Empowering Information Retrieval in Semantic Web

Author: Ahamed. M Mithun, Z. Abu Bakar
Journal: International Journal of Computer Network and Information Security @ijcnis
Article in issue: 2 vol.12, 2020.
Free access
Until the inception of Web 1.0, the Information Retrieval was the center of the stage for library and it was defined as search and passive. Later on, the emergence of Web 2.0 was encouraged into the community, social interaction and user-generated content. Web 3.0 is a modern phenomenon and also known to “3D Web or the Semantic Web”, and it often used for specifically to formats and the technologies. The advanced Web 4.0 is the Ultra-Intelligent Agent Interactions between humans and machines. Semantic web technology finds meanings from various sources to enabling the machines and people to understand and share knowledge. The semantic web technology helps to add, change and implement the new relationships or interconnecting programs in a different way which can be as simple as changing the external model that these programs are shared. To give an information need, the semantic technologies can directly search, capture, aggregate, and make a deduction to satisfy the user needs. The paper presents a framework for knowledge representation assembling semantic technology based on ontology, semantic web, and an intelligent agent algorithm as a connectivity framework to share the appropriate knowledge representation which includes the web ontology language that discovers related information's from various sources to serve the information needs. The research addresses the intelligent agent algorithm is the key contribution that reveals appropriate information and empowers Web 3.0 and embraces Web 4.0 into the coming semantic web technology.
Semantic Web, Information Retrieval, Semantic Search Engine, Knowledge Representation
Short address: https://sciup.org/15017201
IDR: 15017201 | DOI: 10.5815/ijcnis.2020.02.05
Text of the scientific article Empowering Information Retrieval in Semantic Web
Published Online April 2020 in MECS
Information Retrieval (IR) is the process that any information represents from diverse information sources according to the user needs. It usually begins by entering a query into a system, for instance; to retrieve relevant information that is a query done by the users through the web search engines. The user queries take place into the search engine in the information retrieval system and the quires are few statements, such few strings are inputted in the search engine. In IR, searches are likely to get information from any documents, or the document, data, various types of files such as audio, video and image. Moreover, IR deals with the representation, organize, and access to the information's as well. The modern IR in particular, the web search information retrieval was developed and informed relative results in the back 1990s, though the quantity of the information search result was quite a small number [1]. In this context, the term Semantic Web is driven by the World Wide Web and it builds on with the standard of World Wide Web Consortium (W3C) Resource Description Framework (RDF) and designed with syntaxes to represent data using the Uniform Resource Identifiers (URIs). These syntaxes are known as RDF syntaxes. The key concern of semantic web to discover, search, share, and information retrieves by the human with less effort. This term proposed by Tim Berners-Lee; the great expectation of semantic web to create an environment where an intelligent agent will perform complex tasks for user's needs [2]. The emerging concept of Web 3.0 triggers the user's cooperation while Web 2.0 was on the user's participation and Web 1.0 cognitive process of communication. Web 3.0 connected to the semantic web in which the machine will talk to another to understand and to meaning from the semantic data. An instance for Web 3.0 technology is the quora.com, it searches question and answer platform with general knowledge [3], by updating the user's question and answer lively through social networking sites.
In the context of Information Retrieval (IR), to investigating and for information representation, the ontology used in many web search engines. Information is addressed by using Universal Resource Identifiers and the ontology is used to discover the semantics. A language called OWL (Web Ontology Language) defines the data for semantic web and expressiveness than RDF (Resource Description Framework) [4]. The traditional web search engines have challenges such as the resources, organization of resources, and the hyperlinks to assist the search and that requires a strong mechanism for information retrieval [5]. On the other hand, the semantic search engine refers to searches with a meaning where the current search engines search for literal matches of the user query. Besides, the ontology represents formally and the structure is machine-readable in which it increasingly important [6], particularly for the biosciences.
