Информационная поддержка процессов анализа и оценки учебных и научно-технических работ обучающихся

Автор: Тархов Сергей Владимирович, Минасова Наталья Сергеевна, Калимуллина Гульназ Рустэмовна
Журнал: Образовательные технологии и общество @journal-ifets
Статья в выпуске: 3 т.18, 2015 года.
Бесплатный доступ
В статье приведена теоретико-множественная математическая модель и метод многофункционального анализа текста учебных и научно-технических работ обучающихся, показаны основные этапы анализа текста документов. Описаны основные действия, выполняемые экспертом в процессе автоматизированного анализа содержательной части документов, позволяющие: оценить приведенный в анализируемом документе список литературы, а также использование ссылок на литературу в тексте документа; осуществить поиск интересующей эксперта информации, содержащейся в документе; оценить качество документа путем анализа конгруэнтности текстов в его разделах. Рассмотрена практическая реализация метода многофункционального анализа текстового документа. Приведены описания разработанного программного продукта Multifunctional Text Analyzer и схема его работы.
Обучение, оценка работ, семантический анализ, анализ текстов
Короткий адрес: https://sciup.org/14062639
IDR: 14062639
Текст научной статьи Информационная поддержка процессов анализа и оценки учебных и научно-технических работ обучающихся
Современные процессы обучения в образовательных учреждениях различного уровня неразрывно связаны с обработкой, анализом и оценкой значительного числа текстовых учебных и научно-технических документов: рефератов; пояснительных записок к курсовым работам и проектам; выпускных квалификационных работ, докладов и статей на молодежные конференции; конкурсных научно-исследовательских работ; магистерских диссертаций; диссертаций на соискание ученой степени кандидата наук и др. Анализ содержательной части таких документов и их последующая оценка занимает значительную часть рабочего времени преподавателей и сотрудников, в функциональные обязанности которых входит проверка и обработка документов. Традиционные подходы к проведению анализа содержательной части учебных и научно-технических работ обучающихся во многом субъективны и требуют существенной формализации с целью обеспечения эффективной информационной поддержки при принятии решений об оценке качества работ. Существенно снизить временные затраты на непродуктивную работу, выполняемую в процессе анализа и последующей оценки учебных и научно-технических работ обучающихся, повысить качество анализа работ, а также в значительной мере уменьшить число ошибок, неизбежно допускаемых в процессе их проверки, можно посредством применения компьютерных технологий, обеспечивающих всестороннюю информационную поддержку процессов формализованного автоматизированного анализа текстовых документов.
В настоящее время проблема автоматизированного семантического анализа текстовых научно-технических документов является предметом научных исследований как зарубежных, так и российских ученых [1, 2, 3]. Наибольший интерес в рамках данной статьи представляет работа «Инструментальные средство оценки качества научно-технических документов» [3]. Отличительной особенностью выполненного в ней исследования является то, что для оценки качества научнотехнических документов авторы предлагают использовать комбинированный подход, учитывающий различные категории автоматически рассчитываемых характеристик качества документов – как существующие библиометрические и наукометрические характеристики, так и типы характеристик, основанные на семантическом анализе текстов научно-технических документов, применении эвристических правил, а также на применении методов оценки наличия прямых текстовых заимствований (плагиата). Представленная данными авторами экспериментальная система направлена на повышение качества и степени точности оценки научно-технических документов.
В настоящее время разработаны и используются различающиеся по целям и задачам различные программные инструментальные средства для автоматизации процесса анализа текстовых документов. Так, например, известны программы, направленные на проверку уникальности текстов, среди которых можно отметить: Advego Plagiatus; Etxt Антиплагиат; интернет-сервис сравнения схожести двух текстов ; Интернет-сервис «Антиплагиат» и др. Используются программы подсчета статистических характеристик текста, например TextAnalayzer. Известна программа оценивания неосознаваемого эмоционального воздействия фонетической структуры текстов и отдельных слов на подсознание человека – система ВААЛ. Эффективным инструментальным средством, предназначенным для поиска и определения степени совпадения текстов документов является программа Fast Dublicate File Finder.
В настоящей статье рассматриваются модели и алгоритмы, а также программная реализация мультифункционального анализатора текстов Multifunctional Text Analyzer, предназначенного для информационной поддержки процессов анализа и оценки учебных и научно-технических работ обучающихся (далее в статье Документы). В отличие от публицистических и художественных текстов, такие Документы содержат четко сформулированные определения и однозначный понятийный аппарат, а также достаточно строгую структуру. В соответствии со стандартами (ГОСТ 2.105-95 и ГОСТ 7.32-2001) в них не допускаются синонимы для базовых понятий, что несколько упрощает процесс семантического анализа текста Документа.
Модели и методы автоматизированного анализа текстовых документов
Представим Документ как конечное упорядоченное множество D , состоящее из разделов R , содержащих множества текстовых фрагментов T i и объектов O k (рисунки, графики, диаграммы, схемы, формулы и т.д.)
