Enhancing Churn Prediction through Advanced Machine Learning Techniques for Modern Education in Computer Science

Author: Pankaj Hooda, Pooja Mittal, Bala Dhandayuthapani Veerasamy, Ruby Bhatt, Chatti Subba Lakshmi, Shoaib Kamal, Piyush Kumar Shukla
Journal: International Journal of Modern Education and Computer Science @ijmecs
Article in issue: 1 vol.17, 2025.
Free access
Customer attrition is a major issue that affects the telecom industry as it reduces the company’s revenues and the overall customer base. Solving this problem involves the use of accurate prediction models that utilize CRM data and machine learning algorithms. Though several research papers have been written and published on CCP in the telecom industry, the existing models lack reliability and accuracy. The use of sophisticated data mining and machine learning techniques has been widely practised for improving predictive models. Churn prediction models that exist have their problems in terms of accuracy and errors. It is still important to develop more sophisticated models that can work well with large data and give accurate predictions. Therefore, this work aims to offer the OKMSVM model for multiclass cancer-type classification. The method applied for the dimensionality reduction pre-process is Kernel Principal Component Analysis (KPCA) and the feature selection pre-process is done using Ant Lion Optimization (ALO). This combination assists in improving the chance of the prediction and also the reduction of probable errors. The performance of the proposed OKMSVM model was compared with some of the most common churn prediction models such as HTLSVM, DNN, ICPCSF and other ML models. It was seen that the OKMSVM model outperformed other models with an accuracy of 91. 5%, an AUC of 85. Accurate, with a correlation coefficient of 0. 838. It further shows that this model is better than the current models in the market in estimating customer churn.
Modern Education, Computer Science, Customer Churn Analysis, Telecommunication, OKMSVM, KPCA, Hybrid Two Level SVM model, Integrated Churn Prediction and Customer Segmentation Framework
Short address: https://sciup.org/15019689
IDR: 15019689 | DOI: 10.5815/ijmecs.2025.01.07
Text of the scientific article Enhancing Churn Prediction through Advanced Machine Learning Techniques for Modern Education in Computer Science
The telecom industry deals with customers in large numbers and is rapidly growing in the market to produce large volumes of data daily. This data is invaluable for analyzing patterns and trends as they relate to customers and churn.
Data mining is crucial in a business organization to satisfy organizational requirements, allocate resources efficiently, and improve service delivery. The nature and volume of data make it important to use sophisticated methods for churn prediction and to provide decision-makers with timely insights.
The main goal is to compare the efficacy of the suggested OKMSVM model with existing churn prediction models, such as HTLSVM and DNN, ICPCSF, and other related machine-learning techniques. Applying the accuracy, AUC and RMSE for the evaluation of each model is important. When assessing the performance of each model, it is necessary to look at the accuracy of the model, the AUC, and the RMSE. In evaluating each model's performance using its accuracy, it is important to consider root mean square error (RMSE) and area under the curve (AUC). The following are this study's main contributions:
• The paper presents an enhanced Kernel Multi-class Support Vector Machine model called OKMSVM. To overcome this, the high dimensionality of the feature problem is fixed using KPCA, which also enhances the model's performance and prediction accuracy. The model is then improved using the ALO technique.
• Accordingly, the present study can achieve the said objectives effectively by using the KPCA to reduce the data dimensionality to a large extent while incurring less data loss. To enhance feature extraction and the predictive mode's performance, this procedure converts the dataset into a high dimensional linearly separable feature space.
• The OK-MSVM model employs the ALO in feature selection and optimization and this has the advantage of eliminating errors in the feature sets. By focusing on the most beneficial characteristics and those that may help increase the accuracy of the provided model and the RMSE value, this iterative procedure is helpful.
• The research also offers a comparison between the suggested OKMSVM model and other churn prediction models, like HTLSVM and DNN, ICPCSF, and traditional machine learning algorithms. The comparison is made with OKMSVM using parameters like Accuracy, AUC, and RMSE establishing the supremacy of the OK-MSVM model.
2. Literature Review
This work is organised into different sections: Prior works have been reviewed in section 2. The proposed model and other popular churn prediction models for telecom churn prediction and analysis are explained in section 3. Summary of tools and dataset along with a comparative analysis of the performance of these churn prediction models considering three parameters i.e. AUC, in section 4, the accuracy and RMSE score are given. Section 5 discusses the results and potential applications.
