Implementation of the fuzzy logic system rule base by self-configuring genetic programming in solving the classification problem

Author: Koshin M.A., Semenkin E.S.
Journal: Siberian Aerospace Journal @vestnik-sibsau-en
Section: Informatics, computer technology and management
Article in issue: 1 vol.27, 2026.
Free access
Fuzzy logic systems are widely used in classification problems due to their ability to handle uncertainty, imprecision, and subjectivity in data. Unlike traditional “crisp” methods, fuzzy logic allows input features and output classes to be described in terms of linguistic variables – such as “high”, “medium”, and “low” – making models more interpretable and aligned with human reasoning. A key limitation of this approach is the need to construct a rule base using expert knowledge, as well as the ambiguity in selecting appropriate membership function shapes. To address these challenges, various optimization algorithms have been developed. One such method is genetic programming, which purpose is to evolve a rule base capable of accurately capturing underlying patterns for correct classification while preserving interpretability through structural adaptation. This article explores the theoretical framework of self-configuring genetic programming combined with differential evolution for constructing fuzzy logic rule bases. It also presents their practical implementation and application to classification tasks.
Evolutionary algorithms, fuzzy logic systems, genetic programming, classification problem, differential evolution, genetic algorithm, self-configuration
Short address: https://sciup.org/148333267
IDR: 148333267 | UDC: 519.6 | DOI: 10.31772/2712-8970-2026-27-1-33-46
Text of the scientific article Implementation of the fuzzy logic system rule base by self-configuring genetic programming in solving the classification problem
Introduction. Most conventional classification algorithms achieve good performance but suffer from poor interpretability. To address this, fuzzy logic systems have been developed, offering greater transparency through:
– Linguistically interpretable rules that are accessible to non-experts.
-
– Transparent membership functions that map input data to fuzzy terms.
-
– The capacity to incorporate expert knowledge throughout the design process.
A significant drawback of fuzzy systems is the requirement to define a rule base during the design phase. This presents a problem, as it may not be feasible to extract the necessary knowledge from human experts. Expert knowledge is often subjective, which can distort the underlying classification patterns. Furthermore, an adequate number of qualified experts may be unavailable, or may not exist at all.
To mitigate this issue, a fuzzy logic component can be integrated that automatically generates a rule base which accurately captures the patterns required for correct classification, eliminating the mandatory reliance on experts. This approach preserves the benefits of fuzzy logic systems – including high interpretability – even in the absence of domain experts, while also reducing design time.
One promising method for implementing this approach is the use of evolutionary algorithms. Techniques such as genetic algorithms, differential evolution (for numerical adaptation), and genetic programming can be employed to evolve a rule base. These algorithms facilitate both numerical adaptation – such as optimizing membership function parameters, and structural adaptation – such as optimizing the number and composition of the rules.
Before detailing the use of evolutionary algorithms for generating a fuzzy rule base, it is essential to understand the theoretical foundations of fuzzy logic systems.
Fuzzy logic systems concept. Fuzzy logic is a mathematical approach for handling imprecise or uncertain data. Unlike classical Boolean logic, which operates with binary values (0 and 1), fuzzy logic operates with degrees of truth (in the range from 0 to 1) [1].
Each element considered in fuzzy logic belongs to a certain set with some degree of truth:
A = { ( x , H A ( x ) ) I x e X } • (1)
The membership function determines how much the element in question corresponds to the fuzzy set. The Gaussian membership function is considered in the framework of the article:
A
H a ( x ) = exp
\
.. 1
The use of the Gaussian membership function in this article is based on the following two considerations: it has only two optimizable parameters, and assuming that the considered terms always corre- spond to real-world attributes of entities, this function is best suited for their description due to the fact that many processes follow a normal distribution.
Within the framework of fuzzy set theory, the concept of a linguistic variable is also considered – a variable whose values are expressed in words or phrases of a natural language. Linguistic variables are used to describe qualitative characteristics in systems where precise quantitative assessments are difficult to apply. The possible values of a linguistic variable are called terms; for each term some value of the membership function is determined. An example of linguistic variable is the “temperature”, for which terms such as “low”, “below normal”, “normal”, “above normal”, “high” can be defined. For such a linguistic variable, if it is considered in the context of human temperature, the temperature of 35.7 °C will be close in terms of the degree of truth to the term “below normal” if the parameters from (2) are set correctly for this term. The membership function appears at the stage of fuzzification, which is the transformation of numerical data into degrees of belonging to terms.