D = T i с Ок (1)
В свою очередь каждый i -ый текстовый фрагмент T i Документа D состоят из множества символов (знаков) S , среди которых можно выделить:
-
- множество символов алфавита языка AL - символов (алфавиты естественного языка: латинский алфавит, кириллица и т.д.; искусственные алфавиты - некоторые конечные множества символов, например цифры и специальные символы и др.), из которых формируются слова.
-
- множество знаков препинания PM , выполняющих вспомогательные функции: выделения предложений, словосочетаний, слов, частей слова; определения значимости и эмоциональной окраски предложений (текста); указания на грамматические и логические отношения между словами; указания на коммуникативный тип предложения его, законченность и др.;
-
- множество специальных символов SC , включающих: символы типографики (амперсанд (&), коммерческое at (@), звёздочка (*), маркер списка (буллит) (•), знак решётки (октоторп) (#), знак номера (№), знак абзаца (¶), и др.); знаки валют (€, ¥ и др.); знаки интеллектуальной собственности ( © , ® , ™ ).
В процессе выполнения анализа по группе разделов R Документа D необходимо в каждом фрагменте текста T i выделить слова W . Разделителем слов могут быть знаки препинания, являющиеся элементами множества PM (например, пробел, запятая, точка, точка с запятой, двоеточие и др.), а также некоторые специальные символы, являющиеся элементами множества SC (например, табулятор, знак абзаца, звездочка и др.). При этом для проведения анализа в большинстве случаев нет необходимости различать прописные и строчные буквы алфавита естественного языка AL .
Преобразуем текстовый фрагмент Ti, в текстовый фрагмент TW, удалив из него знаки препинания PM, исключая пробел { } и сохранив в нем только слова, составленные из символов алфавита if =( T\(PM\{})) о (AL и {}) . (2)
Сформируем вектор W , элементами которого являются слова текстового фрагмента T W . Количество элементов вектора W равно мощности множества T W .
В зависимости от выбранного критерия, по которому необходимо провести анализ содержательной части совокупности разделов R Документа D на основе выделения множества слов W на базе алфавита естественного языка (латинский алфавит, кириллица) или искусственно алфавита, сформированного как некоторый набор символов, можно выполнить следующие действия:
-
- анализ списка литературы (библиографических ссылок), приведенного в Документе (затекстовых библиографических ссылок, оформленных в соответствии с ГОСТ 7.0.5.-2008);
-
- поиск ссылок на литературу в тексте Документа D , оформленных в соответствии с требованиями ГОСТ 7.0.5-2008 (ссылки в тексте в квадратных скобках) и анализ использования литературы, приведенной в списке литературы Документа D ;
-
- поиск абзацев с заданным образцом текста во фрагментах текста Т i , (тексте в целом) из выбранных разделов R Документа D с учетом/без учета регистра символов;
-
- поиск русских слов Т iW (с учетом ограничения их длины) во фрагментах текста Т i (тексте в целом), из выбранных разделов R Документа D ;
-
- анализ конгруэнтности выбранных фрагментов текста Тi , Документа D , с использованием алгоритмов поиска основ слов, встречающихся в тексте.
Как известно, специфика представления текстовой информации в существенной мере зависит от сферы её применения, а также семантического содержания документа. В общем случае задача проведения автоматизированного анализа содержательной части текстовых документов представляется плохо формализуемой и достаточно сложной. Задача анализа и оценки научно-технической документации несколько упрощается, поскольку ее структура, состав и оформление регламентированы определенными требованиями или стандартами. При этом, в большинстве случаев для оценки могут быть применены как количественные, так и качественные критерии. Чем более четко формализован документ, тем проще разработать и использовать перечень формальных критериев, которые впоследствии будут оцениваться при анализе информации, содержащейся в документе.
Метод многофункционального анализа документа предусматривает выделение в документе текстовых фрагментов, которые фактически представляют собой разделы документа или совокупности разделов, объединенные по их назначению (семантическому содержанию). Базовым объектом в процессе анализа являются слова и словоформы, составленные из алфавитов естественного языка или искусственно созданного для целей анализа алфавита. Процесс многофункционального автоматизированного анализа текста документа выполняется в несколько этапов.
-
1. Анализ структуры документа с определением блоков, которые будут служить базой для сопоставления по отдельным фрагментам (например, введение и заключение, главы и выводы по ним, аннотация и т.п., перечень использованной литературы).
-
2. Определение критериев, по которым будет осуществляться поиск, выполняться анализ и определяться итоговая оценка качества документа.
-
3. Определение поисковых образов в соответствии с множеством сформированных критериев.
-
4. Поиск по документу в целом, отдельным его разделам или совокупности разделов на основе сформированных поисковых образов.
-
5. Получение оценок по отдельным критериям итоговой оценки документа на основе полученных численных результатов поиска по тексту.
