Design an accurate algorithm for alias detection

Author: Muneer Alsurori, Maher Al-Sanabani, Salah AL-Hagree
Journal: International Journal of Information Engineering and Electronic Business @ijieeb
Article in issue: 3 vol.10, 2018.
Free access
An improvement in detection of alias names of an entity is an important factor in many cases like terrorist and criminal network. Accurately detecting these aliases plays a vital role in various applications. In particular, it is critical to detect the aliases that are intentionally hidden from the real identities, such as those of terrorists and frauds. Alias Detection (AD) as the name suggests, a process undertaken in order to quantify and identify different variants of single name showing up in multiple domains. This process is mainly performed by the inversion of one-to-many and many-to-one mapping. Aliases mainly occur when entities try to hide their actual names or real identities from other entities i.e.; when an object has multiple names and more than one name is used to address a single object. N-gram distance algorithm (N-DIST) have find wide applicability in the process of AD when the same is based upon orthographic and typographic variations. Kondrak approach, a popular N-DIST works well and fulfill the cause, but at the same time we uncover that (N-DIST) suffers from serious inabilities when applied to detect aliases occurring due to the transliteration of Arabic name into English. This is the area were we have tried to hammer in this paper. Effort in the paper has been streamlined in extending the N-gram distance metric measure of the approximate string matching (ASM) algorithm to make the same evolve in order to detect aliases which have their basing on typographic error. Data for our research is of the string form (names & activities from open source web pages). A comparison has been made to show the effectiveness of our adjustment to (N-DIST) by applying both forms of (N-DIST) on the above data set. As expected we come across that adjusted (A-N-DIST) works well in terms of both performance & functional efficiency when it comes to matching names based on transliteration of Arabic into English language from one domain to another.
Alias Detection (AD), N-gram Distance, Transliteration, Name Matching
Short address: https://sciup.org/15016134
IDR: 15016134 | DOI: 10.5815/ijieeb.2018.03.05
Text of the scientific article Design an accurate algorithm for alias detection
Published Online May 2018 in MECS
-
I. Introduction
Monitoring and analysis of web forums is becoming important for intelligence analysts around the globe since terrorists and extremists are using forums for spreading propaganda and communicating with each other. Due to this associative phenomenon, the Alias analysis is perhaps one of the most crucial and widely used analyses, and has attracted tremendous research efforts over the years but a problem related to this is that individuals can make use of several aliases. A problem with such a content analysis is that it is not unusual that individuals make use of several aliases on a single web forum or on different social media sites, making it harder to make correct assessments. As an example, the Norwegian rightwing extremist and lone-wolf terrorist Anders Behring Breivik made use of several aliases on various social media sites before his attacks in Norway 2011 [1].The use of several aliases can be perfectly normal, but can become a problematic issue when utilizing content-based analysis. To overcome this problem, we propose a number of matching techniques that can be used to identify users with multiple aliases. The obtained experimental results suggest that the combination of matching techniques can give significantly better results than if the techniques are applied individually. We also show that the achieved accuracy is largely dependent upon the number of aliases under consideration.
The important workers who contributed in natural language processing focuses on entities include those of Muhammad Ghafoor et al 2017 who presented a good literature review about Kurdish Script Languages (TSL).
In their review, they introduced a new system for plagiarism detection for Kurdish Language, based on ngram algorithm, that can detect the word, phrases, and paragraphs. Moreover, this system effectiveness for detect plagiarist texts in local host and online especially in Google search engine. This system is more useful for the academic organizations such as schools, institutes, and universities for finding copied texts from another document the plagiarism detection techniques [4]. Prianka Mandal and B M Mainul Hossain presented a systematic literature review on checking and correcting spelling errors in Bangla language. Their investigate the current methods used for spell checking and find out what challenges are addressed by those methods. We also report the limitations of those methods. Recent relevant studies are selected based on a set of significant criteria. Their results indicate that there are research gaps in this research topic and has a potential for further investigation [5]. Ibrahim et al., 2017 presented a good literature review about Arabic Script Languages (ASL). In their review, they introduced the plagiarism detection techniques per year. They reviewed all publications from 2009 to 2017, as their results plagiarism detection techniques widely used for that language. Moreover, Ibrahim et al. presented the techniques that used for ASLs based on their review, most techniques used for Arabic language, then Persia and Urdu languages, but there is no publication exist for the Kurdish language [6].