Because of advancements in technology and easier access to a greater variety of goods and services, consumer preferences and expectations have changed. This has made the customer service industry—including the financial sector—extremely competitive. To understand the methodologies for churn prediction in a better manner, these have been discussed and compared in this section. Jain et al. proposed a machine learning-based solution for multi-attribute strategic planning in 2021 [11]. The worker churn prediction and retention method was the name given to the recommended approach. We classified employees using a two-step technique and developed an incredible paradigm about the value of employment and benefits. The suggested methodology's initial suggestion was to boost the usage of an entropy-based mechanism for allocating weights to staff performance. In addition, an advanced methodology (CatBoost) was implemented to evaluate staff performance and the value of its class-based classification. The CatBoost approach was then applied to categorise and forecast employee absenteeism. The authors then proposed a retention strategy based on the outcomes of the forecasts and attribute scores. To predict whether a client will unsubscribe and to estimate how customers will pay for services, [12] created a two-tier unsubscribe technique. This classifier utilised the SVM classification method, and SVR based on machine learning was used to predict the recurrent monthly expense. The best-fit features, including both ratings, were chosen using a method for choosing attributes called the MCFS approach. To preserve uniformity and assess the method's effectiveness, an identical attribute selection approach was used in both assessments. Then, mostly using IBM, the proposed schema technique was evaluated. To ensure its applicability and generalizability, the dataset for Telco Customer Churn, which contains more than 7000 customers, was used.
Using an advanced learning technique, Bayrak, A. T., et al devised a model for estimating churn rate in 2020 [13]. The model was made using the Long Short-Term Memory (LSTM) technique. In the customer information architecture, customer information is set up in a particular order. Information sequencing is used to construct a long short-term memory design that compares existing classification techniques while identifying user conversion stages. Even with the assumptions, the proposed model was successful and distinguished itself from the related study. [14] offered paper highlighting the characteristics of churn, which are important considerations when determining its primary source. CRMs can increase productivity, provide talented customers with targeted incentives tied to particular behaviour patterns, and significantly enhance an organization's advertising campaigns by recognising dynamics. user insights are a driving factor. The proposed consumptive estimating method's receiver performance characteristic, recovery, accuracy, precision, and f-measurement are all studied. The findings show that the proposed churn approach significantly classified customers' time and preferences using R.F. and k-means cluster formation. A model based on anticipating frequent interruptions rather than quarterly interruptions, depending on the characteristics of active users was proposed by Alboukaey et al. in 2020 [15]. The authors provide four description-based predictions to forecast daily client income and portray daily consumer behaviour as multidimensional data. Seymen, et al. (2020) [16] have suggested a deeplearning approach to ascertain whether commercial buyers come back later. Regression analysis and cumulative neural network techniques, which are typically utilised in assessments of churn estimations, were used to validate the framework. Remember that a reliability classifier was used by Precision and A.U.C. to evaluate algorithm outputs. The research demonstrates that in prediction and classification, the trained model outperforms alternative approaches. A framework for machine learning that uses an integrated approach was created by Hu, X., et al. in 2020 [17]. In the integration approach, neural networks based on machine learning and decision trees were used. In this study, an effective statistical churn prediction model is created, and its effectiveness is evaluated using statistical findings.
An approach to forecasting telecoms discontinuity that incorporates composite overlay and elevation approaches has been put out by Ahmed et al. (2019) [18]. The assessments have made use of conventional cost and performance (cost) heuristics, with expenditure heuristics getting the greatest attention. The suggested methodology and activities are suitable for most procedures with a high cost of operation due to the high degree of correlation between performance metrics and business goals.
For phones that measure consumer time spent, [19] developed a method attributed to machine learning methods and particle classifier performance-adjusted back-propagation network (B.P.). It is advised to periodically execute PFC (Particle Physical Computation) and PCO (Particle Classification Optimization).
To anticipate churn using the approach of machine learning, [20] and [21] have created estimating methods.
Machine learning approaches were utilised by Butgereit et al. (2020) [22] to forecast when a customer is about to unsubscribe and whenunsubscribers are being thought about. Following that, these estimations are used to look for user input log files that are semi-structured or unstructured to provide reasons why a user might unsubscribe.
