Design and Implementation for Malicious Links Detection System Based On Security Relevance of Webpage Script Text

Author: Xing Rong, Li Jun, Jing Tao
Journal: International Journal of Computer Network and Information Security(IJCNIS) @ijcnis
Article in issue: 3 vol.3, 2011.
Free access
With the development of web technology, spreading of Trojan and viruses via website vulnerabilities is becoming increasingly common. To solve this problem, we propose a system for malicious links detection based on security relevance of webpage script text and present the design and implementation of this system. Firstly, according to the current analysis of malicious links, we describe requirements and the general design for detection system. Secondly we describe the security-related algorithm with mathematical language, and give the data structure of this algorithm. Finally, we analyze and summarize the experimental results, and verify the reliability and rationality of system.
Text analysis, security relevance, malicious links
Short address: https://sciup.org/15011021
IDR: 15011021
Text of the scientific article Design and Implementation for Malicious Links Detection System Based On Security Relevance of Webpage Script Text
Published Online April 2011 in MECS
With the popularity of web technology, website security problems become more and more popular, viruses and Trojan spread faster through the sites. The way that viruses and Trojan spread through the network software has becomes difficult. Now using vulnerabilities of host application to execute malicious code has become the main way to spread viruses and malware [1, 2]. Hackers use free web space or website intrusion to embed virus’s code. The webpage script code text of web Trojan
*This work is supported by Knowledge Innovation Program of Chinese Academy of Sciences, Youth Foundation of Computer Network Information Center, Chinese Academy of Sciences.(Grant No. CNIC_QN_10001)
links is shown as Fig. 1:
<1frame src=http://www. hudieer. com/wangye/inc/pic/DarkTearn, htm width=0 hei ght=0X/ifr ameXi frame src= http://www. hudieer. com/wangye/inc/pic/TZD. htm width=0
hei ght=0X/ifr ameXi frame src=http: //yeweiqun. linn, net /TZD. html width=0 height=OX/ifr ameXi frame src=http://yeweiqun. linn, net/b/MPEG-2. htm width=0
hei ght=0X/i fr ameXi frame src=http: //yeweiqun. linn, net/b/Firefox, htm width=0
hei ght=0X/i fr ameXi frame src=http: //yeweiqun. linn, net/b/Firefox, htm width=0
hei ght=0X/i fr ameXcent er >
-
Figure 1. Web Trojan links in the webpage script text
Some links in the webpage are not web Trojan links, but they are malicious links which Hackers embed into the webpage script text to improve their own sites ranking. These malicious links also pose a threat to website security and they are usually related with online games or Internet advertisement. The webpage script code text of malicious links is shown as Fig.2:
'
# ■Й^ДЖ^/hlX/aXbr /Ха href="http://www. missS. net" title="'|'^"or^A^ "XhlM^^^A^^/hlX/aXbr /Ха href="http://www. sdqcwh. com" title^^t^W'XhlM^ir^^/hlX/aXbr /Ха href="http://www. xz0888. com" title="^^^^''Xhl>^^$yi|i?
^^^Д^^/ЫХ/аХЬг /Ха href-"http://www. com0515. com" title-''^^ ^ДЖ"ХЬ1>^^^ДЖ^/Ь1Х/аХЬг /Ха href="http://www. jn-tt. com" titles"^<ШК"ХЫ>#<М<Л1Х/аХЬг /><Ы>-№чГ$МЕ
^^^ДЖЫХ/аХЬг /Ха href="http://мт. cjl959. com" titled ^?^"^аЖ Х^ЫЯу^^Ж^/Ь1>а><Ьг /Ха href="http://«™. adsl2008. com" 1111е="^"^"МЖ"ХЬ1>#^"^ДЖ ^^■^ДЖ/AlX/aXbr /Ха href="http://raw. u55. cc" 11Г1е="{ф^^ Ж"><Ы>-{^^"^АЖ<Л1Х/аХЬг /Ха href="http://мт. 1214. cc" title=" ■Т^^Т^АЖ"ХН1>-{ф""пГ^АЖ9/Ь1Х/аХЬг /Ха href="http: //та™. 3657. cc" title="#^W"Xhl>#
-
Figure 2. Malicious links in the webpage script text
To deal with these security threats, research work for website security technology is constantly evolving. Many studies focused on Honeypot technology to address security threats [11, 12, 13]. In addition, with the development of research in webpage text mining [4, 6, 7, 8, 9], the technology of Trojan detection based on web script code text analysis emerged as the times require, this technology commonly used the method of text feature matching with Trojan detecting rules. Compared with the technology of Trojan detection with honeypot, the technology of website script text feature matching with Trojan detecting rules is suitable for scanning large scales of websites with its low cost and short time cost [5]. However, this method of website script text feature relies on the characteristics of the malicious links library in advance, so it’s difficult to find the newer malicious web links. The efficiency and accuracy for the technology of website script text feature with Trojan detecting rules can not be guaranteed.
