Использование LLM-моделей для оптимизации управления знаниями в цифровой трансформации торговых компаний

Автор: Прейс В.Е.
Журнал: Петербургский экономический журнал @gukit-journal
Рубрика: Инновационное развитие экономики и социально-культурной сферы
Статья в выпуске: 1 (51), 2026 года.
Бесплатный доступ
В условиях стремительной цифровизации экономики торговые компании сталкиваются с необходимостью фундаментального преобразования своих бизнес-процессов. Особую актуальность приобретает вопрос эффективного управления корпоративными знаниями, который становится критически важным фактором конкурентоспособности. Данное исследование посвящено комплексному анализу возможностей применения крупных языковых моделей (LLM) как инновационного инструмента оптимизации систем управления знаниями в торговых организациях. В работе детально рассматриваются следующие аспекты: технологические основы интеграции LLM в существующие информационные системы торговых предприятий, включая вопросы совместимости с CRM, ERP и другими корпоративными платформами; практические механизмы автоматизации процессов обработки запросов различного уровня сложности – от стандартных вопросов о характеристиках товаров до сложных аналитических запросов, требующих агрегации данных из различных источников; методики улучшения клиентского сервиса и внутренних коммуникаций за счет персонализации взаимодействия на основе возможностей LLM по анализу контекста и истории предыдущих обращений. Результаты исследования демонстрируют значительный потенциал LLM для повышения операционной эффективности торговых организаций. В частности, зафиксированы случаи сокращения времени обработки типовых запросов, уменьшения нагрузки на службы поддержки, а также существенного улучшения показателей удовлетворенности как клиентов, так и сотрудников. Практическая значимость исследования заключается в разработке пошаговой методологии внедрения LLM в торговых компаниях, включающей этапы подготовки данных, выбора платформы, интеграции с существующими системами и обучения персонала. Предложенные решения уже апробированы в нескольких торговых сетях и показали высокую эффективность.
Цифровая трансформация, языковая модель LLM, база знаний, искусственный интеллект, управление знаниями, торговые организации, автоматизация, структурные запросы, RAG-модели, информационная безопасность
Короткий адрес: https://sciup.org/140314286
IDR: 140314286 | УДК: 005.336 | DOI: 10.32603/2307-5368-2026-1-69-78
Using LLM models to optimize knowledge management in digital transformation of trading companies
With the rapid digitalization of the economy, trading companies are faced with the need to fundamentally transform their business processes. The issue of effective corporate knowledge management is becoming particularly relevant, which is becoming a critical factor in competitiveness. This study is devoted to a comprehensive analysis of the possibilities of using large-scale language models (LLM) as an innovative tool for optimizing knowledge management systems in trade organizations. The following aspects are considered in detail in the work. The technological foundations of LLM integration into existing information systems of trading enterprises, including issues of compatibility with CRM, ERP and other corporate platforms. Practical mechanisms for automating query processing processes of various levels of complexity, from standard questions about product characteristics to complex analytical queries that require data aggregation from various sources. Techniques for improving customer service and internal communications by personalizing interactions based on LLM’s capabilities to analyze the context and history of previous requests. The results of the study demonstrate the significant potential of LLM to improve the operational efficiency of trade organizations. In particular, there have been cases of reducing the processing time for typical requests, reducing the burden on support services, as well as significantly improving satisfaction indicators for both customers and employees. The practical significance of the research lies in the development of a step-by-step methodology for implementing LLM in trading companies, including the stages of data preparation, platform selection, integration with existing systems, and staff training. The proposed solutions have already been tested in several retail chains and have shown high efficiency.
Текст научной статьи Использование LLM-моделей для оптимизации управления знаниями в цифровой трансформации торговых компаний
Введение, цель
Современный розничный сектор проходит фазу стремительной цифровой трансформации. По данным отчета Deloitte «Retail Industry Digital Maturity Survey 2024» [1], более 70 % российских компаний отрасли выносят цифровизацию в число приоритетных стратегических задач ближайших трех лет, а международные тренды подтверждают это наблюдение [2; 30]. Ключевые драйверы изменений – смещение ожиданий потребителей в сторону персонализированного сервис-опыта, 24/7-доступа к информации и бесшовных омниканальных сценариев. Одновременно ускоряются внутренние бизнес-циклы: операционные решения принимаются в режиме реального времени, что требует мгновенной верификации данных по всей цепочке поставок. Именно поэтому глобальные логистические структуры становятся зависимыми от надежных цифровых платформ – без них прозрачность потоков ресурсов практически недостижима [3].