Moreover wide range of research in natural language processing focuses on entities. These range from basic language tasks like coreference resolution to broader aggregation applications like sentiment analysis and information extraction. Building an accurate picture of an entity (e.g., aggregate sentiment toward the entity, entity tracking across websites, database population) requires an understanding of all the varying ways people refer to that entity. Tracking “Facebook” is not enough to know how people feel about it, as mentions of “fbook”, “FB”, and “the book” also need to be understood. Although many applications exist for tracking known mentions of entities, less research exists for detecting nicknames and aliases.
In other hand, aliases can also be formulated intentionally with a malicious or mischief plan in mind. This brand of aliases is most wicked and tough in terms of detecting them completely as they are created deliberately by playing with names and personal information. To find a quantifiable mapping criterion is still found to be an uphill task. This class of aliases is referred to semantic errors. Aliases can be based upon various underlying phenomenon such as typographic variations, semantic variations or orthographic & other resulting from their combined existence in the data set (Bilenko et al., 2003;
In this paper, we propose an extension to widely used (N-DIST) algorithms to detect vowel variations of Arabic names including other types of typographic variations. This paper is organized as follows. Section 2 illustrates some challenges of Alias detection. Section 3 describes the related work in field of study. Section 4 demonstrates the proposed algorithm for Alias Detection. Section 5 presents the experimental results and discussions. Finally conclusions and future work are presented in Section 6..
-
II. The face of Alias Detection
In this paper, we aim to detect aliases that occur due to transliteration variations in Arabic names. "Transliteration is the process of representing words from one language using the alphabet or writing system of another language" (Shaikh et al., 2012) [10]. Exact transliteration of the Arabic names to English (Latin alphabets) is a challenging task due to the fact that short vowels are not written in Arabic (Shaikh et al. ,2012)[10]. Branting (Branting et al., 2005) discussed reasons that make Alias Detection a challenging task due to various types of spelling variations. Branting describes eight types of aliases based on orthographic variations: crosslingual transliterations, misspelling, phonetic similarities, nicknames, titles, name changes, identifying phrases, name permutations, and omissions [9]. The Alias Detection poses several issues for English and Arabic language in following aspect (Alhagree et al., 2016;, Ahagree, Master’s thesis,2017) [11&12]:
The first issue, the reasons for appearing different include typing and OCR errors such as “Usama” is misspelled as “Usarna”.
The second issue, the cause of these errors to come as result of the keyboard adjacencies such as “Osama” is misspelled as “Usama”.
The third issue, is that if duplicate letter, repeated just in pronunciation such as “Barack obama” is misspelled as “Barrack Obama” and “Rajinikanth ” is misspelled as “. Raajinikanth”
The fourth issue, is that if deletion letter, removed just in pronunciation such as “Sylvester stallone” is misspelled as “Sylvester stalone” and “embarrass” is misspelled as “embarrass”.
The fifth issue, the insertion or deletion cost of a blank has been defined to be equals to zero beneficial to segmentations which might occur in names. Thus if a blank appears accidentally inside a name such as “the letter” is misspelled as “the letter”, “sylvesterstellone” is misspelled as “Sylvester stallone”, “ابو بکر” is misspelled as “ابوبکر” and “معمر القذافي” is misspelled as “معمرالقذافي ”.This enhancement is based on the observation that typographical variations occur more commonly due to transliteration or cultural difference. For example, "Osama bin Laden" and "Usama bin Ladan" are two strings, S1 and S2, respectively.
