Evaluation of Information Retrieval Based Ontology Development Editors for Semantic Web

Author: N. Kaur, H. Aggarwal
Journal: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Article in issue: 7 vol.9, 2017.
Free access
Ontology is one of the central area in natural language processing (NLP), artificial intelligence (AI) information retrieval (IR) and semantic web (SW). If you are working on ontology project, this paper will give you the relevant information about ontology related terms and best ontology development editor. In this paper five ontology development editors are reviewed and compared with their updated versions. They are Apollo1.0, SWOOP 2.3Beta4, Protégé 5.0, Graffoo 1.0 and Neon 2.5.2. Comparison of two main data models ontology and RDBMS is also done. This paper also present the classification of ontology languages from those reported in the Literature, with a special attention accorded to the interoperability between them. Additionally, this paper presents the important terms related to ontology. The main criterion for comparison of these tools and languages was the user interest and their application in different kind of real world tasks. The primary goal of this study is to introduce these important tools, languages and data models to ensure more understanding from their use.
Ontology, Semantic Web, Information Retrieval, Web services, Ontology Development Tools, Protégé, SWOOP, Neon, Graffoo, Apollo
Short address: https://sciup.org/15014987
IDR: 15014987
Text of the scientific article Evaluation of Information Retrieval Based Ontology Development Editors for Semantic Web
Published Online July 2017 in MECS
The world wide web commonly referred to as just web is the most extensive and widely used knowledge sharing platform and information space based on three pillars or standards namely Uniform Resource Locator (URL) -“address of any resource to give access on web in a uniform way, Hypertext Transfer Protocol (HTTP)-communication protocol used to send or receive named resources over the web aand Hypertext Mark-up Language(HTML)- language in which the resource are formatted[7].This is the largest database in the universe which is mostly understandable by human users and not by machines. For a given query using a search engine, it returns with a very large number of resulting web pages, most of which are irrelevant [4, 22]. In other words, it lacks a semantic structure, which could help the www to ‘understand’ what exactly the user is looking for and would also enable the machines and software to make use of the human information available without human intervention. To increase the integration and interoperability over the web the concept of “Web Service” was introduced [7].
A Web service is a service offered by an electronic device to another electronic device, communicating with each other via the World Wide Web. Generally web service is a software system designed to support interoperable machine-to-machine interaction over a network. Web Service become hugely popular in short span of time but over a period of time, with increase in the number of such services, new issues cropped up like end-to-end service authentication, authorization, security data integrity, confidentiality aand augmentation of meaningful contents in mark-up presentation over the web a semantic based solution “Semantic Web” was introduced by Tim Berners Lee [7]. Semantic Web is an extension of the current World Wide Web where the information in machine understandable form that translates the given unstructured data into knowledgeable representation data thus enabling computers and people to work in cooperation. It is also called as Global Information Mesh (GIM) [1]. The concept of ontology has contributed to the development of Semantic Web. The current www does not support the concept of ontology and users cannot make inferences due to unavailability of complete data .Ontology enables the Web for software components can be ideally supported through the use of Semantic Web technologies [4].
-
II. Need of Ontology
Ontology is formal and explicit specification of a shared conceptualization. Explicit specification of conceptualization means that ontology is a description of the concepts and relationships that can exist for an agent or a community of agents [4]. ‘Explicit’ means that the type of concepts used and the constraints on their use are explicitly defined. ‘Formal’ refers to the fact that the ontology should be machine readable [24].
Ontology has become common on the World-Wide Web. Ontology defines a common vocabulary for researchers who need to share information in a domain. It includes machine-interpretable definitions of basic concepts in the domain and relations among them.
The use of a shared vocabulary according to a specific conceptualization of the world is that much of the information remains implicit. Ontology applications are E-science, Medicine, Organizing complex and semistructured information, Military/Government, the Semantic web and so called semantic grid.
Often, making domain ontology is not an end in itself. It may be used as data or base for building other ontologies by the software agents and individuals [12]. It may also be partially used in other domains, for semantic search in search engines. Also ontology is continuously improved and reworked based on discovery of limitations, new needs and updation of domain knowledge. It is a never ending iterative process.
Ontology helps to provide solution to the following problems like data integrity, authorization, document identification, confidentiality and end to end service authentication [7].
-
III. Related Work
-
[12] Web services are sets of related functionalities that consumer can programmatically access and manipulate through the web. Web services provide a key to enabling the Semantic Web. Mourad Ouzzani and Athman Bouguettaya (2004) proposed a query model which facilitates the formulation and submission of queries and their transformation into actual Web service operations invocations. The optimization model uses quality of web service (QoWS) parameters to meet user’s requirements. The model adjusts QoWS through a dynamic rating scheme and multilevel matching in which the rating provides an assessment of Web Services’ behaviour.
