Генерация мимики для виртуальных ассистентов

Автор: Корзун В.А.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 3 (55) т.14, 2022 года.
Бесплатный доступ
Развитие виртуальных помощников делает их все более востребованными в повседневной жизни, однако они взаимодействуют с человеком, в основном, с помощью текста или аудио. Создание для них визуального образа позволит сделать взаимодействие с ними более увлекательным, но тогда возникает необходимость создания реалистичных движений, в частности мимики, согласующуюся с речью. В данной работе предлагается система автоматической генерации лицевой анимации по аудио. Предлагаемый подход обладает быстрым временем работы и не требует значительных вычислительных ресурсов. Также в ходе работы были обнаружены различные свойства восприятия человеком говорящей головы, позволяющие избавиться от эффекта «зловещей долины» и сделать автоматическую анимацию более реалистичной.
Синхронизация губ, нейронные сети, лицевая анимация, виртуальные ассистенты
Короткий адрес: https://sciup.org/142236478
IDR: 142236478 | УДК: 004.946
Facial expressions generation for virtual assistants
The current progress of virtual assistantants makes them useful in everyday life. However they interact with human mostly through text or audio. Giving them a visual form makes interaction with them more amusing. Therefore there is the need to create realistic movements in particular facial expressions consistent with speech. This paper proposes a system of automatic facial animation from audio. The proposed approach has a fast running time and does not require significant computing resources. Also, we discover some properties of the human perception of the talking head. Thus, we are able to overcome the uncanny valley effect and makes automatic animation more realistic.
Текст научной статьи Генерация мимики для виртуальных ассистентов
Анимирирование трехмерных персонажей достаточно трудоемкий процесс, например, в мультипликации это делается вручную, с помощью манипуляций над управляющими элементами модели. В компьютерных играх анимация лиц людей делается в основном с помощью захвата, движений реального актера. Точный захват движений требует дорогостоящего оборудования, а. также его настройки и позиционирования. Однако не всегда, требуется полное копирование реальных движений лица, например, в больших ролевых играх достаточно, чтобы персонажи воспроизводили основные фонемы. Отсюда, возникает потребность в автоматической генерации подобной анимации. Также из-за. развития диалоговых агентов и систем синтеза, речи появляется все больше виртуальных ассистентов, например помощники в банковских приложениях или же универсальный помощник «Алиса» от Яндекса.
«Московский физико-технический институт (национальный исследовательский университет)», 2022
У некоторых подобных помощников, например у Replika, уже появился визуальный образ, хотя его движения еще недостаточно реалистичны и возникает эффект так называемой «зловещей долины». Поэтому задача генерации мимики для трехмерных персонажей на основе речи начинает быть все более востребованной.
На сегодняшний день уже существует несколько подходов для автоматической генерации лицевой анимации по аудио. Основным в индустрии является прямое отображение фонем в виземы (от видимой фонемы) с последующей пост-обработкой коартикуляции. Последней работой, развивающей данный подход, является виземная модель JALI [1], в которой помимо предложений по разрешению коартикуляции было предложено использовать дополнительные параметры, отвечающие за степень артикуляции челюсти и губ. Основная идея использования подобных параметров заключается в том, что одним фонемам могут соответствовать различные виземы, зависящие от тембра речи, например при бормотании или шепоте степень артикуляции будет сильно отличаться от таковой при нормальной речи или даже экспрессивной. Предложенная модель зарекомендовала себя и была использована при локализации Cyberpunk2077. Основными ограничениями своего подхода авторы называют отсутствие адаптации под синтетическую речь и требование к качественному выравниванию фонем. Также для данного подхода используется проприетарная модель лица, что также накладывает свои ограничения.
Другим подходом является генерация последовательностей полигональных сеток (ме-шей) лица с помощью глубоких нейронных сетей. Самым распространенным считается модель, предложенная NVIDIA [2], которая по аудио предсказывает положения вершин меша фиксированной топологии. Помимо аудио модель также принимает на вход обучаемый вектор представления эмоционального состояния, который позволяет манипулировать выражением говорящей головы, делая мимику более веселой, злой или грустной. Для обучения своей модели авторы используют несколько минут высококачественного захвата движений с одного актера, поэтому генерируемые меши относятся к одному лицу, что накладывает ограничения на использование данного подхода. Также для запуска этой модели в реальном времени требуется достаточно мощные графические ускорители.
