Extractive Text Summarization Using Modified Weighing and Sentence Symmetric Feature Methods

Author: Selvani Deepthi Kavila, Radhika Y
Journal: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Article in issue: 10 vol.7, 2015.
Free access
Text Summarization is a process that converts the original text into summarized form without changing the meaning of its contents. It finds its usefulness in many areas when the time to go through a large content is limited. This paper presents a comparative evaluation of statistical methods in extractive text summarization. Top score method is taken to be the bench mark for evaluation. Modified weighing method and modified sentence symmetric feature method are implemented with additional characteristic features to achieve a better performance than the benchmark method. Thematic weight and emphasize weights are added to conventional weighing method and the process of weight updation in sentence symmetric method is also modified in this paper. After evaluating these three methods using the standard measures, modified weighing method is identified as the best method with 80% efficiency.
Text summarization, Top Score Method, Weighing method, Sentence symmetric feature Method
Short address: https://sciup.org/15014802
IDR: 15014802
Text of the scientific article Extractive Text Summarization Using Modified Weighing and Sentence Symmetric Feature Methods
Published Online October 2015 in MECS DOI: 10.5815/ijmecs.2015.10.05
This keyword is found after the keywords or index terms. This contains text which is of 3 to 4 paragraphs. It gives information related to domain, existing system, proposed system and the sections that will be further dealt in the paper. Once the “i ntroduction ” keyword is identified based on rhetorical roles, the text beside “Introduction” is extracted and it undergoes all the phases till summarization. The output text of this “Introduction” contains domain of the paper and important points are to be extracted based on scoring factor.
Conclusion:
This keyword is identified by the word “conclusion”. The text besides this undergoes all the stages and finally a summarized text will be produced which gives information about the work done in the paper and also the future work.
-
A. Implementation details
In this paper three summarization algorithms are implemented which mainly focuses on research papers of the given area. The three algorithms are, as follows:
-
• Top-Score Algorithm
-
• Modified Sentence symmetric feature Algorithm
-
• Modified Weighing method Algorithm
Top score algorithm [10] is an existing well defined method. In this work sentence symmetric algorithm is used in a modified way to be compared with the top score method. The modifications are done to include more features like thematic weight and emphasize weight. Weighing method is used in the conventional manner but the way in which weights are given is changed and also a graphical matrix representation is used.
-
B. Modified Sentence Symmetric Feature Method
In Sentence Symmetric feature algorithm the following attributes are used to calculate the sentence score.
-
• Cue
-
• Key
-
• Title
-
• Location
To calculate the sentence score the formula S= aC+bK+cT+dL is used.
Where C – Cue weight, K – Key weight, T – Title weight, L – Location weight and a,b,c,d are set of positive integers in the range [0,1] .
The main disadvantage of using this method is irrelevant data is also being displayed. To overcome this disadvantage, a modified version of the above scheme is used in which instead of calculating the key weight, two more features are added i.e.,
-
1 . Thematic weight of the sentence.
-
2 . Emphasize weight of the sentence.
So, the Modified Sentence Symmetric Feature consists of
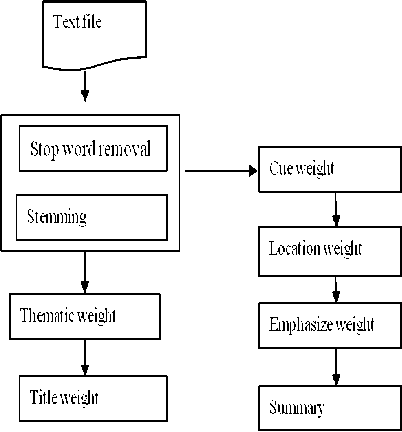
Fig.2. Data flow diagram of Modified Sentence Symmetric feature Method
Cue Weight for sentences:
The Cue Weight for sentences is calculated by adding the cue weight of its constituent words, it is a quantitative description. This depends up on the hypothesis that has significant implications for language acquisition, and is applicable for the specification of a particular sentence by the its existence or nonexistence of particular cue words in the cue dictionary.
Total number of cue words present in a sentence s is denoted by Cwj (Sj) and total number of cue words in the document is denoted by Cwi.
Thematic Weight for sentences:
Thematic words are defined as most frequent words. The functions of the thematic words frequencies are Sentence scores.
Where indicates Total number of thematic words present in a sentence s is denoted by Thej(Si) and total number of thematic words present in the document is denoted by Thei.
Title Weight for sentences:
Here the sentence weight is calculated by the addition of all the words in the content which are given in the title and sub title of a text.
Total number of title words present in that sentence s is denoted by Tij(Si) and total number of title words in the document is denoted by Tii.
