Формирование весовых коэффициентов методик отбора для регрессионного тестирования

Автор: Зарубин И.Б., Филинских А.Д.
Рубрика: Управление сложными системами
Статья в выпуске: 4, 2025 года.
Бесплатный доступ
В статье рассмотрены способы ранжирования и группировки тестов для формирования тестовых наборов при проведении регрессионного тестирования: по приоритету, длительности выполнения, предыдущему результату, общему количеству найденных ошибок, сроку выполнения, приоритету микросервиса, объему внесенных в микросервис изменений, наличию модификаций в смежных сервисах. Предложен подход, позволяющий формировать актуальные значения весовых коэффициентов для каждого из способов отбора и ранжирования тестов с получением результирующего тестового набора, чтобы тесты, которые позволят обнаружить наиболее важные ошибки в информационной системе, находились в верхней половине списка. Описаны способы применения подхода формирования значений весовых коэффициентов для двух систем управления тестированием. Рассмотрен пример использования предложенного подхода при формировании ранжированного списка тестов для регрессионного тестирования реальной микросервисной информационной системы с использованием автоматизированной системы ранжирования тестов, которая произвольное количество способов ранжирования позволяет подключить к современным системам управления тестированием. Приведены графики потери актуальности весовых коэффициентов и появления пропущенных дефектов в зависимости от полноты выполнения тестового набора.
Регрессионное тестирование, отбор тестов для регрессионного тестирования, ранжирование тестов для регрессионного тестирования, методики формирования тестового набора
Короткий адрес: https://sciup.org/148332826
IDR: 148332826 | УДК: 004.054 | DOI: 10.18137/RNU.V9187.25.04.P.24
Formation of Weighting Coefficients for Selection Methods for Regression Testing
The article discusses methods for ranking and grouping tests to form test suites during regression testing: by priority, execution duration, previous result, total number of detected errors, deadline, microservice priority, volume of changes made to the microservice, and the presence of modifications in related services. An approach is proposed for generating relevant weighting coefficients for each test selection and ranking method, resulting in a resulting test suite, so that tests capable of detecting the most important errors in an information system are located in the top half of the list. Application methods for generating weighting coefficient values for two test management systems are described. An example of using the proposed approach to forming a ranked list of tests for regression testing of a real microservice information system is considered using an automated test ranking system, which allows any number of ranking methods to be connected to modern test management systems. Graphs are provided for depreciation of weighting coefficients and the appearance of missed defects depending on the completeness of the test suite execution.
Текст научной статьи Формирование весовых коэффициентов методик отбора для регрессионного тестирования
В настоящее время потребность человечества в различных информационных системах (далее – ИС) весьма велика – ИС позволяют значительно упростить и ускорить практически все процессы, которые происходят в человеческом обществе. Широкое использование ИС в жизнедеятельности человека – от визуализации сложных географических показателей, например, составления этнографической карты России, до создания интерактивных и доступных образовательных платформ [1–3] – накладывает высокие требования на корректность работы ИС: компании-разработчики тратят значительное количество ресурсов на проверку качества и поиск ошибок на всех этапах жизненного цикла разработки ИС [4]. При этом желание снизить издержки в процессе разработки ИС зачастую приводит к необходимости исключения некоторых важных процедур или уменьшению длительности их проведения.
Важнейшим этапом в процессе разработки ИС, который позволяет определить готовность ИС к передаче заказчику или конечному пользователю, является тестирование [2]. Главными задачами тестирования можно назвать поиск ошибок [3] и проверку соответствия поведения разрабатываемой ИС ожиданиям конечного потребителя.
