Common-Sense Word Semantics using Dictionary Based Approach – An Early Model for Semantic Knowledge Processing

Автор: Rashmi S, Hanumanthappa M
Журнал: International Journal of Information Engineering and Electronic Business(IJIEEB) @ijieeb
Статья в выпуске: 1 vol.9, 2017 года.
Бесплатный доступ
Knowledge processing is the prime area of information retrieval in the current era. However knowledge is subjected to the meaning of discretion in any natural language. Intelligent search in various Natural Languages is required in the huge repository of information available online. Language is the integral part for any form of communication but the language has to be meaningful. Semantics is a field of linguistics that deals with the meaning of the linguistic expressions through discovery of knowledge. In this research paper, the dictionary based approach for semantics is studied and implemented. The dictionary based proposal relies on the formalization of sentence across SVO (Subject-Verb-Object) format. Rule-based classifier helps to define the rules that are checked against the dictionary which contains sequence of Subject, Verbs and Object available in English Language. By looking at the accuracy measures, recall and precision the results obtained by the proposed approach is proven good.
Common – Sense Word Semantics, Natural Language, Pragmatics, Predicate Logic, Rule-based classifier, Semantics model, Subject-Verb-Object format
Короткий адрес: https://sciup.org/15013493
IDR: 15013493
Текст научной статьи Common-Sense Word Semantics using Dictionary Based Approach – An Early Model for Semantic Knowledge Processing
Published Online January 2017 in MECS
Novelty of any search is relied upon the meaning of the content retrieved. Though there are many search engines each efficient enough to retrieve the information as accurate as possible but none make an effort in verifying that if this search has any sense. Sense is nothing but any composed meaning in the Natural Language (NL). Searching for meaning in text corpora is difficult as there are various language constraints and complexities. This is mixed with the ambiguities in language model. As worst as it gets, the meaning is associated with the human cognitive phenomena. Sometimes a sentence such as “I want to sea a movie tomorrow” can be easily surpassed in any search engines and never be identified as an incorrect sentence. The field of study of meaning is called
Semantics. Meaning is associated with expressions and word-connections. The consortium of meaning is achieved through various steps in linguistics as shown in figure [1]. The key focus of study in this research paper is on semantics and the process of meaning evaluation. However meaning cannot be directly tested hence the given input has to go through a series of linguistic examinations to ensure that the given sentence comply with the rule of a good syntactic structure.
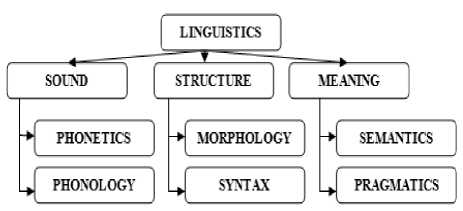
Fig.1. The language model in linguistics showing the classification of sound, structure and meaning
Language primarily indicates written words and consequently little recognition is given for the spoken form of the language. In linguistics, speech perhaps is treated as an integral part since it is composed with intricate abilities such as; first, human always learn to speak first rather than writing. Second, the usage of spoken form of the language takes place without any formal structure. Third, what we speak makes lot of sense and must possess some knowledge. Fourth, Speech is elucidated with expressions and emotions. This includes lot of variations and voice modulation. A lot many such observations, techniques and investigations are made in the field of linguistics called phonetics. Phonology on the other hand evaluates the representation and processing of speech sounds for any given natural language. Once the sound waves are converted into written text, the format of the textual structure is studied by morphology and syntactic composition of natural language processing. This evaluates the data for the correctness and integrity in the structure. This includes stemming, POS tagging, grammar structure and so on. Once the input text is error free from syntactic mistakes, next the sentence will be evaluated for the knowledge representation. This stage of processing majorly concentrates on the meaning representation.
To address the problem of semantic knowledge representation whilst common-sense word semantics, our research work is divided into following phases:
Phase 1: Training Phase: In this phase, a dictionary of fruits, vegetables, things and verb forms are constructed
Phase 2: Make a hypothesis: Since knowledge evaluation is obtained through a process of syntactic examination, in this phase we make an assumption that the given input sentence is syntactically correct i.e. free from grammatical mistakes, spell or typo errors and various other kinds of syntactic errors.
