Иерархическая модель и базовые алгоритмы временной сегментации речевых сигналов

Автор: Томчук Кирилл Константинович, Зилинберг Андрей Юрьевич
Журнал: Ученые записки Петрозаводского государственного университета @uchzap-petrsu
Рубрика: Физико-математические науки
Статья в выпуске: 2 (131), 2013 года.
Бесплатный доступ
Представлен системный подход к временной сегментации речевых сигналов, основанный на разработанной иерархической модели речевых сигналов. Обосновано применение многоуровневой временной сегментации речевых сигналов и разработаны базовые алгоритмы для основных уровней сегментации: VAD-алгоритм; деление речевых сигналов на вокализованный, шумовой, взрывной сегменты; сегментация вокализованных фрагментов на периоды основного тона. Предложен возможный вариант разделения смежных вокализованных звуков с помощью анализа их структуры.
Речь, модель речевого сигнала, сегментация, основной тон
Короткий адрес: https://sciup.org/14750368
IDR: 14750368 | УДК: 004.934.2
Hierarchically structured model and basic algorithms of time domain segmentation of speech signals
This paper introduces a systematic approach to speech signal (SS) segmentation based on developed hierarchically structured SS-model. Ground is given to application of multilevel time voice sound record segmentation, and basic algorithms of principal segmentation stages are developed: VAD algorithm; “voiced / noise / plosive” segmentation; voiced fragments’ segmentation into separate pitch periods. The possible variant of splitting adjacent voiced sounds using analysis of their structure has been proposed.
Текст научной статьи Иерархическая модель и базовые алгоритмы временной сегментации речевых сигналов
Автоматическая обработка речи является современной и актуальной задачей, представленной широким кругом областей приложений: шумоподавление, сжатие речевых сигналов (РС), распознавание, модификация РС, кодирование и т. д. [3], [4], [5], [7], [8], [9], [10], [11], [15]. В силу недостаточной изученности процесса восприятия речи человеком, сложности структуры речевого сигнала, индивидуальных особенностей речи каждого человека, наличия огромного числа языковых культур многие из задач, стоящих перед автоматической обработкой речи, так и не были решены в достаточной степени для свободного практического применения.
Голосовой аппарат человека является акустической системой, состоящей из вибраторов, возбуждаемых потоком воздуха из легких в соответствии с законом Бернулли, и резонаторов – глотки, носовой и ротовой полостей. Механизмы возбуждения акустических колебаний связаны либо с работой гортани, либо с возникновением шумных или импульсных звуков при прохождении воздушного потока через сужения, образующиеся в определенных местах речевого тракта [13].
Все гласные звуки произносятся при активности только голосовых связок и без создания сужений в голосовом тракте. При произнесении согласных звуков в речевом аппарате возникают препятствия для свободного прохождения воздуха. В результате согласные, в том числе вокализованные ([ б ], [ н ], [ р ], …), во-первых, имеют меньшую мощность сигнала, по сравнению с
гласными, а во-вторых, если при произнесении звука воздух с силой проталкивается через значительные сужения, в сигнале появляется шумовая компонента ([ з ], [ c ], [ ш ], [ т’ ]). Кроме того, при произнесении согласного голосовые связки могут быть неактивны – тогда произносится либо чисто шумовой звук, возникающий при длительном протягивании воздуха через значительное сужение (ср. вокализованный [ з ] и шумовой [ с ]), либо так называемый взрывной звук, возникающий при силовом проходе воздуха через резко образуемое отверстие ([ п ], [ т ], [ т’ ], ...). Таким образом, вокализованные (звонкие) звуки формируются с участием голосовых связок, шумовые (фрикативные) – за счет прохождения воздуха через сужения голосового тракта, а взрывные – с помощью кратковременного смыкания речевого аппарата, создания в речевых полостях повышенного давления и затем резкого размыкания аппарата. Частота колебания голосовых связок при произнесении вокализованных звуков называется частотой основного тона (ОТ). Форма голосового тракта остается в основном неизменной на интервале 10–30 мс. На этом интервале речь можно рассматривать как квазистационарный случайный процесс, поэтому большинство алгоритмов предварительной обработки основываются на анализе РС на указанном интервале времени.