Для эффективного поиска ошибок применяется значительное количество подходов тестирования, например, модульное тестирование [4], интеграционное [5], нагрузочное [6], тестирование удобства использования [7] и др. В силу применения итерационных подходов к разработке ИС, таких как Scrum [8], Kanban [9] или экстремальное программирование [10], некоторые виды тестирования также должны выполняться регулярно. Применение всего доступного инструментария по тестированию ИС часто осложняется крайне сжатыми сроками разработки, недостаточной квалификацией инженеров по те-
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
стированию, а также сложными правилами взаимодействия сервисов при использовании микросервисной архитектуры ИС [11]. Сложный механизм влияния сервисов друг на друга значительно усложняет процедуру формирования наборов тестов. Как правило, тестами покрывают непосредственные изменения кода ИС, при этом понять опосредованное влияние модификаций кода того или иного микросервиса на другие микросервисы, которые не подвергались модификациям, бывает крайне непросто.
Вид тестирования, который призван обнаруживать ошибки в микросервисах и блоках кода, которые не подвергались модификациям, но могли утратить корректность работы вследствие модификации смежных структур кода, называется регрессионным тестированием (далее – РТ) [12]. Основные задачи, которые решаются при формировании пула тестов РТ, – отбор, минимизация и приоритизация [13].
Процесс разработки ИС со сложной бизнес-логикой и большим количеством интеграций со смежными ИС может занимать значительное время, в течение которого необходимо поддерживать реализованный функционал в актуальном состоянии. Количество тестов для РТ увеличивается с течением времени при добавлении нового функционала, что может привести к необходимости выделения количества ресурсов для РТ, превосходящих наложенные на команду разработки ограничения. В случае чрезмерного количества регрессионных тестов, отобранных для проверки состояния компонентов ИС, возможно, косвенно затронутых внесенными изменениями, необходимо производить ранжирование набора РТ, то есть решить задачу приоритизации. При наличии ранжированного списка тестов для РТ присутствует возможность обнаружения ошибок более высокого приоритета в более короткие сроки, что, в свою очередь, позволит снизить издержки на исправление найденных ошибок и подготовку ИС к промышленной эксплуатации. Для ранжирования тестов необходимо вычислить значимость каждого теста (далее – ЗТ) на основании некоторых признаков и значений метаданных тестов, следовательно, необходимо описать доступные принципы приоритизации тестового набора и сформировать рекомендации по их применению.
В процессе разработки сценариев для РТ в тест добавляется вспомогательная информация, которая в дальнейшем используется для группировки и ранжирования тестового набора. Метаданные тестов, которые впоследствии используются для ранжирования набора РТ, относятся к следующим категориям.
Приоритет теста. В процессе разработки и пересмотра теста назначается или актуализируется приоритет теста. В подавляющем большинстве систем управления тестированием приоритета теста выбирается один из трех или пяти уровней: высокий, средний и низкий или высший, высокий, средний, низкий и низший соответственно.
Высший приоритет имеют тесты, которые непосредственно проверяют важнейший целевой функционал разрабатываемой ИС: включение/выключение устройства, подключение к точке доступа Wi-Fi смартфона, вход в аккаунт интернет-магазина, отображение мультимедийной информации смарт-телевизора и др. Возникновение ошибки в тесте с высшим приоритетом приводит к невозможности использования ИС или устройства. Возвращение функционала возможно только путем перезагрузки устройства или ИС.
Высокий приоритет имеют тесты, которые проверяют важный целевой функционал ИС: корректная работа смартфона с различными профилями Bluetooth, стабильная работа устройства в течение целевого времени, отображение специфических данных для опре-
Формирование весовых коэффициентов методик отбора для регрессионного тестирования деленного пользователя в интернет-магазине, получение корректного перечня доступных каналов смарт-телевизора и др. Возникновение ошибки в таком тесте приводит к утере ИС или устройством важного функционала с возможностью использования этого функционала каким-либо обходным путем.
Средний приоритет назначается тестам, которые покрывают незначительные возможности ИС или устройства: определенное количество сохраненных Bluetooth устройств, определенные характеристики работы устройства, вспомогательная информация в личном кабинете интернет-магазина, особенности структуры меню смарт-телевизора и др. Возникновение ошибки в тесте со средним приоритетом не приводит к утере возможностей ИС или устройства и вызывает лишь неудобство в использовании, а утерянный функционал может быть получен некоторыми обходными путями.
