media web-based services that permit individuals to build a public or semi-public profile within a restricted system, clear list of other users with whom they share a connection, view and pass through their list of connections and those made by others within the system. Social media use mobile technologies on smartphones and computers to create effective platforms through which individuals, groups, and firms can split, create, discuss, and change any form of the content created by user or content created by the user and published online.
Accordingly, social media sites have offered a policy where youth can create groups and pages depends on their abilities and opportunities for their careers by bringing up to date information on different issues to converse. Social media has become their lifestyle and it makes their lives easier and efficient. It has a great impact on youth.
Social media websites require the internet to connect the users to their particular destination. It makes easier and low cost to connect and get people together effective communication. It expands the universe we can collect the information and opinions of others very easily and fastly likewise helps in growth of organizations.
According to an American survey, the usage of social media had rapidly grown from 2005to2016.Mostly difference had occurred in adults provides a platform to communicate through worldwide, share details about their daily life, share opinions, post videos, and photos, to find entertainment content and updates of news and current events.
Social Networking sites are used by 7% of the US population 10 years ago. Now that outline has risen to 65%. Of those who use the internet a huge majority of 76% of American's use social media. Social media has the practice of gathering data from blogs and social media websites and analyze that data to make business decisions.
-
B. Most commonly and popularly social media sites:
There are 6 types of social media they are:-
-
• Social Networks: -Social Networks permit the user to connect with other people of same interest. User consists of profile and can set groups etc. Such as Facebook, LinkedIn etc.
-
• Bookmarking sites: Bookmarking sites helps the user to save, arrange and handle links to different websites through the internet. It marks the particular link and makes the user search more efficiently.
-
• Social news: Social news allows the public to post various news, links and permits to express opinions through votes, comments etc.
-
• Media Sharing: Media sharing provides the services of uploading, viewing the images and videos. Some sites have additional features like profiles, commenting etc. Such as YouTube, Flickr.
-
• Microblogging: Microblogging is a service that helps focus subscribed the user on receiving their updates.
-
• Blog comments and forums: Online forums allow users to hold the discussion by posting messages.
-
C. The discussion is made on the blog post.
Facebook: Facebook is the most popular site where we can find friends, colleagues, known one, and relatives all floating around. Facebook is the fasting growing website in the country as we can say it as number one in India.
LinkedIn: LinkedIn is specially used for entrepreneurs and skilled people and is one among the most dynamic in the country. Many of them are taking part of it and active in it. LinkedIn offers the chance for people who are part of it to put up their business outline with key issues such as skill, education, and business complex.
Twitter: Twitter is a social networking site where it is connected to interests of a person who had registered and can post called tweets and can give their opinion publicly. It is very useful to know daily updates.
YouTube: YouTube is used to share, upload, and download videos. It allows uploading, view, rate, and share add to favorites, report, and comment on videos. YouTube is the way to share personal and professional videos and also telecasts live updates/programs.
Instagram: Instagram is an application where a user can share photos and videos publicly or privately and users can follow. Users of Instagram can create and share videos with length up to 60 minutes.
Reddit: Reddit is a social networking site where a user can register for free and does not require an email address to complete the profile. When logged in, Reddit users have the facility to enlarge or decline their visibility, place links and comments vote on giving in and comments.
Google+: Google+ is a social network site that put up from your Google Account. The user of Google can activate Google+ account easily. It imports contacts and passing on them to circles. You can add to circles for your particular interests, entertainment, news, sports, etc.
Pinterest: Pinterest helps us to find new thoughts for projects, save them with photo sharing and visual bookmarking social media site or app.
Ask.fm: Ask.fm is collects, stores shares the information in ask website or application according to the agreement of the privacy policy. Registration is not mandatory the user with registration is said to be registered user without registration also some services can be used and said as the Guest user.
WeChat: WeChat is one of the messaging and calls application that allows you to connect with people of your option. It was also developed by Tencent in China and can easily work together with QQ. According to the BI intelligence report, the count of WeChat users is rapidly reaching the number of WhatsApp users.
Skype: Skype is one of the platforms of social networking communications based on the most common. It allows you to connect with people through voice calls, video calls (via a webcam) and text messages. You can also make calls from a group. And, the best part is that Skype-to-Skype calls are free and can be used to, in part relate to the world, the internet.
Viber: This multilingual social policy, available in more than 30 languages, is known for its immediate messaging and voice messaging capabilities. You can also share photos and videos and audio messages. It is possible to call non-Viber users through a functionality called Viber Out.