-
[13] V. Chan, P. Ray and N. Parameswaran (2008) have worked on the main drawbacks of existing deployed e-health monitoring systems originate from the fact that patients are constrained within smart rooms and beds fitted with monitoring devices. Such monitoring is not ubiquitous in view of the privacy, mobility and flexibility issues concerning patients. On the other hand, health monitoring products strapped to the patient’s body provide no analysis or recommendations of results. Authors have presented networked multi-agent architecture for monitoring of human emerging wireless mobile technologies. This architecture provides the basis for the use of intelligent agents to deliver better healthcare to patients, especially in the case of homebased care of chronic illness’, the cost of which is increasing because of the ageing population in the world.
-
[14] Sanjay Kumar Mali, Nupur Prakash and S.A.M Rizvi (2010) have consider education domain and developed an University ontology and various aspects like super class and sub class hierarchy, creating a sub class, instances for classes illustration, query retrieval process, graph corresponding to a sub-class using TGViz have been demonstrated.
-
[15] Lilac A. E. Al-Safadi and Nadeen A. O. Al-Abdulla if (2010) created a domain-dependent Ontology to play a major role in supporting information exchange process in semantic advertising networks. As a result matching ads with publisher had given better results in terms of high precision and low recall. Therefore it is effective for advertising network at a semantic level.
-
[16] Swathi Rajasurya, Tamizhamudhu Muralidharan, Sandhiya Devi, Dr. S. Swamyynathan, (2012) have proposed semantic search engine SIEU (Semantic Information Extraction in University Domain) for University domain. It is one layer above google or any other search engine to retrieve by analyzing just the keywords. In this query is analysed both syntactically and semantically. In this google results are re-ranked and optimised for proving the relevant links. Author said this work can be extended by adding some features like location based information retrieval and Web Services with the help of RSS feeds. In comparison to google SIEU have resulted in higher value of average precision and recall.
-
[17] Parminder Singh and Sandeep Kaur (2013) have developed search engine and analyzed query both syntactically and semantically as in SIEU search engine but in this web services and location based services have also been added. As a result it has improved the performance as compared to previous search existing engines. In future the author said the search can be improved by making location based search more interactive and graphics based and by implementing it with your own API. Mobile Apps for android phones can be created.
-
[18] Ketan D. Bodhe, R.R. Sawant, A.N. Kazi (2014) proposed healthcare system mainly take care of patients like diabetes such person can live normally when the health condition is stable, but in critical condition they needs desperate help of doctors and assistance to reduce the probability of deteriorating health conditions. Such patients can monitor their health through this system. This app accept relevant information from the patient and transfer this information to expert system and make ease to get rapid diagnosis for remote area patients.
-
[19] Ms. Pratibha, S. Sonakneware, (2014) have proposed the approach of ontology based information retrieval system for overcoming the limitation of keyword-based information retrieval system. In this user give a natural language query and the system interprets the meaning of user’s query and finds the relationship between different concepts and then retrieves the semantic information by using ontology based approach. User’s query is expanded to SPARQL query using quepy tool and this SPARQL query is used to extract the RDF data thus retrieving the relevant answers. They have
-
created ontology for academic institution.
-
[20] Remi S, Varghese S C (2015) has proposed a novel method for supporting semantic information retrieval in book domain by building domain specific ontology. A prototype of a fuzzy semantic engine is developed and the experimental result shows that the system retrieves the documents which would have been missed and avoids retrieving documents which are irrelevant despite the presence of the keywords. It has resulted in low recall and high precision as compared to the traditional search engine.
[21]K. R. Uthayan and G. S. Anandha Mala (2015) presented a better querying mechanism for information retrieval which integrates the ontology queries with keywords search. This research presents a development in the hybrid ontology for semantic information retrieval through:-
-
• Getting back a group of relevant document semantic method using the proposed hybrid ontology
-
• Dealing with the variety of field topics problem using hybrid concept view fuzzy ontology and
-
• Ranking the end result set of documents according to F-measures which are relevance quantity with respect to users query, confidence and updating degree.
The hybrid ontology provides better search capabilities achieving quantitative improvement by using keywordbased information retrieval.
-
IV. Ontology Related Terms
Fig.1 shows all the constituent parts of ontology like components, application areas where ontology can be used, languages which can be used to create ontology, type of tools that are used for ontology development, categorization of ontology and most important the ontology development phases.
-
A. Classification of Ontology
According to the object of conceptualization the ontologies are classified into four categories shown in Fig.1 and are discussed below [3, 5].
