Быстрая оценка энтропии длинных кодов с зависимыми разрядами на микроконтроллерах с малым потреблением и низкой разрядностью (обзор литературы по снижению размерности задачи)
")
Автор: Иванов Александр Иванович, Банных Андрей Григорьевич
Журнал: Инженерные технологии и системы @vestnik-mrsu
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 2, 2020 года.
Бесплатный доступ
Введение. Целью работы является снижение требований к разрядности и производительности процессоров доверенной вычислительной среды при оценке энтропии длинных кодов с зависимыми разрядами. Материалы и методы. Используются процедуры тестирования, рекомендованные национальными стандартами России. Используется переход от анализа обычных длинных кодов к расстояниям Хэмминга между случайными кодами «Чужой» и кодом образа «Свой». Результаты исследования. Показано, что переход к представлению данных нормальным законом распределения в пространстве расстояний Хэмминга делает связь между математическим ожиданием и энтропией практически линейной. Построены низкоразрядные таблицы, связьшающие первые статистические моменты распределения расстояний Хэмминга с энтропией длинных кодов. При вычислениях показатель коррелированности разрядов исследуемых кодов может изменяться в широких пределах. Обсуждение и заключение. Вычисление математического ожидания и стандартного отклонения легковыполнимы на малоразрядных микроконтроллерах с низким потреблением. Пользуясь синтезированными таблицами, от младших статистических моментов расстояний Хэмминга удается легко переходить к энтропии длинных кодов. Задача вычисления энтропии многократно ускоряется в сравнении с процедурами Шеннона и становится реализуемой на дешевых малоразрядных процессорах.
Микроконтроллеры с малым потреблением, тестирование нейронных сетей, энтропия длинных кодов, зависимые разряды, код
Короткий адрес: https://sciup.org/147221960
IDR: 147221960 | УДК: 621.865.8:004.032.26 | DOI: 10.15507/2658-4123.030.202002.300-312
Rapid estimation of the entropy of long codes with dependent bits on low-power, low-bit microcontrollers (review of literature on reducing the dimension of a problem)
Introduction. The aim of the work is to reduce the requirements for bit depth and processor performance of a trusted computing environment when estimating the entropy of long codes with dependent bits. Materials and Methods. Testing procedures recommended by the Russia national standards are used. The transition from the analysis of ordinary long codes to Hamming distances between random Alien codes and the Own image code is used. Results. It is shown that the transition to the presentation of data by the normal distribution law in the space of Hamming distances makes the relationship between mathematical expectation and entropy almost linear. Low-bit tables are constructed that relate the first statistical moments of the distribution of Hamming distances to the entropy of long codes. In calculations, the correlation index of the digits of the studied codes can vary widely. Discussion and Conclusion. The calculation of the mathematical expectation and standard deviation is easily feasible on low-discharge low-power microcontrollers. The use of the synthesized tables makes it possible to pass easily from the lower statistical moments of the Hamming distances to the entropy of long codes. The task of calculating entropy is accelerated many times in comparison with Shannon's procedures and becomes feasible on cheap low-bit processors.
Текст научной статьи Быстрая оценка энтропии длинных кодов с зависимыми разрядами на микроконтроллерах с малым потреблением и низкой разрядностью (обзор литературы по снижению размерности задачи)
Цифровая экономика должна базироваться на безопасных облачных сервисах обработки личных и корпоративных данных. Сегодня безопасность облачных сервисов строится на применении парольной аутентификации. К сожалению, человек не может запоминать длинные пароли из случайных символов для своей безопасной работы в интернет-облаках.
Для того чтобы избавить человека от необходимости запоминать длинный пароль доступа, в США, Канаде и странах Евросоюза пытаются применять так называемые «нечеткие экстракторы» [1–3]. Из-за того, что «нечеткие экстракторы» используют классические коды обнаружения и исправления ошибок с 20-кратной избыточностью, пароли, сцепленные с биометрией, оказываются короткими. Так, код пароля для папиллярного рисунка отпечатка пальца составляет примерно 16 бит, или 2 случайных символа в 8-битной кодировке. Очевидно, что вычисление энтропии пароля из двух случайных символов легко выполняется по Шеннону.
