Face Recognition in Multi Camera Network with Sh Feature

Author: R.Sumathy
Journal: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Article in issue: 5 vol.7, 2015.
Free access
Multi view face recognition using multiple camera networks is an active research area. The main aim of this paper is to handle different pose variations in multi camera network and recognizing face from those videos. The traditional approaches handle the pose estimation explicitly ,the proposed work will handle the multiple views of the poses .For a given set of multi view video sequences we use particle filter to track the 3D location of the head. The texture map is generated by back projecting the multi view video. The proposed work is developed using the Spherical Harmonic (SH) representation of the face from the texture mapped on to the sphere. A robust feature is constructed based on the properties of SH projection.
Face recognition, still image based, video based face recognition, multi view recognition, particle filter and spherical harmonics
Short address: https://sciup.org/15014760
IDR: 15014760
Text of the scientific article Face Recognition in Multi Camera Network with Sh Feature
Published Online May 2015 in MECS
Face recognition is the process of identifying an individual or a person from a video or digital image and compared with the stored databases of faces. The application area of face recognition ranges from biometrics to surveillance systems. In general a face can be recognized in a still image or in video systems in a single view or in multiple views. The main drawback of using single view based face recognition is the information loss occurs during image formation. The image obtained from single view also suffers from pose variations .Another drawback is the one part of the image is self-occluded by another part of the image which is a problem in object tracking, motion capture, etc. [3].
Multi camera network provide a valuable tool for safety and security applications. Multi camera network composed of many distributed cameras with their own processors. By having so, the multiple views obtained from those cameras increases the chances of recognizing the person more efficiently. This can be achieved by estimating the pose of the person’s head to an approximation. More attention has to be given on the quality of the image and camera calibration. There are many methods for multi view pose estimation [1],[2] but the pose estimation of head is a problem due to poor resolution of images, camera calibration etc.
Face recognition across multi camera network is the process of recognizing the faces from multiple views with diffuse pose and light variations. At a time we can obtain multi views of the face captured from multiple cameras that combines both frontal and non-frontal poses of the image .In this paper, a robust feature for recognizing face can be obtained For a given video sequence, the particle filter method is used to track the 3D location of the head. For each video frame, the texture map for the whole face is constructed by mapping the image intensity values onto the surface of spherical model using the back projection method. The spherical harmonic transformation of the texture map is computed and robust feature is constructed.
-
II. R elated W ork
-
A. Face Recognition Based On Still Images
In general a face recognition process is formulated as follows: given a input still/video image is given. The detection of face can be done by segmenting the face and the features are extracted using known techniques and the face can be recognized. Fig.1. illustrates the face recognition process.
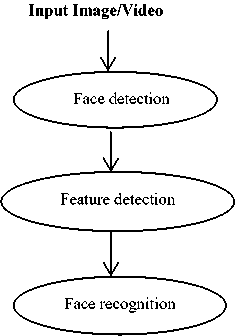
Fig. 1. Face recognition process
Generally recognizing face from a single still image will not provide sufficient information due to unavailability of data’s in those images. Also the view available in the image could not able to recognize face. Still image based multi view face recognition provides a solution. One such method [4] is to use pose estimation method and a pose estimator is constructed using support vector machine. The advantage is that data in SVM based pose estimator can be trained directly and it improves speed and accuracy. Yongbin et.al [5] proposed probabilistic appearance-based face recognition to work with multiple images uses a feature extraction algorithm to find features that describe face images of distinct people. The algorithm was robust to partial occlusions, expression and pose changes. Another approach is using view synthesis proposed by Baymer et.al [6] that creates virtual views from a given still image using prior knowledge of 2D views of prototype faces subjected to various rotations. The combination of virtual views with the real view provides the example view where the face can be recognized. For handling the pose variation in real-life scenarios, Zhimin et.al[7] a pose-adaptive matching method that uses classifiers to deal with different pose combinations having a recognition rate of 84.45% .To obtain 3D model of face from 2D image Lu et.al [8] used feature points and warp algorithm and the texture map for the face model is constructed.
-
B. Face Recognition Based On Video
Normally video provides more information compared to still images (single or multiple views).The detection of face in video is of three processes:
-
1) Frame based detection-methods used for still images. The integration of detection and tracking i.e., detecting the face in the first frame and tracking over the sequence.
