Interconnect network on chip topology in multi-core processors: a comparative study

Author: Manju Khari, Raghvendra Kumar, Dac-Nhuong Le, Jyotir Moy Chatterjee
Journal: International Journal of Computer Network and Information Security @ijcnis
Article in issue: 11 vol.9, 2017.
Free access
A variety of technologies in recent years have been developed in designing on-chip networks with the multicore system. In this endeavor, network interfaces mainly differ in the way a network physically connects to a multicore system along with the data path. Semantic substances of communication for a multicore system are transmitted as data packets. Thus, whenever a communication is made from a network, it is first segmented into sub-packets and then into fixed-length bits for flow control digits. To measure required space, energy & latency overheads for the implementation of various interconnection topologies we will be using multi2sim simulator tool that will act as research bed to experiment various tradeoffs between performance and power, and between performance and area requires analysis for further possible optimizations.
Topology, Multicore Processor, Multi2sim Simulator, Super Scalar, Pipeline
Short address: https://sciup.org/15015554
IDR: 15015554 | DOI: 10.5815/ijcnis.2017.11.06
Text of the scientific article Interconnect network on chip topology in multi-core processors: a comparative study
Published Online November 2017 in MECS
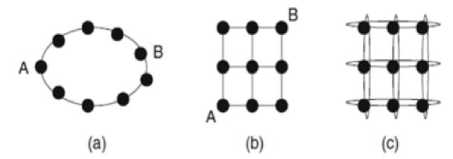
Fig.1. On Chip Interconnect Topologies in Multicore Processor for (a) Ring (b) Mesh (c) Torus Topology
The impact on throughput a topology creates is affected by the total number of alternate paths between nodes. It determines the optimistic way in which a network can flood out its traffic. The fabrication complexity cost of a topology is controlled by two factors: the number of links at each node called node degree and the ease of laying out a topology on a chip wire length and the number of metal layers required. In this paper, we would be determining the best topology of interconnection network architecture by virtual implementation of given number of processing cores using Multi2Sim simulation framework. For CPU-GPU heterogeneous computing, this framework is written in C language and includes templates for superscalar, multithreaded, and multicore CPUs, as well as GPU designs. Thus, the framework would act as perfect model and integration of the main microprocessor components, intended to cover incapability of existing simulators.
-
II. Related Works
All the generations of processors were constantly designed smaller in area with faster performance requirements it started dissipating more heat and exhausted with more power consumption. Starting from the development of Intel's 8086 through the Pentium 4, there was gradual increase in performance from one generation to another due to the increase in processor frequency. As in case of Pentium 4 the frequency ranged from 1.3 to 3.8 GHz in its 8 years of evolution. On the other hand, physical size of chips decreased while the number of transistors per chip increased. As the clock speeds also increases it aids the heating across the chip by raising temperature to a dangerous level. Speeding processor’s frequency had inspired many in industry throughout a decade’s time however chip designers were still in need for a better technology so as to improve the performance. Due to increasing demand, the idea of having additional processing cores to the same chip came into the mind of designers. Hypothetically it was expected that the performance will double and heat dissipation would be less.
In 2000, SPEC CINT2000 benchmark suite was rolled out which consisted over 5.9 trillion instructions when executed with reference inputs. Researchers substantially rely on simulators to analyze, debug and validate new designs before implementation. Modern hardware like a 3.06GHz Pentium 4 [5] consumes about 31 minutes to conclude the benchmark task. If we were to compare the same hardware with one of the fastest and detailed singleprocessor, the superscalar models can only simulate about million instructions per second. This would be taking over 72 days to finish one invocation of the SPEC CINT2000 suite. When additional features are infused such as cache-coherent memories and configuration information to boot the Linux kernel, simulation time becomes even more tedious. A fully configured system with cache-coherent simulator will run only 300,000 instructions per second which would be translating it to 228 days for the SPEC CINT2000 suite.
In 2007, A research on Migration from Electronics to Photonics in Multicore Processor by an engineer from National University of Singapore suggested that the resistive tendency of metals causes the bottleneck problem in interconnects. By replacing Aluminum with Copper, one is slightly able to improve the interconnect performance provisionally, however to achieve a complete sustainable solution so that ongoing pace of progress persists, it is fairly acceptable to have an idea of having an optical interconnect to metallic wires. Manycore microprocessors are also likely to push performance per chip from the 10 giga flop to the 10tera flop range. [15]. Table 1 indicated the comparative studies.