Location Weight for sentences:
The importance of sentence is indicated by its location , sentences tend to occur at the beginning or in the end of documents or paragraphs based on the hypothesis. A greatest correlation is achieved between the human-made exception and automatic exception by adding the three latter methods and the results are shown.
Location of the sentence s is denoted by Lj(Si) and total number of sentences present in the document is denoted by Si.
The proposed algorithm is presented below.
Table 1. Steps for Modified Sentence Symmetric Feature Method
Algorithm
Step 1: Sentence segmentation is performed.
Step 2: for each sentence s do
Step2a:Cue Weight for sentences : for Cwj in Si do C = Σ Cwj(Si) /ΣCwi
Step2b:Thematic Weight for sentences :
for Thej in Si do
Th = Σ Thej(Si) /ΣThei
Step 2c:Title Weight for sentences :
for Tij in Si do
T = Σ Tij(Si) /ΣTii
Step 2d:Location Weight for sentences :
for Lj in Si do
L = Σ Lj(Si) /Σ Si
Step2e:Emphasized words Weight for sentences :
for Emj in Si do
E= Σ Emj(Si)
Step 3.End
Step 4.For each sentence do
Sentence Score :
Sf = C + Th + T + L + E
Step 5.End
Step 6.Return sentence score.
-
C. Modified Weighing Method
-
a) Pre-processing:
The first step in text summarization involves preparing text document to be analyzed by the text summarization algorithm. First of all we perform sentence segmentation to separate text document into sentences. Then sentence tokenization is applied to separate the input text into individual words. Some words in text document do not play any role in selecting relevant sentences of text for summary, Such as stop words ("a", "an", the"). For this purpose, part of speech tagging is used to recognize types of the text words. Finally, nouns of the text document are separated.
-
b) Calculating word local score:
Local score of a word is calculated by using term frequency and sentence count Term frequency is defined as frequency of the word normalized by total number of words. Sentence count is the no of sentences containing the word normalized by total no of sentences.
-
c) Title Weight for sentences:
Here the sentence weight is calculated by the addition of all the words in the content which are given in the title and sub title of a text.
Total number of title words present in that sentence s is indicated by Tij(Si) and total number of title words in the document is indicated by Tii.
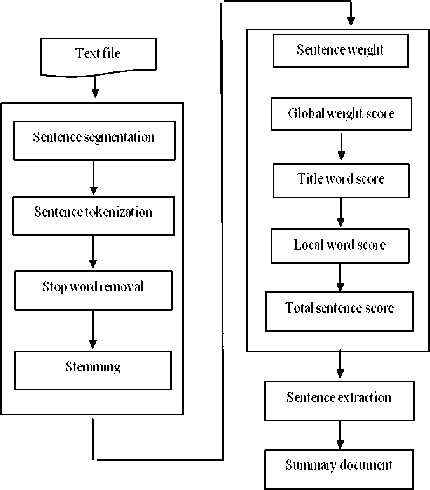
Fig.3. Data Flow Diagram of Modified Weighing Method
-
d) Sentence-to-Sentence Cohesion:
Calculate similarity between each sentence s and each other sentences of the document and then sum those identical values, acquiring the fibrous value of this feature for s. This process is iterated for all sentences.
Sentence weight=∑a[i,j]/∑∑a[p, q]
The proposed algorithm is presented below.
Table 2. Steps for Modified Weighing Method
Algorithm
Step 1: Sentence segmentation is performed.
Step 2: for each sentence do
Title word score(f1)= Σ Tij(Si) /ΣTii
Global keyword score(f2)=no of global keywords present in a sentence
Local keyword score(f3)= no of local key words present in a sentence
Sentence weight(f4)= Σ a[i,j] /ΣΣ a[p,q]
End.
Step 3:for each sentence do
Sentence score= (f2*s)+(f3*s)+(f4*s)
+ f1
Total no of words in sentence i
Where s=1 for title words
S=0.9 for global keywords
S=0.8 for local keywords.
End
Step 4: Return sentence score.
-
IV. Results and Performance Evaluation
Initially selected document is uploaded and the linguistic roles in it are identified. Later the sentence scores for the given document are calculated. Next, extract the sentences of the document based on their sentence scores.
Once the summarized text for the three algorithms is achieved then the precision and recall values are calculated to find the best method.
The performance of the proposed system is evaluated based on available manual summaries as the dataset using the evaluation measures. For experimentation, the summary is generated for different compression rate and is evaluated on the extractive summary provided in the dataset using the evaluation measures.
By comparing the average of precision, recall and F-measure scores of the three algorithms, the best method among the methods is found to be Modified weighing method.
The table 3 presents the values collected while measuring the performance of all the systems.