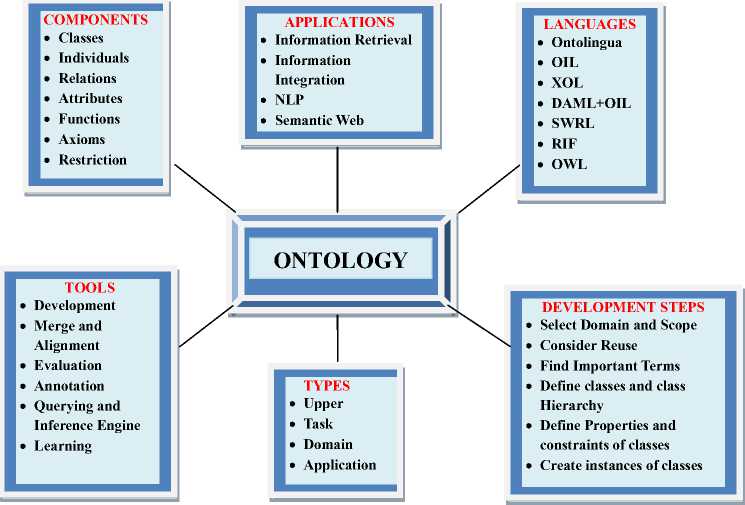
Fig.1. Overview of Ontology Related Terms
-
• Upper ontology, also known as top level or foundation ontology represents very general concepts. This type of ontology is a model of the common objects that are generally applicable across a wide range of domain ontologies. These concepts are independent of a problem or a particular area. For example Dublin Core, General formal ontology (GFO), Open Cyc, Suggested upper merged ontology (SUMO)
-
• Domain Ontology describes the vocabularies about the concepts in a specific domain. It characterizes the knowledge of the area where the task is
performed. Most existing ontologies are domain ontologies. For example one of the most cited ontologies is the wine ontology. It is about the most appropriate combination of wine and meal. An ontology library for lung pathology is maintained by the FU-Berlin.
-
• Task ontology, this type of ontology is used to conceptualize specific tasks in systems. It governs a set of vocabularies and concepts describing a structure of performing the tasks domainindependent. For example scheduling task ontology.
-
• Application ontology, this ontology is the most
specific. The concepts in the application ontology are very domain specific and particular application. In other words, the concepts often correspond to roles played by domain entities while performing a certain activity. For example the French cooking ontology.
-
B. Components of Ontology
The main components of ontology are as shown in Figure 1 and discussed below [2, 3, 4, and 5].
-
• Classes also know as concepts or type of objects or kind of things, are the focus of most ontologies. Classes describe concepts in the domain or tasks, which are usually organized in taxonomies. As example in university-ontology: student and
professor are two classes
-
• Individuals also known as instances or objects that represent specific elements. For example CS101 is the individual or instance of class CS-Module
-
• Relation represents a type of interaction between concepts of the domain. For example teaches is the relation between professor and student.
-
• Attributes are also known as aspects or features or properties that classes or objects can have. For example name, age or date of birth is the properties of object student.
-
• Function is complex structures formed from certain relations that can be used in place of an individual term in a statement. For example Price-of-a-used-car can define the calculation of the price of the second-hand car on the car-model, manufacturing data and kilometres.
-
• Axioms serve to model sentences that are always true. For example if the student attends both A and B course, then he or she must be a second year student.
-
• Restriction is explicitly defined constraint that must be true in order to make an assertion to accept as input. For example the age of student must be greater than 16.
-
C. Ontology Supporting Languages
Ontology languages shown in Figure 1 are generally adopted from the field of Artificial Intelligence which is used to build ontologies. It represents knowledge about specific domain. Classification of ontology languages [4] is shown in Table 1. Table shows that ontology languages are classified by syntax and structure. Syntax ontology languages are further classified into traditional syntax ontology languages like[3,11,25] common logic, CycL, KIF, ontolingua, F-logic, CML, OKBC, KM, OCML, KL-ONE, RACER etc. and web based ontology languages like OIL, DAML+OIL,OWL,SHOE,RDF,RDF Schema etc.[11]. Structure based ontology languages are further classified into three categories: frame-based, description logic-based and first-order logic-based ontology languages. Ontulingua, F-Logic, OCML, OKBC etc languages are completely or partially frame-based languages [11].These are the knowledge representation languages in AI. Frames are stored as ontologies of sets and subsets of the frame concepts. KL-ONE, RACER, OWL are Description logic based languages which provides the extension of frame languages. Many of DLs are less expressive than first-order predicate logic. Common Logic, CycL, KIF languages allow expression in first-order logic and allow predicates. It is also known as first-order predicate calculus. Brief definition of the main knowledge representation languages for authoring ontologies are given below [3, 4, 11].
-
• KIF (Knowledge Interchange Format) was originally developed by Michael Genesereth to interchange knowledge among disparate computer systems which means to facilitate sharing knowledge among different systems that use different languages, platforms and formalisms etc.
-
• Stanford’s Ontolingua ontology language is created in 1992 and it is based on KIF. Ontolingua does not permit reasoning.