Telegram: The network is the same as WhatsApp Message Telegram is the most direct and accessible it is, by a greater than eight languages on the platforms. By means of his or her privacy and the security of a message to a more focused Telegram in diam lore. This allows you to send encrypted, and his own who are harming me. Encryption feature is accessible for WhatsApp In this way, as long as the always Telegram.
Line: The helpline is globally available messaging social network to share photos, text messages, and messengers, or audio files. In addition to that allows you to see the voice calls a day at any time.
Snapchat: Snapchat is an image messages publicly that allows chatting with friends by using images. It allows you to look at news and gives the updates happening around the world.
Badoo: Badoo shares particulars about the persons around you and about people whom you may have hit into in real life. It is used by more than 200 countries.
Skyrock: It is a French social networking site offers a free and personal web space to the user to make and post blogs, add outline and interchange messages. Skyrock is available in seven languages.
Snapfish: Snapfish is a photo-sharing networking site that provides unlimited storage to its user for uploading photos. Users of snappish are out of concern for a huge collection of images.
Flixster: Flixster site is for movie lovers they can give reviews and ratings for particular movie openly. Its users are likely to know about movies and get information about new movies.
Cafemom: Cafemom is an application used for mothers and mothers -to- be that helps them to get support and suggest on various issues pregnancy, fashion, food and health tips. Suggestions are given by experienced mothers.
Renren: Renren site is popular in china and the most users are youth due to its similar to Facebook. It provides all the features of Facebook such as easy to contact, share thoughts, post and update their moods
MyHeritage: MyHeritage is a site where users can make their family group, upload and check family photos and manage their family history and it is also possible to get information about ancestors of a particular person.
Xing: Xing is a professional site that has similar features of LinkedIn. This app was basically used in the countries like Switzerland, Austria, and Germany. Xing provides a platform for the discussion between the company or business.
Flickr: Flickr is a famous site for photo sharing and it provides facilities to store high-quality images by people who love photography. It is an active photo service and effective in sharing service.
Meet Me: Meet Me is a site where a user can meet new people and can have talk to them. This site is mostly used by teenagers and youth.
Meet Up: Meet Up is a site to find a people of same thoughts together means the interest of particular users matches who are nearby locality, anywhere in the world. It has a facility to offline meetings.
-
II. Advantages of Social Media
It provides open communication, leads to improve the information that finds and deliver.
-
• It permits people working in a place to talk about thoughts, post news, ask queries and share links.
-
• Supply’s an opportunity to expand business contacts.
-
• Objects wide viewers, creates a useful and efficient employment device.
-
• It Improves dealings reputation and user base with the minimal use of promotion.
-
• It enlarges market explores, implements advertising campaigns, transverse communications and expresses interested people to specific web sites.
-
• It is cheaper than conventional advertising and encouragement activities.
-
• It Shares mass information is very effortless and very fast since many social media sites give the facility of forming groups.
-
• It’s a way of earning and occupation for a massive number of people who own their Pages on social media sites like Facebook or are running video channels on YouTube.
-
• It’s a great resource of entertainment or energizes which helps you improve your mood.
-
• Social Media brings awareness and modern way of living such as in farmers, students, teachers and common man in the society
-
• It helps to trace the criminal case using networking sites such as drug sellers etc.