(Cross-Lingual Transliterations)There are certain names that can be changed phonetically and or structurally when transferred to a different language, e.g. “Joseph” in English is equivalent to the Italian name “Giuseppe” and is equivalent to the Arabic name “یوسف” and “father” in English is equivalent to the German “vater” and “far” in Norwegian. (Nicknames)There are some people who have more than one name such as pet name and nick name. For instance, one person can be called by his pet name or nick name instead if his first name or last name. In some cultures, the last name of a woman is changed to her husband's last name. Moreover, there are some people who can change their names during their lives.
(Phonetic Similarities) Phonetic error can considered as subcategory of cognitive errors. This can be occur when the writer confused between how the word is pronounced and how it is written , the writer substitutes letters into a word because he mistakenly mispronounced the word that lead him to misspelling the word. On the other hand, there are words which have the same pronunciation but different spelling.
In other cases , Punctuation can be used as a way to separate the parts of the names e.g., “ Owens Corning ” vs. “ Owens - Corning ” ; “ IBM ” vs. “ I.B.M. ”.
-
III. Related Work
The problem of entity alias detection has a close connection with the data matching problem (Christen et al., 2012) [13]. A brief survey of the related work in this research direction is presented below.
(Levenshtein, 1966) Levenshtein Distance (LD) introduces Edit distance algorithm which is used for (Pattern Matching) string processing [14]. This algorithm measures the difference between two string sequences. Levenshtein Distance counts the minimum number of single-character edits (Insertion, Substitution and Deletion) required to change name into the alias, where the cost of substitution is the same as the cost of insertion or deletion, depends on binary codes. This work does not consider the transposition operation of two adjacent characters.
(Jaro, 1989) introduced a string matching algorithm to find the similarity between two strings. This algorithm is based on three basic steps: (1) Compute the string length, (2) Find the number of common characters between two strings and (3) Calculate the number of transpositions (t). (Winkler et al.,, 1990) modified the Jaro algorithm stating that if the prefix is common in two strings then the similarity score is increased [17]. This enhancement of Winkler is based on the observation that most common typographic variations occur towards the end of a string. (Shaikh et al., 2011) they proposed an extension to basic ASM algorithms (Jaro and Jaro-Winkler) to enhance the efficiency of the basic algorithms to detect person name aliases [10]. This enhancement is based on the observation that typographical variations occur more commonly due to transliteration or cultural difference. For example, "Osama bin Laden" and "Usama bin Ladan" are two strings, S1 and S2, respectively. They introduced a new operation called "exchange of vowels" to increase the similarity scores of the basic algorithms. This operation can also be applied to extend some other ASM algorithm such as edit distance algorithm.
-
IV. The Proposed Technique
In this section, we presented an additional new edit operation, that is, ‘exchange of vowels’ (a, e, i, o, u, y).
This new edit operation is proposed to find the most commonly occurring orthographic and typographical errors especially in person names. The ‘exchange of vowels’ edit operation is introduced to account for the most commonly occurring spelling mistakes of vowels due to the converting names from one language to another.