-
• OIL (Ontology Interface Layer) provides modelling primitives from frame-based languages and formal semantics and reasoning from description logics
-
• DAML+OIL stands for DARPA agent mark-up language + OIL. DARPA is the name of US funding program which has main focus on the creation of machine-readable representations for the web. DAML+OIL is a successor language to DAML and OIL
-
• CycL is created by Cycrop and it is a formal language whose syntax is derived from first-order predicate calculus and from Lisp.
-
• CL (Common Logic) is a logic language based on first-order-logic. It encourages the development of different syntactic forms called dialects.
-
• F-Logic (Frame -Logic) is formalism to represent knowledge. It is logic language integrated the advantages of conceptual modelling with object-oriented and frame based paradigm and provide declarative, compact and simple syntax as well as the well-defined semantic of a logic-based languages.
-
• SHOE stands for simple HTML ontology extension built in 1996.It is a small extension to HTML to give semantic meaning to WebPages.
-
• KL-ONE has integral part a language for specifying descriptions and occasionally the name has been used to refer to just that language.
-
• RACER is a knowledge representation system that implements highly optimized tableau calculus for the description logic. Racer provides implementations of standard reasoning problems.
-
• OCML stands for operational conceptual modelling ontology language is a frame based i.e. object-cantered, Knowledge representation system, which also provides a relational view.
-
• OKBC short for open knowledge base connectivity is an application programming interface for accessing knowledge bases stored in knowledge representation systems (KRSs) such as ontology
repositories and object -relational databases.
-
• OWL short for Web ontology Language is a latest standard in ontology languages from the W3C. The OWL family contain many The OWL family contain many versions with similar names but different characteristics.
-
• RDF stands for Resource Description Framework was adopted as W3C recommendation in 1999 .It provides a standard form for representing metadata
in XML.
-
• RDF Schema have mechanism of defining relationship between three object types resources ,properties and statements which is not in the case of RDF data model
Table 1. Classification of Ontology Languages
|
Classification Languages |
Ontology Languages by Syntax |
Ontology Languages by Structure |
|||
|
Traditional Syntax |
Web based |
Frame Base |
Description Logic |
Enriched Predicate Logic |
|
|
KIF |
Yes |
Yes |
|||
|
Ontulingua |
Yes |
Yes |
|||
|
OIL |
Yes |
Yes |
|||
|
DAML+OIL |
Yes |
Yes |
|||
|
CycL |
Yes |
Yes |
|||
|
CL |
Yes |
Yes |
|||
|
F-Logic |
Yes |
Yes |
|||
|
SHOE |
Yes |
||||
|
KL-ONE |
Yes |
Yes |
|||
|
RACER |
Yes |
Yes |
|||
|
OCML |
Yes |
Yes |
|||
|
OKBC |
Yes |
Yes |
|||
|
OWL |
Yes |
Yes |
|||
|
RDF |
Yes |
||||
|
RDF Schema |
Yes |
||||
-
D. Major Application Areas of Ontology
-
• Ontology is highly helpful in the retrieval of relevant information from the web by pre refining the query semantically and syntactically with ease, even across different languages [15, 17].
-
• Integration of information across different web resources and platforms
-
• Ontology can also be used in NLP to get better results. For example you can use ontology in machine translation or for queries using natural language [2].
-
• The Semantic Web aims at tackling the growing problems of traversing the expanding web space, where currently most web resources can only be found by syntactical matches. The Semantic web relies heavily on formal ontologies that structure underlying data for the purpose of comprehensive and transportable machine understanding. They properly define the meaning of data and metadata. [7] In general, one may consider the Semantic Web more as a vision than a concrete application.
-
E. Categories of Ontology Tools
Ontology tools are classified into various categories by Gomez-Perez. Figure 1 shows the classification of ontology tools. Some ontology tools support all or more than one feature of following categories of ontology tools directly or indirectly through Plug-ins .First and the main category is ontology development tools that can be used to develop a new ontology from scratch or by reusing the existing ontologies. Protégé, Graffoo, Neon, Swoop, Apollo etc are some examples of development tools. Ontology merge and alignment tools such as Protégé with Prompt etc are used to merge or align different ontologies of the same domain. Ontology content evaluation tool eliminates the problem when you integrate and use the ontologies. For this ontology evaluation tools are used such as OntoClean, Radon etc. Another category is ontology-based annotation tools that use pre-defined concepts in ontology to mark-up document. For example OntoGloss, OWLDOC, OntoELAN etc. RACER, FACT++, Hermit etc are some querying and inference engine tools which are used to infer and query ontologies easily. Ontology Learning Tools are used to automatic or semi-automatic creation of ontologies from corpus of natural language text. For example Neon with ODEMapster, Protégé with OntoLT etc.
-
F. Phases of Ontology Development Process
We have also presented several methodologies and tools that can support the design and evaluation of new ontologies. We first considered an informal approach for developing ontology that included the following phases. These phases are not necessary to follow in sequence.
