Использование методов машинного обучения для обработки и анализа клиентских отзывов

Автор: Мельников А.А., Диязитдинова А.Р.
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Новые информационные технологии
Статья в выпуске: 3 (91) т.23, 2025 года.
Бесплатный доступ
Машинное обучение сегодня является подтвержденным и неплохо себя зарекомендовавшим инструментом для решения различного рода задач по автоматизации, которые не способны эффективно разрешать иные алгоритмы. Исследование посвящено вопросам использования методов машинного обучения для обработки и анализа текстовых данных. В качестве набора данных были выбраны отзывы клиентов на работу банка, поскольку для банков обратная связь является приоритетной. Задача классификации клиентских отзывов является актуальной для множества бизнес-задач, где сложно обойтись без алгоритмов обучения. Одной из ключевых задач машинного обучения является бинарная классификация, которая заключается в разделении объектов на два класса на основе их признаков. Разработанное приложение упрощает использование методов машинного обучения для широкого круга пользователей, не обладающих глубокими техническими знаниями. Для разработки был использован язык Python 3.12 (библиотека pandas, pytorch, pyqt5, transformers).
Машинное обучение, обработка естественного языка, Transformer, анализ данных, PyOT, бинарная классификация, Python
Короткий адрес: https://sciup.org/140313588
IDR: 140313588 | УДК: 004.65 | DOI: 10.18469/ikt.2025.23.3.11
Customer Feedback Processing and Analyzing by Machine Learning Methods
Currently machine learning is a powerful tool when solving different types of automation tasks. Other methods cannot effectively perform a similar task. The present research describes the issue about machine learning methods for the purpose of the test data processing and analyzing. In the current research the test data is the bank customer feedback, because the feedback is very important information for the bank. The customer feedback classification is a significant task for different business-targets. One of the primary functions of machine learning is objects binary classification for dividing two classes by their attributes. The developed application uses machine learning tools for a wide range of people without deep technical knowledge. The application was developed by Python 3.12 (modules: pandas, pytorch, pyqt5, transformers).
Текст научной статьи Использование методов машинного обучения для обработки и анализа клиентских отзывов
Современные условия цифровой экономики характеризуются экспоненциальным ростом объемов данных, генерируемых в самых различных сферах человеческой деятельности. Данный поток информации требует применения эффективных методов обработки и анализа данных для извлечения полезных знаний для последующего принятия обоснованных решений. Ручной анализ данных слабоприменим и затруднителен, поэтому растет роль методов машинного обучения (Machine Learning, ML) [1; 2]. Главным преимуществом ML является способность к самообучению: обучившись на конкретных примерах, ML-система может применять полученные знания к новым, ранее не встречавшимся данным [3]. ML активно применяется для решения задач классификации, регрессии, кластеризации, а также для обработки естественного языка (Natural Language Processing, NLP). Данная дисциплина, используя вычислительные методы, изучает слова и языковые конструкции и тесно взаимодействует с компьютерными науками и искусственным интеллектом [4].
Одной из задач эффективного управления любого рода бизнесом является оценка и мониторинг степени удовлетворенности клиентов. Традиционные методы измерения и мониторинга пользовательских отзывов трудоемки, требуют больших финансовых вливаний, поскольку, как правило, сбор и анализ информации осуществляется вручную [5]. Следовательно, разработ- ка более эффективного подхода к исследованию удовлетворенности клиентов и его программная реализация является актуальной задачей.
В работе в качестве данных были выбраны отзывы клиентов банка, представляющие собой естественный источник текстовой информации, в котором содержатся реальные мнения, эмоции и чувства, проблемы и ожидания пользователей по отношению к услугам компании. Подобные данные обладают непосредственной практической ценностью: банки и иные финансовые учреждения заинтересованы в повышении качества сервиса, снижении негативной обратной связи и улучшении клиентского опыта. Анализ отзывов помогает выявить слабые места в обслуживании, повторяющиеся жалобы, а также положительные аспекты, требующие дополнительной поддержки и развития. В условиях жесткой конкуренции на финансовом рынке, где лояльность клиента является прямым рычагом успешности бизнеса, это стало особо актуальным [6].