В России эта проблема решается использованием больших искусственных нейронных сетей, которые заранее обучаются преобразовывать биометрические данные человека в длинный код его пароля доступа. При этом обучение выполняется автоматически алгоритмом ГОСТа Р 52633.5-20111. За один бит кода пароля пользователя отвечает один нейрон нейросети, по этой причине нейросетевые преобразователи биометрии обычно строят под длину кода в 256 бит. Наиболее распространенные сегодня операционные системы Linux, Windows, Android воспринимают пароли длиной не больше 256 бит (32 случайных знака в 8-битной кодировке). Нейросетевые преобразователи биометрия-код выгодно строить под максимально возможную длину пароля доступа, характерную для той или иной операционной системы. По этой причине нейросетевую технологию защиты иногда называют «высоконадежной»2. Хакер, ничего не знающий о биометрическом образе пользователя «Свой», вынужден перебирать все состояния очень длинного кода доступа [4].
Как правило, после получения длинного личного ключа пользователя или его длинного пароля доступа запускается некоторый криптографический протокол выполнения аутентификации. Криптографические протоколы принято считать надежными, если энтропия блока шифротекста длинной в 256 бит будет составлять ровно 256 бит. Если энтропия оказывается больше или меньше, то криптосхема защиты информации может оказаться дефектной. Эти соображения с некоторой натяжкой можно перенести на защиту криптографического ключа «нечеткими экстракторами» или размещением его данных в параметрах обученной нейронной сети. Знание энтропии состояний кода ключа оказывается эффективным контрольным параметром при анализе уровня защиты от попыток его подбора.
В случае, если разрядность кода доступа мала, то расчет энтропии этих кодов можно выполнить по Шеннону. В частности, при кодах длиной 16 бит «нечеткого экстрактора» энтропию следует вычислять по следующей формуле [2; 3]:
H ( x 1 , x 2 ,..., x 1б ) = - ^ p- log2( p ) , (1) i = 1
где pi – вероятность появления одного из 216 = 65 536 состояний кодов.
Для того чтобы оценить вероятность появления 216 состояний кода, необходимо иметь базу из 216+4 папиллярных рисунков отпечатков пальцев «Чужой». Собрать базу из почти миллиона рисунков отпечатков пальцев сложно, но технически возможно. По этой причине процедуры вычисления энтропии по Шеннону для «нечетких экстракторов» вполне применимы.
Положение коренным образом меняется, если мы переходим к кодам длинной в 256 бит:
H ( x i , x 2 ,..., x 256 ) = — £ ps ■ log 2 ( p ^. (2) = 1
Для прямых оценок очень малых вероятностей появления 2256 состояний кода потребуется использовать базу из 2256+4 биометрических образов «Чужой». Технически невозможно создать и использовать столь большую тестовую базу.
Обзор литературы
Для решения проблемы больших тестовых баз и сложных вычислений энтропии по Шеннону в России разра- ботан стандарт ГОСТ Р 52633.53. По рекомендациям этого стандарта требуется применение малых тестовых баз образов «Чужой» объемом от 21 до 64 примеров.
Применение стандарта дает экспоненциальное снижение объема тестовой выборки. Этот выигрыш обусловлен тем, что стандарт рекомендует переходить от анализа обычных кодов в пространство расстояний Хэмминга:
c
256 i h = E ® i=1 „ н
_ xt
где '' c i '' – дискретное состояние i -го разряда кода «Свой»; '' x i '' – дискретное состояние i -го разряда случайного кода образа «Чужой»; ⊕ – операция сложения по модулю 2. Если пространство обычных 256-битных кодов имеет огромное число состояний, то пространство расстояний Хэмминга будет иметь всего 257 состояний, наблюдается экспоненциальное снижение размерности задачи.
По малой выборке от 21 до 64 опытов можем вычислить математическое ожидание E ( h ) и стандартное отклонение σ ( h ). Знание о значениях этих двух статистических моментов позволяет оценить вероятность угадывания кода «Свой» P 2 . Оценка вероятности выполняется в рамках гипотезы нормальности:
P 2 -
1 су( h yj2n
(exo Г< E ( h *— u ' 1 ^ I 2 ( o ( h ) ) 2
i
—ro
—
• du . (4)
В этом случае энтропия нейросетевого преобразователя оценивается следующим образом:
H (" x 1 , x 2 ,..., x 256 ") ~- log2( P2) . (5)
Применение тройки преобразований (3), (4), (5) позволяет уйти от экспоненциальной вычислительной сложности оценок энтропии длинных кодов по Шеннону4. Более того, эта совокупность вычислительных процедур обеспечивает линейную вычислительную сложность и снимает проблемы привлечения процессоров, поддерживающих 32- и 64-разрядные вычисления5 [5].