Однако традиционные подходы к управлению корпоративными знаниями все чаще тормозят эти процессы. Согласно опросу IDC «Information Worker Productivity Survey 2023» [4], сотрудники торговых компаний тратят в среднем 28 % рабочего времени на поиск и проверку информации. Ситуацию усугубляют экспоненциальный рост ассортимента SKU, усложнение товарных атрибутов, регулярные промо-кампании и необходимость соблюдения разноформатных отраслевых стандартов [5]. В совокупности это порождает разрозненные хранилища данных, не синхронизированные между собой, и приводит к «информационным островам».
Исследования Westerman, Bonnet и McAfee демонстрируют, что любая цифровая трансформация результативна лишь при радикальном пересмотре внутренних процессов накопления и распространения знаний [6]. Макроэкономическую отдачу подтверждают Brynjolfsson, McAfee и Spence, показывая, что цифровые инвестиции объясняют до 27 % роста производительности розничных компаний за 2020–2023 гг. [3].
Фундамент для такого сдвига создает грамотная архитектура корпоративного храни- лища данных: методология «звездных схем» Kimball–Ross обеспечивает единую «точку истины» для аналитики [7], а гибкие BI-системы, описанные Chen, Chiang и Storey, позволяют извлекать управленческие инсайты из разнородных источников [8]. При этом классические ML-инструменты – от адаптивных деревьев решений до факторизационных машин – уже становятся стандартом корпоративной аналитики [9–11].
Новый виток эволюции задают генеративные модели и Retrieval-Augmented Generation (RAG). Практические аспекты внедрения LLM-сервисов освещены в работах Auffarth [12], Alto [13] и Singh и др. [14], а системати-ческий обзор Sowa, Martinez и Patel фиксирует устойчивое снижение доли нерелевантных ответов в корпоративных системах вопросов-ответов в среднем на 30–35 % при переходе на RAG-архитектуры [15]. Сравнительный анализ Liang и Kumar подтверждает преимущество GPT-4-подобных моделей над BERT-базовыми решениями в задачах корпоративного поиска [16], а Carlson и др. детализируют метрики качества на данных товарного каталога [17].
В области структурирования данных растет роль графовых представлений. Guha, Chen и Lin демонстрируют, как знание-ориентированный поиск повышает точность сопоставления товаров в e-commerce-каталогах [18]; Zhang, Hu и Liu предлагают контекстно-чувствительный подход к сущностной привязке, адаптирован-ный к высокодинамичным розничным каталогам [19]. Для цепочек поставок особое значение приобретают цифровые двойники, интегрированные с графами знаний, что повышает устойчивость и управляемость логистических процессов [20; 21].
Не менее активно развивается омника-нальная аналитика. Эксперименты Chalmers и McMahon показывают, что синтез офлайн-и онлайн-данных позволяет увеличить конверсию на 4–7 % [22]; Zhao, Wang и Li подтверждают этот эффект на китайском рынке [23]. Дополнительный прирост метрик дает применение объяснимого ИИ в рекомендательных системах [24], обеспечивая доверие менеджеров и ускоряя цикл внедрения выводов в операционную деятельность.
Все перечисленные работы сходятся в одном: иерархические базы знаний и поиск по ключевым словам уже не покрывают сложность современных торговых экосистем. Контекстный анализ, знание-графы и масштабирующиеся LLM-решения обеспечивают гибкость, необходимую в эпоху тотальной цифровизации [25]. Исходя из этого, цель настоящего исследования – разработка алгоритма для торговых организаций, оптимизирующего управление корпоративными данными за счет комбинации RAG-подхода, графовых моделей знаний и средств объяснимой аналитики.
Методы исследования
В рамках настоящего исследования был проведен всесторонний анализ научных источников и практических разработок, посвященных вопросам цифровизации бизнес-процессов, совершенствования систем управления знаниями, а также повышению эффективности информационного обеспечения в торговом секторе. В теоретическую основу работы легли труды отечественных и зарубежных специалистов, изучающих проблемы адаптации компаний к условиям цифровой трансформации, а также методы структурирования и распространения знаний в организации. Методология исследования включала применение структурного и сравнительного анализа, методов моделирования и концепций управления знаниями. На основании изученного материала автором предложен оригиналь-ный подход к оптимизации процессов работы с корпоративной информацией, ориентирован-ный на потребности современных торговых предприятий. Практическая часть работы была реализована на примере крупной торговой организации, где провели системный анализ текущих информационных потоков и бизнес-процессов, включая процедуры ввода новых сотрудников в должность и взаимодействие с клиентами. Результатом стала разработка прикладного решения, направленного на повышение оперативности и качества обработки информации в корпоративной среде.