В данной же работе предлагается система генерации мимики по аудио, включая синхронизацию движений губ, ритмичные движения головы, а также другие мимические движения. Предлагаемая система предназначена в основном для «оживления» виртуальных ассистентов, поэтому работает и с синтетическими голосами. Также подход не требует специализированного оборудования и может запускаться на ноутбуке, хотя и поддерживает масштабирование. Полный цикл генерации анимации занимает меньше времени, чем длина входной аудиодорожки, что позволяет при доработке использовать систему в реальном времени.
2. Нейросетевая синхронизация движений губ
Предлагаемый подход состоит из нескольких частей, отвечающих за различные мимические движения. Для синхронизации движений губ с речью используется отдельная нейросетевая модель. В трехмерной графике для представления различных выражений лица используются морфы или блендшейпы [3], с помощью которых любое выражение лица можно представить как линейную комбинацию базовых форм с некоторыми коэффициентами. Поэтому задача генерации анимации губ сводится к отображению последовательности аудиопризнаков {aj}jei,v • о» € R” в последовательность соответствующих векторов коэффициентов {wj }jei,M,Wj € [0,1]m.
В качестве представления аудио используются выходы модели Wav2Vec2.0 [4], обученной для русского языка. Используемые признаки не зависят от тембра голоса и содержат информацию о мофремах, что позволяет использовать их независимо от спикера. Для предсказания вектора коэффициентов блендшейпов используется окно аудиопризнаков, соответствующее 180 миллисекундам исходной аудиодорожки. Сама же модель генерации представляет собой рекуррентную сеть, кодирующую окно аудиопризнаков в один вектор, с последующим линейным слоем, предсказывающим вектор коэффициентов по извлеченному представлению. Последователвноств полученных векторов коэффициентов дополнительно сглаживается для получения стабильной анимации.
Помимо предложенной выше модели, были опробованы другие модели генератора и представления аудио, а также предложен способ оценки качества лицевой анимации [5], согласно которому предложенная выше модель лучше всего показала себя на синтетическом голосе.
3. Генерация движений головы
Помимо синхронизации губ на восприятие также влияют движения головы, поддерживающие ритм речи. В методе [6], предложенном для «оживления» изображений по аудио, представлена также модель для генерации поз головы, согласующихся с ритмом речи. Поза головы представляется вектором размерности 6: 3 отвечают за трехмерную позицию головы в пространстве и 3 - за ее поворот относительно нейтрального положения. Собственно угол поворота можно перенести на шейную кость трехмерной модели.
Однако генерируемая последовательность поворотов имеет частоту 25 кадров в секунду, в то время как последовательность блендшейпов губ - 30. Также при переносе генерируемых поворотов наблюдается отсутствие плавности анимации. Для решения упомянутых выше проблем было решено дублировать каждый пятый кадр и дополнительно сглаживать последовательность как это было сделано для анимации губ. В итоге движения головы трехмерной модели получаются плавными, но также соответствуют ритму речи.
Используемый генератор поз основан на авторегрессионном подходе: для генерации следующей позы используется предыдущая. Для получения первой позы используется глубокая сверточная нейронная сеть, извлекающая признаки из исходного изображения, которое задает начальные условия. Однако в нашем случае предполагается, что начальные условия будут одинаковыми, что позволит облегчить систему. Для этого упомянутая нейронная сеть заменяется на ее выход, полученный на одном изображении в нейтральной позе. В табл. 1 указаны размеры облегченной модели по сравнению с оригинальной, а также средняя скорость инференса за 100 прогонов на тестовой дорожки длиной 22 секунды.
Таблица!
Сравнение облегченной и оригинальной моделей генерации поз
|
Размер, мб |
Средняя скорость инференса, мс |
|
|
Оригинальная модель |
176,9 |
34.16 |
|
Облегченная модель |
91 |
31.3 |
Хоть выигрыш в скорости оказался не столь существенным, удалось сократить размер модели почти в два раза.