СИСТЕМНЫЙ ПОДХОД К МНОГОУРОВНЕВОЙ ВРЕМЕННОЙ СЕГМЕНТАЦИИ РЕЧЕВЫХ СИГНАЛОВ
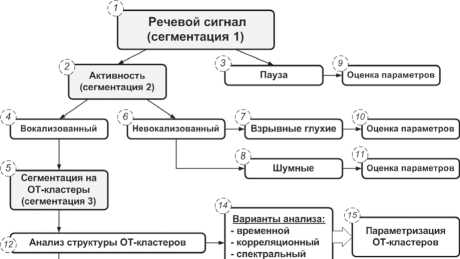
На основе информации о строении речевого сигнала, об особенностях реализаций звуков русской речи задача временной сегментации может быть разбита на несколько последовательно осуществляемых этапов, каждый из которых представляет собой соответствующий уровень сегментации РС (рис. 1).
На первом уровне сегментации (блок 1, рис. 1) происходит разбиение речевого сигнала на фрагменты активной речи и пауз. При этом в роли па- узы может также выступать смычка – кратковре- менная пауза в пределах слова перед взрывным звуком. Вторым уровнем сегментации (блок 2, рис. 1) является разбиение активных участков речи на фрагменты, соответствующие трем основным типам звуков: вокализованные, шумовые и взрывные. Третий уровень (блок 5, рис. 1) относится к дополнительной сегментации только вокализованных фрагментов – разделение РС на отдельные периоды основного тона. Разбиение на периоды основного тона не обязательно является финальной стадией сегментации: в дальнейшем на ее основе может быть выполнено разбиение вокализованных фрагментов на отдельные аллофоны или группы из однотипных аллофонов. В данном случае становится возможным построение собственных нейронных сетей, марковских моделей и других эталонов для различных типов фонем. Например, в системе верификации, разрабатываемой компанией SPIRIT Corp. [12], процедура классификации, основывающаяся на смешанных гауссовских моделях, позволяет принимать во внимание отдельные фонемы или группы фонем и особенности их произнесения конкретным диктором.
Н Анализ трендов и разладок в последовательностях параметров ОТ-кластеров
Рис. 1. Этапы сегментации и параметризации речевого сигнала
На рис. 1 приведен алгоритм предлагаемого системного подхода к сегментации и последующей параметризации речевого сигнала.
На первом шаге обработки (блоки 1…3, рис. 1) сигнал сегментируется на фрагменты активной речи и паузы. Паузы не подвергаются дальнейшей сегментации, а информативным параметром (блок 9) участков паузы является их длительность. Над участками активной речи производится следующий, второй, уровень сегментации, на котором выделяются сегменты, соответствующие определенным типам звуков: вокализованные (блок 4), шумные (блок 8), взрывные глухие (блок 7).
Сегментация «речь / пауза»: VAD-алгоритм (блок 1, рис. 1)
Алгоритм определения временных границ речевой активности говорящего и в зарубежной, и в отечественной литературе сокращенно обозначают как VAD-алгоритм (Voice Activity Detection). Он позволяет произвести сегментацию сигналов по двум качественным параметрам: пауза и активность говорящего.
В результате применения VAD-алгоритма речевой сигнал становится сегментированным на A- и S-сегменты: сегменты активности говорящего A (activity) и сегменты пауз S (silence).
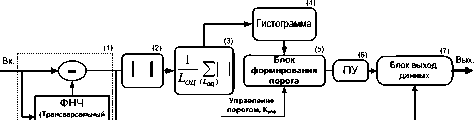
Одной из основных проблем, возникающих перед разработчиками VAD-алгоритма, является обеспечение его надежной работы в условиях шумов, помех, наводок. При этом алгоритм должен хорошо обнаруживать границы речевой активности даже при слабых граничных (начальных и конечных) звуках. Это могут быть шумовые звуки, сравнимые по уровню с фоновыми шумами, и плавно нарастающие / убывающие по уровню вокализованные звуки. Для борьбы с этими проблемами нами был разработан новый энергетический VAD-алгоритм.