-
2) Temporal method to detect faces in multiple frames.
Most of the video sequences are collection of still images. So the algorithms applicable for still images are applied for video .One of the method is Probabilistic recognition of human faces[9].The gallery consists of still images and the probes are video sequences. Using temporal information in a probe video, a model is proposed .As the model is non-linear to non-Gaussian noise, the motion vector and identity variable is approximated using sequential re sampling importance algorithm.
Zhao et.al[10] uses a method called Locality Preserving Projections (LPP) to recognize face sequence to discover semantic information(space and time) hidden in videos simultaneously and a comparison of V-LPP with Eigen face, Fisher faces and Laplacian faces. Zhen Lei et.al [11] used Ad boost algorithm in face detection for hausdroff distance which is a measure between face model and instance of object. The overall performance of the system is increased. Another detection approach for video based face recognition proposed by Ping et.al[12] used cascade verification technique that have three modules for eliminating non frontal portion, tilted face and frontal image is sent to the recognizer. [13]Adaptive hidden Markov models (HMM) to perform video-based face recognition uses training video sequences. The characteristics of the video sequence are analyzed and the scores provided by the
HMMs are compared. The highest score provides the identity of the test video sequence. The local appearancebased face recognition algorithm proposed by Stall Kamp et.al [14] classified the face. The scores are obtained and combined to estimate the entire sequence. The individual frames are weighted using distance- to-model (DTM), distance-to-second-closest (DT2ND), and their combination. Aggarwal et.al [15] possesses video-to-video face recognition by constructing a linear dynamical system ARMA model. Sub space angles are used for computing distances between probe and gallery video sequences.
-
C. Multi View Based Face Recognition
One of the multi view based face recognition uses [16] both gallery and probe .Frames of multi view sequence are collected together to form a gallery or probe set. The frontal or near frontal faces are picked by the pose estimator and retains and others are discarded. The recognition algorithm is frame based PCA and LCA fused by the sum rule.[17] uses AAM framework to the multi view video case. They demonstrate that when 3D constraints are imposed, the resulting 2D+3D AAM is more robust than the single view case. But recognition was not attempted. Chen et.al [18] used geometrical models to normalize pose variations. By back projecting a face image to the surface of an elliptical head model, they obtained a texture map which was generated from different images that were compared in a probabilistic fashion.
-
D. Video Processing Over Distributed Networks
Tracking in video can be defined as a problem of locating a moving object (or multiple objects) over time based on observations of the object in the images. Multiple object tracking is one of the most fundamental tasks for higher level automated video content analysis. Kalman filter [19] achieves Multi target tracking by 2 steps: prediction and correction. The prediction step uses the state model to predict the new state of the variables. The correction step uses the current observations to update the object’s state. A consensus algorithm is an interaction rule that specifies information exchange between a sensor and its neighbors that guarantees that all the nodes to reach a consensus. Distributed Kalman consensus algorithm defines a set of cameras communicating with its neighboring cameras and no cameras can pass information to its non-neigh boring cameras .The extended Kalman Consensus allows to track targets on the ground plane using multiple measurements in the image plane taken from various cameras. Particle filter tracking approach [20] is a sequential Monte Carlo method which provides Monte Carlo approximation to the prediction distribution, which is used to search for newly observed targets. A particle filter is often used because the system and observation models are nonlinear and the posterior can temporarily become multi-model due to background clutter.
Spherical Harmonics (SH) is a connection between SH and PCA, where the principal components are equal to SH basis function under appropriate assumptions. An algorithm to estimate the SH basis images for a face at a fixed pose from a single 2D image based on statistical learning.
-
III. P re -P rocessing
Pre-processing is the first phase in face recognition process which includes converting videos into frames.The videos are acquired by any digital device like digital cameras in multiple views and the obtained video has to be optimized by performing cropping, scaling, aspect ratio adjustments, noise reduction, brightness and color corrections. It is also imperative to achieve properly sized video without motion artefacts due to interlace or film sources being transferred to video. In addition, in the production environment, we may not have control over the original creation of source material. Whether the capture is poor, or simply needs to be de-interlaced and resized, almost invariably the source video needs preprocessing in order to look its best when delivered over limited bandwidth networks.

