Greedy heuristic method for location problems

Author: Kazakovtsev L.A., Antamoshkin A.N.
Journal: Сибирский аэрокосмический журнал @vestnik-sibsau
Section: Математика, механика, информатика
Article in issue: 2 т.16, 2015.
Free access
Authors consider multi-source location problems, k-means, k-median and k-medoid. Such problems are popular models in logistics (optimal location of factories, warehouses, transportation hubs etc.) and cluster analysis, approximation theory, estimation theory, image recognition. Various distance metrics and gauges allow using these models for clustering various kinds of data: continuous and discrete numeric data, Boolean vectors, documents. Wide area of application of such problems leads to growing interest of researchers in Russia and worldwide. In this paper, the authors propose a new heuristic method for solving such problems which can be used as a standalone local search method (local search multi-start) or as the main part of a new algorithm based on ideas of the probability changing method. For the parameters self-tuning of such algorithm, the authors propose new meta-heuristic which allows using new algorithm without learning specific features of each solved problem. Algorithms were tested on various data sets of size up to 160000 data vectors from the UCI repository and real data of semiconductor devices examination. For testing purposes, various distance metrics were used. Computational experiments showed the high efficiency of new algorithms in comparison with local search methods used traditionally for the considered problems. In addition, results were compared with the evolutionary methods and a deterministic algorithm based on the Information Bottleneck Clustering method. Such comparison illustrated the ability of new algorithms to reach higher preciseness of the results in reasonable time.
P-медианная задача, p-median, k-медоид, k-medoid, k-средних, k-means, information bottleneck clustering
Short address: https://sciup.org/148177421
IDR: 148177421 | UDC: 519.6
Метод жадных эвристик для задач размещения
Рассматриваются задачи множественного размещения - k-средних, k-медианная и задача k-медоид. Данные задачи находят широкое применение как в качестве логистических моделей оптимального размещения складов, производств, транспортных узлов и т. д., так и опосредованно - в качестве наиболее популярных моделей кластерного анализа, автоматической группировки, теории аппроксимации, теории оценивания, распознавания образов. При этом использование различных метрик расстояния или мер сходства позволяет применять данные задачи в качестве моделей автоматической группировки данных самой разнообразной природы: непрерывных и дискретных числовых данных, векторов булевых значений, документов. Широтой области применения рассматриваемых задач определяется возрастающий интерес к ним со стороны как российских, так и зарубежных исследователей. Предложен новый эвристический метод решения таких задач, который может применяться как в качестве самостоятельного алгоритма локального поиска (мультистарт локального поиска), так и в составе нового алгоритма, использующего идеи метода изменяющихся вероятностей (МИВЕР). Для автоматической настройки параметров алгоритма схемы МИВЕР предложена новая метаэвристика, позволяющая использовать разработанный алгоритм без предварительного анализа особенностей конкретной задачи. Работа алгоритмов протестирована на различных наборах данных размерностью до 160000 векторов данных. В качестве тестовых примеров использованы как типовые наборы данных из репозитория UCI, так и реальные данные отбраковочных испытаний полупроводниковых приборов. При этом были использованы различные метрики расстояния. Эксперименты показывают высокую эффективность новых алгоритмов в сравнении с традиционными для данных задач методами локального поиска. Проведено сравнение новых алгоритмов с некоторыми эволюционными алгоритмами, а также с детерминированным алгоритмом, реализующим метод Information Bottleneck Clustering («информационного бутылочного горлышка»), показана способность новых алгоритмов достигать более высокой точности получаемых результатов за приемлемое время.
Text of the scientific article Greedy heuristic method for location problems
F ( X 1 , ...,X k ) =
= argmin X 1 , Xk 6 R d Z "i min X e { X 1, ..., X k } 11 4 - X I12 .
F ( X i , ..., Xk ) =
-
= argmin X i , ..., X k e R d Z N - 1 w min X e { X i , .... X k } L ( 4- X Y (
Here, w i > 0 are weight coefficients. In the case of k -means problem, all w i = 1.
F ( X 1 , -, X k ) = argmin X 1 , ..., X k { A i , ..., An }X
-
X Z N - 1 w i min X { X 1 , ..., X k } L ( A , X ) .
Known methods. The most commonly used algorithms for solving k -means problem include the ALA procedure (Alternating Location-Allocation) which repeats two simple steps:
Algorithm 1. ALA procedure.
Required: data vectors A 1 … A N , k initial cluster centers X 1 … X k .