Кроме того, отпадает необходимость тратить значительные объемы памяти на хранение больших объемов тестовой базы образов «Чужой». Достаточно помнить порядка 30 тестовых образов «Чужой». Столь малое число образов «Чужой» может быть использовано как образы-родители. Их морфинг-скрещиванием могут быть получены сотни тысяч синтетических тестовых образов-потомков с помощью процедур, регламентируемых национальным стандартом ГОСТ Р 52633.2-20106. В одном поколении морфинг-скрещиванием удается увеличивать число естественных тестовых примеров «Чужой» примерно в 20 раз, соответственно, для получения больших тестовых баз приходится размножать данные в нескольких поколениях [6–9]. Процедуры размножения данных применимы и к примерам образа «Свой» в рамках бутстрап-идео-
-
3 ГОСТ Р 52633.5-2011. Защита информации...
-
4 Быстрые алгоритмы тестирования нейросетевых механизмов биометрико-криптографической защиты информации / А. Ю. Малыгин [и др.]. Пенза: Изд-во Пензенского государственного университета, 2006. 161 с. URL: (дата обращения: 29.04.2020).
-
5 Нейросетевая защита персональных биометрических данных / под ред. Ю. К. Язова. М.: Радиотехника, 2012. 157 с. URL: http://www.radiotec.ru/book/170 (дата обращения: 29.04.2020).
-
6 ГОСТ Р 52633.2-2010. Защита информации. Техника защиты информации. Требования к формированию синтетических биометрических образов, предназначенных для тестирования средств высоконадежной биометрической аутентификации.
логии, заполнения пустых интервалов реальных гистограмм распределения7.
К сожалению, применение морфинг-размножения биометрических образов в нескольких поколениях приводит к их вырождению. В частности, возникают дефекты «кошмара Дженки-на» [10–12] и дефекты вырождения корреляционных матриц8. Крайне важным является то, что, применяя специальное программное обеспечение, удается практически полностью устранить дефекты размножения данных в первых нескольких поколениях9.
Материалы и методы
Еще одним направлением работ, связанных с упрощением вычислений, является симметризация корреляционных связей в длинном коде с зависимыми разрядами. Идея метода сводится к замене изначально асимметричной корреляционной матрицы на ее симметричный аналог:
где параметр симметричной матрицы r; вычисляется простым усреднением модулей всех коэффициентов корреляции исходной асимметричной матрицы:
r" ” E(|r I)
n2 - 2 n
0, 5 n 2 - n
∑ r i . (7)
= 1
1 r l r 2
r l 1 r n + 1
r 2 r n + 1 1
. r n r 2 n - 2 r 3 n - 3
r r
^
^v ^ ■ r r 1
^v
r
rn r2 n-2
r 3 n - 3
^v r
^v r
^v r
^
При росте размерностей задачи (число нейронов в нейросети: 32, 64, 128, 256) ошибка приближения (7) быстро падает. По этой причине оценивать энтропию можно через вычисления показателя средней коррелиро-ванности (7) [13; 14]. Результаты в этом направлении исследований отражены в работах [15–18].
Очевидно, что при рассматриваемых классах преобразований крайне важным является то, насколько быстро сходятся вычислительные процессы и как быстро снижаются ошибки приближений. Эти вопросы рассматриваются в работах [19–22].
Первоначально задача вычисления энтропии длинных кодов с зависимыми разрядами рассматривалась как некоторая достаточно быстрая и эффективная процедура тестирования. Однако в 2009 г. с привлечением рассматриваемых в данной статье процедур была итерационно решена обратная задача нейросетевой биометрии. Через быстрое вычисление энтропии удалось извлечь знания из нейросети. Это послужило началом работ, улучшающих процедуры вычисления энтропии в контексте решения обратных задач нейросетевой биометрии [23–26].
-
7 Качалин С. В., Иванов А. И. Заполнение пробелов биометрических данных генетическим алгоритмом размножения реальных примеров образа «Свой» без использования «мутаций» // Компьютерные науки и информационные технологии: материалы Международной науч. конф. (30 июня–03 июля 2014 г.). Саратов: Изд-во «Наука», 2014. С. 154–157.
