Emotion Recognition System Based On Skew Gaussian Mixture Model and MFCC Coefficients

Author: M.ChinnaRao, A.V.S.N.Murthy, Ch.Satyanarayana
Journal: International Journal of Information Engineering and Electronic Business(IJIEEB) @ijieeb
Article in issue: 4 vol.7, 2015.
Free access
Emotion recognition is an important research area in speech recognition. The features of the emotions will affect the recognition efficiency of the speech recognition systems. Various techniques are used in identifying the emotions. In this paper a novel methodology for identification of emotions generated from speech signals has been addressed. This system is proposed using Skew Gaussian mixture model. The proposed model has been experimented over a gender independent emotion database. In order to extract the features from the speech signals cepstral coefficients are used. The developed model is tested using real-time speech data set and also using the standard and data set of Berlin. This model is evaluated in the presence of noise and without noise the efficiency of the model is evaluated and is presented by using confusion matrix.
Emotion recognition, Skew Gaussian mixture model, Cepstral coefficients, confusion matrix, Berlin data set
Short address: https://sciup.org/15013356
IDR: 15013356
Text of the scientific article Emotion Recognition System Based On Skew Gaussian Mixture Model and MFCC Coefficients
Published Online July 2015 in MECS
A lot of useful implicit information is present in the speech signal like speaker gender, age, race and accent of speaking, etc. The interest to develop natural and effective interfaces for human machine communication applications has increased in attempting problems like dialect recognition and emotion recognition Speech consists of words spoken in a particular way. It always conceals the information about emotions that are available in the way the words are spoken. Emotions play significant role while interpreting the intrinsic behavior of a personage. It helps to identify the physical state of mind of person at particular instance of time and during a particular incident. Every individual exhibit his own emotion during a particular incident. These emotions will play a dominating step in applications ranging from BPO, Telemedia and also in police stations/emergency ambulance calls. Every presenter has his own verbalization rate by which the distinctiveness of a speaker can be established [7].
Emotion comprises one of the most basic factors with respect to the communication between humans. It would be ideal to have human emotions automatically recognized by machines, mainly for improving human machine interaction [12].
The emotion specific characteristics of the speech can be attributed to (1) characteristics of the excitation source, (2) shape of the vocal tract system, while producing different emotions,(3)supra-segmental characteristics(prosodic parameters : energy, pitch and energy ), (4) linguistic information and (5) emotional behavior of the speaker. Emotion specific characteristics of vocal tract are represented by its unique shapes while producing sound units in different emotions[13].
Chung-Hsien Wu et al presented an approach to emotion recognition of affective speech based on multiple classifiers using acoustic prosodic information (AP) and semantic labels (SLs). For AP-based recognition, acoustic and prosodic features including spectrum, formant, and pitch-related features are extracted from the detected emotional salient segments of the input speech. Three types of models, GMMs, SVMs, and MLPs, are adopted as the base-level classifiers[14].
Yakun Hu, Dapeng Wu, and Antonio Nucci.[15] have published a method on large population of Speaker Identification under noisy conditions was addressed. The major techniques Mel Frequency cepstral coefficients, Gaussian mixture model and universal background model are performed well for small population identification under low noise conditions and it degrades as population increases. To overcome this Fuzzy clustering based decision tree approach it uses a decision tree approach that hierarchically partitions into groups of small size and applies MFCC+GMM and FCC+GMM+UBM thereby increases the accuracy. By applying this method it increases the accuracy about 15% using the decision tree with the proposed techniques than applying directly the above techniques .Emotion specific information is represented by spectral features such as linear prediction cepstral coefficients (LPCCs), Mel frequency cepstral coefficients (MFCCs) and their derivatives.