-
1. For each center X i , define its cluster C i as the subset of data vectors having closest center X i .
-
2. For each cluster C i , recalculate its center X i :
-
3. Repeat from Step 1 is steps 1, 2 made any changes.
X i = argmin Z wL ( X , Y ) .
X Y e C i
The “classical” k -means method with squared Euclidean distances ( l 22 ) has an important advantage. In this case, new cluster center recalculation is a simplest task solved in a single step. An average (weighted average) value of each coordinate in the cluster is the corresponding coordinate value of the center [1]. If i th cluster center Xi = ( xi ,1, …, xi,d ) is a d -dimensional vector and data vectors A j = ( a i ,i , ..., a j, d ), J = 1, N are also d -dimensional vectors then new center of i th cluster for the k -median problem is [1]:
x i , k = Z y e c i w i y k / Z w,k = 1> d .
If the ALA procedure runs with the rectilinear metric ( l 1 ) then the value of each cluster center coordinate is calculated separately as median (weighted median) value of the corresponding coordinate of data vectors which are cluster members. Such procedure can be described as follows.
Algorithm 2. Calculating i th cluster center (median) with the l 1 metric.
-
1. For each k = 1, d :
-
1.1. Arrange data vectors A i = ( a j . 1, ..., a j d ) e C i in ascending order. Denote such sequence a '1, k , ..., a ' Ci , k . Here Ci is the power of a set.
1.2. Calculate m =
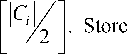
= a ' m , k . Here,
-
square brackets mean integer part.
-
1.3. Repeat 1.
-
2. Return X i = ( x ' 1 ..., x i , d ) .
The result of the ALA procedure depends on selection of the initial centers. Usually, initial centers are selected among data vectors. The k -means++ procedure [12] is preferred in comparison with the chaotic selection of the initial centers. The k -means++ procedure guarantees accuracy O (log( p )). However, such accuracy cannot be acceptable for most practically important problems. In this case, various initial centers recombination techniques are used.
Authors propose many techniques optimizing the ALA procedure: sampling [13] (solving a simplified problem on a randomly selected subset of data vectors and using the result as the initial solution for solving the initial problem), various streaming algorithms for running on big data [14] etc.
Dependence of the ALA and other local search procedures on the given initial data embarrasses the reproducibility of the results: the same data vectors can belong to different clusters or the same cluster depending on chosen initial centers. Thus, problem of developing an algorithm resulting in precise and stable result is needed.
Perfect results of clustering and classification problems can be obtained by using the Information Bottleneck Clustering method (IBC) [15]. Running this algorithm starts with considering each data vector as a separate cluster. Then superfluous clusters are eliminated one by one unless we have k clusters. Each time, this algorithm eliminates the cluster center which gives minimal total distance increase after its elimination. Such algorithms are extremely slow [15]. Genetic algorithms with greedy heuristic [16] use the same principles. However, such algorithms developed initially for solving the k-median problems on a network are compromise methods which allow solving bigger problems. Versions of such algorithms described in article [17] can be used for solving continuous problems. The approach can be described as follows [2].
Algorithm 3. Genetic algorithm with greedy heuristic for k -median problems.
Required: Population size N p .
-
1. Form (randomly with uniform distribution or using the k -means++ procedure) Np different initial solutions X 1 , ..., X Np ^ {1, N }, | xi| =k V i = 1 ,N p . Each of such solutions is a subset of power k used as an initial solution of the ALA procedure. Here and after, for each of the initial solutions, the fitness function Ff itness ( x ) is evaluated by Algorithm 4. Resulting values are stored in variables f 1 , ..., f N p.
-
2. If the stop condition is reached the STOP. The result is the initial solution χ having the minimal corre- i
-
3. Select randomly two indexes k 1 , k 2 e {1 ,N },
-
4. Form an interim solution x c = x k 1 и x k 2 ■
-
5. If χ c >k then go to step 7.
-
6. Calculate j * = argmin F^ ( x c { j '} ) ■ Eliminate j * J e X c
-
7. If 3 i e {1 ,Np } : x i = X c then go to step 2.
-
8. Select index k 3 e {1 ,Np } as follows. Select randomly two indexes k 4 , k 5 e {1 ,N }. If fk 4 > fk 5 then k 3 =k 4else k 3 =k 5.
-
9. Replace χ k 3 and corresponding fitness function Value: X k 3 = X c , fk 3 = F fitness ( X c ) . Go to steP 2.
sponding value fi . For finding the final solution, Algorithm 1 runs again.
k 1 ^ k 2.
from χ c : χ c= χ c\ { j* } . Go to step 5.
