Формирование лексически связанных компонентов информационно-терминологического базиса

Автор: Лесков Виталий Олегович
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 2 (23), 2009 года.
Бесплатный доступ
Рассмотрена проблема информационной поддержки обучения иностранной лексике на основе внутриязыковых ассоциативных зависимостей. Сформулирована задача построения информационно терминологического базиса. В качестве ее решения предлагается нисходящий алгоритм формирования лексически связанных компо- нентов.
Мл-технология, лексически связанный, итб, лск-методика, лс-компонент
Короткий адрес: https://sciup.org/148175869
IDR: 148175869
Formation of lexically related components of information-vocabulary basis
The problem of information support of foreign vocabulary training based on intralingua associative relationships is considered. The task of the information-vocabulary basis formation is defined and resolved by top-down algorithm of the lexically related components building.
Текст научной статьи Формирование лексически связанных компонентов информационно-терминологического базиса
Обучение иностранной лексике подразумевает установление однозначных ассоциативных связей между терминами различных языков, обозначающими одно и то же понятие. Такие связи являются наиболее простыми и устанавливаются непосредственно в процессе обучения. Построение более сложных ассоциативных связей происходит естественным путем в процессе использования усвоенных знаний, в том числе это касается и установления ассоциативных связей внутри изучаемого языка. Однако современные средства обработки и анализа текстов позволяют уже на этапе обучения искусственно воссоздавать такие ассоциативные зависимости.
Так, например, назначение методики обучения на основе лексически связанных компонентов (ЛСК-мето-дики) состоит в построении систем внутриязыковых ассоциативных связей с относительно жесткой структурой непосредственно в процессе обучения [1].
Для понимания сути этой методики обратимся к ее информационному обеспечению, т. е. к информационно-терминологическому базису (ИТБ). Дело в том, что ИТБ ЛСК-методики качественно отличается от классического ИТБ [2]. Различие состоит в информационных базисных компонентах: если в классическом ИТБ таким компонентом является термин, его качества и языковые аналоги, то в случае ЛСК-методики речь идет о более сложной структуре, а именно о лексически связанном компоненте (ЛС-компоненте).
Лексически связанный компонент. ЛС-компонент имеет следующую структуру (см. рисунок).
Лексему, связанную со всеми без исключения лексемами ЛС-компонента ИТБ, принято называть основной лексемой , а лексемы, имеющие только одну связь, - связанными лексемами .
Методика обучения строится на совместном применении двух алгоритмов:
-
- адаптивного алгоритма обучения, рассмотренного в [3], с тем исключением, что в качестве элементов обучающего материала выступают не лексемы, а ЛС-компо-ненты;
-
- алгоритма построения внутриязыковых ассоциативных полей.
Алгоритм построения внутриязыковых ассоциативных полей состоит в последовательной подаче к изучению элементов ЛС-компонента. Порядок выполнения этого алгоритма следующий:
-
- основная лексема - перевод, подсказка на иностранном языке (в рамках мультилингвистической адаптивно-обучающей технологии (МЛ-технологии));
-
- связанная лексема - перевод, подсказка на иностранном языке (в рамках МЛ-технологии);
-
- лексическое сочетание основной и связанной лексем - перевод сочетания, подсказка на иностранном языке (языковой аналог лексического сочетания, а не лексем по отдельности);
-
- переход к следующей связанной лексеме;
-
- переход к следующему лексически связанному компоненту.
Таким образом, на этапе обучения усваивается не только информация о языковых аналогах терминов, но и информация о лексических связях этих аналогов, что в свою очередь ведет к построению систем внутриязыковых ассоциативных связей.
Принципы формирования ЛС-компонентов. Пусть имеется ИТБ с данными о лексических связях. Для применения ЛСК-методики необходимо изменить структуру ИТБ, выделив основные лексемы и построить на их
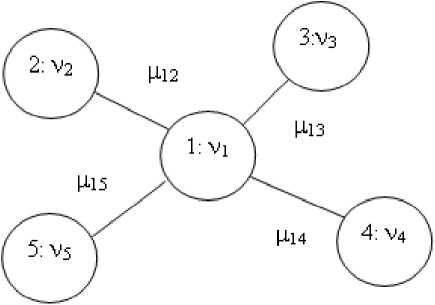
лексемы:
1 - основная лексема
2,3,4,5 - связанные лексемы лексические связи:
1-2,1-3,1-4,1-5
количественные характеристики:
Ук - абсолютная частота i-ой лексемы;
р^ — абсолютная частота сочетания i-ой и k-ой лексем
Лексически связанный компонент ИТБ
основе ЛС-компоненты. Рассмотрим пути решения этой задачи.
