Дифференциация регионов ДФО по показателям уровня жизни населения

Автор: Бушин П.Я.
Журнал: Вестник Хабаровской государственной академии экономики и права @vestnik-ael
Рубрика: Проблемы социально-экономического развития Дальнего Востока России
Статья в выпуске: 2, 2017 года.
Бесплатный доступ
В статье на основе модели панельных данных (модель с фиксированными эффектами) и дисперсионного анализа показана неоднородность регионов ДФО по отдельным показателям уровня жизни населения. Полученная неоднородность затем идентифицировалась с помощью дополнительного анализа полученных показателей индивидуальных эффектов, и на основе дисперсионного анализа проанализирована динамика изменения показателей уровня жизни в анализируемом периоде.
Регионы, уровень потребления, панельные данные, индивидуальные эффекты, дифференциация, дисперсионный анализ
Короткий адрес: https://sciup.org/14319507
IDR: 14319507
Текст научной статьи Дифференциация регионов ДФО по показателям уровня жизни населения
Понятия «уровень жизни» и «качество жизни» являются предметом изучения во многих исследованиях. В современной научной литературе эти понятия трактуются по-разному в зависимости от целей и задач исследования [1]. Более узко под уровнем жизни понимаются обеспеченность населения необходимыми материальными благами и услугами, достигнутый уровень их потребления и степень удовлетворения разумных (рациональных) потребностей. К материальным обычно относят потребности в питании, одежде, жилье, платных услугах, предметах быта, транспорте, здоровье и др.
В настоящем исследовании будет рассмотрена только часть показателей экономической составляющей уровня жизни, таких как валовой региональный продукт на душу населения, потребность в продуктах питания (мясо и мясопродукты, молоко и молочные продукты, картофель,овощи и продовольственные бахчевые культуры, хлебные продукты), жилье (общая площадь жилых помещений в среднем на одного жителя), качество здравоохранения (число больничных коек на 1000 жителей, заболеваемость на 1000 населения с диагнозом, установленным впервые в жизни). Для краткости будем обозначать их как ВРП, мясо, молоко, картофель, овощи, хлеб, жильё, больничные койки и здоровье.
Автор не ставил своей целью делать обзор литературы по изучению уровня жизни. В данном исследовании иллюстрируются только возможности использования статистических методов, таких как анализ панельных данных и кластерный анализ, в дифференциации регионов по отдельным показателям, характеризующим уровень жизни населения регионов, а также динамику этих показателей в анализируемом периоде. Понятно, что в практическом использовании этих методов с указанными целями перечень показателей может быть расширен до необходимого в каждом конкретном случае. Для анализа зависимости показателей уровня жизни в регионах ДФО от доходов населения были проанализированы отдельные данные по уровню жизни населения по девяти регионам ДФО, для каждого региона за 15 лет (2000–2014 гг.). Эти данные представляют собой классический случай сбалансированных панельных данных (макро-эконометрическая выборка).
Перечень и нумерация регионов ДФО в данном исследовании следующая: 1 – Республика Саха (Якутия), 2 – Камчатский край, 3 – Приморский край, 4 – Хабаровский край, 5 – Амурская область, 6 – Магаданская область, 7 – Сахалинская область, 8 – Еврейская автономная область (ЕАО), 9 – Чукотский автономный округ (Чукотка).
Анализ на основе моделей панельных данных
В данной части исследовании будет использоваться модель панельных данных с фиксированными эффектами. Как показал опыт подобных исследований [2], эта модель более адекватно отражает особенности таких исследований по сравнению с моделью со случайными эффектами. Как известно, модели панельных данных позволяют вы- яснить, различаются ли анализируемые объекты (у нас регионы) по анализируемым признакам (независимо от времени) на индивидуальном уровне, и если различаются, то значимое ли это различие. Иными словами, анализ панельных данных позволяет уловить эффект неоднородности регионов по признакам, в том числе и не наблюдаемым, который не изменяется во времени. Несмотря на то, что временные эффекты в явном виде в таких моделях не моделируются, панельные данные содержат информацию относительно развития объектов и во времени.
Рассмотрим сначала применение моделей панельных данных для дифференциации регионов ДФО по показателям «расходы – доходы» (функция потребления).
