Cтатическая оценка производительности посредством эмбеддингов промежуточных представлений LLVM

Автор: Заводских Р.К., Ефанов Н.Н., Томашев Д.Д.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 3 (55) т.14, 2022 года.
Бесплатный доступ
Рассматривается метод отображения программ в пространство векторов (эмбеддингов) для создания инструментария эмпирической оценки производительности программы на этапе компиляции без фактического исполнения. Предлагаемый метод основан на серии трансформаций исходного промежуточного представления (IR), таких как инструментирование искусственными инструкциями в компиляторном проходе, преобразование инструментированного IR в многомерный вектор с помощью технологии IR2Vec [1] с последующим понижением размерности по алгоритму t-SNE [2]. В качестве метрики производительности предлагается доля кэш-промахов первого уровня (D1 cache misses). Приводится эвристический критерий, по которому в двухмерном пространстве есть возможность отличить программы с большой долей промахов в кэше от программ с меньшей долей. Производится экспериментальная проверка критерия на синтетических тестах.
Математическое моделирование, компиляторы, промежуточные представления, эмбеддинги, анализ производительности, статический анализ
Короткий адрес: https://sciup.org/142236475
IDR: 142236475 | УДК: 004.051
Using the LLVM framework for static performanceprediction with embedding of intermediate representation
We consider a method for mapping programs to the space of vector embeddings to create of empirical estimation of programs’ performance at compilation time. This method is based on transformation series of the initial intermediate representation (IR) such as instrumentation with artificial instructions in a compiler’s pass, transformation of instrumented IR in a multidimensional vector with IR2Vec [1] and dimensionality reduction using t-SNE [2]. The D1 cache miss ratio is considered as performance metric. A heuristic separation criterion of programs with more or less cache miss ratio in 2D-space is given. The experimental validation of the criterion is performed in synthetic tests.
Текст научной статьи Cтатическая оценка производительности посредством эмбеддингов промежуточных представлений LLVM
Performance engineering1 - одно из актуальных направлений в разработке программного обеспечения. Эта актуальность обусловлена необходимостью поиска и устранения узких мест проектирования и реализации программных компонент, приводящих к низкой производительности всего исследуемого программного комплекса. На текущий момент наиболее широко используемой техникой анализа производительности является экспертная оценка результатов динамической профилировки приложений на ключевых сценариях использования [3]. Тем не менее такой подход не лишён практических недостатков, в первую очередь связанных с необходимостью фактического исполнения программ на реальном оборудовании либо в виртуализованном окружении, что повышает накладные расходы на анализ производительности, а также затрудняет проведение такого анализа на ранних стадиях разработки. В силу вышесказанного, выполнение предварительной оценки производительности во время статического анализа программы, без фактического запуска, открывает широкие возможности для анализа и улучшения нефукциональных характеристик программ, и задача разработки способов такого оценивания крайне актуальна и практически важна.
Не теряя общности, такой способ может быть реализован на основе инфраструктуры для компиляции исследуемых приложений, что наталкивает на идею дополнить компилятор экспертным модулем, который будет предоставлять некоторые наборы числовых характеристик, статистически коррелирующих с производительностью компилируемой программы. С другой стороны, программы с различной семантикой могут значительно отличаться по производительности, даже если эти числовые характеристики схожи. В связи с этим данный модуль-оценщик должен брать во внимание не только эти числовые характеристики, но и граф потока управления программы. В данной работе предлагается решать эти задачи с помощью инструментов, разработанных на инфраструктуре LLVM, и алгоритмов представления данных в векторных пространствах - эмбеддингах. Последнее предложение связано с тем, что сравнивать векторы некоторого векторного пространства вычислительно проще, нежели сравнивать помеченные графы, которыми структурно являются входные промежуточные представления.
Модель по предсказанию производительности можно было бы построить без использования инфраструктуры LLVM, например, с помощью динамического санитайзера, но в этом случае у модели не было бы возможности учесть информацию из графа потока управления, от которого производительность программ тоже существенно зависит. Кроме того, вето эту информацию нужно получать во время компиляции программы, то есть статически. Поэтому в работе предлагается использовать пользовательские проходы LLVM, которые позволят из программы на C/C++ создать промежуточное представление, дополненное данными оценки производительности, а затем эмбеддинги, включающие информацию как из графа потока управления, так и из расстояния между обращениями в памяти.