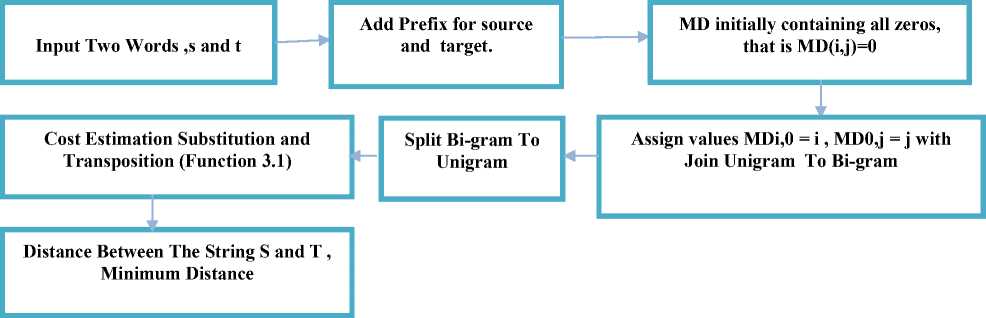
Fig.1. The Proposed Alias Detection System
The substitution of vowels in names is ignorable as compare to dictionary words. For example, (usama, osama) and (same, some) are two pairs of strings with only difference of vowels ‘o’ and ‘a’ in each pair of the string but you can see that in pair1 (usama, osama) in this case, the difference of vowels (‘o’ and ‘a’ ) is ignorable because it’s not influencing the meaning but in case of pair2 (same, some) the difference of ‘o’ and ‘a’ change the meaning of the two strings of pair2. So, on the basis of this observation that if the two names only have the difference of vowels then it can be assumed to be aliases, therefore we have introduce the ‘exchange of vowels’ edit operation to detect the name aliases more efficiently. According to our observation and analysis, these kind of aliases mainly occur because of the vowel variations because short vowels cannot be written in Arabic that’s why the vowelisation process is required, that is insertion of short vowels in target language (English in our case). For that reason, the new edit operation known as ‘exchange of vowels’ is proposed to detect these types of name variations (errors). The proposed new edit operation is added in the list of edit operations as stated in (Sanabani et al., 2015) of basic [21]. N-DIST algorithm and new algorithm named as ‘Adjusted N-gram Distance (A-N-DIST)’ see Figure 1. This operation listing vowels as ‘a, e, i, o, u, and y’, “character ‘y’ is particularly not a vowel but it sounds like a vowel and also a part of vowels in different languages such as Danish, Swedish, etc. Therefore, ‘y’ is included in the vowel’s list in order to detect the most commonly occurred typographic errors efficiently and accurately (Shaikh et al., 2012) [10]. This operation allows swapping and substitution of vowels from the list of vowels at reduced penalty cost that is 0.5. As a result of reducing penalty cost of the vowels in names especially in Arabic names the similarity scores of the name-alias pairs are described in Section 5.
Table 1. The proposed function for substitution operation.
Function. To Compute the Cost of Substitution of N-gram
Input: N-gram Letters (Letter1, Letter2)
Output: cost Substitution Distance (cost)
Decimal cost- Substitution-N-gram-Distance(a[i -1+ni], t[ni])
if (a[i -1+ni] ≠'a') or (a[i -1+ni] ≠'e') or (a[i -1+ni] ≠'i') or (a[i -1+ni] ≠'o') or (a[i -1+ni] ≠'u') or (a[i -1+ni] ≠'y') then cost 0.5
else cost cost +1 // cost++ end if return cost
-
V. Results and Discussion
This section gives details of experiments that have been carried out in this work to illustrate the proposed algorithm that is called (A-N-DIST) and compare it against the compared algorithm.
-
A. Dataset
-
B. Performance Measure
In the subsection, a comparative study is carried out to evaluate the performance of the proposed A-N-DIST algorithm. The first experiment has been carried for the proposed A-N-DIST algorithm and original N-DIST algorithm as compared algorithm with N equal to Bi and Tri (Bi=2, Tri=3) respectively. This experiment is carried based on Dataset 1 which has 10 pairs of names. The result of this experiment is shown in Table 1. The A-N-DIST Algorithm gives better results than the LD and N-DIST algorithms especially when comparing names transposition as shown in Table 1. For example, the names in 1 and 4 rows. Unlike the LD and N-DIST algorithms the A-N-DIST algorithm is sensitive to replacement as shown in 2, 3, 5 and 6 rows.