Steps 5, 6 of this algorithm realize so called greedy heuristic eliminating sequentially the centers from the interim solution.
Analogous greedy heuristic was proposed in 1963 by Kuehn and Hamburger [18]. The Information Bottleneck Clustering method is based on the same principle of sequential cluster elimination [15]. Both method of Kuehn and Hamburger and the IBC method form the initial unfeasible solution as the set of all data vectors.
The fitness function can be evaluated as follows:
Algorithm 4. Calculating fitness function Ffitness ( x ) .
Required: initial solution χ .
-
1. Run Algorithm 1 from initial centers { A i Ii e x}, form set { X 1 , ..., Xp } of centers.
-
2. Return F itness ( X ) = X N = 1 W min, L ( X j ,A i ) . j e {1 ,p } '
An indisputable advantage of the Information Bottleneck Clustering method is its determinancy: this method does not use any random values, thus, each run results in the same result. In general case, if an algorithm uses random values, the precise reproduction of the results is impossible. Using the IBC method slows down the computation utterly. Thus, development of an algorithm giving sufficiently precise results is important for solving many practical problems.
In [3], authors propose a modification of the greedy heuristic used at step 6 of Algorithm 3. In this case, sets of points representing cluster centers in d -dimensional space are used as an alphabet of the genetic algorithm instead of the sets of data vector indexes. Authors call such modification Genetic Algorithm with Floating Point Alphabet. Results of the genetic algorithm, with this new heuristic are significantly more precise than the results of the modification proposed in [17] ( k -problem solution, in fact). At the same time, iterations of Algorithm 3 with this heuristic can be performed faster in comparison with using Algorithm 4. Moreover, abrupt decrease of the computational complexity of step 6 of Algorithm 3 allows using this algorithm for large-scale problems: in [3], authors present results for problems up to 560000 data vectors. Such heuristic can be described as follows [3].
Algorithm 5. Greedy heuristic for the genetic algorithm with floating point alphabet used instead of steps 4–7 of Algorithm 3).
Required: set of data vectors V = ( A 1 , ..., A N ) e R d , quantity k of clusters, two “parent” sets of centers χ k 1 and χ k 2 , parameter α.
-
1. Set x c= X k 1 и x k 2 . Run ALA procedure from initial set of centers χ c . Store the result to χ c .
-
2. If χ c =k then start the ALA procesure from the initial solution χ c then STOP and return the result χ c .
-
3. Calculate distance from each data vector to the nearest center in χ c :
d i = min L ( X , A i ) V i = 1, N .
X e x c
Form clusters around centers χ c :
C i = arg min L ( X, A i ) V i = 1, N .
X e x c
Calculate distances from each data vector to the second closest center in set χ c :
-
d: = min L ( Y , A ) V i = 1, N .
-
4. For ezch center X e xc , calculate 8 X = F ( % c \ { X } ) = IC X e C i ( D - d i )
-
5. Calculate n s = max { [ a ( |x c |- k ) ] ,1 } . Sort values δ X in ascending order and select subset x e ii m = { X i , ..., X n } of n s data vectors with minimal values δ X .
-
6. For each j e { 2, |x e Hm| } : if 3 q e { 1, ( j - 1 ) } : L ( X j , Xq ) < L min then remove X j from set x e Hm . Here, L min = min { max { L ( X , X j ) , L ( X , X q ) } } ’
-
7. Store x c = x c \ x e lim .
-
8. Rearrange the data vectors to the closest centers:
-
9. For each X e x c : if 3 i e { 1, N } : C i = X and C i* ^ X then recalculate center X * of cluster C Xus = { A | C = X , i = 1, N } . Store x c = ( x c \ { X * } j u { X } .
-
10. Go to step 2.
Y e x c \ { C i }
C i* = arg min L ( X , A i ) V i = 1, N .
x e x c
Here, an importan parameter α determines the part of superfluous centers eliminated in a single iteration. Autrors [3] propose value 0.2. Higher values accelerate the algorithm but reduce the preciseness. Small values lead to eliminating the centers one-by-one in accordance with Algorithm 4. In this paper, we used value 0.25.
Iterations of this heuristic combine the fast greedy heuristic [16; 17; 19] eliminating up to 20–25 % superfluous centers with an iteration of the modified ALA procedure. Algorithm 4 requires p ( k 0 - k ) runs of the ALA procedure (here, k 0 is quantity of initial centers), Algorithm 5 reduces number of iterations down to O (log( k 0 – k )). Moreover, each iteration does not require running the whole ALA procedure. Instead, only its separate optimized steps (location – allocation) are performed.