Низкий приоритет назначается тестам, которые покрывают визуальную составляющую или также вспомогательные возможности ИС или устройства, которые не относятся к базовым сценариям использования тестируемого объекта. Возникновение ошибки в тесте с низким приоритетом никак не влияет на функциональность и потребительские свойства ИС или устройства.
Низший приоритет назначается тестам, которые относятся к особенностям ИС или устройства, которые не могут быть замечены пользователем и не оказывают никакого влияния на функционал тестируемого объекта.
Когда применяется приоритизация тестовых сценариев из трех уровней, принципы назначения высшего и высокого приоритета и низкого и низшего приоритета объединяются.
Отбор сценариев для РТ по приоритету может быть выполнен с помощью стандартных средств систем управления тестированием (TMS), как это показано на Рисунках 1 и 2.
Add Criteria: (1) v
Priority: High v X
Reset
О P Key Version Name* Status Estimated R
-
□ P SQM-T784 1.0 - [Политики] Создание кроссплатформенных скрытых политик Wink уров...
‘ О Р SQM-T973 1.0 * (Политики] Создание политики по Radius с агрегацией по Количеству a... зот
-
□ Р SQM-T972 1.0 * [Политики] Создание политики по Radius с агрегацией по Количеству a... (£23 30m
О Р SQM-T974 1.0 * (Политики] Создание политики по Radius с агрегацией по Количеству и/... 30m
О Р SQM-T968 1.0 * [Политики] Создание политики по Vb с агрегацией по Количеству mcast... 2h
О Р SQM-T414 1.0 * (Политики] Создание политики по Топологии
О Р SQM-T148 1.0 * [Политики] ШПД (RADIUS) политики - Создание политики(£23
Рисунок 1. Отбор тестов по приоритету в TMS Zephyr Источник: здесь и далее рисунки выполнены авторами.
Ранжировать отобранные тесты можно простой сортировкой полученного списка по столбцу «Приоритет».
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
Фильтр
Рисунок 2. Отбор тестов по приоритету в TMS TestIT
Длительность выполнения теста. Очевидно, что при прочих равных параметрах и метаданных теста предпочтительно выполнять более короткие тесты. Таким образом, за единицу рабочего времени будет выполнено большее количество проверок, что позволит быстрее сделать вывод о корректности работы ИС или быстрее обнаружить ошибки. Кроме того, в случае недостаточных ресурсов для выполнения всего перечня сценариев РТ большее количество выполненных тестов позволит точнее понять степень готовности разрабатываемой ИС к промышленной эксплуатации. Примерная длительность теста назначается в процессе разработки теста, а впоследствии уточняется при выполнении и пересмотре. Длительность теста не учитывает время исследования найденной проблемы и время создания описания ошибки.
В зависимости от специфики проекта ориентировочное время выполнения теста может меняться в широком диапазоне, например, от пяти минут до одного часа и более. В таких случаях необходимо группировать длительности теста (например, не более пяти минут, не более десяти минут, не более двадцати минут) и в зависимости от длительности теста производить ранжирование пула тестов.
Отбор тестов в зависимости от длительности выполнения также может быть выполнен стандартными средствами некоторых систем TMS (см. Рисунки 3 и 4).
Рисунок 3. Отбор тестов по длительности выполнения в Zephyr
Формирование весовых коэффициентов методик отбора для регрессионного тестирования
Рисунок 4. Отбор тестов по длительности выполнения в TestIT
Негативный результат предыдущего выполнения. Простой и при этом надежный подход, позволяющий обнаруживать ошибки при выполнении РТ. Это тест, который, как правило, позволяет определить корректность исправления ошибки или внесение другой ошибки в попытке исправить исходную ошибку. Информация о результатах предыдущего выполнения данного теста легкодоступна как при использовании систем управления тестированием, так и при работе с тестовыми наборами в виде электронных таблиц. Однако наиболее популярные в настоящее время системы TMS, такие как TestIt, Zephyr, TestLink, DoQA, не имеют соответствующих фильтров и, соответственно, данный подход при формировании пула РТ используется только в ручном режиме – поэлементным добавлением подходящих тестов.