The A-N-DIST Algorithm handles a repeated letters, deletion and dictation errors more efficiently than the LD and N-DIST algorithms as shown in 7, 8,9 and 10 rows. The A-N-DIST algorithm shows many advantages over the LD, and N-DIST algorithms as aforementioned. Therefore, the A-N-DIST algorithm gives more accurate results than the LD and N-DIST algorithms with BI and TRI for all pairs in Dataset 1 as shown in Table 1. And Figure 2.In order to understand how the editing operations in the A-N-DIST algorithm works with variation of names, it will be elaborate of in detail in the following examples and as shown in Figure 3 shows how the N-DIST-A algorithm measures the distance between the name1 “abu abdallah” and name2 “abu abdalluh” as first step. The distance is 0.33, therefore, the similarity between them is 0.97 %. It is obvious that A-N-DIST algorithm gives a very low cost for replacing ‘a’ with “u” from name2 into name1 due to their form similarity. Furthermore, more experiments have been carried with a variety of datasets to get the evidence of A-N-DIST algorithm ability. Datasets are selected and applied on the LD, N-DIST and A-N-DIST algorithms with N=BI as shown in Table 2. That gives the evidence of A-N-DIST algorithm ability in Alias Detection. Table 2 shows the accuracy of the percentage similarity as an mean for Dataset 2. In this Table, the A-N-DIST algorithm gets 74.0% while LD and N-DIST algorithms get 45%, 40%, respectively. Therefore, the A-N-DIST algorithm gives more accurate results than the LD and N-DIST algorithms for dataset , because LD and N-DIST algorithms has not taken into account the characteristics and unique features Alias Detection. More details about the result can be found in Appendix A
Table 2.Comparison between algorithms in Alias Detection Dataset.
|
NO |
String. |
Compared Algorithm |
Proposed Algorithm |
|||||||||
|
LD |
N-DIST |
|||||||||||
|
BI |
TRI |
BI |
TRI |
|||||||||
|
S |
T |
Dist. |
Sim % |
Dist. |
Sim % |
Dist. |
Sim % |
Dist. |
Sim % |
Dist. |
Sim % |
|
|
1 |
abu abdallah |
abu abdalluh |
1.00 |
0.92 |
1.00 |
0.92 |
0.67 |
0.94 |
0.50 |
0.96 |
0.33 |
0.97 |
|
2 |
mujahid shaykh |
mujahid shaikh |
1.00 |
0.93 |
1.00 |
0.93 |
1.00 |
0.93 |
0.50 |
0.96 |
0.50 |
0.96 |
|
3 |
hussein al-sheik |
hassan ali-sheik |
4.00 |
0.75 |
4.50 |
0.72 |
5.17 |
0.68 |
2.25 |
0.86 |
1.92 |
0.88 |
|
4 |
osama bin laden |
usama bin laden |
1.00 |
0.93 |
1.50 |
0.90 |
1.83 |
0.88 |
0.75 |
0.95 |
0.92 |
0.94 |
|
5 |
usama bin ladin |
usama bin laden |
1.00 |
0.93 |
1.00 |
0.93 |
0.67 |
0.96 |
0.50 |
0.97 |
0.33 |
0.98 |
|
6 |
usama bin laden |
osama bin ladin |
2.00 |
0.87 |
2.50 |
0.83 |
2.50 |
0.83 |
1.25 |
0.92 |
1.25 |
0.92 |
|
7 |
abdel muaz |
abdul muiz |
2.00 |
0.80 |
2.00 |
0.80 |
1.67 |
0.83 |
1.00 |
0.90 |
0.83 |
0.92 |
|
8 |
abdal muaz |
abdel muiz |
2.00 |
0.80 |
2.00 |
0.80 |
1.67 |
0.83 |
1.00 |
0.90 |
0.83 |
0.92 |
|
9 |
abu mohammed |
abu muhammad |
2.00 |
0.83 |
2.00 |
0.83 |
1.67 |
0.86 |
1.00 |
