Density Based Script Identification of a Multilingual Document Image

Author: Rumaan Bashir, S. M. K. Quadri
Journal: International Journal of Image, Graphics and Signal Processing(IJIGSP) @ijigsp
Article in issue: 2 vol.7, 2015.
Free access
Automatic Pattern Recognition field has witnessed enormous growth in the past few decades. Being an essential element of Pattern Recognition, Document Image Analysis is the procedure of analyzing a document image with the intention of working out the contents so that they can be manipulated as per the requirements at various levels. It involves various procedures like document classification, organizing, conversion, identification and many more. Since a document chiefly contains text, Script Identification has grown to be a very important area of this field. A Script comprises the text of a document or a manuscript. It is a scheme of written characters and symbols used to write a particular language. Languages are written using scripts, but script itself is made up of symbols. Every language has its own set of symbols used for writing it. Sometimes different languages are written using the same script, but with marginal modification. Script Identification has been performed for unilingual, bilingual and multilingual document images. But, negligible work has been reported for Kashmiri script. In this paper, we are analyzing and experimentally testing statistical approach for identification of Kashmiri script in a document image along with Roman, Devanagari & Urdu scripts. The identification is performed on offline machine-printed scripts and yields promising results.
Document Image Analysis, Multilingual Script Identification, Kashmiri, Roman, Devanagari, Urdu, Density, Statistical Approach
Short address: https://sciup.org/15013523
IDR: 15013523
Text of the scientific article Density Based Script Identification of a Multilingual Document Image
Published Online January 2015 in MECS DOI: 10.5815/ijigsp.2015.02.02
-
1. Literature review which discusses the recent advances in the area of script identification & provides a classification of various script identification techniques.
-
2. Methodology which provides a detailed structure of the method used to solve the identification problem along with the features used. It also lists the algorithm used for the purpose of calculation of density.
-
3. Findings/Discussion which presents the experimental results and illustration of the methodology used.
-
4. The advantages and the future scope are highlighted in conclusion section.
-
II. L iterature R eview
Table 1. Features of Kashmiri script.
|
S. No |
Feature |
Particulars |
|
1. |
Writing/Reading order |
Right to Left |
|
2. |
Diacritical marks |
Heavy usage (pesh, zabbar, zaer, hamza, dots, tashdeed, etc.) |
|
3. |
Complexity |
More Cursive than English & Devanagari |
|
4. |
Distinct Separation between lines, words & letters |
Very Rare |

Fig 1: Example Kashmiri Script.
Based on this survey, a classification of script identification is given below:
-
A. Method of Acquisition:
-
i. Offline: This type of script identification is performed on a document which is already produced and not being produced.
ii.
B.
i.
ii.
C.
i.
ii.
D.
i.
ii.
E.
i.
ii.
iii.
F.
i.
Online: This is the type of script identification wherein the script is being written & identified at the same instance of time. It is a real time system.
Method of Writing:
Handwritten: This type of script identification is applicable when the script has been written using hand and not any machine [26].
Typeset: Here the script is printed using a machine e.g. a printer. Sometimes also called as machine-written.
Type of Script:
Foreign: This script identification involves the identification of scripts which do not belong to a specific country i.e. international scripts.
Domestic: Here the scripts being identified are the scripts which belong to a specific country [27][9].
Features used for identification:
Local: When the feature used for identification fall within a small area of a document e.g. a word in a paragraph.
Global: Here the features of the entire document as a single whole are taken into consideration for performing script identification.
Number of Scripts:
Unilingual: When a particular document under identification consists of only one script the identification is called as the unilingual script identification [28].
Bilingual: When the document under identification consists of two scripts [2], the procedure is called as bilingual script identification.
Multilingual: When a document under the procedure of identification consists of more than two scripts, the identification becomes complex, and is called multilingual script identification [27].
Technique of Identification:
Spatial Domain: When the pixels of an image are used as a base for identification the concept is called spatial domain. It has further two sub types: a. Statistical: Here the pixels are converted to statistical values are used for the identification purpose.
-
b. Structural: Here the structure of the text & symbols delivered by the pixels is used to perform the identification [29].
-
ii. Frequency Domain: When an image is converted to frequencies and those frequencies are processed or manipulated to perform identification / classification it is called frequency-domain technique [30][31].
