Evolution of heuristics for selection synthesis in a genetic algorithm

Author: Korableva A.A., Stanovov V.V.
Journal: Siberian Aerospace Journal @vestnik-sibsau-en
Section: Informatics, computer technology and management
Article in issue: 1 vol.27, 2026.
Free access
A method for the automatic design of selection operators for a genetic algorithm is proposed, based on the Evolution of Heuristics (EoH) approach, which integrates the capabilities of Large Language Models (LLMs) and evolutionary search. The design of selection operators was carried out on three pseudo-Boolean optimization problems, and testing was performed on 17 functions from the IOHprofiler benchmark set. Two experimental setups were considered with and without explicit knowledge of the type of problem being solved. The language model used was DeepSeek-Coder-V2, which was deployed locally using the Ollama framework. The quality of the designed heuristics was determined based on the comparison with the results of standard rank selection. The quality of the obtained solutions is compared with classical selection schemes (tournament, proportional, and rank-based), as well as with the FunSearch method, previously used to generate new implementations of rank-based selection. A comparison of various heuristics was carried out for multiple runs on each of the 17 tasks using the nonparametric Mann-Whitney statistical test. It has been shown that automatically designed heuristics have unique properties, and the lack of information about the type and structure of the problem being solved has led to a greater variety of generated solutions. Namely, in one of the launches, without information about the type of task, the designed code selects individuals whose fitness differs from the maximum by less than half the distance from the maximum fitness to the median. In other words, it is a variant of tournament selection with an adaptive tournament size based on the distribution of quality. The availability of information about the type of problem being solved led to the fact that the language model generated typical known solutions, in particular, variants of simple tournament selection. The proposed approach can be applied to other tasks of automatic design of algorithms as a whole or components of algorithms.
EoH, genetic algorithm, selection, FunSearch, LLM, IOHprofiler, hyper-heuristics, automatic algorithm design
Short address: https://sciup.org/148333266
IDR: 148333266 | UDC: 519.87 | DOI: 10.31772/2712-8970-2026-27-1-21-32
Text of the scientific article Evolution of heuristics for selection synthesis in a genetic algorithm
Large Language Models (LLMs) are a type of machine learning model trained on vast text corpora to predict and generate sequences of text. They are capable of understanding natural language instructions and transforming them into program code or algorithmic structures.
In the context of automatic heuristic generation, LLMs are used to produce new variants of functions, operators, or algorithmic components based on textual problem descriptions and existing solutions. After the LLM generates multiple variants, an evolutionary process selects the best implementations according to the predefined fitness function, enabling automatic synthesis of effective heuristics without manual coding [1, 2].
This approach combines the flexibility of LLMs with performance evaluation through a predetermined assessment method, allowing the discovery of unconventional and efficient algorithmic solutions.
One of the most promising directions is the use of LLMs for developing hyper-heuristics – high-level strategies that control the search process in optimization problems.
Genetic Algorithms (GAs) are a classical method of evolutionary computation inspired by the principles of natural selection [3]. GAs are widely applied in optimization and machine learning tasks. The main challenge in using GAs lies in tuning their parameters and configuring evolutionary operators
(selection, crossover, mutation). Incorrect setting can lead to premature convergence or reduced search efficiency.
The aim of this work was to study LLM creativity with different levels of knowledge about the type of task being studied. Specifically, we focused on evolving a selection heuristic within a genetic algorithm – searching for such a selection function that would better guide the evolutionary process and enhance GA performance. This idea is realized through the EoH (Evolution of Heuristics) framework [4], in which LLM assists in synthesizing and improving heuristic code, while the genetic algorithm evaluates their quality.