Table 1. Comparative Analysis
|
Author |
Techniques/ Parameters |
Advantages |
Disadvantages |
|
Doug Burger and Todd M. Austin (1997) |
High-performance simulation of modern microprocessors, |
Given finish portrayal of the apparatus set, including recovery and establishment directions and depiction of how to utilize the apparatuses, and depiction of the objective SimpleScalar design, and many insights about the internals of the instruments and how to modify them. |
The instrument set can be stretched out to reproduce ISAs other than SimpleScalar what's more, MIPS. |
|
Mayan Moudgill (1999) |
(RTL) processor models, Turandot |
Exhibited test information assembled in the alignment of one processor association displayed |
Turandot against a definite reference model. |
|
Dominik Madon (1999) |
Simultaneous Multithreaded processor, rapid communication system, efficiency of architecture |
Proposed an design which incorporates a product instrument to deal with settings, a fast correspondence framework, and in addition a locking framework to guarantee common avoidance. |
Different commitments have demonstrated that the successful yield of a SMT processor is more noteworthy than that of a standard superscalar processor, it can't be expressed with sureness that the outcome will be as great in homogeneous multitasking mode with code produced by a parallelizing-compiler |
|
Yingmin Li et. al (2005) |
Simultaneous multithreading (SMT) and chip multiprocessing (CMP) |
Utilized Turandot, Power Timer, and Hot Spot to investigate this outline space for a POWER4/POWER5-like center. |
Need to handle the testing issue of considering fundamentally bigger measures of string level parallelism and considering cross breeds amongst CMP and SMT centers. |
|
Benjamin Lee and David Brooks (2005) |
SMT and CMP architecture, voltage/frequency scaling, circuit re-tuning, power performance efficiency |
Directed power-execution reenactments of a few SMT and CMP models utilizing centers of changing many-sided quality. Our examinations distinguish effective pipeline measurements and layout the ramifications of utilizing a power execution proficiency metric for center many. |
Here power and execution are taken essential measurements however territory and interconnect impacts will move toward becoming noteworthy in CMP designs for a bigger number of cores. |
|
Joseph J. Sharkey (2005) |
multi-threaded microarchitectural simulation, Simultaneous Multithreading (SMT) model |
Given a review of M-Sim, including a point by point depiction of the recreated processor and in addition directions for the establishment and utilization of the M-Sim condition. |
Just the Alpha AXP parallels are bolstered by M-Sim. While the first Simplescalar likewise underpins the PISA doubles, M-Sim does not. |
|
Kenneth C. Barr (2006) |
Memory Timestamp Record (MTR), Branch Predictorbased Compression (BPC), |
Researches programming structures and methods for rapidly mimicking current store intelligent multiprocessors by amortizing the time spent to mimic the memory framework and branch indicators. |
Expanded checkpoint measure and the need to know ahead of time the small scale compositional subtle elements that must be warmed. |
|
R. Ubal (2007) |
Microprocessor, interconnection networks |
Displayed the Multi2Sim reproduction structure, which models the real segments of approaching frameworks, and is proposed to cover the impediments of existing test systems. |
Very complex |
|
Bryan Schauer (2008) |
Coherence protocols, efficiency of multicore processors |
Multicore processors are architected to hold fast to sensible power utilization, warm scattering, and store soundness conventions. |
Need to short out the best trouble of showing parallel programming methods (since most developers are so versed in consecutive programming) and in upgrading current applications to run ideally on a multicore framework. |
|
Zhoujia Xu (2008) |
Microprocessor performance, bandwidth performance, performance, |
Presentation of copper set up of aluminum has incidentally enhanced the interconnect execution, however a more problematic arrangement will be required with a specific end goal to keep the current pace of advance, optical interconnect is a fascinating other option to metallic wires. |
So as to take the optical jump, be that as it may, the capacity of proficient treatment of optical flag at low cast is required. |
|
Yaser Ahangari Nanehkaran (2013) |
Chip multiprocessor, Hyper Transport, printed circuit board, front side bus, multithread, DRAM memory, and cache. |
Portrayed a portion of the imperative difficulties of multi-center its essential idea, focal points, and an example of Dual-center Processors in Intel and AMD. |
Memory frameworks and interconnection organizes needs change |
|
Zaki A. Khan (2015) |