0.92 |
0.83 |
0.93 |
|
10 |
ayman al- awahari |
ayman al-zawahiri |
2.00 |
0.88 |
2.00 |
0.88 |
2.00 |
0.88 |
1.00 |
0.94 |
1.00 |
0.94 |
|
Average (percentage similarity) |
0.86 |
0.85 |
0.86 |
0.93 |
0.94 |
|||||||
Table 3. The Distance Between “abu abdalluh” → “abu abdallah” in the A-N-DIST Algorithm with BI
|
-a |
ab |
bu |
u |
a |
ab |
bd |
da |
al |
ll |
la |
ah |
|
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
-a 1 |
0.00 |
1.00 |
2.00 |
3.00 |
4.00 |
4.50 |
5.50 |
6.00 |
6.50 |
7.50 |
8.00 |
8.50 |
|
Ab 2 |
1.00 |
0.00 |
||||||||||
|
bu 3 |
||||||||||||
|
2.00 |
0.00 |
|||||||||||
|
U 4 |
3.00 |
0.00 |
||||||||||
|
a 5 |
3.50 |
0.00 |
||||||||||
|
Ab 6 |
4.00 |
0.00 |
||||||||||
|
Bd 7 |
5.00 |
0.00 |
||||||||||
|
Da 8 |
5.50 |
0.00 |
||||||||||
|
Al 9 |
6.00 |
0.00 |
||||||||||
|
Ll 10 |
7.00 |
0.00 |
||||||||||
|
Lu 11 |
8.00 |
0.00 |
||||||||||
|
Uh 12 |
9.00 |
0.33 |
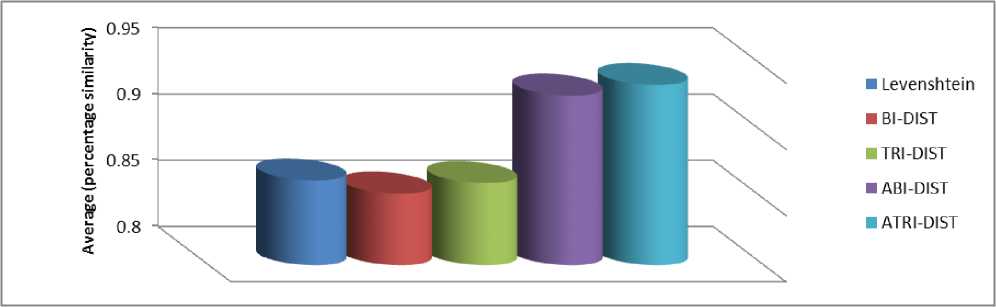
Fig.2. Average (percentage similarity
Table 4. The Average similarity of LD, N-DIST and A-N-DIST algorithms.
|
Compared Algorithms |
Proposed Algorithm |
|
|
Dataset 2 (100 pairs ) |
LD N-DIST |
A-N-DIST |
|
Average (percentage similarity) |
0.45 0.40 |
0.740 |
-
VI. Conclusion
This paper presents the proposed ‘adjusted N-gram Distance A-N-DIST that is the adjusted version of the basic N-DIST and LD. The adjustment is proposed to encounter the problem of aliases generated because of transliteration of Arabic names. Therefore, we have proposed the ‘exchange of vowel’ edit operation to deal this problem. This operation reduces the penalty cost for exchanging the vowels with each other in two strings (name and alias pair) to increase the similarity percentage between the true alias pairs as shown in the experimental results. In our future work we intend to apply our proposed algorithm to larger data set and to calculate the effects on precession and recall measures. Furthermore, we intend to categorize the ‘exchange of vowel’ operation as the vowels that sound like same can be transposition with less different penalty scores such as ‘i’, ‘e’ and ‘y’ in one category, ‘o’ and ‘u’ in other , and includes extracting other kinds of alias names like semantic aliases. Working with non-English language for extracting string variant alias has its own challenges.
References Design an accurate algorithm for alias detection
- J. Brynielsson, A. Horndahl, F. Johansson, L. Kaati, C. M°artenson, and P. Svenson, “Harvesting and analysis of weak signals for detecting lone wolf terrorists,” Submitted to Security Informatics, 2013.
- D. B. Neill 2002. Fully Automatic Word Sense Induction by Semantic Clustering. M.Phil Thesis. Cambridge University.
- D. Jurafsky and J. H. Martin 2000. An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Prentice-Hall.
- Muhammad Ghafoor, Mehyeddin Abdulrahman and Shvan Tariq: Plagiarism Detection System for the Kurdish Language” I.J. Information Technology and Computer Science journal, V.12, no. 64-71,2017.