2. Предлагаемый способ анализа
Для создания обучающей и целевой выборок нужно сгенерировать достаточно большое количество программ из множества целевых программ Р, после этого случайным образом распределить эти программы в обучающую и целевую выборки, после этого разбиения обучить на обучающей выборке классификатор отличать эффективные программы от неэффективных. Способы генерации программ описаны в разделе 4.
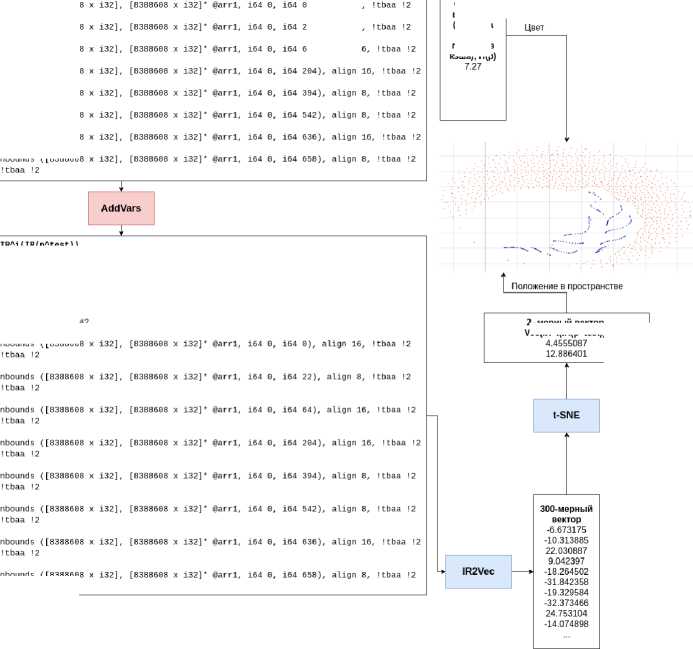
Пусть на вход компилятора подаётся программа ptest из множества целевых программ Р, состоящая из одной единицы трансляции, которая преобразуется в промежу- точное представление IR(ptest). Тогда схема преобразования программы для анализа выглядит следующим образом (схематично отображено на рис. 1):
Исходный код на C/C++, p
LLVM clang
Исполняемый
файл
Промежуточное представление LLVM IR, IR(pAtest) define dso_local 132 @main() #0 {
Xretval = alloca 132, align 4
Xleft = alloca 132, align 4
store 132 9, 132* Xretval, align 4
969 = bitcast 132* Xleft to 18*
call void 961 = load store 132 962 = load store 132 963 = load store 132 964 = load store 132 X5 = load store 132 966 = load store 132 967 = load store 132 968 = load store 132
І32, 132* getelementptr 961, 132* Xleft, align 4 132, 132* getelementptr 962, 132* Xleft, align 4 132, 132* getelementptr 963, 132* Xleft, align 4 132, 132* getelementptr 964, 132* «left, align 4 132, 132* getelementptr 965, 132* Xleft, align 4 132, 132* getelementptr 966, 132* Xleft, align 4 132, 132* getelementptr 967, 132* Xleft, align 4 132, 132* getelementptr 968, 132* «left, align 4
inbounds ([8388608 !tbaa 12
inbounds ([8388608 !tbaa 12
inbounds ([8388608 !tbaa 12
inbounds ([8388608
Опорная величина (медиана долей промахов кэша), П(р)
Промежуточное представление LLVM IR, IRni(IR(pntest)) define dso_local 132 @maln() #0 {
Xretval = alloca 132, align 4
Xleft = alloca 132, align 4
store 132 9, 132* Xretval, align 4
969 = bitcast 132* Xleft to 18*
Xprob = add 164 О, 0
961 = load 132, І32* getelementptr store 132 961, 132* Xleft, align 4
Xprobl = add І64 0, 2
962 = load 132, 132* getelementptr store 132 962, 132* Xleft, align 4
Xprob2 = add І64 0, 2
963 = load 132, 132* getelementptr store 132 963, 132* Xleft, align 4
ХргоЬЗ = add І64 0, 3
964 = load 132, 132* getelementptr store 132 964, 132' Xleft, align 4
Xprob4 = add І64 0, 3
965 = load 132, 132* getelementptr store 132 965, 132* Xleft, align 4
Xprob5 = add І64 0, 3
966 = load 132, 132* getelementptr store 13 2 966, 13 2' Xleft, align 4
Xprob6 = add І64 0, 3
X7 = load 132, 132* getelementptr store 132 X7, 132' Xleft, align 4
Xprob7 = add І64 0, 2
X8 = load 132, 132* getelementptr store 132 X8, 132' Xleft, align 4
Э), align 16,
22), align 8,
64), align IC inbounds ([8388608
inbounds ([8388608
inbounds ([8388608
inbounds ([8388608
inbounds (18388608
inbounds (18388608
inbounds (18388608
inbounds (18388608
inbounds (18388608
inbounds (18388608
inbounds ([8388608
inbounds ([8388608
2-мерный вектор, Vec(IRAi(IR(pAtest)))
Рис. 1. Схема, пайплайпа по анализу программы из тестовой выборки
1) Получить IR(ptest) из ptest.