Phase 3: Construct a rule: In this phase, the rules for the semantically correct sentences are defined. Through this, the given input is tested for the correctness. The syntactically correct sentences are checked against the rules defined to verify if the input sentence is semantically correct.
-
II. Related Works
A variety of projects have designed and implemented multimedia retrieval systems. T Semantics has its roots way back to decades but the research studies in this field took its inception only a decade ago. The perspective of semantics changed ever since then. Semantics which indicates meaning has started to talk about knowledge, ontology and knowledge, pragmatics, latent semantics and so on. The meaning/knowledge is a prime area of concentration in semantics, a branch of linguistics. However semantics has many definitions as stated by various authors. This is discussed in the table [1].
Table 1. Definition of Semantics as stated by various researchers and authors
Using this approach the efficiency and accuracy of information retrieval was improvised in both structured and semi-structured documents. The ranking evaluator is used to measure the resemblance of the documents related to semantics. Yuri Gurevich et al [3] have worked on semantic-to-syntax concept by defining a species of algorithms that leads to the creation of semantics and its characteristics. To add to this the authors have also worked on the computational time. Various Boolean functions are made use for this purpose. Ontology based semantic information retrieval was done by Yinghui Huang et al [4]. They introduced a rough ontology starting off with the advantages of semantic information retrieval. In the second phase, rough ontology was used to expand the ontology and thirdly semantic information retrieval model was suggested named as ROSRS. Semantics creates a sense in the language. However there are many unanswered, unquestioned concepts related to semantics that is still a challenge, perhaps the more crucial ones. Those are:
-
• How can we specify the meaning of “however” or “and”?
-
• There are numerous sentences whose meaning cannot be defined on the basis of the meaning of the words. Example: “Time is money” or “it is raining cats and dogs”. These sentences represent metaphor. So meaning of these sentences cannot be derived merely from the word meaning.
-
• Meaning sometimes is represented in the form of gestures and facial expressions.
-
• How is the integrity of the meaning measured?
-
• Do we have language representation for all the meaning? Or are there any meanings which cannot be expressed at all?
-
• Do semantics see all the facet of meaning? i.e., from speaker point of view, hearer point of view, or a part of pragmatics?
Therefore the challenges and problems in the field of semantics are endless. This enforces many researchers to concentrate on semantics and to evaluate the meaning of “meaning” in semantics in any given language model. In this research paper, we study the semantics and its implementation in real world and also the accuracy achieved by our proposed system.
From table [1] it is clear that there is no perfect definition for semantics that is universally accepted. Nevertheless, semantics portrays meaning, as the presence of the word “meaning” is evident in all the
-
III. Architecture of the Proposed System – Semantic Model using the Dictionary Based Approach
Linguistic theory concentrates on relating the linguistic code and the meaning in the real world representation. Undoubtedly, the task is difficult as the natural world is filled with many ambiguities. This compensates to the more challenging aspects of semantics, making it more elusive, unpredictable yet center for communication especially in linguistics. The next big question is how actually the meaning should be communicated to the physical world? Is it through symbols (Semiotics)? Expressions? Language? Or something more complicated? Unfortunately, the answer to these questions is “yes”. Meaning can be indicated in many of the ways, more innovative and more explorative. Semantics deals with both the word meaning and sentence meaning. For instance, “you cooked the fist very well ”. In this sentence, the word meaning is associated with each word such as cook, fish, very, well . The sentence meaning indicates the composition of all the words and the intrinsic meaning like, cook+fish, cook+fish+very+well . Many times, even though there is a perfect connotation for every word in the word meaning of the sentence, the overall sentence meaning might not have any sense such as “fish cooked you well very”. This sentence contains exactly the same words as in the previous sentence however the arrangement of word meaning is disturbed which in turn affects the sentence meaning. This kind of problem is called Common-Sense Word semantic [5] problem. The problem of this type is addressed in this research paper. We have analyzed semantics from productive and composite point of view. In figure [2], we discuss how overall language model can be constructed by considering the three factors as shown in figure [1]. The figure [2] talks about the actual architecture of the semantics implementation (main topic of interest of this research work).