-
III. Disadvantages of Social Media
-
• The deviation of this tycoon is goanna stick every human life attractively which leads to sort of draw backs
-
• Firstly the things is currently processing is " HACKING" which would take place at common places
-
• It also hacks the confidential info like passwords keywords etc
-
• The hacker will show more interest in professional information which is related to victim profiles
-
• They may create fake ID cards, driver license, social security cards by having the fake info like date of birth, name & location profile id etc
-
• The next comes to the connectivity Scorpio like creating fake advertisement like online shopping case creating fake advertising about a product of 20% of flat offers and if ratio of 100 shares this post it may lead them to be victims
-
• Around over 15 million of white people of US are effected and caught as victims in this case
-
• This sort of problem is again proceeded at facebook hacking the person's ID and involving the unrelated post to that ID & if that post has some likes about above 100 again that may lead to becoming the victims to that like persons
-
• Related to trading companies and some official section the lack of info is hacked and by that company official details are leaked through this aspect and by this captured situation which may collapse company name and fame and leads to breakdowns the company shares to scale down the situation
-
• General to all these aspects it also effects to political issues like upstanding the vote count and during the election process the voting booths are also gonna hacked through the info that related to voters ID proofs etc
-
• Using social networking at all common work place which leads to jam session which would bounce the security confidential networking sites into different networking which may lead to hacking the info and leak disadvantages of social media(potential)
-
• Humanity is the first victim in the sense of social media
According to information from New Media Trend Watch of February 2011, Japan had 94.2 million Internet customers and 39.5 million social networking users. It is estimated that 83 percentages of people in Japan used a mobile phone in 2011, higher than the estimate for Users of US mobile phones (75.7%) (New Media Trend Watch, 2012). In Japan, 65% of mobile phone users have a high specification's functional phone, while 6% Use mobile phones as Smartphone’s. Although the saturation of Internet access and the use of social networks is not the majority of Japanese citizens use this technology to some extent. During the earthquake and tsunami, Japan has about ten million active users twitter, making the country one of the best promotions for Twitter. Whenever an earthquake occurs, they use this communication media to transfer any of the information.
-
IV. Importance of Blogs
A blog is an argument or informational site available on the WWW (World Wide Web) often informal text entries (post).Posts are exhibited in reverse chronological order. The latest post appears at the top of the site. Till 2009 they are work done by single man and covered by the single topic. In 2010 multi-authored blogs are introduced where handled by the group of people.
Bloggers do not only post the content but also maintains a relationship with readers and at the same time with other bloggers. The topics discussed in blogs ranges from politics to sports.
-
V. Twitter for Emergency Management
In twitter, users can send and receive information about 140-character messages. These are used to analyses the tweets from the different users to find the geolocation. The proposed system has used these datasets to identify the place. By using these data, proposed system analyses the ‘Geo-Coordinates’ and apply them into Google API to get the Location in the Map. In this paper, proposed an algorithm to generate Geo-Location based on particular user-generated tweets or based on Particular Tweets. Finally, generates the graphical user interface as shown in the below Figure 5.1.The main objective is to provide the information to Emergency Response Teams (ERT) to help the people.
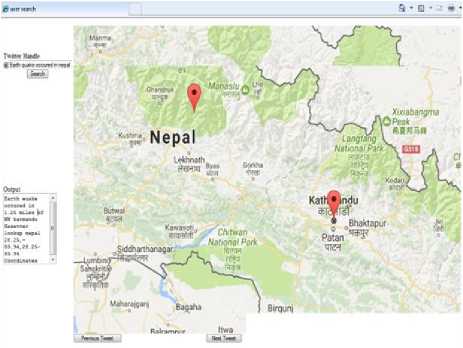
Fig.1. (A) User Search API
Fig.1. (b) User Search API
User Search API:
Methodology to find the geo-location using Social
Media Twitter:
Proposed methodology is to retrieve the tweets and extracts the geo-information from the tweets user and downloads a portion takes by using the user search method. The keyword search method is another component of the user search method. The new tweets come in containing this word by using this keyword search method. The user is tweeting from the utilization of above user search method and to determine the location.
-
VI. Libraries and Api Required for Each Component
These libraries while not necessarily built or tested by twitter. Should support the current Twitter API.
-
1. It handles the requests by using Twitter API and Twitter 4J. This is primarily for data gathering. Twitter 4J is an open source library. The data retrieved from Twitter Developers site it makes the request to the Twitter API by utilizing one’s Twitter API keys. The data retrieved from the twitter for that they provide different API methods retrieve different information from twitter we have two methods.
-
• The first method is GET method, in this method to get a user’s tweets for providing we can utilize this method.
-
• The second method utilizes the streaming API to user this API to look for keywords as they appear in new tweets for us to automate the process of retrieving users.
-
2. The user search method in the twitter API we are several different GET calls. In this method we enter the username into the text box then after a certain number of tweets are retrieved. To accommodate more domain specific search. The keyboard search method of this project was created. For our future work we plan to incorporate, but now this feature does not have all of its functionalities.
-
3. In order to parse through the text of each tweet, we are using Named Entity Recognizer (NER). To pull out proper noun we are mainly using this library that is the method. Stanford’s API is an open source, so it is easily accessible and it is possible that we will develop a NER and it is worked specifically for twitter and micro text place names are always able to recognize or utilize with a different NER.