Genetic Algorithm and Approaches to Automatic Heuristic Generation
A genetic algorithm is a heuristic optimization method inspired by biological evolution, employing population-based search for an optimum and the transmission of genetic information through specialized operators. The algorithm starts by forming an initial population, where each individual is encoded as a genotype – a numerical or binary vector representing a potential solution. For each individual, a phenotype (i.e., the real-valued representation of the problem variables) and a fitness function value are computed, reflecting the quality of the solution. Based on these fitness values, selection determines which individuals will reproduce. Common selection methods include tournament, proportional, and rank-based selection. Then, the crossover operator combines parental genes to create offspring, and mutation introduces random changes to maintain genetic diversity. The population is updated, and the process repeats for a specified number of iterations or until convergence is achieved [5].
The selection operator determines which individuals are chosen to produce offspring based on their suitability. More adapted individuals have a higher probability of passing their genes to the next generation [6].
EoH represents an implementation of the LLM4AD concept – Large Language Model for Algorithm Design – a research platform proposed by Liu et al. [7], created for automated algorithm design using LLMs combined with evolutionary and learning techniques. Its main goal is to teach LLMs not merely to generate code but to evolve algorithms, improving their performance through feedback from a testing system.
EoH performs co-evolution of “thoughts” – textual descriptions of heuristic principles – and their corresponding code implementations. To generate and modify heuristics, an LLM operates within the evolutionary cycle incorporating five generation strategies: two exploratory (E1, E2) and three modifying (M1–M3) [8].
The E1 and E2 operators focus on improving existing ideas (implementations) – they take current programs and “thoughts” from the population and generate new variants based on these well-known good solutions. The M1–M3 operators aim to introduce diversity by slightly modifying existing functions or ideas to explore new regions of the solution space. These strategies model the human-like process of idea generation, refinement, and simplification, ensuring both exploration of new concepts and exploitation of promising ones.
Experiments on combinatorial optimization problems such as Online Bin Packing, Traveling Salesman Problem, and Flow Shop Scheduling have shown that EoH outperforms both classical and modern automatic design methods, including FunSearch, achieving high-quality solutions at significantly lower computational cost [4].
The FunSearch algorithm represents a related concept. FunSearch is a method for automatic search and evolution of functions or operators, also combining the capabilities of LLMs and random search. Its main idea is that the LLM generates new versions of functions or algorithmic components based on textual problem descriptions and existing solutions, selecting the best variants according to a predefined objective function [9].
Although FunSearch and EoH are conceptually similar, they differ significantly in structure [10]. The advantages of EoH over FunSearch include the presence of a full evolutionary algorithm with population dynamics and operators, as well as the co-evolution of thoughts rather than just code.
As an example of application, FunSearch has been used for the automatic discovery of selection operator structures – specifically, it generated and evolved new versions of rank-based selection operators to improve algorithm performance. On benchmark problems such as OneMax, LeadingOnes, and Harmonic Function, the FunSearch-modified ranking functions outperformed classical rank-based selection in solution quality [11]. Besides FunSearch, there are other alternative approaches, such as Effortless Algorithmic Solution Evolution [12].
In this work, we employ the EoH implementation from the LLM4AD project, adapting it for a specialized task – automatic synthesis of selection operators in genetic algorithms. This study thus represents an applied use case of the LLM4AD platform for the evolutionary design of GA components.
The proposed approach
In this study, we propose applying the EoH framework for the automatic evolution of a selection index function in a genetic algorithm, given predefined fitness values.
The genetic algorithm was implemented for several pseudo-Boolean optimization problems from the PBO (Parameterized Boolean Optimization) benchmark suite, namely OneMax, LeadingOnes, and Linear Function with Harmonic Weights [13].
The GA includes the following components:
-
– initialization: generation of random binary chromosomes of fixed length;
-
– selection: by default, rank-based selection is used, where the probability of choosing an individual is proportional to its rank (this operator can be replaced with a EoH-generated version);
-
– crossover: uniform crossover;
-
– mutation: bitwise mutation with adjustable probability;
-
– replacement: full generational replacement of the parent population by offspring with elitist preservation of the best solution.
The operation of EoH is organized as follows:
-
1. Initialization of the main population: EoH generates a set of candidate programs based on a template program and a task description. Each candidate program represents a potential implementation of the selection index function.