Уравнение регрессии, описывающее зависимость расходов населения регионов (consmons) от их доходов (DOHOD), с учётом структуры панельных данных (модель с фиксированными эффектами) показано на рисунке 1. На рисунке 2 показаны графики исходных данных, модельных данных и остатков модели (нижние цифры на графике – это номера регионов, а над ними – годы). Как видно из показателей точности уравнения регрессии, уравнение достаточно точно аппроксимирует зависимость расходов от доходов (R-squared =0,97), а график остатков достаточно часто пересекает нулевую линию, и фактические и расчётные значения расходов плотно прилегают друг к другу (кроме последнего региона (Чукотка)). Тест Вальда (рисунок 3) показал, что эти эффекты значимо различаются (prob. = 0), то есть неоднородность регионов по анализируемым характеристикам (доходы – расходы) существенная.
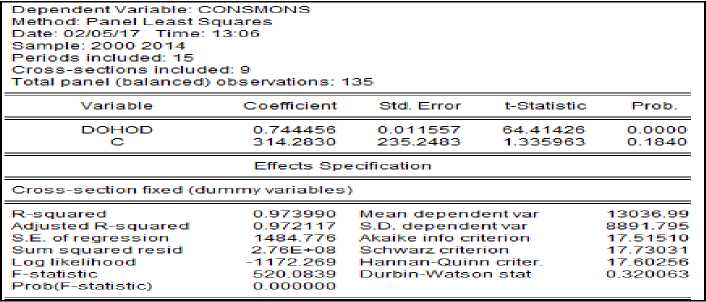
Рисунок 1 – Модель с фиксированными эффектами
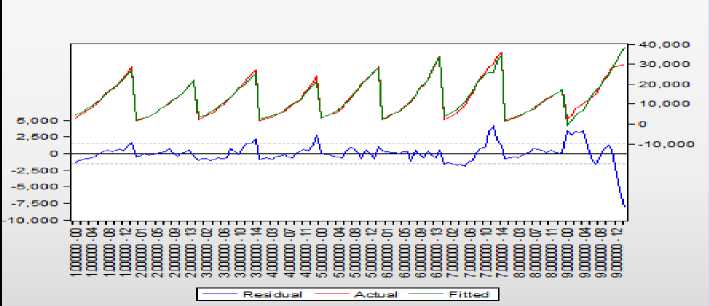
Рисунок 2 – График исходных данных, подогнанных данных и остатков
|
Redundant Fixed Effects Tests Equation: Untitled Test cross-section fixed effects |
|||
|
Effects Test |
Statistic |
d.f. |
Prob. |
|
Cross-section F |
21.312031 |
(8,125) |
0.0000 |
|
Cross-section Chi-square |
116.146224 |
8 |
0.0000 |
Рисунок 3 – Тест Вальда
По величинам индивидуальных эффектов (рисунок 4) можно ранжировать регионы и на основе дополнительных исследований сделать выводы о причинах различий регионов по анализируемым показателям. Сами эффекты не дают какой-либо информации о причинах неод- нородности регионов по рассматриваемым показателям. Как отмечается [3], если один регион отличается от другого, то это просто потому, что это другой регион. Дополнительные же исследования позволят выявить причины неоднородности регионов. Проведём эти исследования.
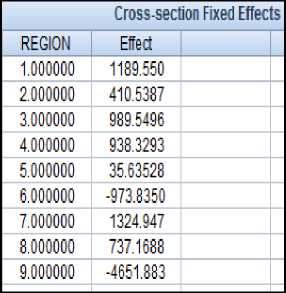
Рисунок 4 – Фиксированные индивидуальные эффекты
Ранжируем регионы по величине эффектов (в порядке возрастания величин эффектов с учётом знака). Получили: 9 6 5 2 8 4 3 1 7. Здесь записаны номера регионов в порядке их следования на рисунке 4 по величинам эффектов, первая цифра 9 означает, что регион под номером 9 (Чукотка) имеет наименьшую величину эффекта (-4651,883) по сравнению с другими регионами и далее – по возрастанию величин эффектов.
В моделях подобного типа (расходы – доходы) коэффициент уравнения регрессии называют коэффициентом склонности к потреблению. Этот коэффициент показывает, какая часть дополнительных доходов расходуется, а какая идёт на накопление. Расчёты показали, что в среднем по всем регионам этот коэффициент равен 0,74.
Аналогичные коэффициенты для отдельных регионов следующие: Чукотка – 0,57, Магаданская область – 0,74, Камчатский край – 0,75, Приморский край – 0,76, ЕАО – 0,78, Амурская область – 0,84, Хабаровский край – 0,84, Якутия – 0,83, Сахалин – 0,86.