Общее количество найденных ошибок. Очевидно, что сценарий РТ, с помощью которого было обнаружено много ошибок, представляет большую значимость с точки зрения подтверждения корректного функционирования ИС. К сожалению, в современных системах TMS возможность фильтрации тестов по количеству найденных ранее ошибок отсутствует, и указанный признак может быть использован для ранжирования только добавлением и поддержкой соответствующей информации в метаданных теста.
Срок предыдущего выполнения. В силу недостатка ресурсов для выполнения всего доступного пула РТ некоторые сценарии могут не выполняться длительное время. При этом необходимо понимать, что в зависимости от специфики разрабатываемой ИС и процессов, принятых в компании-разработчике, периоды между циклами РТ могут быть весьма значительными. Поэтому более корректно выполнять отбор и ранжирование сценариев РТ не в абсолютных временных отрезках, а в циклах РТ, в рамках которых данный сценарий не выполнялся. Данный подход также не может быть применен при использовании стандартных средств систем TMS.
Приоритет микросервиса. При использовании микросервисной архитектуры разрабатываемой ИС важно учитывать, какой микросервис покрывает данный тест. Эту информацию можно указывать как в специальных полях сущности теста, так и в полях, которые могут содержать в себе любую вспомогательную информацию, например, в поле «Тэги» или Label. Используя фильтрацию по данным полям, можно также отбирать соответствующие сценарии стандартными средствами систем TMS.
Однако в подавляющем большинстве случаев каждый сценарий покрывает не один, а несколько микросервисов, при этом степень их участия может сильно разниться. Для этого, например, можно использовать специфические тэги с указанием степени покрытия сцена-
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
рием тех или иных микросервисов или создать специальные поля сущности «тест для хранения соответствующей информации». Степень покрытия сценарием нескольких микросервисов не может быть отфильтрована и ранжирована стандартными средствами TMS.
Объем внесенных изменений в микросервис. Объем внесенных изменений в существующий микросервис является маркером, показывающим степень риска, которую влекут модификации кода. Абсолютные значения модифицированных строк малополезны, при этом, оценивая процент модифицированных, удаленных и добавленных строк, можно сделать вывод о степени модификации того или иного микросервиса. При ранжировании сценариев по степени модификации микросервиса необходимо учитывать специфику разрабатываемой ИС, а также средний процент модифицированных строк. Ранжирование по объему внесенных изменений использует ранжирование по приоритету сервиса или фильтрацию тестов по названию микросервиса.
Стандартные системы TMS не позволяют выполнять отбор и ранжирование сценариев РТ по объему внесенных изменений в силу отсутствия достаточной степени интеграции с системами разработки и контроля версий.
Модификация смежных микросервисов первого, второго уровня. В микросервисных ИС взаимодействие микросервисов между собой позволяет решить вопросы упрощения разработки каждого отдельного микросервиса. При этом большое количество микросервисов может значительно усложнить выявление степени влияния внесенного изменения в один из микросервисов на взаимодействующие с ним микросервисы (Рисунок 5). Количество микросервисов и степень их интеграции зависит от специфики разрабатываемой ИС.