-
2. Multi-step evolution:
-
– at each iteration, the E1, E2, M1, and M2 operators generate new candidates based on existing solutions;
-
– the LLM produces textual versions of functions, which are then converted into executable code.
-
3. Performance evaluation: each generated function is executed in a sandboxed environment within the GA. The genetic algorithm with the generated selection function is run under 12 different configurations, which vary by population size, number of generations, chromosome length, and problem type. The results obtained from five independent runs are compared with those of a standard GA using tournament selection. The configuration parameters are shown in Table 1.
In the table, the following notation is used:
-
– N is the number of individuals in the genetic algorithm;
-
– G is the number of generations;
-
– F is the index of the function;
-
– L is the chromosome length, i.e., the number of bits in the chromosome;
-
– Mean is the average best target function value.
-
4. Evolutionary selection: functions with the highest performance are retained in the population, while less effective ones are discarded. New candidates are generated using the E1, E2, M1, and M2 operators.
-
5. Multithreading: EoH employs multithreading for parallel generation and evaluation of functions, accelerating the search for optimal operators.
-
6. Termination: after reaching the maximum number of iterations or evaluated functions, the best implementation of the selection function is chosen.
Table 1
Genetic algorithm parameter settings
|
N |
G |
F |
L |
Mean |
|
50 |
30 |
1 |
500 |
0.81282 |
|
50 |
30 |
3 |
500 |
0.84372 |
|
50 |
30 |
2 |
50 |
0.56080 |
|
30 |
50 |
1 |
500 |
0.81789 |
|
30 |
50 |
3 |
500 |
0.84864 |
|
30 |
50 |
2 |
50 |
0.66220 |
|
30 |
30 |
1 |
400 |
0.78974 |
|
30 |
30 |
2 |
40 |
0.62099 |
|
30 |
30 |
3 |
400 |
0.81351 |
|
50 |
50 |
1 |
600 |
0.86081 |
|
50 |
50 |
2 |
60 |
0.63599 |
|
50 |
50 |
3 |
600 |
0.88465 |
In the next section the experimental setup will be described including parameter values for EoH and the results will be presented.
Results
A total of 17 test functions from the IOHprofiler framework were used. IOHprofiler provides an environment for running algorithms on pseudo-Boolean optimization problems. In this study, we employed functions that capture different aspects of problem complexity:
-
– OneMax – aims to maximize the number of ones in a binary string;
-
– LeadingOnes – counts the number of consecutive ones at the beginning of the string until the first zero occurs;
-
– Linear Function with Harmonic Weights – a linear function with increasing integer weights, where each bit in the chromosome has a weight; thus, bits near the end of the string are more important than those at the beginning.
Additionally, modified versions of the above functions were used according to the W-model transformations, including:
-
– Dummy Variables – reduction of the number of active bits in the chromosome. Out of n bits, only m
-
– Neutrality – aggregation of bit blocks into a single bit using majority voting. Bits are divided into blocks of a certain length, and each block’s output is determined by the majority (e.g., if 2 out of 3 bits are ones, the resulting bit = 1);
-
– Epistasis – bits are grouped into blocks of a specified length, and a permutation is applied within each block, e.g., the string 1100 becomes 0011. The permutation is designed to disrupt local structure;
-
– Fitness Perturbation – distortion of fitness values, i.e., transforming the objective function outputs to alter their order or introduce plateaus.
These modifications are used to create customizable levels of difficulty, simulate the characteristics of real-world problems, and test the robustness and adaptability of algorithms. Their inclusion allowed us to comprehensively assess the behavior of the proposed approach.
The EoH algorithm was implemented in Python 3.12. All experiments were conducted on a computer running Linux Ubuntu 22.04, equipped with an AMD Ryzen 7950X3D processor (16 cores) and an NVIDIA RTX 3090 GPU. The source code is available at [14].