Современные методы NLP (например, модели на основе архитектуры Transformer) позволяют решать сложные задачи, включая суммаризацию текста, генерацию ответов и диалоговые системы. Примером такой модели можно назвать GigaChat (нейросеть, разработанная Сбером), которая демонстрирует высокие результаты в обработке естественного языка. С другой стороны, несмотря на широкие возможности ML, его применение часто требует специализированных знаний и навыков, что ограничивает доступность этих

технологий для широкого круга пользователей. В этой связи актуальной задачей является разработка удобных инструментов, которые позволяют использовать ML-методы без необходимости детального изучения теоретических и технических деталей. Десктопные приложения с графическим интерфейсом представляют собой одно из решений этой проблемы, предоставляя пользователям интуитивно понятный способ взаимодействия с моделями машинного обучения.
Целью исследования выступает разработка десктопного приложения для выполнения анализа текстовых данных с использованием методов машинного обучения. Данное приложение включает в себя модель бинарной классификации, функцию суммаризации текста, а также диалоговую систему, использующую API GigaChat. Это позволит пользователям решать разнообразные задачи анализа данных, начиная от классификации объектов и заканчивая обработкой текстовой информации.
Особенности применения машинного обучения для обработки и анализа текстовых данных
Применение современных методов машинного обучения показали свою универсальность: один алгоритм может быть использован для решения различного типа задач в разных сферах [7]. Отличительной чертой машинного обучения является способность не просто извлекать из данных полезную информацию, но и по мере увеличения объема обучающей выборки самостоятельно совершенствоваться.
В [8] указаны ключевые преимущества ML-подхода:
– возможность автоматически находить сложные закономерности;
– возможность без перепрограммирования адаптироваться к изменяющимся условиям;
– способность работать как с многомерными, так и неструктурированными данными;
– по мере накопления данных осуществляется постепенное улучшение качества решений.
К недостаткам ML следует отнести следующее [6]:
– существует зависимость от количества данных в наборе данных (dataset): алгоритм ML не способен точно прогнозировать поведение системы без достаточного объема вводных данных;
– трудоемкость процесса обучения моделей: процесс обучения эффективной модели ML может быть трудоемким в течение продолжительного времени и потребовать значительного объема данных;
– неясность в принятии решений: сложность в работе с самообучающимся алгоритмом состоит в неопределенности метода, по которому проходило обучение;
– необходимость экспертной подготовки данных: для практического применения методов машинного обучения необходим высококвалифицированный персонал;
– наличие рисков безопасности.
В работе использовалась технология Transformer, которая расширяет и дополняет понятие машинного обучения. Под Transformer принято понимать архитектуру глубоких нейронных сетей, основанных на механизме внимания без использования рекуррентных нейронных сетей. Описанные алгоритмы применимы в работе для более тонкой настройки моделей с целью обеспечения их эффективного использования. Данная архитектура нейронной сети была предложена в 2017 году в статье «Attention is All You Need» [9] авторами Э. Васвани и его коллегами. Данная нейронная сеть была разработана для решения задач обработки последовательностей, в первую очередь, – для машинного перевода, но позже стала основой большинства современных моделей искусственного интеллекта, включая BERT, GPT и другие крупные языковые модели.
К преимуществам Transformer относят высокую степень параллелизации и способность эффективно работать с длинными контекстами [2]. Основной элемент архитектуры Transformer – это механизм внимания (в частности, механизм selfattention), который обеспечивает возможности модели учитывать все элементы входной последовательности одновременно при генерации каждого следующего элемента. Входная последовательность в архитектуре Transformer первоначально преобразуется в эмбеддинги с добавленной дополнительно позиционной информацией. Затем данные эмбеддинги проходят через многослойную структуру, которая состоит из блоков внимания и полносвязных слоев, снабженных механизмами нормализации и остаточными связями для стабилизации обучения. Модель разделяется на две части: энкодер и декодер. Используя эм-беддинги, полученные из Transformer-энкодера, можно эффективно кластеризовать схожие типы кейсов, выявлять паттерны поведения, определять «хорошие» и «плохие» траектории исполнения процесса.
Кроме того, несмотря на то, что в данном исследовании рассматриваются именно банковские отзывы, предлагаемые методы и подходы универсальны: они могут быть применены к сформули- рованным в текстовой форме отзывам клиентов в любой сфере (отзывам о продуктах, онлайн-ма-газинах, отелях, образовательных курсах и пр.). Это расширяет потенциальную область применения модели и делает ее релевантной не только для конкретной задачи, но и для более широкого круга бизнес-приложений.