-
8 Туреев С. В., Малыгина Е. А., Солопов А. И. Методика формирования тестовых баз для проверки качества обучения нейросетевых преобразователей биометрия-код // Сборник научных статей по материалам I Всероссийской науч.-техн. конф. «Безопасность информационных технологий» (24 апреля 2019 г.). Пенза, 2019. С. 90–101.
-
9 Свидетельство о государственной регистрации программы для ЭВМ № 2019662112 «Саморазвивающийся эмбрион-архив тестовой базы биометрических образов «чужой» / А. В. Безяев [и др.]. Дата государственной регистрации: 17.09.2019.
Результаты исследования
Одной из проблем нейросетевой биометрии является необходимость использования малогабаритной физически и криптографически защищенной доверенной вычислительной среды [27]. Как правило, доверенную вычислительную среду приходится создавать с использованием малопотребляющих, низкоразрядных микроконтроллеров при ограниченном объеме памяти. Система биометрико-криптографической защиты оказывается надежной, только если все криптографические операции над данными и нейросетевые операции будут выполняться внутри доверенной малогабаритной вычислительной среды.
Последнее означает, что на малопотребляющих, низкоразрядных процессорах нужно уметь точно вычислять интегралы вероятности (4). Вычислить подобный интеграл на компьютерах с 32- или 64-разрядной арифметикой несложно. При вычислении интеграла (4) на 4-, 8-разрядном микроконтроллере без привлечения специализированных программ (MathCAD, MatLAB, Maple и т. д.) возникают проблемы из-за низкой разрядности двоичных чисел и отсутствия поддержки повышения точности (разрядности) вычислений, обычно применяемой в типовом программном обеспечении математических пакетов.
Проведенные исследования показали, что если при 32-разрядных вычислениях зафиксировать стандартное отклонение расстояний Хэмминга σ( h ) и изменять только математическое ожидание расстояний Хэмминга E ( h ), то мы получим почти линейную связь с оцениваемой энтропией (рис. 1).
При использовании малоразрядных процессоров экономически выгодно применять таблицы преобразований
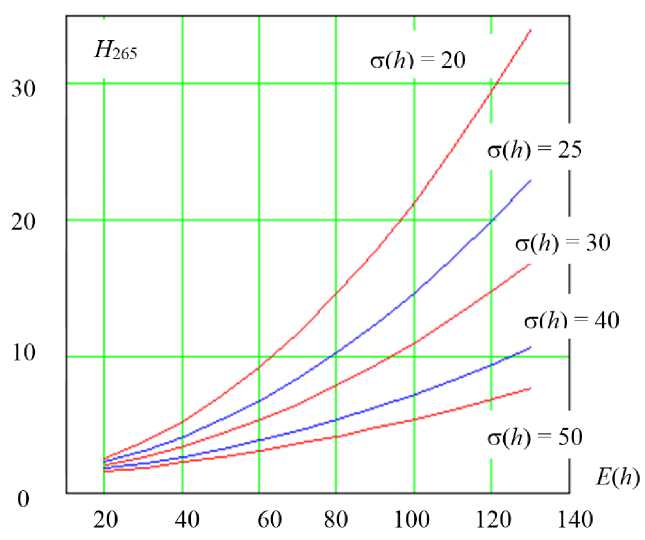
Р и с. 1. Почти линейная связь энтропии с математическим ожиданием расстояний Хэмминга при фиксированном стандартном отклонении
F i g. 1. Almost linear relationship between entropy and mathematical expectation of Humming distances at fixed standard deviation
с шагом записи данных 20 + 10 · i , где строчный индекс i меняется от 0 до 13 для математического ожидания расстояний Хэмминга E ( h ). Таблицы должны быть двухмерными, например, иметь 30 столбцов для значений стандартного отклонения σ( h ), изменяющегося на единицу. В ячейках двухмерной таблицы должны лежать значения энтропии номограммы, отображенной на рисунке 1.
Еще одним важным моментом является использование таблиц поправок значений энтропии DH 256, которые компенсируют ошибку от проявления асимметрии закона распределения расстояний Хэмминга p ( h ).