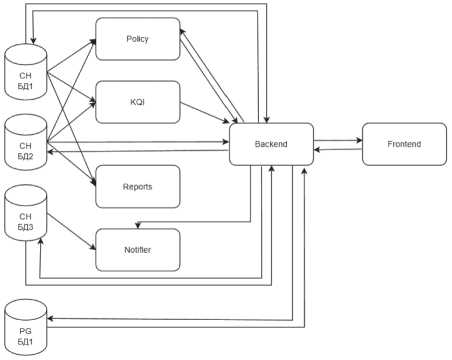
Рисунок 5. Схема взаимосвязей микросервисной ИС с учетом направления взаимодействий
Из архитектуры микросервисной ИС можно определить, на какие смежные микросервисы может оказать влияние модификация того или иного микросервиса. С точки зрения формирования метаданных для сценариев РТ для учета архитектуры ИС добавляется соответствующая информация в дополнительные поля сущности теста в системы TMS, что позволяет отбирать тесты, проверяющие микросервисы первого, второго и последующих уровней смежности.
Формирование весовых коэффициентов методик отбора для регрессионного тестирования
Применение методик отбора по отдельности для всего пула регрессионных тестов не представляет сложной задачи. При этом очевидно, что одновременное применение нескольких методик отбора даже при использовании современных систем TMS крайне затруднительно – не все подходы отбора и ранжирования могут быть реализованы через фильтрацию. Кроме того, ранжирование пула тестов предполагает возможность определения (установки) ЗТ с точки зрения использующихся при отборе и ранжировании тестов [14].
Значимость отдельного теста может быть вычислена по формуле
It = 11 + I2 +••• + In , где It – итоговая значимость теста; I1 – значимость теста, найденная способом 1; I2 – значимость теста, найденная способом 2; In– значимость теста, найденная способом n.
Результаты экспериментов
Когда пул РТ состоит из значительного количества тестов, вычисление ЗТ можно выполнить с помощью разработанной автором автоматизированной «Системы отбора регрессионных тестов» [15], которая позволяет получать полный набор параметров и метаданных каждого сценария РТ и гибко настраивать используемые подходы к ранжированию пула РТ, а также значения весов для того или иного подхода (см. Рисунок 6).
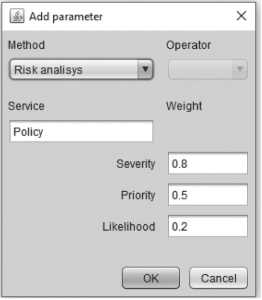
Рисунок 6. Конфигурирование параметров ранжирования пула РТ
Результатом работы системы отбора регрессионных тестов является ранжированный в порядке убывания ЗТ список РТ. Сценарии РТ выполняются в порядке убывания ЗТ. В зависимости от специфики процессов разработки ИС может быть установлен порог ЗТ, при котором тесты, имеющие ЗТ ниже этого порога, выполнять не нужно (см. Рисунок 7).
Значимость теста в зависимости от подхода ранжирования не может быть универсальной величиной, подходящей для ИС любой специфики и сферы применения.
Руководствуясь общими предположениями, определить весовое значение для каждой ЗТ не представляется возможным в силу специфики каждой ИС, процессов и подходов, которые применяются в процессе разработки данной ИС. Для получения значений применительно к конкретной ИС предлагается выполнить максимально возможный перечень сценариев для РТ, получив, таким образом, пул РТ с информацией об ошибках, найденных каждым сценарием. Далее необходимо подобрать значения весовых коэффициентов для каждого подхода ранжирования тестов таким образом, чтобы тесты, с помощью
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
которых были найдены ошибки, были в начале списка. В зависимости от специфики процессов разработки и наличия ресурсов для выполнения пула РТ можно выбрать значения весовых коэффициентов таким образом, чтобы тесты, позволившие обнаружить ошибки, находились в перечне первых 50 или 25 % тестов, или же использовать абсолютное количество сценариев.