Подготовка данных для модели бинарной классификации и для модели суммаризации
Весь этап подготовки данных охватывает несколько ключевых этапов: очистка и разметка данных; их разделение на выборки; валидация данных; преобразование текста в числовой формат и упаковка в структуру, подходящую для передачи в модель.
Бинарная классификация, заключающаяся в разделении объектов на два класса на основе их признаков, является одной из ключевых задач машинного обучения. Бинарная классификация имеет широкое применение, например, фильтрация спама, диагностика заболеваний или анализ тональности в тексте.
Подготовка данных является первостепенной задачей, поскольку от качества ее выполнения напрямую зависит эффективность всей модели бинарной классификации. Сначала необходимо загрузить dataset с отзывами клиентов о банке. Для этого использована библиотека pandas в python, позволяющая удобно работать с табличными данными и с форматами parquet и JSON [10; 11]. После загрузки данных их необходимо предварительно обработать: текстовые метки классов (например, «Positive») преобразуются в числовой формат. Данная бинаризация упрощает задачу и делает ее совместимой с большинством алгоритмов.
Далее данные необходимо разделить на обучающую и тестовую выборки в соотношении 70% (обучающая) и 30% (для проверки точности модели). Данный этап весьма важен, поскольку позволяет модели обучаться на одной части данных и затем проверять свою способность обобщать знания на другой, неизвестной для нее части.
Следующим этапом выступает токенизация. Для этого применяется предобученный токени-затор из библиотеки transformers, соответствующий модели BERT (в исследовании применялась русскоязычная версия от DeepPavlov). Токени-затор преобразует каждое предложение в набор токенов, а также выполняется усечение и дополнение длины текстов для соответствия их заданной максимальной длине с целью последующей пакетной обработки. Подготовленные данные оборачиваются в кастомный класс Dataset, который реализует интерфейс PyTorch. Такой подход упрощает обучение и делает процесс более стабильным и предсказуемым.
При работе над моделью для сокращения объема текстов отельное внимание было уделено подготовке и обработке исходных данных. Речь идет именно о таком виде суммаризации, при которой формируется новый текст с сохранением сути первоначального отзыва, а не просто «выдергиваются» готовые предложения из оригинала.
Подготовка началась с загрузки данных из CSV-файла с помощью библиотеки pandas. Для решения задачи тестировались несколько моделей: mBART, ruGPT3Small, ruGPT3Large, а также ruT5-base и ruT5-large.
Была выбрана модель T5 (Text-to-Text Transfer Transformer), которая изначально обучалась на множестве задач для английского языка. Ее многоязычная версия – mT5 охватывает 101 язык, однако обучалась только на одной задаче – заполнении текста. Российская адаптация этой модели – ruT5 – также была разработана Сбером. Она доступна в двух версиях: ruT5base и ruT5large, и была обучена на том же корпусе, что и ruGPT-3.
Таблица 1. Характеристики выбранного источника dataset
|
Набор данных |
Размер |
Тип данных |
Мин. длина токенов |
Макс. длина токенов |
Средняя длина токенов |
Доля набора |
|
Обучающий |
52,400 |
текст |
28 |
1,500 |
766,5 |
82,6% |
|
Обучающий |
52,400 |
резюме |
15 |
85 |
48,8 |
82,6% |
|
Валидационный |
5,265 |
текст |
191 |
1,500 |
772,4 |
8,3% |
|
Валидационный |
5,265 |
резюме |
18 |
85 |
54,5 |
8,3% |
|
Тестовый |
5,770 |
текст |
357 |
1,498 |
750,3 |
9,1% |
|
Тестовый |
5,770 |
резюме |
18 |
85 |
53,2 |
9,1% |
Данные, взятые на основе корпуса, провалидированы, а в таблице 1 указана информация по данному источнику.
Согласно логике программы, в таблице должен существовать столбец «text», содержащий сами тексты для суммаризации (это один из шагов валидации входных данных). При отсутствии данного столбца, выполнение программы останавливается с соответствующей ошибкой.
В работе использован метод абстрактивной суммаризации, поскольку важно не сократить текст отзыва клиента (это может привести к потере смысла), а сформировать сокращенный вариант отзыва при полном сохранении смысла. Поэтому в задачах, где нужно получить связный и понятный текст, особенно при работе с небольшими или слабо структурированными фрагментами, абстрактивная суммаризация решает эту проблему. Она использует языковые модели и формирует резюме «с нуля», пересказывая текст своими словами. Такой метод позволяет получить более гладкое, последовательное и стилистически единое изложение.