In current web search engine, information is displayed by inputting the queries that are usually done by users, and they predict the information’s are appropriate that they need, however, the information’s gathered are the only a few results in the traditional Web Technology that found from various sources such databases and other websites. The semantic web technology analyzes user queries by aggregating from the various results and represents users that help to take actions for further needs which is not suggested in the current Web Technology. In the context, an intelligent algorithm performs a vital role in semantic web for knowledge representation that gathers user’s quires and analyzes them for future needs, where various intelligent algorithm developed and will continue until the appropriate knowledge representation algorithm have been developed. Some of the approaches of semantic web development for the knowledge representation reveals in related studies.
The research analyzes and illustrates the information retrieval and representation based on the semantic scheme, traditional, and ontology-based searches. The analysis indicates the framework for information retrieval as well as for knowledge representation by assembling the concept of semantic search, ontology and an intelligent agent algorithm that represents two different approaches based on the user query for appropriate knowledge representation. The following sections covered the related studies, illustrations of the traditional semantic search engines and web, information retrieval, and the proposed algorithm in the framework for knowledge representation with analysis and discussion. The conclusion with limitations and the future works for further study of the research.
-
II. Related Studies
The research introduces an intelligent agent algorithm that is related to multiple phenomena including the semantic search, semantic engine, ontology, information retrieval, and knowledge representation arranged in this related studies section. The semantic web technology is involved with diverse technical terms, therefore, being a diversity of the proposed framework and the intelligent agent algorithm, few of the terms previous work discuss in the following. Consequently, in the semantic web, data is stored respectively to XML (Extensible Markup Language), RDF, RDFs (RDF Schema) and the OWL (Ontology). Various semantic web search engines have been developed and keep the process, therefore, the engines are based on various factors and web engine searching activities are performed on the specific key concern. One semantic-based search engine is different and shows variant performance from the other web engines. Research implemented to an Ontological Search Engine entitled 'IBRI-CASONTO' which is based on the ontological graph. Initially, it was designed for the College of Applied Sciences (CAS) in Oman. The structures of search engines are the inference, storing, indexing, searching, query, and the interface. Two experiments conducted for performance measure; first with keyword-based and the other was compared the proposed engine with other engines such as Kngine, Wolfram-Alpha, and Google. The ratio of the result was precious that queried 40 and retrieved 23 relevant answers and 17 were irrelevant, where the other engines answered more, although not much relevant like the proposed engine [7]. The development of the semantic web search technique initiated for several years; an XML based semantic search engine developed that entitled to 'XSEarch'. It was query language that suitable for naive users only which returns the related documents by satisfying users' queries. The answers ranked by the techniques of extended information-retrieval and generate a similar ranking. The advanced indexing techniques were developed for efficient XSEarch implementation. The performance as recall and precision was measured experimentally which indicated the engine was scalable, efficient and ranked the results highly, even if, the engine is useful only for the naive users [8]. This semantic-based file system engine called 'Eureka', that used an inference model linked between files and the file rank metric for ranking according to the semantic importance of the search. Two processes performed in Eureka; 1). the crawler extracts files from the file system and generated two indices as keywords for record keywords and the rank index for the record of metrics of file rank. 2). The second process is by entering a query, the engine matches the term keywords and determines the files and the ranking orders by based on the metrics of the file rank. The result was a small subset of high FileRank, need to collaboration into FileRank and conventional Information Retrieval based ranking [9]. A methodology on semantic search raised for retrieving information from the tables consisting of three steps: to identify the semantic relationships within a table, to convert the table into the data in database form and retrieve the data using the query language [10]. The research purpose was to use a table and domain knowledge that converts a table into a database with semantically. The semantic preserving transformation used to database format from the tables. In experiments, one failed for lack of ontology knowledge for reorganization and many empty cells.
A semantic search process called 'Avatar' combining with the conventional text search engine that used the ontology. The two functions are; first one extraction and representation, and the other one is an interpretation that transforms the keyword searches automatically into several pieces of searches. The two parts of the Avatar engine are; the semantic optimizer and interaction engine.