The behavior of the fuzzy logic system is determined by the rule base, which contains a set of logical conditions of the form “if…, then…”, such conditions connect the input linguistic variables with the target. The database is a main component of an important stage of the fuzzy logic system operation – the application of fuzzy rules to solve the problem. An example of the rule base of a fuzzy logic system is shown in Fig. 1.
Testing Accuracy: 95.6522%
If Bill Depth is Medium And Flipper Length is Large And Body Mass is Very Light Then Species is Adelie If Bill Depth is Medium And Flipper Length is Large And Body Mass is Light Then Species is Adelie If Bill Length is Very Large And Flipper Length is Large And Body Mass is Very Light Then Species is Adelie If Bill Length is Large And Bill Depth is Medium And Flipper Length is Large Then Species is Chinstrap If Bill Length is Large And Bill Depth is Medium And Flipper Length is Medium Then Species is Chinstrap If Bill Length is Large And Flipper Length is Large Then Species is Gentoo
If Bill Length is Very Large And Bill Depth is Medium And Flipper Length is Large And Body Mass is Very Heavy
Then Species is Gentoo
If Bill Length is Medium And Bill Depth is Medium And Flipper Length is Large And Body Mass is Very Heavy Then Species is Adelie
If Bill Length is Small And Bill Depth is Medium And Flipper Length is Large And Body Mass is Light Then Species is Adelie
If Bill Length is Small And Bill Depth is Medium And Flipper Length is Large And Body Mass is Light Then Species is Adelie
If Bill Length is Small And Bill Depth is Medium And Flipper Length is Large And Body Mass is Very Heavy Then Species is Gentoo
If Bill Length is Very Large And Flipper Length is Large And Body Mass is Very Heavy Then Species is Gentoo If Flipper Length is Large And Body Mass is Very Light Then Species is Chinstrap
Рис. 1. База правил классификации пингвинов. Данный пример демонстрирует, что построенная база правил для классификации пингвинов четко определяет принципы реализации процесса классификации
-
Fig. 1. The rule base of the Palmer penguin classification system. This example demonstrates that the rule base constructed for penguin classification clearly outlines the principles for implementing the classification process
The rule base is derived from the knowledge of experts involved in the system’s design. However, such expertise is not always available due to several factors, including a scarcity of qualified experts, the inherent subjectivity of their judgments, and the consequent inconsistency in their knowledge.
Each term of a linguistic variable is assigned a membership function with a specific shape and parameters. For a fuzzy logic system to function correctly, its rule base must be adequately designed, maintaining a structure that is both comprehensible and interpretable.
Once the intended pattern is captured, the final stage of the fuzzy logic process – defuzzification – takes place. This process converts the fuzzy output into a precise, crisp numerical value.
Thus, two key tasks are essential for implementing a fuzzy logic system: first, developing a rule base that accurately describes the desired pattern, and second, selecting membership functions for each term that ensure high model accuracy. To address these challenges, self-adaptive evolutionary algorithms can be employed [2]. Their application provides a solution for optimizing both the membership function and the structure of the rule base simultaneously.
Self-configurable evolutionary algorithms. Evolutionary algorithms (EAs) are a class of optimization techniques inspired by the process of natural selection [3]. The algorithm begins by initializing a set of candidate solutions, referred to as individuals. These individuals are encoded in a way that permits modifications to their structure through operations such as mutation and crossover. Crossover is not a random process; it is guided by selection mechanisms designed to choose the most fit parents. This ensures that individuals in subsequent generations can inherit beneficial traits from their predecessors – a process termed selection within evolutionary algorithm theory. Specific implementations of selection, crossover, and mutation operators define different types of evolutionary algorithms, including genetic algorithms [4], genetic programming [5], and differential evolution [6]. The primary distinctions between these algorithms lie in their representation of an individual's structure and the consequent implementation of the operators that modify it.