Joydeb Kumar Sana et al. [23] suggested a method that increased prediction accuracy by as much as 26.2% and 17%, respectively, in terms of AUC and F-measure.
LewlisaSaha et al. [24] advocated a study design that estimates customer churn rate, or whether a subscriber would quit or not, by examining their behavioural pattern.
2.1 Problem Statement
3. Models for Churn Prediction3.1 Proposed Optimized Kernel MSVM (OKMSVM) MODEL
Despite numerous advancements in churn prediction methodologies, several research gaps persist in the literature. Many studies focus on specific aspects of churn prediction, such as feature selection or classification accuracy, but often lack comprehensive approaches that integrate multiple techniques.
Telecom companies have long been plagued by the problem of churn, which in simple terms entails customer attrition and a consequent loss of revenue. Solving this problem requires building good prediction models that can incorporate CRM data and sophisticated statistical models. Despite extensive research on CCP in the telecom industry, most models developed so far are unable to provide high accuracy and dependability. The existing churn prediction models are also a challenge in aspects like accuracy and error rate and this has led to the development of better techniques that can handle big data and offer accurate results. However, it is still possible to enhance the predictive models even more with the assistance of modern techniques like data mining and machine learning. Still, some of the current models have issues such as high error rates and the absence of suitable methods to process different, large data. Therefore, this research introduces the OKMSVM model to improve the prediction of churn. This model applies KPCA to undertake the dimensionality reduction step and ALO to undertake the feature selection step. This combination is intended to increase the levels of prediction as well as reduce the levels of errors.
This section comprises our proposed model and existing models. A comparison of these models is represented here to show the betterment of our model.
This section explains the proposed optimized kernel MSVM model [25,26]. For optimization purposes, the ALO technique is used, and KPCA is employed to decrease the dimensions of the features. The feature patterns combine M*N matrix numbers that make up an exclusive combination against a certain case. The KPCA modelling of the suggested architecture handles the feature extraction procedure. The KPCA method is used to extract a matrix's characteristics. Without considerable data loss, it decreases the dimensionality of the data. It is used on the dataset that can be linearly separated. Unlike previous techniques, the database is projected into a high-dimensional, linearly distinguishable feature space via KPCA employing a kernel function. The Ant Lion optimizer processes the extracted characteristics. The suggested architecture's ALO optimization module aids in lowering the likelihood of an error in the feature set. The trained model performs with greater precision owing to the training set with lower error probabilities. Determining the most economical input feature patterns is an iterative process. The initial module of the estimation method analyzes the data element once all cases have been processed. The optimized data elements are processed by this module, which also creates various subsets of the original datasets. The prediction model is trained, validated, and tested using these subsets. During this phase, the patterns' labels and training subsets are processed with the training module. To load and carry out test phases, it introduces and stores the OKMSVM model in the secondary storage. Based on the supplied dataset, the Churn analysis method is tested to create predictions. Before initiating the MSVM prediction algorithm, the test set loads the training module and the test subset.
The OKMSVM model flowchart is shown in Fig.1. The OKMSVM model is intended to improve customer churn forecast accuracy and dependability in the telecom sector. Through the use of Ant Lion Optimisation (ALO) for feature selection and KPCA for dimensionality reduction, they overcome the issues of high error rates and inadequate handling of large and complex data. By making the data linearly separable and minimising data dimensionality, KPCA is used to map the data to a higher dimensional feature space. The ALO technique subsequently refines the feature selection process and reduces the probability of producing erroneous solutions to improve the model’s accuracy.
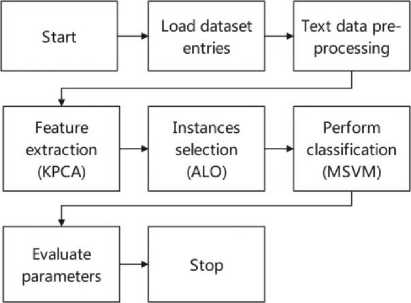
Fig. 1. Process flow of Optimized Kernel MSVM Model
This model shows potential for forecasting real-time datasets since MSVMs employ a risk-minimization technique that accounts for the error. forecasting component, the efficiency of the suggested architecture is calculated using a variety of performance metrics. The comparison sets are created using the computed performance measures, which also serve to verify the effectiveness of this enhancement.