The inputted query ranked a list of interpretations and the top-ranked interpretation displays and retrieve the information, although indexed and representation were done in a structured data store [11]. In search of PubMed is unable to retrieve all the relevant data, therefore, a semantic search process developed and applied to the medical data retrieval called 'LitVar', which retrieved variant information. A user query enters in LitVar that normalizes query and finds the best matching from a database with disambiguation results. Later on, returns a list containing the variants that ordered by the date. The technical processes are; aggregated entities and snippets since PubMed and PMC-OA storing them in MongoDB. The Django server processes requests for both web applications and RESTful API. The LitVar supports popular browsers like Safari, Chrome, Firefox, IE11. The limitations are; variant search system, limited database, and unable to recognize variant of formats [12]. A novel semantic information retrieval framework presented that is knowledge-based using ontology. It contains three terms; ontology design, semantic similarity, and ranking calculation. The approach outperforms the keywordbased, even implicit knowledge without formal queries such as SPARQL. The framework is ontology-based that retrieves the knowledge in a mechanical domain. The purpose was to introduce a user-friendly Information Retrieval system for high retrieval.
The keyword-based query translates automatically into a Boolean model, it can understand the query with a few keywords and then implements it in a human-computer interface and handles without specific training. The drawbacks are; data processors and limited to a keyword by a colon [13]. In the handheld platform such as, for mobile devices, the semantic search technique has been implemented in research. Proposed a mobile ontology, that supports the semantic search which retains existing system data storage, and the system composed the ontological concepts and semantic relationships and conceptualizes system data stored in the DBs by following the OWL syntax. The four steps are translation user query to graphs, extraction answer graphs, ranking the answer graphs, and executing the SQL statements. A few limitations were, it could not perform various queries and unable to interpret the intention of the user's query [14]. The semantic search was in used for the image retrieval, here proposed an ontology-based engine as domain-specific ontology based on the user query. The user input can be a concept or keyword or an image that uses the input as shape, color, and texture for classification. This is such a Content-Based Image Retrieval (CBIR) and still limited to understand the semantic meaning of the images [15]. The research proposed a semantic search approach called ‘*path’ for querying RDF knowledge graphs to explore the term networks. It evaluated by employing the datasets instead of question answering as semantic searches performed score rather than the existing semantic search system. Limitations of the system are to implementing complex queries [16]. A semantic search framework as 'Mimir' introduced, it is able to index and search the full-text contents, documents, ontologies, and linguistic annotations. Mimir is beneficial for searching results requiring knowledge, rather than document contents. It combines texts Boolean Retrieval, graph search, and SPARQL based search. The advantage is extendable and can be added methods in the predefined APIs, where it is required to improve the query language as well [17]. For software components, a concept of semantic search entitled to 'SoftwareFinder' presented, where used simple ontology tag sets for software finding hosting site, semantic auto-suggestion, and recommendation for the similar software components [18]. The limitations and recommendations of the framework need to implement the ranking with heuristics based and linking with the software hosting sites.
-
III. Semantic Web, Search and Information Retrieval
Several questions arise on account of the semantic web and its technologies such; what is the semantic web? Is it different or replacement from the current World Wide Web? How it was built? How to search query on semantic web and how it works? What is the information retrieval in semantic web? And why information retrieval such appropriate knowledge representation is concerned in the semantic web and how? All these questions are relative and consecutive regarding the semantic web technologies. In this section, attempt to analyze and explain concerning the interrogations on the semantic web and its affairs. The research allocated this into three parts of semantic web interrogations; semantic web, semantic search engine and significance of information retrieval to appropriate Knowledge Representation (KR).