Genetic algorithm. The Genetic Algorithm (GA) is a stochastic process that simulates natural evolution. A key characteristic of the canonical genetic algorithm is its representation of an individual's genotype as a binary string. Consequently, the crossover and mutation operations involve manipulating this binary string. When decoded into a decimal form, the modified string yields the parameters of new candidate solutions, which ideally combine the best traits of the parent population or introduce novel variations. The versatility of genetic algorithms allows them to be applied to a wide range of problems by framing them as optimization tasks, where every candidate solution can be evaluated using a fitness function.
In the context of fuzzy logic systems, GA is often employed for designing the rule base. Two primary methodologies for this are the Pittsburgh and Michigan approaches. This article considers a hybrid method that combines both [7]. The core algorithm follows the Pittsburgh approach, where each individual represents an entire rule set, while the Michigan approach is incorporated as a mutation operator. Furthermore, this variant features self-configuration, which adapts the probabilities of selecting different structural modification operators based on their historical performance. This GA variant offers several advantages, including interpretability, automated parameter tuning, and flexibility, meaning the ability to adapt to various problem types. An example of an individual's representation in this GA variant is shown in Fig. 2.
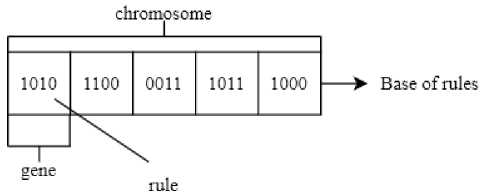
Рис. 2. Пример представления особи в генетическом алгоритме
-
Fig. 2. Individual example in the GA implementing the rule base
A significant drawback observable in this representation is the “rigid” coding scheme, stemming from a fixed rule structure and a chromosome of fixed length. To overcome this limitation, genetic programming can be utilized, as its representation allows for the evolution of a more compact and simplified rule base.
Genetic programming. Genetic Programming (GP) is a method within the class of evolutionary algorithms, characterized by its use of a tree-like structure to represent an individual. This representation involves defining functional and terminal sets. The terminal set comprises variables and constants, while the functional set consists of operations performed on the elements of the terminal set. Conse- quently, the tree structure of an individual necessitates specific implementations for the genetic operators that modify it, such as crossover and mutation.
When applied to fuzzy logic systems, the terminal set for genetic programming can be defined by the terms of the target linguistic variable:
T = {u1 , u2 , ..., u n }. (3)
The functional set can be introduced as an operation that distinguishes terms from different linguistic variables, thereby assigning them to rules corresponding to the various terms of the target linguistic variable. An example of an individual's representation for a rule base implemented with genetic programming – considering a case with two linguistic variables and one target variable – is illustrated in Fig. 3.
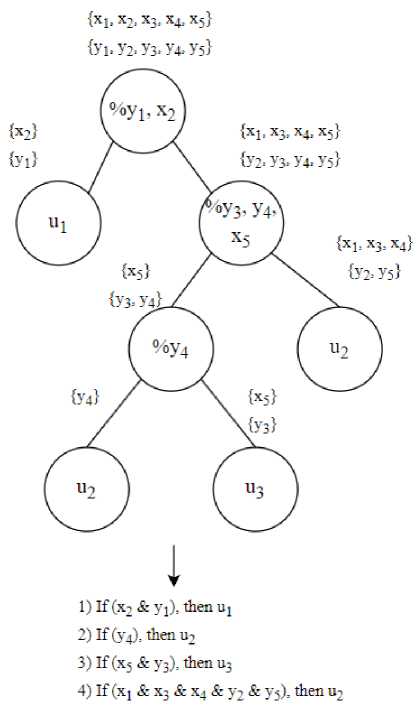
Рис. 3. Пример представления особи в генетическом программировании
-
Fig. 3. Individual example in the GP implementing the rule base
Thus, each individual in the population represents a complete rule base candidate for use in the fuzzy logic system. Over successive generations, the most suitable rule base is evolved and selected as the final output.