- Prianka Mandal and B M Mainul Hossain: A Systematic Literature Review on Spell Checkers for Bangla Language ” I.J. Information Technology and Computer Science journal, V.6, no. 40-47,2017.
- R. Ibrahim, S. Saeed, and K. Wakil, "Plagiarism Detection Techniques for Arabic Script Languages: A Literature Review," Kurdistan Journal of Applied Research, vol. 2, no. 3, 2017.
- Ning An , Lili Jiang , Jianyong Wang , Ping Luo , Min Wang, Bing Nan Li , Toward detection of aliases without string similarity, Information Sciences 261,89–100 ,2014.
- M. Bilenko and R. J. Mooney. On evaluation and training-set construction for duplicate detection. In Proceedings of the KDD-2003 Workshop on Data Cleaning, Record Linkage, and Object Consolidation, pages 7-12, 2003.
- L. K. Branting. Name matching in law enforcement and counter-terrorism. In Proceedings of ICAIL 2005 Workshop on Data Mining, Information Extraction, and Evidentiary Reasoning for Law Enforcement and Counter- Terrorism.
- Shaikh, M. , Dar, H., Shaikh, A., and Shah, A. “Adjusted Edit Distance Algorithm for Alias Detection”, International Conference on Information and Knowledge Management , 2012 .
- Salah Alhagree and Maher A. Al-Sanabani, “ A Framework For Name Matching In Arabic Language”, 1st Scientific Conference on Information Technology and Networks, 2016.
- Salah Alhagree, “Design Algorithms for Matching English and Arabic Names” Master‟s thesis, Thamar University, Department of Computer Science. 2017.
- P. Christen, Data Matching – Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection, Springer, 2012. ISBN 978-3-642- 31163-5
- Levenshtein, Vladimir I. "Binary codes capable of correcting deletions, insertions, and reversals." In Soviet physics doklady, vol. 10, no. 8, pp. 707-710. 1966.
- Zhan Su, Byung-Ryul Ahn, Ki-yol Eom, Min-koo Kang, Jin-Pyung Kim, Moon-Kyun Kim" Plagiarism Detection Using the Levenshtein Distance and Smith-Waterman Algorithm"The 3rd Intetnational Conference on Innovative Computing Information and Control (ICICIC'08), 2008.
- yoke yie chen , suet-peng yong and adzlan ishak , "Email Hoax Detection System Using Levenshtein Distance Method", journal of computers, vol. 9, no. 2, february 2014.
- W. E. Winkler and Y. Thibaudeau. An application of the fellegi-sunter model of record linkage. Technical report, U.S. Decennial Census, Bureau of the Census, 1990.
- P. Hsiung, D. Andrew, W. Moore, and J. Schneider. Alias detection in link data sets. In Proceedings of the International Conference on Intelligence Analysis, 2005.
- L. Jiang, J. Wang, P. Luo, N. An, M. Wang, Towards alias detection without string similarity: an active learning based approach, in: Proceedings of the 35th Annual International ACM SIGIR Conference, 2012. Computer Science, 3772, Springer, Heidelberg, Germany, 115–126, 2005.
- P.Selvaperumal and A.Suruliandi , "String Variant Alias Extraction Method using Ensemble Learner",2016,
- Kondrak, G, “N-gram similarity and distance”, In M. Consens and G. Navarro (eds.), Proceedings of the String Processing and Information Retrieval 12th International Conference, Buenos Aires, Lecture Notes in
- Maher Sanabani, Salah Al-Hagree. ,“Improved An Algorithm For Arabic Name Matching”. Open Transactions On Information Processing ISSN(Print): 2374-3786 ISSN(Online): 2374-3778.2015.
- Abdulhayoglu, M. A , Bart Thijs , Wouter Jeuris , “Using character n-grams to match a list of publications to references in bibliographic databases” , DOI 10.1007/s11192-016-2066-3,2016.
- www.kalmasoft.com/KLEX/dbfamnm.htm.