Interconnection Network, Diameter, Parallel System, Scalability, Load Imbalance, Dynamic Scheduling. |
Proposed and investigated another adaptable interconnection arrange topology named as Linear Crossed Cube (LCQ). |
Can outline more productive planning plan reasonable for the purposed LCQ arrange. |
|
A. J. Umbarkar (2015) |
Metaheuristic, Open Multiprocessing (Open MP), TeachingLearning-Based Optimization (TLBO), Unconstrained Function Optimization, Multi core. |
Usage of TLBO on a multi-center framework utilizing Open MP API's with C/C++ is proposed |
Can explore the proposed Open MP TLBO on CEC 2013 capacity bed. Additionally, obliged streamlining proving ground could be moreover tested. |
|
Fatemeh. Dehghani (2016) |
Code Division Multiple Access technique, Network on Chip, Adaptive traffic controls, routing. |
Transmit information all the while on the system and advancement of the venture in a various leveled organize, will make a system as versatile. |
Increment unwavering quality and better utilize, blame tolerant strategies can be utilized to serve about nature of administration in this structure. Additionally, utilizing productive steering calculations as indicated by introduced structure and its elements in programming calculation to locate the ideal course will have the capacity to diminish the deferral between the transmitter and beneficiary notwithstanding having a consistent esteem. |
|
Liyaqat Nazir (2016) |
Network-on-chip, virtual channels, buffers. |
Introduced the execution examination of different flexible buffering strategies expected to outline miniaturized scale design switches for NoC |
Execution with other buffering approaches, elective full throughput flexible supports full nonexclusive versatile cushion and assess them for credit based stream control convention utilized as a part of NoC switch correspondence with neighboring switches. |
|
Swati Rustogi (2017) |
Multi-core, data mining, parallelism, Apriori. |
An enhanced Apriori method for multi-center condition is proposed. |
It can be investigated from the perspective of load on the centers. |
-
III. Simulation Framework
An endeavor Turandot simulator [11,12] is further inventive effort which simulates a PowerPC architecture. Along with the aid of simultaneous multithread SMT the project was extended for multicore. This effort is made available by the Power-Timer tool [13] as a practical implementation. Tornado addons for parallel micro architectures are ranked under highly researched topics (e.g., [14]), are not available as open source. Both Simple Scalar and Turandot are application-only tools. This means that the simulators would be straightly running the application and simulates its interaction with an underlying virtual operating system. The tool is not prepared to meet the requirements of architecture-specific privileged instruction set as applications cannot be allowed to implement it. The only merit to offer is isolation of the execution instances so that statistics are not affected by a simulation of a real operating system. Multi2Sim is to be categorized as an application-only simulator here.
A key hallmark of chip simulators is “timing-first approach”. It was initiated by GEMS and replicated in Multi2Sim as an addon feature. This approach where timing module is supposed to discover the state of the processor pipeline, instructions helps in spanning over it in an analytical manner. Next functional module is executed along with the instructions dynamically till it attains the commit stage. Thus, legitimate execution paths are perpetually guaranteed by a formerly developed robust simulator. Multi2Sim can be downloaded as a compressed tar file, and has been tested on 32 bit and 64 bit machine architectures, with Ubuntu (Linux OS). The simulator compilation requires the library libbfd, not preset in some Linux distributions by default. All the executables are required to be compiled statically as dynamic linking is not supported. A command line to compile a program composed by a single source file, executables usually have an approximate minimum size of 4MB, since all libraries are linked with it [17, 25].
The following commands are supposed to do us favor in a command terminal to compile it:
./configure make
On simulation bench, booting an application is the operation where an executable file is selectively aligned into different virtual memory regions. In physical system, the operating system is responsible for these operations. In comparison to other simulators ( e.g. SimpleScalar ), Multi2Sim keeps its orientation away from supporting the simulation of an entire Operating System and is confined for running compiled applications only. Thus, loading process must be proactively organized by the simulator at the time of initialization.