-
IV. Architecture of the Proposed System – Semantic Model Using the Dictionary Based Approach
In semantics, it is necessary to understand that the philosophical images of brain have to be drawn against the given input sentence. In reality, semantics requires lot of pre-requisites such as word meaning, sensory data, reference set and concrete meaning of the sentence [6]. The computational and compositional hypotheses considered for the semantic evaluation are indicated below:
-
• When a relation A is true, then the relation B has to be necessarily true forecasting an AND relation. Consider examples 1 and 2 highlighting this theory.
-
1) “Alice likes music and dance” – True for both A and B relation
-
2) “Alice likes music and not dance” – Relation A is true and B is false
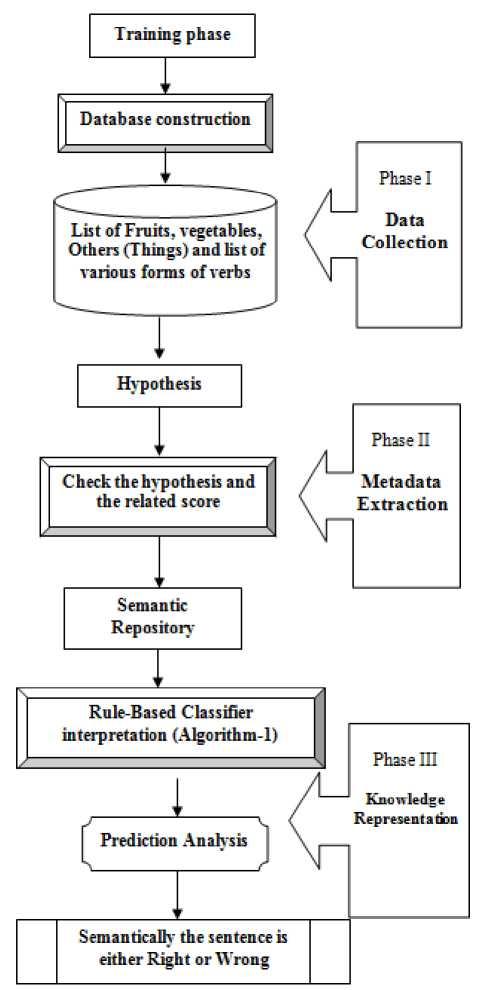
Fig.2. Architecture of the proposed system showcasing the creation of common sense word semantics in real world scenarios
-
• The truthfulness of relation A being true or false is purely dependent on assumption that B is true. For example: “Alice has quit alcohol” – This indicates that Alice has been drinking (B is assumed to be true)
-
• The truthfulness of any relation A and B is dependent on the degree on common sense knowledge as mirrored in the real world. For example: “Rat chased cat” – In reality, this is not true.
The theory of common sense knowledge is dependent on the existence of living and non-living things in the world and the relation between them. For example: “Table killed Alice” – In reality, the non-living thing (Table) cannot perform an action (Kill).
In order to address the common-sense word semantics, we have adopted the dictionary based approach. A dictionary containing three prime elements, fruits, vegetables and things is constructed. English language adhere the Subject, Verb and Object form (SVO form) [7]. Therefore in addition to the dictionary, a list of all the verbs and its forms is prepared in another table. As shown in figure [2], in the training phase the word-set dictionary and the verb list are built. The input sentence from the user is verified for any syntactic mistakes. Once the sentence is free from all types of syntactic errors, it is dispatched to the semantic evaluation phase. In this stage, the sentence is checked if it complies with the rule predefined. If so, the sentence is declared as semantically correct otherwise it will be treated as semantically bad sentence. The procedure of the implementation is discussed in the algorithm 1. The important requirement for the algorithm to work efficiently is to input the grammatically correct sentence. If the user inputs the syntactically wrong sentence then the efficiency of the proposed algorithm may not be debated. Hence one has to ensure that the sentence is free from various types of syntactic mistakes and can pose only the semantic discrepancies.