Если ранжировать регионы по этому показателю, то получим тот же порядок, что и ранжирование по величине фиксированных эффектов, следовательно, ранее полученные ранги по фиксированным эффектам показывают, какая часть доходов в регионах идёт на накопление (по убыванию). Таким образом, больше денежных средств идёт на накопление в таких регионах, как Чукотка, Магаданская область, Камчатский край, Приморский край и ЕАО, большая доля доходов расходуется в Хабаровском крае, Якутии и на Сахалине.
Чукотка и Сахалин в этом смысле оказались на крайних полюсах: на Чукотке доля доходов, идущая на накопление равна 0,47, а на Сахалине – 0,16. Подобная дифференциация довольно простая и при необходимости легко применима.
Применим её для дифференциации регионов по другим показателям уровня жизни населения. Начнём с показателей уровня потребления продуктов питания. Для этого просчитаем по моделям панельных данных зависимость потребления разных видов продуктов питания.
Сначала рассчитаем обобщённую модель зависимости уровня потребления мяса (meate) от доходов. Обобщённая модель не учитывает структуру панельных данных. На графике (рисунок 6) нет чёткой картины неоднородности в потребле- нии мяса по регионам (цифры внутри графика означают: первая – номер региона, вторая – год, третья – расчётный уровень потребления). Эта модель как бы уравняла уровень потребления мяса по всем регионам: сначала занизила его, а затем завысила по сравнению с фактическими значениями. Модель описывает всего около 24 % изменения потребления мяса в зависимости от изменения доходов (рисунок 4 – R-square=0,238). Рассчитаем модель с фиксированными эффектами, которая учитывает структуру панельных данных (рисунок 7). Эта модель более точно аппроксимирует фактические значения моделью и даёт более чёткую картину дифференциации в потреблении мяса по регионам (рисунок 8).
Dependent Variable: MEATE
Method: Panel Least Squares
Date: 02/07/17 Time: 12:46
Sample: 2000 2014
Periods included: 15
Cross-sections included: 9
Total panel (balanced) observations: 135
Variable Coefficient Std. Error t-Statistic Prob.
Рисунок 5 – Обобщённая модель
DOHOD 0.000666 0.000103 6.446067 0.0000
C 50.56543 2.177948 23.21700 0.0000
|
R-squared |
0.238 0 48 |
Mean dependent var |
61.94815 |
|
Adjusted R-squared |
0.232319 |
S.D. dependentvar |
16.90594 |
|
S.E. of regression |
14.81254 |
Akaike info criterion |
8243529 |
|
Sum squared resid |
29181.71 |
Schwarz criterion |
8.286570 |
|
Log likelihood |
-554.43 82 |
Hannan-Quinn criter. |
8.261020 |
|
F-statistic |
41.55178 |
Durbin-Watson stat |
0.034736 |
|
Prob(F-statistic) |
0.000000 |
Рисунок 6 – График фактических и расчётных значений и остатки обобщённой модели