Из рисунка 2 видно, что при значениях математического ожидания E ( h )=12,8, E ( h )=25,6 распределение расстояний Хэмминга становится существенно асимметричным [28; 29]. Это означает, что номограмма данных рисунка 1
при малых значениях математических ожиданий нуждается в значительных поправках DH 256. Вычисление поправок выполняется путем нормирования расстояний Хэмминга, приводящего все возможные состояния к интервалу от 0 до 1. В итоге получается 8-разрядная двоичная таблица преобразований. Далее под заданное значение асимметрии подбираются два параметра бета-распределения. Уже в пространстве бета-распределений по формуле, аналогичной формуле (4), находится вероятность ошибок второго рода на 32-разрядной вычислительной машине:
P = f 1----
2 J o B ( в 1, в 2)
■ h i e 1 - 1 ■ (1 - h) e 2 - 1 ■ dh , (8)
где β 1, β 2 – параметры бета-распределения, обеспечивающие нуж-
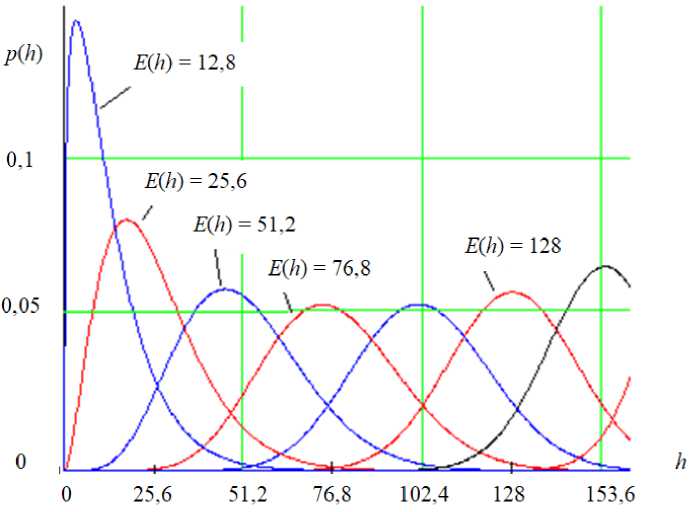
Р и с. 2. Распределение расстояний Хэмминга для одинаково коррелированных данных r = 0,33 и монотонно изменяющихся значений математического ожидания
F i g. 2. Distribution of Humming distances for equally correlated data r = 0.33 and monotonically changing values of mathematical expectation
ный показатель асимметрии полученного распределения Хэмминга;
B ( в 1, р 2) = J x в 1 - 1 • (1 - x ) в 2 - 1 • dx — бета 0
функция; h i = h /256 - нормированное расстояние Хэмминга.
Это и позволяет в конечном итоге синтезировать вторую таблицу поправок DH 256 для малых значений математического ожидания для E ( h ) < 70 бит.
Обсуждение и заключение
Таким образом, использование стан-дартизованых в России нейросетевых преобразователей биометрии в длинный код позволяет снизить вычислительную сложность оценки энтропии с экспоненциальной вычислительной сложности до линейной и одновременно экспоненциально снизить объем памяти, необходимой для хранения тестовых образов «Чужой». Кроме того, в новых условиях перехода в пространство расстояний Хэмминга удается сделать вычисление интегралов вероятности табличным (4), (8) (используются две таблицы размерами 12х30 и 7х30, которые хранят 8-битные значения энтропии и ее поправок).
Следует отметить, что биометрические приложения являются одними из самых глубокопроработанных и стандартизованных приложений искусственного интеллекта. Формально это обусловлено тем, что международный технический комитет по стандартизации ISO/IEC JTC 1/SC 37 (Биометрия) создан в 2002 г., а технический комитет ISO/IEC JTC 1/SC 42 (Искусственный интеллект) создан только в 2017 г. По этой причине международных стандартов по биометрии на текущий момент разработано и находится в разработке 160, тогда как стандартов по искусственному интеллекту разработано и находится в разработке только 11.
Все, что изложено в данной статье, проверено только на биометрических данных, однако авторы уверены в том, что нейросетевое распознавание биометрических образов является частным случаем распознавания образов произвольной природы нейросетевым искусственным интеллектом. При этом перенос достигнутого уровня тестирований и доверия биометрических приложений корректен только в том случае, когда применяются «широкие» нейронные сети, стандартизованные пакетом отечественных стандартов с номерами ГОСТов Р 52633. хх-20хх. Нейронные сети других классов, в том числе сверточные нейронные сети «глубокого» обучения, тестировать с применением быстрых алгоритмов вычисления энтропии нельзя10. Как следствие, доверие к ним должно быть значительно ниже, чем доверие к отечественным стандартизованным нейросетевым конструкциям.