Fig. 2. Shows the sample of 6 frames generated from a set of 500 frames taken from 3 cameras in multiple networks
-
IV. S equential I mportance R esampling
Tracking in camera based network uses [28] Particle filter (SIR) method for tracking the state of dynamic system that can be computationally traceable for large/high dimensional problems. A particle filter is often used because the system and observation models are nonlinear and the posterior can temporarily become multi-model due to background clutter. Particle filter is a Monte Carlo method for performing inference in state space models where the state of the system evolves according to:
Xk = fk (Xk-1 ,v k-1 )
where Xk is a vector representing the state of the system at time k, vk-1 is the state of noise vector ,fk is possibly non-linear and time dependent function describing the evolution of the state vector. Information about Xk is obtained only through noisy measurement of it, zk given by the equation zk=MXk >”k ) (2)
where h k is a possibly non-linear and time dependent function describing the measurement process and nkis the measurement noise vector. The filtering problem involves the estimation of state vector at time k , given all measurements up to and including denoted by z 1:k . In Bayesian settings the problem can be formalized by two steps:
-
1. Prediction step : In this step p(X k |zk-1 ) is
-
2. Update Step : In this step the prior is updated with the new measurement z k using the Bayes rule to obtain the posterior over X k given by:
computed from the filtering distribution p(Xk-1 |z1:k-1 ) at time k-1 is given by:
P(X k |Z 1:k-1 )=J p(X k l X k-1 )P(X k-1 |z 1:k-1 d )dX k-1
where p(X k-1 lz 1:k-1 d) is assumed to be known due to recursion that can be thought as prior over X k and P(Xk |x k-1 ) is given by equation (1).
P(X k lz 1:k )« p(z k |X k )p(X k |z 1:k-1 ) (4)
Sequential importance sampling is based on importance sampling . In this one approximates the target p x using the samples drawn from a proposal distribution q x .Importance sampling is generally used when the target distribution is difficult to sample but much easier to distribute from proposal distribution. The discrepancy between the target and the proposal distribution can be overcome by assigning weight to each sample X1 by where h(x) is a function that is proportional to p(X).After applying the proposal distribution at time k-1 can be determined by
p (X0:k-1 |z1::k-1 ) ~ 1- 1 = 1 к Wk-1 d X0:k-1 (5)
where dX 0:k-1 is the delta function centered at X0:k-1
The SIS algorithm thus constructs a recursive propagation of weights and support points at each measurements .The algorithm for SIS is given below:
ALGORITHM 1: Sequential Importance Sampling [ {X k W }N =1 ] =SIS [{Xl k _1 , w ^—1 } Ni =1 , zk] FOR i=1J Vs
Draw Xk ~q(Xk|xk_1,zk)
Assign the particle a weight, w k
End FOR
A common problem with SIS is degeneracy problem, where each particle has negligible weight and the variance of weight increases over time. A suitable measure for degeneracy problem is the effective sample size Ne^ defined as
-
V / (6)
where wk = p(x k |z1:k )|x k-1 ,zk) is referred to as true weight. The estimate Ve^ can be obtained as
^ У (7)
where w k is the normalized weight Small N eff indicates severe degeneracy. The brute force approach is to use large Ns . This is impractical .So resampling is done to avoid degeneracy.
The effects of degeneracy can be reduced by resampling whenever a significant degeneracy is observed. The basic idea is to eliminate degeneracy is to eliminate particles which have small weights and to concentrate on particles with small weights. The resampling step involves generating new set {x k j^ by re-sampling Ns times from an appropriate discrete representation p(x k-1 |z1:ks) given by
P ( X o:k-1 |Z 1:k-1 ) ® X i=i kW lk—1 9(x k - x k ) (8)
The weights are reset to w k =1/ Ns. This re-sampling procedure can be implemented in O ( Ns) times. The resampling algorithm is given .The algorithm indicates that the weights and state variables are considered and the sampling is made using the algorithm 1.The cumulative density function is calculated and if the value is less again the sampling is done.
The sequential importance resampling algorithm is given below:
ALGORITHM 2: Sequential Importance Re-sampling
[ {x k ,w k IVU I =sir [{ x k , w k ivu ]
Initialize CDF: c1=0
FOR i=2: Ns
Construct CDF: ci= ci-1+ w k
End FOR
Start at the bottom of CDF: i=1
Draw a starting point: u1 ~ U [0,:T Vs -1]
FOR j=1: Ns
Move along the CDF: uj= u1+Ns-1(j-1) WHILE uj> ci
The algorithm for generic particle filter is also introduced.