|
Dependent Variable: MEATE Method: Panel Least Squares Date: 02/07/17 Time: 12:41 Sample: 2000 2014 Periods included: 15 Cross-sections included: 9 |
|||
|
Total panel (balancer |
i) observations: 135 |
||
|
Variable |
Coefficient |
Std Error t-Statistic |
Prob. |
|
DOHOD |
0.000797 |
4.26E-05 18.71855 |
0.0000 |
|
C 48.33461 0.866220 55.79947 Effects Specification Cross-section fixed (dummy variables) |
0.0000 |
||
|
R-squared |
0.902444 |
Mean dependent var |
61.94815 |
|
Adjusted R-squared |
0.895420 |
S.D. dependent var |
16.90594 |
|
S.E. of regression |
5.467170 |
Akaike info criterion |
6.306586 |
|
Sum squared resid |
3736.243 |
Schwarz criterion |
6.521792 |
|
Log likelihood |
-415.6946 |
Hannan-Quinn criter. |
6.394040 |
|
F-statistic Pro b(F-stati sti c) |
128.4802 0.000000 |
Durbin-Watson stat |
0.281433 |
Рисунок 7 – Модель с фиксированными эффектами
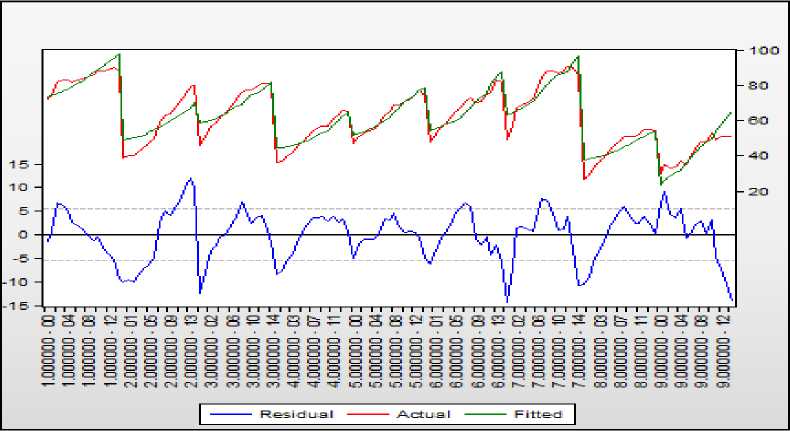
Рисунок 8 – График остатков, фактических и расчётных значений модели с фиксированными эффектами
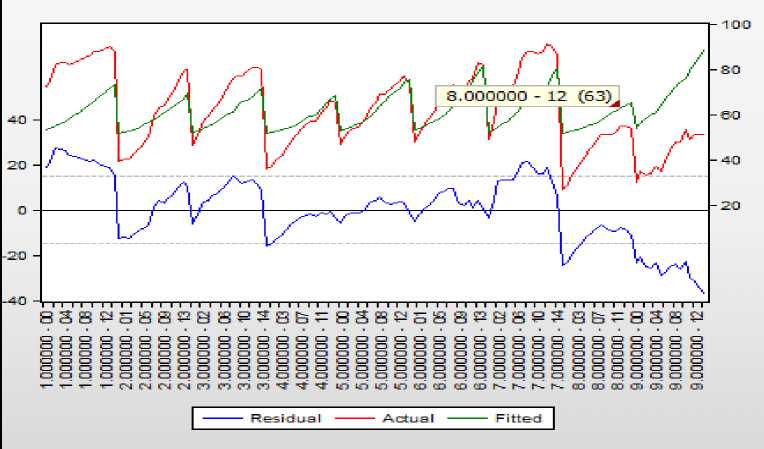
Так, наибольший уровень потребление мяса в Якутии и на Сахалине (1-й и 7-й регионы), а в меньшей мере – в ЕАО и на Чукотке (8-й и 9-й регионы), но на Чукотке темп рост больше (линия, описывающая динамику показателя, круче).
Тест Вальда показал, что различия в регионах по уровню потребления мяса статистически значимы (prob. для F-статистики = 0,00). Аналогично предыдущему ранжируем регионы по величине эффектов (рисунок 10 с учётом знака).
Redundant Fixed Effects Tests Equation: Untitled
Test cross-section fixed effects
|
Effects Test |
Statistic |
d.f. |
Prob. |
|
Cross-section F Cross-section Chi-square |
106.413137 277.487289 |
(8,125) 8 |
0.0000 0.0000 |
Рисунок 9 – Тест Вальда
|
Cross-section Fixed Effects |
|
|
REGION |
Effect |
|
1.000000 |
21.88008 |
|
2.000000 |
-0.649187 |
|
3.000000 |
8.200385 |
|
4.000000 |
-5 383549 |
|
5.000000 |
0.864469 |
|
6.000000 |
2.919332 |
|
7.000000 |
12.86079 |
|
8.000000 |
-11.92835 |
|
9.000000 |
-28.76396 |
Рисунок 10 – Индивидуальные фиксированные эффекты
Получим 9 8 4 2 5 6 3 7 1. И снова Чукотка оказалась на последнем месте по уровню потребления мяса, а наиболее высокий уровень потребления в Якутии. Ту же картину мы видели, анализируя рисунок 8. Рассмотренный метод дифференциации регионов по уровню потребления продуктов является довольно простым как в применении, так и в интерпрета- ции и может быть использован при практическом применении в аналогичных исследованиях.
Рассмотрим далее дифференциацию регионов по потреблению других видов продуктов.
Если просчитать обобщённую модель по молоку, то получим данные, указанные на рисунке 11.