-
III. M ethodology
An image is a two dimensional function f(x,y) where x and y are the spatial or Cartesian coordinates and f is the function representing the intensity values at location (x,y). Therefore, an image is essentially a collection of numerical values representing the intensity. These numerical values can be statistically manipulated to perform certain operations on the image. In order to perform the identification of Kashmiri script along with other related scripts viz. Roman, Urdu, & Devanagari, we propose a simple & statistical solution. Here statistical approach has been used to perform the identification of the four scripts using a concept called “Density”. This Density is represented as Ø. Since the image is visually composed of small dots called pixels, the Density (Ø) here is the density of an image which is the count of the number of black pixels per unit of size used for calculation. It is a representative of how much dense the text part (written part) in a document is. It indicates the amount of fullness in a particular document and amount of emptiness on the contrary. This density is evaluated to check how much full the image is using the black part (or the written part) of it.
Initially, a document image is obtained from a valid source. This document image becomes the input to the procedure of script identification. This document image is then cropped to remove the unwanted portions (borders) in order to extract the text part only. This image is then divided into small pieces extracting lines from the text using a particular unit (in this case pixel). After dividing the image into constituent components, density of each part is calculated.
An image matrix which is the representative of the component of the image in the computer system becomes the base for the purpose of calculating the density. This image matrix is processed & manipulated. The illustration of this calculation is shown in the discussion section. The problem statement of this piece of work is given below:
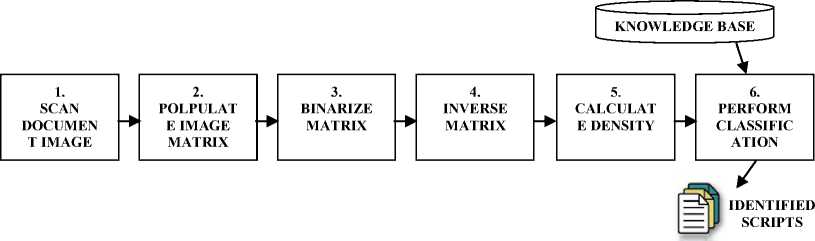
Fig 3. Script identification Methodology Used
-
Problem Statement:
To identify different scripts in an offline machine-written document image using statistical analysis.
Four scripts have been taken into consideration:
-
1. English / Roman, the globally important script
-
2. Hindi / Devanagari, the national script
-
3. Urdu, the formal script of Kashmir
-
4. Kashmiri, the local regional script
The algorithm to calculate the density of the image components is given below:
Algorithm Scriptld^nDensityQ:
Constraints: 1. Populated Knowledge Base for classification purpose. 2. Document image consists of texts only.
-
1. Start
-
2. Scan the sample image
-
3. Populate image matrix in order to contain the intensity values
-
4. Binarize the image matrix
-
5. Invert the binarized matrix
-
6. Calculate the densify of the matrix
-
7. Compare with the knowledge base
-
8. Perform classification
-
9. Stop '
Fig 2: Script Identification Algorithm Steps.
-
IV. F indings /D iscussion
We have applied the proposed technique on a variety of printed document images. The script identification has been performed in two stages. The first stage is a training stage where in a set of 400 image components of document images were used for training the algorithm in order to create the knowledge base. After the creation of the knowledge base, the actual phase of script identification was commenced in which 800 image components of document images were used to test the efficacy of the algorithm.
All of these images were scanned from printed documents containing text in normalized form. These document image components considered for the experiment were of size 610 X 25 pixels representing a single line of unique script.
The document is scanned using a simple multipurpose scanner with a 300 dpi criterion. The document image looks like the image given in Fig. 4. Next, this document image is segmented into components of size 610 X 25 pixels using a segmentation algorithm in order to yield lines of unique scripts. This is shown in Fig. 5.
t, Й^фйя^^^Л^^ТЙ ; fenn -H^H^cH ^Тч-wr ТЙ, 4т wt -ddl У^^ЭТУЧ^^^^Ч^ 34' 3jJ ^ к.1'^1 ^j£ Jill j&t£ «5 _уД ,^д nJ .^U-a. tij ^ -Jj 3“ ->-3^ *^ -» j^-j 3^*3 -^ -Ah ^4 jj -^ /jjISJj! ^4* 4 53*-5 -H" t/J*^ ^ J£^ _A *4U 3“ 2y 3^3 rj^ З'-*-1^). -f» ^j-A 3jj 3j' З^- uj^ 3 -A^ 34Jjv“' ^J^ ^ J" 3^ ЗЗн ЗЗя ** • ^^ ^ a -^ 4hj -A ^^ ^ -Ah -ij-^ u3jh J
Fig 4: A scanned document image.