ALGORITHM 3: Generic Particle Filter
[ {xk ,wk }vi s =1 ] =PF [{ xk-1 , wk-1 } vi=1 ,zk ]
FOR i=1:Vs
Draw x k ~q(X k |x k-1 ,zk)
Assign the particle a weight, w k
End FOR
Calculate total weight: t=SUM [w k }} Vi = 1]
FOR i=1:Vs
Normalize: w k =t-1w k
End FOR
Calculate V^using (7)
If V^ Resample using algorithm (2) *[{xk ,wk, -}Vz=1] =SIR [{xk ,wk }Vt=1] End IF A. Multi View Tracking In this stage the 3D position f the head is localized from multiple views. To describe the position and pose of an object we need 6D representation. But higher the dimensionality of the state space makes difficult in tracking problem .In SIR the number of particle grows dramatically for higher dimensional state spaces .Since we are considering only the location of the head in 3D the state space for tracking let the state space s = (x,y, z) represents only the position of the head. As a result the state transition model P (s£ | S£-1) is modelled. Similarly the observation model P (O t |s£) of the tracker is based on multiple cues such as histogram, the gradient map and a geometric constraint. Histogram: We assume a weak perspective camera model and calculate the image of the spherical model on the jth camera image plane, which is a disk like region. A normalized histogram is built which is the first cue matching function 0(O£, s£ ) Gradient map: On the circular perimeter of the model image, we select 90o arc segment on the top. This part of the boundary coincide with the arc produces a second cue matching score ф (Ot,s£) = -^=1|nm .77m| (9) r7 Geometric constraints: The detector is based on HOG .Potential human subjects are filtered using applying body size constraints and the detection result with highest confidence is picked that produces v(0£ ,s£). ^ (о £s£) ={0 [f EJc Rj *0 t 1 otherwise The overall image likelihood can be calculated as P (Otlst)) a In у (O t,,st). +h In Ф (O t,st) + X2 In ф (O t,st)) where are determined by applying a logistic regressionlike algorithm to independent data. The location of the head in 3D space is determined by: st=argmax P (st) | O t) (12) = argmaxP (O t |st) P (st |st)) st Fig. 3. Shows the result of tracking in multiple views. Our particle filter tracker tracks the location of the head in all the frames. The figure shows 6 frames out of 500 frame B. Texture Mapping Once the 3D location of the head is obtained, the surface texture of the map is obtained by the following procedure. 1. Uniformly sample the radius if the sphere within the range [-R, R] to get zn where n=1, 2 _N 2. Uniformly sample αn within the range [0,2π] to get zn where n=1, 2 ...N 3. xn = 4b2 - zn cosan, yn =4K2 - zn sinan Then perform a coordinate transformation for these sample points. The original points are {((xn,yn ,zn ) n=0,1,..N}.After the transformation we obtain {(хП] ,ynj’Z’j)}.These are the coordinates in the jth camera plane. The visibility of jth camera is determined and an un-occluded point that (xn,yn,zn ) satisfies zn j< z0 jcontribute image on the jth camera image plane z'0]- is the head center to the jth camera plane. The texture map Tj is obtained by back projection approach by creating a back projecting link betweenxn, yn, zn and the image coordinates {( x^j ,y'npz'Y)}.This procedure is repeated over all cameras .The associated texture map for the coordinates(xn, yn , zn )is determined by: T (xn ,yn ,zn) = Tj0 (xn ,yn,zn) (14) where j0 = argmax wnj-j=1, 2^K SH FEATURE A robust recognition system must be able to identify an object across variable lighting conditions .The robust feature is based on the theory of spherical harmonics which is set of orthogonal basis function defined over unit sphere. The SH basis function for degree l and order m has the following form: Ylm(9, ф) = Klm(РГ (cos 9)е1тФ (15) where Klm is normalization constant such that Ie=0Ylm 1ф==0YimYlm * ^вйф =1 (16) The real SH are orthonormal and they share most of the properties of the general spherical harmonics. The spherical model is different from 3D face model. A low resolution images can be dealt using SH model and hence it is suitable for camera network. Even when the face undergoes extreme pose variations the SH model extracts the feature from texture maps leading to