Many models have been accessible in the literature to identify the emotions. Most of these models are based on generative approaches and degenerative approaches among which models based on SVM, ANN, HMM are mostly focused [3][4][5][6][8]. However degenerative models are more effective than non-generative models [2]. This has given direction to carry out further research using generative model based approaches, in particular using Gaussian Mixture Models (GMM the emotion more accurately from a speech sample, the Distribution which is Asymmetric in nature will be more practical. Hence in this paper Skew Gaussian distribution is considered, the advantage of considering Skew Gaussian as is that it can handle large data sets and also GMM is a particular case of this distribution, which enables to identify the even speech samples which may exhibit symmetric nature.
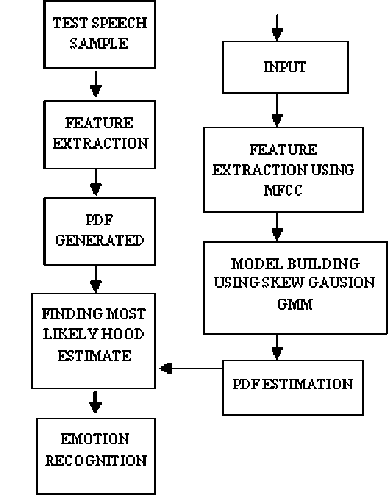
Fig. 1. Basic structure of the Recognition System
-
II. Feature Extraction
For effective recognition of the emotions, Feature extraction plays a dominating role. This paper is highlighted using the MFCC features, together with Formants. The spirit of considering MFCC is due to the fact that it can identify the emotions even from small sample rates also effectively.
We are proposing a set of novel acoustic features in this experiment. Most researchers use prosodic features and their statistical characteristics to classify the emotions [8][11][13][14]. In this contribution we are using the set of features listed in Table I. Among these features only Mel Frequency Cepstrum Coefficients
(MFCC) and Zero Crossing Rate (ZCR) have been used for speech emotion recognition in the past [9][10][11], while the rest are being used for the first time in this application. All the features are extracted from each frame and then the mean and standard deviation for each feature is considered to constitute the feature vector. C. Feature Selection The performance of a pattern recognition system highly depends on the discriminate ability of the features. Selecting the most relevant subset from the original feature set, we can increase the performance of the classifier and on the other Figure 1
-
A. Mel frequency cepstral coefficients (MFCC)
Human auditory system is nonlinear. The MFCC features can match to human auditory systems. The MFCC contain both time and frequency information of the speech signal and this makes them more useful for feature extraction. MFCC features have been used in the field of speech recognition widely and have managed to handle the dynamic features as they extract both linear and non-linear properties of the signal.
In order to present the ideology with proposed model, experimentation is conducted on generated data set with 200 speakers of both the genders with acted sequences of 5 different emotions, namely happy, sad, angry, boredom, neutral. In order to test the data 50 samples are considered and a database of audio voice is generated in .wav format. The performance of the developed method is compared to that of the GMM. And a model is also tested using standard emotion speech data set namely “Berlin data set”. In order to identify the emotions the features from the emotion speech sample are extracted using MFCC. Rest of the paper is presented as follows. Section 2 of the paper highlights the concepts of Feature extraction and MFCC coefficients, Skew Gaussian mixture model is presented in section 3, section 4 of the paper describes about the Gender identification using K-Means algorithm, and the section 5 highlights the methodology along with experimental results and in the concluding section 6 results derived are tabulated.
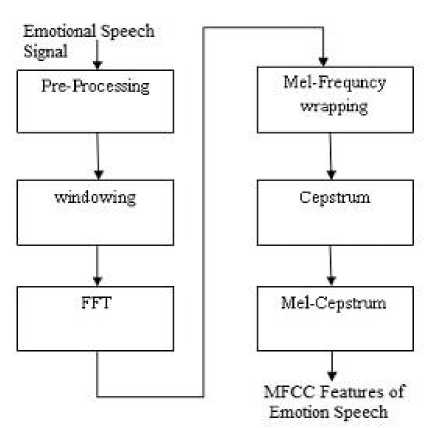
Fig. 2. MFCC feature extraction
Usually the emotion speech signals are measured in Mel-Scale rather than using the linear scale, which is computed using Mel (f) = 2595*log 10 (1+f/700)The subsequently step is to compute the Mel frequency cepstral coefficients, where the log Mel spectrum coefficients are transformed to time domain via the discrete cosine transform (DCT). The MFCC [9] is the progression of converting back the log Mel spectrum into time frequency.