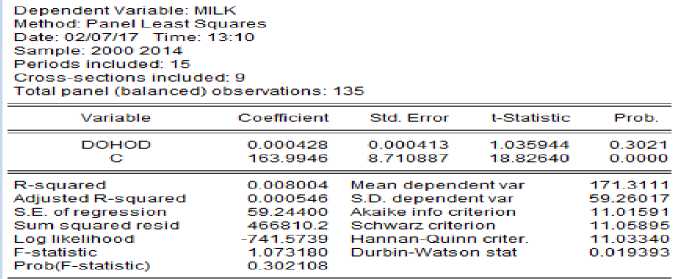
Рисунок 11 – Обобщённая модель зависимости потребления молока от доходов
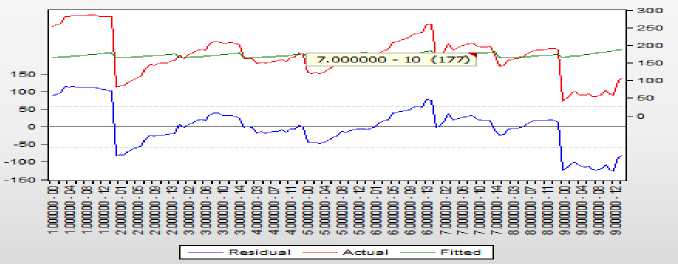
Рисунок 12 – График остатков, фактических и расчётных значений обобщённой модели
На этом примере особенно чётко видно, что обобщённая модель не учитывает структуру панельных данных и не даёт картину неоднородности регионов по рассматриваемым показателям. Во-первых, модель получилась незначимой (Prob(F-statistic = 0,3)), а во-вторых, график расчётных значений показывает, что эта модель не учитывает индивидуальных особенностей регионов. Совсем другую картину даёт модель с фиксированными эффектами зависимости потребления молока от доходов (рисунок 12). Точность этой модели довольно высокая (R-squared = 0,95), и модель значима (Prob(F-statistic = 0,00)). График расчётных значений (рисунок 13) хо- рошо аппроксимирует динамику фактического потребления молока в регионах.
Из графика видно, что молоко в значительно большем объёме потребляется в Якутии (1-й регион), в меньшем – на Чукотке (9-й регион). Ранжируем регионы по величинам фиксированных индивидуальных эффектов (рисунок 16) по аналогии с предыдущим. Получим 9 2 5 4 8 7 3 6 1. И опять Якутия и Чукотка оказались на противоположных концах этого списка: в Якутии потребление молока наибольшее, а на Чукотке – наименьшее, что мы и видели, анализируя график на рисунке 14. Тест Вальда (рисунок 15) показал, что различие в фиксированных эффектах значимо.
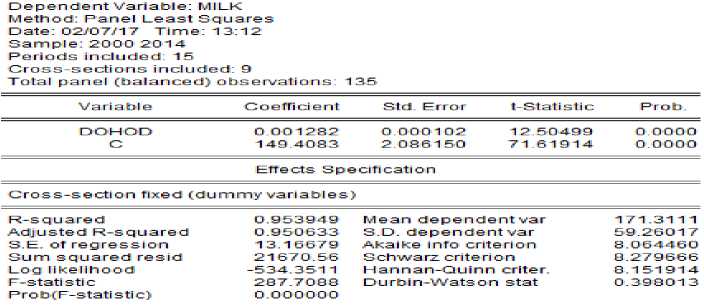
Рисунок 13 – Модель с фиксированными эффектами зависимости потребления молока от доходов
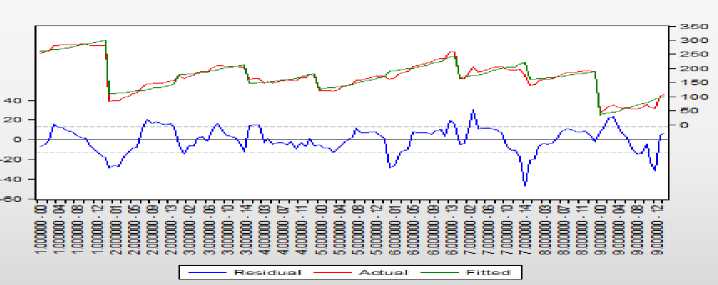
Рисунок 14 – График остатков, фактических и расчётных значений обобщённой модели

Рисунок 15 – Тест Вальда модели с фиксированными эффектами
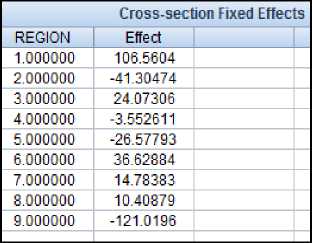
Рисунок 16 – Индивидуальные фиксированные эффекты
Аналогичные исследования по картофелю, овощам и хлебу дали следующие результаты (ниже приведено ранжирование регионов по потреблению соответ- ствующих видов продуктов, включая уже проанализированные):
по молоку 9 2 5 4 8 7 3 6 1;
по мясу 9 8 4 2 5 6 3 7 1;
по картофелю 9 6 1 5 2 7 3 4 8;
по овощам 9 1 6 7 5 2 4 8 3;
по хлебу 9 5 7 2 6 8 3 1 4.