-
4. To spanning the entire United States we also used the geographical survey (USGS) gazetteer. Along with other several types of gazetteers this USGS gazetteer free and it can be downloaded at their site. This particular one list names of highlighted places and also historical and corresponding coordinates as well as within certain states. To predict the locations extracted from tweets gazetteers also integrated into our core algorithm.
It has three attributes for good training and testing data present for the algorithm. These three attributes are necessary for the test.
-
• A place name where the earthquake occurred.
-
• Secondary information it allows finding a place related to another place we have some keywords like north, south, east, west, etc.,
-
• Actual location as given to us by the tweets metadata/tweets geo-tagging API.
The framework describes the proposed algorithm methodology which will shows (Fig.5.2) how the data is retrieved from the tweets being resolve and updated. Also included the error or how far away our predicted location was from the actual location provided to us in the tweets metadata.
-
1. The user inputs a name of a twitter user they would like to download tweets from where this algorithm utilizes the user search.
-
2. Then these tweets are separately parsed by using Stanford’s Named Entity Recognizer. In this tweet, the proper nouns are found in it. Then these tweets are then matched with our downloaded gazetteer to see it. We can resolve a location for the place name. In this the first failure rate was about 30%, however, the addition of a simple check for the name that the NER did identify, prefixed with common California town prefixes (LOS, LAS, SAN, etc.) actually dropped the failure rate to about 18%.
-
3. The important part of this algorithm is the adjust coordinates () method. We are currently classifying the tweets and the predicated coordinates from the gazetteer lookup and add or subtracts to the coordinates based on the secondary information in the tweet. It specific method searches for the use of miles/mi in the tweet. Then after it parses the token for the number of miles that is being referred to then we convert them it into latitude and longitude coordinates the predicted coordinates to adjust them. By utilizing this method on the tweets we can increase the accuracy.
-
4. The interface is utilized by typing the name of a certain user of twitter to search for once the twitter button is pressed 200 of the user’s last tweets are also downloaded for the parsing. Each and every tweet is parsed and the coordinates are saved to the memory. The console on the button left details the steps and displays the information that is retrieved from the tweet. The user who are registered they can get the latest tweet is displayed on the map on the right of the GUI.
-
5. This map utilizes Google maps API in order to display a map that which we can have in the surrounding areas that parsed out. In such cases, the location cannot be retrieved from the selected tweet. In such cases, an error can occur or will center itself on the actual location referred to by the tweet.
-
A. API Objects
There are four main objects that you’ll encounter in the API. Tweets, Users, Entities and places.
-
• Tweets: Tweets are the basic atomic building block of all things twitter. Tweets are also known as status updates. Tweets can be embedded, replied to, liked unlinked and deleted.
-
• Users: Users can be anyone or anything. They tweet, follow, create lists, have a home timeline, can be mentioned, and can be looked up in bulk.
-
• Entities: Entities provide metadata and additional contextual information about content posted on Twitter. Entities are never divorced from the content they describe. Entities are returned whenever Tweets are found in the API. Entities are instrumental in resolving URLs. Read Entities in objects for a more comprehensive guide to how entities are used throughout Twitter objects.
-
• Places : Places are specific, named locations with corresponding geo-coordinates. They can be attached to Tweets by specifying a place_id when tweeting. Tweets associated with places are not necessarily issued from that location but could also potentially be about that location. Places can be searched for. Tweets can also be found by place_id. Places also have an attributes field that further describes a Place. These attributes are more convention rather than standard practice and reflect information captured in the Twitter places database. See Place Attributes for more information.
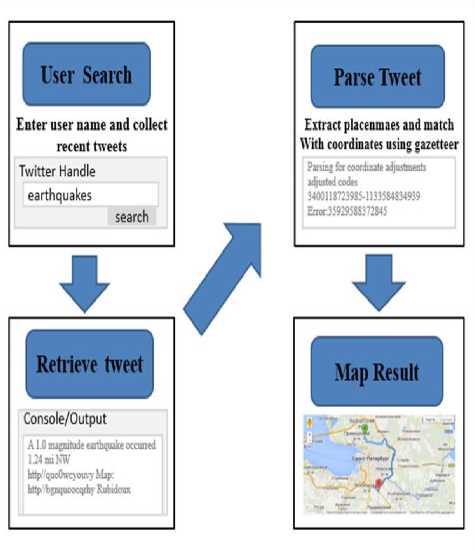
Fig.2. Framework
To implement the proposed System, the following algorithms are used.