Реализация (практическая часть)
Для практического решения задачи информационной поддержки процессов анализа и оценки учебных и научно-технических работ обучающихся был разработан программный продукт Multifunctional Text Analyzer [4], позволяющий проводить автоматический анализ текста Документа и определять количественную оценку его значимых параметров. Главное окно программы Multifunctional Text Analyzer показано на рис. 1
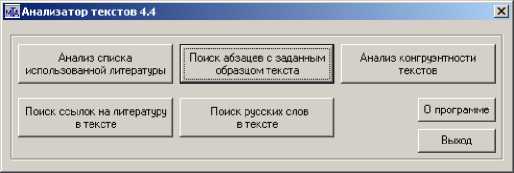
Рис. 1. Главное окно программы Multifunctional Text Analyzer
Анализ списка литературы, приведенного в Документе (затекстовых библиографических ссылок, оформленных в соответствии с ГОСТ 7.0.5.-2008), схема реализации которого показана на рис.2, позволяет:
-
- определить количество источников по каждому году (поиск выполняется в
заданном диапазоне дат; по умолчанию установлены следующие ограничения: по нижней границе поиска 1900 г., по верхней границе поиска – текущий год);
-
- определить количество источников в материалах конференций;
-
- осуществлять поиск записей в списке использованной литературы с заданным образцом текста.
Текстовый документ
Выбор и копирование фрагмента текста со списком использованной литературы
Формирование массива с абзацами (записями) списка литературы
Поиск дат в записях в заданном диапазоне с определением к-ва по каждому году
Электронная таблица
Формирование массива записей с двумя и более датами (числами в формате года)
Рис. 2. Основные этапы анализа списка литературы по годам изданий
Особенностью реализации алгоритма формального поиска библиографических записей является то, что в одной записи могут встречаться две и более отличающиеся даты с указанием года, о чем программа сообщит пользователю. Например, библиографическая ссылка «Тархов С.В. Система автоматизированного сетевого и дистанционного обучения с мультиагентной архитектурой // Информационные технологии в образовании (ИТО-2003): сборник трудов XIV международной конф.-выставки, ч. III. Информационные компьютерные технологии в учебном процессе, - М., - 2004. С. 288-291.» содержит две даты. В таком случае записи могут быть откорректированы в программе анализа вручную для получения правильного результата.
На рис. 3 показано рабочее окно компонента программы Multifunctional Text Analyzer, предназначенное для анализа списка литературы, приведенного в Документе.
Реализованный в программе алгоритм поиска позволяет не только искать в перечне использованной литературы записи с заданным образцом поиска с учетом или без учета регистра символов в определенном диапазоне дат. Алгоритм поиска позволяет также искать и выводить в окне результатов список библиографических записей с заданными номерами, включая поиск по диапазону номеров. Например, при использовании в процессе поиска поискового образа «1,11-14,29» в окне результатов мы увидим библиографические записи с номерами 1, 11, 12, 13, 14, 29. Используя указанный механизм поиска в процессе анализа текста Документа и копируя приведенные в скобках библиографические ссылки, мы получим сформированный перечень библиографических записей, позволяющих посмотреть, на какие именно работы из списка использованной литературы ссылается автор Документа. Результаты анализа могут быть сохранены в текстовом файле следующего содержания:
-
- дата и время проведения анализа;
-
- первый источник из списка литературы, приведенного в Документе и скопированного в рабочее окно программы для проведения анализа;
-
- диапазон дат, в котором проводился анализ;
-
- количество дат (в формате года), найденных в списке литературы (с учетом нескольких дат в одной записи);
-
- количество ссылок на материалы конференций;
-
- количество записей с двумя и более датами или числами, содержащими данные в формате года;
-
- источники из списка литературы с двумя и более датами или числами, содержащими данные в формате года;
-
- перечень найденных в списке литературы дат в формате года с указанием количества записей по каждому году и сортировкой по годам опубликования источников, приведенных в списке литературы;
-
- перечень найденных в списке литературы дат в формате года с указанием количества записей по каждому году и сортировкой по количеству публикаций в год.