As speculated on what is the semantic web in the earlier sections, therefore, this part discusses the attention of the semantic web. The semantic web is a new form of web content rather than replacing on the current web which will unleash a revolution of future possibilities. For example, person A wants to treat for person B's physical disability, and person A searches for the treatment procedures along with the medicine on the web for the specific disease. The semantic web, in that case, retrieves the information based on the prescribed treatment for person B with the patient's condition, treatment, and future task as well. A software agent in semantic web returns the consecutive information's as required for the patient and the process done by semantic web intelligent agent where the ontology has been used in the web that is called knowledge representation which is readable by the human that structures data and machine-understandable [19]. The semantic web acting here as a well-defined structure that brings meaningful content or information's collaborating machine and the human. The current web technology works based on the user searching query for the disease or treatment search, as it will return partial sort of disease and treatment information's that displays on the web browser. Meanwhile, the semantic web represents the patient disease condition, treatment procedure, feasibility, future engagement, available date of appointment which is suitable for the patient and the doctor as well. The semantic web technology is not the separate or the replacement of the current World Wide Web [20], rather than is an extension of the current web technology which is, in fact, effective behind the current web technology moreover.
The second consideration indicates the semantic search engine as exemplified by several semantic search engines and its development in the related studies. Therefore, the semantic search engine works based on the searching intent and its contextual meaning rather than the keyword-based search that enabled in the current search engines such as Google and Bing. Semantic search engines consider few points; search intent, context, location, queries word and its synonyms, concept matching, and the relevant searching results that generalize and represent data to the users. Few challenges to consider for a semantic search engine such; efficiency, scalability, effectiveness, user experience and page ranking [21]. Traditional search engines are keywordbased, which shows results with high recall with less precision; one keyword retrieves thousands of results where most of them not carried answers of the keyword query. On this, get back to the previous paradigm of person A and person B; person A was tried to search the information's for the prescribed treatment of person B on the web, whereas, the current web search engine shows multiple results that are related to the treatment along with various less related results as well. This occurs, due to traditional search engine searches the results on the syntax-based query that matches the word or the phrase in any documents at any available web databases, and it fails sometimes for long queries or phrases that are not matches entirely [22]. In that case, the semantic search engine will retrieve the knowledge-based representation that links the data and ontology technique to find out the meaning and represents them for future acceptance.
Information retrieval is a cabalistic task in search engines as well as in the semantic web for knowledge representation. The IR begins when a user inputs a query in a system, and it identifies a collection of results that match with the query, specifically it finds also for different degrees. The conventional search engines, the IR system retrieves hundreds or thousands of links for the user query, and therefore, it required for the semantic value that to be understandable by the system [23]. A machine is not capable to understand of a human query, or the concept or meaning, it only searches the query that matches into other documents are available on the web; it retrieves information's thereby, however, it fails to represent the precise knowledge. The earlier example has dragged once again; person A searched for information of treatment for the person B. The result was retrieved along with several information and suggestions for the user query and that process occurred in the current web technology. The gathered information is not strictly related where some of them only match the word which is not a subsidiary for the user to make a decision and an action for the treatments that were found on the web. The semantic web will process the data and retrieve the information's as knowledge-based that understood my machine for what the user needs and the task for next approaches, although it is an important research area and still remains more limitations [24]. For semantic web, knowledge representation introduced the term user experience which is related to the usability of the user interface of the system. The usability of the interface must meet the user perception, satisfaction and reliable usability [25], which is in the most concern of HumanComputer Interaction (HCI).
-
IV. Research Design
The research designed with three phases understanding the whole process in itself such as finding the problems, previous research and development that is related, and the development of the previous approach or the new way. The first phase studies the background and the context of the semantic web, semantic search engine, information retrieval for appropriate knowledge representation, and developments with several previous studies. The second phase analyzes the significance and applications of the terms with illustrations that how affected in current web technology as well as in the semantic web. The third phase proposed a framework based on the ontology for appropriate knowledge representation for easy understanding and meaningful to the users. An intelligent agent algorithm entitled to IAA presented for processing the ontologies of the user query with dedicated the three intelligent conditions that separated into the two terms or ideas for appropriate knowledge representation.