Phase II-Consider Reusing Existing Ontologies: To save time and effort of rather than building ontology from scratch, we can also search relevant domain ontology and refine it to be ‘reused’ to meet our objective. There are many libraries of reusable ontologies available on the web. Link of most commonly repositories used are given below.
•
• partments/ontology/
•
• ogy_Library
Apart from the above links, the search regarding the ontology resources can be made using SWOOGLE (The semantic web search engine). We reviewed considerably amount of literature and the previous constructed ontologies in the domain and modelled some of our properties and Concepts based on the description.
Phase III-Find Enumerate Terms: This step involves listing and briefly describing all the terms that are to be used in our ontology. It will act as a glossary of definition of all the words, terms and entities used, their properties , relations among the terms and any remarks or comments of the ‘creator’ for a user to familiarize with and better understand our ontology and its scope. For our ontology, concepts have been finalized after going through the websites of the various universities, engineering colleges and analysing content and the structure of these websites. We also have had detailed discussions with the various stakeholder working or associated with the domain and especially the users accessing these websites.
Phase IV-Create Class and Class Hierarchy: This step along with the next (defining of concept properties) are the two most vital steps in the Ontology engineering process and the two are closely related. In some ontology engineering approaches, defining of concepts (properties) takes precedence. We will first define the basic classes and then the class properties. As the ontology evolves, both the steps of (DEFINING CLASSES and DEFINING CONCEPTS) go hand in hand. Mainly there are two approaches for building class hierarchy in ontology namely top-down and bottom-up. Third is the combination of both top-down and bottom-up approach. The concept is these approaches are same as we have studied in other programming languages.
The enumerated terms identified in step two will help in determining our classes. We generally select the terms that have an “independent” existence and that are then specifically defined in a way that they are capable of holding individuals having similar properties.
We then organize the classes into hierarchy by an “if then” process i.e. If by being an instance of the class, the ‘instance’ is or can also be a member of “another class” , which may be a sub-class or a super-class of the present class. For example a sub class ‘student’ of a super class PERSON represents a “kind-of” relationship between both the classes. The concept that is represented by Student is also of the kind of concept that is represented by the super class PERSON. Also the class ‘graduate student’ is sub class of class student and the class ‘student’ is the sub class of class PERSON, then the class ‘graduate student’ automatically becomes the sub class of super class PERSON.
Phase V-Create Object Properties: After deciding and logically defining the classes, we have to determine and define specifically the properties which will form the ‘STRUCTURE’ of a class. This “explicit specification” of the properties will determine the internal structure of a class and help to ‘identify’ the class ‘instances’ or members. The may be from the earlier enumerated terms in Phase III, or may some new properties. In the protégé 5.0 tool, these properties are also called slots. The sub classes by definition and by hierarchy ‘inherit’ the properties of a super class. A slot should be attached to the most general class that can have that property. Keep track of Inverse relation and default relations and default values while creating these properties For instance, the properties ‘teaches’ and ‘studies’ should define and relate both the classes PERSON and MODULE as they are the general classes[6].
Phase VI-Create Data properties: Data Properties or slots have many different features describing the value type, allowed values, the number of the values (cardinality), and other features that a slot can take. Slot cardinality defines how many values a slot can have. The slot can have integer value, string value, Boolean etc. For example the data property name created under person could have name of employee, student as string value
Further you need to set the domain and range of data properties. Determining the domain and range of a data property is one of the most difficult and challenging task. The basic rules for determining a domain and a range of a slot: find the most general classes or class that can be respectively the domain or the range for the slots. On the other hand, do not define a domain and range that is overly general
Phase VII-Creating or Defining Instance of a Class:
The process of defining instance involves selecting class, creating individual instance and then filling in slot value. In a few cases this process may go parallel while defining the class properties or it may be taken up separately after defining classes and properties. For example many of the members like lecturer_1, student_1, Heat_transfer, Automobile_engineering, compiler_design etc were created while the class properties were being defined and some were created later as our understanding and domain knowledge evolves.
Phase VIII-Check anomalies: The consistency can be checked through the reasoner. Protégé supports many reasoners. This paper uses Hermit as its reasoner. By default hermit and fact++ are in protégé 5.0. Reasoning means to infer new knowledge from the statements asserted by an ontology designer. The illegal mistakes committed by the developer are spotted out by the reasoner. The problem that is faced when the engineering ontology developed is, due to a wrong setting of property characteristics, the reasoner displays error messages like inconsistent ontologies. Reasoning capabilities are exploited to detect logical inconsistencies within the ontology. The error has been occurred while setting characteristics, asymmetric and reflexive to a same property. The consistency checks can help developer in an adequate manner while constructing the ontologies.