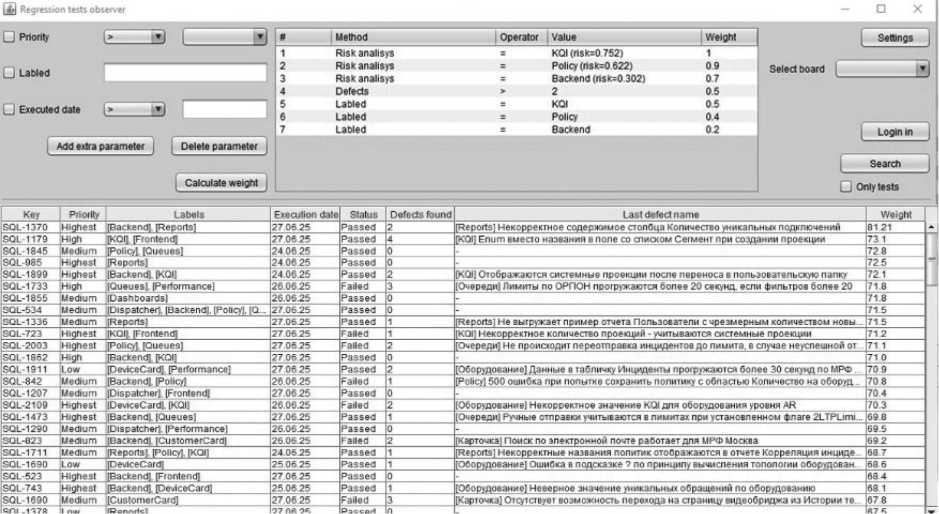
Рисунок 7. Общий вид ИС по ранжированию тестов для РТ
Указанный подход был применен для формирования наборов тестов для РТ в процессе разработки ИС по контролю качества передаваемого мультимедийного сигнала цифрового телевидения и широкополосного доступа в сеть Интернет крупного российского оператора. Архитектура ИС содержит более 180 микросервисов. Общее количество строк кода составляет более 10 млн. Выпуск новых версий происходит в среднем один раз в два месяца. Общее количество сценариев РТ – около 2 тыс. В результате получены следующие значения весовых коэффициентов:
-
• приоритет теста (см. Таблицу 1);
-
• длительность выполнения теста (см. Таблицу 2);
-
• негативный результат предыдущего выполнения, значение весового коэффициента 0,8;
-
• общее количество найденных ошибок (см. Таблицу 3);
-
• период предыдущего выполнения (см. Таблицу 4);
-
• приоритет микросервиса (см. Таблицу 5);
-
• объем внесенных изменений в микросервис (см. Таблицу 6);
-
• модификация смежных микросервисов первого, второго уровня в случае наличия модификаций смежных микросервисов первого или второго уровня – значение весовых коэффициентов, которые покрывают данный микросервис, 0,2.
Формирование весовых коэффициентов методик отбора для регрессионного тестирования
Таблица 1
Значения весовых коэффициентов в зависимости от приоритета теста
|
Приоритет теста |
Высокий |
Средний |
Низкий |
|
Весовой коэффициент |
0,9 |
0,5 |
0,2 |
Источник: здесь и далее таблицы выполнены авторами .