Для выделения основных лексем нужно выработать критерий на основе данных о частоте использования лексем и их лексических связях.
Процесс обучения и, соответственно, процесс формирования порций обучающей информации (ОИ) подчинены адаптивному алгоритму обучения. Согласно данному алгоритму, скорость забывания лексем изменяется по закону an = — $
b i n
Е (1 - Ри< к
,
hk'_ ----+1
Е H k k
где b n – скорость забывания -го элемента ОИ на n-м сеансе; (1 – p k) – вероятность знания k-го элемента ОИ, который лексически связан, т. е. порождает ассоциацию, с -м элементом ОИ; µ k – относительная частота сочетания -й и k-й лексем, отражающая силу ассоциативной связи; k – количество связанных лексем в компоненте; h – параметр, характеризующий активность ассоциативных связей, 0 < h < 1.
Вероятность незнания лексемы через функцию от времени может быть представлена в виде pi = p ,(ti) = 1 -e-aМ, (2) где an - скорость забывания z-го элемента ОИ на n-м сеансе с учетом его связи с элементами ранее изучавшихся иностранных терминологий; t n – время с момента последнего заучивания -го элемента ОИ.
Согласно адаптивному алгоритму обучения, порции обучающей информации формируются с учетом критерия
N
Q n = Е p X t i ) q . ^ min (3)
i =1
где p n ( t n ) – вероятность незнания -го элемента ОИ в момент времени t n ; q – относительная частота, выражающая долю лексической единицы в тексте, подвергшемся статистической обработке при составлении частотного словаря, 0 < q < 1:
q i max
q V,
здесь q max= max q{q 1, q 2, …, q n} – абсолютная частота появления лексической единицы в тексте; q 1, q 2, …, q n – частоты из мультилингвистического словаря, если речь идет о мультилингвистической адаптивно-обучающей технологии [4].
Таким образом, для обеспечения оптимального значения Qn к концу n -го сеанса обучения необходимо найти Mn максимальных членов суммы в критерии, индексы которых и определят очередную порцию ОИ, выдаваемую обучаемому для запоминания. Процедура поиска индексов для терминов записывается следующим образом:
u 1 = arg max p (t”) q , 1 UM = arg maxp.( t”)q, 1 < i < N, i * Uj, j = 1, 2,..., Mn -1, где arg max {a.} = z* - индекс i e Uмаксимального значения a , т. е. a * = max a ; {u1, ..., uMn} = U* – та порция ОИ, которая выдается для заучивания на n-м сеансе. С учетом применения методики обучения на основе лексически связанных компонентов за u берется не термин, а лексическое сочетание основной и связанной лексемы, если наибольший вес приобрела связанная лексема, или лексически связанный компонент, если наибольший вес приобрела основная лексема. Для выработки критерия отбора основных лексем рассмотрим ИТБ в момент времени tn+1, когда прошло уже некоторое время с тех пор как базис был пройден. Допустим, что ИТБ был построен как совокупность ЛС-компонентов, тогда основные лексемы, согласно приведенному выше адаптивно-обучающего алгоритму, будут заучены намного лучше, чем их связанные лексемы: pn+1= pi (t.+1) = 1 - e-an+1ti+1^ max. (6) Значения pзнn+1 позволяют определить, какие из лексем ИТБ более других подходят на роль основных, но это возможно только к концу обучения при условии, что базис уже сформирован как совокупность ЛС-компонентов. Перед нами стоит обратная задача – сформировать ИТБ до начала обучения. Однако по частотным характеристикам лексем и лексических сочетаний можно попытаться оценить значение pзнn+1 для всех лексем базиса и, исходя из этого набора значений, построить критерий для выделения основных лексем. Предположим, что нам удалось вычислить оценку pзнn+1 для каждой лексемы, тогда, учтя относительную частоту лексем q , построим искомый критерий: L= РП+1 q,-^ max (7) Теперь найдем значение pзн i . Подставив выражение (1) в (6), получим b n+1 b n t Е p3HkHk h)k^---------+1 Е Hk k e pn+1 зн где t n+1 – время с последнего заучивания -й лексемы, о котором нам ничего не известно; b n+1 – скорость забывания -й лексемы к моменту времени t n+1, о которой нам также ничего не известно и которая вычисляется итеративно в процессе обучения; pзн kn+1– вероятность знания k-й лексемы, которая лексически связана, т. е. порождает ассоциацию, с -й лексемой. Здесь нужно заметить, что задача выработки критерия для выделения основных лексем сводится к тому, чтобы для каждой лексемы было рассчитано значение (7) и это значение было тем больше, чем больше эта