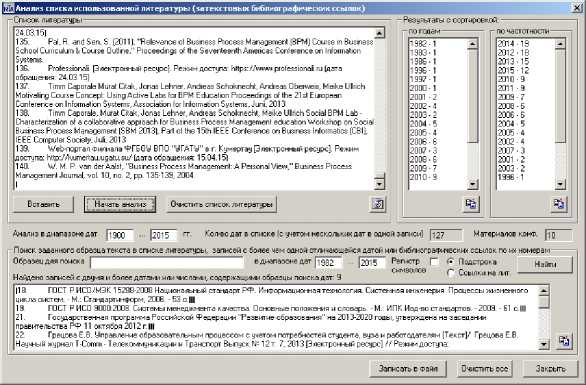
Рис. 3. Рабочее окно анализа списка литературы
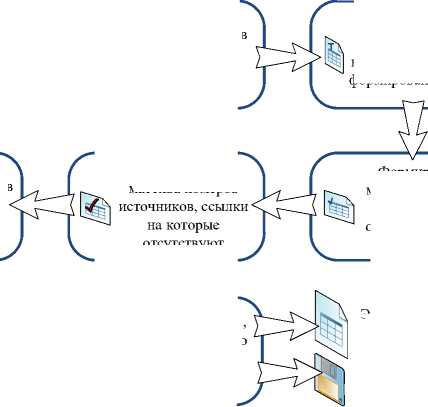
Поиск ссылок на литературу в тексте Документа, оформленных в соответствии с требованиями ГОСТ 7.0.5-2008 (ссылки в тексте в квадратных скобках) и анализ использования литературы, приведенной в списке литературы Документа (процесс показан на рис. 4) позволяет:
-
- получить весь список ссылок в квадратных скобках, имеющихся в тексте документа и оформленных в соответствии с требованиями ГОСТ 7.0.5-2008;
-
- определить количество ссылок в тексте документа на каждый источник, приведенный в перечне использованной литературы;
-
- определить номера библиографических ссылок в перечне использованной литературы, на которые ссылки в тексте документа отсутствуют;
-
- вычислить значения показателей: общее количество ссылок на литературу, количество уникальных ссылок, использование литературы в тексте документа (в процентном отношении).
Текстовый
документ
Выбор и копирование фрагмента текста для поиска ссылок на литературу

ссылок в тексте
документа
Определение числовых характеристик использования
литературы
Формирование массива номеров
в списке использованной
Задание кол-ва источников
Сортировка массивов по возрастанию значений ссылок
литературу с определением к-ва
отсутствуют
Электронная
литературы
Вывод показателя, характеризующего использование
Текстовый файл
Рис. 4. Основные этапы анализа наличия ссылок на литературу в документе

Поиск фрагментов текста, заключенного в квадратные скобки и формирование массива
Формирование массива ссылок на


Окно компонента программы Multifunctional Text Analyzer, предназначенное для поиска ссылок на литературу в тексте Документа показано на рис. 5. Для проведения анализа пользователь должен указать количество источников в списке литературы Документа.
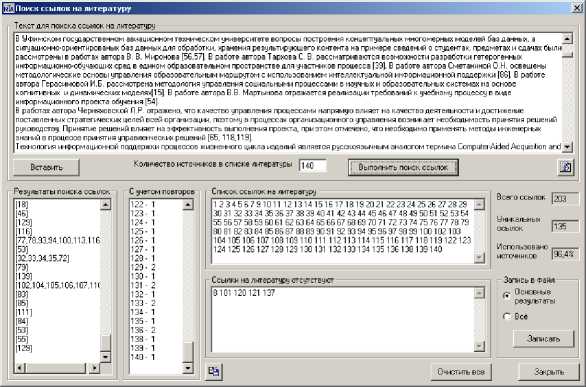
Рис. 5. Рабочее окно поиска ссылок на литературу
Результаты анализа могут быть сохранены в текстовом файле в сокращенном или полном виде:
-
а) в сокращенном виде сохраняются:
-
- дата и время проведения анализа;
-
- фрагмент анализируемого текста длиной 200 символов;
-
- количество источников в списке литературы;
-
- общее количество найденных ссылок;
-
- количество уникальных ссылок;
-
- использование источников из списка литературы в тексте документа в
процентном отношении;
-
- номера источников из списка литературы, которые были использованы в анализируемом тексте Документа;
-
- номера источников из списка литературы, ссылки на которые отсутствуют в анализируемом тексте Документа.
-
б) в полном виде сохраняются:
-
- данные, сохраняемые в сокращенном виде (см. выше);
-
- результаты поиска ссылок в том виде, в котором они присутствуют в анализируемом тексте (в квадратных скобках);
-
- результаты поиска ссылок с указанием количества повторных ссылок на
один и тот же источник.
Поиск абзацев с заданным образцом текста во фрагментах текста Тi , (тексте в целом) из выбранных разделов R документа с учетом/без учета регистра символов (рис. 6) по заданному образцу текста (поисковому образу) позволяет сформировать текст, состоящий из найденных абзацев и, при необходимости сохранить его в файл или в буфер обмена. Поисковый образ в найденном тексте выделяется символом
(группой символов), заданным пользователем программы.
Текстовый документ
Выбор и копирование фрагмента текста для поиска абзацев с заданным образцом
Задание образца и параметров для поиска абзацев во фрагменте текста
Поиск и вывод абзацев с заданным образцом текста
Рис. 6. Основные этапы поиска абзацев с заданным образцом текста
На рис. 7 показано рабочее окно компонента программного продукта Multifunctional Text Analyzer, предназначенное для поиска абзацев, содержащих заданный образец текста.
