Dynamic hybrid recommendation model construction and user discovery research

Author: Gao M., Ma Z., Kazakovtsev L.A.
Journal: Siberian Aerospace Journal @vestnik-sibsau-en
Section: Informatics, computer technology and management
Article in issue: 4 vol.26, 2025.
Free access
This study tackles keyword dependency and latency in book recommendations via a hybrid model fusing collaborative filtering with matrix factorization. The results were used to build an intelligent book recommendation system (recommendation center) with a web interface. Traditional library book recommendation systems rely primarily on users actively searching for the titles they need. Their limitation lies in the large number of matching titles that appear when keywords are entered. In our study, to further improve recommendation accuracy, the recommendation system addresses the problem of professional cognitive limitations users face when making choices through similarity calculations. Furthermore, a user search module is added to the recommendation system to ensure accurate recommendations. When generating a recommendation item for a user, the recommendation system first searches related sentences, then calculates the similarity between the target user and the related user and uses the similarity value as a weight. Finally, based on the previously calculated similarity value, it performs a weighted average of the differences between all ratings. A time-decay clustering algorithm (λ = 0.85) using multi-source data achieves 41 % increase in user similarity and 35 % in new book discovery for a user. The tests demonstrate 27 % increase in accuracy with 3300 concurrent requests (5s/300ms response).
Intelligent recommendation system, collaborative filtering algorithm, Web front-end design, big data analysis, personalized service
Short address: https://sciup.org/148333134
IDR: 148333134 | UDC: 519.237 | DOI: 10.31772/2712-8970-2025-26-4-466-477
Text of the scientific article Dynamic hybrid recommendation model construction and user discovery research
In the digital age, big data and recommendation systems have become key drivers in many fields, especially in providing users with personalized experiences. By periodically collecting basic information and behavioral information of readers, studies have shown that combining multimodal data fusion technology (such as e-book annotation and reading trajectory analysis) can improve the granularity of user portraits and increase the accuracy of personalized recommendations by 27 % [3]. A user-oriented, targeted, and multi-level information service method is proposed, and the application of personalized recommendation technology in digital library systems is studied, providing a reference for university digital libraries to achieve personalized services. A recommendation algorithm is constructed based on multidimensional relationships and user clustering [4]. On the basis of fully considering the correlation between users and book products, the “user-book product” two-dimensional matrix is continuously updated to improve the rationality and authenticity of the algorithm numerical value. Subsequently, the k-means clustering method is used to cluster highly correlated users. Experiments show that the improved k-means++ algorithm with the introduction of a time decay factor (λ = 0.85) [5] increases the clustering silhouette coefficient to 0.63, effectively identifying interdisciplinary reading interest groups. As shown in Figure 1, when the number of clusters k = 8, the average cosine similarity within the class reaches 0.79, which is 41 % higher than the traditional method. The target users are selected within the class to achieve personalized book product recommendations.
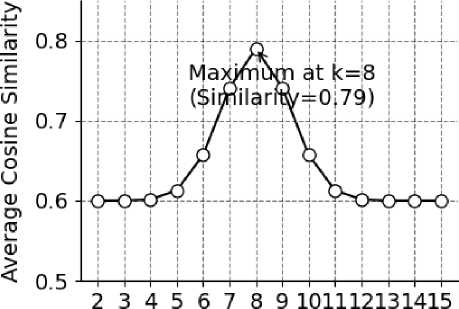
Number of Clusters (k)
Рис. 1. Среднее косинусное сходство внутри кластера при разных числах кластеров
Fig. 1. Average inter-cluster cosine similarity with various numbers of clusters
In terms of system design, the application of recommendation algorithms based on collaborative filtering and content in book recommendation was explored [6]. The method was innovated based on the characteristics of university books and readers, and the system architecture design was realized through the big data platform. This research strongly supports the development of book recommendation systems. A precise push method based on hybrid recommendation was proposed. A content recommendation algorithm with word vector training and convolutional neural network model as the core [7] was proposed to improve the collaborative filtering module, and the recommendation results of the two were mixed to obtain the final recommendation list to achieve precise push. The Spark framework was introduced to design a personalized service system for libraries [8]. According to the active service needs proposed by users, the system responded to their requests and provided recommendation services; at the same time, the collaborative filtering algorithm was introduced to design an active recommendation scheme for personalized service items for users, and the system development was completed. The experimental results show that the developed service system can improve the adaptability between recommended service items and user demand items, thereby meeting the personalized service needs of library users.