лексема подходит на роль основной. Это обстоятельство позволяет нам во многом смириться с частичным незнанием элементов выражения (8). Так, например, для разбивки ИТБ на ЛС-компоненты совершенно не важны значения t n+1 и b n+1, которые мы заменим соответственно на условную безразмерную единицу времени и на b0, получаемое из условия p = 0,5, t = 1 для всех лексем ИТБ. Также примем за единицу оценку параметра h. Что касается вероятности pзн kn+1, то ее мы можем оценить через относительную частоту k-й лексемы, так как к концу обучения, согласно адаптивно-обучающему алго- ритму, вероятности знания всех лексем будут прямо про- порциональны их относительным частотам. Тогда выражение для оценки pзнin+1 будет иметь вид p)n+1 знi b0 s qk и ik kt-----+1 S и ik k где b0 ® 0,7 (получено из условия p = 0,5, t = 1); qk и цЛ содержатся в ИТБ. Подставив выражение (9) в (7), получим критерий для выделения основных лексем: 0,7 — s qk и ik kt-----+1 S и ik Li = e kq > max. (10) Таким образом, мы получили значение Li для каждой лексемы ИТБ. Теперь нам необходимо определить количество основных лексем, и задачу о формировании ИТБ как совокупности ЛС-компонентов можно будет считать решенной. Задачу о нахождении оптимального количества основных лексем решим с помощью перебора. Для этого введем функцию качества ИТБ как совокупности ЛС-компо-нентов от числа основных лексем: 0,7 — S qk и ik kt-----+1 S и ik L (n) = S qie k ^ max, (11) где L(n) показывает сумму взвешенных вероятностей знания лексем по всему базису. Чем больше эта сумма, тем более удачно построен базис. Отсюда, максимизируя L(n), получаем оптимальное значение количества основных лексем. Нисходящий алгоритм формирования ЛС-компонен-тов. Алгоритм формирования ЛС-компонентов состоит из следующих фаз: 1. Подготовка ИТБ. 1.1. Для каждой лексемы ИТБ вычисляется значение Li (10). 1.2. ИТБ упорядочивается по убыванию значения Li таким образом, что чем меньше будет порядковый номер лексемы, тем выше вероятность образования на ее основе ЛС-компонента. 1.3. Данные о лексических связях упорядочиваются по убыванию значения qkµik. Тем самым увеличивается вероятность попадания в ЛС-компонент тех связанных лексем, которые более всего могут улучшить качество ИТБ (11). 2. Поиск оптимального количества основных лексем. 2.1. Осуществляется перебор возможного количества основных лексем k от 1 до объема ИТБ (возможно сужение разработчиком интервала поиска). 2.2. Для текущего значения k определяются основные лексемы (k первых лексем ИТБ). 2.3. Для выбранных основных лексем определяются связанные лексемы (как правило, задается максимум количества связанных лексем). 2.4. Подсчитывается значение функции качества (11). 2.5. Если перебор окончен, то переход к п. 2.6, если иначе, то возврат к п. 2.1. 2.6. Определяется максимум функции качества (оптимальное число основных лексем kmax). 3. Формирование ИТБ как совокупности ЛС-компо-нентов. Искомый ИТБ получается при выполнении пп. 2.2 и 2.3 для kmax основных лексем. Алгоритмы представленного выше вида будем называть нисходящими (Н-алгоритмы), так как определение связанных лексем (см. п. 2.3) происходит непосредственно из свойств текущей основной лексемы (см. п. 2.2), т. е. сверху вниз. Приведем пример работы такого алгоритма. Настраиваемые параметры базиса: – объем базиса в терминах (1 000); – максимальное количество связей на одну лексему (10); – максимальное значение абсолютной частоты лексем (100/50 000); – максимальное значение частоты сочетаний лексем (20/50 000); – объем материала, по которому произведен частотный анализ (50 000); – коэффициент связанности лексем (1). Тестирование Н-алгоритма дает следующие результаты: – максимум L(n), равный 0,496 118 565 143 325, приходится на 188 основных лексем; – количество итераций – 4 981 096; – время исполнения – 3,41 с; – количество элементов, не задействованных в ЛС-ком-понентах, – 320. Таким образом, в данной статье рассмотрена проблема информационной поддержки ЛСК-методики: поставлена и решена задача формирования ИТБ как совокупности ЛС-компонентов; выработаны критерий для выделения основных лексем ИТБ и функция качества построения ИТБ; разработаны общие принципы решения поставленной задачи, реализованные в нисходящем алгоритме формирования ЛС-компонентов, применение которого к ИТБ является ее частным решением.