-
A. Performance comparison
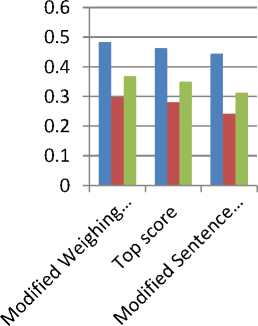
To test the summarization process, different research documents have been used as input. The purpose was to test the context understanding by the summarizers developed in this work. The table gives the results of three approaches with their average precision, recall and f-measure. Therefore it is observed that Modified Weighing method is the best method among the other two methods.
|
Summaries |
Precision |
Recall |
f-measure |
|
Modified Weighing method |
0.4832 |
0.2968 |
0.3678 |
|
Top score |
0.4625 |
0.2806 |
0.3488 |
|
Modified Sentence symmetric |
0.4439 |
0.2418 |
0.3129 |
■ Precision
■ Recall
■ F-Measure
Fig.4. Performance Comparison
Table 3. Measuring the Performance for all Three Methods
|
SN O |
DOC NO |
MODIFIED WEIGHING METHOD |
TOP SCORE METHOD |
MODIFIED SENTENCE SYMMETRIC METHOD |
||||||
|
PRECISI ON |
RECAL L |
F-MEASUR E |
PRECISIO N |
RECAL L |
F-MEASUR E |
PRECISIO N |
RECAL L |
F-MEASUR E |
||
|
1 |
AS001 |
0.3444 |
0.2303 |
0.2759 |
0.3333 |
0.1636 |
0.3078 |
0.3358 |
0.1636 |
0.342 |
|
2 |
AS002 |
0.5259 |
0.2939 |
0.2937 |
0.4259 |
0.2039 |
0.3492 |
0.4629 |
0.2196 |
0.2809 |
|
3 |
AS003 |
0.4222 |
0.3755 |
0.3973 |
0.3888 |
0.3175 |
0.2142 |
0.5135 |
0.2755 |
0.3275 |
|
4 |
AS004 |
0.5512 |
0.3017 |
0.3878 |
0.5253 |
0.2615 |
0.2652 |
0.4938 |
0.2812 |
0.3125 |
|
5 |
AS005 |
0.4925 |
0.3125 |
0.3765 |
0.4125 |
0.3218 |
0.2256 |
0.5246 |
0.2615 |
0.3185 |
|
6 |
AS006 |
0.4812 |
0.2725 |
0.3598 |
0.4821 |
0.3025 |
0.2025 |
0.5315 |
0.2912 |
0.3001 |
|
7 |
AS007 |
0.5816 |
0.2985 |
0.3927 |
0.3961 |
0.2827 |
0.4014 |
0.4521 |
0.2127 |
0.2812 |
|
8 |
AS008 |
0.4998 |
0.2935 |
0.2861 |
0.5142 |
0.2569 |
0.3252 |
0.4925 |
0.2412 |
0.2912 |
|
9 |
AS009 |
0.4514 |
0.3885 |
0.3411 |
0.5652 |
0.3599 |
0.3851 |
0.3215 |
0.2231 |
0.3215 |
|
10 |
AS010 |
0.4821 |
0.3012 |
0.3712 |
0.5841 |
0.3321 |
0.3951 |
0.3112 |
0.2489 |
0.3101 |
|
11 |
AVERAGE |
0.4832 |
0.2968 |
0.3482 |
0.4625 |
0.2806 |
0.3071 |
0.4439 |
0.2418 |
0.3057 |
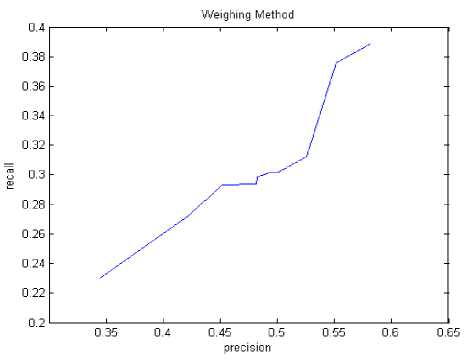
Fig.5. P and R for Modified Weighing Method
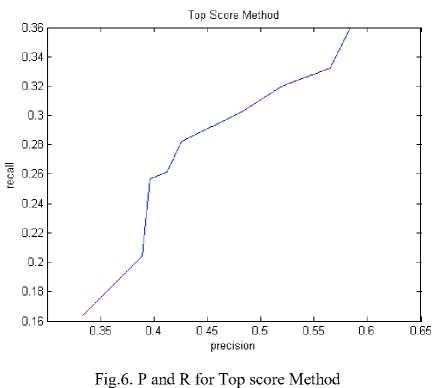
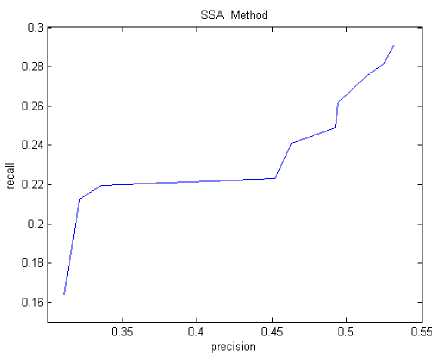
Fig.7. P and R for Modified Sentence Symmetric Method
By comparing Fig. 5 and Fig. 7, Modified Weighing with Modified Sentence Symmetric Method (MSSM) an observation can be made that recall value remained same for an increase in precision for MSSM. Whereas for Modified Weighing Method, the behaviour of recall with precision is linear as should be for a perfect system.