Подведём некоторые итоги этого ис- следования.
Чукотка (9-й регион) выделяется среди всех регионов ДФО более низким уровнем потребления по всем видам анализируемых продуктов. Здесь сказались особенности питания коренных жителей региона.
В ЕАО (8-й регион) низкий уровень потребления мяса, средний уровень потребления молока и хлеба и более высокий уровень потребления картофеля и овощей.
В Сахалинской области (7-й регион) отмечается более низкий уровень потребления хлеба, средний уровень потребле- ния молока, картофеля и овощей, довольно высокий уровень потребления мяса.
Магадан (6-й регион) выделяется низким уровнем потребления картофеля и овощей, средним уровнем потребления мяса и хлеба и более высоким уровнем потребления молока.
В Амурской области (5-й регион) отмечается меньше хлеба и молока, на среднем уровне потребление картофеля, мяса и овощей.
В Хабаровском крае (4-й регион) потребляют меньше мяса, больше овощей, картофеля и хлеба, на среднем уровне потребление молока.
Приморский край (3-й регион) выделяется относительно высоким уровнем почти по всем видам продуктов питания.
На Камчатке (2-й регион) низкий уровень потребления молока, по остальным видам – средний уровень.
В Якутии (1-й регион) отмечается низкий уровень потребления овощей и картофеля, высокий уровень потребления хлеба, молока и мяса.
Здесь речь идёт не об абсолютных показателях потребления, а о ранжировании регионов по уровню потребления основных продуктов питания относительно остальных регионов.
Кластерный анализ
Применение кластерного анализа к данным, сформированным в виде сбалансированной панели, позволяет проследить динамику уровня жизни по анализируемым показателям на рассматриваемом промежутке времени. Чтобы было более ясно, о чём идёт речь, выделим номера наблюдений в выборке по годам и регионам. Поскольку все регионы наблюдались в течение 15 лет, то в выборке каждому региону выделено по 15 наблюдений с номерами, указанными в таблице. Кластеризация проводилась по наблюдениям, то есть по годам и регионам по пяти видам продуктов питания (хлеб, мясо, молоко, картофель и овощи) по методу к-средних. Были продекларированы три кластера. Отчёт об общем итоге проведённого кластерного анализа приведён на рисунке 17.
Таблица – Соответствие номеров в выборке регионам и периодам времени
|
Регион |
Номера в выборке |
|
Якутия |
1–15 |
|
Камчатка |
16–30 |
|
Приморский край |
31–45 |
|
Хабаровский край |
46–60 |
|
Амурская обл. |
61–75 |
|
Магаданская обл. |
76–90 |
|
Сахалинская обл. |
91–105 |
|
ЕАО |
106–120 |
|
Чукотка |
121–135 |
Analysis Summary
Data variables: bread meate milk potato vegetable
|
Number of complete Clustering Method: |
cases: 135 k-Means |
Distance Metric: Squared Euclidean
|
Cluster Members |
Percent |
|
1 15 2 65 3 55 |
11,11 48,15 48,74 |
Centroids
|
Cluster bread |
meate milk potato vegetable |
|
1 58,6 2 115,015 3 116,527 |
42,5333 65,3333 64,2667 15,4667 53,1385 153,754 156,277 110,2 77,6545 220,964 99,9455 88,1636 |
Рисунок 17 – Отчёт о результатах кластерного анализа по продуктам питания
В первый кластер попали 15 наблюдений, во второй – 65, в третий – 55. Центроиды – это, по сути дела, средние значения анализируемых показателей, рассчитанных по тем наблюдениям, которые попали в соответствующий кластер. Эти показатели позволяют идентифицировать полученные кластеры по уровню потребления населением соответствующих продуктов. Принадлежность наблюдений к кластерам следующая (ввиду громоздкости представления этой информации в отчёте статистического пакета программ этот отчёт здесь не воспроизводится).