The following algorithm is used to get the particular user tweets from micro blogging platforms. In this twitter API, Twitter 4J classes and methods are used to get tweets of an exact user. In this method, co key, consumer secret key and access key, access token secret keys are used to access the twitter. User input a key and based on that searched query, tweets are retrieved using getTweets() method from twitter API.
-
VII. Algorithm
Algorithm: LOAD PARTICULAT TWEET’S Start
Load Twitter API
Set CONSUMER_KEY, CONSUMER_KEY_SECRET; getInstance using Twitter Factory,ConfigurationBuilder;
Initialize AccessToken,AcessTokenSecretKey;
Access accessToken, accessTokenSecret;
Access Twitter (accessToken, accessTokenSecret);
Create Query ("Earth Quake In Nepal");//user search information
Get today's date;
ModifiedDate toSimpleDateFormat("yyyymmdd");
Set modifiedDate;
QueryResult result;
List tweets = result.getTweets();
for each Status tweet : tweets
Store every Tweet in File//using tweets.getText Method
End for
End
The following algorithm describes the tweet which is placed in a text file each tweet copied to line string up to 200 characters this line string can be checked with for every gazetteer data after getting gazetteer data this data applied to GEO MAP to know the actual coordinates, and predicate coordinates then the map can be placed.
Load Gazetteer data
Store each location in area;
Open file placename file
If not found
Show tweets are not available;
End if
-
initialize line up to 200 characters;
While [ fgets line[200] from filename ] if strstr [ Line ,Area]
fputs [line,place];
End if
End While
Close file
End
By using Java Script Google map API to get the map, for this, we take two inputs area and place name from place find an algorithm to get the map we used google.map.Map() function is used to get the map on screen respected place names and area latitude and longitude values can be retrieved. These values are placed on the map for team taken geo code method, geo code address method and marker method is used to get marker on the map that to center.
Start GoogleMap
Set lattitude,longitude;
Var Intialize Geocoder;
Add geocoder,map;
End Var
Function set geocode address var initilize address;
getGeoCode address,status ;
if status is ok
Set geometric location to Center;
var setmarker;
initilize result 0,poistion;
get GeoMetricLocation;
End if
Else
Alert geocode was not successful;
End
End
On the actual location referred to by the tweet
A 4.0 magnitude earthquake occurred 1.25miles of NW
Katmandu
Gazetteer lookup (Nepal): 28.25,-83.9428.25,
83.94}
Adjustment (1.25 mi N): {0.01, 0}
Predicted coordinates = {28.25,-83.94} +
Compared to: (actual) {27.71, 85.32}
-
Fig.3. Example of a tweet being parsed
-
3 place -Notepad - □ X
File Edit Format View Help
Chennai)
nizamabad warngal hydenabad rangareddy nepal secundrabad
-
Fig.4. Gazetteer data will load to place DB
Failure: 336/2118=0.1586
Avg Diff: 28.95 mi
Median: 1.769
-
Fig.5. Testing results on 2118 Tweets
Fig 5 shows the output of test in the framework the test conducted for 2118 separate tweets from the use @earthquake Nepal on twitter each tweet received the pass or fail information dependency on the distance between actual coordinates (taken from the tweet )predicates coordinates (taken from the place name). In this out 2118 tweets 336 tweets re trailed to determine a location, pass & fail; grades is dependency weather location is find (or) not the average differences between actual coordinates & predicate coordinates is to be computed to be 2207 miles (this is the overall average distance for all (1782@tweets with predicate location) the median distance the actual middle distance of our sorted set of determined distances was 0.45 miles.
The differences in actual and predicate coordinates, in reality, is very low (over 50% actual coordinates are within 0.45 miles of the actual locations).however the average difference displays much larger discrepancy issue that have to a high disparity between the correctly identified places are ambiguous name which are able to be classified (example greatest Los Angeles area is identified as Los Angeles) and name of places that occur more than once in the state of California these errors can lead to any range from 50 miles to several hundred miles the overall average will be thrown off by these outliers even though most values are within 1 mile.
As a prototype of the proposed framed work, displaying few shortcomings, the median differences of 0.45 miles is not much relatively speaking. But a circle with a 0.44-mile radius can hold many buildings and housing complexes .if this is to be implemented as a tool for search and rescue, the error will need to come down quite a bit.