The gcc bundle that dissipates executable files as output are intended to adapt the ELF (Executable and Linkable Format) specification. The format design is earmarked to comply with shared libraries, core dumps and object code. An ELF file is made up of an ELF header, a set of segments and a set of sections. Typically, one or more sections are enclosed in a segment. ELF sections are identified by a name and contain useful data for program loading or debugging. They are labeled with a set of flags that indicate its type and the way they have to be handled during the program loading[3].
-
• Functional Simulation : The engine which supports the machine design here is MIPS32. It is developed as an autonomous library and supplies interface to the simulator. This simulator kernel is responsible for incurring the functions to create/destroy software contexts, initiate application loading, enumerate existing contexts, consult their status, execute a new instruction and handle speculative execution.
-
• Detailed Simulation : In Multi2Sim, “ Execution-Driven ” simulation is performed by the detailed simulator using former functional engine contained in Libkernel . In each cycle, context state is revised by sequence of calls to the kernel on periodic basis. The latest execution of machine instructions invokes analysis process in detailed simulator about its operational nature and records the function latencies consumed by physical entities.
The pipeline process is basically classified into five stages. First fetch stage inputs the instructions from cache and dispatches them into an IFQ ( Instruction Fetch Queue ). Next to decode these instructions, decode/ rename stage inputs these instructions from an IFQ, renames its registers and allocate them a block in the ROB ( Reorder Buffer ). When the input operands are signaled as available, the decoded instructions are placed into a RQ ( Ready Queue ). Further in issue stage, instructions from the RQ are processed and transmitted to a respective functional unit. In Ex ( Execute Stage ) the functional units process the task and store its result back into a record file. Finally, the commit stage retires instructions from the ROB in program order [20-24].
This processing flowchart is comparative to the one designed by the SimpleScalar tool set [8]. In additional this uses a ROB, an IQ ( Instruction Queue ) and a physical record file in place of integrated RUU ( Register Update Unit ). The sharing strategy of each stage can be varied in a multithreaded pipeline [16] with the Ex stage being the only exception. This scheme aids in achieving superior overall throughput by making use of multithreading. It takes advantage of the sharing of functional units, located in the Ex stage. Thus, utilization is subsequently increased for increasing performance [1719].
Fig.2 depicts two of the pipeline flow model classified on the basis of stages. Fig.2(a) Stages are shared here among various threads, whereas in Fig.2(b) Except “Ex” stages are looped as many times as endured by hardware threads. The application of Multi2Sim aids in accounting variable stage sharing strategies. The multithread design can be classified as fine-grain (FGMT), coarse-grain (CGMT) or simultaneous multithread (SMT), depending on the stages sharing and thread selection protocols.
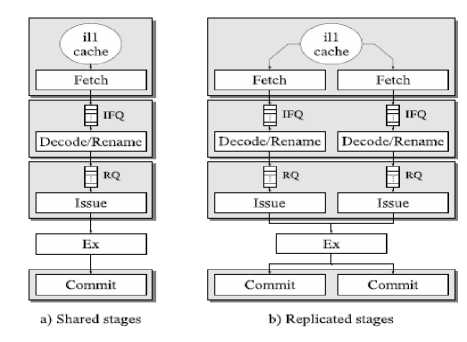
Fig.2. Chain of Instruction’s Processing in Pipelining
Factors like performance, power/area budget, bandwidth, technology, system software etc. gets affected while inventing out for the best possible design of chip in multiprocessing environments. Latest researches try to orient towards comprehensive analysis of the implementation issues for a design class of chip multiprocessor interconnection network.
Our work does a comparative study of three interconnect network i.e. ring, mesh and torus. Experiments were performed using simulation to find out the best possible combination of core and network for better performance.
-
A. Experimental Setup for Ring Topology Interconnect:
Experiment was performed for Ring Topology Interconnect where number of cores were varied as 2, 4, 8, and 16. The simulation benchmark has to be configured as follows.