This approach facilitates the creation of a structurally diverse rule base that comprehensively captures the patterns necessary for the system's correct operation. However, as manually configuring such an algorithm can be time-consuming, a self-adaptation method is proposed to automate this process. When multiple operator variants are available for modifying an individual's structure, operator-level self-configuration can be employed to identify the most effective set of operators for the given problem. Initially, the considered types of crossover, mutation, and selection operators are assigned equal probabilities of being applied to the GP population. A self-configuration system, as depicted in Fig. 4, manages this process.
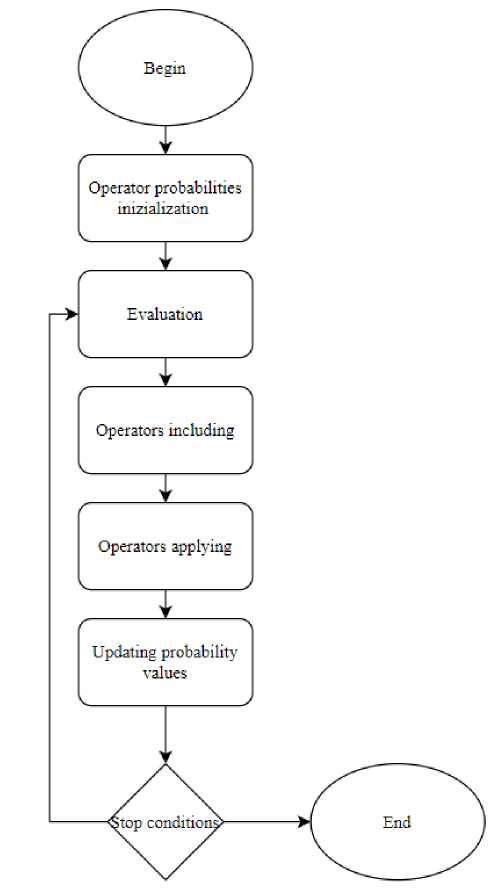
Рис. 4. Блок-схема самоконфигурации
Fig. 4. Self-configuration flowchart
As the algorithm progresses, the probability of selecting a high-performing operator increases, while the probabilities of others decrease. The decreasing probabilities are bounded by a predefined lower limit, which guarantees the continued use of all operators to some extent.
This methodology allows the algorithm to favor more effective operator combinations while maintaining operator diversity through the probability floor. Once the rule base is formed, a membership function is defined for each term within the rules. Consequently, the total number of parameters to be optimized is proportional to the total number of terms. To optimize the parameters of these membership functions, which constitutes a high-dimensional search problem, methods known for their efficacy in such spaces, like differential evolution, are required.
Differential evolution. Differential evolution is the third evolutionary algorithm considered in the framework of the article. Its main difference from other evolutionary algorithms is the implementation of the crossing and mutation operators, corresponding to the vector representation of the individual, an example of which is shown in Fig. 5.
|
10.1 |
29 |
31.5 |
42.21 |
43.21 |
44.142 |
51.1 |
52 |
Рис. 5. Пример индивида в дифференциальной эволюции
Fig. 5. Example of differential evolution individual
Considering the possibility of varying the parameters ( с , σ ) in the membership functions of each term, which have the form (2), it is advisable to combine differential evolution with the GP to correct these parameters in accordance with the same criterion that is used to assess the quality of classification.
Approach description. The article discusses an approach that employs self-configurable genetic programming to evolve a fuzzy rule base, combined with a differential evolution algorithm, specifically L-SRTDE [8], for optimizing membership function parameters. The implementation of this system necessitates the following steps:
– Identify the linguistic variables required to represent the numerical variables pertinent to the problem and define their respective terms.
– Implement the self-configurable GP and adapt the DE to optimize the parameters of the predefined membership function shapes.
– Within the genetic programming framework, define the target linguistic variables as the terminal set. The functional set should include operators for constructing rules by combining terms. The parameters of the membership functions for each term are subject to optimization by the differential evolution algorithm.
– Define the fitness function for both GP and DE based on a criterion that reflects solution quality. Given the classification context, classification accuracy is adopted as the primary fitness criterion.
– Set the initial hyperparameters for GP and DE. For genetic programming, the selection of specific selection, crossover, and mutation operators is automated by the self-configuration mechanism, eliminating the need for manual operator selection.