pose robust face recognition. Another advantage of SH spectrum is ease of use. The only one parameter to be determined in SH feature is number of degrees .If the number of degrees is more means more approximation. We compare the performance of our video recognition algorithm with 2 other ones: In this paper we presented a multi view based approach to recognize face. The main advantage of this paper is it does not require any pose estimation or model registration step .Under normal diffuse lighting conditions we presented a robust feature by SH theory. Also the feature acquisition is automated by multi view tracking algorithm using particle filter. The pose insensitivity property of SH representation relies on the assumption that the spherical function remains unchanged other than rotation. This could be affected by real world lighting conditions .Under normal lighting conditions this assumption is reasonable .In extreme lighting conditions the assumption becomes invalid because if there are any anisotropic illumination variation or strong directional lighting is casted onto the face from the side will result in large fluctuations of features and makes the performance to degrade. So the future work will focus on overcoming these drawbacks. [1] S.Ba, J.M.Odobez “Probabilistic head pose tracking evaluation in single and multiple camera set ups”, Multimodal Techno. Perception Humans, vol 4625, pp.276-286, June 2008. [2] Q.Cai, A.C.Sankaranarayanan, Q.Zhang, Z.Zhang, z.Liu “Real time head pose tracking from multiple camera with generic model” in Proc. CVPR Workshops, pp.25-32 June 2010. [3] JangI.Y., LeeK.H. Depth” Video based human model reconstruction resolving self‐occlusion” IEEE Transactionson Consumer Electronics, 2010, 56(3): 1933‐ 1941. [4] Wen Yi zho, Rama Chellapa “Image based face recognition issues and methods”, IEEE transactions 1997. [5] Yongbin Zhang, Aleix M. Martıńez “A weighted probabilistic approach to face recognition from multiple images and video sequences” Elsevier August 2005. [6] David Beymer Tomaso Poggio “Face recognition from one example view” Massachusetts Institutue of Technology,Sep 1995. [7] Zhimin Cao, Qi Yin, Xiaoou Tang, Jian Sun “Face Recognition with Learning-based Descriptor” Computer Vision and Pattern Recognition (CVPR), IEEE Conference June 2010. [8] Chen Lu, Yang Jie “Automatic 3D Face Model Reconstruction Using One Image” Advances in Machine Vision, Image Processing, and Pattern Analysis Lecture Notes in Computer Science Volume 4153, Springer 2006, pp 235-243. [9] S. Zhou, V. Krueger, and R. Chellappa. “Probabilistic recognition of human faces from video” Computer Vision and Image Understanding, 91:214–245, July-August [10] Ke Lu, Zhengming Ding, Jidong Zhao, Yue Wu “Videobased face recognition”IEEE Image and Signal Processing (CISP), 2010 3rd International Congress on (Volume: 1) Oct. 2010. [11] Zhen Lei, Chao Wang, Qinghai Wang, Yanyan Huang, “Real-Time Face Detection and Recognition for Video Surveillance Applications” Computer Science and Information Engineering, 2009 WRI World Congress on (Volume: 5), April 2 2009. [12] Ping Zhang, Lorman,”A video-based face detection and recognition system using cascade face verification modules” IEEE MS Applied Imagery Pattern Recognition Workshop, AIPR, Oct. 2008. [13] Xiaoming Liu; Tsuhan Chen “Video-based face recognition using adaptive hidden Markov models”, Computer Vision and Pattern Recognition, 2003. Proceedings. 2003 IEEE Computer Society Conference on (Volume: 1) June 2003. [14] Stallkamp, Ekenel, H.K.; Stiefelhagen, J. “Video-based Face Recognition on Real-World Data”. Computer Vision, 2007. ICCV 2007. IEEE 11th International Conference on Oct. 2007. [15] Aggarwal, G.; Chowdhury, A.K.R.; Chellappa, R. “A system identification approach for video-based face recognition” Pattern Recognition, 2004. ICPR 2004. Proceedings of the 17th International Conference(vol 4)Aug 2004. [16] A.Pnevmatikakis, L.Polymenakos, “video –to-video face recognition”, Far field Intech Chennai 2007,pp.468-486. [17] 20. K.Ramnath, S.Koterba, J.Xiao, C.Hu, I.Mathews, s.Baker “Multi view AAM fitting and construction”, International .Journal of Computer Vision Vol 76, PP.183204, Feb 2008.