В этом алгоритме для нахождения порога (блок 5, рис. 2) и сравнения с ним используется сигнал, полученный на основе модуля отсчетов исходного сигнала (блоки 2 и 3, рис. 2), пропущенного для подавления НЧ-наводок через высокочастотный фильтр (блок 1, рис. 2). При формировании порога определения речевой активности необходимо использовать характеристику всего набора значений отсчетов фонового шума. Это можно осуществить, определяя уровень порога на гистограмме (блок 4, рис. 2) отсчетов [2] такого фильтрованного сигнала, по которой видно общее распределение как ВЧ-шума, так и НЧ-компонент речевого сигнала. Функциональная схема такого алгоритма VAD представлена на рис. 2.
интерполирующий фильтр)
Рис. 2. Функциональная схема «энергетического» алгоритма VAD
В алгоритме VAD на интервалах оценивания текущих средних значений модулей отсчетов (длина интервала LОЦ = 2,5…7 мс в зависимости от частоты дискретизации: по достаточной по шуму выборке в 50–70 отсчетов) осуществляется суммирование модулей отсчетов РС с последующей нормировкой на длину интервала (блок 3, рис. 2). Гистограмма строится по результатам обработки отсчетов на интервале порядка 1,5…2 с, в течение которых внешний шум изменяется незначительно (стационарен). Для формирования порога активности используется мода гистограммы, характеризующая средний модуль ВЧ-сигнала на выходе фильтра (блок 1, рис. 2) в паузах.
Основным недостатком энергетического алгоритма является низкая точность определения границ слабых вокализованных звуков и – главное – высокая вероятность пропуска некоторых шумовых звуков, в особенности кратковременных шумовых звуков, расположенных обособленно от других между смычкой и паузой (например, звук [ т’ ] на конце слова).
Для уменьшения неточности определения границ слабых вокализованных звуков необходимо вводить в VAD-алгоритм детектор вокализованных звуков, не зависящий от уровня сигнала (см. раздел «Сегментация “вокализованный / шумовой / взрывной”»).
Для отделения слабых шумовых звуков речи от фонового шума целесообразно воспользоваться текущим спектральным составом сигнала. Исследования показывают, что наиболее часто встречающийся фоновый шум (шум помещений, уличный шум) имеет более низкочастотный спектральный состав, нежели шумовые звуки активной речи. В этом случае для шумовых фрагментов речевого сигнала (как фоновых шумов, так и шумовых звуков) на спектрограмме вычисляется траектория «центра масс» спектра. Если оценка «центра масс» превышает некоторый пороговый уровень подряд на нескольких интервалах оценивания, есть основания полагать, что такой фрагмент относится к речевой активности.
На рис. 3 изображена временная функция только шумовой составляющей речевого сигнала, представляющего слово « вафли » (нешумовые составляющие вырезаны из реализации), и соответствующая спектрограмма с обозначением порога и «центра масс» спектра. На временной функции область шумов с высокой дисперсией соответствует звуку [ ф ].

2 4 6 8 10 12 14 16 18 20
6) 0.05-------------1-------------1-------------1-------------1-------------1-------------1-------------1--------------1-------------1-------------1-------
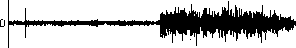
-0.05-------------1-------------1-------------1-------------1-------------1-------------1-------------1--------------1-------------1-------------1-------- П.
500 1000 1500 2000 2500 3000 3500 4000 4500 5000 t
Рис. 3. Спектральное разделение речевых и фоновых шумов: а) спектрограмма сигнала с указанием траектории «центра масс» спектра и порогового уровня; б) временная функция сигнала
Сегментация «вокализованный / шумовой / взрывной» (блоки 2 и 6, рис. 1)
Разделение активных участков речи на шумовые, вокализованные и взрывные производится по выявлению характерных для определенных типов признаков. К примеру, такую сегментацию можно осуществить путем формирования выборочных корреляционных функций фильтрованной от низкочастотных наводок последовательности отсчетов на малых окнах анализа.
Задачу разделения «вокализованный / шумовой / взрывной» можно разделить на два этапа. На первом этапе производится сегментация «шумовой / нешумовой», а на втором, соответственно, сегментация нешумовых фрагментов на сегменты «вокализованный / взрывной».