Результаты и дискуссия
Корпоративные знания являются одним из основополагающих элементов функциониро- вания любой организации. Они представляют собой совокупность информации и техноло-гий, применяемых в конкретной организации, и являются основными ресурсами для успеш-ной деятельности любой компании. База зна-ний торговой организации представляет собой фундамент, необходимый для эффективного управления, наполнение которого должно начинаться как можно раньше и постоянно совершенствоваться.
Необходимость создания и наполнения базы знаний компании обусловлена следующими причинами:
-
1) сохранение и передача опыта . База зна-ний аккумулирует в себе критически важную информацию о процессах, продуктах, клиентах, поставщиках и решениях, что предотвращает ее утерю при смене сотрудников. Таким образом, в торговых компаниях это могут быть данные о специфике тех или иных товаров, список типовых возражений клиентов или же успешные кейсы продаж;
-
2) повышение операционной эффективности . Централизованная база знаний сокращает временные затраты сотрудников на поиск информации, тем самым ускоряя принятие решений;
-
3) стандартизация процессов . База знаний обеспечивает единые правила работы для всех сотрудников, что особенно важно для крупных компаний ритейлеров или франшиз, где
Г" База знаний "Магазин электроники"
|--- v О компании
|--- К Товары
| |---^ Смартфоны (характеристики, сравнение моделей)
| 1--- k Гарантия и возврат
|---й Продажи
| |--- k Скрипты общения с клиентами
| 11 Акции и промокоды
|---ей Логистика
| |--- 1 График поставок
1--- 1 Инструкция по приёмке товара
1---? 1Т-поддержка
|--- k Как работать с кассой
1--- к Ошибки системы и решения
Рис. 1. Пример оформления базы знаний для розничного магазина
Fig. 1. Example of knowledge base design for a retail store
Источник: составлено автором.
Source: compilated by the author.
необходимо поддерживать одинаковый уровень сервиса;
-
4) улучшение клиентского опыта . Быстрый доступ к информации из базы знаний позволяет как можно точнее отвечать на запросы клиентов, учитывая их персональные особенности;
-
5) поддержка инноваций . Постоянный анализ базы знаний помогает выявлять тенденции и оптимизировать стратегии ведения бизнеса.
Обычно база знаний начинает формироваться еще на ранних этапах развития компании, для того чтобы избежать хаотичного накопления данных. В дальнейшем при масштабировании бизнеса база знаний активно дополняется при открытии новых филиалов или при выходе на новые рынки. В момент цифровой трансформации компании база знаний является ключевым источником получения информации при написании системных требований для автоматизации бизнес-процес-сов, и любое изменение этих бизнес-процессов влечет за собой немедленное обновление информации в базе знаний, а затем и в информационных системах.
Зачастую база корпоративных знаний имеет строгую структуру, обусловленную делением на основные процессы компании, пример которой для розничной торговли представлен на рис. 1.
Данная структура базы знаний обеспечивает легкость поиска информации для сотрудников и клиентов, снижает нагрузку на поддержку и легко может масштабироваться. В ней логически выделены разделы, отвечающие за основные бизнес-процессы компании.
Несмотря на оптимальную организацию базы знаний, при росте объемов данных будет снижаться и эффективность навигации по ее разделам, что в дальнейшем замедлит ручной поиск информации. Именно в этот момент возникает потребность в инструменте интеллектуального поиска и автоматической обработки запросов.
Для удовлетворения вышеупомянутой потребности и повышения эффективности поиска информации в базе знаний автором предлагается интеграция LLM (англ. large language model – крупная языковая модель) в поиск по базе знаний компании. Крупные языковые модели легко справляются с большими базами знаний за счет понимания естественного языка, агрегации данных и контекстного анализа. Это позволит сотрудникам задавать вопросы «как человек», а не использовать ключевые слова. Модель, в свою очередь, возьмет на себя функцию объединения информации из разных источников, учитывая историю запросов и специфику бизнеса.
Также использование LLM-моделей позволит избежать неправильных формулировок информации из корпоративной базы знаний. Лауреат нобелевской премии по экономике Даниэль Канеман в своей книге [26] сформулировал работу человеческого мышления как взаимодействие двух систем. Первую систему человек использует, когда необходимо принять быстрое интуитивное решение и дать оперативный ответ, а вторую систему – когда задумывается или мысленно представляет себе что-то. Именно из-за влияния первой системы информация, которую получает сотрудник организации или клиент, может быть интерпретирована неверно. LLM-модели в сравнении с человеческим мышлением помогут сразу получить структурированный ответ, основан-ный на базе знаний.