^^if/ jw
5\У
(klZ
^^0*J^-"1!^^ ^\>/»Й^^ ^ <^-^(
%, Pi-tih
y41-wi34f^t л
4I ^йчГ,
These individual components are then represented as image matrices as shown in the Fig. 6. This image matrix is actually the representation of the image in the computer. The image intensities are normally stored in a 2 dimensional data structure in rows and columns. Here, the image matrix is populated with the intensity values of which the image is comprised.
|
0 |
1 |
0 |
10 |
0 |
255 |
254 |
233 |
|
233 |
1 |
0 |
1 |
10 |
9 |
255 |
250 |
|
2 |
255 |
250 |
247 |
1 |
255 |
0 |
0 |
|
255 |
1 |
1 |
0 |
0 |
0 |
244 |
244 |
|
0 |
0 |
255 |
252 |
250 |
0 |
1 |
0 |
|
0 |
0 |
0 |
0 |
255 |
0 |
0 |
1 |
Fig 6: Image Matrix.
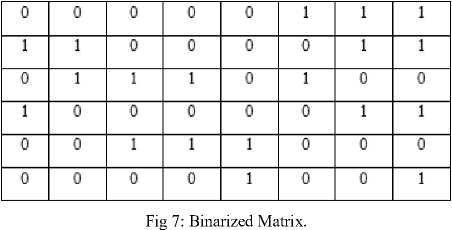
This binarized matrix is then inverted to convert 0 to 1 and 1 to 0 so as to indicate black as 1 (presence of content as true) and white as 0 (absence of content as false). Simply said, a complement of the binarized matrix is calculated. This complemented matrix is shown in Fig. 8 and is called the inverted matrix.
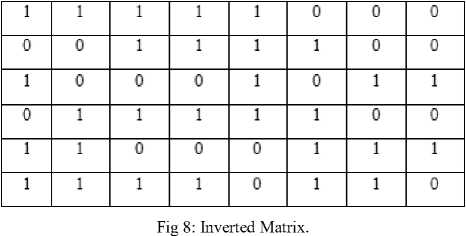
After the creation of inverted matrix, the Density is calculated as per equation (1).
я
Density (0) = V xi i = 0
where n is the number of cells in the matrix and xi = {0,1}.
In the Fig. 8, the Density (Ø) is calculated to 29 and the total cells are 48. These values are converted to the total density peak percentage of (29/48) * 100 = 60.41 %. After evaluating the density, the script is to be classified as per the density factor. In the training stage, the outcome of which is revealed in Table 2, a set of images was used to train the algorithm. In the training phase, the knowledge base was created and the classification/identification index was made. This is shown below:
If Peak percentage for (Ø) == 4.288 % ± 0.3% then
Script = Hindi
Else if Peak percentage for (Ø) == 4.911 % ± 0.3% then
Script = Kashmiri
Else if Peak percentage for (Ø) == 2.862 % ± 0.3% then
Script = English
Else if Peak percentage for (Ø) == 3.521 % ± 0.3% then
Script = Urdu
Else
Script = Others
Table 2: Results of the Training Phase.
|
S. No |
Script |
Size of Image (pixels) |
Density (Ø) Range |
Peak percentage for (Ø) |
|
1 |
Devanagari |
610 X 25 |
613 to 695 |
4.288 % |
|
2 |
Kashmiri |
610 X 25 |
676 to 822 |
4.911 % |
|
3 |
Roman |
610 X 25 |
400 to 473 |
2.862 % |
|
4 |
Urdu |
610 X 25 |
494 to 580 |
3.521 % |
In the testing stage 200 image components were tested for each script type and the results are listed in Table 3. The results of the proposed technique are highly significant and yield 97% overall accuracy.