-
V. Data Models: Ontology Vs RDBMS
Database systems can be based on different database models. A Database model is collection of concepts and rules for the description of the structure (i.e. data types, constraints etc) of the database. RDBMS and ontology databases are currently used for representing knowledge and information [24]. Although they are two different concepts but there is a lot of research going on in integrating these two fields, in light of solving common problems been faced by users. Relational database enabling information to be efficiently stored and queried where as ontologies is appeared as alternative to databases in applications that require a more ‘enriched’ meaning [4, 24]
C. Martinez-Cruz [24] presented the analysis of these data models and concluded that it is not possible to directly say which is better or which is not. Ontologies and RDBMS can represent the same reality, but depending upon the problem to be solved or application to be developed one or another technology presents advantages, or even both. In RDBMS there are highly specialized database technologies for efficient management of a particular kind of data. However, Ontologies provide a restriction-free framework to represent a machine readable reality, even in the Web. If the information to be represented needs to be shared in the web, then ontology is better RDBMS is better method for storing information when data is of considerable size.
Table 2. Difference between RDBMS and Ontology Data Models
|
Feature |
Relational Database |
Ontology |
|
Focus on |
Data |
Meaning |
|
Data |
Tables |
Instance Statements |
|
Purpose |
Efficient Storage and Querying |
Human Communication, Interoperability, Search , Software Engineering |
|
Query Language |
SQL, PLSQL |
SPARQL ,DL Query |
|
Shareable |
No |
Yes |
|
Administrati on Language |
DLL,DML,DCL |
Ontology Statements |
|
Reusable |
No |
Yes |
|
Reasoning |
No |
Yes |
|
Relationships |
Foreign Keys |
Multidimensional |
|
Provide Explicit and Formal Semantics |
Minimal |
Strong |
|
Logic |
External of Database/Triggers |
Formal Logic Statements |
|
Uniqueness |
Primary Keys |
URI |
|
Shareable |
No |
Yes |
|
Structure |
Three Layer Schema |
Ontology Statements |
|
Infer implicit information |
No |
Yes |
The major areas of differences are that RDBMS does not provide explicit and formal semantics and is not shareable across different platforms and database. The modified and updated comparison table of these two data models is shown in Table 2.
-
VI. Ontology Development Tools Under Evaluation
Various ontology development editors have been proposed by researchers in Semantic web. The methodology of the study constitute of collecting a set of free and mostly used ontology development editors to be tested with their updated versions and specifying the domain for which they are to be tested for the tool’s performance. The first step in the methodology consists of selecting tools to be tested, which are freely available and mostly used. There are varieties of tools available for developing ontologies and retrieving information from that. Protégé 5.0[8], SWOOP 2.3Beta4[9], Neon 2.5.2[10], Apollo 1.0[25] and Graffoo 1.0[25] tools are widely used to analyze ontology development editors. Therefore in this section we are comparing the features of these tools shown in Table 3 out of which some have reported in literature and some are new.
Table 3. Evaluation of Ontology Development Tools
FEATURES APOLLO PROTÉGÉ SWOOP GRAFFOO NEON TOOLKIT VENDOR KMI(Open University) SMI(Stanford University) MND(University of Maryland) Silvio Peroni Neon Foundation WEBSITE u/ 2004/swoop graffoo/ CURRENTV ERSION 1.0 5.0 2.3Beta4 V 1.0 2.5.2 EASY TO INSTALL AND USE Easy install and user it has user friendly graphic user interface. Easy to install and Use. It is very user friendly Easy Easy to use and very easy to install Easy FREEWARE Free Free Free and Open Source Free and Open Source Free and Open Source SYSTEM REQUIREM ENTS The application requires Java installed on your machine. The platforms-specific archives include the Java JRE, so it is not required to have Java installed on your machine The application requires Java 1.4 installed on your machine. You can also download the latest version of Java. A free diagram editor Graffoo has been developed using the standard library of the yEd diagram editor [24]. yED application requires Java installed on your machine. The application requires Java installed on your machine. RELEASE DATE OF CURRENT VERSION Aug2004 May 2016 Aug2007 OCT2013 Jan2011 BASE LANGUAGE OKBC model OKBC+CLOS based Meta-Model OWL OWL OWL PLUG-INS Yes, Creating and adding new I/O plug-ins is independent. It is also possible at add a new plugins without changing a source code of Apollo tools. Yes, Protégé plug-in library is available to find, download and use plug-ins that enhance the protégé applicaition.Protege5.0 contains two new bundled plug-ins, "Cellfie" and the "SWRL Tab"[8].Plug-ins can be downloaded from http://protegewiki.stanfor d.edu/wiki/Protege_Plugi n_Library Yes, It has extensible plug-in architecture. Plugins. Can be downloaded from ugins. Yes, Graffoo also provide plug-ins. Yes, At present Neon toolkit provides 45 plugins, which are ever increasing covering a wide variety of activities.