Для выделения шумовых звуков пороговым параметром может являться отношение среднеквадратического отклонения (СКО) от линии нуля отсчетов речевого сигнала, пропущенного через низкочастотный фильтр, к СКО отсчетов исходного речевого сигнала:
K =
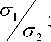
^ 1 =
N
I y 2 (n n )
n =1 .
N ’
CT 2 =
N
I y 2 ( n )
^=1--------, (1)
N где σ1 – СКО сигнала yF (пропущенного через НЧ-фильтр исходного сигнала y); σ2 – СКО исходного сигнала y; N – апертура прямоугольного окна низкочастотного фильтра (заметим, что весовая функция трансверсального фильтра может быть и сглаженной, например, соответствовать окнам Хемминга, Блекмана; при этом полоса среза НЧ-фильтра должна составлять порядка 500 Гц).
Для шумовых участков среднеквадратическое отклонение σ2 от нуля исходного сигнала будет больше, чем СКО σ1 фильтрованной версии сигнала, поэтому отношение K для шумовых участков заведомо меньше единицы.
Вокализованные фрагменты, которые соответствуют вокализованным звукам, выделяются из общей картины своей квазипериодичностью. Как известно, автокорреляционная функция периодического сигнала также является периодической функцией [4]. При реализации алгоритма вычисляются взаимные корреляционные функции (ВКФ) отрезка речевого сигнала, находящиеся на текущем окне анализа, и отрезков такой же длины, находящихся справа и слева от исследуемого. Такой подход позволяет более точно найти позиции начала и окончания вокализованного участка, нежели процесс вычисления АКФ от участка речевого сигнала с более широким окном анализа.
Для оценки периодичности следования экстремумов находятся максимумы и минимумы полученной ВКФ, вычисляется оценка среднего интервала их следования. Затем от этой оценки вычисляется оценка СКО интервалов между экстремумами. Для оценки относительной сте- пени периодичности следования экстремумов используется отношение найденных оценок СКО и среднего интервала следования. Пример корреляционной функции для вокализованных участков показан на рис. 4. На рис. 4а приняты следующие обозначения: N – количество локальных максимумов и минимумов ВКФ; M – оценка среднего интервала; SD – оценка СКО интерва- лов от среднего значения.
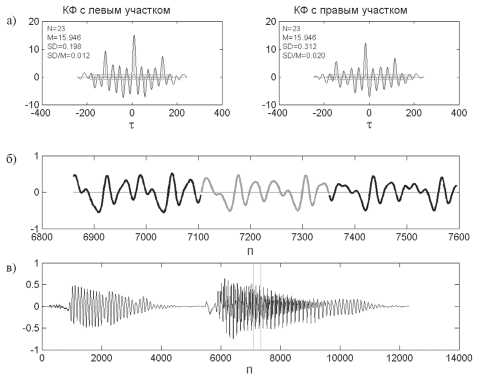
Рис. 4. Выделение вокализованных фрагментов речи: а) ВКФ исследуемого вокализованного участка речевого сигнала с двумя смежными вокализованными участками;
б) временные функции исследуемого (в центре серый) участка и двух смежных; в) временная функция РС с указанием границ фрагмента, соответствующего эпюре «б» рисунка
Сегментация на периоды основного тона (блок 5, рис. 1)
В зависимости от выбранных функциональных методов обработки речевого сигнала может также потребоваться дополнительная сегментация вокализованных фрагментов на отдельные периоды основного тона, характеризующие колебания голосовых связок диктора.
Для сегментации вокализованных фрагментов РС периодов основного тона существует большое количество алгоритмов, работа которых основана на разных математических подходах [5].
Среди методов оценки периода ОТ можно выделить две основные подгруппы алгоритмов [3]: структурные методы оценки периода ОТ (локальные методы) и алгоритмы без привязки к временной структуре РС (интегральные методы).
При реализации корреляционного метода сегментации на периоды ОТ из речевого фрагмента берется участок длительностью не менее двух максимально возможных для человеческого голоса периодов ОТ (для человека TMAX имеет значение ~20 мс) симметрично по времени относительно известной (или предполагаемой – на первом шаге работы алгоритма) левой границы периода ОТ.