2) Получить IRl(IR(ptest)) - промежуточное представление, инструментированное параметрами производительности, полученными статически по используемой модели.
3) Построить эмбеддинг V ec(I R1 (I R(ptest))).
4) Провести классификацию Vec(IRz(IR(ptest))) в пространстве эмбед-
- дингов, предварительно разбитому на. классы по обучающей выборке Т = {(Vec(IRz(IR(p))), П(р)) : р G P'train С P} , г де П(р) - результаты реального измерения производительности программы р3, скомпилированной непосредственно из IR(p) без инструментирования. 3. Используемые инструменты3.1. LLVM 3.2. IR2Vec 3.3. AddVars LLVM-проход
Таким образом, для предсказания производительности прежде всего необходимо определить релевантную числовую характеристику П(р) и выполнить её измерение для всех программ РtTam обучающей выборки. В рамках данной статьи будем считать основной характеристикой производительности долю кэш-промахов на чтение по данным. Чем она меньше, тем лучше, потому что малое число промахов косвенно говорит об использовании данных преимущественно из быстрой памяти, доступ к которой занимает наименьшее число тактов процессора. Также будем считать, что для одной программы выделен ровно один ключевой сценарий исполнения, данные детерминированы, а результаты измерений получены осреднением по серии измерений с многократным повторением, и могут быть повторно воспроизведены. Следовательно, для подготовки обучающей выборки требуется для каждой входной программы р измерить долго промахов в кэше. Данная величина в работе измерялась с помощью инструмента perf stat [4], который предоставляет информацию о числе различных событий во время выполнения программы. Примером таких событий является инструкция загрузки из памяти - load, а также промах в кэше при её выполнении.
LLVM — это инфраструктура компиляторных инструментов, объединяющая в себе переиспользуемые модули для компиляции, анализа и оптимизации программ на С, C++, Fortran и некоторых других языках программирования [5].
Внутри LLVM, как внутри любого компилятора, реализован набор проходов для оптимизации программ. Проходы запускаются в заранее заданной последовательности на так называемом промежуточном уровне компилятора («middle-end»), получающем на вход программу, транслированную синтаксическим модулем («front-end») в промежуточное представление LLVM IR, и выполняют преобразование входного представления, изменяя его в соответствии со своей внутренней логикой. В качестве примеров проходов можно привести сворачивание комбинации из нескольких констант в одну (constant folding) или размотку циклов (loop unrolling) для трансформации цикла в последовательность инструкций. Это примеры стандартных оптимизационных проходов, которые призваны уменьшить время выполнения программы или размер исполняемого файла.
Инфраструктура LLVM предоставляет программный интерфейс для разработки собственных проходов [6] пользователями. Кроме того, LLVM позволяет сохранять дамп LLVM IR в файл для дальнейшего его использования вне инфраструктуры LLVM. В частности, проект IR2vec [1] является примером стороннего анализатора LLVM IR, в настоящий момент уже достаточно хорошо апробированного, например, на задачах укрупнения потоков (thread coarsening) [1] и задачах планирования последовательности применения оптимизационных проходов [7].
