Increasing software reliability of a distributed control systems

Author: Strelavina O.D., Efimov S.N., Terskov V.A., Likharev M.A.
Journal: Siberian Aerospace Journal @vestnik-sibsau-en
Section: Informatics, computer technology and management
Article in issue: 3 vol.22, 2021.
Free access
The article considers a method of assessing and improving main parameters of the computer network efficiency. Reliability is the main criteria for ensuring the required performance of distributed control systems. To improve reliability of the computer network hardware and software redundancy are used. Software redundancy requires new versions to be developed for software modules in which failures are likely to occur. The article considers the N-version programming and recovery block as methods of introducing software redundancy and, taking the need to develop multiple versions of the same software module into account, estimates the costs of network software development. To implement the proposed approach article presents mathematical reliability model that takes into consideration the architecture of a computer network software and the labor costs that its development is going to require. This model becomes a basis for a software created to research computer network software reliability, which allows finding the dependence of network software reliability on the number of one of its software module versions. Comparison of the dynamics changes of reliability indicators and labor intensity of software development indicated a sufficient amount of software module versions that need to be developed. The article concludes by pointing out the importance of determining the labor intensity of network software development and of its usage in the design of a computer networks in which reliability is increased through software redundancy.
Computer network reliability, software reliability, software redundancy, reliability model, labor intensity
Short address: https://sciup.org/148329579
IDR: 148329579 | DOI: 10.31772/2712-8970-2021-22-3-459-467
Text of the scientific article Increasing software reliability of a distributed control systems
The quality of any computer network (CN) can be assessed using its main characteristics. These include the completeness of the functions performed, performance, throughput, reliability, security, transparency, scalability and versatility [1]. None of these criteria can definitely be called the most important, but among them there are several of the most significant. One of such criteria is reliability [2–5].
Reliability is the ability of the computer network (CN) to reliably perform certain functions under given conditions for a given period of time with a sufficiently high probability [6-8]. With a low level of reliability of the CN, the functionality of systems responsible for indicators of other quality criteria will also be affected. Therefore, ensuring the reliability of the CN is a priority task when building a computer network [9].
It is impossible to eliminate the possibility of failures, and therefore ensuring reliability is to reduce the number of errors that a user may encounter during the operation of the network. One of the most proven and trusted ways to increase reliability is the introduction of redundancy [10; 11].
In the hardware of the CN, redundancy serves to deal with periodically failing processors and buses. Hardware redundancy is introduced by reserving processor elements and interface buses. The required number of duplicated hardware components varies and depends on the failure rate and recovery time. Calculating the optimal number of these components is the main difficulty of introducing hardware redundancy.
Software redundancy cannot be achieved by duplication as errors that occur in software modules have an internal nature [12], which leads to the appearance of the same errors in identical copies. Therefore, instead of copies, it is necessary to create new versions that differ from each other in the programming language, the programmers who developed them, and the algorithms used. Due to internal differences between different versions, the probability of similar failures is minimized [13; 14].
Software redundancy is not applied to the entire program or software package – it is used to increase the reliability of modules that are critical for the functioning of the entire network as a whole or to which users and other modules most often turn [15]. As in the case of hardware redundancy, the number of introduced versions of software modules must be selected for each individual network, which, combined with the labor costs of developing new versions, indicates a non-trivial task of effectively using software redundancy. To conduct research on this problem, a mathematical model to assess the reliability of the software is used.
Software reliability assessment model
The reliability of the network software is affected by its hierarchical levels – the dependence of software modules on each other can lead to a failure in one module spreading across the architecture of the entire network software [16]. The model describing the reliability of the network software should take into account the influence of the hierarchy of software modules on failures and downtime [17].