In order to predicate the probability for some webpage links are malicious link, we present an analysis system based on web script text for website security, which can determine probability of webpage malicious links with computing correlation in sets of words from some special webpage scripts code text, and is verified by experiments that the system can improve the efficiency and accuracy for malicious links detection.
The remainder of this paper is organized as follows: We describe related work in section 2. Then we present requirement of the system in section 3. In section 4, we propose the general design of this system. Then we propose the mathematical representation of security relevance algorithms and design the data structure of algorithms. In section 8, we show the results of the experiments based on this system. Finally, we summarize our results and future works in section 9.
detects malicious links based on honeypot principle, while the other one uses the characteristics of the malicious links. Dr ZHUGE Jian-wei from Institute of Computer Science and Technology, Peking University put an automated malware collection tool based on the high-interaction honeypot principle forward. He focused on the use of honeypot technology to build malicious code automatically capture and collection system[3]. CHEN Ling from Institute of Information Security Engineering, Shanghai Jiaotong University presented a Web Trojan detection scheme based on HoneyClient which is an efficient client-side honeypot system[14]. WU Run-pu from Institute of Information Security, Sichuan University proposed a Web Trojan detecting model based on statistics and analysis of code characteristics [10].
Research studies on webpage text mining have recently gained lots of attentions. But, current studies of webpage script text feature matching with Trojan detecting rules focus on the characteristics of malicious links, there are lots of information for Web mining. So we propose a system for malicious links detection based on security relevance of webpage script text and present design and implementation of this system.
III S ystem R equirement
The requirement of system is based on the prevailing scenario and necessity pointed out in the introduction. The basic requirement can be summarized as below:
-
• System must be able to detect malicious links which have been known.
-
• System must be able to detect malicious links which have obvious characteristics.
-
• System must be able to report links which have high probability of being malicious links.
-
• The system must have a model which is able to calculate the probability of web links being malicious links.
-
• The model of system must be feasible in the level of mathematics.
-
• System must be able to complete the detection task within an acceptable time.
-
• System must be able to provide a query interface for users.
In order to meet the requirement, the system has been designed as discussed in the next section.
IV S ystem D esign
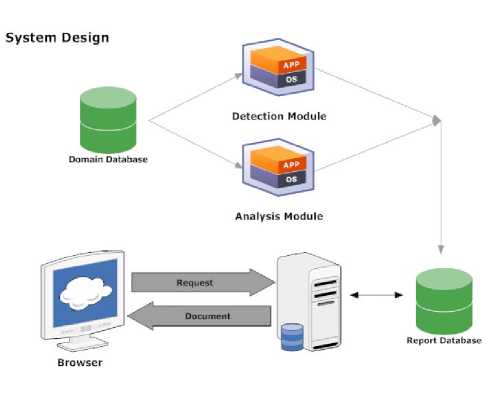
The system is developed to detect malicious links in webpage script and analyze the probability of web links being malicious links. From this point of view, the system is devised as Fig.3:
II R elated W ork
In general, current studies for malicious links detection are classified into two categories: The first one
-
Figure 3.General design of the detection system
The overall system architecture is shown in Fig. 3. The basic components of the system are: • Domain database.