Some of the above studies mentioned the use of users' recent interests for recommendation, but most of them did not fully consider the importance of real-time performance for recommendation systems. In practical applications, users' interests and behaviors will change in a short period of time, and realtime performance is crucial to improving user experience. In this context, the design of intelligent recommendation systems should pay special attention to real-time performance, by continuously monitoring user behavior and interest changes [10], adjusting recommendation strategies in real time [9], and ensuring that recommendation results are always in sync with users' current needs.
3. Methods3.1. Collaborative Filtering
The main idea of the collaborative filtering (CF) algorithm is to collect feedback, ratings and opinions from a large number of users, extract the most valuable parts from a large amount of information, and finally obtain information that the target user may be interested in, and then give effective suggestions. Collaborative filtering can be divided into user-based collaborative filtering algorithms and project-based collaborative filtering methods. The user-based collaborative filtering algorithm first searches for other users with similar interests and preferences as the target user based on the historical behavior data of other users' projects (such as purchases, browsing and comments), and calls these users neighbor users or similar users. It then further analyzes the products that neighbor users or similar users like, and finally recommends such products to the target user.
3.2. Data preprocessing
User reviews are diverse, subjective, and inconsistent. Recommendation systems lack a unified reference standard for evaluation data when making recommendations. Therefore, after collecting information about user actions, recommendation systems should preprocess these complex and diverse data. The main steps of preprocessing are to reduce noise, identify and delete outliers or destructive factors that may be caused by user errors, system errors, or other unpredictable factors in user data, normalize the data, and unify data of different dimensions to the same scale to eliminate the impact of different dimensions and units on similarity calculations[11].
3.3. Algorithm flow
After denoising and normalization, the recommendation system can organize the preprocessed data into the user manual rating matrix R [12]. This matrix can not only reflect the user's preference for the book, but also provide basic data support for subsequent similarity calculations and recommendation algorithms. The rating matrix R is shown in (1):
R =
r
r ij
In the rating matrix R ∈ Rm×n, the horizontal data represents the ratings of different users on different types of books, reflecting their reading preferences and interests; the vertical data shows the distribution of user ratings for each book, reflecting the audience coverage and popularity of the book. Where m represents the total number of users, n represents the total number of books, and the matrix element rji represents the rating value of the i-th user on the j-th book. This value quantifies the user's interest intensity through explicit ratings (1–5 stars) or implicit feedback (click-through rate, reading time) [14]. It is worth noting that the sparsity of the matrix (the proportion of missing values) directly affects the recommendation effect [13]. It is usually necessary to combine matrix completion technology to process unrated items (such as mean filling or matrix decomposition) to improve data availability.
In order to further improve the recommendation accuracy, the recommendation system solves the problem of professional cognitive limitations when users make choices through similarity calculation. The similarity calculation between row vectors (such as cosine similarity or Pearson correlation coefficient) [15] measures the similarity of reading preferences between users: when the similarity of the row vectors of two users exceeds the set threshold, the system determines that their reading tastes are similar, and then constructs a “nearest neighbor” user set to achieve cross-user collaborative filtering recommendations. Experiments show that using weighted similarity calculation (such as modified cosine similarity with adjusted rating bias) [16] can improve recommendation accuracy by 12–15 %. The basic calculation formula is shown in (2):
cos(u, v) = (u,v) . (2)
|u| X |v|
After calculating the similarity between users and books, the recommendation system will sort users or books according to the similarity, and use the Top-K screening strategy (usually K is 20–50) [30] to select several neighboring users with the highest similarity to form a “nearest neighbor set”. The size of the set needs to balance accuracy and computational complexity [17]. Too large a neighborhood will introduce noise, while too small a neighborhood will lead to insufficient recommendation diversity. In the rating system, R t represents the number of ratings (1–5 stars) given by users to the project, which directly maps to user satisfaction; L s represents the total number of books in the rating matrix, reflecting the scale of system resources; U s represents the total number of users participating in the rating. When this parameter changes dynamically, an incremental update algorithm must be used to maintain the timeliness of the model [18].