Поступила 15.01.2020; принята к публикации 20.02.2020; опубликована онлайн 30.06.2020
Об авторах:
Все авторы прочитали и одобрили окончательный вариант рукописи.
Список литературы Быстрая оценка энтропии длинных кодов с зависимыми разрядами на микроконтроллерах с малым потреблением и низкой разрядностью (обзор литературы по снижению размерности задачи)
- Juels, A. A Fuzzy Commitment Scheme / A. Juels, M. Wattenberg. - DOI 10.1145/319709.319714 // CCS'99: Proceedings of the 6th ACM Conference on Computer and Communications Security. - 1999. -Pp. 28-36. - URL: https://dl.acm.org/doi/10.1145/319709.319714 (дата обращения: 29.04.2020).
- Ramirez-Ruiz, J. A. Cryptographic Keys Generation Using Finger Codes / J. A. Ramirez-Ruiz, C. F. Pfeiffer, J. Nolazco-Flores. - DOI 10.1007/11874850_22 // Advances in Artificial Intelligence - IB-ERAMIA-SBIA. - 2006. - Pp. 178-187. - URL: https://link.springer.com/chapter/10.1007/11874850_22 (дата обращения: 29.04.2020). 10 Гудфеллоу Я., Бенджио И., Курвиль А. Глубокое обучение. М.: ДМК Пресс, 2017. 652 с. Computer science, computer engineering and management 307
- Ушмаев, О. В. Алгоритмы защищенной верификации на основе бинарного представления топологии отпечатка пальцев / О. В. Ушмаев, В. В. Кузнецов // Информатика и ее применения. -2012. - Т. 6, № 1. - С. 132-140. - URL: http://www.ipiran.ru/journal/issues/2012_01_eng/ (дата обращения: 29.04.2020). - Рез. англ.
- Иванов, А. И. Протоколы биометрико-криптографического рукопожатия: защита распределенного искусственного интеллекта интернет-вещей нейросетевыми методами / A. И. Иванов, П. А. Чернов / Системы безопасности. - 2018. - № 6. - С. 50-59. - URL: http:// cs.groteck.ru/SS_6_2018/index.html?pn=&pageNumber= (дата обращения: 29.04.2020).
- Ivanov, A. Statistical Description of Output States of the Neural Network "Biometrics-code" Transformers / A. Ivanov, B. Akhmetov, V. Funtikov [et al.] // Progress in Electromagnetics Research Symposium : PIERS Proceedings. - Moscow, 2012. - Pp. 62-65. - URL: https://piers.org/pierspublica-tions/PIERS2012MoscowFinalProgram.pdf (дата обращения: 29.04.2020).
- Ахметов, Б. С. Дополнение нечетких биометрических данных морфинг-размножением примеров родителей в нескольких поколениях примеров потомков / Б. С. Ахметов, С. В. Качалин, А. И. Иванов // Вестник КазНТУ. - 2014. - № 4 (104). - С. 194-199. - URL: https://official.satbayev.university/ download/document/7138/ВЕСТНИК-2014 №4.pdf (дата обращения: 29.04.2020). - Рез. англ.
- Малыгин, А. Ю. Требования к синтетическим базам биометрических образов и генераторам для их формирования / А. Ю. Малыгин, В. В. Федулаев, Д. Н. Надеев [и др.] // Нейрокомпьютеры: разработка, применение. - 2007. - № 12. - С. 60-64. - URL: http://www.radiotec.ru/article/3747 (дата обращения: 29.04.2020). - Рез. англ.
- Akhmetov, B. Morph-Reproduction Examples of Parents in Several Generations of Examples Descen / B. Akhmetov, A. Ivanov, A. Malyghin [et al.] // International Conference on Global Trends in Academic Research. - Lumpur, 2014. - Pp. 188-190. - URL: https://globalilluminators.org/conferences/ icmrp-2014-kuala-lumpur-malaysia/icmrp-full-paper-proceeding-2014/ (дата обращения: 29.04.2020).
- Волчихин, В. И. Регуляризация вычисления энтропии выходных состояний нейросетевого преобразователя биометрия-код, построенная на размножении малой выборки исходных данных / B. И. Волчихин, А. И. Иванов, А. Г. Банных. - DOI 10.21685/2072-3059-2017-4-2 // Известия высших учебных заведений. Поволжский регион. Технические науки. - 2017. - № 4. - С. 14-23. - URL: https://izvuz_tn.pnzgu.ru/tn2417 (дата обращения: 29.04.2020).