IR2Vec [1] принимает на вход промежуточное представление и строит 300-мерный4 числовой вектор, который является обобщённым представлением соответсвующей программы, называемым IR-эмбеддингом. В задачах обработки текстов эмбеддинги позволяют значительно улучшать качество для классификации текстов. Это приводит к идее использования IR-эмбеддингов для задач анализа программ, в особенности для предсказания производительности. В IR2Vec есть два режима работы - Flow-Aware и Symbolic, Symbolic является более грубым вариантом построения эмбеддинга, он собирает информацию всех инструкций программы, рассматривает последовательность инструкций как последовательность токенов, без учёта графа потока управления. Flow-Aware является улучшенным относительно Symbolic вариантом построения эмбеддинга, поскольку он также учитывает эм- беддиниги всех инструкций, но при этом учитывает зависимости по данным внутри программы: эмбеддинг инструкции зависит от всех достигающих определений переменных, используемых в этой инструкции.
AddVars - разработанный в рамках данной работы пользовательсткий инструментирующий проход LLVM, который на уровне функции проходит по каждой инструкции load и оценивает, насколько удалён адрес5, по которому обращается этот load, от адреса, по которому обращялся предыдущий load в этой же функции. В зависимости от этой удалённости вставляется фиктивная инструкция 7,prob = add 164 0, some_number, где переменная %prob по факту дальше нигде не используется, a some_number зависит от расстояния до адреса предыдущего loada следующим образом:
1) 1, если расстояние меньше либо равно 8 байт,
2) 2, если расстояние больше 8 байт и меньше либо равно 64 байт,
3) 3, если расстояние больше 64 байт и меньше либо равно 512 байт,
4) 4, если расстояние больше 512 байт и меньше либо равно 4096 байт,
5) 5, если расстояние больше 4096 байт и меньше либо равно 16384 байт,
6) 6, если расстояние больше 16384 байт и меньше либо равно 65536 байт,
7) 7, если расстояние больше 65536 байт и меньше либо равно 524288 байт,
8) 0 во всех остальных случаях, в том числе если расстояние невозможно вычислить статически.
4. Построение обучающей выборки
4.1. Генерация программ: простейший генератор
Каждой из восьми возможных фиктивных инструкций должен быть присвоен свой собственный эмбеддинг, отличный от всех остальных возможных эмбеддингов других инструкций, такой, чтобы эмбеддинги программ существенно зависели от этих инструкций. Заметим, что поскольку /«prob больше нигде не используется, то эти инструкции семантически не влияют на программу.
Для построения адекватной модели, которая на двухмерном пространстве эмбеддингов могла бы предсказать долю промахов кэша, необходимо создать обучающую выборку из большого числа программ на C/C++ определённого семантического класса, для каждой из них необходимо вычислить эмбеддинг и с достаточно большой точностью измерить долю промахов кэша. Измеренное значение назовём опорным.
Тогда при взятии тестовых программ из этого же класса модель будет адекватно предсказывать долю промахов кэша у этих программ по их эмбеддингам в двухмерном пространстве. Далее будет изложено, как сгенерировать достаточно репрезентативную обучающую выборку из программ, для которых граф управления имеет один и тот же вид6, а последовательность обращений к памяти настраивается.
Процесс генерации обучающей выборки реализован как скрипт на Python:
def
generate_code (indexes , array_len, mult): prefix = "#include„
mult = 1 for idx in range( iterat i о ns ): if idx == 0:
p = np. array ([1] — [0 for i in range(lim — 1)]) mult = 1
-
e 1 i f idx == 1:
p = np. array ([0 for i in range(lim)]) p[32 * 1024] = 1 mult = 512
elif idx < iterations //2:
p = np . array ( [ 0. 99 * * i for i in range(lim)]) mult = 1
else :
p = np . array ([ 1.00000 1 * * i for i in range(lim)]) mult = 512
p = p/p .sum] )
permutation = | | elems = [i for i in range (lim)]
ds = np . random . choice ( elems , second_lim , p=p ) for j in range ( second_lim ) :
if len ( permutation ) == 0:
permutation . append ( 0 ) else :
permutation . append (( permutation [ —1] — ds[j])%lim) generated = generate_code ( permutation , array_len=lim , mult=mult) if src dir:
with open(src_dir — os . sep — str(idx) — "_perm" — str(lim) — ".c", "w+") as f:
f . write ( generated )
Скрипт генерирует набор программ на С, каждая из которых итеративно выполняет load из одного и того же массива, но по различным индексам. Первая программа (ветвв idx = 0) выполняет все чтения по нулевому индексу, поэтому её доля промахов кэша должна быть минимально возможной. Вторая программа (ветвь idx = 1) выполняет чтения по строго увеличивающемуся индексу, причём шаг, с которым увеличивается индекс, равняется полному размеру кэша, что гарантирует промах кэша с каждым чтением, поэтому доля промахов в кэше должна быть максимальной. Далее примерно половина программ (ветвь idx < iterations//2) увеличивает индекс случайным образом, но соблюдая свойство локальности, поскольку вероятность шага размера i по геометрической прогрессии падает с увеличением i. Другая половина программ (ветвь else) читает массив случайно, поэтому доля промахов кэша в них достаточно большая.