– Validate the algorithm on benchmark classification tasks. Upon successful validation, the system can be deployed for the intended classification problems.
– The fitness of a genetic programming individual is evaluated after the parameters of the membership functions have been optimized. Specifically, the fitness value of an individual in GP is set equal to the fitness value of an individual in DE, with the latter being computed within the evaluation procedure of the GP fitness function.
A conceptual representation of such a system is shown in Fig. 6.
The resulting system integrates algorithms for both automatically generating and optimizing a rule base, and for deploying this rule base within a fuzzy logic system to solve classification tasks. While classification accuracy is used here, the fitness function can be substituted with other quality metrics if they are deemed more suitable for a given problem, without critically altering the framework. The composition of the terminal and functional sets, as described, provides a sufficient foundation for constructing a rule base for a wide range of problems.
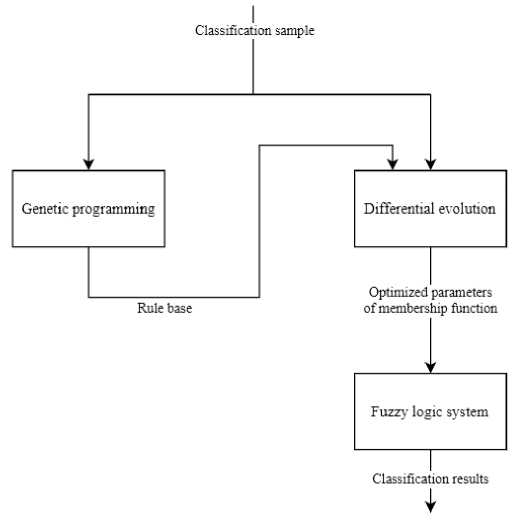
Рис. 6. Концепция комбинирования ГП и ДЭ
Fig. 6. Combining GP and DE concept
Testing. Two tasks were selected as test tasks: the task of classifying Fisher's irises [9], and the task of classifying Palmer penguin species [10].
In the first case, four parameters are presented as linguistic variables: the length and width of the outer lobe of the perianth, and the length and width of the inner lobe of the perianth. For each linguistic variable, five terms are defined that characterize the values of linguistic variables in the verbal range: very small, small, medium, large, very large. The target linguistic variable is a class characterized by three terms.
In the second case, four features are also presented as linguistic variables. The target linguistic variable is the penguin species: Adelie, Gentoo, Chinstrap. The initial parameters of self-configurable genetic programming are shown in Table 1.
Initial parameters of self-configurable genetic programming during testing
Table 1
|
Parameter |
Value |
|
Generation number |
40 |
|
Population size |
35 |
|
Probability limit |
0.1 |
|
Tree depth |
5 |
|
Number of runs |
30 |
Accordingly, since the GP method is stochastic, the results were averaged based on 30 runs of the algorithm. Initialization parameters were selected empirically, the depth value is set arbitrarily.
The initial parameters of differential evolution for optimizing membership function parameters are shown in Table 2.
Initial parameters of differential evolution during testing
Table 2
|
Parameter |
Value |
|
Generation number |
60 |
|
Population size |
30 |
The initial parameters of the genetic algorithm for optimizing membership function parameters are shown in Table 3.
Initial parameters of genetic algorithm during testing
Table 3
|
Parameter |
Value |
|
Generation number |
60 |
|
Population size |
30 |
|
Type of selection |
Tournament |
|
Epsilon |
0.0001 |
Since the modification of L-SRTDE is considered as the DE used, the crossing coefficient and the mutation coefficient are adaptively selected depending on the success rate. The test results of the differential evolution and genetic programming combination are shown in Table 4.
The results of DE and GP combination test
Table 4
|
Sample |
Criterion |
Average |
MSE |
|
Fisher’s Irises |
Accuracy (train) |
0.9823 |
0.00006 |
|
Accuracy (test) |
0.9311 |
0.0013 |
|
|
Penguins |
Accuracy (train) |
0.963467 |
0.000172 |
|
Accuracy (test) |
0.931733 |
0.000602 |
The test results of the genetic algorithm and genetic programming combination are shown in Table 5.