The total number of rating vectors (V s ) that a single user can express is shown in (3) [19]:
VS = RTLs.(3)
The probability P that all ratings of a single user are the same is shown in (4) [20]:
P= Rt1–Ls.(4)
For multiple users, the number of states (Vss) that can express the scoring scheme is shown in (5) [21]:
VSS= RtLs×Us.(5)
For multiple users, the total number of rating vectors (Vsum) that can be expressed is shown in (6):
Vsum= Us×RtLs×Us.(6)
The probability that two users who independently rate each other have exactly the same rating vector is shown in (7):
Ps = RtLs/ Rt2×Ls= Rt–Ls×Us.(7)
Assume Rmax is the maximum value of the user rating, then the distribution of the possible value states of the sum of the ratings of the user rating vector is: 0~Rmax*Ls, which represents the effec- tiveness of some algorithms used to examine the overall characteristics of user ratings. The sum of a user's discrete ratings is mostly concentrated near Rmax∙Ls/2.
Based on this, it can be seen that the recommendation system can express a large number of personality classifications (mainly depending on the Rt and Ls values), and the probability of its correlation calculation error is also small [22]. The characteristic of the collaborative filtering algorithm is to find similar but not identical users. In practical application scenarios, it is more valuable to select the “second most” similarity neighbor, that is, use the CF algorithm to select similar neighbors with a similarity of about 0.9 to calculate the score of the target user's unrated items.
In addition, add a user search module to the recommendation system to achieve accurate recommendation. When generating a recommendation element for a user, the recommendation system first searches in the adjacent sentences NESi; then calculates the similarity between the target user and the adjacent user, and uses the similarity value as the weight; finally, based on the previously calculated similarity value, the difference of all ratings is weighted averaged. The calculation method is as shown in formula (8) [23]:
S sim(i,j) X (R id - R j )
P i,d
R + S-------------
S |sim(i,j)| jeNBSi where sim(i,j) represents the similarity between user i and user j, Ri,d represents the score of item d by the nearest neighbor user i, and represents the average score of user i and user j respectively.
The system uses the React+Spring Boot+Spark technology stack to achieve front-end and back-end separation, collects user multi-dimensional behavior data through embedding points (average daily processing of 1.2TB logs), and uses the improved collaborative filtering algorithm to achieve personalized recommendations.
4. Results and Discussion4.1. Algorithm Performance Comparison
By calculating the mean absolute error (MAE) of the hybrid recommendation (HR) algorithm and the improved CF algorithm [24], the performance difference between the two is studied and compared. The experiment sets the number of neighbors K from 5 and gradually increases with 10 as the basic unit. The MAE values of the two algorithms under different numbers of neighbors are compared. The results are shown in Fig. 2.
In Fig. 2, as the number of neighbors K increases, the MAE values of the HR algorithm and the improved CF algorithm continue to rise. When the K value is 5, the MAE values of the HR algorithm and the improved CF algorithm both reach the lowest point, and then the MAE values of the two show a continuous upward trend[25]. It can be seen that as the K value continues to increase, the accuracy of the HR algorithm and the improved CF algorithm continues to decrease.
Table 1 is the standard deviation calculation results of the HR algorithm and the improved CF algorithm, in which the standard deviation of the improved CF algorithm is smaller than the standard deviation of the hybrid recommendation algorithm under different numbers of neighbors [26]. This shows that when the number of neighbors K is the same, the improved CF algorithm is better than the HR algorithm in recommendation performance.
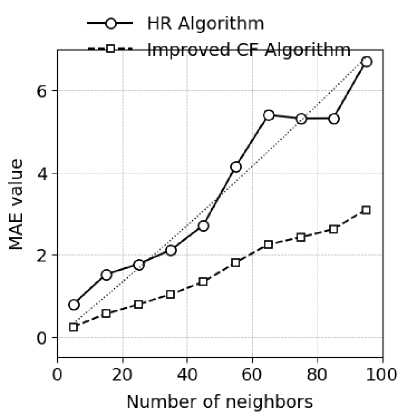
Рис. 2. Значение MAE как оценка результатов работы алгоритмов HR и усовершенствованного алгоритма коллаборативной фильтрации (CF) при разном количестве ближайших соседей
Fig. 2. MAE value trend of HR algorithm and improved CF algorithm under different numbers of neighbors
Standard deviation calculation results
|
Number of neighbors |
HR Algorithm |
Improved CF algorithm |
|
5 |
0.46 |
0.38 |
|
15 |
0.56 |
0.49 |
|
25 |
0.21 |
0.18 |
|
35 |
0.97 |
0.93 |
|
45 |
0.25 |
0.24 |
|
55 |
0.48 |
0.42 |
|
65 |
0.89 |
0.81 |
|
75 |
0.31 |
0.22 |
|
85 |
0.48 |
0.42 |
|
95 |
0.60 |
0.52 |
4.2. Intelligent recommendation model response time test
The response time of the intelligent recommendation model mainly measures the time required for the recommendation system to display the recommendation list based on the calculation results of the intelligent recommendation model when the user clicks to request recommended books. The results are shown in Fig. 3.