As the language model, we used a locally deployed DeepSeek-Coder-V2. This model was chosen for its high processing speed, availability, and relatively low computational requirements, making it well-suited for running experiments on a personal computer without specialized hardware. The local deployment of the LLM was performed using the Ollama framework [15].
Fig. 1 presents the function template whose body is modified by the LLM. Without this template, the LLM would not know which function to generate, which arguments to use, or what values to return. Following the function, a textual task description is provided, which is used to form the input prompt for the LLM.
In this study, two EoH configurations were proposed, differing in the base structure of the function that the LLM modifies and improves:
-
– EOH (GA-specific): the function template is designed for selecting an individual in a genetic algorithm based on an array of fitness values (Fig. 1);
-
– EoH (general): the function template is defined in a more general form, where the function selects an element based on a quality array without explicit knowledge of the GA (Fig. 2).
#Prompt:
template program = import numpy as np import random def GA_Selection(Fitness) -> int:
Args:
Fitness: Fitness array
Return:
Рис. 1. Пример подсказки LLM для первого шаблона запроса
-
Fig. 1. Example of LLM prompt for the first prompt template
As shown in Fig. 1, the function receives as input an array of fitness values of all individuals and must return the index of the selected individual. This approach provides EoH with the explicit task context, enabling the model to understand that it operates within a genetic algorithm rather than with an abstract set of values.
#Prompt:
template_program = import numpy as np import random def Choose(Quality) -> int:
Args:
| Quality: Quality array
Return:
Рис. 2. Пример подсказки LLM для второго шаблона запроса
-
Fig. 2. Example of LLM prompt for the second prompt template
Fig. 2 presents a function template where EoH is not informed about the use of a genetic algorithm and therefore solves the problem in an abstract form, with-out specific information about the algorithm’s type.
The method EoH was launched [16] with the following parameters:
– Maximum number of samples 4000;
-
– Maximum number of generations 50;
-
– Population size 40;
-
– Search operators were: E1, E2, M1, M2.
With every prompt template there were five independent runs, each of them took 1.5 hours. From each of the runs the best heuristic was chosen and tested on 34 configurations – 17 test functions with two different parameter sets. In the first parameter set population size was 30, number of generations 30, chromosome length 50. In the second parameter set population size was 50, number of generations 50, chromosome length 500.
To evaluate the effectiveness of various selection operator modifications proposed by the EoH system, statistical analysis was performed using the Mann–Whitney U test. This non-parametric test is widely used to determine whether there are significant differences between two samples based on their ranked values [17]. The results of the Mann – Whitney U test are presented in Table 2.
The Wins value reflects the number of cases where the modified selection operator statistically significantly outperformed the baseline implementation. Ties refer to the number of cases where the difference did not reach statistical significance, and Losses indicate the number of cases where the baseline operator outperformed the modified one. Score is the sum of Z-scores across all comparisons.
The best of runs with the first and the second templates were chosen, in particular runs 5 and 2. Fig. 3 and 4 show examples of LLM responses for two prompt templates.