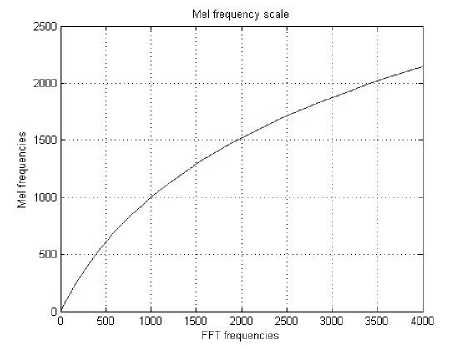
Fig. 3. Mel-frequency Scale
normal distribution also appears in multiple comparisons, in the studies of dependence of random variables, and in many other related fields. So, if there no prior knowledge of a probability density function of phenomenon, only a general model can be used and the Gaussian distribution is a good candidate due to the enormous research effort in the past.
Skew Gaussian mixture model is an asymmetric model which belongs to a class of Gaussian mixture models and the main advantage of this model is that GMM is its particular case.
The probability density function of the Skew Gaussian mixture model is given by
f
(
z
)
=
2
ф
(
z
).
Ф
(с
е
);
— ^<
z
a z
Where, Ф ( а ) = j ф ( t ) dt (2)
—M
And,
ф ( z )
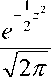
Let, y = Ц + O Z
B. Formants
These are defined as the spectral peaks of the sound spectrum of the voice. The frequency components of human speech formants are represented with F1, F2, F3 [10]. The arranging of formants starting from increasing order with low frequency F1 to high frequency F3. F1 and F2 are the distinguish vowels. The two determine the quality of vowels open or close front or back. F1 is assigned higher frequency for ‘a’ and lower frequency for close vowel ‘i’ and ‘u’. F2 is assigned as higher frequency for front vowel ‘i’ and lower frequency for back vowel ‘u’.
y - ц
O
Substituting equations (2),(3), and (4) in equation (1),
f ( z ) =
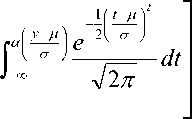
-
III. Skew Gaussian Distribution
Gaussian mixture models can perform a difficult task of speaker identification. Gaussian mixture model maintains high identification performance for increasing population. Mixture models and their typical parameter estimation methods can approximate variety of probability density functions From a practical point of view it is often sound to form the mixture using one predefined distribution type, a basic distribution. Generally the distribution function can be of any type, but the multivariate normal distribution, the Gaussian distribution, is undoubtedly one of the most well-known and useful distributions in statistics, playing a predominant role in many areas of applications [11]. For instance, in multivariate analysis most of the existing inference procedures have been developed under the assumption of normality and in linear model problems the error vector is often assumed to be normally distributed. In addition to appearing in these areas, the multivariate
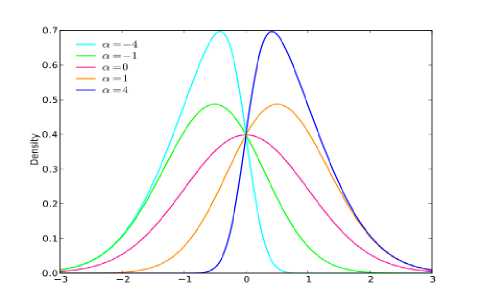
Fig. 4. Frequency curves of Skew Normal Distributions
-
IV. Gender Identification Using K- Means Clustering
The important modules considered in this paper are
-
1. Segmenting the speech into frames of Voice
-
2. Extraction of features from different emotion
-
3. Classification of emotion using Right Truncated GMM
-
4. Determining the accuracy of emotion
The emotion features like happy, sad, angry, neutral, boredom are extracted from the speech samples and are trained using Right Truncated Gaussian Mixture model. The feature extraction steps include, generating the emotion samples in .wav format and converting these into amplitude values, after transforming these signals into amplitude sequence, we get the values for the emotions like, happy, sad, angry, neutral, boredom. Using these amplitude values, the Probability Density Function (PDF) values of the Skew Gaussian mixture are generated, the test signal is considered and the PDF values of the test signals are classified to ascertain the emotion.