-
V. A Framework for Knowledge Representation based on Ontology and Intelligent Agent Algorithm
It is significant for knowledge representation and the ontology in the semantic web. The moral approach of the research to introduce a semantic web framework based on OWL and the proposed intelligent agent algorithm (IAA) to appropriate knowledge representation that shows in the following Fig.1. In the framework, the semantic search engine and the OWL are the existing layers in the current semantic web technology where the IAA is the proposed algorithm for knowledge representation.
In Fig.1, represents the OWL is an existing ontology layer stack in the semantic web technology and is a former vocabulary description language that was used to define the properties and classes of the RDF resources [26]. In the proposed framework, the OWL layer remains as before and acts such as methodical in current semantic web technology. It was started to lightweight ontology language which contributes such class subsumptions computing and with the involvement of the large development communities [27], OWL became core ontology language on semantic web technology although the language recommended for further development. The proposed intelligent agent algorithm (IAA) represents in the following Fig.2.
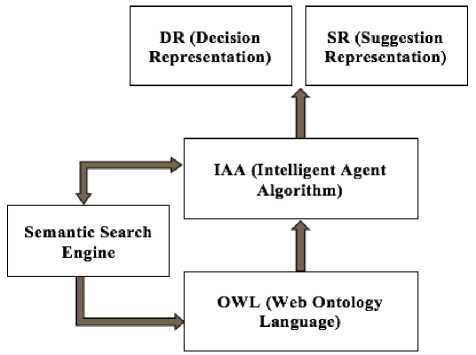
Fig.1. Proposed Framework for Appropriate Knowledge Representation based on Ontology and IAA х = phrase;
d = dl+d2+d3+d4+d5+d6;
dl = is;
d2 = are;
d3 = what;
d4 = how;
dS = when;
d6 = where;
s = sl*s2;
si = i;
-
s2 = am;
Step-1: if x = s.start OR s.match represent SR [Suggestion Representation] else go
Step-2: if x = d.start OR d.match represent DR [Decision Representation] else go
Step-3: if s.match >= d.match represent SR else represent DR
Fig.2. Intelligent Agent Algorithm (IAA)
In Fig.2, IAA is the intelligent agent algorithm that gathers the user search phrase from the semantic search engine. The engine executes the users’ search in which moves through the existing semantic web technologies such as URI, XML, RDF and RDFS, SPARQL, OWL, Proof, Trust and the other layers. Therefore, the IAA gathers the user's search phrase since semantic search engine which finds the relations and meaning by OWL and its vocabulary that prepares its result for representing the users. The task of IAA; intelligent agent algorithm finds phrases that start and match with the two predefined variables are DR (Decision Representation) and the SR (Suggestion Representation) with the values accordingly i, am, and is, are, what, where, how, and when. By analyzing through the research, it evident, that semantic web technology is not the replacement of the World Wide Web, rather than is an extension of the Web that enables it. Moreover, IAA divides its consequences into two variables as DR and SR whereas the values of the variables to be contained in the user search phrase. Three conditions are existing in IAA, firstly; it searches the values from search phrase for SR (I and am), secondly; it searches the values from phrase for DR (what, where, how, etc.), thirdly; searches the both of values from search phrase by analyzing more existence between the two variables SR and DR values, whether SR is high, it represents the SR, else represents the DR to the users. The motive of the two isolated representations of semantic value such as DR is the ordinary consequence that to be followed in present status based on the user query. The SR represents information for users to future suggestions which also based on the user query. In the context, the SR accomplishes its intelligent task such whether a user query starts and matches with I or am, that is refers, the user looking for or performing something that will be affected on the future activities and for DR represents its consequence for present activities whether the user query starts and matches with when, where, how, etc.; it refers the user searching something to know information's that is based on the user's present context.