Obviously, if k 0 = N then Algorithm 5 is similar with the Information Bottleneck Clustering: number of centers (and clusters) at the first iteration coincides with the number of data vectors. Moreoved, if k 0 = N is not random. Thus, a simple deterministic algorithm can be constructed [20].
Algorithm 6. Deterministic algorithm with greedy heuristic.
Required: set of data vectors V = ( A 1 , ..., A N ) e R d , number of clusters k , parameter α.
-
1. Set χ c =V .
-
2. Start Algorithm 5 from step 2.
Table shows somparison of results of various algorithms. This algorithm is deterministic but not very precise.
New algorithms. Deterministic Algorithm 6 is a special case of Algorithm 6 with initial value χ c =N . The crossover procedure of the genetic algorithm with floating point (Algorithm 5) starts from a joint interim solution x c = xk 1 u x k 2 . If k << N then in most cases (at least at the initial iterations of the GA), elements of the “parent” sets χ k 1 and χ k 2 do not coincide and Algorithm 5 has χ c = 2 k at its initial iteration. In [21; 22], authors propose various efficient modifications of the greedy heuristic for genetic algorithm with partial joining of the “parent” sets. In this case, |x c | e { ( k + 1 ) ,2 k } . The GA with recombination of fixed length subsets [10] operates sets of power k only. All listed algorithms are most efficient for different problem classes. Thus, depending on problem class, various power χ c of the initial solution can be optimal.
Let us denote quantity of centers in the initial solution as k init = χ c and a ratio of the superfluous centers to k init as
P = ( kmU - k ) / k .
Greedy heuristic in its original form (steps 4–7 of Algorithm 3) and modified form with floating point alphabet (Algorithm 5) can be used as a standalone method for solving the problem. An algorithm can be described as follows.
Algorithm 7. Greedy heuristic method with multistart.
Required: sed of data vectors V = ( A 1 , ..., A N ) e R d , number k of clusters, parameters α and β.
-
1. Calculate kinit =k +[ в k ] . Select randomly subset x с e V of power k nit .
-
2. Start Algorithm 5 from step 2.
-
3. Check the stop conditions and repeat from step 1.
Such approach requires indicating the value of parameter β. Results given in table (see algorithm “GH”) show the importance of this parameter.
Let us consider a known method of solving pseudoBoolean optimization problems, Probability Changing Method [23–25]. The main idea of this method is selecting elements from some given set randomly in accordance with the probability vector depending on previously aclieved results. An algorithm based on this method was proposed for solving the p-median problem on a network [26; 27]. However, such algorithm has very slow convergence and can be used as an aiding method for the genetic algorithm [26]. Similar algorithm can be used for approximate solution of the k-median problem with an arbitrary distance function [28]. Inclusion of the greedy heuristic into the Probability Changing Method leads to new efficient algorithm:
Algorithm 8. Adaptive greedy heuristic method for continuous location problems.
-
1. Set equal values of probabilities pi = 1 / N for all
-
2. For each j = 1, N pop do:
-
2.1. Copy the probabilities q i = p i for all i = 1, N . Set X c =0 . Generate randomly r e [ 0; 2 ) with uniform distribution. Calculate kinit = k + Г в rk ] .
-
2.2. While |x c | < k nt do:
-
2.2.1. Generate random Q e Г о; X N q ) with uniform distribution. Set S = 0; l = 1.
-
2.2.2. While S + q j < Q do: S = S + q j ; l = l + 1; repeat 2.2.2.
-
2.2.3. Set x c = X c u{ A } ; set q i = 0.
-
2.2.4. Repeat 2.2.
-
-
2.3. Copy the initial set £ c = x c .
-
2.4. Start Algorithm 5 from step 2. Store the result f} = F ( x c ) ; set x j = x c ; в j = ( k mU - k ) / k .
-
2.5. Next iteration 2.
-
-
3. Calculate в = в X N , pp .1N , j = 1 X N = 1 op ( N pop - n j ) X N = 1 op в J
-
4. Chose index b having minimal corresponding value f b and index w having maximal f w .
-
5. For each i = 1, N do:
-
5.1. If A i e £ b and A i £ £ w then set p i = y p i . Else if A i e £ w and A i £ £ b then p i = p / y .
-
5.2. Next iteration 5.
-
-
6. Check the stop conditions and repeat step 2.
i = 1, N . Set в = 0.5.