Domain database stores webpage script texts of websites that need to be detect if have malicious links.
-
• Detection Module.
Detection Module detect malicious links in webpage script based on known characteristics
-
• Analysis Module.
Analysis Module determine the probability of web links being malicious links based on analysis mathematical model.
-
• Report Database.
Report Database stores reports of malicious links and suspicious malicious links which are used to provide a query interface for users.
In analysis module, we introduce the concept of correlation to analyze malicious links. Correlation determines the possibility of a link being malicious link. So the general flow chart of the system is shown as Fig. 4:
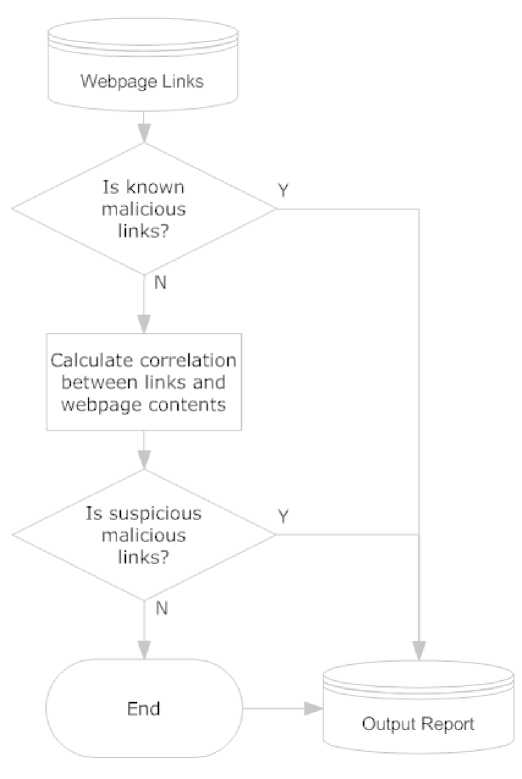
Webpage Links "-—~T—~"
End
Output Report
Is known malic ous links?
Is susp ci Ous malic ous links?
Calculate correlation between inks and webpage contents
Figure 4.Flow chart of the detection system
This article focuses on the analysis of suspicious malicious links. So in the next section, we introduce the mathematical model of suspicious malicious links analysis.
V M athematical R epresentation O f A nalysis M odule
-
A. Related Concepts
-
1) UL and SL
By analysing the correlation between web links and web contents, the model determines probability of webpage malicious links, so we can define the concept as follows:
Unsafe Links : Web links that have the probability of being malicious links, denoted by
UL = {u l , ul , ul , L , ul } 1 , 2 , 3 , , m
Safe Links : Web links that have no probability of being malicious links, denoted by
SL = { sl 1, sl 2, sl 3, L , sln }
-
2) Effective Keywords
Unsafe links and safe links cannot be directly used for the calculation of correlation, so define the concept as follows:
Effective Keywords : set of the keywords that can be used to calculate the correlation.
Effective keywords of unsafe links are denoted by
KU = {{kU i },{ ku 2 },{ ku 3}, - ,{ kU m }}
Effective keywords of unsafe links are denoted by
KS = {{ ks . },{ ks 2Ы ks 3 }, - ,{ ks n }}
-
3) AI and NAI
Calculating correlation needs information of web contents, so define the concept as follows:
Authoritative Information : Key information that represents the webpage significance, denoted by
KAI = {kaipkai2,kai3, - ,kai k }
Non-authoritative Information : Information that can’t represent the web significance, but it is correlated with web contents. In this model, safe links are the non-authoritative information.
-
B. Calculation of Correlation Modulus
Calculation of CMAI
Define the relationship between KU to KAI ц = { < { ku }, kai > \aai £ { ku }}
Expressed in matrix form:
' b ii - b k'
m = m о m
и bLb m1 mk
( 1 )
Matrix elements value 1 or 0. Sum of each row is:
-
C. Calculation of Correlation
CMW is calculated according to CMAI and CMNAI, which the probability of web links being malicious links is determined by.