4.2. Измерение доли кэш-промахов
Опорную величину доли промахов в кэше можно измерять с помощью динамических профилировщиков, таких как, к примеру, valgrind cachegrind [8] либо perf stat [4]. В данном исследовании был выбран perf stat, поскольку он собирает данные из счётчиков событий ядра операционной системы, в отличие от valgrind cachegrind, который выполняет симуляцию реальной модели кэша.
Запустим генератор с параметрами python generate _ programs.ру 8388608 128 2047. В каждой программе 128 load.
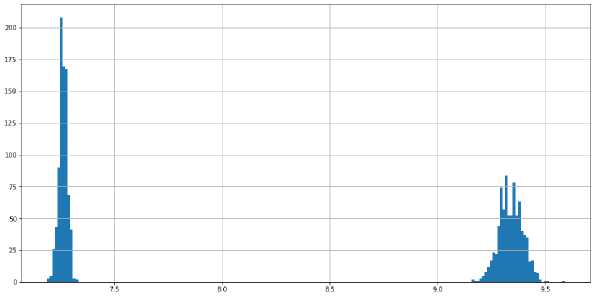
Рис. 2. Распределение долей промахов кэша.
В данной версии генерации обучающей выборки медианная доля промахов имеет распределение, изображенное на. рис. 2, где явно выделяются «условно кэш-эффективные программы» (распределение слева) с долей промахов между 7% и 7.5% и «условно кэш-неэффективные программы» (распределение справа) с долей промахов между 9% и 9.5%.
4.3. Инструментирующий проход и построение эмбеддингов
Далее рассмотрим, как создаются эмбеддинги. Для того чтобы в получаемых эмбед-дингах была, какая-то статистическая зависимость от промахов в кэше, был разработан проход LLVM AddVars, описанный выше, добавляющий информацию о расстоянии между обращениями к памяти в промежуточное представление. Этот проход посещает все load в исходном промежуточном представлении в каждой функции в Reverse Post-Order Traversal (RPOT) порядке, заданном потоком управления, и перед каждым load добавляет фиктивную инструкцию, которая семантически не изменяет программу, но добавляет информацию о том, каково расстояние между текущим обращением к памяти и предыдущим.
Каждой фиктивной инструкции прохода, был присвоен собственный эмбеддинг в 300-мерном пространстве, этот эмбеддинг был добавлен в исходный код IR2Vec, чтобы эмбеддинги зависели от фиктивных инструкций. На рис. 3 совмещены эмбеддинги, которые выдаёт IR2Vec для одного и того же набора, программ до и после прохода, который добавляет фиктивные инструкции. Все 300-мерные эмбеддинги были отображены в двухмерное пространство методом t-SNE [2], сохраняющим расстояние между точками. Синий — это эмбеддиги без фиктивных инструкций, красный — с ними.
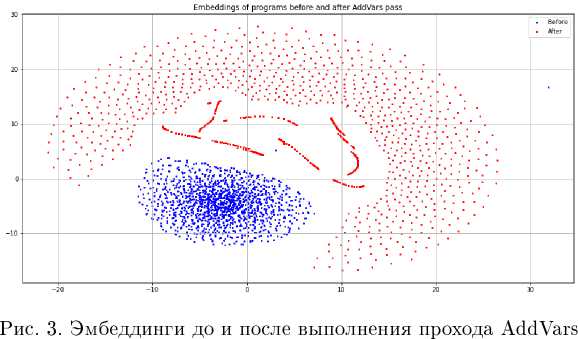
Далее рассмотрим толвко эмбеддинги после прохода AddVars вместе с информацией с рис. 4 о доле промахов кэша. Здесв цветом обозначена доля промахов в кэше, чем ближе к синему, тем лучше. На рисунке видно, что задача предсказания производительности в данном случае представляет собой бинарную классификацию, при этом два класса программ, эффективные и неэффективные, легко отделимы друг от друга. Это и есть эвристический критерий, по которому «условно кэш-эффективные программы» отличаются от «условно кэш-неэффективных программ».