4. Другие мимические движения
После добавления генерации поз головы, возникла новая проблема в восприятии получаемых движений. Дело в том, что во время речевого акта человек, в основном, смотрит на собеседника вне зависимости от положения головы. Текущая же система это не учитывает, и направление взгляда следует за положением головы, что выглядит неправдоподобно. Однако современные средства трехмерного моделирования позволяют манипулировать поведением трехмерной модели. Например, можно задать правило, согласно которому направление взгляда будет всегда направлено в одну точку. После ограничения направления взгляда модели на камере, получаемые движения выглядят более реалистично, однако до сих по наблюдается некоторый диссонанс.
Оказывается [7], глаза человека постоянно совершают микроскопические движения -саккады. Таким образом, происходит «сканирование» объектов и получение их полного образа. Саккады возможно моделировать, однако в мимике человека присутствуют другие движения, например бровей. Поэтому было решено записать движения с человека и совместить их с генерируемыми движениями губ, и головы. Это делается довольно просто, так как за различные части лица отвечают различные группы блендшейпов, поэтому во время анимации блендшейпы, отвечающие за движения губ, берутся из сгенерированной последовательности, а другие - из записанной. Таким образом, получается реалистичная анимация головы трехмерного персонажа во время речевого акта.
5. Архитектура системы
Далее рассмотрим реализацию итоговой системы генерации мимики. Сама система представляет собой http-сервис, реализованный на фреймворке TorchServe. Данный фреймворк позволяет развертывать нейросетевые модели и их ансамбли на различных конфигурациях вычислительных машин. На рис. 1 изображена схема полученной системы.
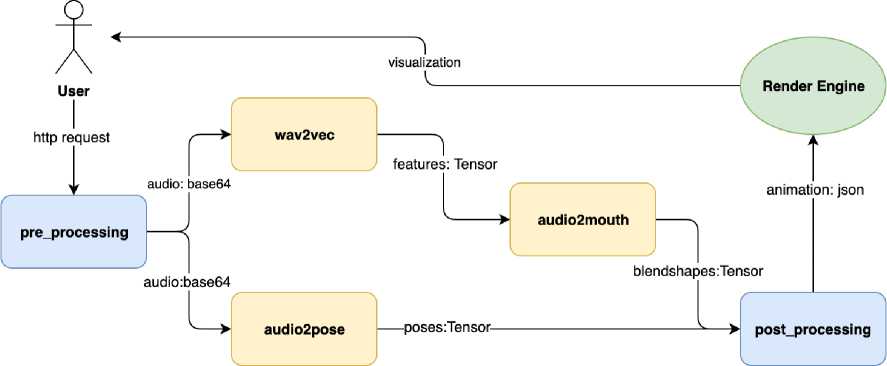
Рис. 1. Схема, системы генерации мимики
Приведенная система, состоит из нескольких основных модулей:
• pre processing - входная точка, пайплайна, принимает запрос от пользователя, из-вл екает аудио и передает дальше.
• wav2vec - модуль wav2vec, извлекает признаки из аудио и возвращает их в виде тензора. PyTorch.
• audio2mouth - модуль генерации мимики губ, принимает аудиопризнаки от wav2vec, конструирует из них окна, для параллельной обработки, прогоняет модель и возвращает последовательность коэффициентов блендшейпов с частотой, равной частоте wav2vec (49.86 кадров в секунду) в виде тензора.
• audio2pose - модуль генерации поз, извлекает признаки из входящего аудио, прогоняет модель и возвращает последовательность поз с частотой 25 кадров в секунду в виде тензора.
• post processing - выходная точка, пайплайна, принимает выходы генераторов, изменяет их частоту, накладывает фильтры сглаживания и запаковывает в json-файл с итоговой анимацией.