-
1) Calculation of CMW
As in the determination of correlation, authoritative information is more convincing; the weight of CMAI is greater than the weight of CMNAI. So CMW is calculated as:
CMW = l + mt i (0 < l < m ;0 < t i < k ; i = 1,2, - , m ) (5)
-
2) Calculation of Correlation
Correlation between unsafe links and web contents is expressed as followed:
C o rrelation modulus weighted
C o rrelation =------------------------------
Sum of all elements
Then we can draw a formula as below:
l + mt f (i) = —----— (0 < li < m ;0 < ti < k;
m + n + mk i = 1,2,L, m) (6)
-
m + n is the number of all web links.
f (1), f (2), f (3), L , f ( m )
Define , , , , as correlation between unsafe links
{u l , ul , ul , L , ul }
1, 2, 3, , m and web
contents.
The more correlation close to zero, indicating that the greater probability of web links being Malicious links is, vice-versa.
m = m *
t ц
' *\
t
V m V
( 2 )
Define { t 1, t 2, t 3, L , tm } as CMAI of unsafe
{u l , ul , ul , L , ul } links 1, 2, 3, , m
2) Calculation of CMNAI Define the relationship between KU to KS
0 = { < {ku}, { ks } > |{ ku } n { ks } ^ ф }
Expressed in matrix form:
a 11
a 1 n
M 0
V a
a mn
( 3 )
Mi =
Matrix elements value 1 or 0. Sum of each row is:
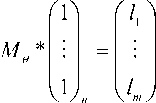
( 4 )
Define { l 1, l 2, l 3, L , lm } as CMNAI of unsafe
{u l , ul , ul , L , ul } links 1, 2, 3, , m
VI M odel D escription O f A nalysis M odule
Model describes the relationship between the elements (unsafe links, safe links, authoritative information, non-authoritative information and webpage content), the model is defined as a quintuple:
A (Algorithm) = {UL, SL, AI, NAI, WC}
-UL( U nsafe L inks) : Web links that have the probability of being determined malicious links
-SL( S afe L inks) : Web links that have no probability of being malicious links
-AI( A uthoritative I nformation) : Key information which can represents the webpage significance
-NAI( N on- A uthoritative I nformation) :
Information that can’t represent the webpage significance, but it is correlated with webpage contents. In this model, safe links are the non-authoritative information.
-WC( W ebpage Script Text C ontent) : Information of the webpage script code text contents
UL = { Lp L 2 , L 3 , - , L m }
- L ( links ) = { CMAI , CMNAI , CMW }
---CMAI: Correlation modulus for authoritative information
---CMNAI: Correlation modulus for non-authoritative information
---CMW: Correlation modulus for web
VII D esign O f A nalysis M odule
Based on the above discussion, analysis module is designed as followed. Module process is divided into four steps:
Step 1. Information Extraction
Extract the unsafe links, non-authoritative information and authoritative information from the webpage. In this model, safe links are the non-authoritative information.
Step 2. Information Pre-processing
Remove the interference words from the extracted information which can be used to calculate correlation, such as www, cn, us, de, and so on.
For example, if the extracted information is “”, the words “www”, “hk” and dot are the interference words.