Example sentence showing the implementation of the proposed system
Example 1: “Apple ate Ramsey”
The above sentence surpasses from the metadata extraction module as it does not contain any syntactic errors. For the semantics, we begin the scan word-byword and it is compared with the list of fruits/vegetables/ things and verb list. Every time the sentence is checked for SVO rule constraint.
Rule is violated because the content of verb is preceded by the content of fruit. Therefore no further scanning of the sentence is required and hence the sentence is declared as semantically incorrect.
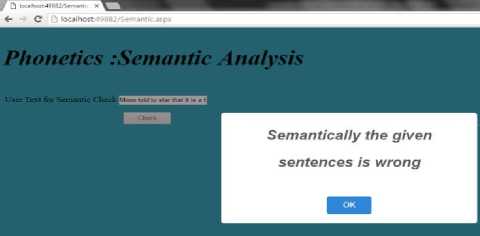
Example 2: “It is a beautiful day”, Moon told to star.
Once again the rule is violated. Hence the given sentence is semantically incorrect
Example 3: “I walked past the street very quickly”
No rule violated. Hence this sentence is semantically correct.
Examples:
Rule 1: Adam (factor) borrowed the money (Action) from Kinsley (Receiver)
Rule 2: Mary (participator) saw the eclipse (action) with a sunglass (instrument)
A lg orithm _1
-
< input _ the _ given _ sentence >
-
< Scan the input sentence
-
< Rule - defined >
-
• Fruit, vegetables _& _ things _
are _ considered _ as _ table [1]
-
• verb _ list _ is _ said _ to _ be _ table [2]
-
< if _ the _ content _ from _ table [1] _ preceed _
the_content_of _table[2] _then, the sentence is semantically incorrect > otherwise
-
< Semantically _ correct >
RULES _ OF _ THE _ PROPOSED
_ ALGORITHM ( Abbreviations )
Factor ( Instigator _ of _ the _ action )
Action ( Verb _ kind )
о Re ciever (Re cipient _ of _ the - action )
Objective ( Purpose / endpo int_ of _ the _ action )
Originator ( Source _ po int_ of _ the _ action )
Instrument ( Mechanism _ to _ achieve _ the _ goal )
Participator(Receiver_of _ tactile / auditory_inf ormation)
< Rule -1 >< Factor >< Action >< Re cipient >< Rule - 2 >< Participator >< Action >< Instrument >< Rule - 3 >< Factor >< Originator >< Objective >
-
4.1 Semantics and Predicate Logic
The meaning of the language expressions can be expressed in terms of predicate logic [8]. However once must note that the predicate logic is irrelevant for lexical semantics – meaning of atomic words – although some connection can be drawn based on unary predicate or binary predicate under first order predicate logic [9]. Consider an example sentence, “ Apple (S) ate (V) Ramsey (O) ” This sentence portrays SVO format. Therefore the first order predicate logic for the above sentence is,
V( s) aV( v) aV( o) (1)
Equation [1] symbolizes that all the subject s , verb v and object o has to be in the same order as indicated.
∀ ( x ) γ ∀ ( y ) - > Incorrect _ sentence (2)
Here x represents the list of fruits, vegetables and things/others , y indicates the verb list and γ tells the fact of following immediately. Equation [2] represents that fruits, vegetables and things/others should not be followed immediately by verbs. If it does, then the sentence is semantically incorrect.
∃ ( x ) ω ∀ ( y ) - > Correct _ sentence (3)
In equation (c), ω is the list of primary verb as shown in glossary [1]. The rule represents that for some x if followed by words in list and then followed immediately by verb list then the sentence is correct. Consider the example, “ Stone ∃ ( x ) was ω eaten ∀ ( y ) by Ramsey ”, therefore the sentence is semantically correct. However observe the next example sentence, “ Stone ∃ ( x ) had been ω to New York” , here ∀ ( y ) is not found. Hence the sentence is declared as semantically incorrect.