Первый кластер включает наблюдения с номерами 121–135. В соответствии с таблицей 1 это Чукотка на протяжении всего анализируемого периода. Из анализа центроидов (рисунок 17) заключаем, что потребление включённых в анализ продуктов здесь существенно ниже, чем по другим регионам, кроме как по мясу, здесь отставание не так существенно (по крайней мере, по сравнению с наблюдениями второго кластера). Скорее всего, на этом сказалось то, что в анализируемом перечне продуктов питания не учитываются особенности питания коренных жителей Чукотки. В нашем исследовании в перечень анализируемых продуктов не вошли рыба и морские животные, а основу питания коренных жителей Чукотки составляет мясо морских животных и оленей в сочетании с дикоросами, а также охота на птиц, рыболовство и собирательство на берегу моря (интенсивно используются природные ресурсы).
Второй кластер включает наблюдения с номерами 16–38,46–68,91–93 и 106–120. Здесь уровень потребления хлеба незначительно отличается от наблюдений третьего кластера, мяса и молока – на среднем уровне, а картофеля и овощей – существенно выше наблюдений первого и третьего кластеров. В этот кластер попали: полностью Камчатка (16–30), первых восемь лет Приморского края (31–38), полностью Хабаровский край (46–60), первых восемь лет Амурской области (61–68), первые три года Сахалинской области (91–93) и полностью ЕАО (106–120).
В третий кластер попали наблюдения с номерами 1–15, 39–45, 69–90 (кроме 76), и 94–105. В этот кластер попали: Якутия на протяжении всего периода наблюдений (1–15), семь последних лет Приморского края (39–45), семь последних лет Амурской области (69–75), полностью Магаданская область (76–90) и почти весь наблюдаемый период (последние двенадцать лет) в Сахалинской области (94– 105). Здесь потребление хлеба немного выше уровня второго кластера, мяса и молока существенно выше, чем в двух других кластерах, а картофеля и овощей ниже, чем во втором кластере, но выше, чем в первом, то есть на среднем уровне.
Переход того или иного региона из одного кластера в другой в разные годы означает, что в этот период произошли изменения структуры потребления. Так, Приморский край и Амурская область в первую половину наблюдаемого периода, то есть в период 2000–2007 гг. были во втором кластере, а затем перешли в третий. Это означает, что начиная с 2008 г. в этих регионах уровень потребления мяса и молока увеличился, а картофеля и овощей снизился до среднего уровня. Аналогичные изменения произошли и в Амурской области, но там такой переход осуществился в более ранний период – в 2002 году.
В остальных регионах структура потребления основных видов продуктов не изменялась на протяжении всего периода наблюдений, кроме Магаданской области, там переход из 2-го кластера в 3-й осуществился на второй год периода наблюдений, то есть с 2001 года.
А теперь проведём аналогичный кластерный анализ по показателям, характеризующим в какой-то степени качество жизни населения, а именно: число впервые заболевших (health), обеспеченность жилой площадью (sqmetre), количество больничных коек на 1000 человек (bed) и валовой региональный продукт (grp). Для анализа был выбран аналогичный метод кластеризации по тем же регионам и тем же периодам наблюдений. Отчёт об этом исследовании представлен на рисунке 18.
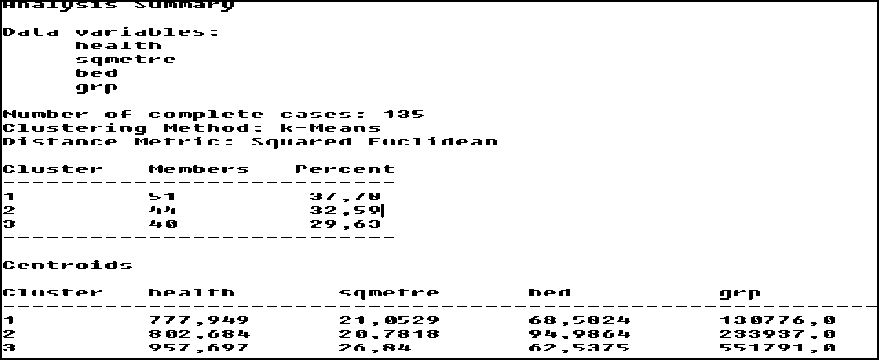
Рисунок 18 – Отчёт о результатах кластерного анализа по качеству жизни
Как видно из рисунка 18, в первый кластер вошли 51 наблюдение, во второй – 44 наблюдения, в третий – 40 наблюдений.