The configuration file for 8 cores are shown here:
CPU configuration [General] Cores = 8 Threads = 1
Context Configuration
[ Context 0 ]
Exe = radix.x86
args = -p1 -r128 -n262 -m524
[ Context 1 ]
Exe = specrand_base.x86
Args = 55 99
[ Context 2 ]
Exe = sort.x86
[ Context 3 ]
Exe = lu.x86 args = -p1 -n8 -b2
Network Configuration
[Network.net0]
DefaultInputBu_erSize = 1024
DefaultOutputBu_erSize = 1024
DefaultBandwidth = 256
; Making a Ring with 6 switches
Source = sw0
Dest = sw1
Type = Bidirectional
Source = sw1
Dest = sw2
Type = Bidirectional
Source = sw2
Dest = sw3
Type = Bidirectional
Source = sw3
Dest = sw4
Type = Bidirectional
Source = sw4
Dest = sw5
Type = Bidirectional
Source = sw5
Dest = sw0
Type = Bidirectional
Dest = n2
Type = Bidirectional
Source = sw1
Dest = n3
Type = Bidirectional
Source = sw2
Dest = n4
Type = Bidirectional
Source = sw3
Dest = n5
Type = Bidirectional
Source = sw4
Dest = n8
Type = Bidirectional
Source = sw5
Dest = n9
Type = Bidirectional
; Links from Switches to L2 caches
Source = sw1
Dest = n0
Type = Bidirectional
Source = sw2
Dest = n1
Type = Bidirectional
Source = sw3
Dest = n6
Type = Bidirectional
Source = sw4
Dest = n7
Type = Bidirectional
Simulation results for Ring Topology Interconnect shows that there is significant improvement in “ Dispatch IPC ” with number of cores. It is to be noted here that, initially the “ Dispatch IPC ” increases but after 4 cores it remains constant. The “Issue IPC” also increases up to 4 cores and after 4 cores it comes to steady state. There is significant improvement in “ Commit IPC ” for Ring Topology with number of cores as 2 and 4. After 4 cores, no significant improvement in commit IPC is seen. The average latency increases for 2 and 4 cores. For 8 and 16
cores, it remains constant. Therefore, it can be concluded the 4 cores is acting as optimal number for Ring Topology Interconnect.
-
B. Experimental Setup for Mesh Topology Interconnect:
Experiments performed for Mesh Topology Interconnect had the variation for number of cores as 2, 4, 8, and 16. The simulation was setup by various configuration files.
The configuration file for 8 cores are shown here:
CPU Configuration [General] Cores = 8 Threads = 1
Context Configuration [ Context 0 ]
-
[ Context 1 ]
Exe = specrand_base.x86 Args = 55 99
[ Context 2 ]
Exe = sort.x86
[ Context 3 ]
DefaultInputBu_erSize = 1024 DefaultOutputBu_erSize = 1024 DefaultBandwidth = 256
[Network.net0.Node.n0] Type = EndNode [Network.net0.Node.n1] Type = EndNode [Network.net0.Node.n6] Type = EndNode [Network.net0.Node.n7] Type = EndNode [Network.net0.Node.n2] Type = EndNode [Network.net0.Node.n3] Type = EndNode [Network.net0.Node.n4] Type = EndNode [Network.net0.Node.n5] Type = EndNode [Network.net0.Node.n8] Type = EndNode [Network.net0.Node.n9]
Type = EndNode
; Making a Mesh with 6 switches
Dest = sw1
Type = Bidirectional
Dest = sw2
Type = Bidirectional
Dest = sw3
Type = Bidirectional
Source = sw3
Dest = sw4
Type = Bidirectional
Source = sw4
Dest = sw5
Type = Bidirectional
Dest = sw0
Type = Bidirectional
Dest = sw4
Type = Bidirectional
Dest = n2
Type = Bidirectional
Source = sw1
Dest = n3
Type = Bidirectional
Source = sw2
Dest = n4
Type = Bidirectional
Source = sw3
Dest = n5
Type = Bidirectional
Source = sw4
Dest = n8
Type = Bidirectional
Source = sw5
Dest = n9
Type = Bidirectional
; Links from Switches to L2 caches
Dest = n0
Type = Bidirectional
Source = sw2
Dest = n1
Type = Bidirectional
Source = sw3
Dest = n6
Type = Bidirectional
Source = sw4
Dest = n7
Type = Bidirectional
For this topology too, initially the “ Dispatch IPC ” was noted to be increased till 4 cores & remains constant afterwards. The “ Issue IPC ” was showing the same tends as “ Dispatch IPC ” i.e. increases up to 4 cores and after that there was no remarkable variation. From 2 to 4 cores, the “ Commit IPC ” showed improvement and after 4 cores no significant improvement was observed on simulation bench. As the number of core is increased from 2 to 4, the average latency increases. After 4 cores i.e. for core 8 and 16, average latency is seen as constant. Therefore, it can be concluded the 4 cores is acting as optimal number for Mesh Topology Interconnect too.