Table 3: Final Results.
|
S. No |
Type of Script |
Total No. of Images Tested |
Correctly Identified |
Accuracy Rate |
|
1 |
Roman |
200 |
194 |
97% |
|
2 |
Devanagari |
200 |
196 |
98% |
|
3 |
Kashmiri |
200 |
194 |
97% |
|
4 |
Urdu |
200 |
192 |
96% |
|
Overall Accuracy Rate |
800 |
776 |
97% |
V. C onclusion
Document image analysis is a highly important area of research with direct application and implementation in the practical world with Script identification being an important procedure in it. Script identification has been performed in detail for many scripts. This work is a pioneering step for the identification of Kashmiri script together with its closely related scripts. Till date extremely little work has been reported for the identification of Kashmiri script.
The technique of density calculation has been proposed and experimentally tested for identifying Kashmiri and its related scripts. Density is used as a statistical feature for identification which indicates the fullness (written part) of a document image or the amount of content present. The technique proposed in this paper provides promising results. It is very simple to implement and gives concrete output. Further, it does not require any specialized equipment for identification purposes.
The work presented in this paper can be improved and extended in many ways some of which have been listed as under:
-
1. Improve the technique / method to increase the rate of recognition / identification. (fast processing & less memory i.e. optimize)
-
2. Extend the work presented to include more scripts.
-
3. Extend the work on handwritten Kashmiri script.
-
4. The technique could be applied to work out numerals of various scripts.
-
5. Typically, identify & experiment other features to distinguish between Urdu & Kashmiri as these are very similar scripts and very common scripts in Kashmir.
-
6. The concept of density could be used to solve or improve other issues of document image analysis.
References Density Based Script Identification of a Multilingual Document Image
- S. S. Toshkhani, "Kashmiri Language: Roots, Evolution and Affinity". Kashmiri Overseas Association, Inc. (2008)
- Rumaan Bashir and Smk Quadri, “Identifiction of Kashmiri Script in a Bilingual Document Image”, In Proc. 2nd IEEE ICIIP, JUIT Shimla, India, (2013).
- Ahmed M Elgammal & Mohamed A. Ismail, “Techniques for Language Identification for Hybrid Arabic-English Document Images”, IEEE, (2001).
- Sukalpa Chanda, Umapada Pal, Katrin Franke & Fumitaka Kimura, “Script Identification- A Han and Roman Script Perspective”, IEEE, Intl. Conf. on Pattern Recognition, (2010).
- Shamita Ghosh and Bidyut B. Chaudhuri, “Composite Script Identification and Orientation Detection for Indian Text Images”, IEEE Intl. Conf. on Document Analysis and Recognition, (2011).
- Sukalpa Chanda, Umapada Pal & Katrin Franke, “Font Identification – In Context of Indic Script”, 21st Intl. Conf. on Pattern Recognition ( ICPR-2012), Japan.
- U. Pal, S. Sinha and B. B. Chaudhari, “Multi-Script identification from Indian documents”, IEEE, Proc. 7th Intl. Conf. on Document Analysis and Recognition, (ICDAR 2003) vol 2. pp 880-884.
- B. V. Dhandra, P. Nagabushan, Mallikarjun Hangarge, Ravindra Hegadi, V.S. Malemath, “Script Identification Based on Morphological Reconstruction in Document images”, IEEE, 18th Intl. Conf. on Pattern Recognition, (2006).
- U. Pal & B. B. Chaudhari, “Automatic Identification of English, Chinese, Arabic, Devanagari and Bangla Script Line”, IEEE, (2001).
- M. C. Padma, P. A. Vijaya, P. Nagabushan, “Language Identification from an Indian Multilingual Document Using profile features”, IEEE, Intl. Conf on Computer and Automation Engineering, (2009).
- M Swamy Das, D. Sandhya Rani, C. R. K. Reddy, “ Heuristic based Script Identification from Multilingual Text Documents”, IEEE, 1st Intl. Conf on Recent Advances in Information Technoogy (RAIT), (2012).
- P. A. Vijaya & M. C. Padma, “Text Line Identification from a Multilingual Document”, IEEE, Intl. Conf. on Digital Image Processing, (2009).
- Prakash K. Aithal, Rajesh G., Dinesh U. Acharya, Krisnamoorthi M. Subbareddy N.V, “Text Line Script Identification for a Trilingual Document”, IEEE, 2nd Intl. Conf. on Computing, Communication and Networking Technologies, (2010).
- Mohamed Benjelil, Remy Mullot, Adel M. Alimi, “Language and Script identification based on Steerable Pyramid Features”, IEEE, Intl. Conf. on Frontiers in Handwriting Recognition, (2012).