-
VI. Analysis and Discussion
The analysis and discussion illustrate the framework and the proposed intelligent agent algorithm through an instance that how the user query represents information's to the users within the current World Wide Web and the proposed algorithm for semantic web that is based on the ontology that executes the knowledge representation through IAA. A user search query in the following:
QUERY: "I am looking for Star Wars movie DVD within 10$ price and the delivered time is maximum one week"
The above user query will represent several related and less related information's on the current Web technology and usually, it occurs being the current Web technology with keyword-based search techniques, rather than the meaning of the query as the machine does not understand the internal meaning of the user query. The keywords are Star Wars, movie, DVD, delivery time and the others are such few keywords for a machine and it searches those keywords from various texts and documents are available in the existing web databases, whenever matches the keywords, it returns and represents the information's to the users. In this context, on semantic technology, a user searches query through the semantic web search engine; it finds the relations and addresses of the query from the links available in existing web that connects data are accessible by machines and creates data model, finds meaning and shares information to the Web and application [28]. The semantic web technology will represent the information's likely based on the user query in the following:
ANSWER: "Star Wars movie DVD - 10$ - one week "
The above consequence of semantic web technology based on the user query and it could be varying from semantic web developments. Concerning in the proposed semantic web framework, one of the IAA variables is SR and the values are I and am that matches in the algorithm whereas by applying the intelligent algorithm, the SR will represent the suggestions for the query to the users as follows:
ANSWER: "Star Wars movie DVD - 10$ - one week ; Star Wars movie DVD - 8$ - 10 days - "
The SR represents two different outcomes of the searching for buying DVD containing various privileges from two websites which indicate suggestions, that one option is to be considered as price or time for the users of the product. The following query is an instance for DR to matches the phrase as:
QUERY: "What is the price of Star Wars movie DVD with delivery time within one week?"
In the semantic web, by applying the IAA, DR will represent the following information to the users based on the query:
ANSWER : "Star Wars movie DVD - 8$ or more - one week or more - from two sites"
The result is the formal representation on the semantic web by applying the IAA knowledge representation framework as DR, that the query started and matched with the word is What , which is one of the values in DR variable that refers a user want to have certain knowledge for an item within specified time and price. In IAA, the third condition for knowledge representation where the user query for the product as follows:
QUERY: "What is the best price of Star Wars movie DVD and the minimum delivery time if i order now?"
Following the third condition, the intelligent algorithm will represent from the DR variable into information containing the maximum matching in the DR variable values as follows:
ANSWER: "Star Wars movie DVD - 8$ - 10 days "
The three conditions of IAA represent three different knowledge for the users based on the three queries with a close identical sense. The user queries may have a similar or different meaning, however, on the semantic web, it refers to different consequences being understanding the meaning of the query by machine in which what exactly a user wants as formal information of the query? or the information's with a future task of the query?
The intends of the proposed intelligent agent algorithm is to help in the semantic web for appropriate knowledge representation based on the user quires for future needs. In current web technology, the user quires are yet to take as ordinary actions performed by the users in traditional search engines. Where the proposed IAA divided the user quires into two predefined variables are SR (Suggestion Representation) and the DR (Decision Representation). The values of the two variables defined in the algorithm that matches the values since user quires that they input in the semantic web search engine. Whether matches values from the user quires thereafter, it decides the action goes for the SR or DR. The following approach refers more precisely to the variables of IAA that representing more appropriate knowledge to users.
SR finds values from user quires (i and am) ^ SR suggests future actions to take based on the user query (as formal information).
DR finds values from user quires (is, are, what, how, when, and where) ^ DR decides future actions to take based on the user query (as a future task).
The above analysis addresses the findings of the research that proposed IAA in semantic technology for appropriate knowledge representation. The discussion evident the two variables of IAA, that how the variables of the algorithm find values since user quires, analyzes and represents information to user future needs as for suggestion or decision. Moreover, IAA is an intelligent agent that represents information and the future task for the users based on the meaning of the user query.