Npop в l ( Nnn n - n I )
here, n j is the number of value f j in an ascending sequence os these values.
If 4в k > N then set в = N /4 k .
This algorithm requires indicating values of parameters N pop (population size) and γ (probability change coefficient). Small populations are enough for this algorithm. We used N pop = 9 and γ = 1,1. Parameter β is adjusted with special meta-heuristic (step 3).
New algorithms and the deterministic algorithm with greedy heuristic [20] have an important feature. Many clustering problems (see for example [19]) are decomposed into series of k-means problems with k = km, km„ where kmin = 1 (the whole data set is min max m n supposed to be a single cluster) and kmax is equal to some reasonable value. Algorithm 6 can be used for a problem with k = kmax and then Algorithm 5 from step 2 can be started again for obtaining other results down to k = kmin. Thus, all results for k = kmin, kmax can be obtained in a single loop.
In many cases, a single start of the greedy heuristic cannot be completed within the given time limit. Running time of the algorithm depends on parameter β. In such cases, table contains dashes. Problems with data sets are not solved with deterministic algorithms either due to huge amount of time needed.
The optimal value of parameter α remains an open question. Note that if α = 0.001 then centers are eliminated from the interim solution one-by-one in accordance with the original greedy heuristic. For the deterministic algorithm with greedy heuristic [20], value α = 0.25 guarantees faster result (not the most precise) in accordance with results obtained with α = 0.001. In the case of stochastic algorithm, it is not easy to foresee which value leads to better result in reasonable time. As we can see in table, data vectors quantity (compare data sets MissA-merica1, BIRCH3 and examination of diodes) and metric do not determine the optimal value of this parameter. Developing a meta-heuristic algorithms adjusting this parameter seems to be promising. Adjusting parameter α with fixed value of β can be easily performed. Simultaneous adjustment of both parameters requires factor analysis for evaluating the influence of each parameter on the results. Thus, developing a co-evolutionary algorithm with two concurrent populations having different fixed values of parameter α seems to be simpler. An example of analogous algorithm with concurrent populations evolving with various bionic algorithms was proposed in [30].
Nevertheless, it is obvious that new adaptive algorithm allows to obtain better results than multiple start of the ALA procedure and multiple start of the greedy heuristic with fixed β.
Used algorithms: “ALA” is ALA procedure multistart; “GA-MIX” is genetic algorithm with fixed length subsets recombination [10]; “GA-GHFP” is genetic algorithm with greedy heuristic and floating point alphabet [3]; “GA-classic” is GA with classical recombination, “IBC” is Information Bottleneck Clustering [15; 20]; “Determ. GH” is deterministic algorithm with greedy heuristic [20]; “GH” is new Algorithm 7; “GL” is multistart of the original greedy heuristic with local search (steps 4–7 of Algorithm 3 at α = 0.001 or steps 4–7 of Algorithm 3 with fast elimination of centers from the interim solution similar with steps 5–7 of algorithm 5 at α = 0.25); “GH” adapt is adaptive greedy heuristic (Algorithm 8). If no result was achieved within specified time limit, the table contains a dash.
Results of various methods
Completion of table
|
Data set, number of data vectors, dimension, data type |
Number of clusters k , metric, problem type |
Algorithm |
Time, sec. |
Average result of 30 runs: total distance (2) F ( X 1, …, Xk ) |
Std. deviation of the result (30 runs) |
||
|
Parameter α = 0.25 |
Parameter α = 0.001 |
Parameter α = 0.25 |
Parameter α = 0.001 |
||||
|
Generated problem, |
20, metric |
ALA |
4 |
4461.24 |
25.9199 |
||
|
N = 500, d = 2, real |
based on |
GA-MIX |
4 |
4509.49 |
14.4368 |
||
|
angular, |
GA-GHFP |
4 |
4326.72 |
4.7587 |
|||
|
distances, k - |
GA-classic |
4 |
4392.95 |
79.6913 |
|||
|
median |
IBC |
3141 |
4381.34 |
Determ. |
|||
|
Determ. GH |
4.9/23.5 |
4377.12 |
4376.43 |
Determ. |
Determ. |
||
|
GH, β = 0.5 |
4 |
4350.36 |
4378.30 |
15.1717 |
15.4234 |
||
|
GH, β = 1 |
4 |
4333.02 |
4371.50 |
5.8614 |
38.5620 |
||
|
GH, β = 3 |
4 |
4389.32 |
– |
22.5053 |
– |
||
|
GL β = 0.5 |
4 |
4428.97 |
4453.65 |
59.4167 |
34.3130 |
||
|
GL, β = 1 |
4 |
4379.42 |
4359.41 |
46.1732 |
22.5052 |
||
|
GL, β = 3 |
4 |
4429.37 |
– |
78.2398 |
– |
||
|
GH adapt. |
4 |
4313.67 |
4309.43 |
3.7077 |
1.4427 |
||
References Greedy heuristic method for location problems
- Facility Location Concepts, Models, Algorithms and Case Studies/R. Z. Farahani, М. Hekmatfar (editors). Berlin Heidelberg: Springer-Verlag, 2009. 550 p.