Designations used in the model:
-
1) M – the number of architectural levels in the architecture of the network software;
-
2) N j is the number of modules at the level j , j ∈ {1, ..., M };
-
3) D ij is the set of module indexes that depend on module i at the level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M };
-
4) F ij is a failure event that occurred in module i at level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M };
-
5) PU ij is the probability of using module i at level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M };
-
6) PF ij is the probability of a failure in module i at level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M };
-
7) PL ij - conditional probability of a failure in module m at level n when a failure occurs in module i at level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M }, n ∈ {1, ..., N m }, m ∈ {1, ..., M };
-
8) TA ij is the relative access time to module i at level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M }, defined as the ratio of the average access time to the module i at level j to the number of failed modules at small levels of the architecture at the same time;
-
9) TC ij is the relative time of the failure analysis module i to level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M }, which is defined as the average time of failure analysis in the module i at the level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M }, to the number of failed modules at all levels of architecture, analyzed at the same time;
-
10) TE ij is the relative time for Troubleshooting in the module i to level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M }, defined as the ratio of the mean recovery time in the module i at the level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M }, to the number of failed modules at all levels of the architecture, which is a fault at the same time;
-
11) TU ij – relative time of the module being used i at the level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M }, which is defined as the average usage time of module i at the level j , i ∈ {1, ..., N j }, j ∈ {1, ..., M }, to the number of modules at all levels of the architecture used at the same time;
-
12) Z ij – the set of versions of module i , at the level j , k = 1, ..., K ;
-
13) T ij – the labor intensity of developing module i at level j ;
-
14) T k – the labor intensity of developing version k of module i at level j , k ∈ Z ij in person-hours;
-
15) NVX ij – the labor intensity of developing an acceptance test (for RB ) or a voting algorithm (for NVP );
-
16) T s – total network labor intensity;
-
17) B ij is a dichotomous variable that takes the value 1 (then NVP ij = 0, RB ij = 0), if in the software module software redundancy is not used , otherwise it is equal to 0;
-
18) NVP ij is a dichotomous variable that takes the value 1 (then B ij = 0, RB i = 0) if the software module uses N -version programming software redundancy, otherwise it is equal to 0;
-
19) RB ij is a dichotomous variable that takes the value 1 (then B ij = 0, NVP ij = 0) if the software module uses software redundancy according to the recovery block method, otherwise it is equal to 0;
-
20) TR is the average downtime of the CN software, defined as the time during which the system cannot perform its functions;
-
21) MTTF is the average time of occurrence of a failure in the network software of the CN, defined as the time during which there are no failures in the system;
-
22) S is the readiness coefficient of the CN software;
-
23) T s is the total labor intensity of the implementation of the network software.
The average failure time of the network software of the computer network is equal to:
M Nj
MTTF=SS{ PUj «(1 - PFj )x [ TU + j=1 i =1
( Лк x TUnm + S ((1 - PL™ )x TUim )
к l ^ D nm ) )
M Nm ,
+ S S (1 - PLjm )
+
( m = 1 ) & ( m * j ) n = 1 к
+
(
S ( 1 - PL ,
k £ D ij
к
(
x TU. +
к
M Nm
У Ш1 - PLkLV( тип + nm nm
( m = 1 ) & ( m * j ) n = 1
+ S ( ( 1 - pL m ) x TU m ) ))))]}.
l e D nm
The average downtime of the network software of the computer network is equal to:
MM j
TR = SS{PUij xPFij x[(TAj + TCij + TE,) + j=1 i=1
M Nm
+ S S P j x
( m = 1 ) & ( m * j ) n = 1 к
кк
(TAnm + TCnm + TEnm ) + S (P^ x (TAlm + TClm + TElm ))
x
l eDnm) )
x S [ PL x[(TA. + TCtl+ k e Dij
M N m
+ S S PL - ( m = 1 ) & ( m * j ) n = 1 к
кк
(TAnm + TCnm + TEnm) + S (PLm x (TAm + TClm + TEm )) l£Dnm) )
Both of these formulas take into account the hierarchy of modules and therefore are universal for any network software with architectural levels. According to them, the readiness coefficient of the software part of the CN is also determined:
MTTF
= MTTF + TR
.
By themselves, these indicators consider the reliability of the network software of the computer network only in its initial state. Two main methods of introducing multiversion are described in [18]: NVP ( N- version programming) and RB (recovery block).
NVP implies that all versions of the program are executed in parallel, and the result of their work is determined using the voting algorithm [19]. The reliability of the multiversion module i at the level j , built from K versions by the method of multiversion programming for any k , is equal to
R j = p v 1 - n ( 1 - p k ) ,
k = 1
where p v is the probability of failure-free operation of the voting algorithm; p k - the probability of failure-free operation of version k e Z ij .
With the RB approach, multiversion is introduced through the addition of several versions of the computing module, the creation of an acceptance test that verifies the operation of the versions, and a subprogramme that, based on the test results, either accepts the result of the module, or selects another version and restarts the calculation [19]. Reliability of such a module:
Kk
Rij =S pikpAT П((1 - 4) pi+pj (i - pAT)), ke ZijI where pAT is the probability of failure-free operation of the acceptance test for module i, i = 1, ..., N at level j, j = 1, ..., M; pk is the probability of failure of version ke Zij.