-
VII. Conclusion and Future Work
The research illustrates the semantic web technology, semantic web search engine, ontology, information retrieval, and the knowledge representations studies assist to carry out the approach. The semantic web knowledge representation framework with the proposed Intelligent Agent Algorithm (IAA) will help the semantic web for appropriate knowledge representation that users understand the query results into two patterns such as formal information and for the future task for better appearance. The three conditions of IAA are conceptual terms have defined as the words of phrase of the user's quires as variables, where the variables contain several values and these values promote into intelligent terms in IAA. The IAA analyzes the query among three conditions that follow the user query by dividing three significant ways in terms of mobilization of the knowledge representation that brings a specific meaning of the knowledge. The proposed algorithm in the framework is a developmental approach for the semantic web to appropriate knowledge representation rather than the alternation of any existing frameworks on semantic web technology. The proposed IAA is a new approach to the development of semantic technology. The previous developments that referred in the related studies are likely to concern on any specific phenomenon or to develop the search engine for user quires meanwhile, the proposed IAA divides the user quires into two different aspects and represents the information’s into two ways such as the formal information or the future task that to be taken by the users.
The proposed algorithm is IAA in the framework is a developmental approach, that is required to implement on semantic web technology for further acceptance of the intelligent agent concept which is the limitation of the research. The concept of the intelligent agent algorithm (IAA) is extendable that can be developed and extended into the next research. Future works suggested the implementation and evaluation of the intelligent agent concept for the appropriate knowledge representation on the semantic web technology. Another future work suggested revising the values of the two variables of IAA whether requires to improve the knowledge representation based on the user quires.
References Empowering Information Retrieval in Semantic Web
- Sanderson. M and Croft. W. B, “The history of information retrieval research,” Proceedings of the IEEE, 100 (Special Centennial Issue), pp. 1444-1451, 2012.
- Machado. L. M. O, Souza. R. R, and da Graça Simões. M, “Semantic Web or Web of Data? A diachronic study (1999 to 2017) of the publications of Tim Berners-Lee,” Association for Information Science and Technology, pp. 1-20, 2018.
- Barassi. V and Treré. E, “Does Web 3.0 come after Web 2.0? Deconstructing theoretical assumptions through practice,” New media & society, 14(8), pp. 1269-1285, 2012.
- Akgün. A and Ayvaz. S, “An Approach for Information Discovery Using Ontology In Semantic Web Content,” In Proceedings of the 2018 International Conference on Information Science and System, ACM, pp. 250-255, 2018.
- Aggarwal. C. C, “Information Retrieval and Search Engines,” In Machine Learning for Text, Springer, Cham, pp. 259-304, 2018.
- Polavaram. S and Ascoli. G. A, “An ontology-based search engine for digital reconstructions of neuronal morphology,” Brain informatics, 4(2), pp. 123-134, 2017.
- Sayed. A, and Al Muqrishi. A, “IBRI-CASONTO: Ontology-based semantic search engine,” Egyptian Informatics Journal, 18(3), pp. 181-192, 2017.
- Cohen. S, Mamou. J, Kanza. Y, and Sagiv. Y, “XSEarch: A semantic search engine for XML,” In Proceedings of the 29th international conference on Very large data bases-Volume 29, VLDB Endowment, pp. 45-56, 2003.
- Bhagwat. D and Polyzotis. N, “Searching a file system using inferred semantic links,” In Proceedings of the sixteenth ACM conference on Hypertext and hypermedia, ACM, pp. 85-87, 2005.
- Wang. H. L, Wu. S. H, Wang. I. C, Sung. C. L, Hsu. W. L, and Shih. W. K, “Semantic search on Internet tabular information extraction for answering queries,” In Proceedings of the ninth international conference on Information and knowledge management, ACM, pp. 243-249, 2000.
- Kandogan. E, Krishnamurthy. R, Raghavan. S, Vaithyanathan. S, and Zhu. H, “Avatar semantic search: a database approach to information retrieval,” In Proceedings of the 2006 ACM SIGMOD international conference on Management of data, ACM, pp. 790-792, 2006.