- Kazakovtsev L. A., Stupina A. A. Fast Genetic Algorithm with Greedy Heuristic for p-Median and k-Means Problems//IEEE 2014 6th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT) (October 6-8, 2014. St.-Petersburg). 2014. Р. 702-706.
- Kazakovtsev L. A., Antamoshkin A. N. Genetic Algorithm wish Fast Greedy Heuristic for Clustering and Location Problems//Informatica. 2014. Vol. 38, iss. 3. Рp. 229-240.
- Deza M. M. and Deza E. Encyclopedya of Distances. Berlin-Heilderberg: Springer Verlag, 2009. 590 p. DOI: DOI: 10.1007/978-3-642-00234-2_1
- Трубин В. А. Эффективный алгоритм для задачи Вебера с прямоугольной метрикой//Кибернетика. 1978. № 6. С. 67-70. DOI: DOI: 10.1007/BF01070282/
- Kaufman L. and Rousseeuw P. J. Finding Groups in Data: an Introduction to Cluster Analysis. New York: John Wiley & Sons, 1990. 342 p. DOI: DOI: 10.1002/9780470316801.ch1
- Park H. S., Jun C.-H. A simple and fast algorithm for K-medoids clustering//Expert Systems with Applications. 2009. Vol. 36. Р. 3336-3341.
- Lucasius C. B., Dane A. D., Kateman G. On K-Medoid Clustering of Large Data Sets with the Aid of a Genetic Algorithm: Background, Feasibility and Comparison//Analytical Chimica Acta. 1993. Vol. 282. Р. 647-669. DOI: DOI: 10.1007/s10732-006-7284-z
- Zhang Q., Couloigner I. A New Efficient K-Medoid Algorithm for Spatial Clustering//ICCSA 2005, LNCS. 2005. Vol. 3482. Р. 181-189. DOI: 10.1007/11424857_20.
- Sheng W., Liu X. A Genetic K-Medoids Clustering Algorithm//Journal of Heuristics. 2004. Vol. 12, iss. 6. Р. 447-466. DOI: DOI: 10.1007/s10732-006-7284-z
- Cooper L. Location-allocation problem//Oper. Res. 1963. Vol. 11. Р. 331-343, DOI: DOI: 10.1287/opre.11.3.331
- Arthur D., Vassilvitskii S. k-Means++: the Advantages of Careful Seeding//Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. 2007. Р. 1027-1035. DOI: DOI: 10.1.1.360.7427
- Mishra N., Oblinger D., Pitt L. Sublinear time approximate clustering//12th SODA. 2001. Р. 439-447.
- StreamKM: A Clustering Algorithm for Data Streams/M. R. Ackermann //J. Exp. Algorithmics. 2012. Vol. 17. Article 2.4. DOI: DOI: 10.1145/2133803.2184450/
- A parallel clustering method combined information bottleneck theory and centroid-based clustering/Zh. Sun //The Journal of Supercomputing. 2014. Vol. 69, iss. 1. Р. 452-467. DOI: DOI: 10.1007/s11227-014-1174-1
- Alp O., Erkut E., Drezner Z. An Efficient Genetic Algorithm for the p-Median Problem//Annals of Operations Research. 2003. Vol. 122, iss. 1-4. Р. 21-42. DOI: DOI: 10.1023/A:1026130003508
- Neema M. N., Maniruzzaman K. M., Ohgai A. New Genetic Algorithms Based Approaches to Continuous p-Median Problem//Netw. Spat. Econ. 2011. Vol. 11. Р. 83-99. DOI: DOI: 10.1007/s11067-008-9084-5
- Kuehn A. A., Hamburger M. J. A heuristic program for locating warehouses//Management Science. 1963. Vol. 9, iss. 4. Р. 643-666. DOI:10.1287/mnsc.9.4.643.
- Задача классификации электронной компонентной базы/Л. А. Казаковцев .//Вестник СибГАУ. 2014. № 4(56). С. 55-61.