В автокорреляционной функции этого фрагмента ищется максимум, лежащий в пределах возможного периода основного тона человека, то есть между значениями 2,5 и 20 мс (рис. 5б). Смещение, соответствующее этому максимуму, и является оценкой среднего для текущего фрагмента периода основного тона. Так как это средняя величина, она нуждается в коррекции: правая граница периода ОТ вычисляется прибавлением к левой границе длительности оценки среднего периода ОТ с коррекцией до точки ближайшего пересечения нуля в направлении снизу вверх (для сегментации предлагается руководствоваться переходами сигнала через ноль в направлении снизу вверх) пропущенного через ФНЧ сигнала. Завершающим шагом коррекции должен стать поиск ближайшего к положению найденной границы перехода через ноль снизу вверх уже исходным сигналом. На рис. 5а левая серая черта – известная левая граница периода ОТ, правая серая черта – полученная непосредственно по оценке среднего периода основного тона правая граница периода ОТ. Черная черта – скорректированная в ноль правая граница. Таким образом, расстояние между левой серой чертой и черной чертой является оценкой текущего периода основного тона, а расстояние между серыми чертами – средним периодом основного тона исследуемого участка речевого сигнала.
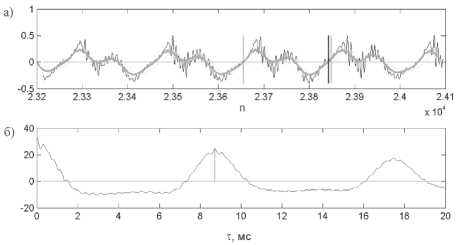
Рис. 5. Выделение периодов ОТ: а) исследуемый фрагмент сигнала; б) автокорреляционная функция исследуемого фрагмента
Сегментация вокализованных фрагментов на фонемы
В ряде функциональных приложений обработки речи может также возникнуть задача фонемной сегментации речевых сигналов. Проблема такой сегментации заключается в том, что на вокализованные звуки приходится в среднем три четверти общей длительности активной речи [14]. Поэтому различные вокализованные звуки зачастую следуют в речи непрерывно друг за другом. При этом переходы между отдельными звуками с сигнальной точки зрения могут представлять собой как плавное изменение структуры и «энергетики» колебания основного тона говорящего, так и относительно быструю их перестройку.
Для характеризации изменений структуры кластеров основного тона (ОТ-кластеров) можно ввести метрики, учитывающие разницу
«энергетик» и структур двух сравниваемых кластеров [14]. При этом плавные переходы внутри одного звука и между звуками являются трендами, а сравнительно резкие переходы между звуками – разладками структуры РС. Рассмотрим два вида метрик: амплитудно-структурную и структурную.
Амплитудно-структурные тренды выражаются как в амплитудных, так и в структурных изменениях периодов ОТ:
-
1 T ot ( j )
M амп - стр (j) = - S X (i, j) - X (i, j - 1)1, (2) TOT ( j ) Acp (j ) И где M(j) - последовательность метрик, полученная на последовательности периодов ОТ Tom(j — 2) => Tom(j — 1) => Tom(j) => Tom(j + 1) => Tom(j + 2) => ..; Tom(j) - длительность j-го периода ОТ; Acp(j) — средняя амплитуда группы периодов ОТ (группа состоит из 2–3 периодов), вычис- ленная на скользящем временном интервале для j-го периода ОТ.
Структурные тренды выражаются в структурных изменениях периодов ОТ:
M стр ( j ) =
1 T OT ( j ) X ( i , j ) - X ( i , j - 1)
T ot ( j ) S X max ( j ) X max ( j - 1)
где Xmax(j) — максимальный отсчет на интервале j -го ОТ-кластера.
По формулам (2) и (3) видно, что для вычисления предложенных метрик длины векторов отсчетов речевого сигнала, соответствующих периодам ОТ, должны быть равны. Однако в общем случае в реальном РС длины двух смежных векторов ОТ немного отличаются, поэтому перед вычислением метрик необходимо уравнять длины двух исследуемых векторов путем векторной интерполяции.