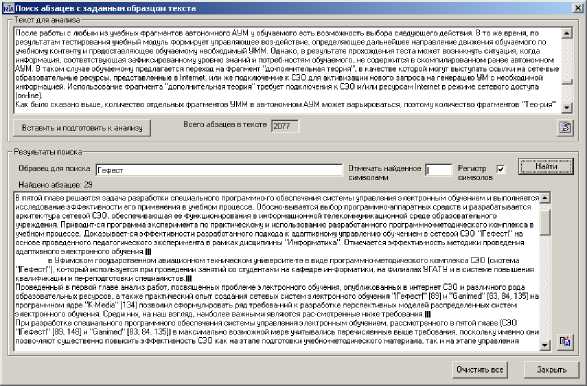
Рис. 7 . Рабочее окно поиска абзацев с заданным образцом текста
Перед выполнением поиска абзацев с заданным образцом текста после вставки текста из буфера обмена в рабочее окно программы с использованием кнопки «Вставить и подготовит к анализу» вычисляется общее количество абзацев в анализируемом тексте. При задании ключа «Регистр символов» поиск будет осуществляться в строгом соответствии с регистром символов поискового образа, в противном случае без учета регистра символов. Выделение поискового образа в найденном тексте символом или группой символов позволяет при чтении текста, сформированного из найденных абзацев, визуально находить интересующий пользователя фрагмент и выполнять дальнейшую неформальную оценку содержания фрагментов анализируемого Документа. Результаты поиска абзацев могут быть скопированы в буфер обмена для последующей вставки в документ с результатами анализа текста. Поиск русских слов (с учетом ограничения их длины) во фрагментах текста (тексте в целом), из выбранных разделов R документа (рис. 8) позволяет:
-
- получить весь список найденных русских слов и словоформ с учетом заданного ограничения минимальной длины слова и с указанием количества каждой найденной словоформы;
-
- определить значения показателей: общее количество слов и словоформ в тексте, включая числа; общее количество русских слов, количество русских слов с
учетом ограничения длины; количество уникальных русских слов с учетом документ ограничения длины. Текстовый
Выбор и копирование фрагмента текста для поиска русских слов
в слове и
Задание ограничений по количеству символов вхождения в слово заданной подстроки
Формирование массива найденных слов

Электронная таблица
повторов в тексте
Вывод найденных русских слов с указанием количества их
Вывод количества: - слов и словоформ; - слов с учетом ограничения длины; - уникальных слов.
Поиск уникальных слов в массиве с

определением количества их повторов
Рис. 8. Основные этапы поиска русских слов в тексте Документа
На рис. 9 показано рабочее окно компонента программы Multifunctional Text Analyzer, предназначенное для поиска абзацев, содержащих заданный образец текста. Помимо основной функции данный инструмент позволяет искать русские слова, в которых содержится заданный пользователем программы поисковый образ.
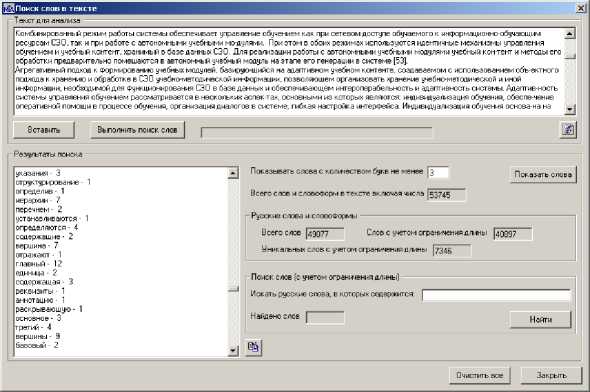
Рис. 9 . Рабочее окно поиска абзацев с заданным образцом текста
Анализ конгруэнтности фрагментов текста, скопированных из Документа, базируется на использовании алгоритма поиска основ слов (части слова представляющей собой его неизменяемую часть, выражающую его лексическое значение) встречающихся в тексте. Для нахождения основы слова в заданном исходном слове (найденной словоформе) применяется стемминг. Программа
Multifunctional Text Analyzer позволяет выполнять сравнение до четырех выбранных фрагментов текста Тi , включая ключевые слова или название Документа D (рис. 10). Анализ конгруэнтности текстовых фрагментов документа позволяет определить:
-
- конгруэнтность фрагментов текста как отношение количества совпадающих основ слов в двух сравниваемых фрагментах, к общему количеству основ слов в одном из них (в процентах);
-
- комплексный показатель конгруэнтности фрагментов текста (в процентах) как с учетом, так и без учета повтора слов;
-
- значения показателей для каждого анализируемого фрагмента текста: общее количество слов учетом ограничения заданной при поиске длины слов; количество уникальных основ слов, количество повторений каждой найденной
основы слова.
Текстовый документ
для анализа
Определение попарной конгруэнтности фрагментов текста
Определение конгруэнтности ключевых слов и каждого фрагмента текста
Выбор и копирование фрагментов текста и ключевых слов
Определение числовых характеристик анализируемых фрагментов текста
Определение и вывод
:^ комплексного и
^ частных показателей конгруэнтности
Задание ограничения на длину слов при проведении анализа
Поиск слов во фрагментах текста, формирование ■ массивов слов
Выделение основ слов в найденных массивах слов (алгоритм стемминга )
Электронная
Текстовый файл
Рис. 10. Основные этапы анализа на конгруэнтность текстовых фрагментов
Окно компонента программы Multifunctional Text Analyzer, предназначенное для анализа на конгруэнтность фрагментов текста Документа показано на рис. 11.