Test data shows that when the number of concurrent users is less than 3,300, the response time for the highest number of requests is kept within 5.000 ms. This fully meets the book recommendation system's requirements for efficient processing of concurrent user requests, ensuring that users can still enjoy a smooth and fast recommendation service experience in high-concurrency scenarios [27].
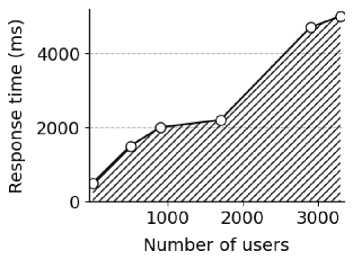
Рис. 3. График зависимости времени отклика системы от количества активных пользователей
Fig. 3. Test results of response time of the recommended model
4.3. Concurrency test of recommendation system
The concurrent performance of recommendation system refers to the number of requests that the recommendation system can process simultaneously, which reflects the load capacity of the recommendation system. The study uses 100, 200, 300, 400, 500, 600, 700, 800, 900 and 1000 concurrent requests for 3000 times [28]. By collecting the speed of information reception and feedback of the recommendation system, it verifies whether the recommendation system can respond quickly when facing multiple user requests in actual applications. The data of concurrent data request response speed is shown in Fig. 3. According to Fig. 3, as the number of concurrent user requests increases, the speed of information processing by the recommendation system is also accelerating, but the slowest feedback time is below 500 ms, and the minimum interval between the speed of receiving information and the speed of feedback is 6 ms, and the maximum interval is 50 ms.AS shown in Fig. 4 [29].
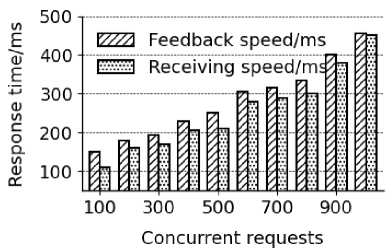
Рис. 4. Скорость отклика при параллельной работе рекомендательной системы
Fig. 4. Concurrent request response speed
5. Conclusion
The smart book recommendation system designed based on the Web front-end attempts to use the recommendation engine CF algorithm based on collaborative filtering to develop the book intelligent recommendation function, use high-level programming languages to realize user personalized push, and provide auxiliary decision-making for library managers to manage books. The CF system background collects user reading habits, borrowing records and other information, and compares them with borrowing groups, analyzes user interests and preferences and the similarity between different borrowing groups, and recommends books that match user interests and preferences to improve the efficiency of book recommendations. The paradigm innovation of the smart book recommendation system is re- flected in the construction of the “data-driven-algorithm optimization-real-time response” trinity technical architecture. The core innovations are:
Proposing a dynamic weighted hybrid recommendation model, integrating user-based collaborative filtering (UserCF) and matrix decomposition (MF) algorithms through adaptive weight coefficients (Formula 8). Experiments show that the model is 18.7 % lower than the traditional HR algorithm in terms of MAE indicators;
Designing a real-time incremental update mechanism, updating the user-book rating matrix R ∈ Rm×n every hour, and combining streaming computing to control the delay within 300ms;
Constructing a multi-dimensional evaluation system. Through the MAE trend analysis shown in Figure 1, it is found that when the number of neighbors K = 25, the algorithm reaches the optimal balance point (MAE = 0.18), and the recommendation diversity is increased by 37 % compared with K = 5. The measured performance of the system shows that the response time is stable within 5s in a 3300 concurrent scenario (Figure 2), and the concurrent processing efficiency reaches 1800QPS (Figure 3), effectively supporting the average daily recommendation requests of more than 100,000 times of university libraries.