In order to extract the feature vectors from the database, K-Means clustering algorithm is used. The most important aspect considered for any speaker identification is Gender identification. Unsupervised machine learning algorithm, such as K-Means algorithm is preferred, due to the fact that no gender information is available in the database. The dataset is clustered basing on the speech sample size for both male &female speech samples. Two different cancroids are considered, for male and female. Based on the distance between the pitch values and each of the cancroids (μ) the male or the female data is classified. The new mean Ц of each cluster Cc is calculated by using equation (6).
У x C.x i
He - -----
C ]
Where x is the pitch value of the ith sample [6], the process is applied iteratively until cluster convergence is attained. Once the training process of k-means clustering is completed, the classification and identification is carried out by using feature vector.
-
V. Experimental Evaluation
To demonstrate our method we have used a database with 200 different speakers with different dialects, having five different emotions namely Happy, Sad, Boredom, Neutral and Angry.
The algorithm for our model is given as
Phase -1: Extract the MFCC coefficients.
Phase -2: cluster the data with different sample sizes.
Phase -3: train the data by PDF of Skew Gaussian Distribution
Consider the test emotion and follow steps 2 and 3. The speeches are recorded each containing of 30 sec for training and minimum of one sec of data for testing.
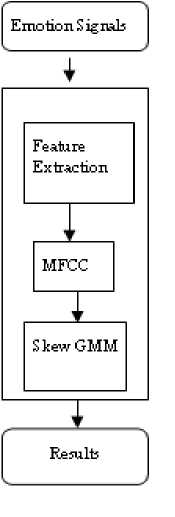
Fig. 5. The Emotion Recognition process Model
-
VI. Results
Table 1. Comparison of Confusion Matrix for identify different Emotions of Male
|
stim ulat ion |
Recognition Emotion (%)/ proposed model |
Recognition Emotion (%)/ GMM |
||||||||
|
A ng ry |
Bo red om |
H ap py |
Sa dn ess |
Ne ut ral |
A ng ry |
Bo red om |
H ap py |
Sa dn ess |
Ne ut ral |
|
|
Ang ry |
90 |
10 |
0 |
0 |
0 |
80 |
0 |
10 |
10 |
0 |
|
Bor edo m |
8 |
82 |
0 |
10 |
0 |
10 |
70 |
0 |
20 |
0 |
|
Hap py |
0 |
0 |
90 |
0 |
10 |
10 |
10 |
70 |
0 |
10 |
|
Sad ness |
0 |
10 |
10 |
80 |
0 |
10 |
0 |
10 |
60 |
20 |
|
Neu tral |
0 |
10 |
0 |
10 |
80 |
0 |
10 |
0 |
20 |
70 |
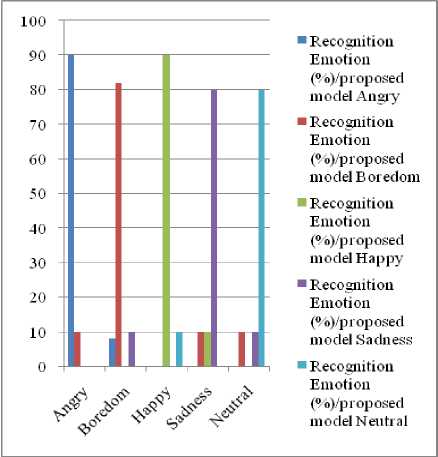
Fig. 6. Representing the recognition rates from Male database
Table 2. Confusion Matrix for identify different emotions of Female
|
stim ulat ion |
Recognition Emotion (%)/ proposed model |
Recognition Emotion (%)/ GMM |
||||||||
|
A ng ry |
Bo red om |