Предлагаемый алгоритм работы десктопного приложения
Алгоритм работы приложения состоит из следующих этапов:
-
1. Вызов программы и отображение главное окна, где пользователю предоставляется возможность выбора одного из трех режимов работы: выполнение суммаризации текста, осуществление классификации или диалоговое взаимодействие с Gigachat.
-
2. В случае выбора окна суммаризации открывается форма с текстовым полем, кнопками и прогресс-баром. Пользователю необходимо ввести текст отзыва, нажать на кнопку «Суммировать». В результате запускается визуальный прогресс выполнения. Введенный текст проходит предобработку (удаление лишних пробелов), токенизируется и подается в модель T5ForConditionalGeneration. После генерации итог сокращается, очищается от дубликатов и отображается в поле вывода.
-
3. В случае выбора пункта «Классификация» загружается исходный текст, затем разбивается на токены и присваивается соответствующая метка из набора данных. Потом добавляются системные токены и формируется числовое представление. После преобразования, обучения, оптимизации процесса пользователь получает dataset, состоящий из исходной
-
4. В случае выбора пункта «Чат» создается и отображается окно чата GigaChatApp.
-
5. Пользователь может очистить текст и результат кнопкой «Очистить», либо закрыть программу кнопкой «Выход».
метки, первоначального текста и предсказанного результата.
Практическая реализация предлагаемого решения
Для практической реализации была использована среда разработки PyCharm, целевая версия используемого языка – Python 3.12. Для исполнения программного кода и дообучения моделей использовалась библиотека torch. Также для обучения были импортированы такие библиотеки, как transformers (загрузка модели и то-кенизатора), sklearn (разделение dataset), pandas (обработка CSV-файла), matplotlib (построение графиков).
В функции обучения был использован прямой проход модели, расчет функции потерь, обратное распространение ошибки, а также шаг оптимизации с использованием алгоритма AdamW [12]. Обучение осуществлено в течение трех эпох. По окончании обучения создаются графики точности и потерь, отдельно для обучающей и тестовой выборок (рисунок 1).
Из левого графика следует, что потери на обучающем наборе (Train Loss) последовательно сокращаются с каждой эпохой, т.е. модель все лучше запоминает тренировочные данные. Но Validation Loss (ошибка на валидации) наоборот – растет после первой эпохи. Это может быть признаком переобучения. Правый график показывает: точность на обучении уверенно растет, а валидационная точность сначала немного падает, а потом остается примерно стабильной, следовательно, переобучение не выполнено, и увеличивать количество эпох для обучения не потребуется.
Для модели суммаризации была использована абстрактивная суммаризация как наиболее эффективный инструмент для обработки большого объема данных. Использование модели суммаризации позволяет сжимать длинные тексты в краткое представление при сохранении основной мысли, что упрощает восприятие и ускоряет процесс принятия решений. Этот факт особенно актуален при мониторинге обратной связи в режиме реального времени и необходимости оперативной реакции на проблемные сообщения.