-
C. Experimental Setup for Torus Topology Interconnect:
Experiments performed for Torus Topology Interconnect consisted the variation for number of cores as 2, 4,8, and 16. The simulation was setup by various configuration files.
The configuration file for 8 cores are shown here:
CPU configuration
[General]
Cores = 8
Threads = 1
Context Configuration [ Context 0 ]
Exe = radix.x86
args = -p1 -r128 -n262 -m524
-
Stdout = context-0.out
[ Context 1 ]
Exe = specrand_base.x86
Args = 55 99
-
Stdout = context-1.out
[ Context 2 ]
Exe = sort.x86
-
StdOut = context-2.out
[ Context 3 ]
Exe = lu.x86
args = -p1 -n8 -b2
-
StdOut = context-3.out
Network Configurations
[Network.net0]
DefaultInputBu_erSize = 1024 DefaultOutputBu_erSize = 1024 DefaultBandwidth = 256
-
; 6 switches
Type = Switch
Type = Switch
Type = Switch
Type = Switch
Type = Switch
Type = Switch
-
; 2 L2s
-
; 4 Main Memory access points [Network.net0.Node.n2] Type = EndNode
-
; Making a Torus with 6 switches [Network.net0.Link.sw0-sw1] Source = sw0
Dest = sw1
Dest = sw2
Dest = sw3
Dest = sw4
Dest = sw5
Dest = sw0
Dest = sw2
Dest = sw3
Dest = sw4
Dest = sw3
Dest = sw4
Dest = sw5
Dest = sw4
Dest = sw5
Dest = sw5
Type = Bidirectional
Dest = n3
Dest = n4
Dest = n5
Dest = n8
Dest = n9
Type = Bidirectional
-
; Links from Switches to L2 caches [Network.net0.Link.sw1-n0] Source = sw1
Dest = n0
Dest = n1
Dest = n6
Dest = n7
Type = Bidirectional
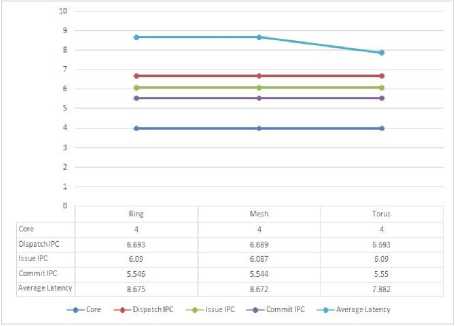
Fig.3. Simulation Result’s Comparison
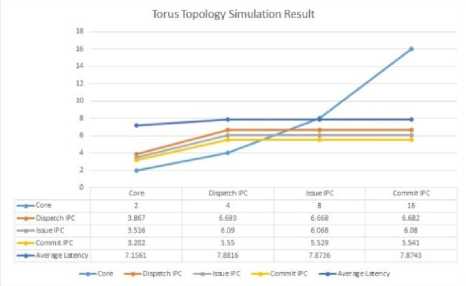
Fig.4. Torus Topology Simulation Result
-
VI. Conclusions
“ timing-first ” simulation along with functional units. Hence there is no requirement to simulate a whole operating system. Executing parallel workloads with dynamic threads creation would be sufficient. The simulation framework which we have used has been developed for adapting the key attributes of popular simulators like partitioning functional and timing simulation, SMT and multiprocessor support and cache coherence. The module of the simulator also supports application of execution-driven simulation like SimpleScalar. This design facilitates the unitization of the functional kernel as an independent library plus allows the definition of the instruction set to be mapped into a central file (machine.def).
References Interconnect network on chip topology in multi-core processors: a comparative study
- Schauer, B. (2008). Multicore processors - a necessity. ProQuest discovery guides, 1-14.
- Mukherjee, S. S., Bannon, P., Lang, S., Spink, A., & Webb, D. (2002). The Alpha 21364 network architecture. IEEE micro, 22(1), 26-35.
- Ubal, R., Sahuquillo, J., Petit, S., & Lopez, P. (2007, October). Multi2Sim: A Simulation Framework to Evaluate Multicore-Multithreaded Processors. In Sbac-Pad (pp.62-68).