-
3.2 Existing Churn Prediction Models
-
3.2.1 Hybrid Two-Level SVM model
The hybrid two-level SVM (Support Vector Machine) model used the SVR (Support Vector Regression) and MCFS (Multi-Cluster Feature Selection) model. For this categorization component, a classification approach known as support vector machine was used, and to predict a recurrent monthly cost, a support vector regression approach based on machine learning was used [12]. The most pertinent characteristics, taking into account both evaluations, were chosen by the multi-cluster feature selection strategy, an autonomous feature selection technique. To determine its effectiveness, the same attribute selection method for uniformity was used in both assessments. IBM Telecom dataset having 7036 samples (users) with 21 features was used and simulation was done with the help of e-commerce tools. It was evaluated and performed at a similar time with a maximum accuracy rate. It provided an accuracy of 81.5%, AUC of 85.6% and RMSE score of 3.01.
-
3.2.2 Integrated Churn Prediction and Customer Segmentation Framework
-
3.2.3 Machine Learning Approach
Lalwani et al. employed a machine-learning approach in 2021 [28]. Six steps make up the suggested strategy. During the first two phases, feature analysis and data pre-processing are done in the third stage, feature selection is taken into consideration using the gravitational search approach. The data was subsequently divided into two groups: the train set, which made up the remaining 80% of the data, and the test set, which made up 20% of the total data. A variety of popular predictive models, such as logistic regression, random forests, decision trees, naive Bayes, support vector machines, etc., have been employed in the prediction process. Ensemble and boosting techniques have also been used to assess the effect on model accuracy. Additionally, on the train set, K-fold cross-validation has been utilised to adjust the hyperparameters and avoid overfitting the models. Lastly, the results of the test set were examined using the AUC curve and confusion matrix. The results showed that the XGboost and Adaboost Classifier exhibited the highest accuracy, with corresponding values of 80.8 and 81.71 percent. Both the XGBoost and Adaboost classifiers beat others and got the greatest AUC score of 84 percent.
-
3.2.4 Deep Neural Network
This section discusses the existing and popular churn prediction models for telecom churn prediction and analysis.
Customer segmentation, factor analysis, churn prediction, data pre-processing, exploratory data analysis (EDA), and analytics of customer behaviour are the six elements of the Telco Business Integrated Churn Prediction and Customer Segmentation Framework (ICPCSF) [27]. This approach combines the segmentation of customers and forecasting churn to give telco operators an in-depth investigation of customer churn. The tests using six machine learning classifiers use three datasets. First, several machine learning classifiers are used to estimate the consumers' churn state. The training set is exposed to the Synthetic Minority Oversampling Technique to solve the issues related to unbalanced datasets (SMOTE). Ten-fold cross-validation is used in the models' assessment. The model's accuracy and F1-score are used to evaluate it. The F1-score is regarded as a vital indication to evaluate models for unbalanced datasets since the ability to identify customers who would quit is the foundation of churn management. AdaBoost demonstrated the best performance in Dataset 1 according to the experimental study, with an F1score of 63.11 percent and an accuracy rate of 77.19 percent. With an F1-score of 77.20 percent and an accuracy rate of 93.6 percent. In Dataset 2, Random Forest delivered the best results. Random Forest outperformed Multi-Layer Perceptron in Dataset 3 in terms of F1-score, scoring 63.09 percent, and 42.84 percent accuracy. Following the implementation of churn prediction, factor analysis is done using Bayesian Logistic Regression to identify some key features for turnover customer segmentation. Then, K-means clustering is utilised to divide up customers who churn. Customers are divided into various groups, allowing marketing professionals and promoters to more precisely implement retention measures.
Hyperparameter tuning random search testing is used in DNN modelling to ascertain the learning rate, dropout as well as the number of nodes in every hidden layer [29].
Testing was then done with three different hidden layer counts, two different activation functions (Sigmoid and ReLu), and five different optimizer modifications (Adam, SGD, Adagrad, RMSprop and Adadelta).
30 batch sizes and 50 epochs were used to train this model. Findings indicate that the DNN algorithm, which uses hyperparameter tuning random search, surpasses modelling utilising the comparison techniques of decision tree (DT), random forest (RF), and k-nearest neighbour (K-NN), utilising three hidden layers and the RMSprop optimizer, [16,9] being nodes per hidden layer, a learning rate of 0.01, and 0.1 dropouts, with a performance value of 83.09 percent accuracy.