Table 2
Comparison of selection operator’s effectiveness (Mann–Whitney U test)
|
# |
Wins |
Ties |
Losses |
Score |
|
EoH (prompt 1), run 1 |
11 |
15 |
8 |
16.41 |
|
EoH (prompt 1), run 2 |
11 |
17 |
6 |
16.83 |
|
EoH (prompt 1), run 3 |
11 |
14 |
9 |
15.51 |
|
EoH (prompt 1), run 4 |
11 |
17 |
6 |
18.72 |
|
EoH (prompt 1), run 5 |
12 |
15 |
7 |
20.78 |
|
EoH (prompt 2), run 1 |
9 |
20 |
5 |
16.25 |
|
EoH (prompt 2), run 2 |
10 |
17 |
7 |
20.14 |
|
EoH (prompt 2), run 3 |
7 |
19 |
8 |
-9.871 |
|
EoH (prompt 2), run 4 |
11 |
11 |
12 |
-5.682 |
|
EoH (prompt 2), run 5 |
10 |
18 |
6 |
13.32 |
|
FunSearch |
5 |
19 |
10 |
-23.69 |
#Response:
import random def GA_Selection(Fitness) -> int:
Args:
Fitness: Fitness array
Return:
Returns index of selected individual if sum(Fitness) == 0:
return random. randint (0, len(Fitness) - 1)
-
# Adaptive tournament size up to a maximum of 15 individuals tournament_size = min(max(5, int(len(Fitness) ** 0.5)), 15)
-
# Select participants with weighted random choice based on fitness values participants = random. choices (range(len(Fitness)), weights=Fitness, k=tournament_size)
-
# Find the fittest individual among the participants
selected_index = max(participants, key=larnbda i: Fitness[i])
return selected index
Рис. 3. Пример ответа LLM для первого шаблона подсказки, запуск 5
Fig. 3. Example of LLM response for the first prompt template, run 5
The code in Fig. 3 is in fact a variant of tournament selection, where the tournament size is equal to the square root of the population size, but at least 5 and at most 15. That is, as the LLM was informed about the problem type, GA selection, it implemented the most widely used operator.
The code in Fig. 4, as it seems, implements a variant of fitness proportionate selection, but with random perturbation of qualities, i.e. fitness values. However, the response does not contain any mentioning of proportionate selection, as the LLM was not informed about the task.
#Response:
import random def Choose(Quality) -> int
Args:
Quality: Quality array
Return:
Returns index of chosen perturbed_quality = [q + random.uniform(-0.1, 0.1) for q in Quality]
max quality = -float('inf *) candidates = []
-
# Find the maximum quality value and indices where this occurs
for i, quality in enumerate(perturbedquality):
if quality > max_quality: max_quality = quality candidates = [i]
-
# If there is only one candidate, return it directly
if len(candidates) == 1: return candidates[0]
-
# Calculate the weights based on the perturbed qualities weights = [perturbed_quality[index] for index in candidates] total_weight = sum(weights)
f Normalize the weights and generate a random choice based on these probabilities probabilities = [weight / total_weight for weight in weights]
selected index = random.choices(candidates, weights=probabilities, k=l)[0]
return selected index
Рис. 4. Пример ответа LLM для второго шаблона подсказки, запуск 2
Fig. 4. Example of LLM response for the second prompt template, run 2
In Fig. 5 a more unusual selection operator, generated in run 4 with the second prompt template, is shown.
#Response:
import random def Choose(Quality) -> int
Args:
Quality: Quality array
Return:
Returns index of chosen n = len(Quality) if n = 0: return -1
-
# Calculate the median quality value sorted_quality = sorted(Quality)
median_quality = sorted_quality[n // 2]
# Select candidates with maximum quality and low variance around the median top_variance_candidates = [i for i in range(n) if Quality[i] >= max(Quality)
0.2 - о
(max(Quality) - median_quality) / 2]
return -1
Рис. 5. Пример ответа LLM для второго шаблона подсказки, запуск 4
Fig. 5. Example of LLM response for the second prompt template, run 4
u
— EoH(plr5)
— EoH(p2r2)
ЕоН (р2г4)
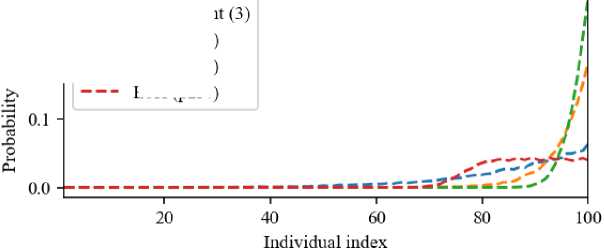
Рис. 6. Сравнение селективного давления турнирной селекции и трёх сгенерированных эвристик
Fig. 6. Comparison of the selective pressure of tournament selection and three heuristics
Fig. 6 shows graphs of the selective pressure of the three heuristics from Fig. 3, 4, and 5, as well as tournament selection for comparison. Heuristic p2r2 is characterized by the highest selective pressure, while heuristic p2r4 selects one of the top 25 percent of individuals with equal probability. Heuristic p1r5 is tournament selection with a larger tournament size.