- Казаковцев Л. А. Детерминированный алгоритм для задачи k-средних и k-медоид//Системы управления и информационные технологии. 2015. № 59. С. 95-99.
- Казаковцев Л. А., Ступина А. А., Орлов В. И. Модификация генетического алгоритма с жадной эвристикой для непрерывных задач размещения и классификации//Системы управления и информационные технологии. 2014. № 2(56). С. 35-39.
- Modified Genetic Algorithm with Greedy Heuristic for Continuous and Discrete p-Median Problems/L. A. Kazakovtsev //Facta Universitatis Series Mathematics and Informatics. 2015. Vol. 30, iss. 1. Р. 89-106.
- Antamoshkin A. N. Brainware for Searchal Pseudoboolean Optimization//Transactions of the Tenth Prague Conference Czechoslovak Academy of Sciences Volume. 1988. Р. 203-206. DOI: DOI: 10.1007/978-94-009-3859-5_16
- Казаковцев Л. А. Параллельный алгоритм случайного поиска с адаптацией для систем с распределенной памятью//Системы управления и информационные технологии. 2012. № 3(49). С. 11-15.
- Kazakovtsev L. A. Random Constrained Pseudo-Boolean Optimization Algorithm for Multiprocessor Systems and Clusters//ICUMT 2012, International Congress on Ultra-Modern Telecommunications. S-Petersburg: IEEE Press, 2012. Р. 650-656. DOI: DOI: 10.1109/ICUMT.2012.6459711
- Antamoshkin A. N., Kazakovtsev L. A. Random Search Algorithm for the p-Median Problem//Informatica, 2013. Vol. 37, iss. 3. Р. 267-278.
- Антамошкин А. Н., Казаковцев Л. А. Применение метода изменяющихся вероятностей для задач размещения на сети//Вестник СибГАУ. 2014. № 5(57). С. 10-19.
- Антамошкин А. Н., Казаковцев Л. А. Алгоритм случайного поиска для обобщенной задачи Вебера в дискретных координатах//Информатика и системы управления. 2013. № 1. С. 87-98.
- Patrick M. Murphy P. M., Aha D. W. UCI Repository of Machine Learning Databases . 1994. URL: http://www.cs.uci.edu/mlearn/mlrepository.html (дата обращения: 02.01.2015).
- Akhmedova Sh. A., Semenkin E. S. New optimization metaheuristic based on co-operation of biology related algorithms//Вестник СибГАУ. 2013. № 4(50). С. 92-99.
- Farahani R. Z., Hekmatfar M. (editors). Facility Location Concepts, Models, Algorithms and Case Studies. Springer-Verlag Berlin Heidelberg, 2009, 550 p.
- Kazakovtsev L. A., Stupina A. A. Fast Genetic Algorithm with Greedy Heuristic for p-Median and k-Means Problems. IEEE 2014 6th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), St.-Petersburg, October 6-8, 2014. 2014, P. 702-706.
- Kazakovtsev L. A., Antamoshkin A. N. Genetic Algorithm wish Fast Greedy Heuristic for Clustering and Location Problems. Informatica. 2014, Vol. 38, Iss. 3, P. 229-240.
- Deza M. M., Deza E. Encyclopedya of Distances. Springer Verlag. Berlin, Heilderberg, 2009, 590 p., DOI: DOI: 10.1007/978-3-642-00234-2_1
- Trubin V. A. Kibernetika. 1978, Iss. 6, P. 67-70, DOI:(In Russ.) DOI: 10.1007/BF01070282/
- Kaufman L., Rousseeuw P. J. Finding Groups in Data: an Introduction to Cluster Analysis. New York: John Wiley & Sons, 1990, 342 p., DOI: 10.1002/9780470316801.ch1.
- Park H. S., Jun C.-H. A simple and fast algorithm for K-medoids clustering. Expert Systems with Applications. 2009, Vol. 36, P. 3336-3341.
- Lucasius C. B., Dane A. D., Kateman G. On K-Medoid Clustering of Large Data Sets with the Aid of a Genetic Algorithm: Background, Feasibility and Comparison. Analytical Chimica Acta. 1993, Vol. 282, P. 647-669, DOI: DOI: 10.1007/s10732-006-7284-z
- Zhang Q., Couloigner I. A New Efficient K-Medoid Algorithm for Spatial Clustering. ICCSA 2005, LNCS. 2005, Vol. 3482, P. 181-189, DOI: DOI: 10.1007/11424857_20
- Sheng W., Liu X. A Genetic K-Medoids Clustering Algorithm. Journal of Heuristics. 2004, Vol. 12, Iss. 6, P. 447-466, DOI: DOI: 10.1007/s10732-006-7284-z
- Cooper L. Location-allocation problem. Oper. Res. 1963, Vol. 11, P. 331-343, DOI: 10.1287/opre.11.3.331.