- Hiremath P. S., Shivashankar S., Jagdeesh D Pujari & V. Mouneswara, “Script Identification in a handwritten document image using texture features”, IEEE, Proc. 2nd Intl. Advance Computing Conf. (2010).
- Bashir, R. and Quadri, S.M.K., “Entropy based Script Identification of a multilingual Document Image”, IEEE Intl. Conf. Computing for Sustainable Global Development (INDIACom), 2014 Page(s): 19 – 23.
- Obaidullah, S.M.; Mondal, A.; Roy, K. “Structural feature based approach for script identification from printed Indian document”, IEEE Intl. Conf. on Signal Processing and Integrated Networks (SPIN), 2014 Page(s): 120 - 124
- Ferrer, M.A.; Morales, A.; Pal, U., “LBP Based Line-Wise Script Identification”, 12th IEEE Intl. Conf. on Document Analysis and Recognition (ICDAR), 2013 Page(s): 369 – 373.
- Mingji Piao; Rongyi Cui, “An Approach to Script Identification in Multi-language Text Image”, IEEE 6th Intl. Conf. on Intelligent Networks and Intelligent Systems (ICINIS), 2013 Page(s): 248 – 251.
- Obaidullah, S.M.; Roy, K.; Das, N., “Comparison of different classifiers for script identificationfrom handwritten document”, IEEE Intl. Conf. on Signal Processing, Computing and Control (ISPCC), 2013 Page(s): 1 – 6.
- Saidani, A.; Echi, A.K.; Belaid, A. , “Identification of Machine-Printed and Handwritten Words in Arabic and Latin Scripts”, IEEE 12th Intl. Conf. on Document Analysis and Recognition (ICDAR), 2013 Page(s): 798 – 802.
- Angadi, S.A.; Kodabagi, M.M., “A fuzzy approach for word level script identification of text in low resolution display board images using wavelet features”, Intl. Conf. on Advances in Computing, Communications and Informatics (ICACCI), 2013 Page(s): 1804 – 1811.
- Banerjee, P.; Chaudhuri, B.B., “A System for Handwritten and Machine-Printed Text Separation in Bangla Document Images”, Intl. Conf. on Frontiers in Handwriting Recognition (ICFHR), 2012 Page(s): 758 – 762.
- Busch, Andrew; Boles, W.W.; Sridharan, S., “Texture for script identification”, Pattern Analysis and Machine Intelligence, IEEE Transactions on Volume: 27, Issue: 11 (2005), Page(s): 1720 – 1732.
- Debashis Ghosh, Tulika Dube, & Adamane P. Shivprasad, “Script Recognition – A Review”, IEEE, Trans. On PAMI Vol. 32 No. 12 pp 2142-2161 (2010).
- K. Roy, S. Kundu Das, Sk Md Obaidullah, “Script Identification from Handwritten Documents”, IEEE Proc. 3rd Intl. Conf on Computer Vision, Pattern Recognition, Image Processing and Graphics, (2011).
- U. Pal & B. B. Chaudhari, “Script Line Separation From Indian Multilingual Script Documents”, Proc 5th Intl. Conf, on Document Analysis ad Recognition, IEEE Comp. Society Press pp 406-409 (1999).
- Faoud Slimane, Slim Kanoun, Jean Hennebert, Adel M. Alimi, Rolf Ingold, “A study on font family and font size recognition applied to Arabic word images at ultra-low resolution”, Elsevier, Pattern Recognition Letters 34 (2013), 209-218.
- Rajesh Gopakumar, N. V. Subareddy, Krishnamoorthi Makkithaya & U. Dinesh Acharya, “Zone-based Structural feature extraction for Script Identification from Indian Documents”, IEEE, 5th Intl. Conf. on Industrial & Information Systems, (2010).
- Zhou, L.; Ping, X.J.; Zheng, E.G.; Guo, L., “Script identification based on wavelet energy histogram moment features”, 10th IEEE Intl. Conf. on Signal Processing (ICSP), 2010 Page(s): 980 – 983.
- Jianjia Pan; Yuanyan Tang, “A rotation-robust script identification based on BEMD and LBP”, IEEE Intl. Conf. on Wavelet Analysis and Pattern Recognition (ICWAPR), 2011 Page(s): 165 – 170.