- Allot. A, Peng. Y, Wei. C. H, Lee. K, Phan. L, and Lu. Z, “LitVar: a semantic search engine for linking genomic variant data in PubMed and PMC,” Nucleic acids research, 46(W1), pp. W530-W536, 2018.
- Ma. S and Tian. L, “Ontology-based semantic retrieval for mechanical design knowledge,” International Journal of Computer Integrated Manufacturing, 28(2), pp. 226-238, 2015.
- Shin. S, Ko. J, Eom. S, Song. M, Shin. D. H, and Lee. K. H, “Keyword-based mobile semantic search using mobile ontology,” Journal of Information Science, 41(2), pp. 178-196, 2015.
- Manzoor. U, Balubaid. M. A, Zafar. B, Umar. H, and Khan. M. S, “Semantic image retrieval: An ontology based approach,” International Journal of Advanced Research in Artificial Intelligence (IJARAI), 1(4), pp. 1-8, 2015.
- Marx. E, Höffner. K, Shekarpour. S, Ngomo. A. C. N, Lehmann. J, and Auer. S, “Exploring term networks for semantic search over rdf knowledge graphs,” In Research Conference on Metadata and Semantics Research, Springer, Cham, pp. 249-261, 2016.
- Tablan. V, Bontcheva. K, Roberts. I, and Cunningham. H, “Mímir: An open-source semantic search framework for interactive information seeking and discovery,” Web Semantics: Science, Services and Agents on the World Wide Web, 30, pp. 52-68, 2015.
- Humm. B. G and Ossanloo. H, “A semantic search engine for software components,” In Proceedings of the International Conference WWW/Internet pp. 127-135, 2016.
- Bakar. Z. A and Ismail. K. N, “Base durian ontology development using modified methodology,” In Soft Computing Applications and Intelligent Systems, Springer, Berlin, Heidelberg, pp. 206-218, 2013.
- Berners-Lee. T, Hendler. J, and Lassila. O, “The semantic web,” Scientific american, 284(5), pp. 34-43, 2001.
- Fatima. A, Luca. C, and Wilson. G, “New Framework for Semantic Search Engine,” In Computer Modelling and Simulation (UKSim), 2014 UKSim-AMSS 16th International Conference on IEEE, pp. 446-451. 2014.
- El-gayar. M. M, Mekky. N, and Atwan. A, “Efficient proposed framework for semantic search engine using new semantic ranking algorithm,” International Journal of Advanced Computer Science and Applications, 6(8), pp. 136-143, 2015.
- Azizan. A, Bakar. Z. A, Khairuddin. N, and Saad. N. L, “Ontology-Based Information Retrieval: A Review,” In International Symposium on Mathematical Sciences and Computing Research, pp. 68-72, 2013.
- Chernenkiy. V, Gapanyuk. Y, Nardid. A, Skvortsova. M, Gushcha. A, Fedorenko. Y, and Picking. R, “Using the metagraph approach for addressing RDF knowledge representation limitations,” In Internet Technologies and Applications (ITA), IEEE, pp. 47-52, 2017.
- Mithun. A. M, Bakar. Z. A, and Yafooz. W. S, “Revised Theoretical Approach of Activity Theory for Human Computer Interaction Design,” In Science and Information Conference, Springer, Cham, pp. 803-815, 2018.
- Kontopoulos. E, Martinopoulos. G, Lazarou. D, and Bassiliades. N, “An ontology-based decision support tool for optimizing domestic solar hot water system selection,” Journal of Cleaner Production, 112, pp. 4636-4646, 2016.
- Gandon. F, “A survey of the first 20 years of research on semantic Web and linked data,” Revue des Sciences et Technologies de l'Information-Série ISI: Ingénierie des Systèmes d'Information, pp. 12-35, 2018.
- Niknam. M and Karshenas. S, “Integrating distributed sources of information for construction cost estimating using Semantic Web and Semantic Web Service technologies,” Automation in Construction, 57, pp. 222-238, 2015.