For any of the approaches, the probability of failure will be calculated as
PE. = \-R... ijij
When introducing software redundancy, the question always arises: exactly how many versions is needed to introduce? The possibility of using multiversion is limited by many factors. One of the most significant of them is the labor intensity, reflecting the labor costs on building a network, directly dependent on the number of versions of software modules that need to be developed. To reflect this limitation, the model has the formula [20]:
MN i
T s = YL j = 1 i = 1
BT + ( NVP
+ RB ij V
K
NVX„ ■ YT ij ij k eZij )
In the study of CN, this indicator can be used to find the optimal number of versions for each software module. There are different ways to explore the network, but they all have the same points: the labor intensity of T s should strive for a minimum, and the readiness factor S should strive for a maximum.
Investigation of the reliability of the network software
Based on the considered model, a software system has been developed that allows calculating the reliability of the network software and conducting research on the specified input data.
To conduct the study, consider the network software consisting of 10 modules. Assume that all modules, with the exception of one, work without failures (i.e. have reliability equal to 1). The overall reliability of the software will be determined by the reliability of the critical module with a value of 0.55. Software redundancy is introduced into it by the NVP method, the complexity of developing new versions of this module is taken for 1000.
The table shows the results of the dependence of the reliability indicators of the network software on the versions of one of its modules, and the figure clearly shows the dynamics of parameter changes.
Results of the network software study
|
Number of critical module versions |
Average downtime |
Average time before the failure |
Readiness ratio |
Labor intensity |
|
1 |
82115 |
169838 |
0.5500 |
6981 |
|
2 |
47509 |
175844 |
0.7975 |
7981 |
|
3 |
21373 |
180379 |
0.9089 |
8981 |
|
4 |
9619 |
182420 |
0.9590 |
9981 |
|
5 |
4340 |
183336 |
0.9815 |
10981 |
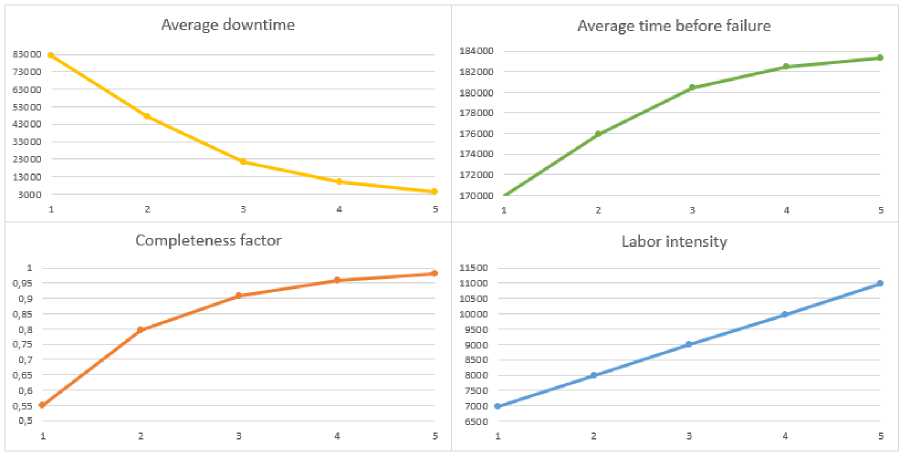
Computer network software parameters’ change dynamics Динамика изменения параметров ПО ВС
Conclusion
The obtained graphs allow us to determine the number of new versions of the dedicated module, at which the increase in the cost of developing a new software element begins to exceed the increase in software reliability. At some point, the introduction of new versions ceases to be expedient, since the costs begin to exceed the returns received.
In the situation chosen for the example, the reliability of the entire network software depends on one of its modules. When designing real network software, there will be significantly more such modules, which will greatly complicate the task of research. This underlines the importance of the labor intensity parameter, which is determined by the model along with the reliability of the network software. Comparing the increase in labor costs with the increase in the software reliability of the network, you can see at what point you should stop adding new versions of software modules.
Thus, an approach was considered that allows both evaluating and improving such parameters of the network software as reliability and labor costs. To do this, on the basis of a mathematical model for assessing reliability and labor costs for development, the software was created to study the dependence of the reliability of the software and labor costs for its development on the number of versions for problematic, from the point of view of reliability, software modules. The dynamics of changes in the parameters of reliability of network software and labor costs for its development from the number of versions of one of its software modules is analyzed. From the results obtained, it can be concluded that it is important to take into account the complexity parameter when studying the reliability of a network into which software redundancy is introduced.
References Increasing software reliability of a distributed control systems
- Kuzin A. V. Komp'yuternye seti [Computer networks]. Moscow, Forum: Infra-M Publ., 2011, 192 p.
- Makaruk R. V. [Fuzzy models and a software package for analyzing the characteristics of a computer network]. Nauchnye vedomosti belgorodskogo gosudarstvennogo universiteta. Seriya: ekonomika. informatika,. 2013, No. 22, P. 161–166 (In Russ.).