Интеграцию LLM рекомендуется организовать в RAG-формате. RAG – это способ работы с большими языковыми моделями, когда при написании пользователем вопросов информационная система программно дополняет их информацией из источников и подает на вход языковой модели [27]. Данный формат позволит пользователю получить развернутый и точный ответ на свой вопрос.
Для осуществления RAG-поиска рекомендуется использовать векторные базы данных, информация в которых будет записана с учетом разбиение статей на чанки (кусочки информации из статей в базе знаний). Для записи в векторные базы знаний используются модели эмбеддинги (векторное представление слов), что позволяет сгруппировать семантически схожие статьи в облака знаний, представленные на рис. 2, которые были созданы при помощи базы данных Neo4j и языка запросов Cypher.
В представленном облаке знаний можно увидеть качество (расстояние между векторами знаний) организации данных в базе знаний, обусловленное количеством связей между разделами базы знаний. Использование облаков знаний превращает статичную базу знаний в интерактивную систему, где LLM дает персонализированные ответы на вопросы пользователей [28].
В ходе проведения исследования было разработано и внедрено программное обе- спечение, в основу которого легли крупные языковые модели Gemma 3 и Mistral. Данное решение было создано на основе алгоритма, представленного на рис. 3.
Подготовка базы знаний с целью обеспечения структурированности и полноты дан- ных стала первым этапом вышеприведенного алгоритма. Для этого провели аудит существующих данных (документов базы знаний, корпоративных чатов и CRM-системы), в ходе которого были выявлены устаревшие и противоречивые данные. Была проведено разделение базы корпоративных знаний на логические категории, а также удалены конфиденциальные знания. Также тексты документов были разбиты на фрагменты по 256–512 слов, а из таблиц и презентаций было извлечено тексто- вое содержимое.
Рис. 2. Облако знаний, созданное на основе базы корпоративных знаний
Fig. 2. Knowledge cloud created on the basis of basic knowledge
Источник: составлено автором. Source: compilated by the author.
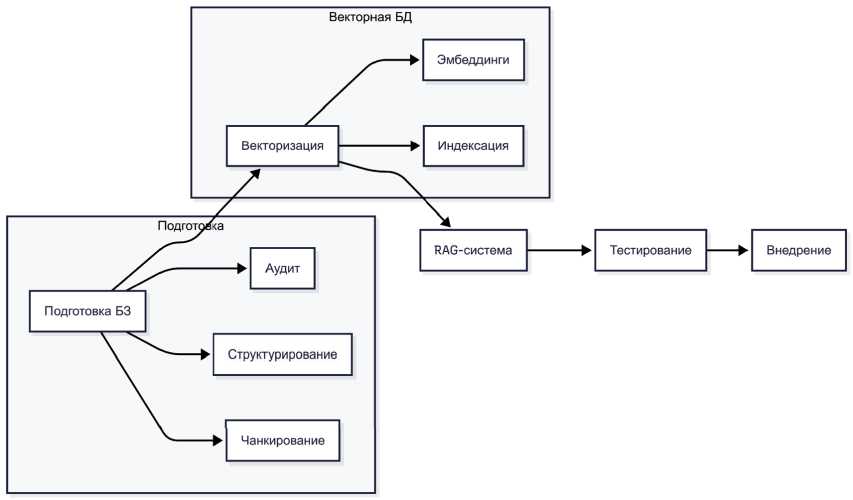
Рис. 3. Алгоритм внедрения LLM-моделей для оптимизации организации базы знаний
Fig. 3. Algorithm for implementing LLM models to optimize the organization of the knowledge base
Источник: составлено автором. Source: compilated by the author.
Вторым этапом стала векторизация данных с целью преобразования текстов в числовые векторы для организации семантического поиска. Для этого выбрали модель эмбеддинга all-MiniLM-l6-v2, каждый чанк был превращен в вектор с добавлением метаданных (источники, дата обновления и автор). Также данные были загруженные в векторную БД и проиндексированы для оптимизации скорости поиска.
Настройка RAG-системы для связки векторного поиска с генерацией ответов LLM была определена третьим этапом алгоритма внедрения крупных языковых моделей для оптимизации базы знаний. Для этого выбрали модель Gemma 3 от компании Google и при помощи фреймворка langchain создали интеграцию с векторной базой данных Weaviate. Отдельно стоит осветить проведенный промпт-инжиниринг (создание текстовых шаблонов к LLM), который позволил структурировать ответы от модели.
Четвертым этапом алгоритма стали тестирование и оптимизация с целью обеспечения точности и скорости работы системы. Для этого провели тесты на типовых ответах. Для оценки качества были использованы такие метрики, как
Accuracy (процент правильных ответов), время ответов и confidence score (уверенность модели в ответе). После проведения тестирования была проведена калибровка чанков.