- Owens, J. D., Dally, W. J., Ho, R., Jayasimha, D. N., Keckler, S. W., &Peh, L. S. (2007). Research challenges for on-chip interconnection networks. IEEE micro, 27(5), 96-108.
- Barr, K. C. (2006). Summarizing multiprocessor program execution with versatile, microarchitecture-independent snapshots (Doctoral dissertation, Massachusetts Institute of Technology).
- Nanehkaran, Y. A., & Ahmadi, S. B. B. (2013). The Challenges of Multi-Core Processor. International Journal of Advancements in Research & Technology, 2(6), 36-39.
- McLean, R. A. R. A. (1984). Applied factorial and fractional designs (No. 04; QA279, M2.).
- Burger, D., & Austin, T. M. (1997). The SimpleScalar tool set, version 2.0. ACM SIGARCH computer architecture news, 25(3), 13-25.
- Madoń, D., Sanchez, E., &Monnier, S. (1999, August). A study of a simultaneous multithreaded processor implementation. In European Conference on Parallel Processing (pp. 716-726). Springer, Berlin, Heidelberg.
- Sharkey, J., Ponomarev, D., &Ghose, K. (2005). M-sim: a flexible, multithreaded architectural simulation environment. Techenical report, Department of Computer Science, State University of New York at Binghamton.
- Moudgill, M., Bose, P., & Moreno, J. H. (1999, February). Validation of Turandot, a fast processor model for microarchitecture exploration. In Performance, Computing and Communications Conference, 1999 IEEE International (pp. 451-457). IEEE.
- Moudgill, M., Wellman, J. D., & Moreno, J. H. (1999). Environment for PowerPC microarchitecture exploration. IEEE Micro, 19(3), 15-25.
- D. Brooks, P. Bose, V. Srinivasan, M. Gschwind, and M. Rosenfield P. Emma. Microarchitecutre-Level Power-Performance Analysis: The Power Timer Approach. IBM J. Research and Development, 47(5/6), 2003.
- Lee, B., & Brooks, D. (2005). Effects of pipeline complexity on SMT/CMP power-performance efficiency. Power, 106, 1.
- Xu, Z. (2008). Migration from electronics to photonics in multicore processor(Doctoral dissertation, Massachusetts Institute of Technology).
- Shen, J. P., &Lipasti, M. H. (2013). Modern processor design: fundamentals of superscalar processors. Waveland Press.
- Umbarkar, A. J., Rothe, N. M., &Sathe, A. S. (2015). OpenMP teaching-learning based optimization algorithm over multi-core system. International Journal of Intelligent Systems and Applications, 7(7), 57.
- Khan, Z. A., Siddiqui, J., &Samad, A. (2015). Linear crossed cube (LCQ): A new interconnection network topology for massively parallel system. International Journal of Computer Network and Information Security, 7(3), 18.
- Dehghani, F., &Darooei, S. (2016). A Novel Architecture for Adaptive Traffic Control in Network on Chip using Code Division Multiple Access Technique. International Journal of Computer Network and Information Security, 8(8), 20.
- Nazir, L., & Mir, R. N. (2016). Realization of Efficient High Throughput Buffering Policies for Network on Chip Router. International Journal of Computer Network and Information Security, 8(7), 61.
- Rustogi, S., Sharma, M., &Morwal, S. (2017). Improved Parallel Apriori Algorithm for Multi-cores. International Journal of Information Technology and Computer Science (IJITCS), 9(4), 18.
- Joseph, P. M., Rajan, J., Kuriakose, K. K., & Murty, S. S. (2013). Exploiting SIMD Instructions in Modern Microprocessors to Optimize the Performance of Stream Ciphers. International Journal of Computer Network and Information Security, 5(6), 56.
- Le, D. N. (2013). Optimizing the cMTS to Improve Quality of Service in Next Generation Networks based on ACO Algorithm. International Journal of Computer Network and Information Security, 5(4), 25.
- Basmadjian, R., & de Meer, H. (2012, May). Evaluating and modeling power consumption of multi-core processors. In Proceedings of the 3rd International Conference on Future Energy Systems: Where Energy, Computing and Communication Meet (p. 12). ACM.
- M2S Guide 4.2, The Multi2Sim Simulation Framework, www.multi2sim.org.