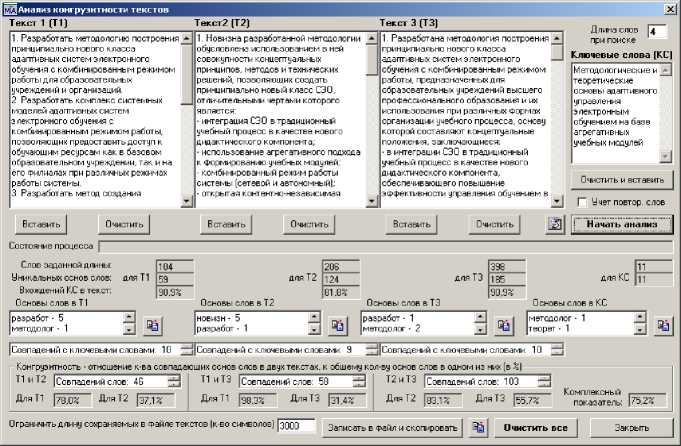
Рис. 11. Рабочее окно анализа на конгруэнтность
Результаты анализа могут быть сохранены в текстовых файлах:
-
а) в файле с подробными результатами анализа текстов содержится:
-
- дата и время проведения анализа;
-
- сведения об установленном пользователем ограничении длины сохраняемых в файле фрагментов текста по количеству символов;
-
- анализируемые фрагменты текста (до четырех фрагментов) заданной длины;
-
- сведения об установленном пользователем ограничении минимальной длины слов при выполнении анализа на конгруэнтность текстов;
-
- для каждого их трех текстовых фрагментов: количество слов заданной длины, количество уникальных основ слов, степень сходства с ключевыми словами (в процентах);
-
- конгруэнтность для каждой пары анализируемых текстовых фрагментов как отношение количества совпадающих в них основ слов к общему количеству основ слов в одном из них (в процентах);
-
- комплексный показатель конгруэнтности текстов (в процентах) с учетом или без учета повторов слов в текстах.
-
б) в файле для анализа данных в электронной таблице содержатся записи (строки данных с разделителями):
-
- дата и время проведения анализа;
-
- сведения о настройках параметров анализа текстов: ограничение на минимальную длину слов; значение ключа учета повтора слов;
-
- для каждого анализируемого текстового фрагмента: количество слов заданной длины, количество уникальных основ слов; степень сходства с ключевыми словами;
-
- для каждой пары анализируемых текстовых фрагментов: количество совпадающих основ слов, конгруэнтность анализируемых текстовых фрагментов как отношение количества совпадающих в них основ слов к общему количеству основ слов в одном из них (в процентах);
-
- комплексный показатель конгруэнтности текстов (в процентах) с учетом или без учета повторов слов в текстах.
Существенное внимание при разработке программного продукта Multifunctional Text Analyzer уделялось совершенствованию механизмов оценочных мероприятий и подготовке отчетной документации. Отличительной особенностью использования программного продукта Multifunctional Text Analyzer в процессе анализа и последующей оценки Документов является возможность многофакторного анализа текста. Основной алгоритм программного продукта Multifunctional Text Analyzer базируется на поиске и выделении слов и словоформ в естественных и формальных алфавитах. Так, для поиска основ русских слов (алфавит кириллицы) используется стемминг – модифицированный алгоритм стеммера Портера, основный на применении ряда правил образования слов и словоформ. В процессе анализа литературы, использованный в Документе, выделяются слова, формируемые на основе искусственного алфавита, связанного с правилами формирования библиографических ссылок по ГОСТ 7.0.5.2008. Разработанные в процессе создания программного продукта Multifunctional Text Analyzer математическая модель и алгоритмы позволяют пользователю быстро и в то же время эффективно проводить всесторонний анализ Документов.
На рис. 12 показана схема работы программного продукта Multifunctional Text Analyzer. Программный продукт Multifunctional Text Analyzer позволяет выполнять автоматизированный анализ текста научно-технических документов. После запуска программы пользователю в главном окне программы (блок 4) доступен перечень решаемых задач (блок 2). Пользователь выбирает (блок 1) необходимый ему для анализа Документа модуль и открывает его (блок 7). В процессе работы с программным продуктом Multifunctional Text Analyzer пользователю в многозадачном режиме доступны все модули (блоки 13, 18, 20, 22, 27), описанные ниже.