4. Performance analysis of Proposed and Existing Models
In this section, we compared our proposed model with the existing models on three classification metrics i.e. Accuracy, AUC and RMSE Score.
All the existing models and proposed models have been implemented on a common dataset i.e. "WA_Fn-UseC-Telco-Customer-Churn" data set. [15]. This dataset contains 21 columns (referred to as “properties”) and 7043 rows (referred to as "users") of raw data. 21 characteristics are used as the target position for the regression and categorization activities. The training phase is created using Python, a language with a scripting foundation. To help the user click and see the outcomes, it creates the man-to-machine interfaces.
Three parameters are used for the evaluation of the performance of these models. These are Accuracy, AUC and RMSE Score.
AUC: The entire amount of classification assessment necessary to implement all projected categorization options can be calculated from the area under the curve. The accuracy percentage can be described as;
Accuracy = 100 * —f—---y . ’ —p—(1)
RMSE: One often used measure to assess a model's predicting accuracy for quantitative data is the Root Mean Square Error (RMSE). The official definition is as follows:
RMSE = .^^^^(2)
Here, n1 stands for the total sample count in the telecom dataset, and yl i and yl’ i for the intended and expected values.
Accuracy: To determine a test's accuracy, the percentage of genuine positive and true negative findings across all instances analysed must be determined. The following can be expressed mathematically:
accuracy =
tp+tn tp+fp+fn+tn
Here, tp stands for True Positive, tn for True Negative, fp for False Positive, fn for False Negative respectively.
The suggested model for churn prediction outperforms previous methods based on implementation. The comparison of the models according to Accuracy, AUC and RMSE score is displayed in Table 1 as follows:
Table 1. Comparison based on different evaluation parameters
|
MODEL |
Accuracy |
AUC |
RMSE Score |
|
OKMSVM |
91.05% |
85.76% |
2.838 |
|
HTL SVM |
81.50% |
85.60% |
3.01 |
|
DNN |
83.09% |
84.9% |
2.99 |
|
ICPCSF |
83.70% |
84.52% |
3.04 |
|
ML Approach |
81.26% |
84% |
2.97 |
The results show that the OKMSVM-based model outperforms other models because it can choose distinctive and relevant attributes. Using ALO, it achieved a high classification accuracy rate of 91.05% and AUC of 85.76%, outperforming the results of other models.
As we can see from the above table, the OK-MSVM model outperforms the most popular churn prediction models like HTLSVM, DNN, ICPCSF and ML approach in terms of accuracy and AUC.
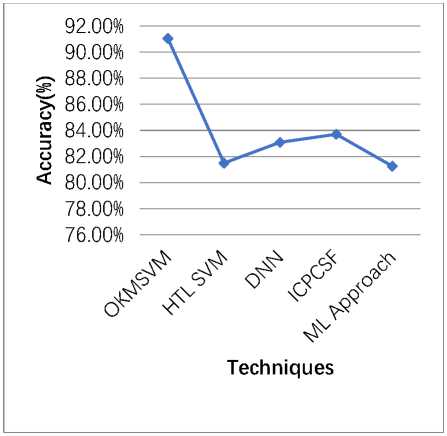
Fig. 2. Accuracy comparison of OK-MSVM with popular churn prediction models
Fig. 2 shows the comparison between the OKMSVM model and several churn prediction models that are popular in the current literature. The metric measures how accurately each model is in predicting customer churners, that is, those who are likely to leave. The accuracy metric is quite simple and quantifies the models’ performances with higher values being more favorable. The chart illustrates how accurate the OKMSVM model is when compared to other models, demonstrating the model's effectiveness and dependability in churn prediction.
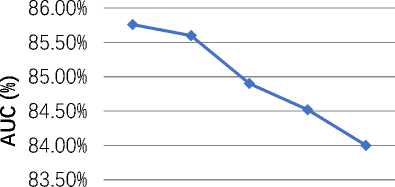
83.00%
Techniques
Fig. 3. AUC comparison of OKMSVM with existing churn prediction model
Figure 3 shows the AUC values for the different churn prediction models as well as the suggested OKMSVM model. Because it incorporates both the true positive rate and the false positive rate, AUC provides a useful performance metric for classifying models by indicating how well a model performs in terms of classification. The AUC demonstrates how effectively the model can distinguish between clients who are likely to churn and those who are not. The figure also displays that the OKMSVM model, which has the highest AUC score, is much more efficient in terms of the likelihood of customer churn as compared to the other models.