Another issue is the fail rate of our framework tweets containing ambiguous language, or unclear place names can lead to failures when trying to predict coordinates .this can be mediated through either the development of a natural language pre-processing (NLP) library built specifically for micro text/microblogging sites or an overhauled gazetteer.
To assist in resolving place names KS (keyword search) functionality is also extremely important for our services as this would allow us to listen to calls for help from any user on twitter.
-
VIII. Conclusion and Future Work
This paper based on geo-location service. The most popular microblogging platform twitter from this tweet is identified, retrieved from each tweet place names are recognized. After this placement are correlated with gazetteer data of particular region.
Then based on place name actual correlated and predicted coordination calculate and by using this to calculate, GUI map can be drawn automatically. We plan to improve the NLP framework to identify, the place name more accurately in different microblogging platform such as (tweet, Facebook status). In order to speed up the procedure extends this project, some connections are required, this connection is like a plug on to twitter automatically this plug is used to analyze, the real-time messages on twitter can be separated and processed by algorithm instantly. With cloud streaming services such as Amazon kinesis, the framework can be scaled up to the process all the global Twitter data information in real-time.
Acknowledgment
References Building a Natural Disaster Management System based on Blogging Platforms
- Gelernter, Judith and Nikolai Mushegian. "Geo-parsing messages from microtext." Transactions in GID 15.6 (2011): 753-773.
- Jaiswal, Anuj, Wei Peng and Tong Sun. "Predicting Time-sensitive User Locations from Social Media." 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. New York: ACM, 2013. 870-877.
- Zhang, Wei and Judith Gelernter. "Geocoding location expressions in Twitter messages: A preference learning method." Journal of Spatial Information Science 9 (2015): 37-70.
- Nadeau, David and Satoshi Sekine. "A survey of named entity recognition and classification." National Research Council Canada (2006).
- Leidner, Jochen L. and Michael D. Lieberman. "Detecting Geographical References in the Form of Place Names and Associated Spatial Natural Language." SIGSPATIAL Special 3.2 (2011): 5-11.
- Wang, Wei. "Automated spatiotemporal and semantic information extraction for hazards." PhD (Doctor of Psychology) thesis, University of Iowa (2014).
- Kinsella, Sheila, Vanessa Murdock and Neil O'Hare. "I'm eating a sandwich in Glasgow: modeling locations with Tweets." Proceedings of the 3rd international workshop on Search and mining user-generated contents. ACM (2011).
- Starbitd, Kate and Stamberger, Jeannie. “Tweak the Tweet: Leveraging Microblogging Proliferation with a Prescriptive Syntax to Support Citizen Reporting”. Proceedings of the 7th International ISCRAM Conference – Seattle, USA (2010).
- HAN, B., COOK, P., AND BALDWIN, T. Text-based twitter user geolocation prediction. Journal of Artificial Intelligence Research 49 (2014), 451–500. doi:10.1613/jair.4200.
- AHLERS, D. Assessment of the accuracy of geonames gazetteer data. In Proc. 7th Workshop on Geographic Information Retrieval (Orlando, Florida, 2013), ACM, pp. 74–81. doi:10.1145/2533888.2533938.
- EDWARDS, S. E., STRAUSS, B., AND MIRANDA, M. L. Geocoding large populationlevel administrative datasets at highly resolved spatial scales. Transactions in GIS 18, 4 (2013), 586–603. doi:10.1111/tgis.12052.
- GELERNTER, J., AND BALAJI, S. An algorithm for local geoparsing of microtext. GeoInformatica 17, 4 (2013), 635–667. doi:10.1007/s10707-012-0173-8
- GELERNTER, J., GANESH, G., KRISHNAKUMAR, H., AND ZHANG, W. Automatic gazetteer enrichment with user-geocoded data. In Proc. 2nd ACM SIGSPATIAL International Workshop on Crowdsourced and Volunteered Geographic Information (New York, NY, 2013), pp. 87–94. doi:10.1145/2534732.2534736.
- GELERNTER, J., AND ZHANG, W. Cross-lingual geo-parsing for non-structured data. In Proc. 7th Workshop on Geographic Information Retrieval (New York, NY, 2013), ACM, pp. 64–71. doi:10.1145/2533888.2533943.
- SPERIOSU, M., AND BALDRIDGE, J. Text-driven toponym resolution using indirect supervision. In Proc. 51st Annual Meeting of the Association for Computational Linguistics (ACL) (Sofia, Bulgaria, 2013), pp. 1466–1476.