- Akhmetov, B. Solving the Inverse Task of Neural Network Biometrics without Mutations and Jenkins "Nightmare" in the Implementation of Genetic Algorithms / B. Akhmetov, S. Kachalin, A. Ivanov [et al.] // International Conference "Computational and Informational Technologies in Science, Engineering and Education". - 2015. - URL: http://conf.ict.nsc.ru/citech-2015/en/reportview/261166 (дата обращения: 29.04.2020).
- Качалин, С. В. Алгоритм генетического обращения матриц нейросетевых функционалов без дефектов «кошмара» Дженкина / С. В. Качалин // Евразийский Союз Ученых. - 2015. - № 4 (13). - C. 59-62. - URL: https://euroasia-science.ru/tehnicheskie-nauki/алгоритм-генетического-обращения-ма/ (дата обращения: 29.04.2020).
- Качалин, С. В. Направленное морфинг-размножение биометрических образов, исключающее эффект вырождения их популяции / С. В. Качалин, А. И. Иванов // Вопросы радиоэлектроники. - 2015. - № 1. - С. 76-85.
- Надеев, Д. Н. Связь энтропии выходных состояний нейросетевых преобразователей биометрия-код с коэффициентами парной корреляции / Д. Н. Надеев, В. А. Фунтиков, А. И. Иванов // Нейрокомпьютеры: разработка, применение. - 2012. - № 3. - С. 74-77. - URL: http://www.radiotec.ru/ article/10426 (дата обращения: 29.04.2020). - Рез. англ.
- Ахметов, Б. С. Моделирование длинных биометрических кодов, воспроизводящих корреляционные связи выходных данных нейросетевого преобразователя / Б. С. Ахметов, В. И. Волчи-хин, С. В. Куликов [и др.] // Нейрокомпьютеры: разработка, применение. - 2012. - № 3. - С. 40-43. -URL: http://www.radiotec.ru/article/10418 (дата обращения: 29.04.2020). - Рез. англ.
- Bezyaev, V. On the Issue of Modeling Long Biometric Codes with Dependent Bit States / V. Bezyaev, I. Serikov, A. Kruchinin [et al.] // Progress in Electromagnetics Research Symposium : PIERS Proceedings. - Moscow, 2012. - Pp. 62-65. - URL: https://piers.org/pierspublications/ PIERS2012MoscowAbstracts.pdf (дата обращения: 29.04.2020).
- Ivanov, A. I. Reducing the Size of a Sample Sufficient for Learning Due to the Symmetrization of Correlation Relationships Between Biometric Data / A. I. Ivanov, P. S. Lozhnikov, Yu. I. Serikova. - DOI 10.1007/s10559-016-9838-x // Cybernetics and Systems Analysis. - 2016. - Issue 52. - Pp. 379-385. -URL: https://link.springer.com/article/10.1007%2Fs10559-016-9838-x (дата обращения: 29.04.2020).
- Волчихин, В. И. Быстрый алгоритм симметризации корреляционных связей биометрических данных высокой размерности / В. И. Волчихин, Б. Б. Ахметов, А. И. Иванов // Известия высших учебных заведений. Поволжский регион. Технические науки. - 2016. - № 1. - С. 3-7. - URL: https://izvuz_tn.pnzgu.ru/tn1116 (дата обращения: 29.04.2020).
- Ivanov, A. I. Simplification of Statistical Description of Quantum Entanglement of Multidimensional Biometric Data Using Simmetrization of Paired Correlation Matrices / A. I. Ivanov, A. V. Bezy-aev, A. I. Gazin // Journal of Computational and Engineering Mathematics. - 2017. - Vol. 4, Issue 2. -Pp. 3-13. - URL: https://jcem.susu.ru/jcem/article/view/110 (дата обращения: 29.04.2020).
- Качалин, С. В. Оценка устойчивости алгоритмов обучения больших искусственных нейронных сетей биометрических приложений / С. В. Качалин // Вестник СибГАУ - 2014. - № 3 (55). -С. 68-72. - URL: https://vestnik.sibsau.ru/vestnik/897/ (дата обращения: 29.04.2020). - Рез. англ.