[10] Plug-ins can be downloaded from STORAGE Files Files, DBMS(JDBC) HTML Models Files Files BACK-UP MANAGEME NT No No No Yes Yes ARCHITECT URE Standalone Standalone & Eclipse Client/Server Web based and client Server Standalone Standalone IMPORT CLOS;
Reasoner No Yes, Pellet, Fact++, Hermiit 1.3.8.413, Ontop 1.18.0,jcel,Elk0.4.3 these all are internal reasoners Yes, Pellet No Yes, Pellet2, Hermit, Onto Broker KR paradigam of Knowledge model Frames Frames+, FOL+, SWRL Meta classes DL DL DL Ontology libraries Yes Yes, Available at http://protegewiki.stanfor d.edu/wiki/Protege_Ontol ogy_Library Yes, Available at http://semanticweb.o rg/wiki/ ml Yes, Available at No Graphical class/property taxonomy No Yes Yes Yes Yes Graphical Prunes(views) No Yes No Yes Yes Zooming No such feature is available Yes it has zooming facility No Yes Yes Querying OR Searching No Yes(DL Querry_SPARQL are built in) No Yes Yes Search option is there to find any entity from ontology) Tutorial User Guide is available. User guide is available at http://protegewiki.stanfor d.edu/wiki/WebProtegeU sersGuide and video lectures are also available on YouTube. No No Yes Neon OWL manual is available on. User can download from ml Contact for Additional Information Paul Mulholland Email: p.mulholland@o Protégé provide free support for all protégé questions via mailing lists. User need to subscribe to a list before posting messages. Click on u/ for any help. Aditya Kalyanpu Email: aifb-neon- Support for Indian Languages No No No No No
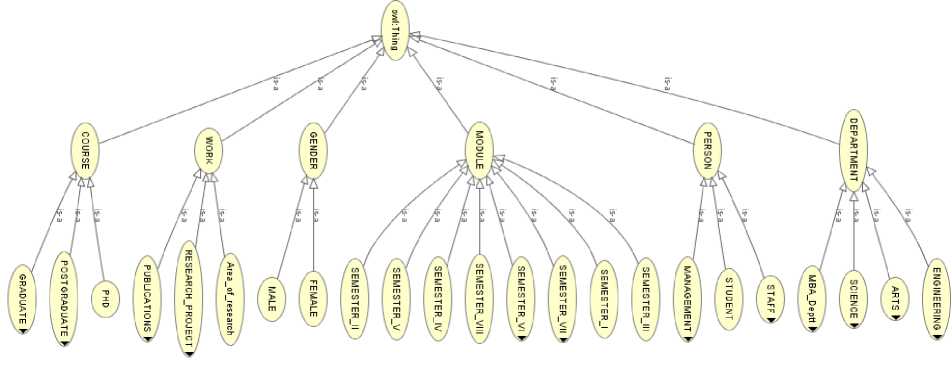
Fig.2. OWLViz Visualization of University Research Ontology
This paper restrict the comparison of ontology development tool to the following properties: General Description, Software architecture, interoperability, inference services, usability, Knowledge representation and contact details and training details. From the above comparison we can say that Protégé 5.0 is more useful and powerful tool which helps in creating best ontologies. Neon and Graffoo are also good ontology editors for some domains. Protégé is very expressive and easy to use. This tool helps us to create ontology quickly and efficiently. Even in online survey carried out by M. Rahamatullah Khonodoker and Paul Mueller in 2010 resulted that the most dominant and domain-independent tool is protégé which is used by 75% respondent. So Protégé 5.0 offers major improvements and enhancements in terms of functionality such as in searching, annotation and hierarchical visualization. It has also fixes the some previous issues and provides more user friendly interface. During this evaluation we have created the ontology of research work of university in Education domain. The OWLViz visualization of University Research work ontology with protégé 5.0 is shown in Fig. 2.In this the class hierarchy radius is three.
-
VII. Conclusion
This paper reviewed and analyzed the deficiencies of five commonly used ontology editors and Most of these editors focus on different activities of the ontology lifecycle design, such as editing, inference engines, reasoning, documenting, merging, importing/exporting for the various formats, graphical views, storage, ontology libraries, querying/searching and browsing functionalities. Classification of ontology languages by syntax and structure and the comparative study of two main data models ontology and RDBMS are also discussed. In conclusion the Ontology data models retrieve information semantically and the Protégé 5.0 is the best tool to create ontology easily, quickly and efficiently for every domain. This paper can guide new researcher about why ontology is needed and how to develop it and with which tool one should develop it. Recently the Protégé 5.1.0 have been released.
References Evaluation of Information Retrieval Based Ontology Development Editors for Semantic Web
- WANG Yong-gui, JIA Zhen, “Research on Semantic Web Mining” International Conference On Computer Design and Applications” Volume 1, 67-70, 2010
- Pallavi Grover, Sonal Chawla, “Evaluation of Ontology Creation Tools”, International Journal of Soft Computing and Engineering (IJSCE), Vol. 4, Issue 2, May 2014.