Анализ принадлежности наблюдений к кластерам дал следующие результаты.
В первый кластер вошли наблюдения с номерами 1–5, 46–53, 57, 61–69, 71, 76– 77, 91–97, 106–120. Во второй кластер вошли наблюдения с номерами 9–45, 54– 56, 58–60, 70. В третий кластер вошли наблюдения с номерами 72–75, 78–90, 100–105, 121–135.
В соответствии с таблицей получили, что в первый кластер попали Якутия, Хабаровский край, Амурская область, Сахалинская область в первой половине наблюдаемого периода и ЕАО за весь период наблюдений. В соответствии с анализом центроидов видно, что этот кластер характеризуется низким уровнем заболеваемости, средним уровнем обеспечения жилой площадью, низким уровнем валового регионального продукта и средним уровнем числа больничных коек.
Во второй кластер попали: вторая половина периода наблюдения Якутии, полностью Камчатка и Приморский край и вторая половина периода наблюдения Хабаровского края. Этот кластер характеризуется более высоким уровнем заболеваемости, меньшим уровнем обеспечения жилой площадью, средним уровнем валового регионального продукта, зато существенно большим количеством больничных коек.
Третий кластер отличается более высоким уровнем числа заболевших, большей степенью обеспечения жилой площадью, средним количеством больничных коек и наиболее высоким показателем валового регионального продукта. К этому кластеру относятся: последний период Амурской области, целиком Магаданская область, последний период Сахалинской области и целиком Чукотка.
А теперь проанализируем последствия переходов регионов в разные периоды в разные кластеры.
Приморский край и Камчатская область во всём периоде наблюдения относятся ко второму кластеру, ЕАО – к первому кластеру, а Чукотка – к третьему кластеру, то есть ситуация с анализируемыми показателями в этих регионах оставалась неизменной в течение всего анализируемого периода.
Переход Якутии из первого кластера во второй в середине анализируемого периода означает, что после 2007 г. в Якутии возросло число впервые заболевших, несколько уменьшилось обеспечение населения жилой площадью, повысилось обеспечение больничными койками и увеличился валовой региональный продукт. Аналогичная ситуация и в Хабаровскому краю.
Амурская, Сахалинская и Магаданская области перешли из первого кластера в третий, но в разные промежутки времени: Амурская область после 2011 г., Сахалинская область после 2007 г., Магаданская область после 2001 года. Начиная с этих периодов число впервые заболевших в этих регионах существенно повысилось, значительно возросла обеспеченность жилой площадью, снизилось обеспечение больничными койками и существенно увеличился валовой региональный продукт.
Как видим, использование кластерного анализа наравне с анализом панельных данных позволяет более детально анализировать дифференциацию регионов, в том числе и динамику показателей, характеризующих в нашем случае, некоторые характеристики уровня жизни населения этих регионов.
Список литературы Дифференциация регионов ДФО по показателям уровня жизни населения
- Беляева Л. А. Уровень и качество жизни. Проблемы измерения и интерпретации/Л. А. Беляева//Социологические исследования. 2009. № 1.
- Бушин П. Я. Анализ панельных данных как инструмент сравнения региональных экономических систем/П. Я. Бушин//Вестник Хабаровского гос. ун-та экономики и права. 2016. № 2.
- Вербик Марно. Путеводитель по современной эконометрике/Марно Вербик; пер. с англ. В. А. Банникова; науч. ред. и предисл. С. А. Айвазян. М.: Науч. книга, 2008. (Библиотека Солев).
- Малкина М. Ю. Оценка факторов внутрирегиональной дифференциации доходов населения РФ/М. Ю. Малкина//Пространственная экономика. 2009. № 3.
- Михеева Н. Н. Анализ дифференциации социально-экономического положения регионов/Н. Н. Михеева//Проблемы прогнозирования. 1999. № 5.
- Мотрич Е. Л. Население и социальное развитие российского Дальнего Востока/Е. Л. Мотрич, С. Н. Найден//Пространственная экономика. 2009. № 2.
- Найден С. Н. Дифференциация показателей социального развития субъектов РФ/С. Н. Найден//Пространственная экономика. 2015. № 5.
- Регионы России//www.gks.ru/bgd/reg1 (дата обращения 10.12.2016).