Таблица 2
Значения весовых коэффициентов в зависимости от приоритета теста
|
Длительность теста, мин |
≤5 |
>5≤10 |
>10≤20 |
>20≤30 |
>30 |
|
Весовой коэффициент |
0,8 |
0,7 |
0,6 |
0,4 |
0,2 |
Таблица 3
Значения весовых коэффициентов в зависимости от количества найденных ошибок
|
Количество найденных ошибок |
0 |
1 |
2 |
3-4 |
>4 |
|
Весовой коэффициент |
0 |
0,3 |
0,5 |
0,7 |
1 |
Таблица 4
Значения весовых коэффициентов в зависимости от периода предыдущего выполнения
|
Период от предыдущего выполнения теста (в количестве циклов РТ) |
1 |
2 |
3-4 |
5-7 |
>7 |
|
Весовой коэффициент |
0 |
0,1 |
0,2 |
0,4 |
0,6 |
Таблица 5
Значения весовых коэффициентов в зависимости от приоритета микросервиса
|
Название микросервиса |
Backend |
PolicyEngine |
KQI |
Audit |
WinkComposer |
Прочие |
|
Весовой коэффициент |
0,8 |
0,9 |
0,3 |
0,2 |
0,6 |
0 |
Таблица 6
Значения весовых коэффициентов в зависимости от объема внесенных изменений
|
Процент внесенных изменений, % |
<0,1 |
<0,5 |
<1 |
<3 |
<5 |
>=5 |
|
Весовой коэффициент |
0 |
0,2 |
0,4 |
0,6 |
0,8 |
1 |
На основании приведенных весовых коэффициентов формировался пул тестов объемом 25 % от полного набора сценариев для РТ. Исследования показали, что для данной ИС актуальность выбранных весовых коэффициентов снижается с каждым новым запуском выполнения РТ в силу внесенных модификаций, новых микросервисов, изменения архитектуры взаимодействия микросервисов и др. Для 25 % тестов с высшей ЗТ актуальность выбранных весовых коэффициентов составляет три запуска выполнения РТ, для 50 % – пять запусков (см. Рисунок 8).
Потеря актуальности весовых коэффициентов приводит к появлению пропущенных во время проведения РТ ошибок, то есть ошибки покрыты тестами, не входящими в вы-
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
борку. В зависимости от принятых пределов допустимого количества известных ошибок в передаваемой заказчику версии ИС количество циклов выполнения РТ без уточнения весовых коэффициентов может быть увеличено. Уточнение значений весовых коэффициентов производится путем выполнения всего пула РТ в совокупности с анализом пропущенных дефектов (Escaped Defect Analysis – EDA).
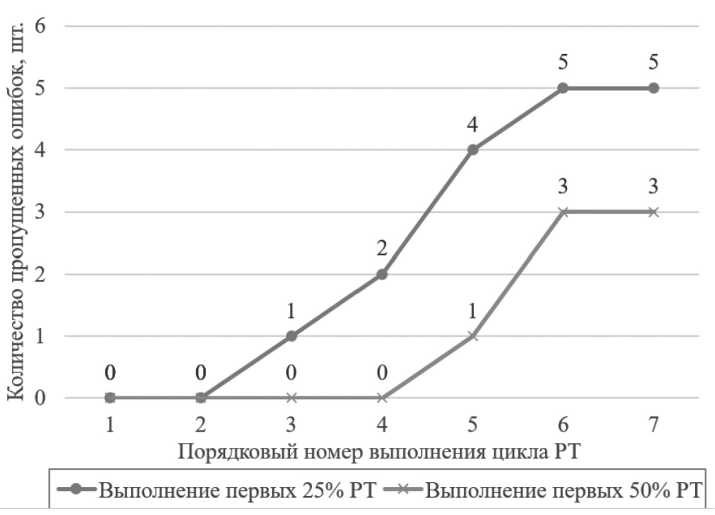
Рисунок 8. Динамика возникновения пропущенных дефектов при потере актуальности весовых коэффициентов
Представленная методика позволяет формировать весовые коэффициенты для выбранных подходов к отбору и минимизации пула тестов для РТ таким образом, чтобы при формировании ранжированного списка сценариев тесты, которые помогут обнаружить ошибки или подтвердить корректность работы значимого функционала ИС, находились вверху списка. Это позволит получать ошибки в более сжатые сроки и выполнить меньшее количество тестов для определения корректности работы разрабатываемой ИС, что, в свою очередь, приводит к экономии ресурсов в процессах разработки ИС. Количество сценариев, достаточных для вынесения вердикта о готовности ИС к промышленной эксплуатации, зависит от специфики разрабатываемой ИС и процедур, принятых в компании – разработчике ИС.
Необходимо отметить, что предложенная методика формирования весовых коэффициентов требовательна к корректному формированию метаданных сценариев РТ, а также может быть применена только в совокупном использовании с автоматизированными системами ранжирования тестов для РТ.