В практических приложениях могут быть более полезны модифицированные методы анализа трендов и разладок. Например, для исключения случайных изменений структур и длительностей от одного периода ОТ к другому следует вычислять метрики не смежных периодов, а разнесенных друг от друга на несколько промежуточных периодов. В этом случае значения метрик в трендах станут несколько выше по величине (так как в тренде дальше отстоящие друг от друга периоды ОТ будут сильнее отличаться и, следовательно, иметь большую метрику), а огибающая метрик станет «плавнее».
ЗАКЛЮЧЕНИЕ
Системный подход к сегментации речевых сигналов позволяет получать необходимую для реализации речевых приложений детальность сегментации вплоть до выделения и параметрического описания отдельных периодов основного тона диктора. Приведенные в статье алгоритмы многоуровневой временной сегментации относятся к классу технологических и могут использоваться в широком спектре речевых приложений.
HIERARCHICALLY STRUCTURED MODEL AND BASIC ALGORITHMS OF TIME DOMAIN
SEGMENTATION OF SPEECH SIGNALS
Список литературы Иерархическая модель и базовые алгоритмы временной сегментации речевых сигналов
- Архипов И. О., Гитлин В. Г. Оценка точности выделения основного тона методом GS//Современные речевые технологии: Сборник трудов IX сессии Российского акустического общества. М.: ГЕОС, 1999. С. 38-42.
- Зилинберг А. Ю., Корнеев Ю. А. Разработка и исследование временных и спектральных алгоритмов VAD (Voice Activity Detection)//Российская школа-конференция «Мобильные системы передачи данных». М.: МИЭТ, 2006. С. 5870.
- Кипяткова И. С. Комплекс программных средств обработки и распознавания разговорной русской речи//Информационно-управляющие системы. 2011. № 4. С. 53-59.
- Кипяткова И. С., Карпов А. А. Автоматическая обработка и статистический анализ новостного текстового корпуса для модели языка системы распознавания русской речи//Информационно-управляющие системы. 2010. № 4. С. 2-8.
- Маркел Дж. Д., Грэй А. Х. Линейное предсказание речи: Пер. с англ. М.: Связь, 1980. 308 с.
- Михайлов В. Г., Златоустова Л. В. Измерение параметров речи. М.: Радио и связь, 1987. 168 с.
- Ронжин А. Л., Глазков С. В. Метод автоматического распознавания голосовых команд и неречевых акустических событий//Информационно-управляющие системы. 2012. № 4. С. 74-77.
- Ронжин А. Л., Карпов А. А., Кагиров И. А. Особенности дистанционной записи и обработки речи в автоматах самообслуживания//Информационно-управляющие системы. 2009. № 5. С. 32-38.
- Ронжин А. Л., Карпов А. А., Лобанов Б. М., Цирульник Л. И., Йокиш О. Фонетико-морфологическая разметка речевых корпусов для распознавания и синтеза русской речи//Информационно-управляющие системы. 2006. № 6. С. 24-34.
- Савченко В. В., Акатьев Д. Ю. Результаты экспериментальных исследований методики формирования фонетической базы данных диктора из непрерывного потока его разговорной речи//Информационно-управляющие системы. 2012. № 6. С. 38-42.
- Савченко В. В., Савченко А. В. Метод фонетического декодирования слов в информационной метрике Кульбака -Лейблера для систем автоматического анализа и распознавания речи с повышенным быстродействием//Информационно-управляющие системы. 2013. № 2. С. 7-12.
- Свириденко В. А. Аутентификация личности по голосу//Мобильные системы. 2004. № 2 [Электронный ресурс]. Режим доступа: http://www.spirit.ru/articles/svi_mb.html
- Старченко И. Б., Вишневецкий В. Ю. Практикум по курсу «Математическое моделирование биологических процессов и систем». Таганрог: Изд-во ТТИ ЮФУ, 2010. 36 с.
- Томчук К. К., Зилинберг А. Ю., Корнеев Ю. А. Анализ трендов и разладок структуры ОТ-кластеров вокализованных сегментов речи//Сборник докладов Научной сессии ГУАП. СПб.: ГУАП, 2010. С. 70-73.
- Хованова Н. А., Хованов И. А. Методы анализа временных рядов. Саратов: ГосУНЦ «Колледж», 2001. 120 с.