Step 3. Calculation of Correlation Modulus
Calculate CMAI according to the correlation between unsafe links and authoritative information, and calculate CMNAI according to the correlation between unsafe links and non-authoritative information. Model specifically addressed as follows:
Г if L i n AI * ф , then L i .CMAI = Max
Flow chart of core code for calculating CMAI is shown in Fig. 5:
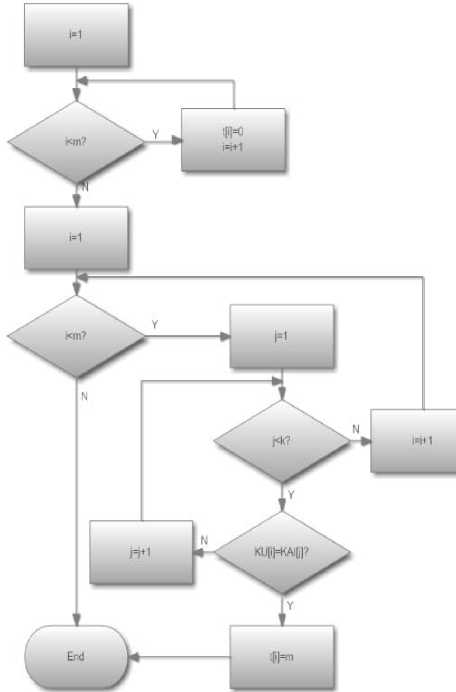
Figure 5.Flow chart of core code for calculating CMAI
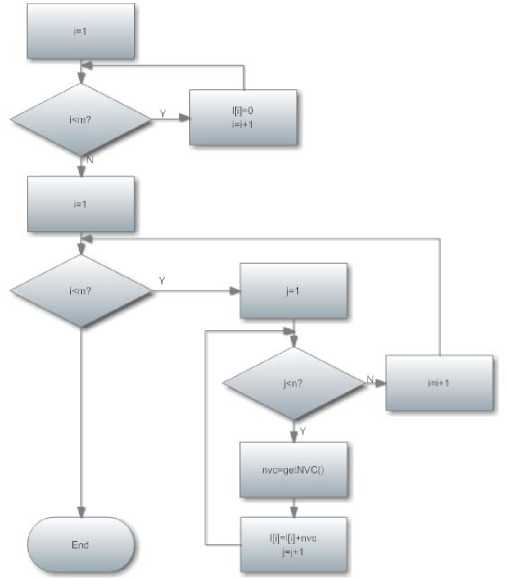
Flow chart of core code for calculating CMNAI is shown in Fig. 6:
-
f igure 6. f low chart of core code for calculating cmnai
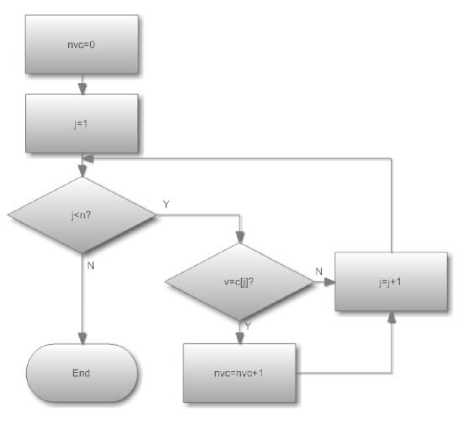
Function getNVC() is to calculate the correlation between one unsafe link and all safe links, of which flow chart is shown in Fig.7:
-
f igure 7. f low chart of function get nvc()
Step 4. Correlation Analysis
Calculate CMW according to CMAI and CMNAI, which the probability of webpage malicious links is determined by.
VIII E xperimental A nalysis
The main parameters of experimental environment are shown as Table I:
Design and Implementation for Malicious Links Detection System Based On
Security Relevance of Webpage Script Text
TABLE I. P arameters of experimental environment
|
Experimental environment |
Parameters |
|
CPU |
Intel(R) Xeon(R) CPU E5620 @ 2.40GHz |
|
Memory |
48G |
|
Hard Drive |
3T |
|
Network Interface Card |
Intel PRO/1000 VT Quad Port Server Adapter |
|
Operating System |
Red Hat Enterprise Linux Server 5.0 |
-
A. Information Extraction
Extract the unsafe links, non-authoritative information and authoritative information. We select some of the set of unsafe links:
UL = {, , ,L }
We select some of the set of safe links:
SL = { /dsn/, , ,L }
-
B. Information Pre-treatment
Remove the interference of the extracted information and extract sets of effective keywords which can be used to calculate correlation.