- Arthur D., Vassilvitskii S. k-Means++: the Advantages of Careful Seeding. Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. 2007, P. 1027-1035, DOI: DOI: 10.1.1.360.7427
- Mishra N., Oblinger D., Pitt L. Sublinear time approximate clustering. 12th SODA. 2001, P. 439-447.
- Ackermann M. R. et al. StreamKM: A Clustering Algorithm for Data Streams. J. Exp. Algorithmics. 2012, Vol. 17, Article 2.4, DOI: DOI: 10.1145/2133803.2184450/
- Sun Zh., Fox G., Gu W., Li Zh. A parallel clustering method combined information bottleneck theory and centroid-based clustering. The Journal of Supercomputing. 2014, Vol. 69, Iss. 1, P. 452-467. DOI: DOI: 10.1007/s11227-014-1174-1
- Alp O., Erkut E., Drezner Z. An Efficient Genetic Algorithm for the p-Median Problem. Annals of Operations Research. 2003, Vol. 122, Iss. 1-4, Р. 21-42. DOI: DOI: 10.1023/A:1026130003508
- Neema M. N., Maniruzzaman K. M., Ohgai A. New Genetic Algorithms Based Approaches to Continuous p-Median Problem. Netw. Spat. Econ. 2011, Vol. 11, P. 83-99. DOI: DOI: 10.1007/s11067-008-9084-5
- Kuehn A. A., Hamburger M. J. A heuristic program for locating warehouses. Management Science. 1963, Vol. 9, Iss. 4, P. 643-666, DOI: DOI: 10.1287/mnsc.9.4.643
- Kazakovtsev L. A., Orlov V. I., Stupina A. A., Masich I. S. . Vestnnik SibGAU. 2014, No. 4(56), P. 55-61 (In Russ.).
- Kazakovtsev L. A. . Sistemy upravleniya I informatsionnye tekhnokogii. 2015, No. 1(59), P. 95-99 (In Russ.).
- Kazakovtsev L. A., Stupina A. A., Orlov V. I. . Sistemy upravleniya i informatsionnye tekhnokogii. 2014, No. 2(56), P. 35-39 (In Russ.).
- Kazakovtsev L. A., Orlov V. I., Stupina A. A., Kazakovtsev V. L. Modified Genetic Algorithm with Greedy Heuristic for Continuous and Discrete p-Median Problems. Facta Universitatis Series Mathematics and Informatics. 2015, Vol. 30, Iss. 1, P. 89-106.
- Antamoshkin A. N. Brainware for Searchal Pseudoboolean Optimization. Transactions of the Tenth Prague Conference Czechoslovak Academy of Sciences Volume. 1988, P. 203-206, DOI: DOI: 10.1007/978-94-009-3859-5_16
- Kazakovtsev L. A. . Sistemy upravleniya I informatsionnye tekhnokogii. 2012, No. 3 (49), P. 11-15 (In Russ.).
- Kazakovtsev L. A. Random Constrained Pseudo-Boolean Optimization Algorithm for Multiprocessor Systems and Clusters. ICUMT 2012, International Congress on Ultra-Modern Telecommunications. IEEE Press. S-Petersburg. 2012, P. 650-656, DOI: 10.1109/ICUMT.2012.6459711.
- Antamoshkin A. N., Kazakovtsev L. A. Random Search Algorithm for the p-Median Problem. Informatica, 2013, Vol. 37, Iss. 3, P. 267-278.
- Antamoshkin A. N., Kazakovtsev L. A. . Vestnik SibGAU. 2014, No. 5(57), P. 10-19 (In Russ.).
- Antamoshkin A. N., Kazakovtsev L. A. . Informatika i systemy upravleniya. 2013, No. 1, P. 87-98 (In Russ.).
- Patrick M. Murphy P. M., Aha D. W. UCI Repository of Machine Learning Databases. 1994. Available at: http://www.cs.uci.edu/mlearn/mlrepository. html (accessed 02.01.2015).
- Akhmedova Sh. A., Semenkin E. S. New optimization metaheuristic based on cooperation of biology related algorithms. Vestnik SibGAU. 2013, No. 4(50), P. 92-99 (In Russ.).