Table 3 presents the comparative analysis of three standard selection methods and two designed heuristics, in particular heuristic, generated with the first prompt template, run 5 (p1r5), and generated with the second prompt template, run 2 (p2r2). The fitness values for each of the 34 testing configurations are shown.
Comparative analysis of the standard and designed selections
Table 3
|
# |
Tournament |
Proportional |
Ranked |
EoH (p1r5) |
EoH(p2r2) |
|
1 |
0.9872 (0.014) + |
0.832 (0.041) + |
0.9656 (0.024) + |
1 (0.000) = |
1 (0.000) |
|
2 |
0.8422 (0.013) + |
0.611 (0.015) + |
0.8181 (0.013) + |
0.886 (0.012) – |
0.8649 (0.019) |
|
3 |
0.408 (0.065) + |
0.372 (0.078) + |
0.3072 (0.071) + |
0.5016 (0.109) + |
0.604 (0.103) |
|
4 |
0.04632 (0.014) = |
0.03904 (0.009) + |
0.03296 (0.009) + |
0.03776 (0.012) + |
0.04912 (0.009) |
|
5 |
0.9861 (0.009) + |
0.8724 (0.022) + |
0.9803 (0.011) + |
0.9996 (0.001) – |
0.9989 (0.002) |
|
6 |
0.8695 (0.012) = |
0.6362 (0.014) + |
0.8501 (0.016) + |
0.9096 (0.013) – |
0.8799 (0.014) |
|
7 |
1 (0.000) = |
0.9408 (0.041) + |
1 (0.000) = |
1 (0.000) = |
1 (0.000) |
|
8 |
0.9411 (0.011) = |
0.671 (0.021) + |
0.9128 (0.014) + |
0.965 (0.013) – |
0.947 (0.011) |
|
9 |
1 (0.000) = |
1 (0.000) = |
1 (0.000) = |
1 (0.000) = |
1 (0.000) |
|
10 |
1 (0.000) – |
0.9096 (0.029) + |
1 (0.000) – |
1 (0.000) – |
0.9952 (0.009) |
|
11 |
1 (0.000) = |
1 (0.000) = |
1 (0.000) = |
1 (0.000) = |
1 (0.000) |
|
12 |
0.9889 (0.007) – |
0.7535 (0.025) + |
0.9773 (0.011) = |
0.9805 (0.011) = |
0.9747 (0.015) |
|
13 |
0.7152 (0.019) – |
0.7192 (0.018) – |
0.72 (0.026) – |
0.696 (0.015) – |
0.68 (0.017) |
|
14 |
0.5762 (0.007) = |
0.5772 (0.007) = |
0.5745 (0.005) = |
0.5747 (0.006) = |
0.5728 (0.008) |
|
15 |
0.5048 (0.014) + |
0.4184 (0.022) + |
0.4976 (0.009) + |
0.5192 (0.004) = |
0.52 (0.000) |
|
16 |
0.4236 (0.007) + |
0.3072 (0.007) + |
0.4105 (0.006) + |
0.4436 (0.008) – |
0.4308 (0.007) |
|
17 |
0.9784 (0.021) + |
0.7968 (0.033) + |
0.9552 (0.019) + |
1 (0.000) = |
1 (0.000) |
|
18 |
0.8387 (0.010) + |
0.6111 (0.016) + |
0.8182 (0.011) + |
0.8826 (0.015) – |
0.8572 (0.013) |
|
19 |
0.6792 (0.031) = |
0.6824 (0.034) = |
0.6824 (0.040) = |
0.6664 (0.040) = |
0.6736 (0.036) |
|
20 |
0.5506 (0.012) = |
0.5494 (0.009) = |
0.5519 (0.008) = |
0.5516 (0.011) = |
0.5518 (0.008) |
|
21 |
0.7808 (0.168) + |
0.7536 (0.150) + |
0.6384 (0.139) + |
0.9488 (0.092) = |
0.936 (0.106) |
|
22 |
0.09504 (0.023) = |
0.08032 (0.016) + |
0.06064 (0.020) + |
0.08032 (0.026) + |
0.1043 (0.028) |
|
23 |
1 (0.000) = |
1 (0.000) = |
1 (0.000) = |
1 (0.000) = |
1 (0.000) |
|
24 |
0.4944 (0.098) – |
0.3888 (0.101) = |
0.2936 (0.096) = |
0.396 (0.127) = |
0.376 (0.113) |
|
25 |
0.96 (0.127) – |
0.99 (0.038) – |
0.9225 (0.129) – |
0.8125 (0.277) = |
0.685 (0.291) |
|
26 |
0.0906 (0.019) – |
0.07639 (0.029) = |