Модуль «Анализ списка литературы по годам изданий» (блок 18) (библиографических ссылок, приведенных в Документе (блок 15), позволяет анализировать список литературы, оформленный в соответствии с ГОСТ 7.0.5.-2008), Модуль позволяет вводить ограничения поиска (диапазон дат для проведения анализа) (блок 19) и выводить результаты, как в рабочее окно модуля (блок 21), так и сохранять их в текстовый файл (блок 24).
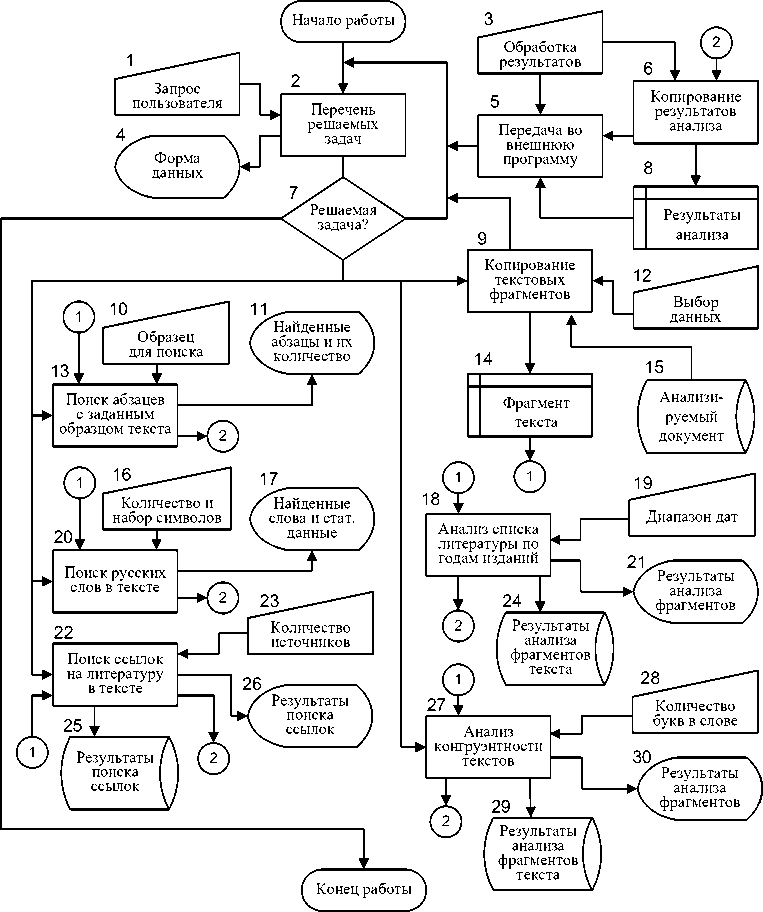
Рис. 12. Схема работы программного продукта Multifunctional Text Analyzer
Модуль «Поиск ссылок на литературу в тексте» Документа (блок 22), (ссылки, оформленные в квадратных скобках в соответствии с требованиями ГОСТ 7.0.5-2008 (ссылки в тексте)) и анализ использования литературы, приведенной в списке литературы Документа (блок 15). В процессе работы с модулем необходимо в качестве данных для поиска ввести не только фрагмент анализируемого текста (как привило, весь текст Документа, за исключением самого списка литературы), но и количество источников в списке литературы (блок 23). Результаты анализа выводятся как в рабочее окно модуля (блок 26), так их можно сохранить и в текстовом файле (блок 25).
Модуль «Поиск абзацев с заданным образцом текста» (блок 13) позволяет искать абзацы с заданным образцом текста во фрагментах, скопированных из текста Документа (блок 15), или в тексте Документа в целом как с учетом, так и без учета регистра символов (ввод данных – блок 10). Результаты работы выводятся в рабочее окно модуля (блок 11).
Модуль «Поиск русских слов в тексте» (блок 20) позволяет искать русские слова с учетом заданного ограничения их длины во фрагментах, скопированных из текста Документа (блок 15) или в тексте Документа в целом. В качестве ограничений вводятся минимальное количество символов (букв) в слове, а также может вводиться подстрока поиска (блок 16). Результаты работы выводятся в рабочее окно модуля (блок 17).
Модуль «Анализ конгруэнтности текстов» (блок 27) позволяет проанализировать до четырех скопированных из текста Документа (блок 15) фрагментов, включая перечень ключевых слов. Результаты анализа конгруэнтности текстовых фрагментов выводятся как в рабочее окно модуля (блок 30), так их можно сохранить и в текстовом файле (блок 29).
Выбор данных (блок 12) для анализа Документа (блок 15) выполняется пользователем вручную путем выделения в тексте Документа необходимых фрагментов (блок 14) и их копирования (блок 9) в буфер обмена.
Модули «Анализ списка литературы по годам изданий» (блок 18), «Поиск русских слов в тексте» и «Анализ конгруэнтности текстов» (блок 27) программного продукта Multifunctional Text Analyzer предусматривают сохранение результатов поиска и анализа в текстовые файлы (блоки 24, 25, 29). Последующая обработка результатов (блок 3) в виде дополнительного анализа показателей качества Документа (блок 15) с построением графиков и диаграмм может быть выполнена во внешней программе (блок 5), например, средствами электронных таблиц (блок 8). Данные для анализа в электронной таблице могут быть введены из сохраненных в Multifunctional Text Analyzer текстовых файлов (блоки 24, 25, 29), или скопированы из буфера обмена (блок 6).