6. Заключение
Render Engine не является частью пайплайна. TorchServe, однако в нем находится логика, движений глаз и объединения сгенерированной и записанной анимаций. В качестве такой системы используется Blender, хотя можно использовать и другие, например
При всех замерах для каждой дорожки проводилось несколько запусков и выбиралась медиана по total. В качестве тестового стенда использовался MacBook Pro (16-inch, 2019), CPU: Intel Core i7 2,6 GHz, RAM: 32 Gb 2667 MHz DDR4- Из таблицы видна линейная зависимость по времени от длины дорожки. Самым «тяжелым» модулем является wav2vec, который занимает большую часть времени обработки запроса. Также стоит заметить, что генерация поз головы занимает больше времени, чем инференс модели, рассмотренный ранее, так как теперь учитывается еще и время обработки аудио и модель работает параллельно с wav2vec. Весь пайплайн генерации примерно в два раза быстрее длины дорожки, что позволяет его использовать в реальном времени без использования значительных вы-числетельных ресурсов. Стоит также уточнить, что для каждого модуля использовалась одна реплика, хотя TorchServe позволяет масштабировать модули независимо и использовать различные виды вычислительных устройств. Например, wav2vec можно развернуть на ГПУ, позволив освободить ресурсы процессора для других модулей, что должно значительно сократить время генерации.
Т а б л и ц а 2
Время обработки дорожек различной длины
|
Модуль Длина дорожки, с |
Время обработки, с |
||||||
|
3.21 |
6.74 |
8.94 |
10.55 |
15.52 |
17.79 |
22.42 |
|
|
pre_processing |
0.002 |
0.004 |
0.005 |
0.005 |
0.006 |
0.06 |
0.007 |
|
wav2vec |
1.68 |
3.624 |
4.704 |
5.461 |
8.838 |
10.341 |
13.51 |
|
audio2mouth |
0.012 |
0.028 |
0.032 |
0.036 |
0.055 |
0.056 |
0.069 |
|
audio2pose |
0.845 |
1.879 |
3.021 |
3.231 |
5.15 |
6.368 |
7.55 |
|
post_processing |
0.018 |
0.024 |
0.025 |
0.027 |
0.03 |
0.033 |
0.038 |
|
total |
1.76 |
3.759 |
4.846 |
6.616 |
9.045 |
10.542 |
13.721 |
В ходе данной работы была создана эффективная система генерации мимики по речи, которая может создавать анимацию быстрее реального времени и не требует значительных вычислительных ресурсов. Однако благодаря выбранному фреймворку система легко масштабируется и все вычисления можно проводить на сервере, а клиенту передавать итоговую анимацию. Также в ходе построения системы были обнаружены различные свойства восприятия человеком говорящей головы. Чтобы избавиться от эффекта «зловещей долины», нужна не только синхронизация движений губ с произносимой речью, а также ритмичные движения головы и другие мелкие мимические движения, такие как саккады. Результаты данной работы могут использоваться для создания визуальных образов для виртуальных помощников, а также для анимирования персонажей в видео-играх.
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 20-31-90051.
Список литературы Генерация мимики для виртуальных ассистентов
- Edwards P., Landreth C., Fiume E., Singh K. Jali: an animator-centric viseme model for expressive lip synchronization // ACM Transactions on graphics (TOG). 2016. V. 35, N 4. P. 1-11.
- Karras T., Aila T., Laine S., Herva A., Lehtinen J. Audio-driven facial animation by joint end-to-end learning of pose and emotion // ACM Transactions on Graphics (TOG). 2017. V. 36, N 4. P. 1-12.
- Lewis J.P., Anjyo K., Rhee T., Zhang M., Pighin F.H., Deng Z. Practice and theory of blendshape facial models // Eurographics (State of the Art Reports). 2014. V. 1, N 8. P. 2.
- Baevski A., Zhou Y., Mohamed A., Auli M. wav2vec 2.0: A framework for self-supervised learning of speech representations // Advances in Neural Information Processing Systems. 2020. V. 33. P. 12449-12460.
- Корзун В., Гадецкий Д., Берзин В. Ильин А. Спикер-независимое предсказание блендшейпов области рта по речи // Компьютерная лингвистика и интеллектуальные технологии. 2022. Т. 21. C. 323-332.
- Wang S., Li L., Ding Y., Fan C., Yu X. Audio2head: Audio-driven one-shot talking-head generation with natural head motion // arXiv preprint arXiv:2107.09293. 2021.
- Gegenfurtner, K.R. The interaction between vision and eye movements // Perception. 2016. V. 45, N 4. P. 1333-1357.