V. Experimental Results
VI. Conclusion
VII. Future Work
References Face Recognition in Multi Camera Network with Sh Feature
- S.Ba ,J.M.Odobez "Probabilistic head pose tracking evaluation in single and multiple camera set ups",Multimodal Techno . Perception Humans, vol 4625,pp.276-286,June 2008.
- Q.Cai,A.C.Sankaranarayanan,Q.Zhang,Z.Zhang,z.Liu "Real time head pose tracking from multiple camera with generic model" in Proc.CVPR Workshops, pp.25-32 June 2010.
- JangI.Y., LeeK.H. Depth " Video based human model reconstruction resolving self‐occlusion" IEEE Transactionson Consumer Electronics, 2010, 56(3): 1933‐1941.
- Wen Yi zho, Rama Chellapa "Image based face recognition issues and methods",IEEE transactions 1997.
- Yongbin Zhang, Aleix M. Martıńez "A weighted probabilistic approach to face recognition from multiple images and video sequences" Elsevier August 2005.
- David Beymer Tomaso Poggio "Face recognition from one example view" Massachusetts Institutue of Technology,Sep 1995.
- Zhimin Cao, Qi Yin, Xiaoou Tang, Jian Sun "Face Recognition with Learning-based Descriptor" Computer Vision and Pattern Recognition (CVPR), IEEE Conference June 2010.
- Chen Lu, Yang Jie "Automatic 3D Face Model Reconstruction Using One Image" Advances in Machine Vision, Image Processing, and Pattern Analysis Lecture Notes in Computer Science Volume 4153,Springer 2006, pp 235-243.
- S. Zhou, V. Krueger, and R. Chellappa. "Probabilistic recognition of human faces from video" Computer Vision and Image Understanding, 91:214–245, July-August 2003.
- Ke Lu , Zhengming Ding , Jidong Zhao , Yue Wu "Video-based face recognition"IEEE Image and Signal Processing (CISP), 2010 3rd International Congress on (Volume:1 ) Oct. 2010.
- Zhen Lei ,Chao Wang , Qinghai Wang , Yanyan Huang, "Real-Time Face Detection and Recognition for Video Surveillance Applications" Computer Science and Information Engineering, 2009 WRI World Congress on (Volume:5 ), April 2 2009.
- Ping Zhang , Lorman,"A video-based face detection and recognition system using cascade face verification modules" IEEE MS Applied Imagery Pattern Recognition Workshop, AIPR, Oct. 2008.
- Xiaoming Liu ; Tsuhan Chen "Video-based face recognition using adaptive hidden Markov models", Computer Vision and Pattern Recognition, 2003. Proceedings. 2003 IEEE Computer Society Conference on (Volume:1 ) June 2003.
- Stallkamp, Ekenel, H.K. ; Stiefelhagen, J. "Video-based Face Recognition on Real-World Data". Computer Vision, 2007. ICCV 2007. IEEE 11th International Conference on Oct. 2007.
- Aggarwal, G. ; Chowdhury, A.K.R. ; Chellappa, R. "A system identification approach for video-based face recognition " Pattern Recognition, 2004. ICPR 2004. Proceedings of the 17th International Conference(vol 4)Aug 2004.
- A.Pnevmatikakis ,L.Polymenakos, "video –to-video face recognition", Far field Intech Chennai 2007,pp.468-486.
- 20.K.Ramnath,S.Koterba,J.Xiao,C.Hu,I.Mathews,s.Baker "Multi view AAM fitting and construction", International .Journal of Computer Vision Vol 76,PP.183-204,Feb 2008.
- X.Liu ,T.Chen "Pose –robust face recognition using geometry assisted probabilistic modeling" IEEE Conference Computer Vision Pattern Recognition ,vol 1 pp.502-509,June 2005.
- R. E. Kalman "A new approach to linear filtering and prediction problems" Transactions of the ASME – Journal of Basic Engineering, No. 82 (Series D). (1960), pp. 35-45.
- Olfati-Saber, R., Fax, J. A., Murray, R. M. (2007). "Consensus and cooperation in networked multi-agent systems." Proceedings of the IEEE, pp.215–233.