The results of GA and GP combination test
Table 5
|
Sample |
Criterion |
Average |
MSE |
|
Fisher’s Irises |
Accuracy (train) |
0.962 |
0.00022 |
|
Accuracy (test) |
0.912 |
0.0152 |
|
|
Penguins |
Accuracy (train) |
0.94252 |
0.00081 |
|
Accuracy (test) |
0.931733 |
0.00162 |
Based on the results obtained, it can be concluded that for the test problems, the combination of genetic programming and differential evolution yields superior performance. In addition, it is noteworthy that the second combination (GP+GA) required greater computational resources to solve the problem.
The first combination of algorithms (GP+DE) demonstrates robust performance for classification tasks within the fuzzy logic system. Despite this, the approach can be further improved by optimizing the membership function parameters after the formation of each individual in the GP, thereby fostering competition among the most suitable candidates.
It should be noted that the proposed approach is computationally expensive in terms of RAM and processing time. However, for problems where high interpretability is required and expert knowledge for rule base formation is insufficient, this approach represents a well-justified solution.
Validation. To validate the algorithms, the following samples were selected for classification: German credit data [11], Australian credit approval [12], and data on heart disease [13].
The first dataset contains information about the credit history of German bank customers and includes 1,000 observations and 20 variables (9 categorical and 7 numeric, as well as an identifier and a target variable). The target variable is binary: “good” (1) or “bad” (2) is credit risk, where “good” means that the customer pays off the loan on time, and “bad” means that there is a high risk of default. The signs include information about age, gender, marital status, employment, loan amount, loan term, availability of guarantors, and credit history. The peculiarity of the data is a strong class imbalance (about 70% of “good” borrowers and 30% of “bad” ones), which makes the classification task difficult. In this regard, accuracy for a given sample means weighted accuracy.
The second dataset is anonymized (feature names have been replaced with abbreviations) and contains 690 observations and 15 variables (6 numeric, 8 categorical, and a target variable). The target variable is binary: 0 (loan denial) or 1 (loan approval). The signs include information about income, age, credit history, property, marital status. The special feature of the data is the absence of gaps and careful preprocessing (all string values are replaced with numeric codes), which makes them convenient for validation algorithms.
The third dataset contains the medical records of patients and includes 303 observations (after removing the gaps – 297) and 14 variables. The target variable is the presence of heart disease (0 – healthy, 1 – sick). Signs include age, gender, type of chest pain, blood pressure, cholesterol levels, ECG results, pulse. The special feature of the data is its small size and the presence of gaps, which requires pre-processing. Since the tasks under consideration have a larger dimension compared to the test samples, more resources have been allocated to work with them.
Tables 6, 7, and 8 present the initial parameters of genetic programming, differential evolution, and the genetic algorithm during validation, respectively.
Table 6
Initial parameters of self-configurable genetic programming during validation
|
Parameter |
Value |
|
Generation number |
40 |
|
Population size |
60 |
|
Probability limit |
0.1 |
|
Tree depth |
8 |
|
Number of runs |
30 |
Initial parameters of differential evolution during validation
Table 7
|
Parameter |
Value |
|
Generation number |
75 |
|
Population size |
45 |
Table 8
Initial parameters of genetic algorithm during validation
|
Parameter |
Value |
|
Generation number |
75 |
|
Population size |
45 |
|
Type of selection |
Tournament |
|
Type of crossing |
One-point |
|
Epsilon |
0.0001 |
The validation results of the differential evolution and genetic programming combination are shown in Table 9.
Table 9
The results of DE and GP combination validation
|
Sample |
Average |
MSE |
Max |
Min |
|
|
German credits |
Train |
0.6725 |
0.009528 |
0.69 |
0.65 |
|
Test |
0.63075 |
0.023912 |
0.675 |
0.59 |
|
|
Australian credits |
Train |
0.6515 |
0.009366 |
0.671506 |
0.629764 |
|
Test |
0.63285 |
0.036069 |
0.71223 |
0.561151 |
|
|
Heart disease |
Train |
0.7914 |
0.0074 |
0.81 |
0.7625 |
|
Test |
0.771 |
0.0216 |
0.815 |
0.74 |
|
The validation results of the genetic algorithm and genetic programming combination are shown in Table 10.