By comparing Figure 6 and Figure 5, Top score method with Modified Weighing method, both are behaving similarly. But for a text summarization system, a system with better precision is preferred. And if both the graphs of Modified Weighing Method and Top score method are observed, for the Top score method the precision dipped for a higher recall but in the Modified Weighing method the increase in precision is consistent.
Hence, an observation can be made that Modified Weighing Method is a better and consistent method. And as the average Precision (P) and Recall(R) numbers are suggesting, the Modified Weighing Method is suitable.
-
V. Conclusion and Future Work
This paper mainly focused on summarization of research papers. Three different algorithms for summarization are implemented and the performance is observed. Keywords are used for identifying the rhetorical roles in the document. For the calculation of sentence scores and their feature scores for summarizing the text all these three methods are used based on statistical approaches. The work with text data is difficult at times due to vast amount of data to be summarized. While using extractive methodologies sometimes the sentences that are not important to be included in the summary also get included. In the proposed work this limitation was overcome, by using compression ratio to find out the important sentences.
The scope of the paper is maintained to Extractive summarization approaches only. In future, the scope of this work can be extended to abstractive summarization approaches, so that the system can be more efficiently used by all the researchers by giving semantic meanings to the sentences. Also hybrid approaches of extractive and abstractive methods can also be tried.
Acknowledgement
The authors would like to thank the anonymous reviewers for their careful reading of this paper and for their helpful comments.
References Extractive Text Summarization Using Modified Weighing and Sentence Symmetric Feature Methods
- H.P.Luhn "The Automatic Creation of Literature Abstracts". IBM Journal of Research and Development, 2(92):159 - 165, 1958.
- H. P. EDMUNDSON "New Methods in Automatic Extracting", Journal of the Association for Computing Machinery, Vol. 16, No. 2, April 19691 pp. 264~285.
- A.Das, M.Marko, A.Probst, M.A.Portal, C.Gersheson "Neural Net Model For Featured Word Extraction", 2002.
- Jagadeesh J, Prasad Pingali, Vasudeva Varma, "Sentence Extraction Based Single Document Summarization" Workshop on Document Summarization, 19th and 20th March, 2005, IIIT Allahabad.
- Arman Kiani B, M. R. Akbarzadeh "Automatic Text Summarization Using: Hybrid Fuzzy GA-GP", IEEE International Conference on Fuzzy Systems.Juky 16-21, 2006.
- Saeedeh Gholamrezazadeh, Mohsen Amini Salehi, Bahareh Gholamzadeh, A Comprehensive Survey on Text Summarization Systems, IEEE 2009.
- Ladda Suanmali, Naomie Salim, Mohammed Salem Binwahlan "Fuzzy Logic Based Method for Improving Text Summarization", (IJCSIS) International Journal of Computer Science and Information Security, Vol2 No1 2009.
- Rasim ALGULIEV, Ramiz ALIGULIYEV "Evolutionary Algorithm for Extractive Text Summarization" Intelligent Information Management 2009, Science Research.
- Vishal Gupta, Gurpreet Singh Lehal "A Survey of Text Summarization Extractive Techniques" Journal Of Emerging Technologies In Web Intelligence, VOL. 2, NO. 3, August 2010.
- Maryam Kiabod, Mohammad Naderi Dehkordi and Sayed Mehran Sharafi "A Novel Method of Significant Words Identification in Text Summarization", Journal Of Emerging Technologies In Web Intelligence, VOL. 4, NO. 3, August 2012
- Masrah Azrifah Azmi Murad, Trevor Martin "Similarity-Based Estimation for Document Summarization using Fuzzy Sets", International Journal of Computer Science and Security, volume 1 issue 4 2006.
- Rafeed Al-Hashemi "Text Summarization Extraction System(TSES) Using Extracted Keywords", International Arab Journal e-Technology, vol 1 No 4, June 2010.
- Shaidah Jusoh, Hejab M. Alfawareh, Techniques "Applications and Challenging Issue in Text Mining", IJCSI International Journal of Computer Science Issues,vol 9, issue 6,November 2012.