Анализ и оценка разработки
Программный продукт Multifunctional Text Analyzer разработан для поддержки принятия решений при оценке экспертами (преподавателями или сотрудниками) учебных научно-технических работ с использованием многофункционального автоматизированного анализа текста документа. Очевидно, что при оценке Документов не следует полностью полагаться на результаты автоматизированного анализа, как впрочем, не следует полагаться и только на субъективную оценку эксперта. Для оценки качества выполненных учебных научнотехнических работ следует использовать комплексный подход, который предполагает применение как качественных методов оценки работы экспертом, так и количественных методов оценки работы с использованием компьютерных инструментальных средств.
Для качественной оценки Документа экспертом без применения инструментов автоматизированного анализа целесообразно использовать математическую модель, построенную на основе методов нечеткой логики. Такая модель содержит функцию принадлежности и ранговую шкалу, в которой фактическим значениям соответствующих показателей и индикаторов придается конкретный смысл, связанный с выполняемой оценкой работы. В качестве ранговой шкалы может быть принята n-уровневая лингвистическая шкала. Такой подход (в данной работе не рассматривается) позволяет привести значения качественной оценки Документа к количественным показателям. В случае использования для оценки количественных методов, которые в значительной мере реализуются инструментарием автоматизированного анализа текста документа, в частности показателями, полученными в программном продукте Multifunctional Text Analyzer, функция принадлежности будет тождественна фактическому измеренному значению конкретного параметра по выбранной измерительной шкале. Значение итогового показателя по всему множеству параметров и индикаторов, характеризующих оцениваемую работу в количественной форме может быть вычислена как взвешенная сумма всех измеренных или определенных с использованием ранговой шкалы значений показателей.
Авторами с использованием программного продукта Multifunctional Text Analyzer было проанализировано значительное количество научно-технических работ (пояснительных записок к выпускным квалификационным работам, конкурсных научно-исследовательских работ, диссертаций). Практическое использование программного продукта Multifunctional Text Analyzer при анализе качества учебных научно-технических работ показало его высокую эффективность. Так, при оценке научно-технических работ у эксперта-рецензента появилась реальная возможность детально проанализировать использование автором работы современных достижений науки и техники на основе приведенных в тексте работы списка литературы и ссылок в работе на публикации из списка литературы. Текст анализируемой работы может быть в оценен как качественный, если комплексный показатель конгруэнтности фрагментов текста работы (название, цель, задачи, новизна, заключение (выводы)) превышает 70%.
Заключение
Рассмотрена практическая реализация метода многофункционального анализа текста учебных и научно-технических работ обучающихся. Информационная поддержка процесса анализа и оценки экспертами учебных научно-технических работ обеспечивается использованием разработанного авторами программного продукта Multifunctional Text Analyzer, который, как показало его практическое применение, позволяет:
-
- существенно сократить непродуктивную работу преподавателей и сотрудников (экспертов), в чьи функциональные обязанности входит проверка и оценка учебных научно-технических работ;
-
- в значительной мере снизить влияние субъективных факторов на результаты оценки работы;
-
- определять значения показателей, оценка которых без использования компьютерных технологий нецелесообразна по причине высоких трудозатрат (например, использование в тексте статьи ссылок на литературу), а в ряде случаев практически неосуществима (анализ конгруэнтности текстов).
Работа выполнена при поддержке гранта РФФИ 15-07-0239315
Список литературы Информационная поддержка процессов анализа и оценки учебных и научно-технических работ обучающихся
- Инструментальные средства оценки качества научно-технических документов/С.В. Герасимов //Труды Института системного программирования РАН. -М., -2013. -Т.24. -С. 359-378.
- Бутакова М.А., Климанская Е.В., Янц В.И. Мера информационного подобия для анализа слабоструктурированной информации//Современные проблемы науки и образования. -2013. -№6, URL: www.science-education.ru/113-11307 (дата обращения: 20.05.2015).
- Симанков В.С., Толкачев Д.М. Автоматическая оценка смыслового подобия текстов//Сб. ст. по материалам XXXVII междунар. науч.-практ. конф. №8(33). Новосибирск: Изд. «СибАК», -2014. -104 с. URL: http://sibac.info/15679 (дата обращения: 12.05.2015).
- Тархов С.В., Минасова Н.С., Калимуллина Г.Р. Свид. о гос. рег. программы для ЭВМ № 2015612998. Мультифункциональный анализатор текстов МТА/Российская Федеральная служба по интеллектуальной собственности, патентам и товарным знакам. М.: Зарег. в реестре программ для ЭВМ 27 февраля 2015 г.