Заключительным этапом алгоритма стали внедрение и масштабирование системы с целью интеграции в рабочие процессы организации. Для этого провели пилотный запуск в отделе технической поддержки, а также собрали результаты обратной связи о функционировании LLM-системы. После чего провели интеграцию с внутренними корпоративными мессенджерами.
Данный алгоритм был внедрен в крупную торговую организацию, которая занимается розничной продажей бытовой техники и электроники. После внедрения описанного подхода организации базы знаний в отдел поддержки пользователей были проведены сбор и анализ данных для оценки влияния внедрения крупных языковых моделей.
В первую очередь провели оценку времени поиска информации в базе знаний. Результаты изменения среднего времени поиска данных в базе знаний показаны на рис. 4.
На рисунке видно, что если раньше поиск информации сотрудником занимал в среднем
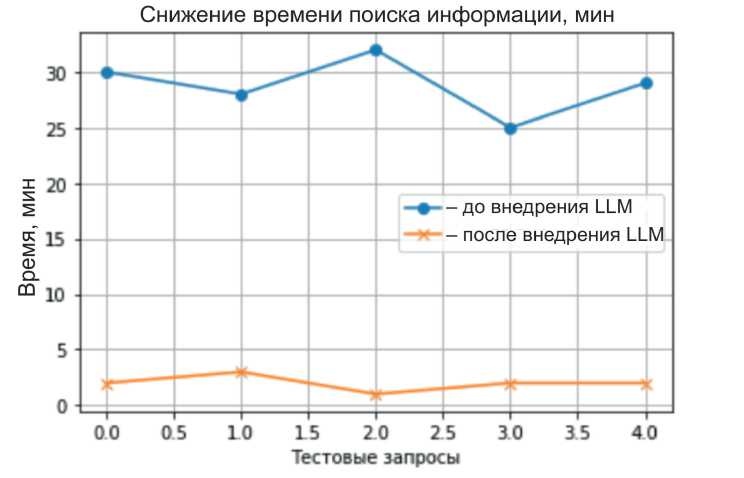
Рис. 4. График изменения среднего времени поиска информации в базе знаний
Fig. 4. Graph of changes in the average time spent searching for information in the knowledge base
Источник: составлено автором. Source: compilated by the author.
от 25 до 30 мин, то после внедрения чата с крупной языковой моделью время поиска информации занимает от 1 до 3 мин. Для проверки на нормальность выборок, формирующих данный показатель, был проведен тест Шапиро–Уилка, который показал, что временная выборка до внедрения LLM является нормальной, а после внедрения – ненормальной [29]. Именно поэтому было принято решение о проведении t-теста Стьюдента и u-теста Манна–Уитни. Данные тесты показали, что T-статистика = 31.81 и p-value = = 0.0000, а U-статистика = 100.0 и p-value = = 0.000157. По результатам t-теста можно сделать вывод, что разница между группами очень велика по сравнению с разбросом данных, а p-value = 0 означает, что вероятность получить такое различие случайно нулевая. Результаты u-теста отражают его надежность, несмотря на то, что данные «после» ненормальные.
Для проверки выборок на их отличие по отношению к общему разбросу было получено значение d-Коэна равное 14.23. Это значит, что среднее время до и после внедрения различаются не просто статистически, а радикально, так как различие в группах в 14 раз больше, чем естественный разброс внутри каждой группы. Это говорит о том, что после внедрения LLM поведение системы фундаментально изменилось – по сути, это две разные реальности, в которых существует отдел поддержки пользователей.
Заключение
Базы знаний торговых организаций являются одним из важнейших аспектов обеспечения их деятельности. Они представляют сосредоточения артефактов всех бизнес-про-цессов, а также задокументированный опыт сотрудников компании. Учитывая динамическую среду, в которой существуют торговые компании, ценность принятия решений возрастает с каждым днем. Для поддержки процесса принятия решений и управления на основе данных в этой статье приведен пример алгоритм-интеграции LLM-моделей в деятельность компании. Он представляет собой лишь общее описание этапов, которые необходимо пройти компании для обеспечения цифровой трансформации процесса управления корпоративными знаниями. Подводя итог, хотелось бы отметить, что на практике внедрение LLM-моделей с системой RAG-поиска помогло увеличить скорость ответов отдела поддержки пользователей, и это позволило повысить результативность бизнес-процессов отдела и удовлетворенность потребителя.
Практическая значимость исследования заключается в том, что его результаты могут ис- пользоваться на практике не только в торговых организациях, но и в любой сфере экономики с целью повышения уровня владения корпоративными знаниями.