- Thabet Slimani, “Ontology Development: A Comparing Study on Tools, Languages and Formalisms”, Indian Journal of Science and Technology, Vol 8(24), pp 1-12, September 2015
- Vishal Jain, “Ontology Development and Query Retrieval using Protégé Tool” I.J.Intelligent Systems and Applications, 2013, 09, 67-75
- Bhaskar Kapoor and Savita Sharma, “A Comparative Study Ontology Building Tools for Semantic Web Applications” .
- Natalya F. Noy and Deborah L. McGuinness “Ontology Development 101: A Guide to Creating Your First Ontology” available at : http://protege.stanford.edu/publications/ontology_development/ontology101.pdf
- Zeeshan Ahmed and Detlef Gerhard, “Role of Ontology in Semantic Web Development” Article available online at http://arxiv.org/ftp/arxiv/papers/1008/1008.1723.pdf
- Protégé ontology Editor, Retrieved on May, 2016 from Stanford University School of Medicine: http://protege.stanford.edu/
- SWOOP (2004), Semantic Web Ontology Overview and Perusal. Retrieved January 2016 from MINDSWAP: http://www.mindswap.org/2004/SWOOP/
- Neon Toolkit (2011), Retrieved December 2015 from: http://neon-toolkit.org/wiki/Main_Page.html
- Xiaomeng Su, Lars Ilebrekke, “A Comparative Study of Ontology Languages and Tools”, International Conference on Advanced Information Systems Engineering, pp 761-765, 2002
- Mourad Ouzzani and Athman Bouguettaya, “Efficient Access to Web Services” IEEE INTERNET COMPUTING, Vol 8, Issue 2, pp. 34–44, 2004.
- V. Chan, P. Ray and N. Parameswaran, “Mobile e-Health monitoring: an agent-based Approach”, The Institution of Engineering and Technology, Vol 2(2), pp. 223–230, 2008.
- Sanjay Kumar Malik, Nupur Prakash, S.A.Mrizvi, “Developing an University Ontology in Education Domain using Protégé for semantic Web”, International Journal of Engineering Science and Technology, Vol. 2(9), pp. 4673-4681, 2010.
- Lilac A.E. Al-Safadi and Nadeen A.O. Al-Abdullatif, “Educational Advertising Ontology: A Domain-Dependent Ontology for Semantic Advertising Networks”, Journal of Computer Science Vol 6 (10), pp 1070-1077, 2010.
- Swathi Rajasurya, Tamizhamudhu Muralidharan, Sandhiya Devi, S.Swamynathan, “Semantic Information Retrieval Using Ontology In University Domain”, International Journal of Web & Semantic Technology (IJWesT), Vol.3, No.4, October 2012.
- Parminder Singh, Sandeep Kaur , “Generic Education based Optimized Search Engine using Web Services and Location Services” International Journal of Computer Applications, Vol. 68, No. 22, April 2013.
- Ketan D. Bodhe, R. R. Sawant, A. N. Kazi, “A Proposed Mobile Based Health Care System For Patient Diagnosis Using Android Os ” International Journal of Computer Science and Mobile Computing, Vol.3 Issue.5, pp. 422-427 May2014.
- Ms. Pratibha S. Sonakneware, Prof. S. J. Karale , “ Ontology Based Approach for Domain Specific Semantic Information Retrieval System” International Journal of Engineering Research and Applications (IJERA),ICIAC, pp.69-74, April 2014.
- Remi S, Varghese S C, “Domain Ontology Driven Fuzzy Semantic Information Retrieval”, International Conference on Information and Communication Technologies (ICICT 2014), Vol. 46, pp 676 – 681, 2015.
- K. R. Uthayan1 and G. S. Anandha Mala, “Hybrid Ontology for Semantic Information Retrieval Model Using Keyword Matching Indexing System” , The Scientific World Journal ,Vol 2015, 2015
- Vishal Jain, Mayank Singh, “Ontology Based Information Retrieval in Semantic Web: A Survey”, I. J. Information Technology and Computer Science, Vol 10, pp 62-69, Sep 2013, DOI:10.5815/ijitcs.2013.10.06.
- Carmen Martinez-Cruz · Ignacio J. Blanco · M. Amparo Vila, “Ontologies versus relational databases: Are they so different? A comparison”, Vol 38, Issue 4, pp 271–290, December 2012.
- Graffoo (2013) Graphical Framework for OWL Ontologies. Retrieved 10 April 2016 from http://www.essepuntato.it/graffoo/.
- Apollo Ontology Editor(2004), Retrieved 15 December 2015 from http://apollo.open.ac.uk/
- Salim Khiat, Hafida Belbachir, Sid Ahmed Rahal, “MAROR: Multi-Level Abstraction of Association Rule Using Ontology and Rule Schema”, I. J. Information Technology and Computer Science, Vol 12, pp 24-34, Nov 2014, DOI:10.5815/ijitcs.2014.12.04.