0.0747 (0.017) = |
0.06361 (0.024) = |
0.06916 (0.022) |
|
27 |
0.2064 (0.035) – |
0.172 (0.026) – |
0.1928 (0.032) – |
0.1192 (0.027) = |
0.144 (0.038) |
|
28 |
0.02312 (0.004) = |
0.01808 (0.003) + |
0.02408 (0.005) = |
0.01144 (0.003) + |
0.02224 (0.004) |
|
29 |
0.2192 (0.038) = |
0.1792 (0.049) + |
0.1432 (0.029) + |
0.2576 (0.059) = |
0.2432 (0.045) |
|
30 |
0.02184 (0.006) = |
0.02184 (0.006) = |
0.01464 (0.004) + |
0.01864 (0.006) = |
0.02176 (0.005) |
|
31 |
0.3856 (0.067) + |
0.2272 (0.139) + |
0.3112 (0.092) + |
0.5184 (0.159) = |
0.5344 (0.135) |
|
32 |
0.0504 (0.012) = |
0.01784 (0.014) + |
0.02816 (0.008) + |
0.02784 (0.013) + |
0.04608 (0.013) |
|
33 |
0.1256 (0.048) = |
0.144 (0.061) = |
0.1272 (0.043) = |
0.136 (0.054) = |
0.1472 (0.044) |
|
34 |
0.0176 (0.003) = |
0.0148 (0.005) = |
0.01416 (0.004) = |
0.01616 (0.005) = |
0.01472 (0.005) |
|
Sum |
7-/17=/10+ |
3-/11=/20+ |
4-/13=/17+ |
8-/21=/5+ |
0-/34=/0+ |
In each cell «+» means that Heuristic 4 was statistically significantly better according to the Mann-Whitney test on this problem, «-» means that it was significantly worse, «=» means that there was no significant difference.
The mean fitness value reflects the overall performance of the algorithm, while the standard deviation indicates the stability and reliability of its behavior. The low standard deviation confirms the robustness of the proposed method to random variations, whereas a high standard deviation suggests instability in the algorithm’s behavior when solving certain types of problems.
As can be seen from Table 3, the designed heuristics outperform the standard ones in most cases. The designed heuristics have similar performance, but the one generated with the second prompt template has slightly better results. The designed heuristics were worse than the standard selection operators only in three cases out of 34, namely, configurations 13, 25, and 27.
Conclusion
The experiments performed in this study have shown that the evolution of heuristics method performs much better than the FunSearch algorithm, used before. The two prompt templates have resulted in different behavior of the LLM. In the first case, when the LLM knew about the task, it generated classical structures, such as tournament-based selection. In the second case the creativity of the LLM was much higher, and it created several very different approaches to selection, for example using median values. Also, different runs of the same approach without informing the LLM gave very different selection operator structures.
Some of the future work directions may include, but are not limited to applying the same method to the whole metaheuristic algorithm, i.e. generating new algorithm entirely. Another direction could include modifications of the EoH itself, for example by changing its selection procedure.