The occurrences of word-pair in a given sentence can be explained as discussed here. Let S be the input sentence which is composed of series of word-pair say W1, W2 ... Wn. For each Wi is assumed to appear independently however for the problem under consideration the meaning of any Wi is correlated and dependent on the neighbour word-pair W j . this is composed of exhaustive enumeration of word pairs to derive the meaning of the entire sentence S. with the rule defined in our approach the interpretation of word series W s consisting of W i ,…… W k … W l can be defined as following,
l
∑ W = W γ ≠ W η , W ≥ 2
S=i where∀γ ∈ fruits / Vegetables / Things / Others, (4)
∀ η ∈ verb _ list
W ≥ 2 in equation [4] implies that the sentence S must contain at least 2 word-pair ( W → W , W ) to be processed using the proposed methodologies
Therefore W enumerations direct to the induction of binomial coefficients as given by,
W i = n W j = n Wz = n
∑ ( ∑ (... ∑ W γ ≠ W η ))) (5)
posW = 1 posWj = W + 1 posWz = Wy + 1
Equation [5] indicates that the sentence S starting from word Wi in the position 1 ranging till position n followed by next word Wj where the position is again incremented by 1 to n, so on and so forth continuing till the last word Wz the rule Wγ≠ Wηhas to be satisfied. This says that the fruits/ vegetables/ things/ others should not be immediately followed by verb. The main aim of this section was to provide the proposed architecture in terms of quantified formulae that will summarize the subject domain and its attributes in a more argument position [9].
The syntactic rules defined in our architecture stipulate a course to assign semantic values as interpreted in language expressions. The sentences with the arbitrary values are combined using these stated rules. Henceforth the integrity of the system majorly depends on the "truthful conditional evaluation" [10] The variables considered here are the database dictionaries as shown in glossary 1. Accordingly these tables serves as universal quantifiers, thus not affecting the individual parameters. The scope of the algorithm is bound to the rules annotated hence it will always ensure a closed-bounded semantic [11] component. In the upcoming section, the results and discussions of our system are argued.
-
V. RESults and Discussions
The entailment of meaning evaluation is dependent on the concepts of real world knowledge representation. For instance: “Alice drove past the bank last evening”. In this sentence, the word “bank” could mean “financial institution” or “river bank”. Therefore semantics, in linguistics deals with meaning from the perspective of both ‘word’ and ‘sentence’. The ambiguity of word meaning can be eliminated through Word Sense Disambiguation (WSD), a field in linguistics. However in our research study, the concentration is on sentence meaning. The characterization of sentence meaning is studied by comprehending the common-sense knowledge theory. The contextual dependencies showed in our study focuses on boundary of understanding as seen by users or speakers direction. The flexibility achieved in our proposed system entails the fact that a naïve relationship can be built between the sensitivity and structural aspects of meaning representation. Our algorithm suggests that the meaning evaluation is an inherent part of knowledge representation and is part of learning process in every day’s life of a human. Figure [3] represents the various forms of ontology’s [12] with three different variations. The class hierarchies considered in our architecture concentrates on the reference correspondence functions [13]. The interpretation of these references indicates the necessary rules for a given sentence to be semantically correct. Various notations have been used to diagrammatically indicate the rules of the proposed system. If content from fruits/vegetables/things follows immediately by a verb then the sentence is semantically incorrect irrespective of what follows after this pattern. In the second scenario, if a fruit/vegetable/thing follows the primary verb such as is/was/has and others and then immediately followed by a verb then the sentence is semantically correct. As an instance, consider an example: “Apple was eaten by Ramsey”. However consider the sentence, “Apple was hungry”, here if the content from fruit/vegetable/thing follows a primary verb and then have something else in the sentence but not the verb then the sentence is still claimed as semantically wrong. This is shown in the third case in the above figure [3]. The same rules were tested in different variations throughout the time. The proposed architecture was implemented on .Net platform.