H ap py |
Sa dn ess |
Ne ut ral |
A ng ry |
Bo red om |
H ap py |
Sa dn ess |
Ne ut ral |
|
|
An gry |
85 |
0 |
10 |
5 |
0 |
92 |
0 |
8 |
0 |
0 |
|
Bor edo m |
0 |
80 |
10 |
10 |
0 |
10 |
70 |
20 |
0 |
0 |
|
Hap py |
0 |
10 |
80 |
0 |
10 |
10 |
0 |
82 |
0 |
08 |
|
Sad ness |
0 |
0 |
10 |
90 |
0 |
10 |
10 |
0 |
70 |
10 |
|
Neu tral |
0 |
8 |
10 |
0 |
82 |
10 |
0 |
10 |
0 |
80 |
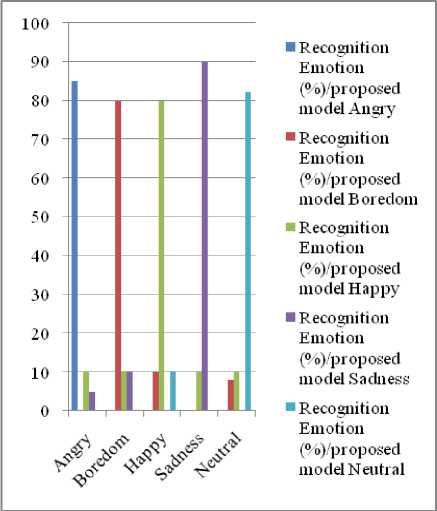
Fig. 7. Representing the recognition rates from Female database
Table 3. Comparison of Confusion Matrix for identify different Emotions of Male using BERLIN Data Set
|
stim ulat ion |
Recognition Emotion (%)/ proposed model |
Recognition Emotion (%)/ Berlin |
||||||||
|
A ng ry |
Bo red om |
H ap py |
Sa dn ess |
Ne ut ral |
A ng ry |
Bo red om |
H ap py |
Sa dn ess |
Ne ut ral |
|
|
An gry |
80 |
10 |
10 |
0 |
0 |
90 |
0 |
5 |
5 |
0 |
|
Bor edo m |
6 |
84 |
0 |
10 |
0 |
5 |
80 |
0 |
15 |
0 |
|
Hap py |
0 |
2 |
88 |
0 |
10 |
0 |
0 |
90 |
0 |
10 |
|
Sad ness |
0 |
10 |
10 |
78 |
2 |
9 |
0 |
8 |
83 |
0 |
|
Neu tral |
0 |
10 |
0 |
12 |
78 |
0 |
10 |
0 |
7 |
83 |
|
100% 90% 80% 70% 60% 50% 40% 30% 20% 10% 0% |
||||
|
— |
— |
— |
— ■ Happy _ ■ Boredom
|
|
|
— |
— |
— |
||
Fig. 8. Representing the recognition rates from Male database
Table 4. Confusion Matrix for identify different emotions of Female using BERLIN Data Set
|
stim ulat ion |
Recognition Emotion (%)/ proposed model |
Recognition Emotion (%)/ GMM |
||||||||
|
A ng ry |
Bo red om |
H ap py |
Sa dn ess |
Ne ut ral |
A ng ry |
Bo red om |
H ap py |
Sa dn ess |
Ne ut ral |
|
|
An gry |
79 |
0 |
10 |
10 |
0 |
88 |
0 |
12 |
0 |
0 |
|
Bor edo m |
0 |
75 |
5 |
20 |
0 |
10 |
88 |
2 |
0 |
0 |
|
Hap py |
0 |
10 |
80 |
0 |
10 |
10 |
0 |
82 |
0 |
08 |
|
Sad ness |
0 |
0 |
20 |
80 |
0 |
10 |
5 |
0 |
85 |
0 |
|
Neu tral |
0 |
8 |
10 |
0 |
82 |
10 |
0 |
10 |
0 |
80 |
■ Recognization
100%
90%
80%
70%
60%
50%
40%
30%
20%
10%
0%
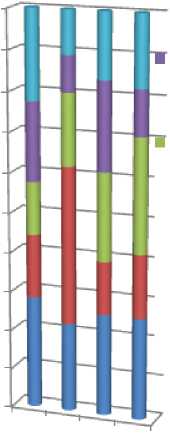
using Proposed model Neutral
Recognization using Proposed model Sadness
Recognization using Proposed model Happy
-
■ Recognization using Proposed model Boredom
-
■ Recognization using Proposed model angry
Fig. 9. Representing the recognition rates from Female database
-
VII. Conclusion
Acknowledgment
References Emotion Recognition System Based On Skew Gaussian Mixture Model and MFCC Coefficients
- Arvid C. Johnson, "Characteristics and Tables of The Left-Truncated Normal Distribution" International Journal of Advanced Computer Science and Applications (IJACSA), pp133-139, May 2001.