Effective keywords of unsafe links are as followed:
KU ={{ newspaper , dufe },{80 xiazai },{zhaosfpk}, L }
Effective keywords of safe links are as followed:
KS ={{ dufedsn },{ showtime , dufe },{ youth , dlmu }, L }
Effective keywords of authoritative information are as followed:
KAI ={colors,dufe}
-
C. Calculation of Correlation Modulus
According to the formula (1) and formula (2), calculate CMAI with effective keywords of unsafe links and authoritative information. According to the formula (3) and formula (4), calculate CMNAI with effective keywords of unsafe links and non-authoritative information.
-
D. Correlation Analysis
According to the formula (5) and formula (6), calculate CMW with CMAI and CMNAI, according to which we calculate correlation between unsafe links and web contents.
We select some of the correlation between unsafe links and web contents shown in Table II and Fig. 8:
TABLE II.C orrelation between unsafe links and web CONTENTS
UL KU l t f {newspaper,dufe} 91 1 0.62 {80xiazai} 0 0 0 {zhaosfpk} 0 0 0
Correlation
1.2
References Design and Implementation for Malicious Links Detection System Based On Security Relevance of Webpage Script Text
- ZHUGE Jianwei, YE Zhiyuan, ZOU Wei. “Research on Classification of Attack Technologies” [J]. Computer Engineering,Vol.31, No.21, pp.121-126, 2005.
- LUO Chuan,XIN Mingting,LING Zhixiang. Analysis and realization of the web Trojan horse [J]. NETWORK & COMPUTER SECURITY,Vol.12, pp.83-85, 2007.
- ZHUGE Jianwei , HAN Xinhui , ZHOU Yonglin. HoneyBow: an automated malware collection tool based on the high-interaction honeypot principle [J]. Journal on Communications,2007,28(12):8-13.
- E. Glover, K. Tsioutsiouliklis, S. Lawrence, D. Pennock, and G. Flake. Using web structure for classifying and describing web pages. In Proc. of WWW, Hawaii, USA, May 2002. ACM Press.
- WU Runpu, FANG Yong, WU Shaohua. Web Trojan Detection Model Based on Statistics and Code Characteristics Analysis [J]. Information and Electronic Engineering,Vol.1, pp.71-75, 2009.
- A. Sun and E.-P. Lim. Web unit mining – finding and classifying subgraphs of web pages. In Proc. of 12th ACM CIKM, pages 108–115, New Orleans, LA, USA, Nov. 2003.
- Han J, Kamber M. Data Mining: Concepts and Techniques SanMateo, CA: Morgan Kaufmann, 2000.
- HAN Jia-Wei, MENG Xiao-Feng, WANG Jing, and LI Sheng-En. Research On Web Mining: A Survey [J]. JOURNAL OF COMPUTER RESEARCH & DEVELOPMENT, Vol. 38, No. 4, pp. 405-414, 2001.
- XUE Wei-min and LU Yu-chang. Research On Text Data Mining [J]. Journal of Beijing Union University(Natural Sciences), Vol. 19, No. 4, pp. 59-63, 2005.
- WU Runpu, FANG Yong, WU Shaohua. Web Trojan Detection Model Based on Statistics and Code Characteristics Analysis [J]. Information and Electronic Engineering,Vol.1, pp.71-75, 2009.
- LEVINE J, GRIZZARD J, OWEN H. Application of a methodology to characterize rootkits retrieved from honeynets[A]. Proceedings of the Fifth Annual Information Assurance Workshop[C]. West Point, NY, USA, 2004. 15-21.
- PROVOS N. A virtual honeypot framework [A]. Proceedings of 13th USENIX Security Symposium[C]. San Diego, CA, USA, 2004. 1-14.
- Ali Ikinci, Thorsten Holz, Felix Freiling. Monkey-Spider : Detecting Malicious Websites with Low-Interaction HoneyClients[C]//Gesellschaft für Informatik. Proceedings of Sicherheit. Mannheim : University Mannheim,2008:233-244.
- CHEN Ling, WANG Yi-jun and XUE Zhi. Detection of Web-site with Trojan Based on HoneyClient [J]. CHINA INFORMATION SECURITY, Vol. 5, pp. 75-77, 2010.