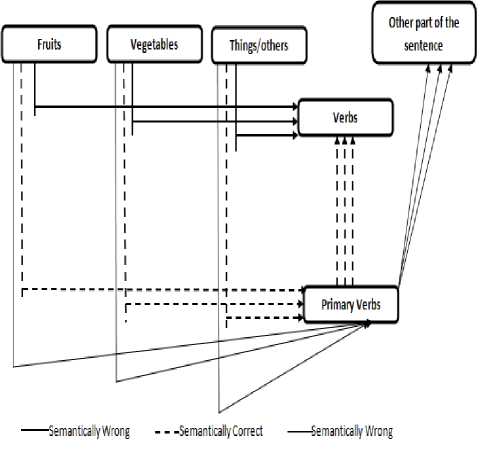
Fig.3. Variations of Rules defined in the proposed architecture
In order to implement the proposed system the key source of information for comparison was a dictionary. therefore a dictionary was built in excel sheet containing the list of fruits, vegetables, things and others and a separate list of verb and its variations consisting of both primary and other forms of verbs. The dictionary table word-set is shown in the glossary 1. Figure [4] shows the experimental set up of the architecture. Different variations of sentences were tested in the interface. The results were recorded precisely to test the accuracy in the later phases. In all the dimensions of the test, the hypotheses of the rules were kept alive and all sentences were tested against these rules. The structure of the sentences was modified each time the test was conducted. In general sentences all of the k-dimensions were taken into consideration to evaluate the toughness of the system.
The measure of accuracy is done using the recall and precision in information retrieval [14] [15]. These are rooted on the juxtaposition of what is expected and what is obtained from the system under evaluation. Since these measures are universally accepted as a commonplace to measure the efficiency, the same has been adopted for semantics as well. Recall calculates the ratio of precisely observed correspondences (true positives tp) over the total number of anticipated correspondences (true positives and true negatives tn). Recall always indicates the completeness measure. Precision calculates the ratio of observed correspondences (true positives) over the total number of yielded correspondence (true positives and false positives fp). Therefore the recall and precision is given by the following equations [6] and [7]
Recall = —tp— tp + tn
Pr ecision = —tp— (7)
tP + fP
Out of 1000 manually built sentences for testing purpose, 942 sentences were identified correctly as semantically correct and 47 of them were recognized as incorrect sentences. However 8 out of 1000 sentences were identified as correct for the semantically wrong sentences and 4 out of these 1000 sentences were obtained as incorrect for semantically correct sentences. Therefore when worked out on the recall and precision formulae as discussed in [6] and [7] on these numbers the proposed system on common sense semantics has 95.24% of recall and precision of 99.15%.
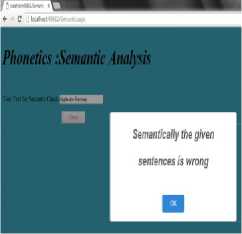
In figure [4], the output of the proposed system is shown. Various rules defined in the training phase were tested with this interface. The results were proven good. The sentences with true variance and false variance are tested across the semantically correct and incorrect sentences. It is also observed that the external criterion of appropriate measures satisfy the theoretical and practical aspects of semantics. The sentences in this figure are:
-
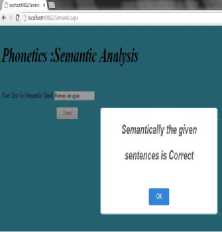
1) Apple ate Ramsey- Semantically wrong
-
2) Ramsey ate Apple- Semantically correct
-
3) Moon told star that it is a beautiful night-Semantically Wrong
Though our system gave an outstanding score on recall and measure, there are certain drawbacks in the existing approach. Those are,
-
• The system fail to identify the knowledge based sentences. For example, “Bachelor is a married man”, “Black is white” and other sentences of this kind.
-
• Word-to-word connections cannot be formulated
with the present approach as we concentrate only on the sentence meaning.
The main concentration addressed in this research paper is common – sense word semantics. However semantics is wide subject of interest hence the proposed method concentrates on semantics problem of only about 75%. There are still many variations in semantics that is yet to be explored. Semantics is more likely to be contra posted with pragmatics – a field in Natural Language Processing. The best of knowledge processing in any system is best when the concepts of semantics and pragmatics are associated thereby building a true intelligent structure.
-
VI. Conclusion
The Evaluation of Information Retrieval is often made on the basis of the meaning retrieved in the information. The meaning has to be well-perceived and well-understood. Therefore semantics is very important in any knowledge processing systems. There are various parameters to measure the semantics of a language however semantics should ensure that it recognizes some form of language and its intrinsic meaning.