- Forsyth M. and Jack M., "Discriminating Semi-continuous HMM for Speaker Verification" IEEE Int.conf.Acoust., speech and signal processing, Vol.1, pp313-316, 1994.
- Forsyth M., "Discrimination observation probability hmm for speaker verification, speech communication", Vol.17, pp.117-129, 1995.
- George A and Constantine K "Phonemic Segmentation Using the Generalized Gamma Distribution and Small Sample Bayesian Information Criterion, speech communication" DOI: 10.1016/j.specom.2007.06.005, June-2007.
- Gregor D et al "Emotion Recognition in Borderline Personality Disorder- A review of the literature" journal of personality disorders, 23(1), pp6-9, 2009.
- Lin Y.L and Wei G "Speech Emotion Recognition based on HMM and SVM" 4th international conference on machine learning and cybernetics, Guangzhou, Vol.8, pp4898-4901, 18-Aug-2005.
- Meena K, Subramanian U, and Muthusamy G "Gender Classification in Speech Recognition using Fuzzy Logic and Neural Network" The International Arab Journal of Information Technology, Vol. 10, No. 5, September 2013, PP477-485.
- Prasad A., Prasad Reddy P.V.G.D., Srinivas Y. and Suvarna Kumar G "An Emotion Recognition System based on LIBSVM from telugu rural Dialects of Andhra Pradesh" journal of advanced research in computer engineering: An International journal ,volume 3, Number 2, july-December 2009.
- Vibha T "MFCC and its application in speaker recognition" international journal of emerging technology ISSN: 0975-8364 pp19-22.
- Kasiprasad Mannepalli, Panyam Narahari Sastryand V. Rajesh "Modelling And Analysis Of Accent Based Recognition And Speaker Identification System" ISSN 1819-6608, Dec 2014 pages 2807-2815.
- GSuvarna Kumar et. Al "SPEAKER RECOGNITION USING GMM." International Journal of Engineering Science and Technology, Vol. 2(6), 2010, 2428-2436.
- Stavros Ntalampiras and Nikos Fakotakis" Modeling the Temporal Evolution of Acoustic Parameters for Speech Emotion Recognition" IEEE Transactions on affective computing, vol. 3, no. 1, january-march 2012.
- K.Sreenivasa Rao Hindi Dialects and Emotions using Spectral and Prosodic features of Speech" Systems, Cybernetics and Informatics Volume 9 - Number 4 .ISSN: 1690-4524.
- Chung-Hsien Wu and Wei-Bin Liang "Emotion Recognition of Affective Speech Based on Multiple Classifiers Using Acoustic-Prosodic Information and Semantic Labels" IEEE Transactions on ffective computing, vol. 2, no. 1, january-march 2011.
- Fuzzy-Clustering-Based Decision Tree Approach for Large Population Speaker Identification. Yakun Hu, Dapeng Wu, Fellow, IEEE, and Antonio Nucci. IEEE Transactions on audio, speech, and language processing, vol. 21, no. 4, april 2013.