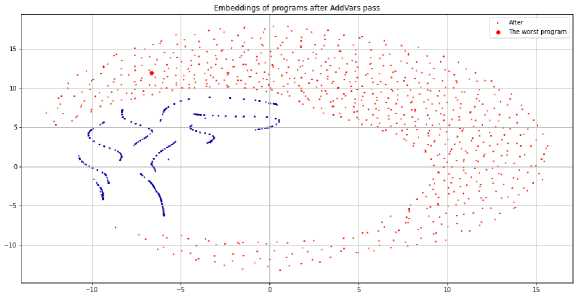
Рис. 4. Эмбеддинги программ после прохода. AddVars, цветами показаны доли промахов в кэше
4.4. Эксперименты с другими генераторами
Рассмотрим другой генератор программ на. С. Этот генератор увеличивает индекс на. размер кэша, при этом индекс берётся в каждой программе по всё увеличивающемуся модулю.
def generate_code(i ) :
prefix = "#includе„
" int „main ()„{\n" \
" \ t char „arr _elem„=„ 0; \ n"
s t r s = || for j in range(2 * * 11):
st rs . append ( f " \tarr_elem„+=„ arr [ { ( j „%„ (1 „+„2* i ))„*„32„*„1024}]; \ n" ) suffix = ’ \ t printf ("%d\\n" , „arr_elem ); \ n ’ \
’\treturn„O;\n ’ \ return prefix — " " . j oin ( st rs ) — suffix i f name == ’ main ’ :
-
#... some code omitted ...
for idx in range( iterat i о ns ): generated = generate_code(idx) if src dir:
with open(src_dir — os . sep — str(idx) — "_perm" — str(lim) — ".c", "w+") as f:
f . write ( generated )
Этот генератор позволяет сгененировать программві с достаточно вариативной долей промахов в кэше, что позволяет сделатв обучающую выборку более репрезентативной. Для этой вариативности необходимо сделатв число load в этой программе достаточно большим, в данном случае 2048 loadoB. Это необходимо, потому что кроме тех инструкций, что есть в исходном коде на С, есть также инструкции, которые запускают функцию main, и этот код тоже вносит вклад в долю промахов в кэше. Распределение долей промахов в кэше для этого случая отображено на рис. 5. К сожалению, при таком большом количестве load в совокупности двух проходов были выявлены проблемы с производительностью, поэтому приведём данные только по доле промахов кэша. Эти проблемы с производительностью не связаны с IR2Vec, поскольку внутри него используется очень хорошо оптимизированная библиотека eigen [9]. Поэтому мы предполагаем, что проблемы с масштабированием связаны со значительным разрастанием размера промежуточного представления после выполнения прохода Add Yars.
Генератор был запущен с параметрами python generate_programs. ру 8388608 2048 900
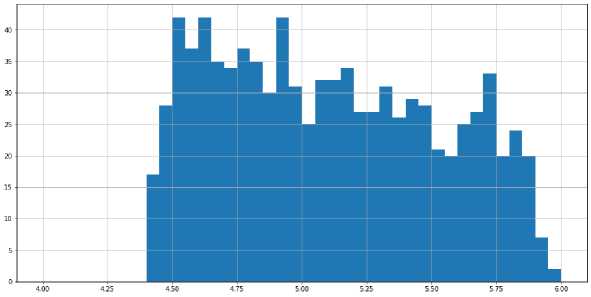
Рис. 5. Распределение долей промахов кэша.
В качестве ещё одного эксперимента, был запущен ещё один генератор, он отличается от предыдущего только меньшим числом loadoB в одной программе, в данном генераторе их число уменьшено до 512. Результаты работы этого генератора, видны на. рис. 6 и рис. 7, он был запущен с параметрами python generate_programs .ру 8388608 512 300
def generate_code(i ) :
prefix = "//include„< stdio .h>\n" \ n\nchar„arr[100000„*„32„*„1024ULL] ;\n"\
" int „main ()„{\n" \
" \ t char „arr _elem„=„ 0; \ n"
s t r s = || for j in range(2**9):
st rs . append ( f " \tarr_elem„+=„ arr [{ ( j „%„ (1 „+„2* i ))„*„32„*„1024}]; \ n")
suffix = ’ \ t printf ("%d\\n" , ^arr_elem ); \ п ’ \ tr е tu гп _() :n ’ \ return prefix — " " . j oin ( st rs ) — suffix i f name == ’ main ’ :
Д.. some code omitted ...