In this paper, we provided the basic view of handling semantics through a process of meaning representation. The part of semantics concentrated here is called common-sense word semantics. The problem is addressed in terms of SVO format supported by English language. We designed the architecture on the basis of a hand-built dictionary of words containing the list of Fruits/ vegetables/ things/ others and a list of verb. Rule-based classifier helped us to define the rules based on our requirements. Finally the proposed architecture obtains good accuracy as sighted by recall and precision measures. However the results obtained using these measures are dependent on the type of the knowledge processing that is to be made; in this case it is commonsense word semantics. One main advantage of the proposed algorithm is that the potential meaning is represented through the contextual structure of the sentence. Furthermore, concentration will be paid on the drawbacks of the existing system and the future scope of this research work is to expand the view of semantics and connect the pragmatics and various others forms of semantics thereby modeling a robust knowledge processing system.
Список литературы Common-Sense Word Semantics using Dictionary Based Approach – An Early Model for Semantic Knowledge Processing
- Kruse, P.M., Naujoks, A., Roesner, D., Kunze, M.: Clever search: A wordnet based wrapper for internet search engines. In: Proceedings of the 2nd GermaNet Workshop. (2005)
- Jiang Huiping, "Information Retrieval and the semantic web" International Conference on Educational and Information Technology (ICEIT), 2010 DOI:10.1109/ICEIT.2010.5607549 Publisher:IEEE
- Yuri Gurevich, \Foundational Analyses of Computation", in How the World Com- putes (eds. S. Barry Cooper et al.), Turing Centennial Conference, Springer LNCS 7318 (2012)
- Yinghui Huang, "Rough Ontology Based Semantic Information Retrieval", Computational Intelligence and Design (ISCID), 2013 Sixth International Symposium on (Volume:1 )Date of Conference: 28-29 Oct. 2013 DOI:10.1109/ISCID.2013.23 Publisher:IEEE
- Wang Yong-gui, "Research on semantic Web mining", International Conference on Computer Design and Applications (ICCDA), 2010 (Volume:1) DOI: 10.1109/ICCDA.2010.5541057 Publisher: IEEE
- Semantics and Pragmatics 2 , University of Chicago, Winter 2011, Handout 1
- LIN1180 Semantics, Stavros Assimakopoulos by by Albert Gatt, Lecture Notes 2012
- Yongyang Xu, "Research on semantics of entity space similarity measure based on artificial neural networks" International Conference on Geoinformatics, 2015 DOI: 10.1109/GEOINFORMATICS.2015.7378707 Publisher: IEEE
- Yi Jin, The Research of Search Engine Based on Semantic Web", International Symposium on Intelligent Information Technology Application Workshops, 2008 DOI: 10.1109/IITA.Workshops.2008.193 Publisher: IEEE
- Masao Yokota, " Aware computing guided by Lmdexpression and direct knowledge in spatial language understanding", 2011 3rd International Conference on Awareness Science and Technology (iCAST), DOI: 10.1109/ICAwST.2011.6163164 Publisher: IEEE
- Guanghui Yang,Junkang Feng,"Database Semantic Interoperability based on Information Flow Theory and Formal Concept Analysis", IJITCS, vol.4, no.7, pp.33-42, 2012.
- Zahia Marouf, Sidi Mohamed Benslimane,"An Integrated Approach to Drive Ontological Structure from Folksonomie", IJITCS, vol.6, no.12, pp.35-45, 2014 DOI: 10.5815/ijitcs.2014.12.05
- Kavitha, A., Rajkumar, N., and Victor, S.P., An Integrated Approach for Measuring Semantic Similarity Between Words and Sentences Using Web Search Engine. The International Journal of Information Technology & Computer Science (IJITCS), 9(3), 68-78.2013
- Djuana, E., Xu, Y., Li, Y., Learning Personalized Tag Ontology from User Tagging Information. Conferences in Research and Practice in Information Technology (CRPIT), Australia, 2012.
- Radziah Mohamad, "Similarity algorithm for evaluating the coverage of domain ontology for semantic Web services", International conference on Software Engineering Conference (MySEC), 2014, DOI: 10.1109/MySec.2014.6986012 Publisher: IEEE