- Иванов, А. И. Номограммы оценки погрешности, коэффициентов корреляции, вычисленных на малых выборках биометрических данных / А. И. Иванов, Ю. И. Серикова // Вопросы радиоэлектроники. - 2015. - № 12. - С. 123-130.
- Волчихин, В. И. Компенсация методических погрешностей вычисления стандартных отклонений и коэффициентов корреляции, возникающих из-за малого объема выборок / В. И. Волчи-хин, А. И. Иванов, Ю. И. Серикова // Известия высших учебных заведений. Поволжский регион. Технические науки. - 2016. - № 1. - С. 45-49. - URL: https://izvuz_tn.pnzgu.ru/tn9116 (дата обращения: 29.04.2020).
- Иванов, А. И. Корректировка методической погрешности вычисления статистических моментов четвертого порядка для малых выборок биометрических данных / А. И. Иванов, Ю. И. Серикова, А. Г. Банных // Модели, системы, сети в экономике, технике, природе и обществе. - 2016. -№ 4 (20). - С. 108-114. - URL: https://mss.pnzgu.ru/mss416 (дата обращения: 29.04.2020).
- Akhmetov, B. Evaluation of Multidimensional Entropy on Short Strings of Biometric Codes with Dependent Bits / B. Akhmetov, A. Ivanov, V. Funtikov // Progress in Electromagnetics Research Symposium : PIERS Proceedings. - Moscow, 2012. - Pp. 66-69. - URL: https://piers.org/pierspublications/ PIERS2012MoscowFinalProgram.pdf (дата обращения: 29.04.2020).
- Иванов, А. И. Биометрическая аутентификация личности: обращение матриц нейросете-вых функционалов в пространстве метрики Хемминга / А. И. Иванов, Е. А. Малыгина // Вопросы защиты информации. - 2015. - № 1. - С. 23-29. - URL: http://izdat.ntckompas.ru/editions/magazine_ news/detail.php?ELEMENT_ID=20164&SECTI0N_ID=155&ID=184 (дата обращения: 29.04.2020).
- Волчихин, В. И. Оценка эффекта ускорения вычислений, обусловленного поддержкой квантовой суперпозиции при корректировке выходных состояний нейросетевого преобразователя биометрии в код / В. И. Волчихин, А. И. Иванов, А. В. Безяев [и др.]. - DOI 10.21685/2072-30592017-1-4 // Известия высших учебных заведений. Поволжский регион. Технические науки. - 2017. -№ 1. - С. 43-55. - URL: https://izvuz_tn.pnzgu.ru/tn4117 (дата обращения: 29.04.2020).
- Волчихин, В. И. Нейросетевая молекула: решение обратной задачи биометрии через программную поддержку квантовой суперпозиции на выходах сети искусственных нейронов / B. И. Волчихин, А. И. Иванов. - DOI 10.15507/0236-2910.027.201704.518-529 // Вестник Мордовского университета. - 2017. - Т. 27, № 4. - С. 518-529. - URL: http://vestnik.mrsu.ru/index.php/en/articles2-en/56-17-4/358-10-15507-0236-2910-027-201704-04 (дата обращения: 29.04.2020). - Рез. англ.
- Гулов, В. П. Перспектива нейросетевой защиты облачных сервисов через биометрическое обезличивание персональной информации на примере медицинских электронных историй болезни (краткий обзор литературы) / В. П. Гулов, А. И. Иванов, Ю. К. Язов [и др.]. - DOI 10.12737/ article_5947d5509f0411.58967456 // Вестник новых медицинских технологий. - 2017. - Т. 24, № 2. - C. 220-225. - URL: https://naukaru.ru/en/nauka/article/17188/view (дата обращения: 29.04.2020). -Рез. англ.
- Иванов, А. И. Оценка вероятности ошибок биометрической аутентификации на малых выборках, использующая гипотезу бета-распределения расстояний Хэмминга / А. И. Иванов, А. В. Бе-зяев, А. В. Елфимов [и др.] // Специальная техника. - 2017. - № 1. - С. 48-51.
- Ivanov, A. I. A Simple Nomogram for Fast Computing the Code Entropy for 256-Bit Codes That Artificial Neural Networks Output / A. I. Ivanov, P. S. Lozhnikov, A. G. Bannykh // Journal of Physics: Conference Series. - 2019. - Vol. 1260, Issue 2. - URL: https://iopscience.iop.org/ar-ticle/10.1088/1742-6596/1260/2/022003/meta (дата обращения: 29.04.2020).