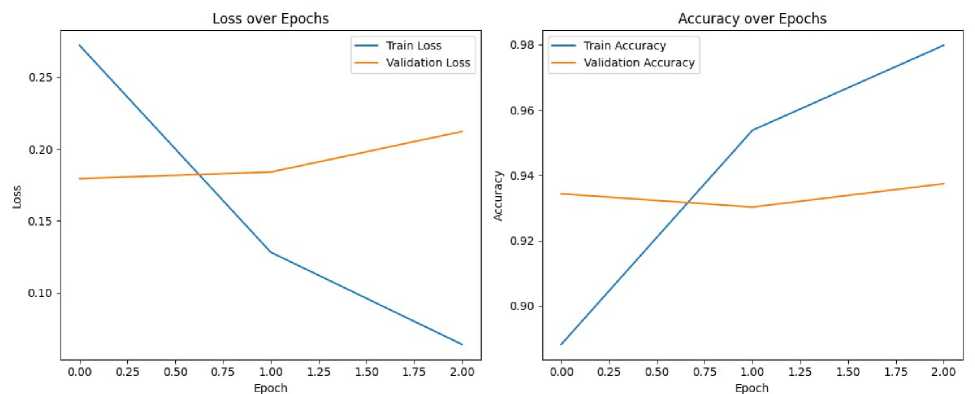
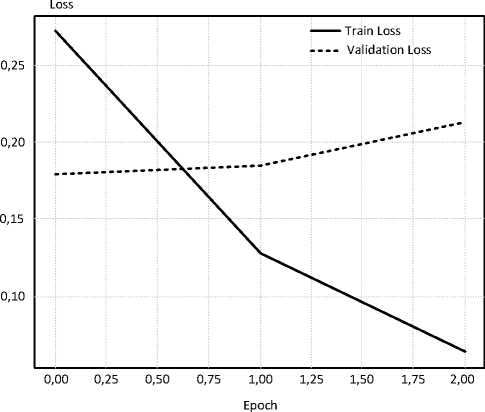
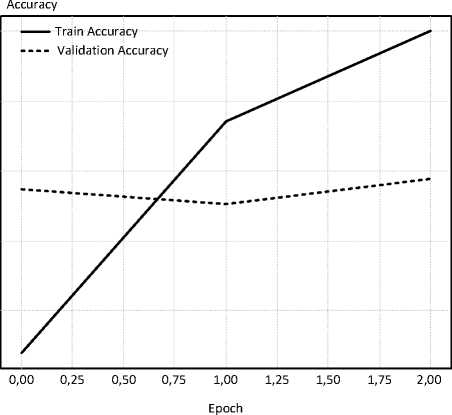
Рисунок 1. Графики модели классификации
Для более объективной и качественной оценки работы моделей суммаризации и классификации текстов был использован API GigaChat, позволяющий получить оценку от крупной языковой модели, ориентированной на понимание смысла. Это позволяет проводить качественную оценку с точки зрения человека, а не машинных шаблонов. Интеграция API GigaChat в систему использована как дополнительный модуль анализа и интерпретации текстов. Основной задачей API является обеспечение альтернативной интерпретации интерпретацию отзывов и их суммаризаций с использованием внешней крупной языковой модели. Это позволяет сравнивать выводы разработанной собственной модели (например, на основе RuBERT) с результатами, полученными от GigaChat, что позволит повысить надежность анализа и выявить возможные расхождения в оценке тональности или смысловой нагрузки текста.
Клиентская часть моделей – это полноценное графическое приложение на PyQt5, реализация которого применима ко всем имеющимся моделям. Итоговая форма модели представлена на рисунке 2.
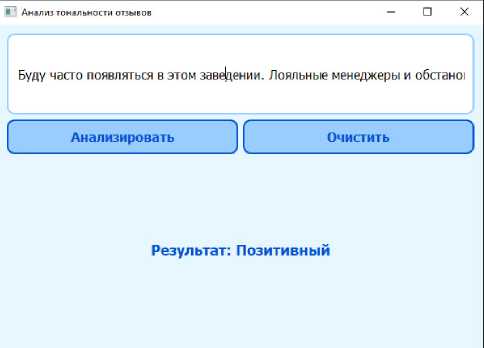
Рисунок 2. Форма для модели классификации
Задача классификации клиентских отзывов важна для множества бизнес-задач, где требуется использование алгоритмов для обучения. С помощью моделей, предобученных на данных заданной отрасли, можно автоматически определять тональность сообщений или текстов, а также выделять конкретные темы (например, технические проблемы, качество обслуживания или удовлетворенность клиента). Это позволяет формировать более точную аналитику, отслеживать динамику удовлетворенности клиентов и выявлять закономерности в поведении аудитории. Наличие автоматической классификации также способствует приоритизации обращений, например, негативные отклики могут попадать в отдельную очередь для первоочередной обработки.
Заключение
В рамках исследования рассмотрен вопрос применения методов машинного обучения для обработки и анализа клиентских отзывов в банковской сфере. Был сформирован dataset для выполнения ручного и автоматического анализа, включающие необходимые признаки и метки.
В ходе работы был разработан алгоритм, на основе которого была построена модель; определены инструменты и библиотеки, необходимые для его реализации; а также рассмотрены критерии оценки эффективности модели.
Сформированы модели для бинарной классификации и суммаризации текста, а также пользовательский интерфейс программного продукта. Параметры моделей оптимизированы для достижения наилучшей производительности. Реализовано подключение к API Gigachat для сравнительного анализа выходных данных моделей, что повышает степень объективности оценки.
Разработанный программный продукт позволит упростить процесс обработки больших данных за счет оптимизированных параметров работы. Программный продукт позволяет сократить время, требуемое для ручного тестирования моделей.
Разработанное программное обеспечение упростит применение методов машинного обучения для широкого круга пользователей, не обладающих глубокими техническими знаниями.