for idx in range( iterat i о ns ): generated = generate_code(idx) if src dir:
with open(src_dir — os . sep — str(idx) — "_perm" — str(lim) — ".c", "w+") as f:
f . write ( generated )
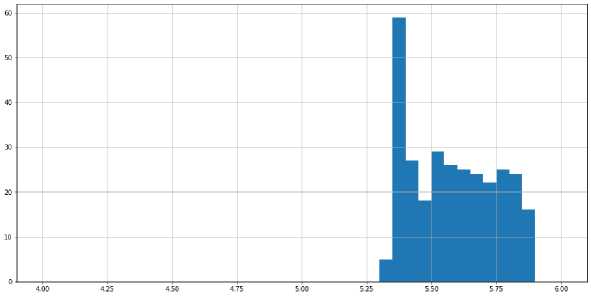
Рис. 6. Распределение долей промахов кэша.
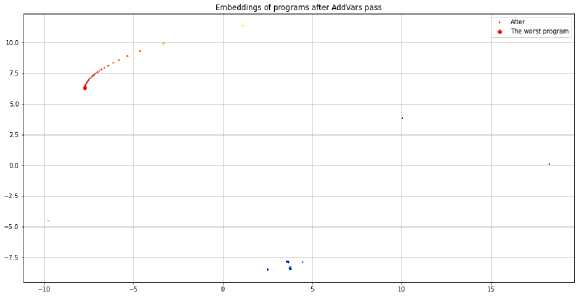
Рис. 7. Эмбеддипги программ после прохода. AddVars, цветами показаны доли промахов в кэше
Пример демонстрирует, что эмбеддинги в целом коррелируют с долей промахов кэша, но коэффициент корреляции сильно зависит от начальной инициализации метода, понижения размерности t-SNE [2]. Кроме того, вариативность метрики производительности очень мала, в связи с малым числом инструкций в программе.
5. Заключение и дальнейшие действия
Дальнейшая работа предполагает генерацию программ с большей вариативностью доли промахов в кэше для проверки того, как располагатотся эмбеддинги программ друг относительно друга в этом случае и являются ли они легко различимыми.
Кроме того, необходимо провести исследования, возможно ли улучшить качество классификатора при применении других методов понижения размерности вместо t-SNE, в частности, UMAP [10].
Список литературы Cтатическая оценка производительности посредством эмбеддингов промежуточных представлений LLVM
- Venkata Keerthy S., Rohit Aggarwal, Shalini Jain, Maunendra Sankar Desarkar, Ramakrishna Upadrasta, Srikant Y.N. IR2VEC: LLVM IR Based Scalable Program Embeddings // ACM Transactions on Architecture and Code Optimization, V. 17. 4. ACM. New York. NY. USA. 2020. Article 32 (December 2020). 27 p.
- van der Maaten L., Hinton G. Visualizing Data using t-SNE // Journal of Machine Learning Research. 2008.
- Becker M.,Chakraborty S. Measuring Software Performance on Linux, Technical Report // Technical University of Munich. Munich. Germany, 2018.
- Linux kernel profiling with Perf // Online. 2022. https://perf.wiki.kernel.org/index.php/Tutorial.
- The LLVM Compiler Infrastructure Project // Online. 2022. https://llvm.org.
- Writing an LLVM Pass // Online. 2022. https://llvm.org/docs/WritingAnLLVMPass.html.
- Jain S., Andaluri Y., Venkata Keerthy S. and Upadrasta R. POSET-RL: Phase ordering for Optimizing Size and Execution Time using Reinforcement Learning // 2022 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 2022. P. 121-131.
- Cachegrind: a cache and branch-prediction profiler // Online. 2022. https://valgrind.org/docs/manual/cg-manual.html.
- eigen.tuxfamily.org Eigen is a C++ template library for linear algebra: matrices, vectors, numerical solvers, and related algorithms // Online. 2022. https://eigen.tuxfamily.org/index.php.
- McInnes L., Healy J., Saul N., Grossberger L. UMAP: Uniform Manifold Approximation and Projection // The Journal of Open Source Software 3(29):861 2018.