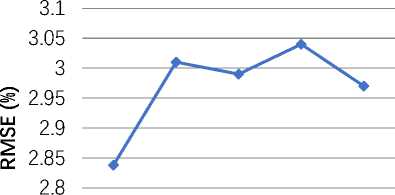
2.75
2.7
Tehniques
Fig. 4. RMSE comparison of OKMSVM with existing churn prediction models
Figure 4 displays the RMSE of the OKMSVM model in addition to the RMSE of the other churn prediction models. A relative measure of the variation between expected and actual values is called RMSE; therefore, the best model performance is expected when the value of RMSE is as small as possible due to the smaller prediction errors. This figure also proves that the proposed OKMSVM model is helpful in churn prediction since the RMSE of this model is less than other models. This indicates that in addition to yielding accurate predictions, the OKMSVM reduces the degree of error in its prediction, further underlining its usefulness in real-world scenarios.
Because OK-MSVM optimized the classification model and feature selection was implemented, it contains improved performance measures as compared to existing models such as HTLSVM, DNN, ICPCSF and ML approach. Additionally, ALO reduces the RMSE score to 2.838, reducing the possibility that feature sets may contain errors. The model proposed with all feature sets has better root mean square error rates than existing popular models.
5. Conclusion and Future Work
By putting out and evaluating an OKMSVM model, this study adds to the corpus of information already available in the field of customer churn prediction, particularly in the telecom industry. The proposed approach is beneficial in the following ways in addressing the limitations of the existing models, especially about accuracy and error rates. It is possible to deduce from the comparison study that the suggested OKMSVM model is more accurate than the current models, including HTLSVM, DNN, and the ICPCSF. It has achieved 91% accuracy in classifying the images of the given objects. 5%, an AUC of 85. Specifically, the mean age was 29. 838, in addition to improving the prediction accuracy, the OKMSVM model also offers a handy tool for telecom firms to better plan for customer retention. This improvement in predictive accuracy is essential for sustaining and building customer relationships, which in turn are fundamental for the financial solvency and development of telecom enterprises. The scientific relevance of this work is based on the possibility of becoming a guide for telecom companies in the definition of strategies to predict customer churn. With the use of improved machine learning techniques and improved feature extraction techniques, the OKMSVM model has provided a new platform for performance in this area. It is possible that future research can consider using other advanced machine learning algorithms and optimization methods to increase the model’s precision and versatility. Furthermore, this model could be applied to other industries that have the same issue of customer churn and it could be trialled in other sectors.
References Enhancing Churn Prediction through Advanced Machine Learning Techniques for Modern Education in Computer Science
- S, E., "A proposed churn prediction model." International Journal of Engineering Research and Applications 2, no. 4 (2012): 693-697.
- V. Lazarov, and M Capota. "Churn prediction." Bus. Anal. Course. TUMComput. Sci 33 (2007): 34.
- B, Ionut, and G Toderean. "Churn prediction in the telecommunications sector using support vector machines." Margin 1 (2013): x1.
- Bandara, W. M. C., Perera, A. S., and Alahakoon, D. "Churn prediction methodologies in the telecommunications sector: A survey." In 2013 international conference on advances in I.C.T. for emerging regions (ICTer), pp. 172-176. IEEE, 2013.
- Acero-Charaña, Carlos, Erbert Osco-Mamani, and Tito Ale-Nieto. "Model for Predicting Customer Desertion of Telephony Service using Machine Learning."
- Ewieda, Mahmoud et al., "Review of Data Mining Techniques for Detecting Churners in the Telecommunication Industry." Future Computing and Informatics Journal 6, no. 1 (2021): 1.
- Khedra, MM Abo, et al. "A Novel Framework for Mobile Telecom Network Analysis using Big Data Platform."
- Jadhav, Rahul J., and Usharani T. Pawar. "Churn prediction in telecommunication using data mining technology." International Journal of Advanced Computer Science and Applications, (2011).
- Yihui, Q., and Chiyu, Z. "Research of indicator system in customer churn prediction for telecom industry." In 2016 11th International Conference on Computer Science & Education (ICCSE), pp. 123-130. IEEE, 2016.