- Efimov S. N., Tynchenko V. V., Tynchenko V. S. [Design of computing network with efficient architecturefor complex problems distributed solving]. Vestnik SibGAU. 2007. No. 3, P. 15–19 (In Russ.).
- Efimov S. N. [The industrial distributed control system reliability estimation]. Promyshlennye ASU i kontrollery. 2011, No. 9, P. 15–19 (In Russ.).
- Rasulov M. M. [Software reliability assessment]. Aktual’nye nauchnye issledovaniya v sovremennom mire. 2020, No. 6, P. 112–116 (In Russ.).
- Lozhkov A. V. [Methodology for assessing the reliability of a computer network]. Nauchnye zapiski molodykh issledovateley. 2014, No. 4, P. 28–31 (In Russ.).
- Gurov S. V., Polovko A. M. Osnovy teorii nadezhnosti [Fundamentals of the theory of reliability]. St.Petersburg, BKhV-Peterburg Publ., 2006, 704 p.
- Brzhozovskiy B. M., Martynov V. V., Skhirtladze A. G. Diagnostika i nadezhnost’ avtomatizirovannykh sistem [Diagnostics and reliability of automated systems]. Moscow, TNT Publ., 2013, 352 p.
- Vorotnikova T. Y. [Research of the development of increasing the software reliability issue]. Globus. 2019, No. 11, P. 42–45 (In Russ.).
- Shubinskiy I. B. Nadezhnye otkazoustoychivye informatsionnye sistemy. Metody sinteza [Reliable fault-tolerant information systems. Synthesis methods]. Ulyanovsk, Pechatnyy dvor Publ., 2016, 547 p.
- Gruzenkin D. V., Kamysov S. S. [Application of software redundancy to increase software reliability]. Novaya nauka: Ot idei k rezul’tatu. 2016, No. 9, P. 9–11 (In Russ.).
- Naumov A. A., Aydinyan A. R. [Software reliability and methods to improve it: Don’s Engineering Bulletin]. Nadezhnost’ programmnogo obespecheniya i metody ee povysheniya. Inzhenernyy vestnik Dona. 2018, No. 2. (In Russ.). Available at: http://ivdon.ru/ru/magazine/archive/ n2y2018/4946 (accessed 10.05.2021).
- Kovalev P. V. [The reliability research of n-version software using methods of network analysis]. Vestnik SibGAU. 2009, Vol. 22, № 1-2, P. 56–59 (In Russ.).
- Pozdnyakov D. A. Komponentnaya programmnaya arkhitektura mul’tiversionnykh sistem obra- botki informatsii i upravleniya. Dis. kand. tekhn. nauk. [Component software architecture of multiversion information processing and control systems. Cand. techn. sci. diss.]. Krasnoyarsk, 2006, 126 p.
- Tynchenko V. V., Tsarev R. Yu. [Toward the problem of evaluation of the reliability of software with multiple level architecture]. K voprosu otsenki nadezhnosti programmnogo obespecheniya s mnogourovnevoy arkhitekturoy. Sovremennye problemy nauki i obrazovaniya. 2015, No. 2-1 (In Russ.). Available at: http://science-education.ru/ru/article/view?id=20878 (accessed: 18.04.2021)
- Karavanov A. V., Ivanov N. D [Software architecture for highly reliable systems]. Kosmicheskie apparaty i tekhnologii. 2018, No. 2, P. 100–104 (In Russ.).
- Rusakov M. A. Mnogoetapnyy analiz arkhitekturnoy nadezhnosti v slozhnykh informatsionno-upravlyayushchikh sistemakh. Dis. kand. tekhn. nauk [Multi-stage analysis of architectural reliability in complex information management systems. Cand. techn. sci. diss.]. Krasnoyarsk, 2005, 168 p.
- Novoy A. V. Sistema analiza arkhitekturnoy nadezhnosti programmnogo obespecheniya. Dis. kand. tekhn. nauk. [Software architectural reliability analysis system. Cand. techn. sci. diss.]. Krasnoyarsk, 2011, 131 p.
- Kovalev I. V., Novoy A. V. [Software architecture for highly reliable systems]. Vestnik SibGAU. 2007, No. 4, P. 14–17 (In Russ.).
- Sheenok D. A. Mnogokriterial'naya optimizatsiya otkazoustoychivoy programmnoy arkhitektury spetsializirovannymi evolyutsionnymi algoritmami. Dis. kand. tekhn. nauk. [Multi-criteria optimization of fail-safe software architecture by specialized evolutionary algorithms. Cand. techn. sci. diss.]. Krasnoyarsk, 2013, 84 p.