Table 10
The results of GA and GP combination validation
|
Sample |
Average |
MSE |
Max |
Min |
|
|
German credits |
Train |
0.6525 |
0.00821 |
0.6625 |
0.6425 |
|
Test |
0.6125 |
0.0419 |
0.635 |
0.5825 |
|
|
Australian credits |
Train |
0.6425 |
0.00881 |
0.65 |
0.635 |
|
Test |
0.62 |
0.0528 |
0.61 |
0.59 |
|
|
Heart disease |
Train |
0.7615 |
0.0084 |
0.7725 |
0.75 |
|
Test |
0.7412 |
0.0452 |
0.76 |
0.735 |
|
The first conclusion based on the results is that during both validation and testing, the combination of genetic programming and differential evolution consistently delivers better results. The statistical significance was assessed using the Wilcoxon test, which was applied to the raw results from 30 independent runs, revealing a significant difference (α = 0.05).
Conclusion
The research presented in this article has empirically evaluated a hybrid approach for the automated design of fuzzy logic systems applied to classification problems. The proposed methodology synergistically combines self-configuring genetic programming for the structural evolution of the rule base with differential evolution for the parametric optimization of the membership functions. The core objective was to circumvent the well-known bottleneck of fuzzy logic systems design – the reliance on subjective and often unavailable expert knowledge for rule base construction – while preserving the model's interpretability.
The experimental results, validated on both benchmark and real-world datasets, lead to several key conclusions. Firstly, the evolutionary framework successfully generates rule bases that adequately capture the underlying patterns necessary for correct classification. The combination of GP and DE consistently outperformed the hybrid of GP and a standard GA in terms of classification accuracy across all tested scenarios. This superior performance, coupled with the lower computational resource requirements of DE for high-dimensional parameter optimization, establishes the GP and DE combination as the more effective and efficient variant of the proposed approach.
However, the analysis also reveals a fundamental compromise inherent in this method. The primary advantage of the evolved fuzzy logic system is its high interpretability, providing a transparent, human-readable set of linguistic rules. This comes at the cost of a reduction in average predictive accuracy when com-pared to conventional “black-box” classifiers.
Several limitations and avenues for future improvement have been identified:
-
– Computational Complexity: the nested optimization process, where DE fine-tunes membership functions for each candidate rule base in the GP population, is computationally intensive. This limits the approach's applicability to very large datasets or real-time systems. Future work could investigate surrogate models or more efficient optimization schedules to mitigate this cost;
-
– Data Preprocessing and Dimensionality: the performance of the system is like-ly sensitive to the quality of data preprocessing and the initial definition of linguistic variables. The method's performance on complex, high-dimensional datasets may be constrained by the resulting search space explosion. Techniques for automated feature selection or dimensionality reduction prior to the evolutionary process could be integrated to enhance scalability;
-
– Deanonymization Potential: a notable, albeit secondary, finding is that the interpretable nature of the evolved rule bases could potentially facilitate the deanonymization of sensitive datasets. This raises important considerations for the application of such methods in privacy-critical domains like finance and healthcare, warranting further investigation into privacy-preserving evolutionary techniques;
-
– Fitness Function Design: while classification accuracy was used as the fitness criterion, the interpretability of the resulting rule bases was not explicitly quantified or optimized. Future iterations could incorporate multi-objective optimization to explicitly balance accuracy with interpretability metrics, such as rule simplicity or comprehensibility, potentially yielding more compact and intuitive models.
In summary, the self-configuring GP and DE hybrid presents a robust and justified methodology for constructing fuzzy logic system in scenarios where expert knowledge is scarce and model interpretability is a critical requirement. Despite its computational demands and the inherent accuracyinterpretability compromise, it offers a powerful, automated pathway to creating transparent and effective classifiers, thereby advancing the goals of explainable artificial intelligence.
Acknowledgment. This research was supported by the Russian Science Foundation (project № 25-19-20154, , and the Krasnoyarsk Regional Science Foundation.