- Zhao, M., Zeng, Q., Chang, M., Tong, Q, and Su, J. "A Prediction Model of Customer Churn Considering Customer Value: An Empirical Research of Telecom Industry in China." Discrete Dynamics in Nature and Society 2021 (2021).
- Jain, N., Tomar, A., and Jana, P. K "A novel scheme for employee churn problem using multi-attribute decision making approach and machine learning." Journal of Intelligent Information Systems 56, no. 2 (2021): 279-302.
- Sarac, F., Şeker, H., Lisowski, M., and Timothy, A "A Hybrid Two-Level Support Vector Machine-Based Method for Churn Analysis." In 2021 5th International Conference on Cloud and Big Data Computing (ICCBDC), pp. 77-81. 2021.
- Bayrak, A. T., Aktaş, A. A., Susuz, O., &Tunalı, O. "Churn prediction with sequential data using long short term memory." In 2020 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), pp. 1-4. IEEE, 2020.
- Deng, Y., Li, D., Yang, L., Tang, J., & Zhao, J. “Analysis and prediction of bank user churn based on ensemble learning model”, In 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), pp. 288-291, 2021.
- Alboukaey, Nadia, Ammar Joukhadar, and Nada Ghneim. "Dynamic behavior based churn prediction in mobile telecom." Expert Systems with Applications 162 (2020): 113779.
- Seymen, Omer Faruk, OnurDogan, and AbdulkadirHiziroglu. "Customer Churn Prediction Using Deep Learning." International Conference on Soft Computing and Pattern Recognition. Springer, Cham, 2020.
- Hu, X., Yang, Y., Chen, L., & Zhu, S. (2020, April). Research on a customer churn combination prediction model based on decision tree and neural network. In 2020 IEEE 5th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA) (pp. 129-132). IEEE.
- Ahmed, Ammar AQ, and D. Maheswari. "An enhanced ensemble classifier for telecom churn prediction using cost based uplift modelling." International Journal of Information Technology 11.2 (2019): 381-391.
- Yu, Ruiyun, et al. "Particle classification optimization-based B.P. network for telecommunication customer churn prediction." Neural Computing and Applications 29.3 (2018): 707-720.
- Abou el Kassem, Essam, et al. "Customer Churn Prediction Model and Identifying Features to Increase Customer Retention based on User Generated Content." IJACSA) International Journal of Advanced Computer Science and Applications 11.5 (2020).
- Khan, Yasser, et al. "Customers churn prediction using artificial neural networks (ANN) in telecom industry." Editorial Preface From the Desk of Managing Editor 10.9 (2019): 2019.
- Butgereit, Laurie. "Big Data and Machine Learning for Forestalling Customer Churn Using Hybrid Software." 2020 Conference on Information Communications Technology and Society (ICTAS). IEEE, 2020.
- JK Sana et al, "A novel customer churn prediction model for the telecommunication industry using data transformation methods and features election" PLoSONE17(12): e0278095, 2022.
- LewlisaSaha et al, 'Deep Churn Prediction Method for Telecommunication Industry", Sustainability, 15, 4543, 2023.
- Pankaj Hooda, Pooja Mittal, “An Optimized Kernel MSVM Machine Learning-based Model for Churn Analysis” International Journal of Advanced Computer Science and Applications (IJACSA), 13(5), 2022
- Pankaj Hooda, Pooja Mittal, "IMPLEMENTATION AND PERFORMANCE ENHANCEMENTS OF OPTIMISED KERNEL MSVM MODEL FOR EARLY CHURN PREDICTION IN TELECOM SECTOR", Semiconductor Optoelectronics, 42 (1), 280-298, 2023.
- S. Wu, W. -C. Yau, T. -S. Ong and S. -C. Chong, "Integrated Churn Prediction and Customer Segmentation Framework for Telco Business," in IEEE Access, vol. 9, pp. 62118-62136, 2021
- Lalwani, P., Mishra, M. K., Chadha, J. S., and Sethi, P. "Customer churn prediction system: a machine learning approach." Computing (2021): 1-24.
- H. Nalatissifa, and H.F. Pardede, "Customer Decision Prediction Using Deep Neural Network on Telco Customer Churn Data," JurnalElektronikadan Telekomunikasi, vol. 21, no. 2, pp. 122-127, Dec. 2022
